目錄
- 一、ELK日志分析系統概述
- (1)傳統日志服務器的優點與缺點和為什么要使用ELK日志分析系統
- (2)ELK日志分析系統日志的分類
- (3)ELK日志分析系統的分類
- ——Elasticsearch:
- ——Logstash:
- ——Kibana:
- (4)日志處理的步驟
- 二、部署ELK日志分析系統
- (1)實驗環境
- (2)實驗目的
- (3)實驗步驟
- 1、node1配置
- 2、node2配置
- 3、node1和node2共同配置
- 4、安裝elasticsearch-head插件——node1和node2
- 5、node2配置——安裝logstash
- 6、node1安裝Kibana
- 三、擴展——添加apache日志
- -步驟
- -驗證
一、ELK日志分析系統概述
(1)傳統日志服務器的優點與缺點和為什么要使用ELK日志分析系統
通常來說,日志被分散的存盤在各自的不同的設備上,如果說需要管理上百臺機器,那么就需要使用傳統的方法依次登錄這上百臺機器進行日志的查閱,這樣會使得作業效率即繁瑣且效率低下,所以就引出了把日志集中化的管理方法,
例如: 開源的syslog,將所有的日志都放在一臺服務器上進行匯總,
下面就是傳統日志服務器的優點和缺點:
- 優點:
(1)提高安全性
(2)集中存放日志 - 缺點:
因為是集中存放日志,所有說對日志的分析是比較困難的
由上得知傳統日志服務器的缺點就是不方便作業人員進行日志的統計、檢索,那么一般作業人員會使用grep、awk和wc等linux命令進行統計和檢索,但是對于更高要求的查詢、排序、統計,再加上龐大的機器數量,再讓作業人員使用這種方法就顯得力不從心了,
而ELK日志分析系統就完美的解決了上面的問題,它是一個開源、實時的日志分析系統,
官方網站是: https://www.elastic.co/products
(2)ELK日志分析系統日志的分類
- 系統日志
- 應用程式日志
- 安全日志
日志分析是運維工程師解決系統故障,發現問題的主要手段,系統運維和開發人員可以通過日志了解服務器的軟硬體資訊,并且可以檢查配置程序中的錯誤以及錯誤發生的原因,經常分析日志可以了解服務器的負荷,性能安全性,從而及時的采取措施糾正錯誤,
(3)ELK日志分析系統的分類
ELK日志分析系統是由三個完全開源的軟體組合而成: Elasticsearch、Logstash、Kibana
——Elasticsearch:
Elasticsearch是一個開源的分布式搜索引擎, 特點有:分布式,零配置,自動發現,索引自動分片,索引副本機制,restful風格介面,多資料源,自動搜索負載等, 它是基于Lucene的搜索服務器,提供了一個分布式多用戶能力的全文搜索引擎,java開發,并且作為apache許可條款下的開放原始碼發布, 是第二流行的企業搜索引擎,設計用于云計算中,能夠達到實時搜索,穩定、可靠、快速、安裝使用方便,
概念:
- 接近實時:(NRT)
Elasticsearch是一個接近實時的搜索平臺,這意味著,從一個索引到一個檔案直到這個檔案能夠被搜索到會有一個輕微的延遲(通常是一秒)
- 集群:(cluster)
一個集群就是由一個或者多個幾點組織在一起,它們共同持有整個的資料,并且一期提供索引和搜索功能,集群中會有一個節點作為主節點,這個主節點可以通過選舉產生,并提供跨節點的聯合索引和搜索的功能,
集群會有一個唯一性的標識名稱,默認就是elasticsearch,集群的名稱很重要,每個節點都是基于集群名稱而加入到指定集群的,因此,必須確保在不同環境中使用不同的集群名稱,
一個集群可以只有一個節點,
最好在配置elasticsearch的時候,就配置成集群模式
- 節點:(node)
節點就是一臺單一的服務器,它是集群的一部分,進行存盤資料并且參與集群的索引和搜索功能,
和集群相同,節點也是通過名稱來進行標識,默認是在節點啟動時隨機分配的字符名,也可以進行自定義,該名稱用于在集群中識別服務器對應的節點,所以也很重要
- 索引:(index)
一個索引就是一個擁有相似特征的檔案的集和,
例如: 就像在網上買東西,如果要買褲子,那么你會搜索褲子,然后就會出現各式各樣的關于褲子的商品,或者在網上搜索某個明星的名字,就會出現這個明星相關的資訊,
在一個集群中,一個索引由一個名字來進行標識,這個名稱必須全部都是小寫字母,也可以自定義索引,
索引相當于關系型資料庫的庫
索引(庫)——型別(表)——檔案(資料)
- 型別:(type)
在一個索引中,用戶可以定義一種或者多種型別,一個型別是你的索引的一個邏輯上的分類磁區,其語意會完全由用戶來定義,
通常來說,會為具有一組共同欄位的檔案定義一個型別,
例如: 上面說的要買褲子,這個時候如果搜索的是牛仔褲、休閑褲,這種的,其實就是加了一個型別,
型別相當于關系型資料庫的表
索引(庫)——型別(表)——檔案(資料)
- 檔案:(document)
一個檔案是一個可以被索引的基礎資訊單元,
例如: 搜索牛仔褲,出來的各式各樣的牛仔褲,就可以看作是一個個資訊,
在一個索引和型別里面,只要用戶需要,可以存盤任意多的檔案,但是,雖然一個檔案在物理上位于一個索引中,實際上一個檔案必須在一個索引內被索引和給這個檔案分配一個型別
檔案相當于關系型資料庫的資料
索引(庫)——型別(表)——檔案(資料)
- 分片和副本:(shards and replicas)
分片: 在實際情況下,索引存盤的資料可能超過單個節點的硬體限制,例如:存盤10億個檔案需要1tb的空間,1tb的空間可能不適合存盤在單個節點的磁盤上,或者說10億個檔案在單個節點的搜索請求太慢了,而為了解決這個問題,elasticsearch提供將索引分成多個分片的功能,當在創建索引時,可以自定義想要分片的數量,每一個分片就是一個全功能的獨立的索引,可以位于集群中的任何節點上,
分片的兩個最主要的原因:
(1)水平分割擴展,增大存盤量
(2)分布式并行跨分片操作,提高了性能和吞吐量
副本: 分布式分片的機制和搜索請求的檔案如何匯總完全是由elasticsearch控制的,這些對于用戶而言是透明的,為了防止網路問題和其他的各種問題在任何時候的不請自來,一些用戶建議要有一個故障切換機制,來應對任何故障而導致的分片或者節點的不可用,為此,elasticsearch讓用戶將索引分片進行復制一份或者多分,而這個就稱之為分片副本或者副本,
副本的兩個最主要的原因:
(1)高可用性,以應對分片或者節點出現故障,因為這個原因,分片副本要在不同的節點上
(2)增大吞吐量,搜索可以并行在所有副本上執行
總的來說,每個索引可以被分成多個分片,一個索引也可以被復制0次(即沒有復制)或者多次,一旦復制了,每個索引就有了主分片 (即作為復制源的原來的分片) 和復制分片 (即主分片的拷貝) 的分別, (也就是 說只要索引被復制了一次,那么就會產生主分片和復制分片也就是兩個分片)
分片和副本的數量可以在索引創建的時候指定,在索引創建之后,用戶可以在任何時候動態的改變副本的數量,但是之后用戶無法改變分片的數量,
默認情況下,Elasticsearch中的每個索引都被分片成5個主分片和1個副本,這意味著,如果用戶的集群中至少有兩個節點,那么你的索引將會有5個主分片和另外5個副本分片還有一個索引的完全拷貝,這樣的化每個索引總共就有10個分片
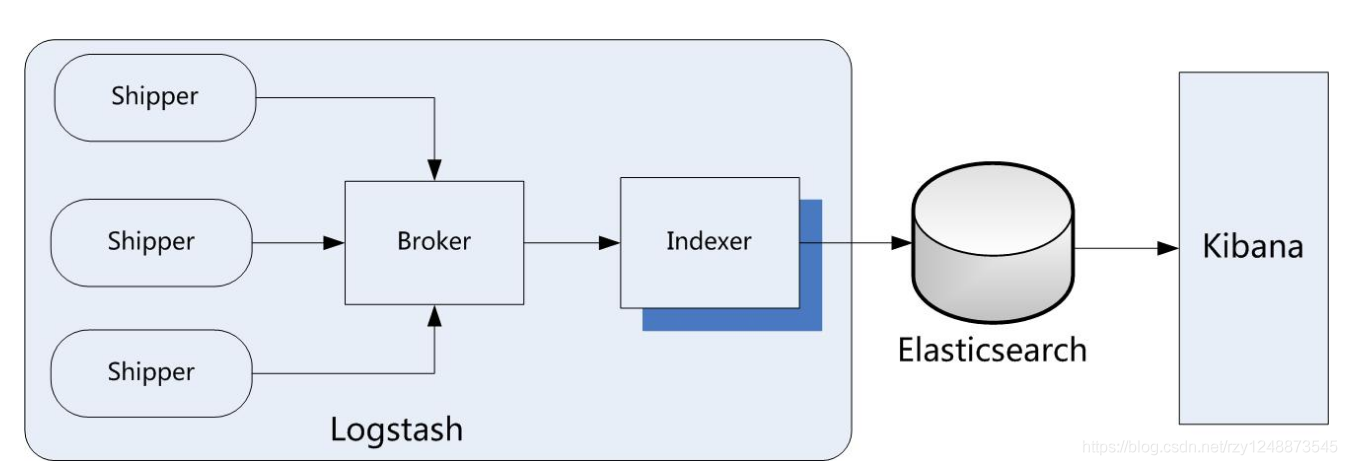
——Logstash:
Logstash是一個完全開源的工具,它可以對你的日志進行收集、過濾并且將其進行存盤, 它是由JRuby語言撰寫,基于訊息(message-based)的簡單架構,并且運行在java虛擬機上(即JVM),不同于分離的代理段(agent)或者主機端(server),LogStash可以配置單一的代理段(agent)于其他開源軟體結合,來實作不同的功能,
其實Logstash的理念很簡單,只做三件事情:
(1)Collect:資料輸入
(2)Enrich:資料加工,例如:過濾、改寫等
(3)Transport:資料輸出
別看Logstash只做三件事情,但是通過組合輸入和輸出,可以變化出多種架構從而實作各種需求,
Logstash主要組件:
- Shipper:
日志收集者,負責監控本地日志檔案的變化,及時把日志檔案的最新內容收集起來,通常,遠程代理端(agent)只需要運行這個組件即可
- Indexer:
日志存盤者,負責接收日志并且寫入到本地檔案
- Broker:
日志Hub(中心轉發器), 負責連接多個Shipper和多個Indexer
- Search and Storage:
運行對事件進行搜索和存盤
- Web Interface:
基于Web的展示界面
正因為上面的組件在Logstash架構中可以獨立部署,才提供了更好的集群擴展性
Logstash主機分類
- 代理主機(agent host):
作為事件的傳遞著(Shipper),將各種日志資料發送至中心主機,只需要運行logstash代理程式(agent) - 中心主機(central host):
可以運行包括中間轉發器(Broker)、索引器(Indexer)、搜索和存盤器(Search and Storage)、Web界面端(Web interface)在內的各個組件,以實作對日志資料的接收、處理和存盤,
——Kibana:
Kiabna是一個完全開源的工具,它可以為Logstash和Elasticsearch提供可視化的web界面, 并且可以幫助用戶進行匯總、分析和搜索重要的資料日志,使用Kibana,可以通過各種圖表進行高級資料分析以及展示,它讓海量資料更容易理解,操作簡單,基于瀏覽器的用戶界面可以快速創建儀表盤(dashboard,一種圖表)實時顯示Elasticsearch查詢動態,設定Kibana非常簡單,無需撰寫代碼,幾分鐘之內就可以完成Kibana的安裝并且啟動Elasticsearch索引監測,
Kibana主要功能:
-
Elasticsearch無縫之集成:
Kibana架構為Elasticsearch定制,可以將任何結構化和非結構化資料加入Elasticsearch索引,它還充分利用了Elasticsearch強大的搜索和分析功能 -
整合資料:
Kibana能夠更好的處理海量的資料,并且創建柱形圖、折線圖、直方圖等各種圖表 -
復雜資料分析:
Kibana提升了Elasticsearch的分析能力,能夠更加智能的分析資料,執行數學轉換并且根據要求對資料切割分塊 -
讓更多團隊成員收益:
強大的資料庫可視化介面讓各個業務崗位都能夠從資料集和中收益 -
介面靈活,分享更容易:
使用Kibana可以更加方便的創建、保存、分享資料,并且將可視化資料進行快速交流 -
配置簡單,可視化多資料源:
KIbana可以非常方便的把來自Logstash、ES-Hadoop、Beats或者第三方技術的資料整合到Elasticsearch,支持的第三方技術包括apache flume、fluentd等 -
簡單資料匯出:
Kibana可以方便的匯出用戶感興趣的資料,并且與其他資料集和、融合后快速建模分析,發現新結果
(4)日志處理的步驟
Logstash收集AppServer產生的log,并且存放到ElasticSearch集群中,而Kibana則從ES集群中查詢資料并且生成圖表,再回傳給Browser,總的來說,整個的程序需要進行以下幾個步驟:
(1)將日志進行集中化管理
(2)將日志格式化(Logstash)并且輸出到Elasticsearch
(3)對格式化后的資料進行索引和存盤(Elasticsearch)
(4)前端資料的展示(Kibana)
二、部署ELK日志分析系統
(1)實驗環境
本次實驗全部采用centos7.*系統
| 主機名稱 | ip地址 | 扮演角色 | 記憶體 |
|---|---|---|---|
| node1 | 192.1683.100.1 | node節點 | >=2G建議4G |
| node2 | 192.168.100.2 | node節點 | >=2G建議4G |
- node1部署:
(1)elasticsearch:埠 9200
(2)elasticsearch——head插件:埠 9100
(2)Kibana 日志分析平臺: 埠 5601 - node部署:
(1)elasticsearch:埠 9200
(2)logstash——日志采集
(2)實驗目的
- 配置ELK日志分析集群
- 使用logstash收集日志
- 使用Kibana查看分析日志
(3)實驗步驟
1、node1配置
******(1)先做基礎配置
[root@Centos7 ~]# hostnamectl set-hostname node1
[root@Centos7 ~]# su
[root@node1 ~]# systemctl stop firewalld
[root@node1 ~]# setenforce 0
setenforce: SELinux is disabled
[root@node1 ~]# mount /dev/cdrom /mnt/
mount: /dev/sr0 寫保護,將以只讀方式掛載
mount: /dev/sr0 已經掛載或 /mnt 忙
/dev/sr0 已經掛載到 /mnt 上
******(2)添加地址到hosts檔案,可以決議elk-2主機
[root@node1 ~]# echo '192.168.100.1 elk-1' >> /etc/hosts
[root@node1 ~]# echo '192.168.100.2 elk-2' >> /etc/hosts
[root@node1 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.100.1 node1
192.168.100.2 node2
[root@node1 ~]# bash (換一個bash環境更新配置)
2、node2配置
******(1)先做基礎配置
[root@Centos7 ~]# hostnamectl set-hostname node2
[root@Centos7 ~]# su
[root@node2 ~]# systemctl stop firewalld
[root@noded2 ~]# setenforce 0
setenforce: SELinux is disabled
[root@node2 ~]# mount /dev/cdrom /mnt/
mount: /dev/sr0 寫保護,將以只讀方式掛載
mount: /dev/sr0 已經掛載或 /mnt 忙
/dev/sr0 已經掛載到 /mnt 上
******(2)添加地址到hosts檔案,可以決議elk-1主機
[root@node2 ~]# echo '192.168.100.1 node1' >> /etc/hosts
[root@node2 ~]# echo '192.168.100.2 node2' >> /etc/hosts
[root@node2 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.100.1 node1
192.168.100.2 node2
[root@node2 ~]# bash
3、node1和node2共同配置
******(1)安裝java環境
[root@node1 ~]# yum -y install java
,,,,,,
完畢!
[root@node1 ~]# java -version
openjdk version "1.8.0_131"
OpenJDK Runtime Environment (build 1.8.0_131-b12)
OpenJDK 64-Bit Server VM (build 25.131-b12, mixed mode)
******(2)上傳軟體包并且安裝
[root@node1 ~]# ll
總用量 69660
-rw-------. 1 root root 1264 1月 12 18:27 anaconda-ks.cfg
-rw-r--r-- 1 root root 33396354 3月 30 22:08 elasticsearch-5.5.0.rpm
-rw-r--r-- 1 root root 37926436 3月 30 22:08 elasticsearch-head.tar.gz
[root@node1 ~]# rpm -ivh elasticsearch-5.5.0.rpm (使用rpm安裝)
,,,,,,
******(3)加載系統服務
[root@node1 ~]# systemctl daemon-reload
[root@node1 ~]# systemctl enable elasticsearch.service
Created symlink from /etc/systemd/system/multi-user.target.wants/elasticsearch.service to /usr/lib/systemd/system/elasticsearch.service.
******(4)更改主組態檔
[root@node1 ~]# cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml.bak (先做一個備份)
[root@node1 ~]# vim /etc/elasticsearch/elasticsearch.yml
,,,,,,
16 #
17 cluster.name: my-elk-cluster #集群名稱
18 #
,,,,,,
22 #
23 node.name: node1 #節點服務器名稱,node2寫node2即可
24 #
,,,,,,
32 #
33 path.data: /data/elk_data #資料存放路徑
34 #
,,,,,,
36 #
37 path.logs: /var/log/elasticsearch/ #日志存放路徑
38 #
,,,,,,
42 #
43 bootstrap.memory_lock: false #在啟動時不鎖定記憶體
44 #
,,,,,,
54 #
55 network.host: 0.0.0.0 #提供服務系結的ip地址,0.0.0.0表示所有地址
56 #
,,,,,,
58 #
59 http.port: 9200 #偵聽埠
60 #
,,,,,,
67 #
68 discovery.zen.ping.unicast.hosts: ["node1", "node2"] #集群發現通過單播傳輸實作
69 #
保存退出
******(5)利用scp傳輸到node2主機,修改部分內容即可
[root@node1 ~]# scp /etc/elasticsearch/elasticsearch.yml root@192.168.100.2:/etc/elasticsearch/elasticsearch.yml
The authenticity of host '192.168.100.2 (192.168.100.2)' can't be established.
ECDSA key fingerprint is SHA256:VhTZ5YxS5af2rHtfCvyc6ehXh3PD2A8KY2MyE6rHjiU.
ECDSA key fingerprint is MD5:e8:41:d2:8a:7e:e9:a9:47:a3:f0:29:be:e9:6d:df:51.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '192.168.100.2' (ECDSA) to the list of known hosts.
root@192.168.100.2's password:
elasticsearch.yml 100% 2853 3.7MB/s 00:00
******(6)創建資料存放路徑并且授權
[root@node1 ~]# mkdir -p /data/elk_data
[root@node1 ~]# chown elasticsearch.elasticsearch /data/elk_data/
******(7)啟動elasticsearch并且查看是否成功開啟
[root@node1 ~]# systemctl start elasticsearch.service
[root@node1 ~]# netstat -anpt | grep 9200
tcp6 0 0 :::9200 :::* LISTEN 15622/java
現在就可以使用客戶機先驗證一下,訪問:http://192.168.100.1:9200
查看集群的健康狀態,顯示:status:‘green’ 則節點健康運行,訪問:http://192.168.100.1:9200/_cluster/health?pretty

查看集群狀態資訊,訪問:http://192.168.100.1:9200/_cluster/state?pretty
因為這種查看方式及其不方便,所以可以考慮安裝elasticsearch-head插件,方便管理集群
4、安裝elasticsearch-head插件——node1和node2
可以先等node1安裝完這個插件之后,node2在安裝,安裝時程序較長,node2可以先做上面的步驟
—————————————————————————————————擴展———————————————————————————————————
elasticsearch在5.0版本之后,elasticsearch-head插件需要作為獨立服務進行安裝
需要使用npm安裝,并且需要提前安裝node和phantomjs
node:基于chrome V8引擎和javascript運行環境
phantomjs:基于webkit的javascriptAPI,這個可以理解為一個隱形的瀏覽器,可以做到webkit瀏覽器的作用
————————————————————————————————————————————————————————————————————————
******(1)編譯安裝node,需要四十分鐘左右
[root@node1 ~]# ll (上傳node和phantomjs的軟體包)
總用量 122152
-rw-------. 1 root root 1264 1月 12 18:27 anaconda-ks.cfg
-rw-r--r-- 1 root root 33396354 3月 30 22:08 elasticsearch-5.5.0.rpm
-rw-r--r-- 1 root root 37926436 3月 30 22:08 elasticsearch-head.tar.gz
-rw-r--r-- 1 root root 30334692 3月 30 23:13 node-v8.2.1.tar.gz
-rw-r--r-- 1 root root 23415665 3月 30 23:13 phantomjs-2.1.1-linux-x86_64.tar.bz2
[root@node1 ~]# tar xf node-v8.2.1.tar.gz
[root@node1 ~]# cd node-v8.2.1
[root@node1 node-v8.2.1]# ./configure && make && make install (時間較長,大約半小時左右)
******(2)安裝phantomjs
[root@node1 ~]# ll
總用量 122156
-rw-------. 1 root root 1264 1月 12 18:27 anaconda-ks.cfg
-rw-r--r-- 1 root root 33396354 3月 30 22:08 elasticsearch-5.5.0.rpm
-rw-r--r-- 1 root root 37926436 3月 30 22:08 elasticsearch-head.tar.gz
drwxr-xr-x 10 502 games 4096 3月 30 23:45 node-v8.2.1
-rw-r--r-- 1 root root 30334692 3月 30 23:13 node-v8.2.1.tar.gz
-rw-r--r-- 1 root root 23415665 3月 30 23:13 phantomjs-2.1.1-linux-x86_64.tar.bz2
[root@node1 ~]# tar xf phantomjs-2.1.1-linux-x86_64.tar.bz2 -C /usr/src/
[root@node1 ~]# cp /usr/src/phantomjs-2.1.1-linux-x86_64/bin/phantomjs /usr/local/bin/
******(3)安裝elasticsearch-head
[root@node1 ~]# tar xf elasticsearch-head.tar.gz -C /usr/src/ (解壓)
[root@node1 ~]# cd /usr/src/elasticsearch-head/
[root@node1 elasticsearch-head]# npm install (使用npm安裝)
npm WARN optional SKIPPING OPTIONAL DEPENDENCY: fsevents@^1.0.0 (node_modules/karma/node_modules/chokidar/node_modules/fsevents):
npm WARN network SKIPPING OPTIONAL DEPENDENCY: request to https://registry.npmjs.org/fsevents failed, reason: getaddrinfo ENOTFOUND registry.npmjs.org registry.npmjs.org:443
npm WARN elasticsearch-head@0.0.0 license should be a valid SPDX license expression
up to date in 2.707s
[root@node1 elasticsearch-head]# cd
******(4)修改elasticsearch主組態檔
[root@node1 ~]# vim /etc/elasticsearch/elasticsearch.yml
,,,,,,
末尾添加
http.cors.enabled: true #開啟跨域訪問支持,默認為false,所以需要改成true
http.cors.allow-origin: "*" #跨域訪問允許所有的域名地址
保存退出
[root@node1 ~]# systemctl restart elasticsearch (重啟服務)
******(5)啟動elasticsearch-head服務
————————————————————注意!!!!—————————————————
此操作必須在解壓的目錄下啟動,行程會讀取目錄中的gruntfile.js檔案,否則可能會失敗
監聽埠為:9100
————————————————————————————————————————————————
[root@node1 ~]# cd /usr/src/elasticsearch-head/ (進入解壓目錄)
[root@node1 elasticsearch-head]# ll Gruntfile.js (查看指定檔案)
-rw-r--r-- 1 root root 2231 7月 27 2017 Gruntfile.js
[root@node1 elasticsearch-head]# npm start & (掛到后臺啟動)
[1] 61130
[root@node1 elasticsearch-head]#
> elasticsearch-head@0.0.0 start /usr/src/elasticsearch-head
> grunt server
Running "connect:server" (connect) task
Waiting forever...
Started connect web server on http://localhost:9100
[root@node1 elasticsearch-head]# netstat -anpt | grep 9100 (檢查是否成功啟動)
tcp 0 0 0.0.0.0:9100 0.0.0.0:* LISTEN 61140/grunt
[root@node1 elasticsearch-head]# netstat -anpt | grep 9200
tcp6 0 0 :::9200 :::* LISTEN 1154/java
使用瀏覽器進行訪問:http://192.168.100.1:9100
在最上面輸入http://192.168.100.1:9200,點擊連接,就可以看到node1節點了
******(6)插入索引,進行測驗,索引名稱為index-demo,型別為test
[root@node1 elasticsearch-head]# curl -XPUT '192.168.100.1:9200/index-demo/test/1?pretty&pretty' -H 'Content-Type:application/json' -d'{"aaa":"bbb","ccc":"ddd"}'
{
"_index" : "index-demo",
"_type" : "test",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"created" : true
}
———————————————————選項——————————————————————
-X 指定命令,默認的命令是get
-P 通過ftp進行傳輸
-U 指定上傳用戶和密碼
-T 指定上傳
-H http協議的頭部資訊
-d 提交的資料資訊
—————————————————————————————————————————————
使用瀏覽器查看
點擊資料瀏覽,就會看到添加的索引
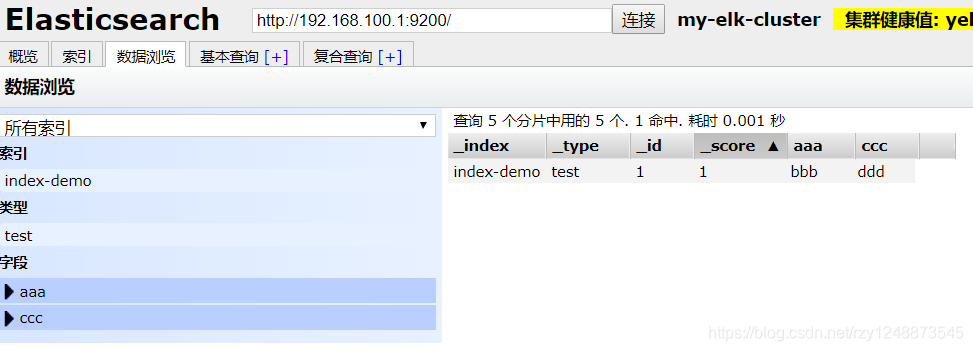 這個0-4就是五個分片
這個0-4就是五個分片
5、node2配置——安裝logstash
Logstash使用管道方式進行日志的搜集處理和輸出,有點像linux系統中的管道符"|",即執行完一個執行下一個
在Logstash中,包括了三個階段:
輸入input——處理filter(不是必須的)——輸出output
這三個階段都會有很多的插件來配置,比如:file、elasticsearch、redis等
每個階段也可以指定多種方式,比如輸出既可以輸出到elasticsearch中,也可以指定到stdout在控制臺列印,由于這種插件式的組織方式,使得logstash變得易于擴展和定制
logstash常用命令:
-f 通過這個命令可以指定logstash的組態檔,根據組態檔來配置logstash
-e 后面跟著字串,該字串可以被當作logstash的配置,如果是""則默認使用stdin作為輸入,stdout作為輸出
-t 測驗組態檔是否正確,然后退出
******(1)安裝logstash,安裝這個需要java環境,之前兩臺node已經裝過了
[root@node2 ~]# ll (上傳logstash的rpm包)
總用量 161612
-rw-------. 1 root root 1264 1月 12 18:27 anaconda-ks.cfg
-rw-r--r-- 1 root root 33396354 3月 30 22:08 elasticsearch-5.5.0.rpm
-rw-r--r-- 1 root root 37926436 3月 30 22:08 elasticsearch-head.tar.gz
-rw-r--r-- 1 root root 94158545 3月 30 23:17 logstash-5.5.1.rpm
[root@node2 ~]# rpm -ivh logstash-5.5.1.rpm (使用rpm安裝)
警告:logstash-5.5.1.rpm: 頭V4 RSA/SHA512 Signature, 密鑰 ID d88e42b4: NOKEY
準備中... ################################# [100%]
正在升級/安裝...
1:logstash-1:5.5.1-1 ################################# [100%]
Using provided startup.options file: /etc/logstash/startup.options
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
Successfully created system startup script for Logstash
[root@node2 ~]# systemctl start logstash.service (開啟服務)
[root@node2 ~]# ln -s /usr/share/logstash/bin/logstash /usr/local/bin/ (添加軟連接,優化命令執行路徑)
******(2)輸入采用標準輸入,輸出采用標準輸出
[root@node2 ~]# logstash -e 'input{stdin{}}output{stdout{}}'
,,,,,,
等待一段時間,當下面這段文字出現后再進行操作
The stdin plugin is now waiting for input:
01:47:27.213 [Api Webserver] INFO logstash.agent - Successfully started Logstash API endpoint {:port=>9600}
www.baidu.com (手動輸入)
2021-03-30T17:51:24.294Z node2 www.baidu.com (這個就是標準輸出)
www.sina.com (手動輸入)
2021-03-30T17:51:28.962Z node2 www.sina.com (標準輸出)
Ctrl+C退出
******(3)使用rubydebug顯示詳細輸出,dodec是一種編碼器
[root@node2 ~]# logstash -e 'input { stdin{} } output { stdout { codec=>rubydebug } }'
,,,,,,
再次等待一段時間,出現下面欄位后進行操作
01:56:30.916 [Api Webserver] INFO logstash.agent - Successfully started Logstash API endpoint {:port=>9600}
www.baidu.com (標準輸入)
{
"@timestamp" => 2021-03-30T17:56:36.133Z, (這個就是處理過后的輸出)
"@version" => "1",
"host" => "node2",
"message" => "www.baidu.com"
}
Ctrl+C退出
******(4)使用logstash將資訊寫入到elasticsearch中,并且遠程主機192.168.100.1:9200
[root@node2 ~]# [root@node2 ~]# logstash -e 'input { stdin{} } output { elasticsrch { hosts=>["192.168.100.1:9200"] } }'
,,,,,,
02:01:27.882 [Api Webserver] INFO logstash.agent - Successfully started Logstash API endpoint {:port=>9600}
www.baidu.com (三個標準輸入,會發現沒有進行輸出,這是因為發送到了elasticsearch中了)
www.sina.com
www.aaa.com
瀏覽http://192.168.100.1:9100查看結果
點擊資料瀏覽,就會看到

******(5)編輯logstash組態檔,收集系統日志,輸出到elasticsearch中
————————————————————————————————華麗分割線————————————————————————————————————
logstash組態檔基本上是由三部分組成的,input、output以及用戶需要時才添加的filter
標準的組態檔格式為:
input{,,,,}
filter{,,,,}
output{,,,,}
在每個部分中,可以指定多個訪問方式,例如:想要指定兩個日志來源檔案,那么就可以這樣寫,指定多個也是這種格式即可
input {
file { path => "/var/log/messages" type => "sylog" }
file { path => "/var/log/apache/access.log" type => "apache" }
}
—————————————————————————————————————————————————————————————————————————————
[root@node2 ~]# ll /var/log/messages
-rw-------. 1 root root 1184764 3月 31 02:06 /var/log/messages
[root@node2 ~]# chmod o+r /var/log/messages (給系統日志添加其他用戶的只讀權限)
[root@node2 ~]# ll /var/log/messages
-rw----r--. 1 root root 1185887 3月 31 02:07 /var/log/messages
[root@node2 ~]# ls /etc/logstash/conf.d/
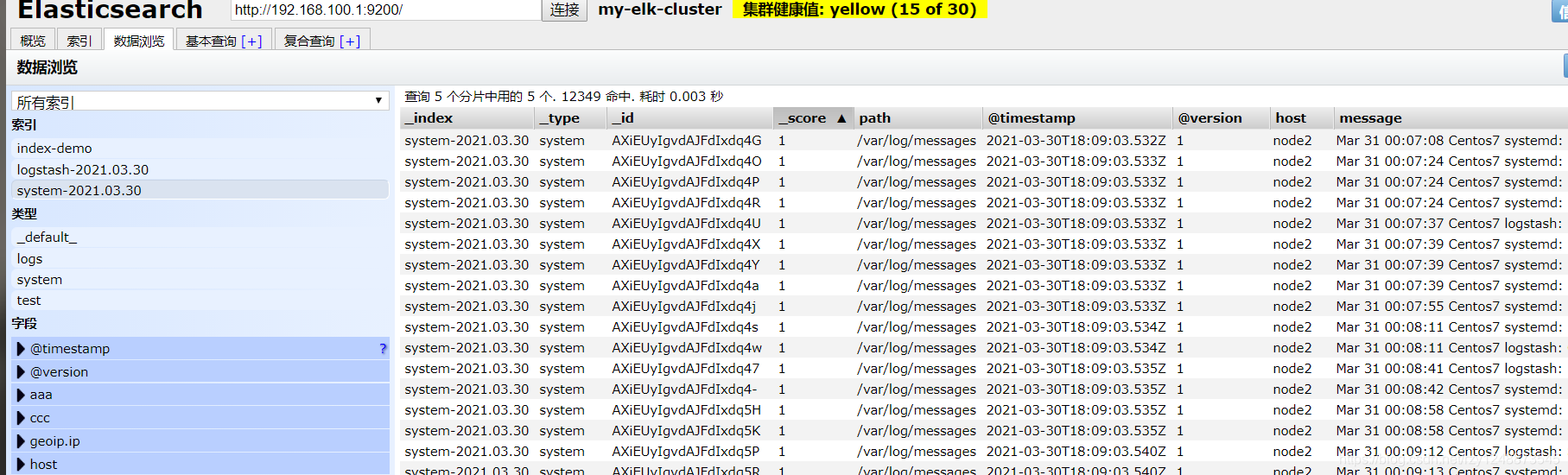
[root@node2 ~]# vim /etc/logstash/conf.d/system.conf (撰寫一個新檔案)
input {
file { #從檔案中讀取
path => "/var/log/messages" #檔案路徑
type => "system"
start_position => "beginning" #是否從頭開始讀取
}
}
output {
elasticsearch { #輸出到elasticsearch中
hosts => ["192.168.100.1:9200"] #指定elasticsearch的主機地址和埠
index => "system-%{+YYYY.MM.dd}" #索引名稱,這個是日期
}
}
保存退出
[root@node2 ~]# systemctl restart logstash (重啟服務)
瀏覽器訪問http://192.168.100.1:9100進行驗證,查看是否有系統日志存在
6、node1安裝Kibana
******(1)使用rpm方式安裝kibana
[root@node1 ~]# ll kibana-5.5.1-x86_64.rpm (上傳rpm包)
-rw-r--r-- 1 root root 52255853 3月 31 02:22 kibana-5.5.1-x86_64.rpm
[root@node1 ~]# rpm -ivh kibana-5.5.1-x86_64.rpm
,,,,,,
[root@node1 ~]# systemctl enable kibana (設定為開機自啟)
Created symlink from /etc/systemd/system/multi-user.target.wants/kibana.service to /etc/systemd/system/kibana.service.
******(2)配置kibana主組態檔
[root@node1 ~]# vim /etc/kibana/kibana.yml
,,,,,,
2 server.port: 5601 #打開kibana的埠
3
,,,,,,
7 server.host: "0.0.0.0" #kibana偵聽的地址,0.0.0.0為偵聽所有
8
,,,,,,
21 elasticsearch.url: "http://192.168.100.1:9200" #和elasticsearch的主機建立連接,指定地址和埠
22
,,,,,,
30 kibana.index: ".kibana" #再elasticsearch中添加.kibana索引
31
,,,,,,
保存退出
******(3)啟動Kibana服務
[root@node1 ~]# systemctl start kibana
[root@node1 ~]# netstat -anpt | grep 5601
tcp 0 0 0.0.0.0:5601 0.0.0.0:* LISTEN 1373/node
瀏覽器訪問http://192.168.100.1:5601,進入kibana控制臺
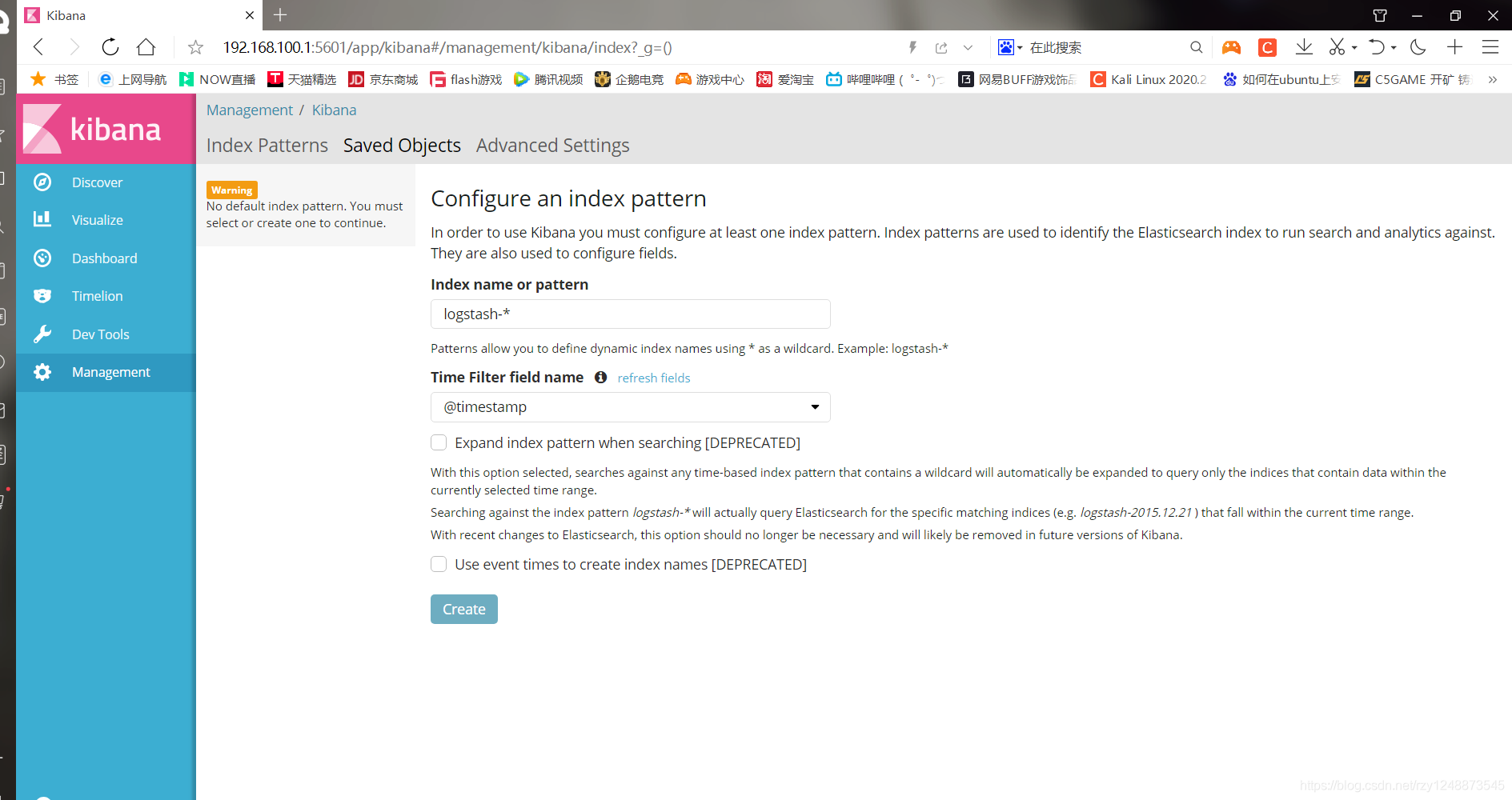
第一次登錄需要添加一個elasticsearch索引,添加前面的索引即可
依次點擊:
management——index patterns——create index pattern
index name or pattern選項是索引名稱,隨便起就行,我這里添加system*
time filter field name選項是設定時間過濾,選擇I don't want to use the time filter
填寫完后點擊Create
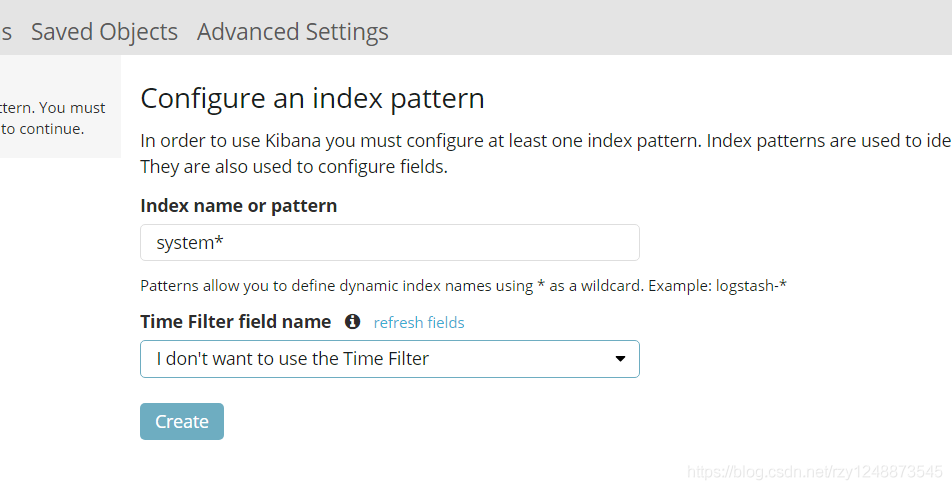
點擊Discover進行查看
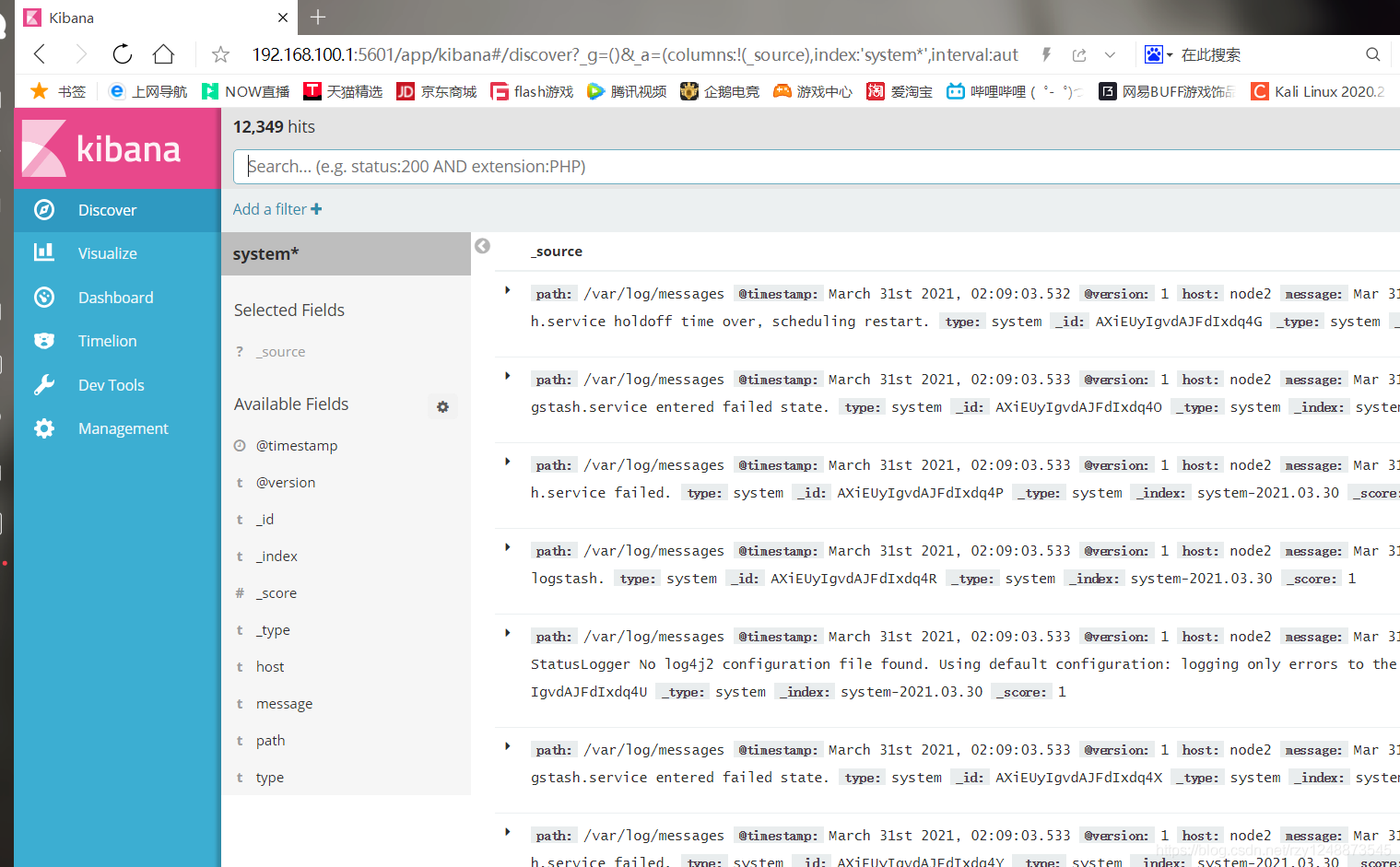
可以點擊這些選項進行篩選,想要篩選什么就點擊該選項的”add“即可,然后會進行篩選
如果添加后想要取消這個篩選條件,點擊指定選項的×號即可
三、擴展——添加apache日志
要求:將apache服務器的日志添加到elasticsearch并且通過kibana顯示
添加一個主機,用于安裝apache
| apache | 192.168.100.3 | 安裝httpd和logstash |
|---|
-步驟
******(1)先做基礎配置
[root@Centos7 ~]# hostnamectl set-hostname apache
[root@Centos7 ~]# su
[root@apache ~]# systemctl stop firewalld
[root@apache ~]# setenforce 0
setenforce: SELinux is disabled
[root@apache ~]# mount /dev/cdrom /mnt/
mount: /dev/sr0 寫保護,將以只讀方式掛載
mount: /dev/sr0 已經掛載或 /mnt 忙
/dev/sr0 已經掛載到 /mnt 上
******(2)安裝搖晃httpd,并且寫一個網頁
[root@apache ~]# yum -y install httpd
,,,,,,
完畢!
[root@apache ~]# systemctl enable httpd
Created symlink from /etc/systemd/system/multi-user.target.wants/httpd.service to /usr/lib/systemd/system/httpd.service.
[root@apache ~]# systemctl start httpd
[root@apache ~]# echo "<h1>aaaaaaa</h1> " > /var/www/html/index.html
******(3)安裝java
[root@apache ~]# yum -y install java
,,,,,,
完畢!
[root@apache ~]# java -version
openjdk version "1.8.0_131"
OpenJDK Runtime Environment (build 1.8.0_131-b12)
OpenJDK 64-Bit Server VM (build 25.131-b12, mixed mode)
******(4)上傳logstash的rpm包,進行安裝、配置
[root@apache ~]# ls
anaconda-ks.cfg logstash-5.5.1.rpm
[root@apache ~]# rpm -ivh logstash-5.5.1.rpm
[root@apache ~]# systemctl daemon-reload
[root@apache ~]# systemctl enable logstash.service
Created symlink from /etc/systemd/system/multi-user.target.wants/logstash.service to /etc/systemd/system/logstash.service.
[root@apache ~]# vim /etc/logstash/conf.d/apache_log.conf
input {
file {
path => "/etc/httpd/logs/access_log"
type => "access"
start_position => "beginning"
}
file {
path => "/etc/httpd/logs/error_log"
type => "error"
start_position => "beginning"
}
}
output {
if [type] == "access" {
elasticsearch {
hosts => ["192.168.100.1:9200"]
index => "apache_access-%{+YYYY.MM.dd}"
}
}
if [type] == "error" {
elasticsearch {
hosts => ["192.168.100.1:9200"]
index => "apache_error-%{+YYYY.MM.dd}"
}
}
}
保存退出
[root@apache ~]# ln -s /usr/share/logstash/bin/logstash /usr/local/bin/
[root@apache ~]# logstash -f /etc/logstash/conf.d/apache_log.conf
,,,,,,
03:07:07.932 [Api Webserver] INFO logstash.agent - Successfully started Logstash API endpoint {:port=>9600}
www.aaaa.com (隨便輸入幾個域名)
www.bbbbb.com
abc.www.com
-驗證
登錄kibana,訪問http://192.168.100.1:9100查看索引是否存在

登錄kibana界面添加索引,訪問http://192.168.100.1:5601
和上面相同的方法,添加一個新的apache索引
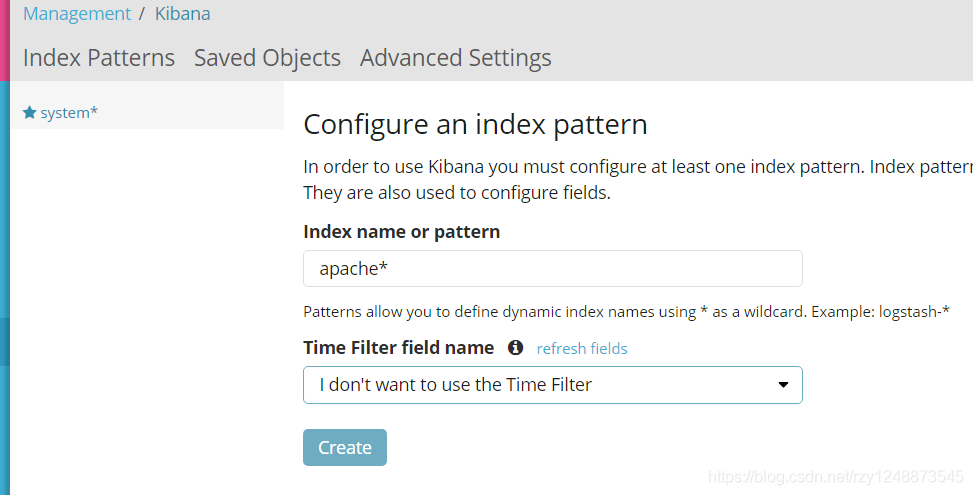
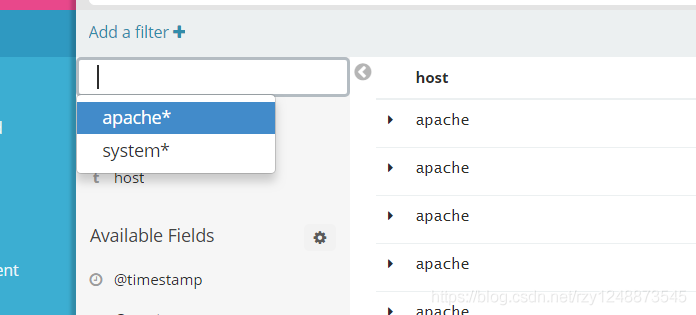
至此,ELK日志分析平臺搭建完成!!!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/271287.html
標籤:其他
上一篇:藍橋杯集錦04(python3)
下一篇:中科大大資料考研資訊匯總Q&A