從本專欄開始,作者正式研究Python深度學習、神經網路及人工智能相關知識,前一篇文章分享了Keras實作經典的深度學習文本分類演算法,包括LSTM、BiLSTM、BiLSTM+Attention和CNN、TextCNN,這篇文章將詳細介紹生成對抗網路GAN的基礎知識,包括什么是GAN、常用演算法(CGAN、DCGAN、infoGAN、WGAN)、發展歷程、預備知識,并通過Keras搭建最簡答的手寫數字圖片生成案例,本文主要學習小象學院老師的視頻,并結合論文介紹,希望對您有所幫助!不服GAN,讓我們開始吧~

文章目錄
- 一.GAN簡介
- 1.GAN背景知識
- 2.GAN原理決議
- 3.GAN經典案例
- 二.GAN預備知識
- 1.什么是神經網路
- 2.全連接層
- 3.激活函式
- 4.反向傳播
- 5.優化器選擇
- 6.卷積層
- 7.池化層
- 8.影像問題基本思路
- 三.GAN網路實戰分析
- 1.GAN模型決議
- (1) 目標函式
- (2) GAN圖片生成
- 2.生成手寫數字demo分析
- 3.其他常見GAN網路
- (1) CGAN
- (2) DCGAN
- (3) ACGAN
- (4) infoGAN
- (5) LAPGAN
- (6) EBGAN
- 4.GAN改進策略
- 四.總結
本專欄主要結合作者之前的博客、AI經驗和相關視頻及論文介紹,后面隨著深入會講解更多的Python人工智能案例及應用,基礎性文章,希望對您有所幫助,如果文章中存在錯誤或不足之處,還請海涵~作者作為人工智能的菜鳥,希望大家能與我在這一筆一劃的博客中成長起來,寫了這么多年博客,嘗試第一個付費專欄,為小寶賺點奶粉錢,但更多博客尤其基礎性文章,還是會繼續免費分享,該專欄也會用心撰寫,望對得起讀者,當然如果您是在讀學生或經濟拮據,可以私聊我給你每篇文章開白名單,或者轉發原文給你,更希望您能進步,一起加油喔!這篇文章在論文閱讀專欄免費供大家學習,這里主要是補全該專欄知識,
- 小象學院的老師 & B站 joe liu 老師分享
https://www.bilibili.com/video/BV1ht411c79k
注意,本文代碼采用GPU+Pycharm實作,如果你的電腦是CPU實作,將相關GPU操作注釋即可,這里僅做簡單的對比實驗,不進行引數優化、實驗原因分析及詳細的效果提升,后面文章會介紹優化、引數選擇、實驗評估等,
- Keras下載地址:https://github.com/eastmountyxz/AI-for-Keras
- TensorFlow下載地址:https://github.com/eastmountyxz/AI-for-TensorFlow
前文賞析:
- [Python人工智能] 一.TensorFlow2.0環境搭建及神經網路入門
- [Python人工智能] 二.TensorFlow基礎及一元直線預測案例
- [Python人工智能] 三.TensorFlow基礎之Session、變數、傳入值和激勵函式
- [Python人工智能] 四.TensorFlow創建回歸神經網路及Optimizer優化器
- [Python人工智能] 五.Tensorboard可視化基本用法及繪制整個神經網路
- [Python人工智能] 六.TensorFlow實作分類學習及MNIST手寫體識別案例
- [Python人工智能] 七.什么是過擬合及dropout解決神經網路中的過擬合問題
- [Python人工智能] 八.卷積神經網路CNN原理詳解及TensorFlow撰寫CNN
- [Python人工智能] 九.gensim詞向量Word2Vec安裝及《慶余年》中文短文本相似度計算
- [Python人工智能] 十.Tensorflow+Opencv實作CNN自定義影像分類案例及與機器學習KNN影像分類演算法對比
- [Python人工智能] 十一.Tensorflow如何保存神經網路引數
- [Python人工智能] 十二.回圈神經網路RNN和LSTM原理詳解及TensorFlow撰寫RNN分類案例
- [Python人工智能] 十三.如何評價神經網路、loss曲線圖繪制、影像分類案例的F值計算
- [Python人工智能] 十四.回圈神經網路LSTM RNN回歸案例之sin曲線預測
- [Python人工智能] 十五.無監督學習Autoencoder原理及聚類可視化案例詳解
- [Python人工智能] 十六.Keras環境搭建、入門基礎及回歸神經網路案例
- [Python人工智能] 十七.Keras搭建分類神經網路及MNIST數字影像案例分析
- [Python人工智能] 十八.Keras搭建卷積神經網路及CNN原理詳解
[Python人工智能] 十九.Keras搭建回圈神經網路分類案例及RNN原理詳解 - [Python人工智能] 二十.基于Keras+RNN的文本分類vs基于傳統機器學習的文本分類
- [Python人工智能] 二十一.Word2Vec+CNN中文文本分類詳解及與機器學習(RF\DTC\SVM\KNN\NB\LR)分類對比
- [Python人工智能] 二十二.基于大連理工情感詞典的情感分析和情緒計算
- [Python人工智能] 二十三.基于機器學習和TFIDF的情感分類(含詳細的NLP資料清洗)
- [Python人工智能] 二十四.易學智能GPU搭建Keras環境實作LSTM惡意URL請求分類
- [Python人工智能] 二十六.基于BiLSTM-CRF的醫學命名物體識別研究(上)資料預處理
- [Python人工智能] 二十七.基于BiLSTM-CRF的醫學命名物體識別研究(下)模型構建
- [Python人工智能] 二十八.Keras深度學習中文文本分類萬字總結(CNN、TextCNN、LSTM、BiLSTM、BiLSTM+Attention)
- [Python人工智能] 二十九.什么是生成對抗網路GAN?基礎原理和代碼普及(1)
《人工智能狂潮》讀后感——什么是人工智能?(一)
一.GAN簡介
1.GAN背景知識
Ian Goodfellow 因提出了生成對抗網路(GANs,Generative Adversarial Networks)而聞名, GAN最早由Ian Goodfellow于2014年提出,以其優越的性能,在不到兩年時間里,迅速成為一大研究熱點,他也被譽為“GANs之父”,甚至被推舉為人工智能領域的頂級專家,
- GAN原文:https://arxiv.org/abs/1406.2661

實驗運行結果如下圖所示,生成了對應的影像,

或許,你對這個名字還有些陌生,但如果你對深度學習有過了解,你就會知道他,最暢銷的這本《深度學習》作者正是Ian Goodfellow大佬,

在2016年,Ian Goodfellow大佬又通過50多頁的論文詳細介紹了GAN,這篇文章也推薦大家去學習,
- https://arxiv.org/pdf/1701.00160.pdf

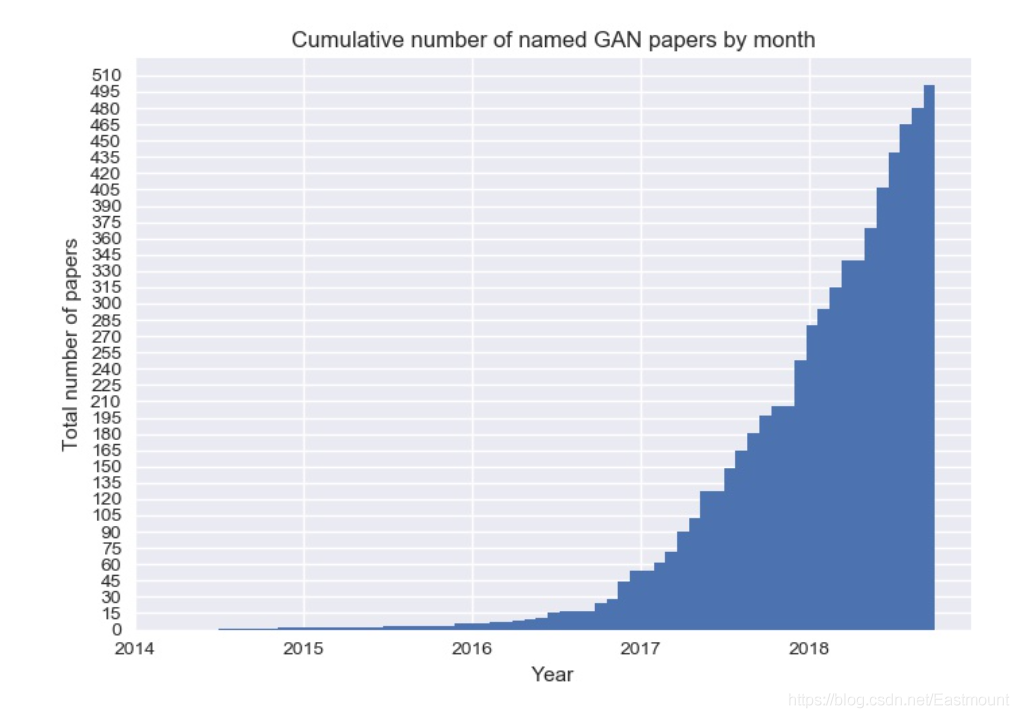
Yann LeCun稱GAN為“過去十年機器學習界最有趣的idea”,GAN在github上的火熱程度如下圖所示,呈指數增漲,出現各種變形,當然,其中也存在很多比較水的文章,推薦大家盡量學習比較經典的模型,
- https://github.com/hindupuravinash/the-gan-zoo
2.GAN原理決議
首先,什么是GAN?
GANs(Generativeadversarial networks,對抗式生成網路)可以把這三個單詞拆分理解,
- Generative:生成式模型
- Adversarial:采取對抗的策略
- Networks:網路(不一定是深度學習)
正如shunliz大佬總結:
GANs是一類生成模型,從字面意思不難猜到它會涉及兩個“對手”,一個稱為Generator(生成者),一個稱為Discriminator(判別者),Goodfellow最初arxiv上掛出的GAN tutorial文章中將它們分別比喻為偽造者(Generator)和警察(Discriminator),偽造者總想著制造出能夠以假亂真的鈔票,而警察則試圖用更先進的技術甄別真偽,兩者在博弈程序中不斷升級自己的技術,
從博弈論的角度來看,如果是零和博弈(zero-sum game),兩者最侄訓達到納什均衡(Nash equilibrium),即存在一組策略(g, d),如果Generator不選擇策略g,那么對于Discriminator來說,總存在一種策略使得Generator輸得更慘;同樣地,將Generator換成Discriminator也成立,
如果GANs定義的lossfunction滿足零和博弈,并且有足夠多的樣本,雙方都有充足的學習能力情況,在這種情況下,Generator和Discriminator的最優策略即為納什均衡點,也即:Generator產生的都是“真鈔”(材料、工藝技術與真鈔一樣,只是沒有得到授權),Discriminator會把任何一張鈔票以1/2的概率判定為真鈔,
那么,GAN究竟能做什么呢?
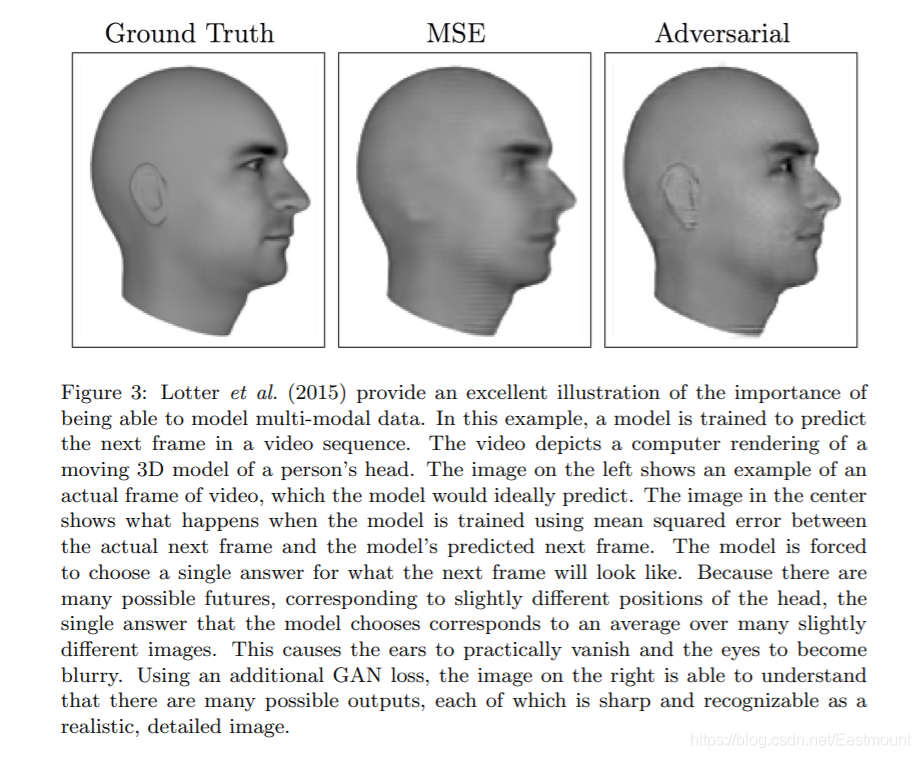
如下圖所示,這是一張非常有意思的圖,最左邊是真實的圖,我們希望去預測視頻后幾幀的模樣,中間這張圖是用MSE做的,最右邊的圖是生成對抗網路做的,通過細節分析,我們可以看到中間這張圖的耳朵和眼睛都是模糊的,而GAN生成的效果明顯更好,
接著我們在看一個超解析度的實體,首先給出一張超解析度的圖,最左邊的影像是原始高解析度影像(original),然后要對其進行下采樣,得到低解析度影像,接著采用不同的方法對低解析度影像進行恢復,具體作業如下:
- bicubic:第二張圖是bicubic方法恢復的影像,經過壓縮再拉伸還原影像,通過插值運算實作,但其影像會變得模糊,
- SRResNet:第三張影像是通過SRResNet實作的恢復,比如先壓縮影像再用MSE和神經網路學習和真實值的差別,再進行恢復,(SRResNet is a neural network trained with mean squared error)
- SRGAN:第四張圖是通過SRGAN實作的,其恢復效果更優,SRGAN是在GAN基礎上的改進,它能夠理解有多個正確的答案,而不是在許多答案中給出一個最佳輸出,

我們注意觀察影像頭部雕飾的細節,發現GAN恢復的輪廓更清晰,該實驗顯示了使用經過訓練的生成模型從多模態分布生成真實樣本的優勢,

在這里,我們也科普下超解析度——SRCNN,
它最早是在論文《Learning a Deep Convolutional Network for Image Super-Resolution》中提出,這篇文章的四位作者分別為董超,Chen Change Loy,何凱明,湯曉歐,也都是妥妥的大神,從CV角度來看,這篇論文是真的厲害,
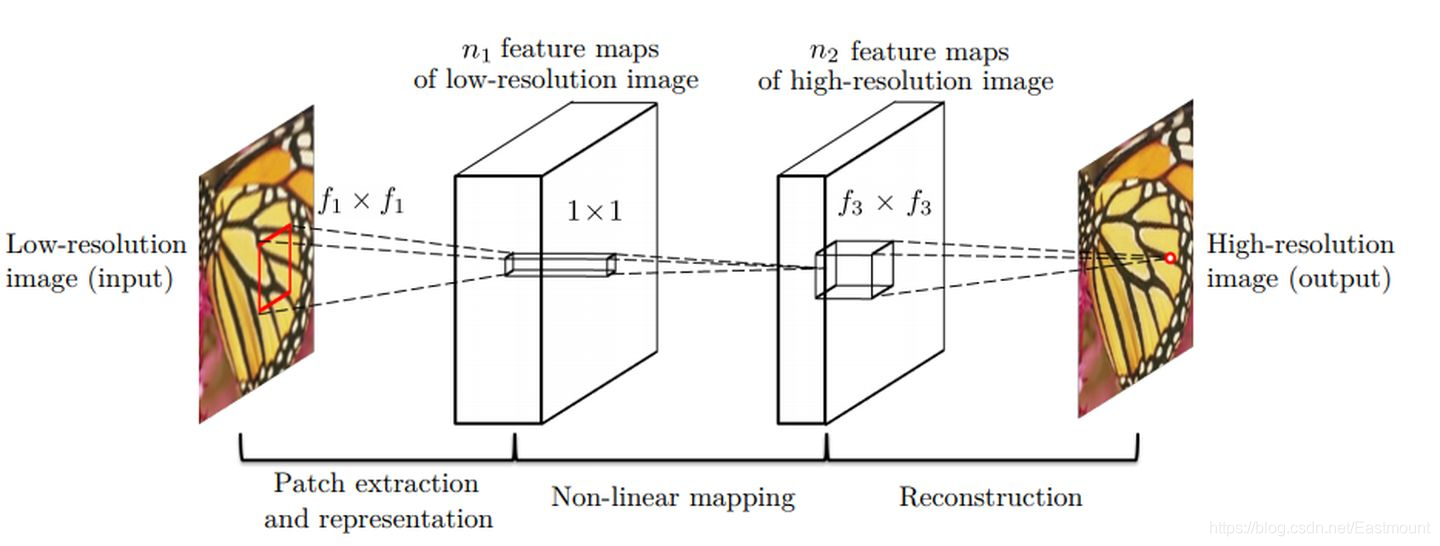
現假設要解決一個問題:能不能解決超解析度,從一個低解析度的影像恢復成一個高解析度的影像,那怎么做呢? 他們通過增加兩個卷積層的網路就解決了一個實際問題,并且這篇文章發了一個頂會,
- https://link.springer.com/chapter/10.1007/978-3-319-10593-2_13
更詳細的介紹參考知乎oneTaken大佬的分享,
這是第一篇將端到端的深度學習訓練來進行超分的論文,整篇論文的的程序現在看起來還是比較簡單的,先將低解析度圖片雙三次插值上采樣到高解析度圖片,然后再使用兩層卷積來進行特征映射,最后使用MSE來作為重建損失函式進行訓練,從現在來看很多東西還是比較粗糙的,但這篇論文也成為很多超分論文的baseline,
整篇論文的創新點有:
(1) 使用了一個卷積神經網路來進行超分,端到端的學習低解析度與超解析度之間的映射,
(2) 將提出的神經網路模型與傳統的稀疏編碼方法之間建立聯系,這種聯系還指導用來設計神經網路模型,
(3) 實驗結果表明深度學習方法可以用于超分中,可以獲得較好的質量和較快的速度,
整個的模型架構非常的簡單,先是對于輸入圖片進行雙三次插值采樣到高分辨空間,然后使用一層卷積進行特征提取,再用ReLU進行非線性映射,最后使用一個卷積來進行重建,使用MSE來作為重建損失,中間一個插曲是將傳統用于超分的稀疏編碼演算法進行了延伸,可以看作是一種具有不同非線性映射的卷積神經網路模型,
3.GAN經典案例
GNN究竟能做什么呢?
下面來看看一些比較有趣的GAN案例,
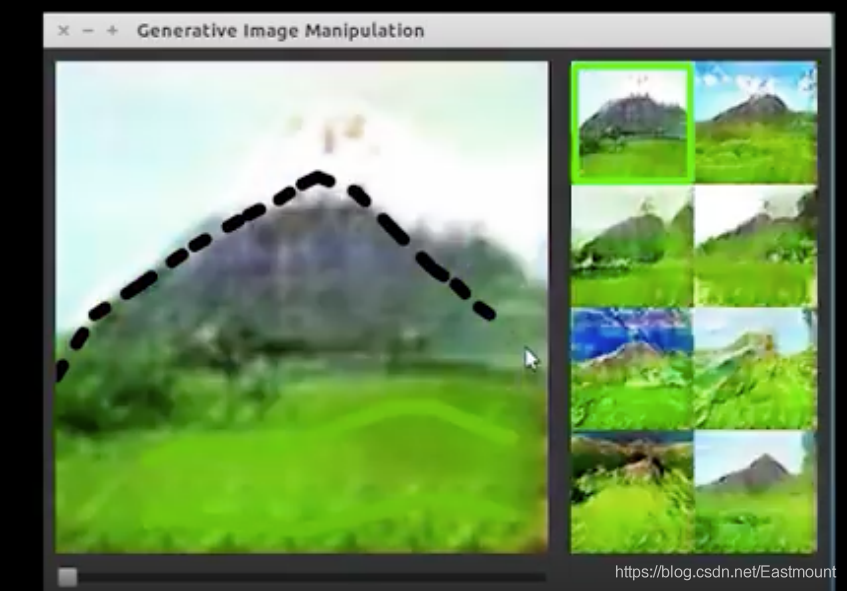
首先是一個視頻,這篇文章中介紹了Zhu等人開發了互動式(interactive)生成對抗網路(iGAN),用戶可以繪制影像的粗略草圖,就使用GAN生成相似的真實影像,在這個例子中,用戶潦草地畫了幾條綠線,就把它變成一塊草地,用戶再花了一條黑色的三角形,就創建了一個山包,
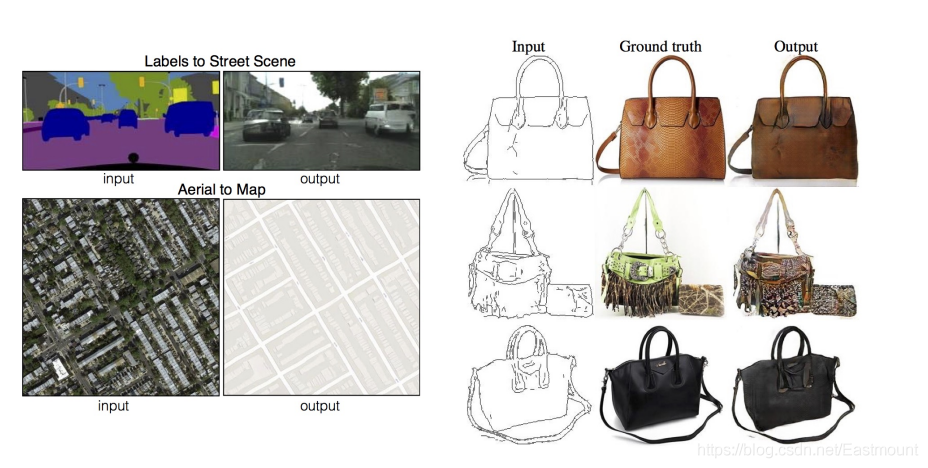
另一個比較經典的案例是左側輸入的皮包簡圖最終生成接近真實包的影像,或者將衛星照片轉換成地圖,將閾值車輛影像轉換為現實中逼真的影像,
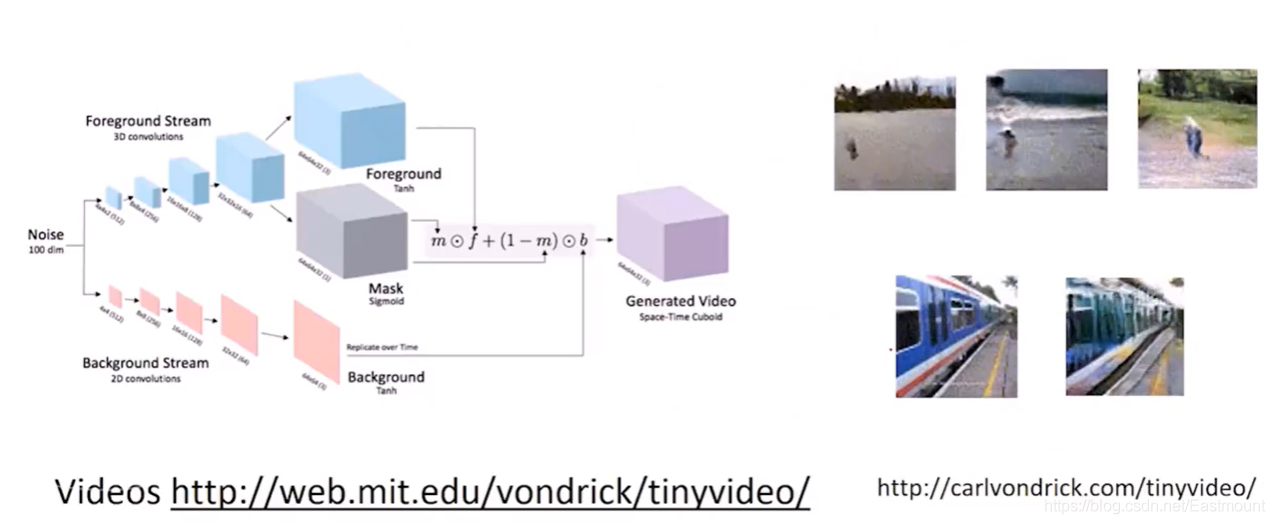
再比如通過GAN去預測視頻中下一幀影片會發生什么,比如右下角給了一張火車的靜態圖片,會生成一段火車跑動的動態視頻,
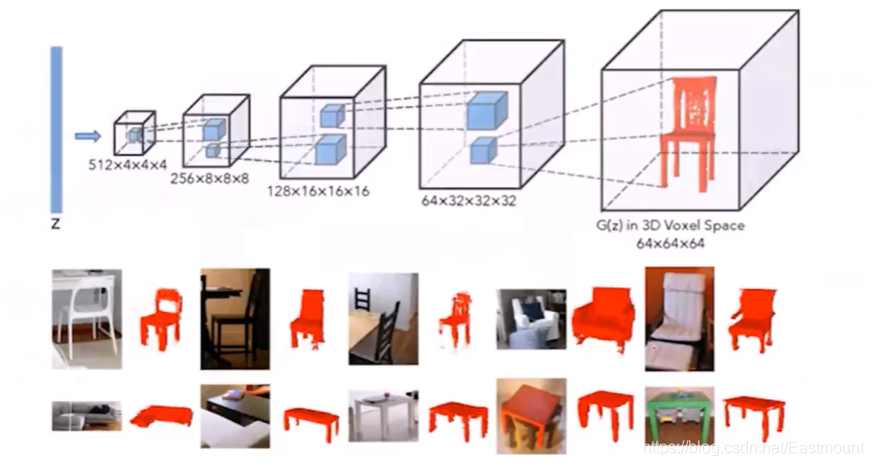
Wu等在NIPS 2016中通過GAN實作了用噪聲去生成一張3D椅子模型,
下圖是starGAN,左側輸入的是一張人臉,然后GAN會生成對應的喜怒哀樂表情,這篇文章的創新不是說GAN能做這件事,而是提出一個方案,所有的核心功能都在一起,只訓練一個生成器,即不是生成多對多的生成器,而只訓練一個生成器就能實作這些功能,
starGAN轉移從RaFD資料集中學到的知識,在CelebA資料集上的多域影像轉換結果,第一和第六列顯示輸入影像,其余列是由starGAN生成的影像,請注意,這些影像是由一個單一的生成器網路生成的,而憤怒、快樂和恐懼等面部表情標簽都來自RaFD,而不是CelebA,
- http://cn.arxiv.org/pdf/1711.09020.pdf

二.GAN預備知識
為什么要講預備知識呢?
通過學習神經網路的基礎知識,能進一步加深我們對GAN的理解,當然,看到這篇文章的讀者可能很多已經對深度學習有過了解或者是大佬級別,這里也照顧下初學者,普及下GAN相關基礎知識,這里推薦初學者去閱讀作者該系列文章,介紹了很多基礎原理,
1.什么是神經網路
首先,深度學習就是模擬人的腦神經(生物神經網路),比如下圖左上方①中的神經元,可以認為是神經網路的接收端,它有很多的樹突接收信號,對應Neuron的公式如下:
z = a 1 w 1 + . . . + a k w k + . . . + a K w K + b z=a_1w_1+...+a_kw_k+...+a_Kw_K+b z=a1?w1?+...+ak?wk?+...+aK?wK?+b
其中,a表示信號(樹突接收),w表示對應的權重,它們會進行加權求和組合且包含一個偏置b,通過激活函式判斷能否給下一個神經元傳遞信號,
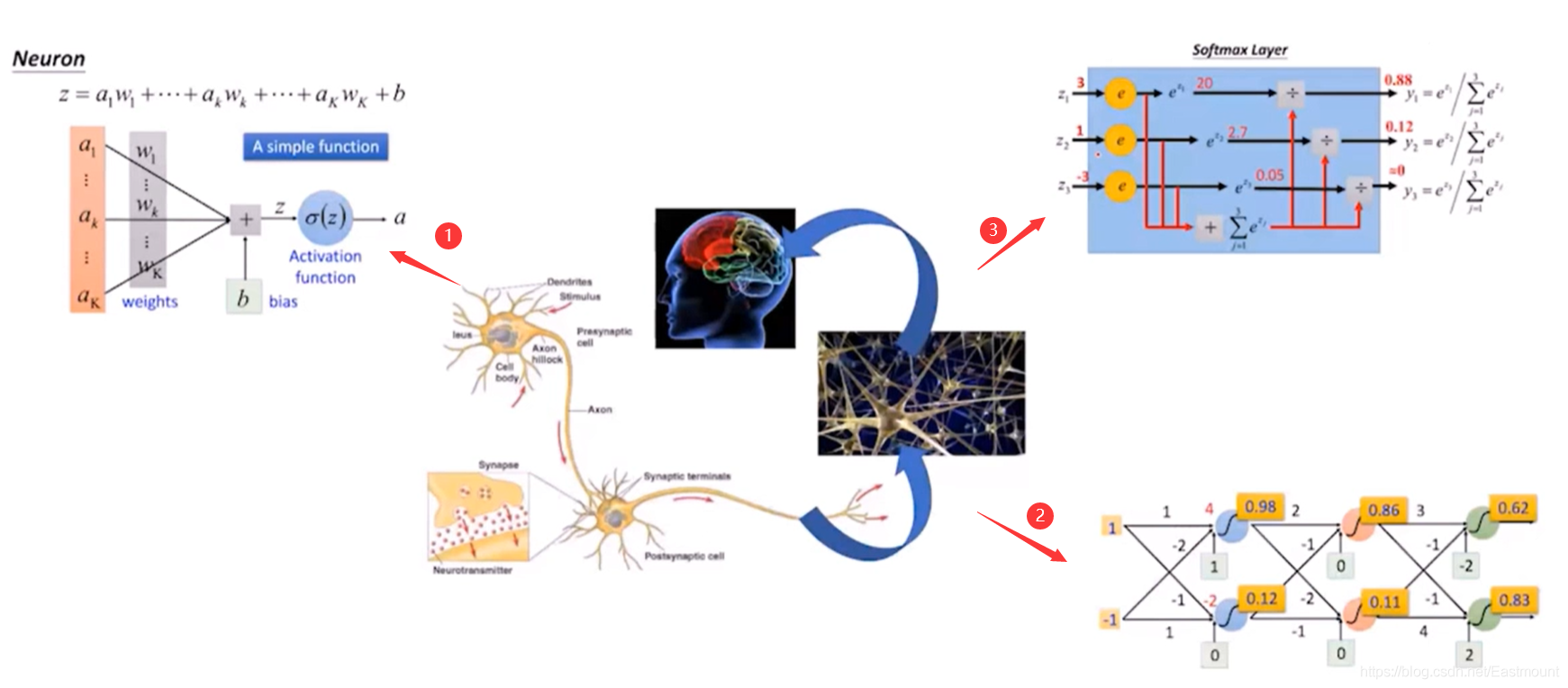
有了這個神經元之后,我們需要構建網路,如右下方②所示,經過一層、兩層、三層神經網路,我們最后會有一個判斷,如右上方③所示,經過Softmax函式判斷,決策這幅影像是什么,比如貓或狗,
其次,深度學習有哪些知識點呢?
深度學習的網路設計如下圖所示:
- 神經網路常見層
全連接層、激活層、BN層、Dropout層、卷積層、池化層、回圈層、Embedding層、Merege層等 - 網路配置
損失函式、優化器、激活函式、性能評估、初始化方法、正則項等 - 網路訓練流程
預訓練模型、訓練流程、資料預處理(歸一化、Embedding)、資料增強(圖片翻轉旋轉曝光生成海量樣本)等

補充:
深度學習的可解釋性非常差,很多時候不知道它為什么正確,NLP會議上也經常討論這個可解釋性到底重不重要,個人認為,如果用傳統的方法效果能達到80%,而深度學習如果提升非常大,比如10%,個人感覺工業界還是會用的,因為能提升性能并解決問題,除非比如風控任務,美團檢測例外刷單情況,此時需要準確的確認是否刷單,
2.全連接層
隱藏層的輸入和輸出都有關聯,即全連接層的每一個結點都與上一層的所有結點相連,用來把前邊提取到的特征綜合起來,由于其全相連的特性,一般全連接層的引數也是最多的,
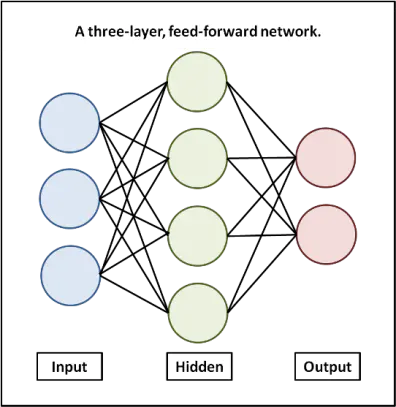
全連接層包括神經元的計算公式、維度(神經元個數)、激活函式、權值初始化方法(w、b)、正則項,
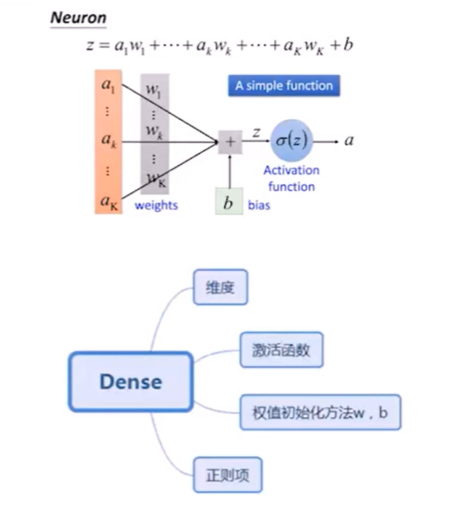
3.激活函式
激活函式(activation function)會讓某一部分神經元先激活,然后把激活的資訊傳遞給后面一層的神經系統中,比如,某些神經元看到貓的圖片,它會對貓的眼睛特別感興趣,那當神經元看到貓的眼睛時,它就被激勵了,它的數值就會被提高,
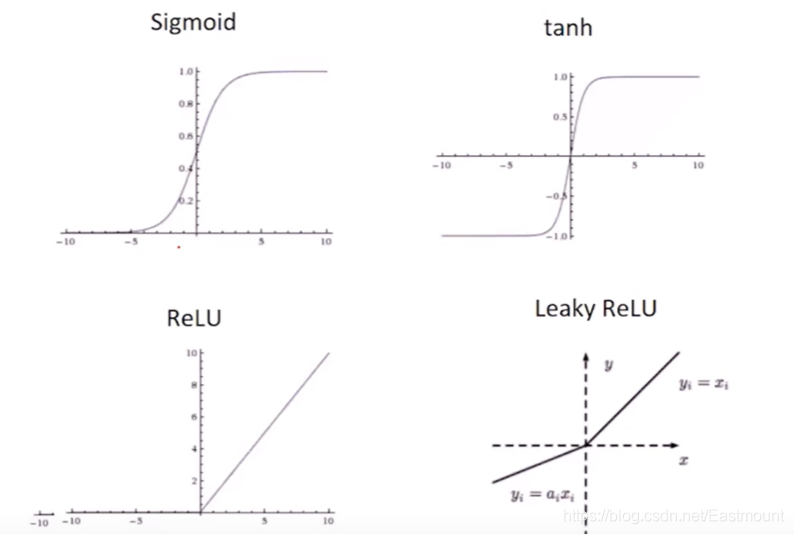
激活函式相當于一個過濾器或激勵器,它把特有的資訊或特征激活,常見的激活函式包括softplus、sigmoid、relu、softmax、elu、tanh等,
- 對于隱藏層,我們可以使用relu、tanh、softplus等非線性關系;
- 對于分類問題,我們可以使用sigmoid(值越小越接近于0,值越大越接近于1)、softmax函式,對每個類求概率,最后以最大的概率作為結果;
- 對于回歸問題,可以使用線性函式(linear function)來實驗,
激活函式可以參考作者前面的第三篇文章,
- [Python人工智能] 三.TensorFlow基礎之Session、變數、傳入值和激勵函式
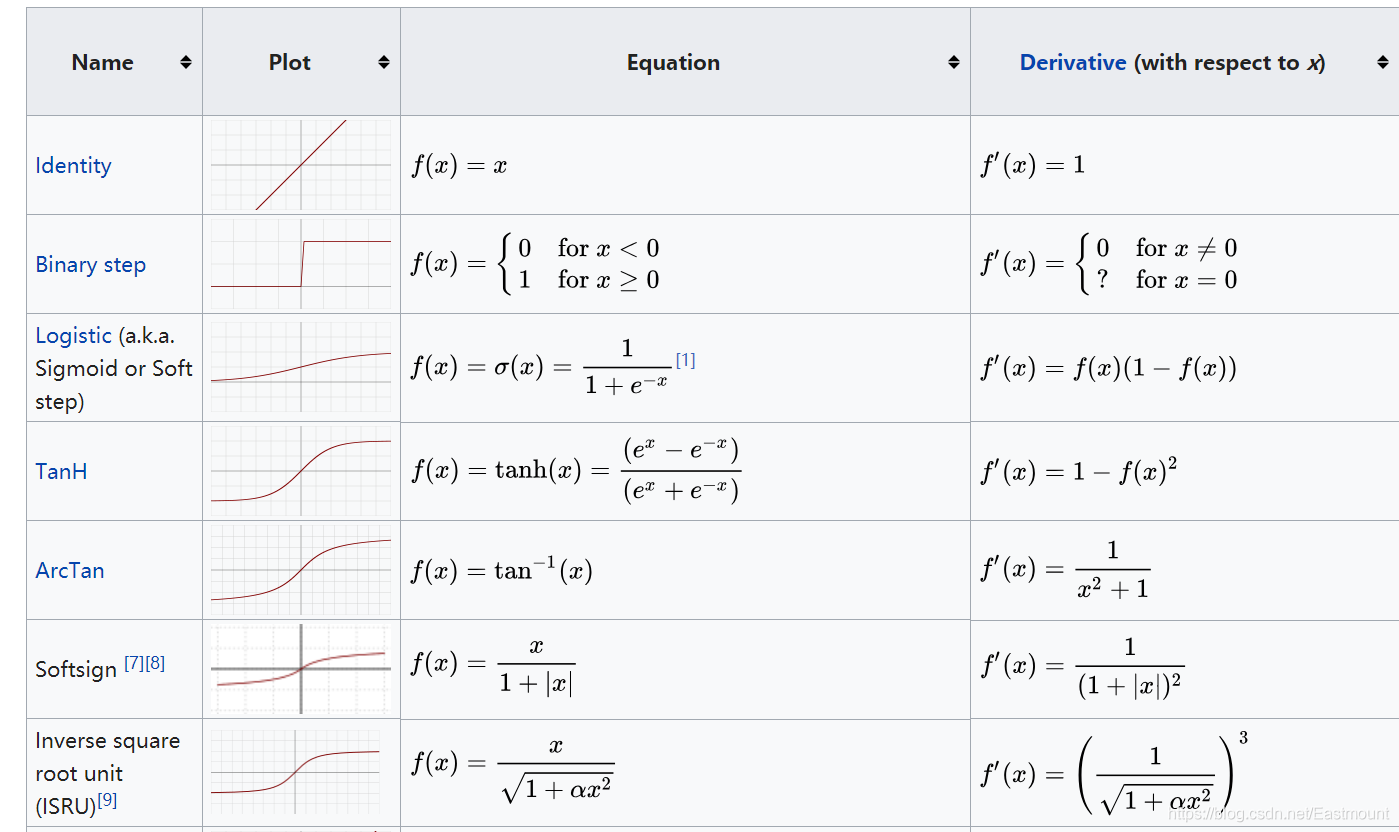
常用的激活函式Sigmoid、tanh、ReLU、Leaky ReLU曲線如下圖所示:
4.反向傳播
BP神經網路是非常經典的網路,這里通過知乎EdisonGzq大佬的兩張圖來解釋神經網路的反向傳播,對于一個神經元而言,就是計算最后的誤差傳回來對每個權重的影響,即計算每層反向傳遞的梯度變化,
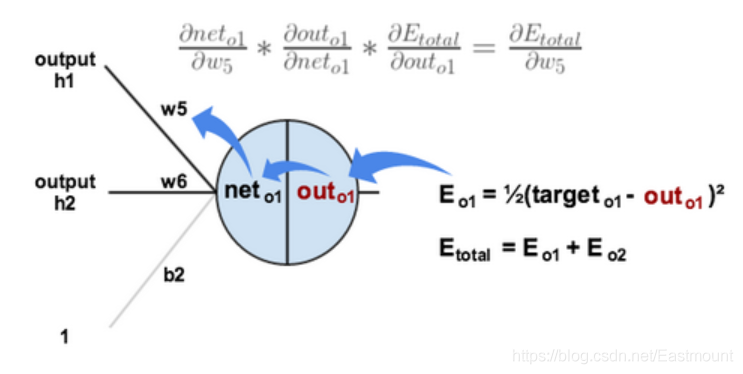
對于多個神經元而言,它是兩條線的輸出反向傳遞,如下圖所示Eo1和Eo2,
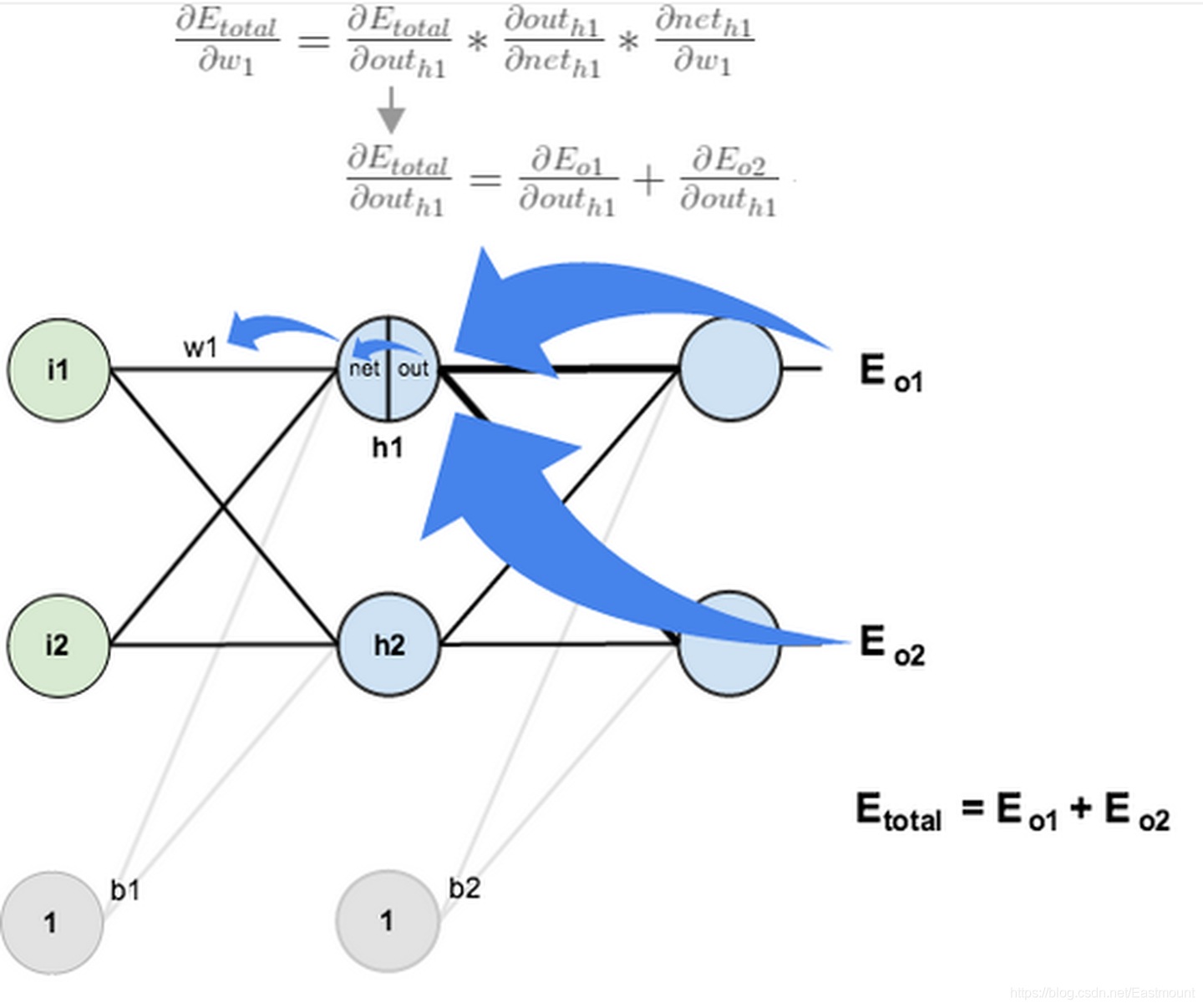
5.優化器選擇
存在梯度變化后,會有一個迭代的方案,這種方案會有很多選擇,優化器有很多種,但大體分兩類:
- 一種優化器是跟著梯度走,每次只觀察自己的梯度,它不帶重量
- 一種優化器是帶重量的
class tf.train.Optimizer是優化器(optimizers)類的基類,優化器有很多不同的種類,最基本的一種是GradientsDescentOptimizer,它也是機器學習中最重要或最基礎的線性優化,七種常見的優化器包括:
- class tf.train.GradientDescentOptimizer
- class tf.train.AdagradOptimizer
- class tf.train.AdadeltaOptimizer
- class tf.train.MomentumOptimizer
- class tf.train.AdamOptimizer
- class tf.train.FtrlOptimizer
- class tf.train.RMSPropOptimizer
下面簡單介紹其中四個常用的優化器:(推薦 優化器總結 )
-
GradientDescentOptimizer
梯度下降GD取決于傳進資料的size,比如只傳進去全部資料的十分之一,Gradient Descent Optimizer就變成了SGD,它只考慮一部分的資料,一部分一部分的學習,其優勢是能更快地學習到去往全域最小量(Global minimum)的路徑, -
MomentumOptimizer
它是基于學習效率的改變,它不僅僅考慮這一步的學習效率,還加載了上一步的學習效率趨勢,然后上一步加這一步的learning_rate,它會比GradientDescentOptimizer更快到達全域最小量, -
AdamOptimizer
Adam名字來源于自適應矩估計(Adaptive Moment Estimation),也是梯度下降演算法的一種變形,但是每次迭代引數的學習率都有一定的范圍,不會因為梯度很大而導致學習率(步長)也變得很大,引數的值相對比較穩定,Adam演算法利用梯度的一階矩估計和二階矩估計動態調整每個引數的學習率, -
RMSPropOptimizer
Google用它來優化阿爾法狗的學習效率,RMSProp演算法修改了AdaGrad的梯度積累為指數加權的移動平均,使得其在非凸設定下效果更好,
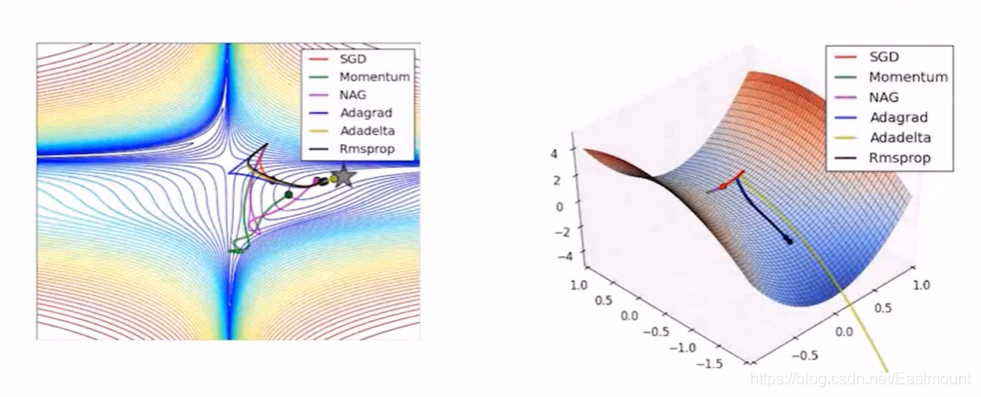
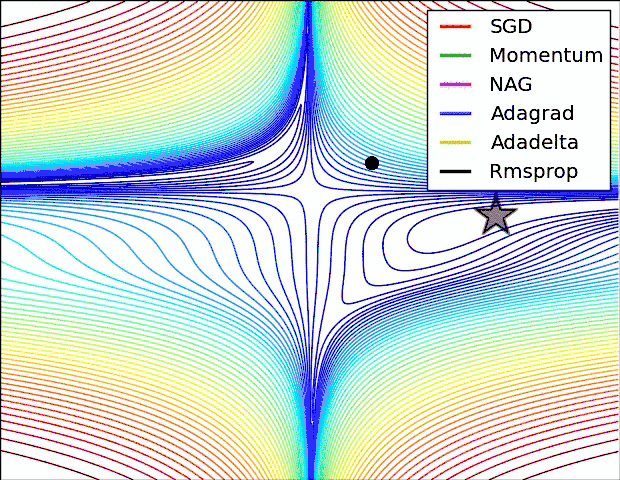
各種優化器用的是不同的優化演算法(如Mmentum、SGD、Adam等),本質上都是梯度下降演算法的拓展,下圖通過可視化對各種優化器進行了對比分析,機器學習從目標學習到最優的程序,有不同的學習路徑,由于Momentum考慮了上一步的學習(learning_rate),走的路徑會很長;GradientDescent的學習時間會非常慢,建議如下:
- 如果您是初學者,建議使用GradientDescentOptimizer即可,如果您有一定的基礎,可以考慮下MomentumOptimizer、AdamOptimizer兩個常用的優化器,高階的話,可以嘗試學習RMSPropOptimizer優化器,總之,您最好結合具體的研究問題,選擇適當的優化器,
6.卷積層
為什么會提出卷積層呢?因為全連接層存在一個核心痛點:
- 圖片引數太多,比如1000*1000的圖片,加一個隱藏層,隱藏層節點同輸入維數,全連接的引數是10^12,根本訓練不過來這么多引數,
利器一:區域感知野
提出了一個卷積核的概念,區域感知資訊,
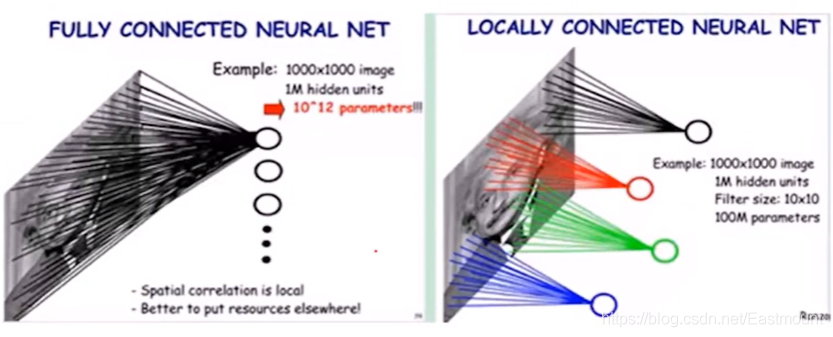
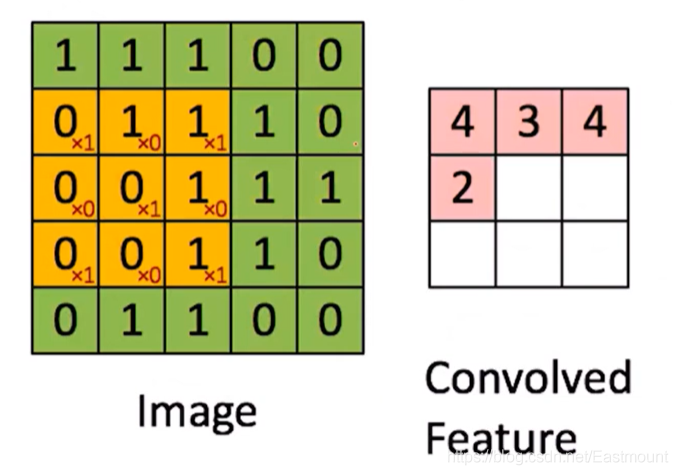
利器二:引數共享
從影像的左上角按照3x3掃描至右下角,獲得如右圖所示的結果,通過卷積共享減少了引數個數,注意,這里的卷積核是如下:
[ 1 0 1 0 1 0 1 0 1 ] \left[ \begin{matrix} 1 & 0 & 1 \\ 0 & 1 & 0 \\ 1 & 0 & 1 \end{matrix} \right] ???101?010?101????
當前掃描的區域為如下,最終計算結果為2,
[ 0 1 1 0 0 1 0 0 1 ] \left[ \begin{matrix} 0 & 1 & 1 \\ 0 & 0 & 1 \\ 0 & 0 & 1 \end{matrix} \right] ???000?100?111????
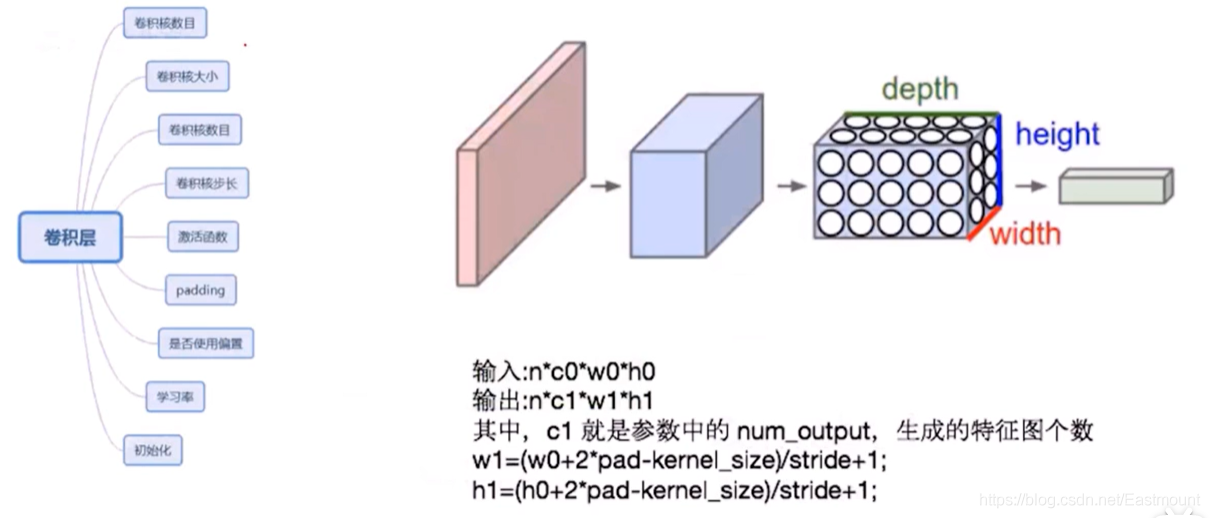
卷積層的核心知識點如下:
- 卷積核數目
- 卷積核大小:如上面3x3卷積核
- 卷積核數目
- 卷積核步長:上面的步長是1,同樣可以調格
- 激活函式
- Padding:比如上圖需要輸出5x5的結果圖,我們需要對其外圓補零
- 是否使用偏置
- 學習率
- 初始化
下圖展示了五層卷積層,每層輸出的內容,它從最初簡單的圖形學習到后續的復雜圖形,

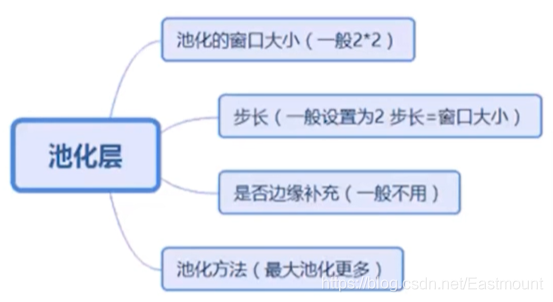
7.池化層
池化層主要解決的問題是:
- 使特征圖變小,簡化網路;特征壓縮,提取主要特征
常用池化層包括:
- 最大池化:比如從左上角紅色區域中選擇最大的6,接著是8、3、4
- 平均池化:選擇平均值
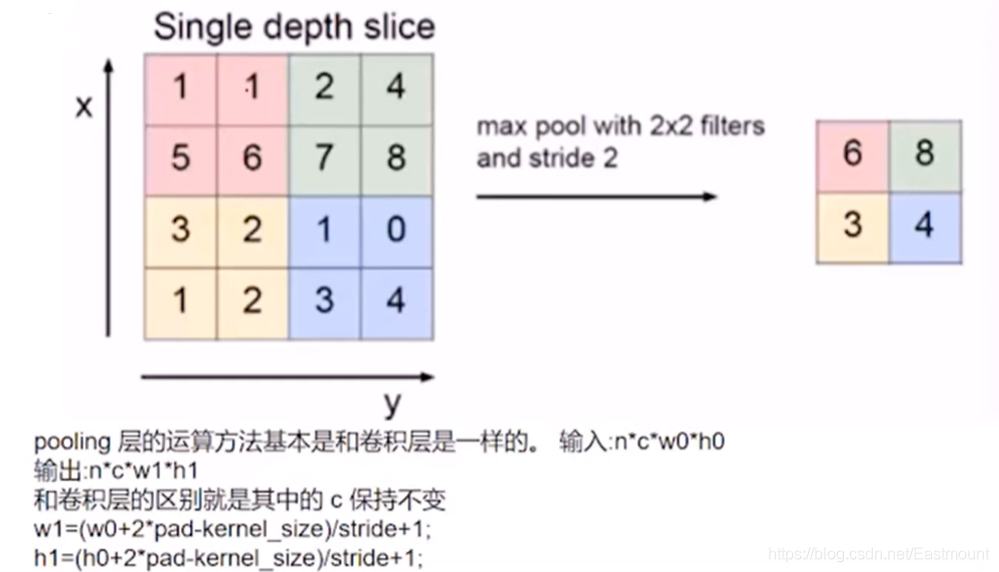
基本知識點如下圖所示:
8.影像問題基本思路
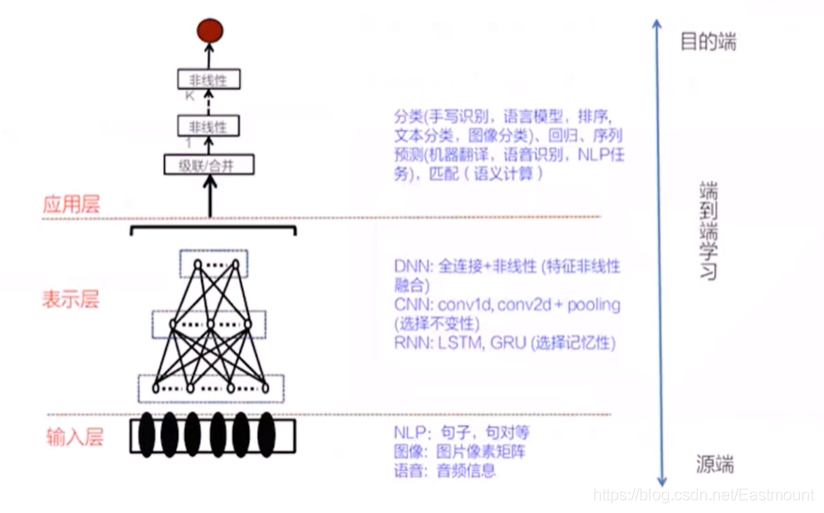
此時,我們通過介紹的全連接層、卷積層、池化層,就能解決實際的問題,如下圖所示:
- 輸入層
如NLP句子、句對,影像的像素矩陣,語音的音頻資訊 - 表示成
DNN:全連接+非線性(特征非線性融合)
CNN:Conv1d、Conv2d、Pooling
RNN:LSTM、GRU(選擇記憶性) - 應用層
分類、回歸、序列預測、匹配
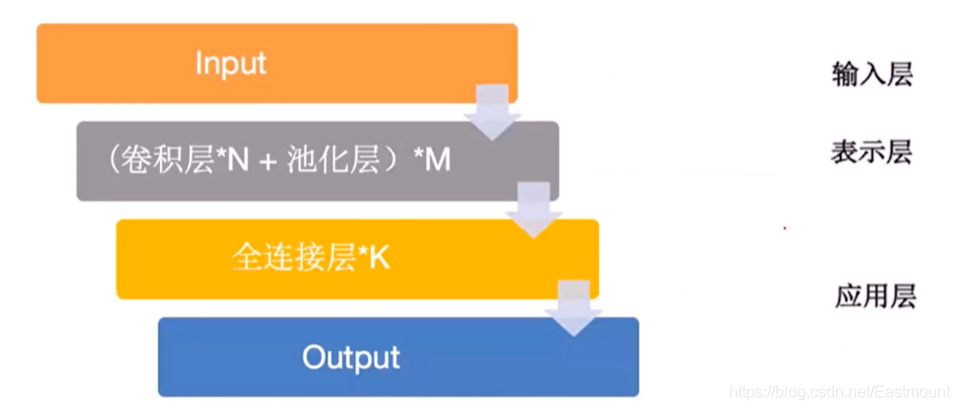
可以將影像問題基本思路簡化為下圖的模型,
至此,預備知識介紹完畢!接下來我們進入GAN網路實戰分析,
三.GAN網路實戰分析
GANs(Generativeadversarial networks)對抗式生成網路
- Generative:生成式模型
- Adversarial:采取對抗的策略
- Networks:網路
1.GAN模型決議
首先,我們先說說GAN要做什么呢?
- 最開始在圖(a)中我們生成綠線,即生成樣本的概率分布,黑色的散點是真實樣本的概率分布,這條藍線是一個判決器,判斷什么時候應該是真的或假的,
- 我們第一件要做的事是把判決器判斷準,如圖(b)中藍線,假設在0.5的位置下降,之前的認為是真實樣本,之后的認為是假的樣本,
- 當它固定完成后,在圖?中,生成器想辦法去和真實資料作擬合,想辦法去誤導判決器,
- 最終輸出圖(d),如果你真實的樣本和生成的樣本完全一致,分布完全一致,判決器就傻了,無法繼續判斷,
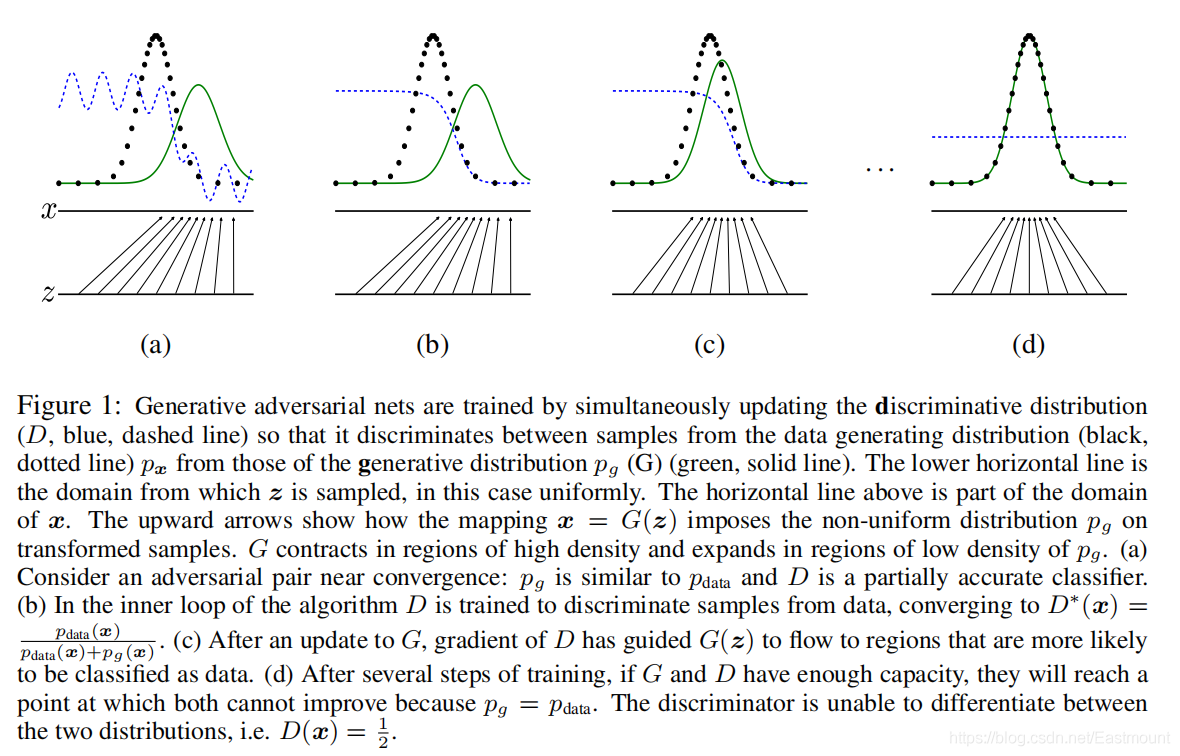
可能大家還比較蒙,下面我們再詳細介紹一個思路,
- 生成器:學習真實樣本以假亂真
- 判別器:小孩通過學習成驗鈔機的水平
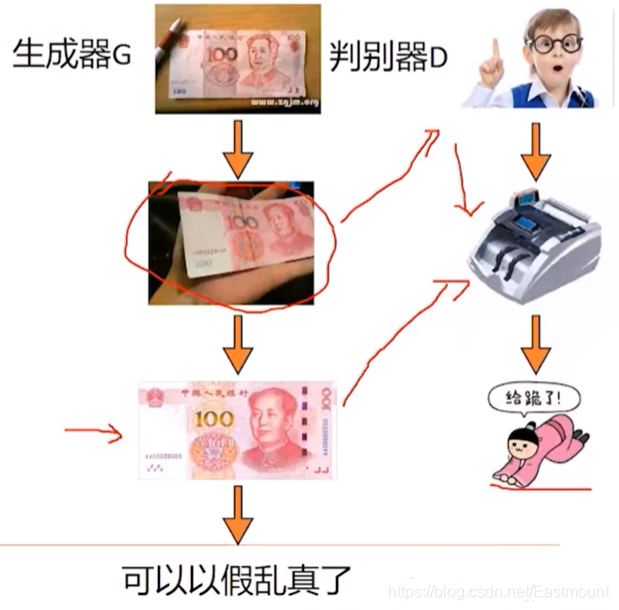
GAN的整體思路是一個生成器,一個判別器,并且GoodFellow論文證明了GAN全域最小點的充分必要條件是:生成器的概率分布和真實值的概率分布是一致的時候,
G l o b a l O p t i m a l i t y o f p g = p d a t a Global Optimality of p_g=p_{data} GlobalOptimalityofpg?=pdata?
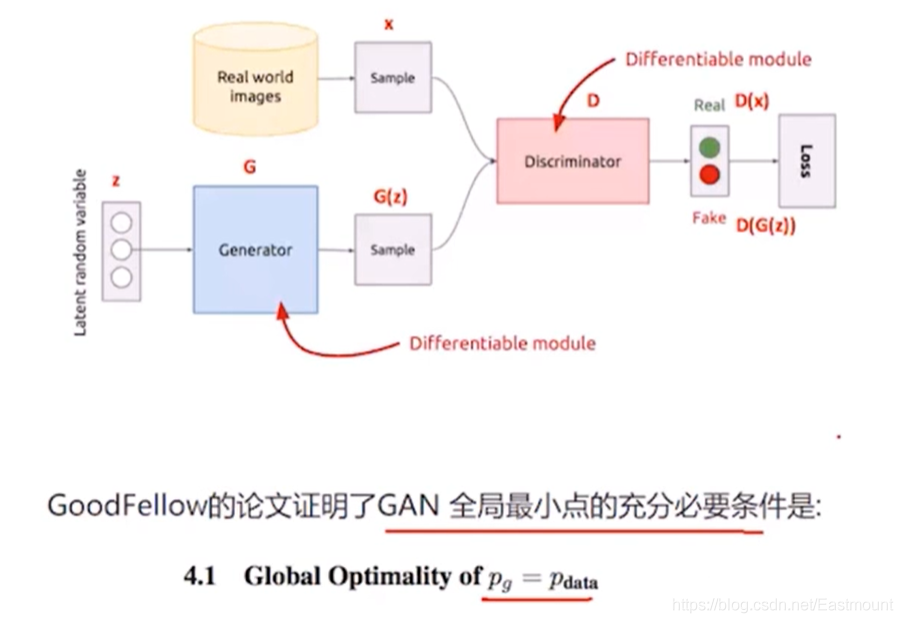
其次,GAN還需要分析哪些問題呢?
- 目標函式如何設定?
- 如何生成圖片?
- G生成器和D判決器應該如何設定?
- 如何進行訓練?
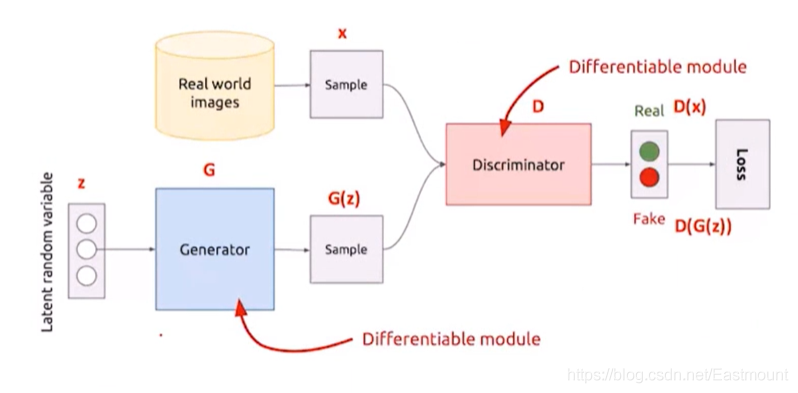
(1) 目標函式
該目標函式如下所示,其中:
- max()式子是第一步,表示把生成器G固定,讓判別器盡量區分真實樣本和假樣本,即希望生成器不動的情況下,判別器能將真實的樣本和生成的樣本區分開,
- min()式子是第二步,即整個式子,判別器D固定,通過調整生成器,希望判別器出現失誤,盡可能不要讓它區分開,
這也是一個博弈的程序,
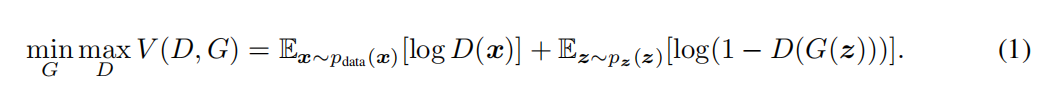
整個公式的具體含義如下:
- 式子由兩項構成,x表示真實圖片,z表示輸入G網路的噪聲,而G(z)表示G網路生成的圖片,
- D(x)表示D網路判斷真實圖片是否真實的概率(因為x就是真實的,所以對于D來說,這個值越接近1越好),
- D(G(z))是D網路判斷G生成的圖片是否真實的概率,
- G的目的:G應該希望自己生成的的圖片越接近真實越好,
- D的目的:D的能力越強,D(x)應該越大,D(G(x))應該越小,這時V(D,G)會變大,因此式子對于D來說是求最大(max_D),
- trick:為了前期加快訓練,生成器的訓練可以把log(1-D(G(z)))換成-log(D(G(z)))損失函式,
接著我們回到大神的原論文,看看其演算法(Algorithm 1)流程,
- 最外層是一個for回圈,接著是k次for回圈,中間迭代的是判決器,
- k次for回圈結束之后,再迭代生成器,
- 最后結束回圈,

(2) GAN圖片生成
接著我們介紹訓練方案,通過GAN生成圖片,
-
第一步(左圖):希望判決器盡可能地分開真實資料和我生成的資料,那么,怎么實作呢?我的真實資料就是input1(Real World images),我生成的資料是input2(Generator),input1的正常輸出是1,input2的正常輸出是0,對于一個判決器(Discriminator)而言,我希望它判決好,首先把生成器固定住(虛線T),然后生成一批樣本和真實資料混合給判決器去判斷,此時,經過訓練的判決器變強,即固定生成器且訓練判決器,
-
第二步(右圖):固定住判決器(虛線T),我想辦法去混淆它,剛才經過訓練的判決器很厲害,此時我們想辦法調整生成器,從而混淆判別器,即通過固定判決器并調整生成器,使得最后的輸出output讓生成的資料也輸出1(第一步為0),
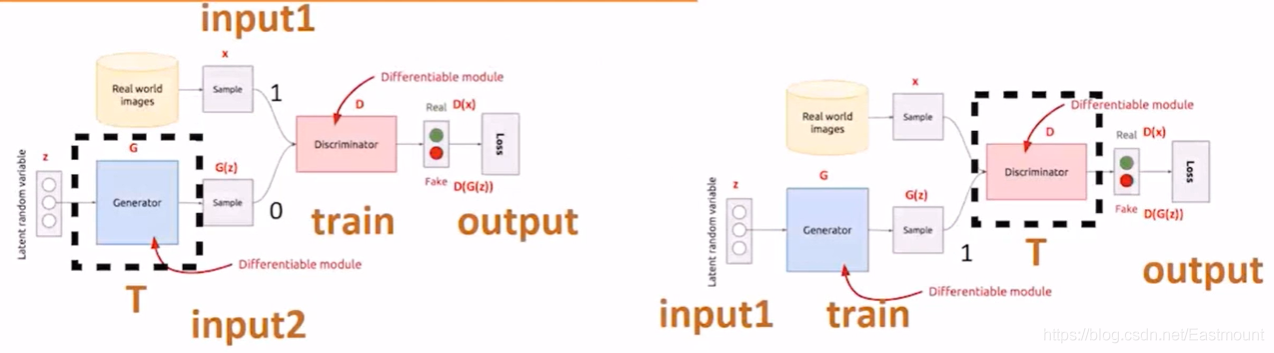
GAN的核心就是這些,再簡單總結下,即:
- 步驟1是在生成器固定的時候,我讓它產生一批樣本,然后讓判決器正確區分真實樣本和生成樣本,(生成器標簽0、真實樣本標簽1)
- 步驟2是固定判決器,通過調整生成器去盡可能的瞞混判決器,所以實際上此時訓練的是生成器,(生成器的標簽需要讓判決器識別為1,即真實樣本)
其偽代碼如下:
for 迭代 in range(迭代總數):
for batch in range(batch_size):
新batch = input1的batch + input2的batch (batch加倍)
for 輪數 in range(判別器中輪數):
步驟一 訓練D
步驟二 訓練G
2.生成手寫數字demo分析
接下來我們通過手寫數字影像生成代碼來加深讀者的印象,這是一個比較經典的共有資料集,包括影像分類各種案例較多,這里我們主要是生成手寫數字影像,

首先,我們看看生成器是如何生成一個影像(從噪音生成)?
核心代碼如下,它首先要隨機生成一個噪音(noise),所有生成的圖片都是靠噪音實作的,Keras參考代碼:
- https://github.com/jacobgil/keras-dcgan/blob/master/dcgan.py
(1) 生成器G
生成器總共包括:
- 全連接層:輸入100維,輸出1024維
- 全連接層:128x7x7表示圖片128通道,大小7x7
- BatchNormalization:如果不加它DCGAN程式會奔潰
- UpSampling2D:對卷積結果進行上采樣從而將特征圖放大 14x14
- Conv2D:卷積操作像素尺度不變(same)
- UpSampling2D:生成28x28
- Conv2D:卷積操作
- Activation:激活函式tanh

(2) 判別器D
判別器就是做一個二分類的問題,要么真要么假,
- Conv2D:卷積層
- MaxPooling2D:池化層
- Conv2D:卷積層
- MaxPooling2D:池化層
- Flatten:拉直一維
- Dense:全連接層
- Activation:sigmoid二分類
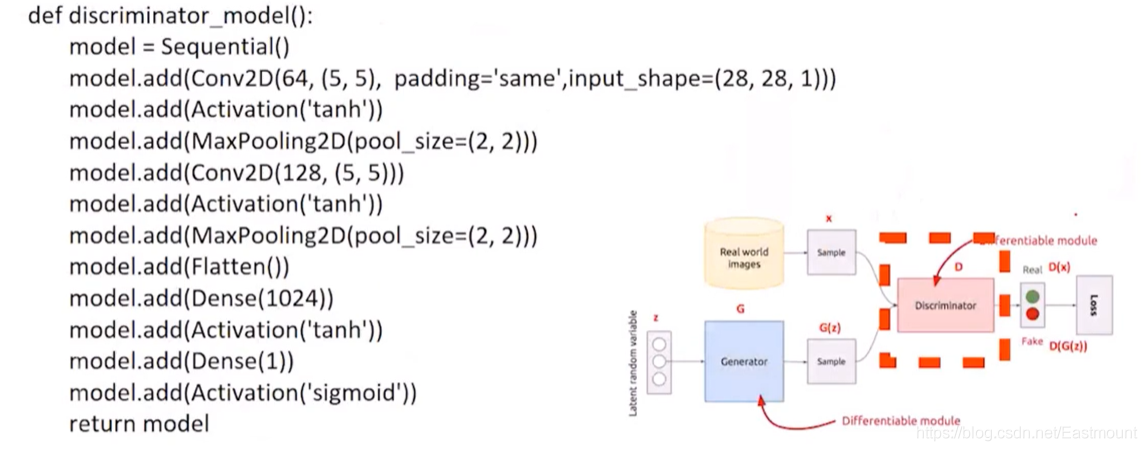
(3) 輔助函式
如何把D固定去調整G的函式generator_containing_discriminator,
- model.add(g):加載生成器G
- d.trainable=False:判決器D固定
combine_images函式實作合并影像的操作,
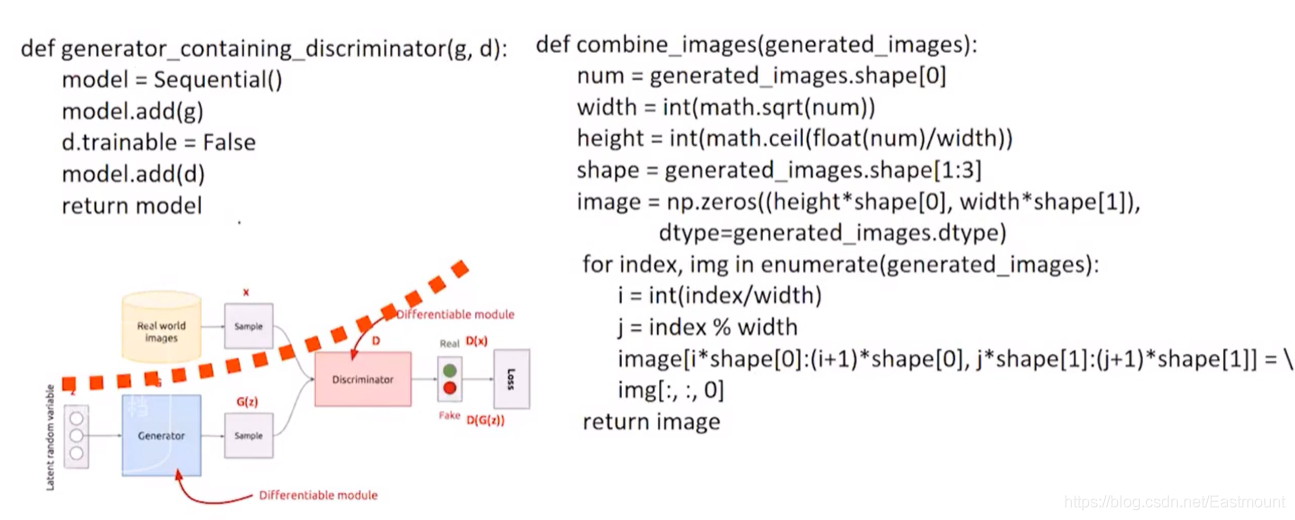
(4) GAN圖片生成訓練
GAN核心流程包括:
- load_data:載入圖片
- d = discriminator_model:定義判別器D
- g = generator_model:定義生成器G
- generator_containing_discriminator:固定D調整G
- SGD、compile:定義引數、學習率
- for epoch in range、for index in rangeBATCH
- X = np.concatenate:影像資料和生成資料混合
- y = [1] x BATCH_SIZE + [0] x BTCH_SIZE:輸出label
- d_loss = d.train_on_batch(X,y):訓練D判別器(步驟一)
- d.trainable = False:固定D
- g_loss = d_on_g.train_on_batch(noise, [1]xBATCH_SIZE):訓練G生成器(步驟二),混淆
- d.trainable = True:打開D重復操作
- 保存引數和模型

(5) 生成
模型訓練好之后,我們想辦法用GAN生成圖片,
- g = generator_model:定義生成器模型
- g.load_weights:載入訓練好的生成器(generator)
- noise:隨機產生噪聲
- 然后用G生成一幅影像,該影像就能欺騙判別器D

完整代碼如下:
這段代碼更像一個簡單的GAN生成圖片,
# -*- coding: utf-8 -*-
"""
Created on 2021-03-19
@author: xiuzhang Eastmount CSDN
參考:https://github.com/jacobgil/keras-dcgan
"""
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Reshape
from keras.layers.core import Activation
from keras.layers.normalization import BatchNormalization
from keras.layers.convolutional import UpSampling2D
from keras.layers.convolutional import Conv2D, MaxPooling2D
from keras.layers.core import Flatten
from keras.optimizers import SGD
from keras.datasets import mnist
import tensorflow as tf
import numpy as np
from PIL import Image
import argparse
import math
import os
## GPU處理 讀者如果是CPU注釋該部分代碼即可
## 指定每個GPU行程中使用顯存的上限 0.9表示可以使用GPU 90%的資源進行訓練
os.environ["CUDA_DEVICES_ORDER"] = "PCI_BUS_IS"
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.8)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options))
#----------------------------------------------------------------
#生成器
def generator_model():
model = Sequential()
model.add(Dense(input_dim=100, output_dim=1024))
model.add(Activation('tanh'))
model.add(Dense(128*7*7)) #7x7 128通道
model.add(BatchNormalization())
model.add(Activation('tanh'))
model.add(Reshape((7, 7, 128), input_shape=(128*7*7,)))
model.add(UpSampling2D(size=(2, 2)))
model.add(Conv2D(64, (5, 5), padding='same'))
model.add(Activation('tanh'))
model.add(UpSampling2D(size=(2, 2)))
model.add(Conv2D(1, (5, 5), padding='same'))
model.add(Activation('tanh'))
return model
#----------------------------------------------------------------
#判別器
def discriminator_model():
model = Sequential()
model.add(
Conv2D(64, (5, 5),
padding='same',
input_shape=(28, 28, 1))
)
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, (5, 5)))
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(1024))
model.add(Activation('tanh'))
model.add(Dense(1))
model.add(Activation('sigmoid'))
return model
#----------------------------------------------------------------
#輔助函式 固定D調整G
def generator_containing_discriminator(g, d):
model = Sequential()
model.add(g)
d.trainable = False
model.add(d)
return model
#輔助函式 合并影像
def combine_images(generated_images):
num = generated_images.shape[0]
width = int(math.sqrt(num))
height = int(math.ceil(float(num)/width))
shape = generated_images.shape[1:3]
image = np.zeros((height*shape[0], width*shape[1]),
dtype=generated_images.dtype)
for index, img in enumerate(generated_images):
i = int(index/width)
j = index % width
image[i*shape[0]:(i+1)*shape[0], j*shape[1]:(j+1)*shape[1]] = \
img[:, :, 0]
return image
#----------------------------------------------------------------
#訓練
def train(BATCH_SIZE):
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = (X_train.astype(np.float32) - 127.5)/127.5
X_train = X_train[:, :, :, None]
X_test = X_test[:, :, :, None]
#X_train = X_train.reshape((X_train.shape, 1) + X_train.shape[1:])
d = discriminator_model()
g = generator_model()
d_on_g = generator_containing_discriminator(g, d)
d_optim = SGD(lr=0.0005, momentum=0.9, nesterov=True)
g_optim = SGD(lr=0.0005, momentum=0.9, nesterov=True)
g.compile(loss='binary_crossentropy', optimizer="SGD")
d_on_g.compile(loss='binary_crossentropy', optimizer=g_optim)
d.trainable = True
d.compile(loss='binary_crossentropy', optimizer=d_optim)
for epoch in range(100):
print("Epoch is", epoch)
print("Number of batches", int(X_train.shape[0]/BATCH_SIZE))
for index in range(int(X_train.shape[0]/BATCH_SIZE)):
noise = np.random.uniform(-1, 1, size=(BATCH_SIZE, 100))
image_batch = X_train[index*BATCH_SIZE:(index+1)*BATCH_SIZE]
generated_images = g.predict(noise, verbose=0)
if index % 20 == 0:
image = combine_images(generated_images)
image = image*127.5+127.5
Image.fromarray(image.astype(np.uint8)).save(
str(epoch)+"_"+str(index)+".png")
X = np.concatenate((image_batch, generated_images))
y = [1] * BATCH_SIZE + [0] * BATCH_SIZE
d_loss = d.train_on_batch(X, y)
print("batch %d d_loss : %f" % (index, d_loss))
noise = np.random.uniform(-1, 1, (BATCH_SIZE, 100))
d.trainable = False
g_loss = d_on_g.train_on_batch(noise, [1] * BATCH_SIZE)
d.trainable = True
print("batch %d g_loss : %f" % (index, g_loss))
if index % 10 == 9:
g.save_weights('generator', True)
d.save_weights('discriminator', True)
#----------------------------------------------------------------
#GAN圖片生成
def generate(BATCH_SIZE, nice=False):
g = generator_model()
g.compile(loss='binary_crossentropy', optimizer="SGD")
g.load_weights('generator')
if nice:
d = discriminator_model()
d.compile(loss='binary_crossentropy', optimizer="SGD")
d.load_weights('discriminator')
noise = np.random.uniform(-1, 1, (BATCH_SIZE*20, 100))
generated_images = g.predict(noise, verbose=1)
d_pret = d.predict(generated_images, verbose=1)
index = np.arange(0, BATCH_SIZE*20)
index.resize((BATCH_SIZE*20, 1))
pre_with_index = list(np.append(d_pret, index, axis=1))
pre_with_index.sort(key=lambda x: x[0], reverse=True)
nice_images = np.zeros((BATCH_SIZE,) + generated_images.shape[1:3], dtype=np.float32)
nice_images = nice_images[:, :, :, None]
for i in range(BATCH_SIZE):
idx = int(pre_with_index[i][1])
nice_images[i, :, :, 0] = generated_images[idx, :, :, 0]
image = combine_images(nice_images)
else:
noise = np.random.uniform(-1, 1, (BATCH_SIZE, 100))
generated_images = g.predict(noise, verbose=1)
image = combine_images(generated_images)
image = image*127.5+127.5
Image.fromarray(image.astype(np.uint8)).save(
"generated_image.png")
#引數設定
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument("--mode", type=str)
parser.add_argument("--batch_size", type=int, default=128)
parser.add_argument("--nice", dest="nice", action="store_true")
parser.set_defaults(nice=False)
args = parser.parse_args()
return args
if __name__ == "__main__":
"""
args = get_args()
if args.mode == "train":
train(BATCH_SIZE=args.batch_size)
elif args.mode == "generate":
generate(BATCH_SIZE=args.batch_size, nice=args.nice)
"""
mode = "train"
if mode == "train":
train(BATCH_SIZE=128)
elif mode == "generate":
generate(BATCH_SIZE=128)
代碼執行引數:
Training:
python dcgan.py --mode train --batch_size <batch_size>
python dcgan.py --mode train --path ~/images --batch_size 128
Image generation:
python dcgan.py --mode generate --batch_size <batch_size>
python dcgan.py --mode generate --batch_size <batch_size> --nice : top 5% images according to discriminator
python dcgan.py --mode generate --batch_size 128
訓練程序,首先手寫數字MNIST圖片資料集可以下載存盤至該位置,也可以運行代碼在線下載,
Epoch is 0
Number of batches 468
batch 0 d_loss : 0.648902
batch 0 g_loss : 0.672132
batch 1 d_loss : 0.649307
....
batch 466 g_loss : 1.305099
batch 467 d_loss : 0.375284
batch 467 g_loss : 1.298173
Epoch is 1
Number of batches 468
batch 0 d_loss : 0.461435
batch 0 g_loss : 1.231795
batch 1 d_loss : 0.412679
....

運行程序中會生成很多影像,隨著訓練次數增加影像會越來越清晰,

然后引數設定為“generate”,利用GAN最終生成影像,如下圖所示,

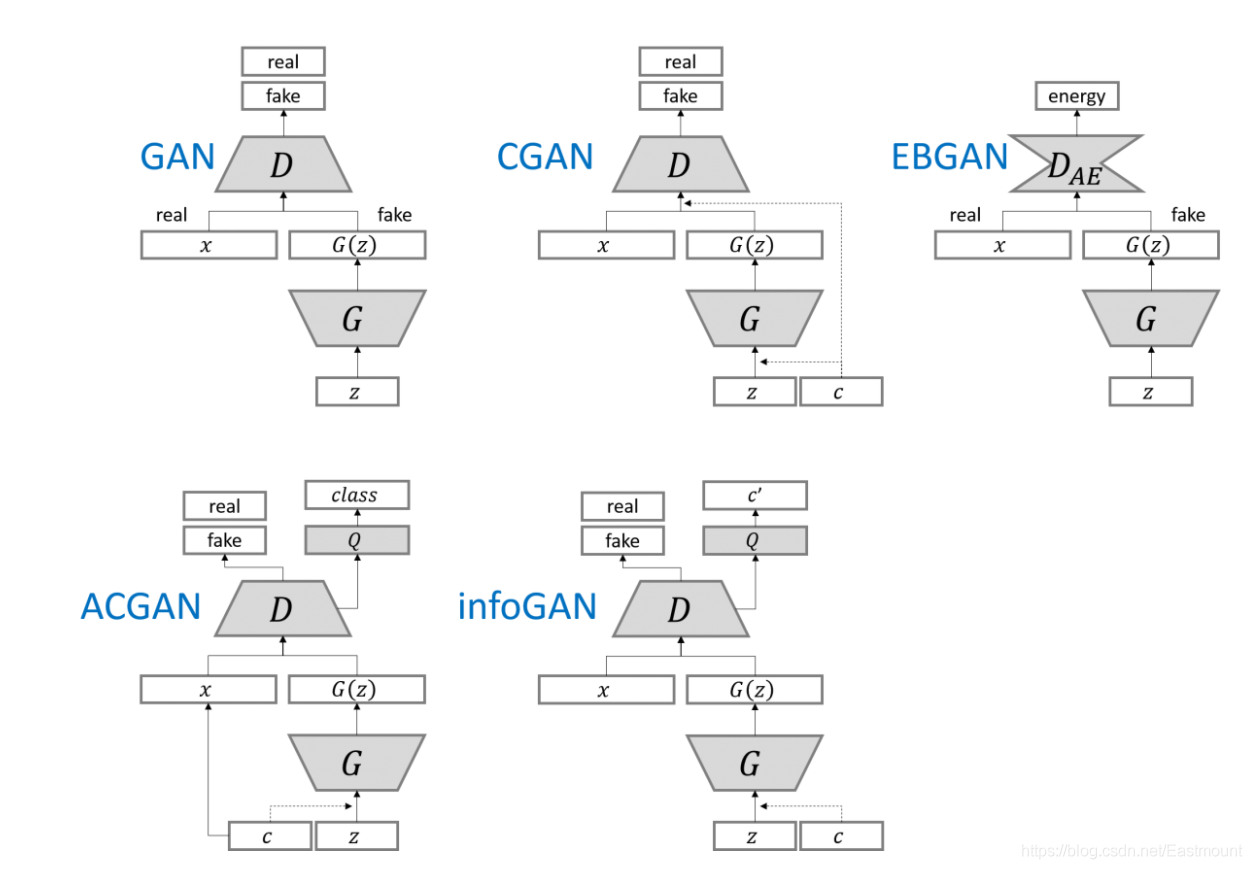
3.其他常見GAN網路
(1) CGAN
首先,GAN如何輸出指定類的影像呢?
CGAN出場,這里簡單介紹下GAN和CGAN的區別:GAN只能判斷生成的東西是真的或假的,如果想指定生成影像如1、2、3呢?GAN會先生成100張影像,然后從中去挑選出1、2、3,這確實不方便,
在2014年提出GAN時,CGAN也被提出來了,CGAN除了生成以外,還要把條件帶出去,即帶著我們要生成一個什么樣的圖條件去混淆,如下右圖:噪聲z向量+條件c向量去生成,
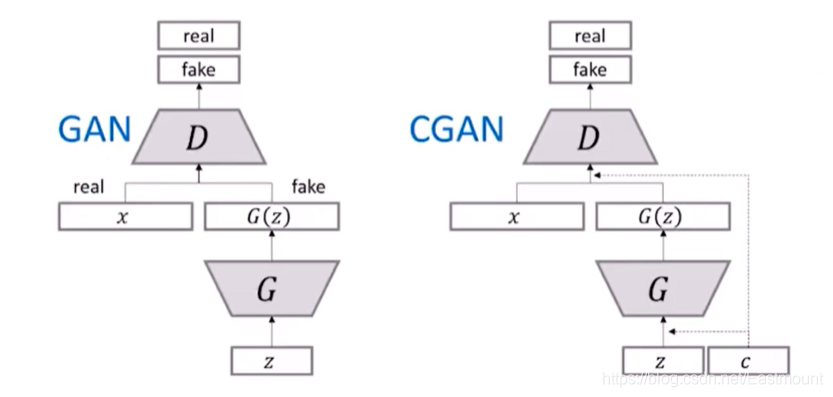
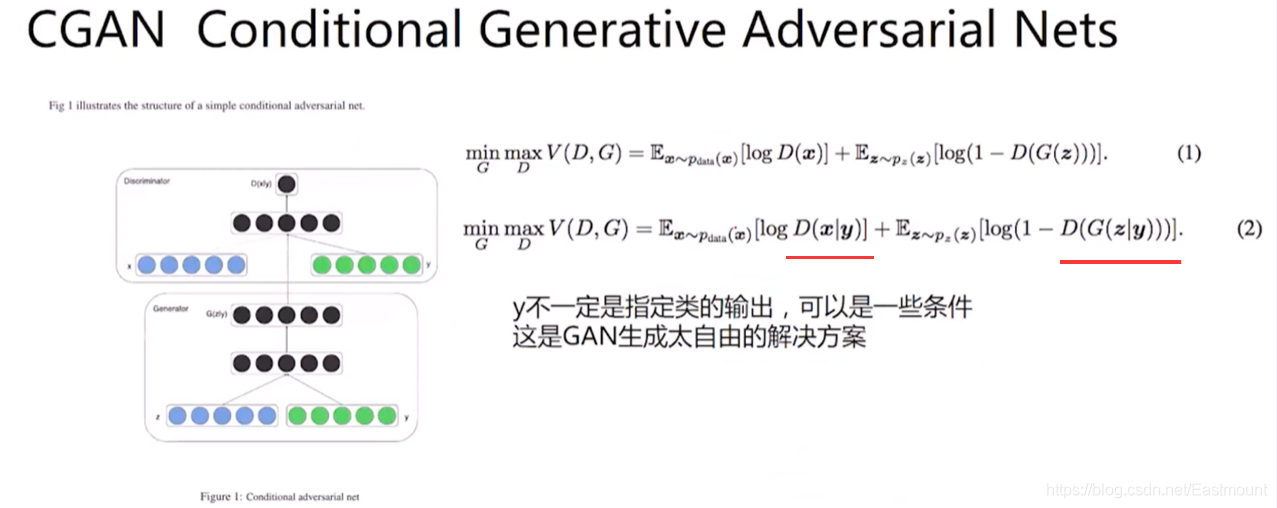
所以整套流程大體不變,接著我們看看公式,它在D(x|y)和G(z|y)中增加了y,其中,y不一定是指定類的輸出,可以是一些條件,
(2) DCGAN
DCGAN(Deep Convolutional Generative Adversarial Networks)
卷積神經網路和對抗神經網路結合起來的一篇經典論文,核心要素是:在不改變GAN原理的情況下提出一些有助于增強穩定性的tricks,注意,這一點很重要,因為GAN訓練時并沒有想象的穩定,生成器最后經常產生無意義的輸出或奔潰,但是DCGAN按照tricks能生成較好的影像,
- https://arxiv.org/pdf/1511.06434.pdf
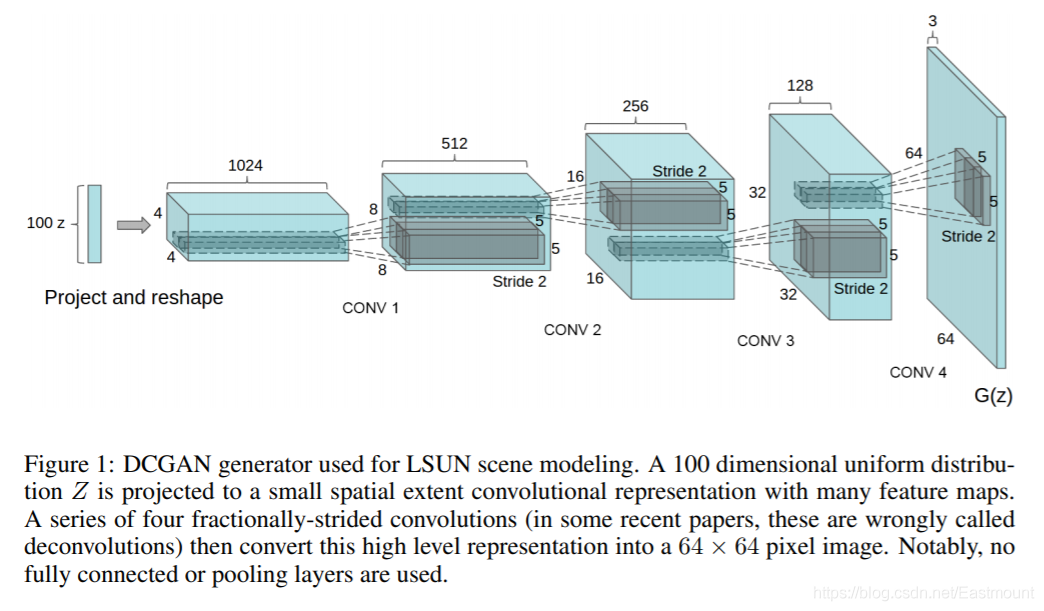
DCGAN論文使用的tricks包括:
- 所有pooling都用strided convolutions代替,pooling的下采樣是損失資訊的,strided convolutions可以讓模型自己學習損失的資訊
- 生成器G和判別器D都要用BN層(解決過擬合)
- 把全連接層去掉,用全卷積層代替
- 生成器除了輸出層,激活函式統一使用ReLU,輸出層用Tanh
- 判別器所有層的激活函式統一都是LeakyReLU

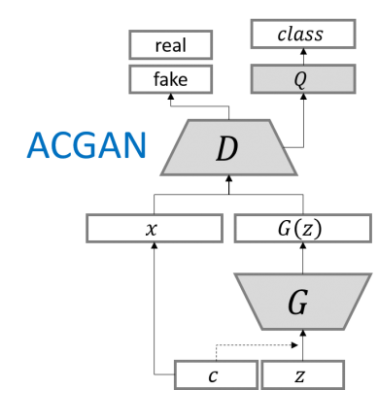
(3) ACGAN
ACGAN(既能生成影像又能進行分類)
Conditional Image Synthesis with Auxiliary Classifier GANs,該判別器不僅要判斷是真(real)或假(fake),還要判斷其屬于哪一類,
- https://arxiv.org/pdf/1610.09585.pdf
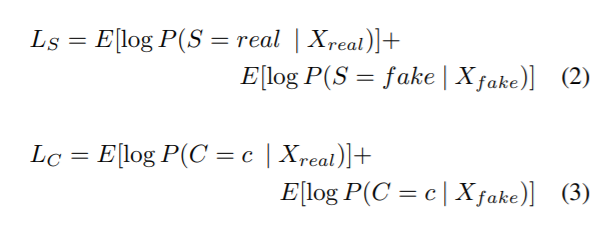
(4) infoGAN
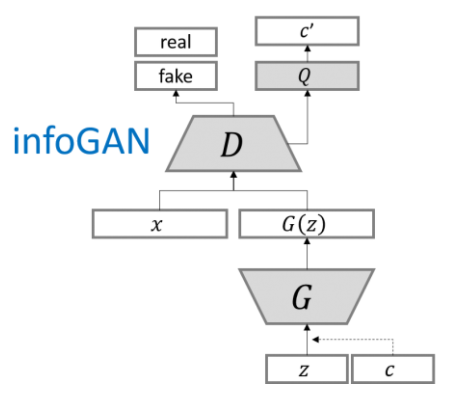
InfoGAN:Interpretable Representation Learning by Information Maximizing Generative Adversarial Networks,這個號稱是OpenAI在2016年的五大突破之一,
- D網路的輸入只有x,不加c
- Q網路和D網路共享同一個網路,只是到最后一層獨立輸出
- G(z)的輸出和條件c區別大
原文地址:https://arxiv.org/abs/1606.03657
其理論如下:
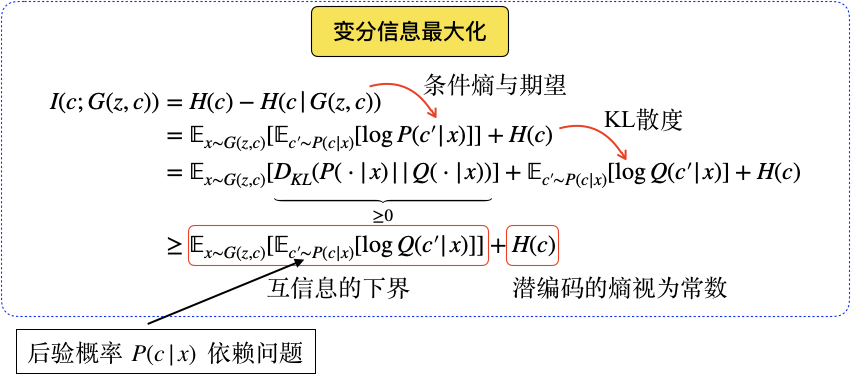
整個網路的訓練在原目標函式的基礎上,增加互資訊下界L(G,Q),因此InfoGAN的目標函式最終表示為:
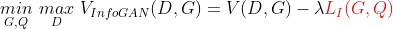
實驗結果如下圖所示:

(5) LAPGAN
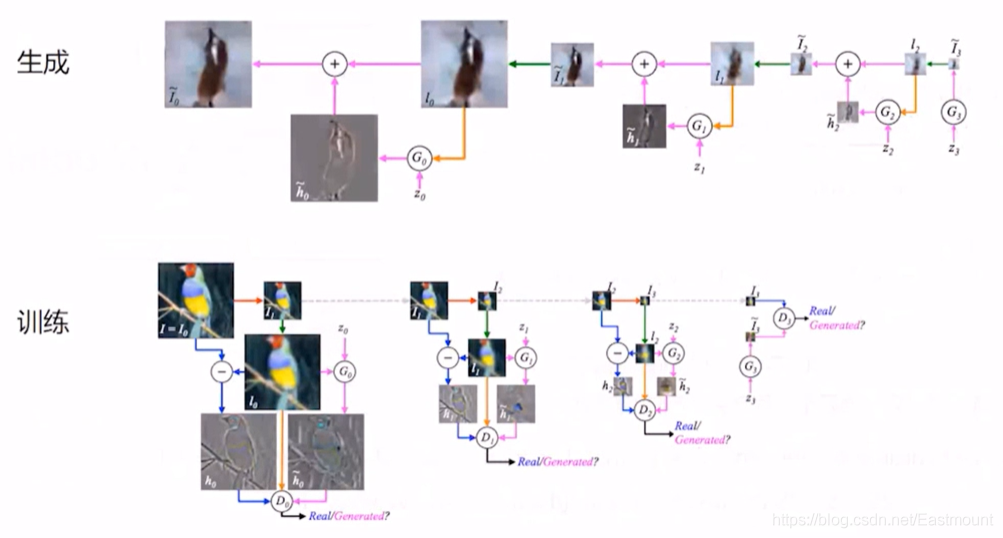
下面介紹一個比較有趣的網路拉普拉斯GAN,我們的目標是如何通過噪音生成一張圖片,噪聲本身生成圖片比較困難,不可控量太多,所以我們逐層生成(生成從右往左看),
- 首先用噪聲去生成一個小的圖片,解析度極低,我們對其拉伸,
- 拉伸之后,想辦法通過之前訓練好的GAN網路生成一個它的殘差,
- 殘差和拉伸圖相加就生成一張更大的圖片,以此類推,拉普拉斯生成一張大圖,
那么,如何訓練呢?對原來這個大圖的鳥進行壓縮,再生成一張圖去判別,依次逐層訓練即可,
(6) EBGAN
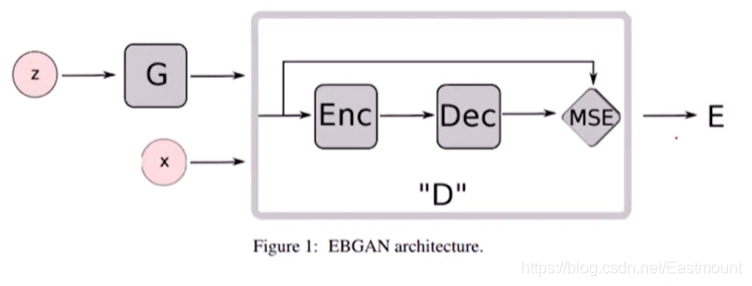
再來看一個EBGAN(Energy-based GAN),它拋棄了之前說的對和錯的概念,它增加了一個叫能量的東西,經過自動編碼器Enc(中間提取特征)和Dec解碼器(輸出),它希望生成一個跟真實圖片的能量盡可能小,跟假的圖片能量更大,
- 《Energy-based Generative Adversarial Network》Junbo Zhao, arXiv:1609.03126v2
其生成器和判別器的損失函式計算公式如下(分段函式):
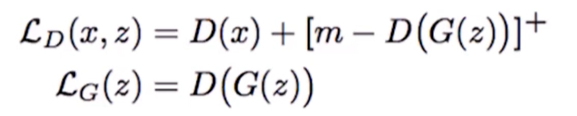
下圖展示了GAN、EBGAN、EBGAN-PT模型生成的影像,

4.GAN改進策略
你以為解決了所有問題了嗎?too young.
如下圖所示誤差,我們無法判斷GAN訓練的好壞,
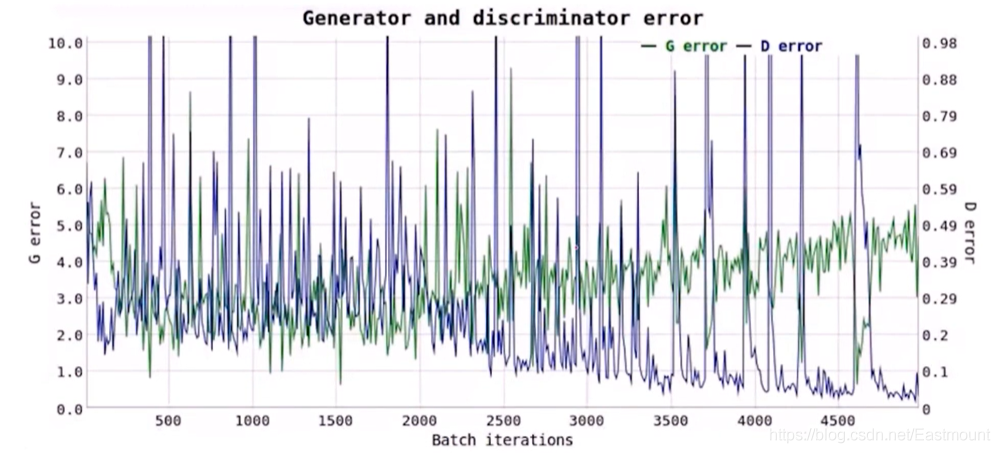
GAN需要重視:穩定(訓練不奔)、多樣性(各種樣本)、清晰度(質量好),現在很多作業也是解決這三個問題,
- G、D迭代的方式能達到全域最優解嗎?大部分情況是區域最優解,
- 不一定收斂,學習率不能高,G、D要共同成長,不能其中一個成長的過快
– 判別器訓練得太好,生成器梯度消失,生成器loss降不下去
– 判別器訓練得不好,生成器梯度不準,四處亂跑 - 奔潰的問題,通俗說G找到D的漏洞,每次都生成一樣的騙D
- 無需預先建模,模型過于自由,不可控
為什么GAN存在這些問題,這是因為GAN原論文將GAN目標轉換成了KL散度的問題,KL散度就是存在這些坑,

最終導致偏向于生成“穩妥”的樣本,如下圖所示,目標target是均勻分布的,但最終生成偏穩妥的樣本,
- “生成器沒能生成真實的樣本” 懲罰小
- “生成器生成不真實的樣本” 懲罰大
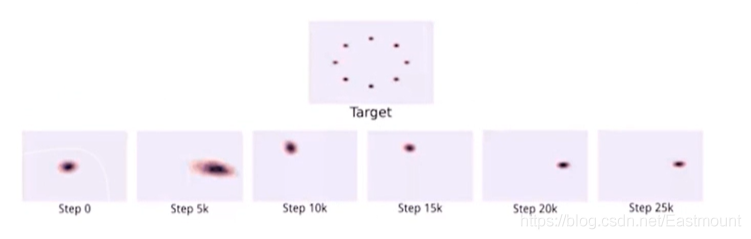
那么,有沒有解決方法呢?
WGAN(Wasserstein GAN)在2017年被提出,也算是GAN中里程碑式的論文,它從原理上解決了GAN的問題,具體思路為:
- 判別器最后一層去掉sigmoid
- 生成器和判別器的loss不取log
- 每次更新判別器的引數之后把它們的絕對值截斷到不超過一個固定的常數c
- 不要用基于動量的優化演算法(包括Momentum和Adam),推薦使用RMSProp、SGD
- 用Wasserstein距離代替KL散度,訓練網路穩定性大大增強,不用拘泥DCGAN的那些策略(tricks)
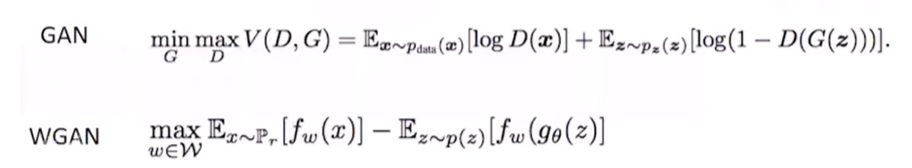
后續接著改進,提出了WGAN-GP(WGAN with gradient penalty),不截斷,只對梯度增加懲罰項生成質量更高的影像,它一度被稱為“state of the art”,
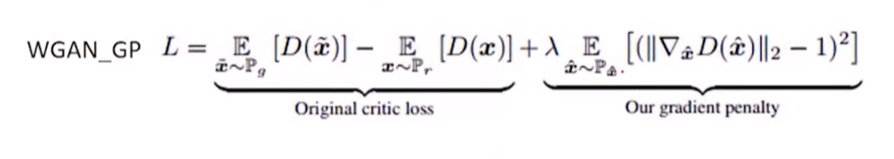
接下來,做GAN的就會出來反駁“誰說GAN就不如WGAN,我們加上Gradient Penalty,大家效果都差不多”,
- https://arxiv.org/pdf/1705.07215.pdf

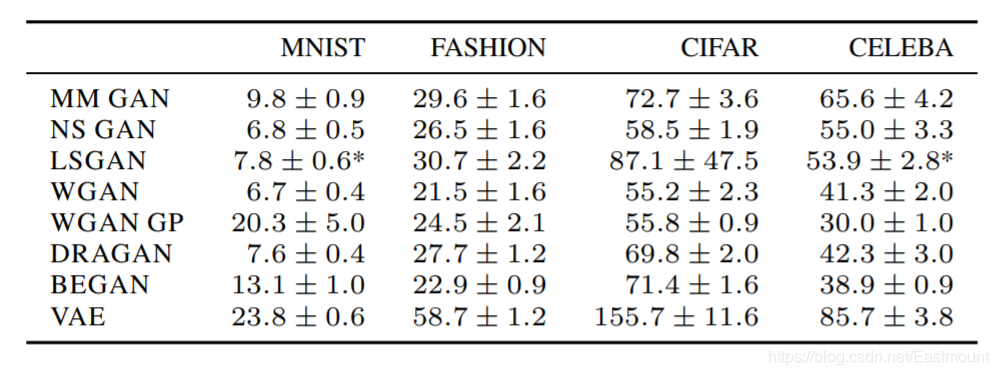
效果如下圖所示:

《Google Brain: Are GANs Created Equal? A Large-Scale Study》 這篇論文詳細對比了各GAN模型點心LOSS優化變種,
- https://arxiv.org/pdf/1711.10337.pdf
- https://arxiv.org/pdf/1706.08500.pdf

這篇文章比較的結論為:特定的資料集說特定的事情,沒有哪一種碾壓其他,好的演算法還得看成本,時間短的效果某家強,但訓練時間長了,反倒會變差,根據評價標準的不同,場景的不同,效果差的演算法也可以逆襲,工業界更看重穩定性,比如WGAN,
參考知乎蘇劍林老師的回答
首先,從理論完備的角度來看,原始的GAN(SGAN)就是一個完整的GAN框架,只不過它可能存在梯度消失的風險,而論文比較的是 “大家都能穩定訓練到收斂的情況下,誰的效果更好” 的問題,這答案是顯然易見的:不管是SGAN還是WGAN,大家都是理論完備的,只是從不同角度看待概率分布的問題而已,所以效果差不多是正常的,
甚至可以說,SGAN的理論更完備一些(因為WGAN需要L約束,而目前L約束的各種加法都有各自的缺點),所以通常來說SGAN的效果還比WGAN效果好一些,那么WGAN它們的貢獻是什么呢?WGAN的特點就是基本上都能 “穩定訓練到收斂”,而SGAN相對而言崩潰的概率更大,所以,如果在“大家都能穩定訓練到收斂”的前提下比較效果,那對于WGAN這些模型本來就很不公平的,因為它們都是致力于怎么才能“穩定訓練到收斂”,而這篇論文直接將它作為大前提,直接抹殺了WGAN所作的貢獻了,

四.總結
寫到這里,這篇文章就介紹結束了,希望對您有所幫助,首先非常感謝小象學院美圖老師的介紹,文章雖然很冗余,但還是能學到知識,尤其是想學GAN的同學,這算一個非常不錯的普及,當然,后續隨著作者深入,會分享更簡潔的介紹和案例,繼續加油~
個人感覺GAN有一部分很大的應用是在做強化學習,同時在推薦領域、對抗樣本、安全領域均有應用,希望隨著作者深入能分享更多的實戰性GAN論文,比如如果圖片被修改,GAN能不能第一次時間反饋出來或優化判決器,最后給出各類GAN模型對比圖,
- 一.GAN簡介
1.GAN背景知識、2.GAN原理決議、3.GAN經典案例 - 二.GAN預備知識
1.什么是神經網路、2.全連接層、3.激活函式、4.反向傳播
5.優化器選擇、6.卷積層、7.池化層、8.影像問題基本思路 - 三.GAN網路實戰分析
1.GAN模型決議
2.生成手寫數字demo分析
3.CGAN、DCGAN、ACGAN、infoGAN、LAPGAN、EBGAN
4.GAN改進策略
希望您喜歡這篇文章,從看視頻到撰寫代碼,我真的寫了一周時間,再次感謝參考文獻的老師們,真心希望這篇文章對您有所幫助,加油~
- https://github.com/eastmountyxz/AI-for-Keras
- https://github.com/eastmountyxz/AI-for-TensorFlow
2020年8月18新開的“娜璋AI安全之家”,主要圍繞Python大資料分析、網路空間安全、人工智能、Web滲透及攻防技術進行講解,同時分享CCF、SCI、南核北核論文的演算法實作,娜璋之家會更加系統,并重構作者的所有文章,從零講解Python和安全,寫了近十年文章,真心想把自己所學所感所做分享出來,還請各位多多指教,真誠邀請您的關注!謝謝,

(By:Eastmount 2021-03-30 周二夜于武漢 http://blog.csdn.net/eastmount/ )
參考文獻:
- https://www.bilibili.com/video/BV1ht411c79k
- https://arxiv.org/abs/1406.2661
- https://www.cntofu.com/book/85/dl/gan/gan.md
- https://github.com/hindupuravinash/the-gan-zoo
- https://arxiv.org/pdf/1701.00160.pdf
- https://link.springer.com/chapter/10.1007/978-3-319-10593-2_13
- https://zhuanlan.zhihu.com/p/76520991
- http://cn.arxiv.org/pdf/1711.09020.pdf
- https://www.sohu.com/a/121189842_465975
- https://www.jianshu.com/p/88bb976ccbd9
- https://zhuanlan.zhihu.com/p/23270674
- ttps://blog.csdn.net/weixin_40170902/article/details/80092628
- https://www.jiqizhixin.com/articles/2016-11-21-4
- https://github.com/jacobgil/keras-dcgan/blob/master/dcgan.py
- https://arxiv.org/abs/1511.06434
- https://arxiv.org/pdf/1511.06434.pdf
- https://blog.csdn.net/weixin_41697507/article/details/87900133
- https://zhuanlan.zhihu.com/p/91592775
- https://liuxiaofei.com.cn/blog/acgan與cgan的區別/
- https://arxiv.org/abs/1606.03657
- https://blog.csdn.net/sdnuwjw/article/details/83614977
- 《Energy-based Generative Adversarial Network》Junbo Zhao, arXiv:1609.03126v2
- https://www.jiqizhixin.com/articles/2017-03-27-4
- https://zhuanlan.zhihu.com/p/25071913
- https://arxiv.org/pdf/1705.07215.pdf
- https://arxiv.org/pdf/1706.08500.pdf
- https://arxiv.org/pdf/1711.10337.pdf
- https://www.zhihu.com/question/263383926
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/271233.html
標籤:AI