大資料主要所學技術簡介:
目錄
大資料主要所學技術簡介:
一: 大資料技術生態體系
二: 各個技術堆疊簡介
一: 大資料技術生態體系
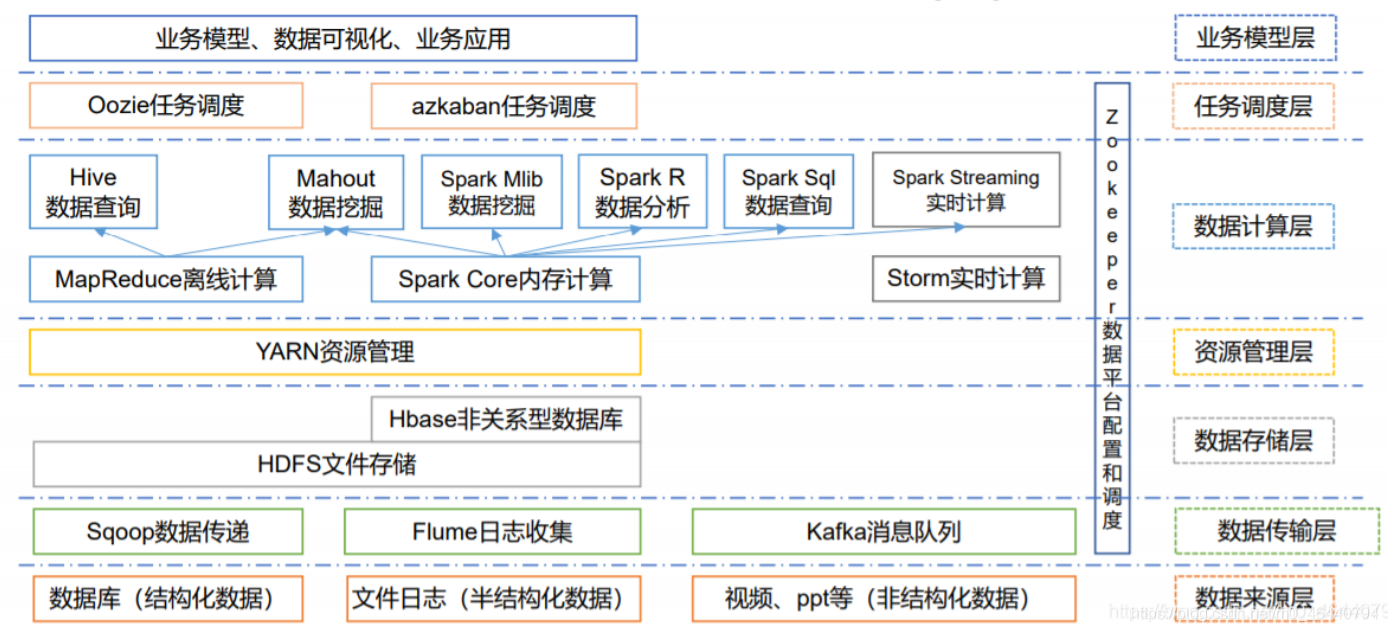
二: 各個技術堆疊簡介
Hadoop
hadoop是一個用java實作的一個開源框架,是一種用于存盤和分析大資料的軟體平臺,專為離線資料而設計的,不適用于提供實時計算,對海量資料進行分布式計算,Hadoop=HDFS(檔案系統,資料存盤相關技術)+ Mapreduce(資料處理)+ Yarn (運算資源調度系統)
zookeeper
它是針對大型分布式系統的可靠協調系統,提供功能:【本質是替客戶端保管資料,為客戶提供資料的監聽服務】
1. 統一命名服務: 在分布式環境下,經常需要對應用/服務進行統一命名,便于識別,例如:一個域名下可能有多個服務器,服務器不同,但域名一樣,
2. 統一配置管理: 把集群統一組態檔交給zookeeper
3. 統一集群管理: 分布式環境中,實時掌握集群每個節點狀態,zookeeper可以實作監控節點狀態的變化,
4. 服務器動態上下線: 客戶端能實時洞察到服務器上下線變化,
5. 軟負載均衡: 在zookeeper中記錄服務器訪問數,讓訪問數最小的服務器去處理最新的客戶端請求
Hive
hive是由facebook開源用于解決海量結構化日志的資料統計,是一個基于hadoop的資料庫工具,可以將結構化資料映射成一張資料表,并提供類SQL的查詢功能,本質是將SQL陳述句轉化為MapReduce程式,用hive的目的就是避免去寫MapReduce,減少開發人員學習成本,
Flume
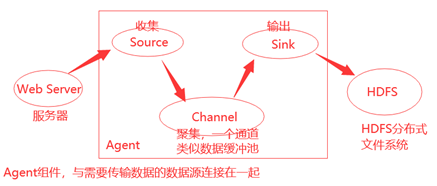
Flume是hadoop生態圈中的一個組件,主要應用于實時資料的流處理,是一個高可用,高可靠,分布式的海量日志采集,聚合和傳輸的系統,支持多路徑流量,多管道接入流量,多管道接出流量,
含有三個組件:
- source 【收集】
- channel 【聚集,一個通道,類似資料緩沖池】
- sink 【輸出】
基礎架構:
Kafka
分布式的基于發布/訂閱模式的訊息佇列,主要用于大資料實時處理領域,主要功能可概括為三句話:
生產者發生訊息給kafka服務器
消費者從kafka服務器讀取訊息
kafka服務器依托zookeeper集群進行服務的協調管理
Hbase
Hbase是構建在HDFS之上的分布式,面向列的存盤系統,在需要讀寫時,隨機訪問超大規模資料庫集時,可使用Hbase,Hbase利用HDFS作為其檔案存盤系統,利用MapReduce來處理hbase中的海量資料
Sqoop
sqoop是一個關系型資料庫于hadoop間的資料同步的工具,
sqoop import : 將資料從關系型資料庫匯入hadoop中
sqoop Export: 將資料從hadoop中匯入到關系型資料庫中
Spark
spark是基于記憶體的開源分布式記憶體計算框架,是快速通用的大規模資料處理引擎,基于記憶體運算,具有優秀的作業調度策略,
spqrk優勢:
- 速度快【基于記憶體資料處理】
- 易用性【支持java,scala,python等語言】
- 通用性【一堆疊式解決方案】
Storm
Storm是Twitter開源的分布式實時大資料處理框架,被業界稱為實時版Hadoop,隨著越來越多的場景對Hadoop的MapReduce高延遲無法容忍,比如網站統計、推薦系統、預警系統,大資料實時處理解決方案(流計算)的應用日趨廣泛,目前已是分布式技術領域最新爆發點,而Storm更是流計算技術中的佼佼者和主流,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/271278.html
標籤:其他
上一篇:極客日報第92期:華為高管揭秘公司不上市的原因;微信回應「花錢就能查到聊天記錄」;馬斯克洗掉「超蘋果只要幾個月」評論
下一篇:Docker基礎命令