文章目錄
- JVM體系結構
- 類加載器和雙親委派機制
- 沙箱安全機制
- 本地方法堆疊
- 程式計數器
- 方法區
- 堆疊
- 堆
- 創建物件程序
- 物件訪問方式
- 垃圾判斷
- GC演算法
- GC收集器

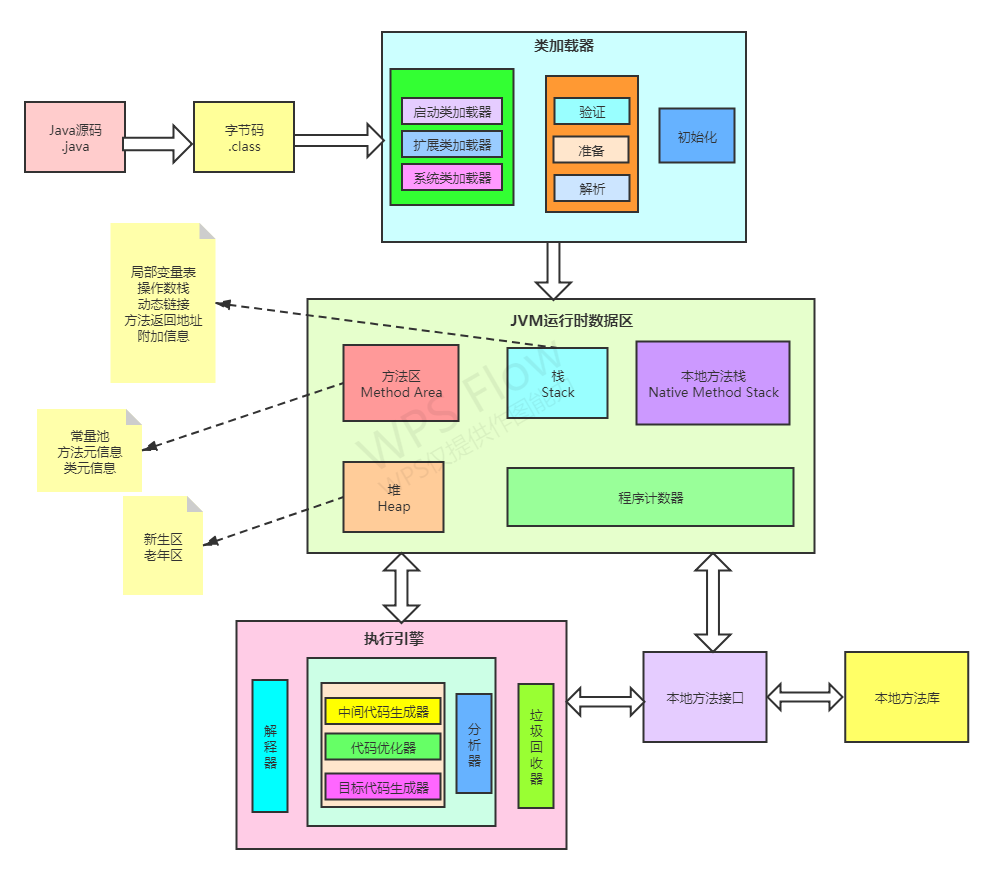
JVM體系結構
JVM是Java Virtual Machine(Java虛擬機)的縮寫,JVM是一種用于計算設備的規范,它是一個虛構出來的計算機,是通過在實際的計算機上仿真模擬各種計算機功能來實作的,這樣一來無論是什么作業系統或平臺,通過對應版本的JVM都可預編譯成位元組碼檔案(.class),使得Java語言在不同平臺上運行時不需要重新編譯,也不需要修改,
JVM實際上有三種:
- Sun:HotSpot
- BEA:JRockit
- IBM:J9VM
用的最多(99.9%),最主要的就是HotSpot,其余兩種了解即可,本文是基于HotSpot的JVM介紹,
類加載器和雙親委派機制
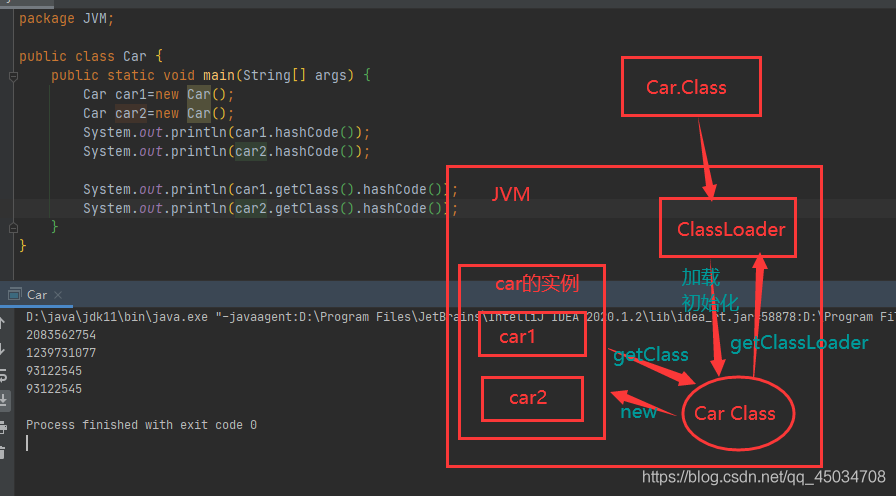
從源代碼.java檔案編譯成.class位元組碼檔案后,是通過類加載器ClassLoader檔案位元組碼內容加載到記憶體中,并將這些靜態資料轉換成方法區的運行時資料結構,然后在堆中生成一個代表這個類的java.lang.Class物件,作為方法區中類資料的訪問入口,
如下所示,都是同一個Car.Class為模板創建出來的兩個不同實體化物件,
通過方法getClass()可以反射物件的Class類,此部分可參考一文掌握Java注解和反射-你總該用過@Override吧?
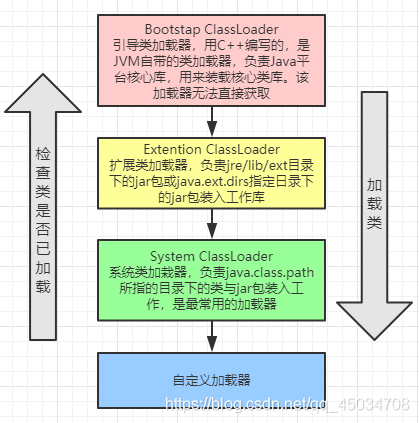
ClassLoader內部由下而上還分為自定義加載器、系統加載器、擴展加載器和引導加載器,加載的順序保證了安全性,也就是所謂的雙親委派機制,
雙親委派機制:當某個類加載器需要加載某個.class檔案時,它首先把這個任務委托給他的上級類加載器,遞回這個操作,如果上級的類加載器沒有加載,自己才會去加載這個類,
- 從最內層JVM自帶類加載器開始加載,外層惡意同名類得不到加載從而無法使用;
- 由于嚴格通過包來區分了訪問域,外層惡意的類通過內置代碼也無法獲得權限訪問到內層類,破壞代碼就自然無法生效,
如下圖:向上級委托檢查是否加載,上級自頂向下優先去加載類,
public class Car {
public static void main(String[] args) {
Car car1=new Car();
Class c1 = car1. getClass();
ClassLoader classLoader = c1. getClassLoader();
System.out.println(classLoader);//AppClassLoader
System.out.println(classLoader.getParent()); //ExtClasslLader
System.out.println(classLoader.getParent().getParent()); //null
//APP=>Ext=>Boot
}
}
/*運行結果如下
jdk.internal.loader.ClassLoaders$AppClassLoader@2437c6dc
jdk.internal.loader.ClassLoaders$PlatformClassLoader@7c30a502
null
*/
比如說你自己定義了一個java.lang.String類,但是向上委派后加載的是根加載器的系統原來定義好的包,你自己定義的重名String不會加載,
沙箱安全機制
這趴了解即可
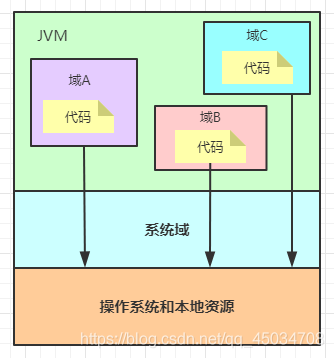
Java安全模型的核心就是Java沙箱(sandbox) ,什么是沙箱?沙箱是一個限制程式運行的環境,沙箱機制就是將Java代碼限定在虛擬機JVM特定的運行范圍中,并且嚴格限制代碼對本地系統資源訪問,通過這樣的措施來保證對代碼的有效隔離,防止對本地系統造成破壞,沙箱主要限制系統資源訪問,包括 CPU、記憶體、檔案系統、網路,
當前最新的1.6以后安全機制實作,引入了域(Domain)的概念,虛擬機會把所有代碼加載到不同的系統域和應用域,系統域部分專門負責與關鍵資源進行互動,而各個應用域部分則通過系統域的部分代理來對各種需要的資源進行訪問,
虛擬機中不同的受保護域(Protected Domain)對應不一樣的權限(Permission),存在于不同域中的類檔案就具有了當前域的全部權限,
本地方法堆疊
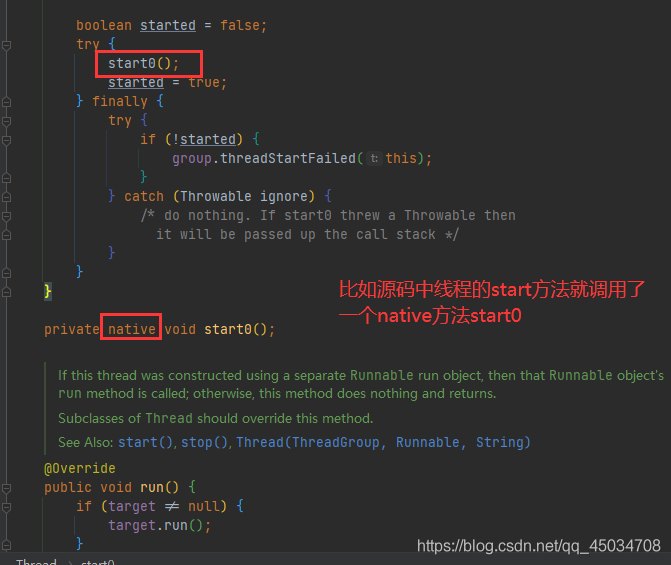
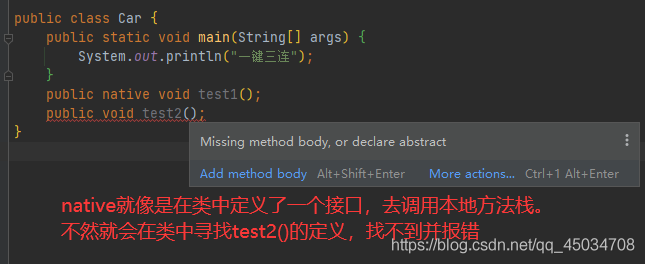
native關鍵字說明java的作用范圍達不到了,會去呼叫底層c語言的庫,進入本地方法堆疊,去呼叫本地方法介面JNI,換言之,JNI作用是擴展了Java的使用,融合不同的編程語言為Java所用,
從Java歷史來看,Java誕生于C/C++盛行之下,不得不提供C/C++的程式介面以立足,所以它在記憶體區域中專門開辟了一塊標記區域:Native Method Stack本地方法堆疊,登記native方法在最終執行的時,加載本地方法庫中的方法通過JNI,在企業級應用中較為少見,
程式計數器
程式計數器(Program Counter Register),也叫PC暫存器,每個執行緒都有一個程式計數器,是執行緒私有的,就是一個指標, 指向方法區中的方法位元組碼(用來存盤指向像一條指令的地址, 也即將要執行的指令代碼), 在執行引擎讀取下一條指令, 是一個非常小的記憶體空間,可以看作是當前執行緒所執行的位元組碼的信號指示器,
主要兩個作用:
- 位元組碼解釋器通過改變程式計數器來依次讀取指令,從而實作代碼的流程控制,如順序執行、選擇、回圈、例外處理等,
- 在多執行緒的情況下,程式計數器用于記錄當前執行緒執行的位置,從而當執行緒被切換回來的時候能知道該執行緒上次運行到哪兒了,
為了執行緒切換后能恢復到正確的執行位置,每條執行緒都需要有一個獨立的程式計數器,各執行緒間計數器互不影響,獨立存盤,稱之為執行緒私有的記憶體,
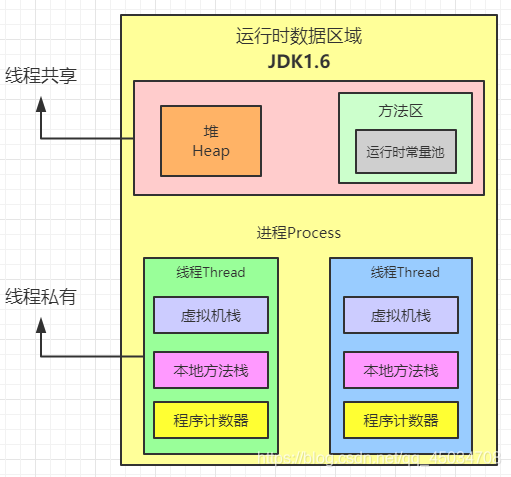
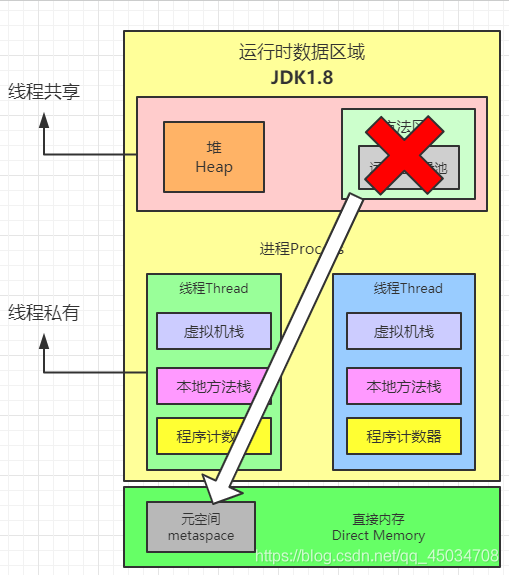
方法區
方法區(Method Area)和堆一樣,是各個執行緒共享的記憶體區域,用于存盤已被虛擬機加載的類資訊、常量、靜態變數、即時編譯后的代碼等資料,雖然Java虛擬機規范把方法區描述為堆的一個邏輯部分,但是它卻有一個別名叫做非堆,目的是與堆分離開來,
方法區也稱為永久代(PermGen),方法區和永久代的關系就像Java中介面和類的關系,類實作了介面,而永久代就是HotSpot虛擬機對虛擬機規范中方法區的一種實作方式,JDK1.8后,方法區(HotSpot的永久代)被徹底移除了,取而代之的是元空間(MetaSpace),元空間使用的是直接記憶體,而垃圾回收在這個區域較少出現,但并不等于資料進入方法區后就永久存在了,后續會介紹,
為什么替換永久代為元空間?
其中一個原因是因為整個永久代有一個JVM本身設定固定大小上線,無法調整;而元空間使用的是直接記憶體,受本機可用記憶體限制,并且永遠不會OOM(java.lang.OutOfMemorryError),可以使用-XX:MaxMetaspaceSize修改最大元空間大小,默認值是unlimited,這意味著它只受系統記憶體的限制,-XX:MetaspaceSize設定元空間初始大小,若未設定則會根據運行時應用程式需求動態重新調整大小,
那什么是直接記憶體?
直接記憶體并不是虛擬機運行時資料區的一部分,也不是虛擬機規范中定義的記憶體區域,但是這部分記憶體也被頻繁地使用,而且會導致OOM例外,
(
插播反爬資訊)博主CSDN地址:https://wzlodq.blog.csdn.net/
堆疊
堆疊(Stack)同資料結構中的堆疊,也就是所謂的先進后出,先入堆疊的元素被壓在堆疊底,后入堆疊的元素則壓在堆疊頂,出堆疊順序是先彈出堆疊頂元素,再依次向下彈出底部元素,
比如主函式呼叫一個test()方法,是先入堆疊main,然后再入堆疊test,只有當test出堆疊后,main才會出堆疊,main出堆疊即程式結束,差不多這個亞子:
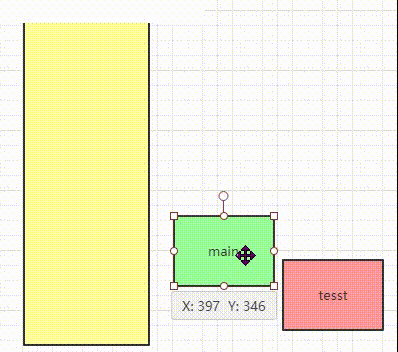
所以垃圾回收什么的不會在堆疊這塊,要是有垃圾堵住堆疊的話,出入堆疊完成不了,程式就崩了,
堆疊的兩種例外:
StackOverFlowError
若堆疊的記憶體大小不允許超過動態擴展,當堆疊請求深度超過了堆疊的最大深度時拋出該例外,OutOfMemoryError
若堆疊的記憶體大小允許超過動態擴展,而且隨著執行緒的創建而創建,隨著執行緒的死亡而死亡,
堆
堆(Heap)是所有執行緒共享的一塊記憶體區域,在虛擬機啟動時創建,是JVM所管理的記憶體中最大的一塊,此區域的唯一目的就是存放物件實體,幾乎所有的物件實體以及陣列都在這里分配記憶體,
特別注意JDK1.7后,JVM已經將運行時常量池從方法區移了出來,在堆中開辟了一塊區域存放運行時常量池,
堆是垃圾收集器管理的主要區域,因此堆也稱為GC堆(Garbage Collected Heap),從垃圾回收的角度,由于現在收集器都采用分代垃圾收集演算法(具體演算法后文介紹),所以堆還可以細分為新生代和老年代,再細分下去可以是:Eden空間、From Survivor、To Survivor等,進一步劃分的目的是為了更好的回收記憶體和分配記憶體,
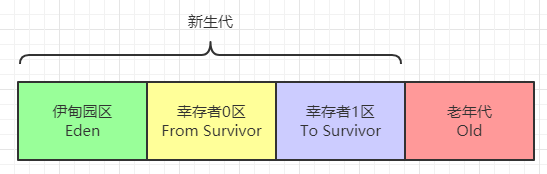
大部分情況下,物件首先會在Edun區域分配,在一次新生代垃圾回收后,如果物件還存活,則會進入S0或S1,并且物件的年齡還會加1,當它的年齡增加到一定程度(默認15歲),就會晉升到老年代,物件晉升到老年代的閾值可以通過XX:MaxTenuringThreshold來設定,這是堆記憶體調優的一種方式!提高老年閾值門檻來回收更多資料,
創建物件程序
如下五步:
- 類加載檢查
當JVM遇到一條new指令后,會先去檢查這個指令的引數是否能在常量池中定位到這個類的符號參考,并且檢查這個符號參考代表的類是否已被加載、決議和初始化過,如果沒有,那就先走一遍類加載程序(前文介紹的), - 分配記憶體
接下來JVM將為新生物件分配記憶體,物件所需記憶體大小在類加載完成后便可確定,為物件分配空間的任務等同于把一塊確定大小的記憶體從堆中劃分出來,分配方式有指標碰撞和空閑串列兩種,選擇那種分配方式是由堆是否規整決定的,而堆是否規整又是GC決定的,

- 初始化零值
記憶體分配完成后,虛擬機需要將分配到的記憶體空間都初始化為零值(不包括物件頭),保證物件的實體欄位在Java代碼中可以不賦初始值就直接使用,程式能訪問到這些欄位的資料型別所對應的零值, - 設定物件頭
初始化零值完成后,虛擬機要對物件進行必要的設定,例如這個物件是哪個類的實體、如何才能找到類的元資料資訊、物件的哈希碼等,這些資訊存放在物件頭中, - 執行init方法
從虛擬機視角看,做完上面作業后,一個新物件就產生了,但從Java程式視角來看,物件創建才剛開始,<init>方法還沒有執行,所以欄位都還為零,所以一般來說new指令之后會緊接著<init>方法,把物件按程式員意愿初始化,
物件訪問方式
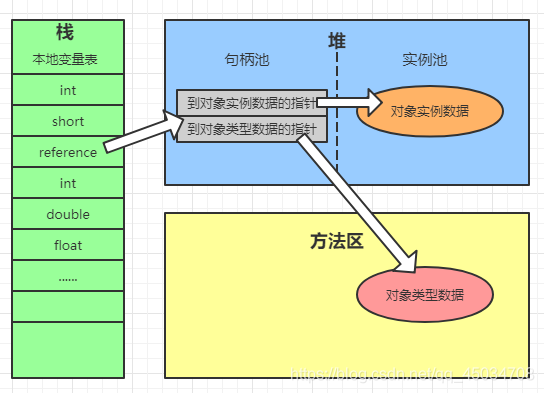
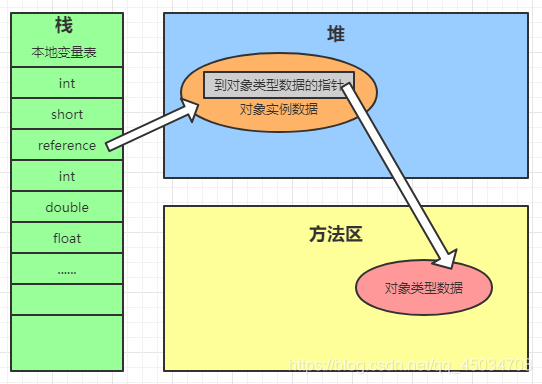
建立物件可不就是為了使用物件,Java程式通過堆疊上的reference資料來操作堆上的具體物件,物件的訪問方式由虛擬機實作而定,主要分使用句柄和直接指標兩種,
- 使用句柄
堆中劃分一塊記憶體出來作為句柄池,reference中存盤的就是物件的句柄地址,而句柄中包含了物件實體資料與型別資料各自的具體地址資訊:
- 直接指標
若直接使用指標訪問,堆的布局中就要考慮如何放在訪問型別資料的相關資訊,而reference中存盤的直接就是物件的地址,
垃圾判斷
物件:
堆中幾乎放著所有的物件實體,對堆垃圾回收前的第一步就是要判斷哪些物件已死亡,即不能在被任何途徑使用的物件,
- 參考計數法
給物件添加一個參考計數器,每當有一個地方參考它,計數器就加1,當參考失效時,計數器就減1,任何時候計數器為0的物件就是不可能再被使用的,
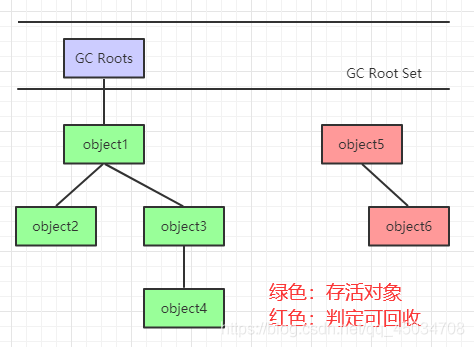
但是給每個物件開計數,也是一種消耗, - 可達性分析演算法
基本思想時通過一系列稱為GC Roots的物件作為起點,從這些節點開始向下搜索,節點所走過的路徑稱為參考鏈,當一個物件到GC Roots沒有任何參考鏈相連的話,則證明此物件時不可用的,
常量:
運行時常量池主要回收的是廢棄的常量,那么如何判斷一個常量是廢棄常量?
設在常量池中存在字串“abc”,如果當前沒有任何String物件參考該字串常量的話,就說明常量“abc”是廢棄變數,
類:
判定廢棄常量比較簡單,但判定類是無用類就較苛刻了,需要同時滿足以下3點:
- 該類所有實體都已經被回收,也就是堆中不存在該類的任何實體,
- 加載該類的
ClassLoader已經被回收, - 該類對應的
java.lang.Class物件沒有在任何地方被參考,無法在任何地方通過反射訪問該類的方法,
GC演算法
GC演算法即垃圾回收演算法,上面確定了垃圾的判斷,現在要對垃圾進行回收,
主要分以下三種演算法:
-
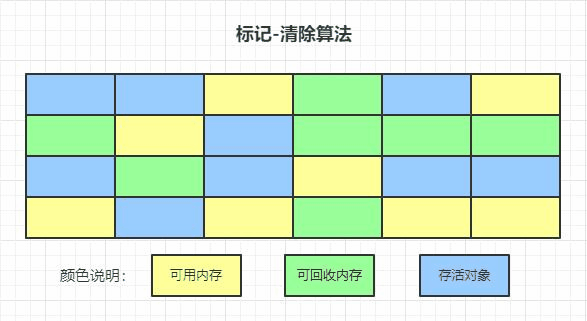
標記-清除演算法
演算法分為“標記”和“清除”兩階段,首先標記出所有需要回收的物件,在標記完成后統一回收所有被標記的物件,后續演算法都是對它的改進,
但這種演算法存在兩個問題:效率低、產生大量不連續的記憶體碎片,
-
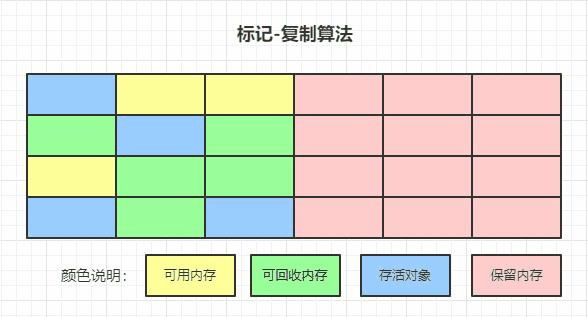
標記-復制演算法
為了解決效率問題,復制演算法將記憶體分為大小相同的兩塊,每次使用其中的一次,當這一塊的記憶體使用完后,就將還存活的物件復制到另一塊去,然后再把使用的空間一次清理掉,這樣就使每次記憶體回收都是對記憶體區間的一半進行回收,也就是前面堆中介紹的幸存者0和幸存者1區(至于誰是from誰是to看上一次復制方向)
但每次會有一半空間不可使用,
-
標記-壓縮演算法
也稱為標記-整理演算法,讓所有的存活物件向一端移動,然后清理掉端邊界以外的記憶體,
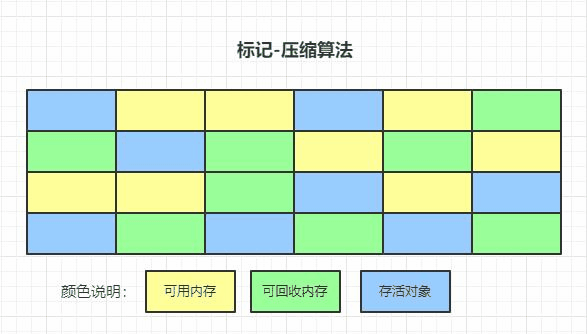
當前虛擬機都采用分代收集演算法,就是根據新生代和老年代的特點選擇合適的垃圾收集演算法,
- 新生代存活率低,采用復制演算法,
- 老年代存活率高采用清除或壓縮演算法,
GC收集器
介紹五種GC收集器:
-
Serial收集器
Serial(串行)收集器是最基本的垃圾收集器,顧名思義就是一個單執行緒收集器,不僅僅是只會使用一個執行緒去收集垃圾,更重要的是它在進行垃圾收集作業的時候必須暫停其他所有執行緒,直到它收集結束,簡單高效,但是又停頓時間,用戶體驗感差,采用新生復制老年壓縮, -
ParNew收集器
ParNew收集器其實就是Seria收集器的多執行緒版本,除了使用多執行緒進行垃圾收集外,其余行為不變,減少停頓時間,提高用戶體驗 ,采用新生復制老年壓縮, -
Parallel Scavenge收集器
類似ParNew收集器,只不過關注點是吞吐量(高效利用CPU),而ParNew關注是用戶體驗(停頓時間),該收集器提供了很多引數供用戶找到最合適的停頓時間或最大吞吐量,采用新生復制老年壓縮, -
CMS收集器
CMS(Concurrent Mark Sweep)收集器是HotSpot虛擬機第一款真正意義上的并發收集器,它第一次實作了垃圾收集執行緒和用戶執行緒基本上同時作業,從名字Mark Sweep看出采用的是清除演算法,分四步實作:
①初始標記:暫停其他執行緒,標記與root相連物件,速度很快,
②并發標記:同時開啟GC執行緒和用戶執行緒,用閉包記錄可達物件,
③重新標記:重新標記因用戶行程產生變動的物件,
④并發清除:開啟用戶執行緒,同時GC執行緒清掃標記物件, -
G1收集器
G1(Garbage-Firse)是面向服務器的垃圾收集器,主要針對多處理器即大記憶體的機器,以極高概率滿足GC停頓時間要求的同時,還具備吞吐量性能特征,分為初始標記、并發標記、最終標記和篩選回收,
G1收集器在后天維護了一個優先佇列,每次根據允許的收集時間,優先選擇回收價值最大的Region,保證在有限時間內盡可能高的收集效率,
原創不易,請勿轉載(
本不富裕的訪問量雪上加霜)
博主首頁:https://wzlodq.blog.csdn.net/
微信公眾號:唔仄lo咚鏘
如果文章對你有幫助,記得一鍵三連?
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/271260.html
標籤:其他