全面決議LinkedList
- 由ArrayList引發的思考
- 在講之前來對比一下ArrayList和LinkedList
- 首先看看LinkedList的繼承實作關系
- 類內部的成員變數
- 構造方法
- 最難的addAll()方法
- 一些輔助的方法(private),無法主動呼叫
- 關于clone()實作鏈表的深拷貝
- 關于fast-fail機制和執行緒不安全
- 寫在最后
在講LinkedList之前,建議先對ArrayList有一個較為深入的理解,這樣兩者對比之下,就能找到更適合生產環境中的容器型別,相信我,看下去一定讓看官滿意~
可以閱讀博主的另一邊文章,帶你全面了解ArrayList,從擴容機制,常見方法,到fail-fast以及并發情況下的問題都有深入分析:深入理解ArrayList
由ArrayList引發的思考
由于ArrayList底層是由陣列存盤的,優點很明顯:連續存盤空間可以由角標在o(1)的時間復雜度內完成
缺點:
1.對于元素的增刪操作最差達到o(n)
2.并且存在不斷擴容的問題,時間消耗較大
3.并且空間并不是你想用多少就給多少,很大可能會造成空間浪費
那么,有沒有一種要多少空間就申請多少空間,并且大大較快增刪效率的集合呢?
有,那就是接下來講到的LinkedList
在講之前來對比一下ArrayList和LinkedList
1.ArrayList底層是由動態陣列作為存盤結構,LinkedList由雙向鏈表作為存盤結構
2.ArrayList對于get(),set()方法效率較高,因為存盤空間連續,由下標就可以找到對應存盤空間的元素
3.LinkedList對于remove(),add()方法效率較高,因為鏈表存盤結構,只用改變前后指標指向即可,而陣列需要挪動資料
4.ArrayList和LinkedList都是執行緒不安全的,在本文的最后會介紹原因以及解決方案
首先看看LinkedList的繼承實作關系
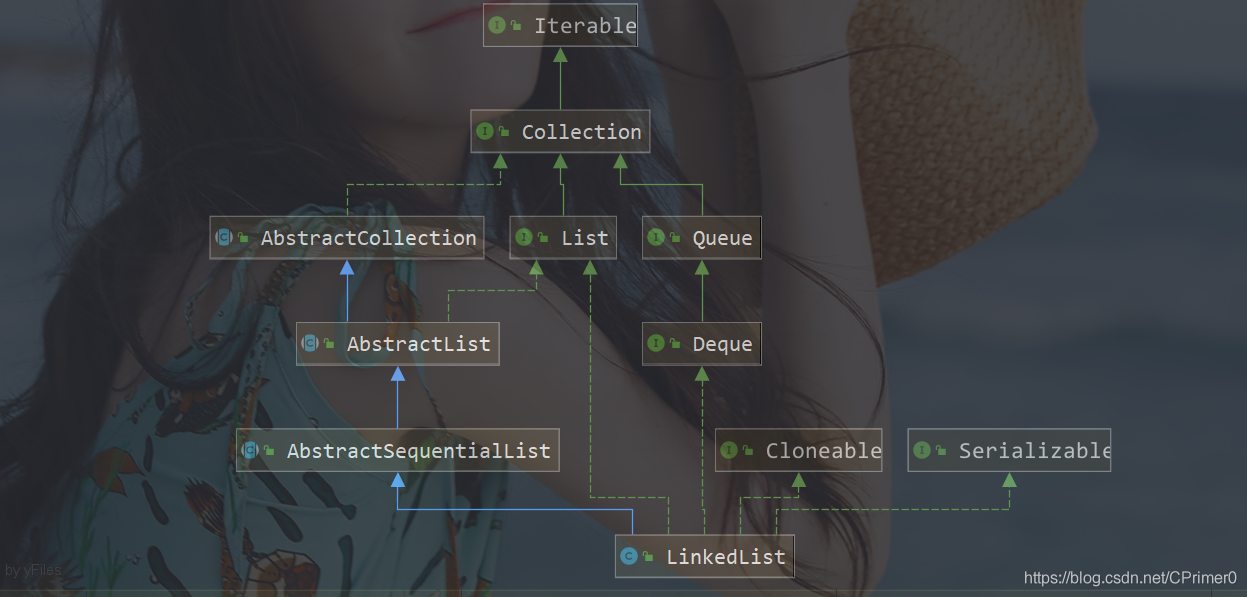
這里的介面不在一一分析了,在博主的ArrayList系列文章中已經深入講解這些介面,可以移步:深入理解ArrayList,
相比于ArrayList,它額外實作了雙端佇列介面Deque,這個介面主要是宣告了隊頭,隊尾的一系列方法,
類內部的成員變數
//容器元素個數
transient int size = 0;
//雙向鏈表的頭節點
transient Node<E> first;
//雙向鏈表的尾節點
transient Node<E> last;
//內部類,鏈表的實作機制:Node節點,將存盤陣列轉換為Node節點
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
//構造方法
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
transient的作用:簡單來理解: Map,Set,List等都是使用transient關鍵字屏蔽變數,然后自己實作的序列化操作(writeObject(),readObject()方法),
構造方法
//空參構造器
public LinkedList() {
}
//傳入一個Colleaction集合
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
我查看了網上的大多數博客都沒有解釋addAll()操作,這里我帶大家深入看看這個addAll()方法的奧妙,其中的判斷遍歷方法大家在演算法或者撰寫代碼中都可以借鑒
最難的addAll()方法
先說結論
1.傳入集合的構造方法,底層呼叫,新建一個鏈表
2.當你想再index位置插入集合時,主動呼叫
//addAll()方法不止一次呼叫
public boolean addAll(Collection<? extends E> c) {
//當構造方法呼叫時,這時size為默認值0
return addAll(size, c);
}
//這里index為傳入的size為0
public boolean addAll(int index, Collection<? extends E> c) {
//簡單的判斷索引是否合法
checkPositionIndex(index);
//轉換為陣列
Object[] a = c.toArray();
int numNew = a.length;
//如果陣列為空,就不用往后操作了,直接回傳false
if (numNew == 0)
return false;
//succ表示當前節點插入的位置
//pred表示插入位置的前一個位置
Node<E> pred, succ;
//接下來看文章來分析
if (index == size) {
succ = null;
pred = last;
} else {
succ = node(index);
pred = succ.prev;
}
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
Node<E> newNode = new Node<>(pred, e, null);
if (pred == null)
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
if (succ == null) {
last = pred;
} else {
pred.next = succ;
succ.prev = pred;
}
size += numNew;
modCount++;
return true;
}
我們來看看方法的具體業務邏輯,首先我們明確一點,succ是索引index處的節點,pred是index前一個節點,結合代碼看我分析
1.確定succ和pred的位置,當size==index時,說明我們要插入的位置是在隊尾,所以我們將succ設為null,pred設為last堆尾
-
構造方法中呼叫,這時size==index為0,還沒有節點,last還為null,所以prev和succ都為null
-
如果是你主動呼叫,size==index,說明要插入到隊尾,所以prev=last,succ=null
2.否則我們插入的不是堆尾,我們呼叫node()方法,我們稍后講解這個方法,我們暫時只要知道這個方法回傳了對應索引位置上的Node(節點),succ = Node,pred = Node.prev,找到了succ和prev的位置
- 這里構造方法呼叫addAll()方法時并不會執行,而是當你想在index位置插入一個集合時呼叫方法時才會走這里的邏輯
3.接下來就是回圈入隊了, if (pred == null),說明什么?當前要插入位置的前置節點為null,說明要插入的位置就是頭節點,所以令頭節點first=newNode,否則:pred.next表示當前要插入的位置,令pred.next=newNode,你可能會有疑惑?為什么不直接把succ = newNode,別急接著看
4.succ == null,插入的是隊尾,last = pred;
5.這里就是上面的答案,假如你的index是插入到鏈表中間(也就是else邏輯),將鏈表劈成兩節,pred記錄劈開的左端,succ記錄劈開的右端,上個for回圈將節點都插入到了pred的后面,現在把pred和succ連接,就練成了一條完整的鏈表,如果沒有succ記錄,就找不到鏈表劈開的又斷了
上文遺留node(index)方法
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
首先size>>1==size/2,所以判斷index是偏向鏈表的左端還是右端,偏向左端從頭遍歷,偏向右端從尾遍歷,加快了找到index節點的速率,是不是很巧妙
一些輔助的方法(private),無法主動呼叫
不知道你是否記得開頭LinkedList同樣實作了Deque介面,LinkedList中大多數通過他們來完成List、Deque中類似的操作,
1.linkFirst(E e)方法
把引數中的元素作為鏈表的第一個元素,
private void linkFirst(E e) {
final Node<E> f = first;
//prev==null,item==e,next==f
final Node<E> newNode = new Node<>(null, e, f);
//將newNode賦給first作為頭節點
first = newNode;
//f為null,說明鏈表為空,將尾節點也指向newNode
if (f == null)
last = newNode;
//f不為null,將f連接在newNode后
else
f.prev = newNode;
//元素個數+1
size++;
//fast-fail實作機制
modCount++;
}
在集合的CRUD操作中,modCount變數都會改變,設計到fast-fail機制,本文最后講到
2.linkLast(E e)
把引數中的元素作為鏈表的最后一個元素
邏輯幾乎同上,不在贅述
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
3.linkBefore(E e, Node succ)
在非空節點succ前插入元素E
由于底層呼叫,不給程式員機會,所以succ傳入的一定不為null
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
//記錄當前節點的前置節點
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
//將newNode設定在succ前
succ.prev = newNode;
//pred為空,說明當前節點就是頭節點,所以在succ前插入節點,
//然后直接將first指向newNode
if (pred == null)
first = newNode;
else
//否則將newNode插入到succ前
pred.next = newNode;
size++;
modCount++;
}
4.unlinkFirst(Node f)
洗掉掉鏈表中第一個節點
private E unlinkFirst(Node<E> f) {
//這里注釋很明顯,傳入的f == first,并且不為null
// assert f == first && f != null;
//獲取到元素
final E element = f.item;
//拿到下一個節點
final Node<E> next = f.next;
//將傳入的first頭節點清理掉
f.item = null;
f.next = null; // help GC
//令頭節點等于第二個節點,next晉升為頭節點
first = next;
//頭節點的下一個節點是null,說明只有一個節點,
//洗掉后first==last==null
if (next == null)
last = null;
else
//新晉的next作為頭節點,把前置節點設為null
next.prev = null;
size--;
modCount++;
return element;
}
unlinkLast(Node l)
洗掉掉最后一個節點,這里的邏輯和上述方法大致相似,更加簡單,自己嘗試分析試一下
private E unlinkLast(Node<E> l) {
// assert l == last && l != null;
final E element = l.item;
final Node<E> prev = l.prev;
l.item = null;
l.prev = null; // help GC
last = prev;
if (prev == null)
first = null;
else
prev.next = null;
size--;
modCount++;
return element;
}
5.unlink(Node x)
洗掉掉x節點,并回傳洗掉節點的元素
E unlink(Node<E> x) {
//同理,底層呼叫不給你傳null的機會
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
//洗掉的是頭節點,直接令next晉升為頭節點
if (prev == null) {
first = next;
}
else {
prev.next = next;
x.prev = null;
}
//洗掉的是尾節點,直接令prev晉升為尾節點
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
這里我們不考慮洗掉的是頭節點,尾節點的情況,一個圖帶你快速了解洗掉的程序
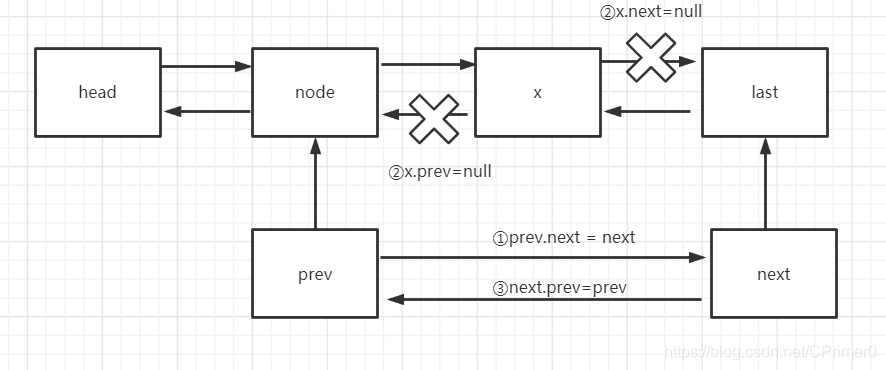
由于prev和next是淺賦值,參考指向的是同一個物件,所以修改了prev和next的指標就相當于修改了上圖的node和last的指標,這樣就洗掉了X節點
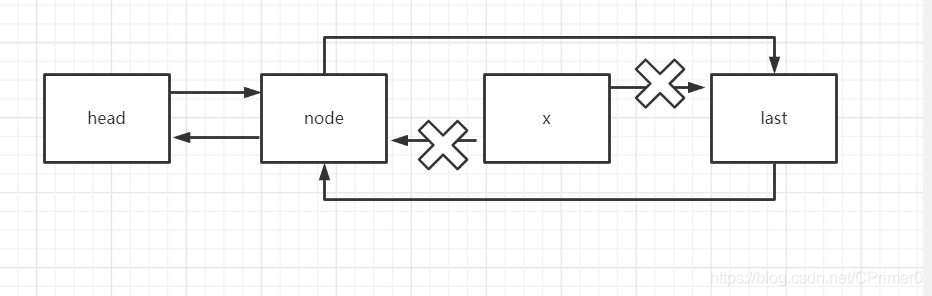
其他方法
其他方法的邏輯就十分簡單了,就是通過呼叫我們上述的各種方法來實作,方法十分多且簡單,在此就不再介紹了
關于clone()實作鏈表的深拷貝
首先我們看到LinkedList實作了clone()介面,并且重寫了clone()方法,所以這里我們對于LinkedList呼叫clone()方法是實作深復制的程序,即不單單拷貝參考,如果對深拷貝和淺拷貝還有疑問:請戳
public static void main(String[] args) throws CloneNotSupportedException {
LinkedList<Person> objects = new LinkedList<>();
Person jack = new Person("jack");
objects.add(jack);
objects.add(new Person("rose"));
LinkedList clone = (LinkedList) objects.clone();
//這里我們洗掉克隆鏈表的元素,看看原來的鏈表是否會改變
objects.remove(jack);
System.out.println(objects);
System.out.println(clone);
//答案是不會,所以這里的clone()是深拷貝
//[Person{name='jack'}, Person{name='rose'}]
//[Person{name='rose'}]
}
關于fast-fail機制和執行緒不安全
上文留下的modCount這個變數的坑,有什么用呢?和ArrayList幾乎一摸一樣,這里可以看看博主的另一篇文章,點擊開頭的目錄跳轉到指定的位置即可:fast-fail機制和執行緒不安全
寫在最后
博主看過許多網上的博客,發現對于許多操作都模糊不堪,例如插入集合,洗掉指定位置節點,我試圖清晰的講述給你,如果有疑問或者錯誤,歡迎留演討論,如果你覺得不錯,點個小小的贊,就是對作者最大的鼓勵
作者的java集合專欄打算深入ArrayList,LinkedList,Set,Map等等集合,關注一波,相信不會讓你失望噠~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/271524.html
標籤:其他
上一篇:多執行緒系列:三大特性理解