Hadoop 全分布安裝部署:
目錄
Hadoop 全分布安裝部署:
一: 安裝前準備
二: 配置jdk
三: 部署hadoop集群
四: 啟動hadoop集群
五: 總結
VMWare上安裝liunx系統: 裝虛擬機及linux系統
hadoop偽分布安裝請移步:hadoop偽分布安裝
一: 安裝前準備
安裝工具準備: 都已經在hadoop偽分布中準備齊全,自取
hadoop偽分布安裝
1. 確保已經安裝好三臺虛擬機及linux系統
2. 確定那一臺為主節點,剩余兩臺為從節點
3. 都需要關閉防火墻
systemctl status firewalld.service 【查看狀態】
systemctl start firewalld.service 【開啟】
systemctl stop firewalld.service 【關閉】
systemctl disable firewalld.service 【關閉開機自啟】
4. 設定主機名【我的三臺演示主機名分別設定為: bigdata1(主節點) , bigdata2,bigdata3】
5. 配置host
5.1 主節點輸入配置 hosts 檔案: vi /etc/hosts
5.2 把三臺機器的ip地址和主機名添加進去
5.3 將主節點hosts檔案拷貝到其他子節點

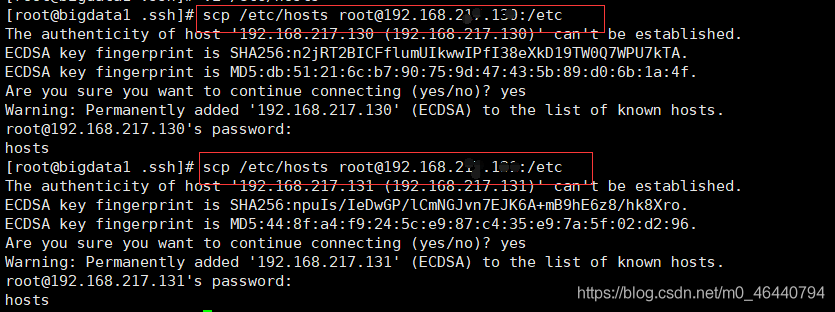
6. 配置免密登錄【方便后續遠程拷貝資料,快速操作集群】
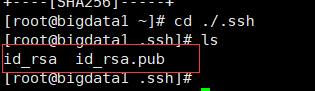
1. 每臺機器上輸入: ssh-keygen -t rsa,生成兩個檔案,一個公鑰(id_rsa.pub),一個私鑰(id_rsa)
2. 將公匙上傳到目標機器
注意:在每臺機器上都要輸入:【分別將各自的公匙上傳到另外兩臺機器】
ssh-copy-id 上傳到的機器主機名
3. 測驗無密碼登錄挑轉到其他機器: ssh 主機名
二: 配置jdk
主節點進行以下配置: 【實質三臺機器都要進行配置jdk,但是只用在主節點配置,后拷貝到其他節點即可】
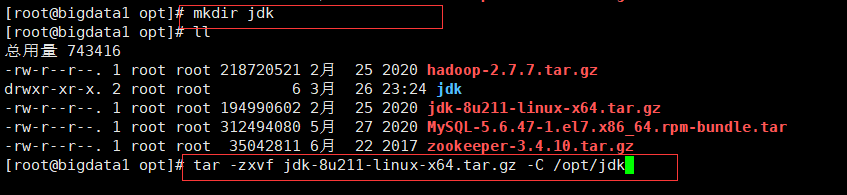
1. 在/opt下創建目錄jdk,將jdk解壓在該檔案下
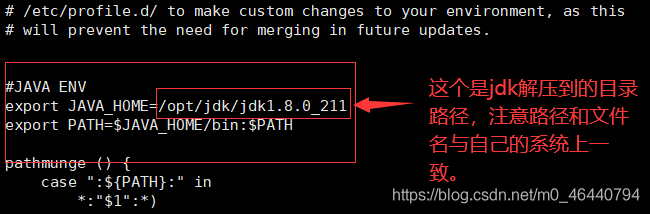
2. 在/etc/profile目錄下配置環境變數和啟動程式,輸入:vi /etc/profile 【按 i 進入編輯模式,編輯完后先按esc 再輸入 :wq 保存并退出】
#JAVA ENV
export JAVA_HOME=/jdk解壓目錄
export PATH=$JAVA_HOME/bin:$PATH
3. 重繪使得編輯檔案生效,輸入: source /etc/profile
4. 輸入查看java環境是否安裝成功: java -version

三: 部署hadoop集群
1. 只配置主節點,最后將配置好的jdk,hadoop資料拷貝到子節點即可,
2. hadoop全分布環境需要配置8個組態檔
hadoop-env.sh //用于修改JAVA_HOME后的目錄,改成實際本機jdk所在目錄位置
core-site.xml //用于指定namenode節點的位置,Hadoop運行時產生檔案所存盤的mulu
hdfs-site.xml //指定hdfs的副本數和secondarynamenode的位置
slaves //用于指定組成機器的主機名
yarn-env.sh //用于修改JAVA_HOME后的目錄,改成實際本機jdk所在目錄位置
yarn-site.xml //用于指定reducer獲取資料的方式、指定resourcemanager的位置
mapred-env.sh //用于修改JAVA_HOME后的目錄,改成實際本機jdk所在目錄位置
mapred-site.xml //指定mr在yarn上運行
3. 配置hadoop環境變數
配置hadoop環境【在 /etc/profile 目錄下配置,輸入:vi /etc/profile,按 i 進入編輯模式,編輯完后先按esc 再輸入 :wq 保存并退出】
#HADOOP ENV
export HADOOP_HOME=/hadoop解壓目錄
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH

重繪使得檔案生效,并查看環境是否配置成功【重繪:source /etc/profile ; 查看是否配置成功:hadoop】
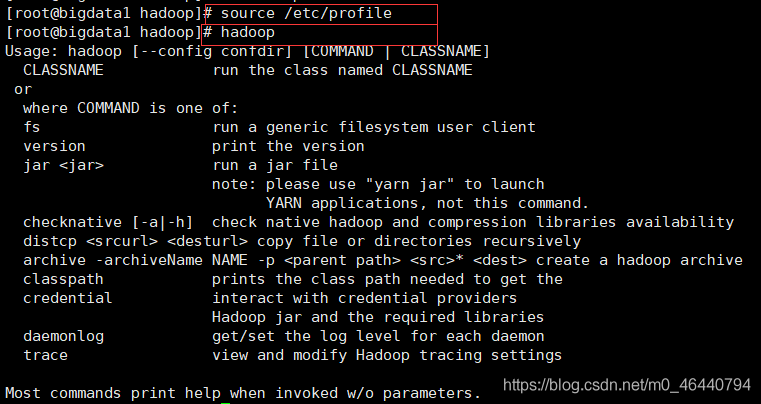
4. 進入hadoop解壓目錄下的 /etc/hadoop 中

5. 修改以下三個組態檔中對應的jdk安裝位置:
- hadoop-env.sh
- yarn-env.sh 【將前面的注釋去掉】
- mapred-env.sh 【將前面的注釋去掉】
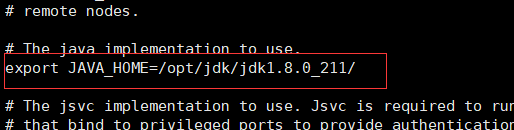
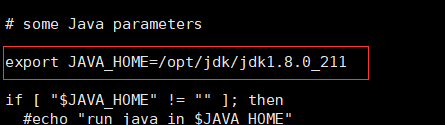
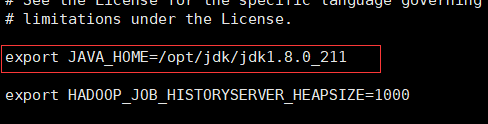
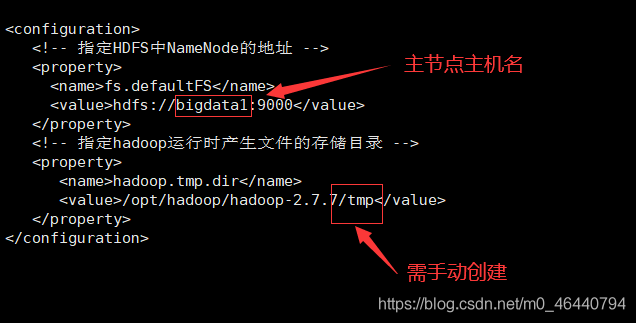
6. 配置core-site.xml檔案
<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata1:9000</value>
</property>
<!-- 指定hadoop運行時產生檔案的存盤目錄 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/hadoop-2.7.7/tmp</value>
</property>
</configuration>
7. 配置hdfs-site.xml檔案
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata1:50090</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
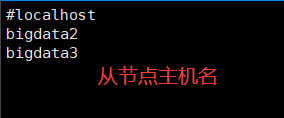
8. 配置slave檔案
9, 配置mapred-site.xml 【先通過mapred-site.xml.template復制: cp mapred-site.xml.template mapred-site.xml】
<configuration>
<!--指定mr運行在yarn上-->
<property>
<name>mapreduce.framwork.name</name>
<value>yarn</value>
</property></configuration>

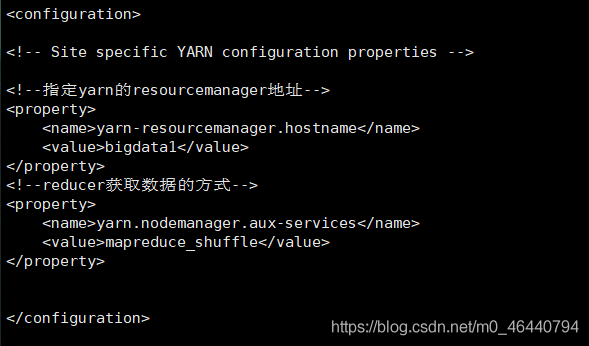
10. 配置yarn-site.xml檔案
<configuration>
<!--指定yarn的resourcemanager地址-->
<property>
<name>yarn-resourcemanager.hostname</name>
<value>bigdata1</value>
</property>
<!--reducer獲取資料的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
11. 拷貝hadoop安裝檔案,jdk安裝檔案,profile檔案到從節點
scp -r /要拷貝的目錄 root@主機名:/拷貝到的目錄
12. 在從節點執行命令使profile檔案生效
source /etc/profile
13. 格式化主節點的namenode
- 進入hadoop目錄下的bin目錄
- 執行: ./hadoop namenode -format
- 成功格式化提示如下:

四: 啟動hadoop集群
1. 進入sbin目錄下輸入啟動:
- 執行啟動: ./start-all.sh
2. 啟動成功主節點行程如下:
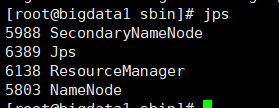
兩個從節點進程如下:
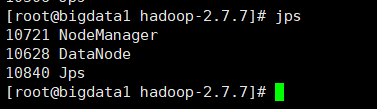
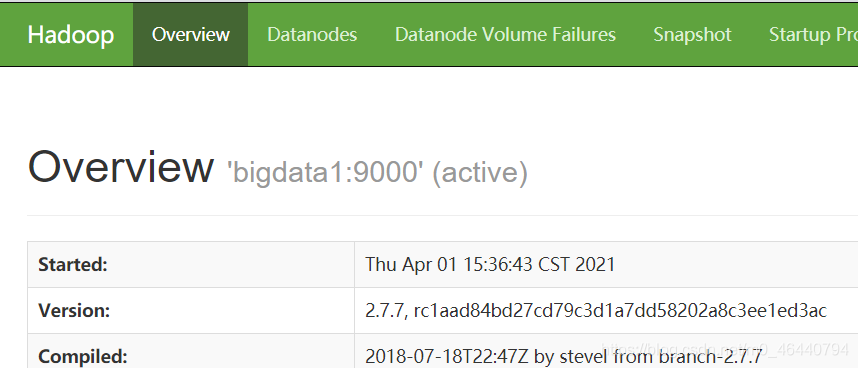
3. 瀏覽器查看hadoop頁面:【切記先關閉防火墻,且在windows端配置ip映射】
主節點:50070
五: 總結
以上就是hadoop的全分布安裝部署,
整個程序: 安裝三臺虛擬機------配置hosts-----配置免密登錄-------配置jdk-----配置hadoop(8個組態檔)------格式化namenode------啟動hadoop集群
后續將繼續給出有關hadoop更多的學習文章,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/271544.html
標籤:其他