目錄
RDD概念
RDD簡介
什么是RDD?
RDD的五個主要屬性
分片/區(Partition)
磁區計算函式
RDD的分片函式(Partitioner)
RDD相互依賴
優先位置串列
創建RDD
基于資料集合創建RDD
基于外部資料源創建RDD
Python統計檔案總字數
RDD算子-轉換和動作
RDD算子(主要操作)
轉換操作 map
轉換操作 flatMap
轉換操作 filter
轉換操作 union
轉換操作 intersection
轉換操作 distinct
轉換操作 sortBy
轉換操作 glom
轉換操作 mapPartitions
轉換操作 mapPartitionsWithIndex
動作操作
動作操作 collect
動作操作 reduce
動作操作 count
動作操作 take
動作操作 first
動作操作 max
動作操作 top
動作操作 saveAsTextFile
動作操作 foreach
動作操作 foreachPartition
PairRDD
轉換操作 mapValues
轉換操作 flatMapValues
轉換操作 groupByKey
?轉換操作 reduceByKey
轉換操作 sortByKey
轉換操作 partitionBy
轉換操作 keys
轉換操作 values
轉換操作 join
轉換操作 leftOuterJoin
轉換操作 rightOuterJoin
動作操作 collectAsMap
動作操作 countByKey
共享變數
閉包問題
累加器 Accumulator
廣播變數 Broadcast
廣播變數示例
RDD依賴關系
依賴關系
RDD的持久化
每文一語
RDD概念
RDD簡介
什么是RDD?
Spark 的核心是建立在統一的抽象彈性分布式資料集(Resiliennt Distributed Datasets,RDD)之上的,這使得 Spark 的各個組件可以無縫地進行集成,能夠在同一個應用程式中完成大資料處理,
RDD是彈性分布式資料集:它是一種容錯的并行資料機構
RDD數只讀的磁區記錄集合:在這個基礎上提供比較豐富的操作方法
RDD是spark的基石也是spark的靈魂:在spark里面將資料抽象為RDD,這就使得我們在處理大資料集可以得心應手

RDD的五個主要屬性
分片/區(Partition)
Partition(磁區或分片)是 Spark 資料集的基本組成單位,Spark 集群讀取一個檔案會根據具體的配置將檔案加載在不同的節點的記憶體中,每個節點中的資料就是一個分片,對于 RDD 來說,每個分片都會被一個計算任務處理,并決定并行計算的粒度,用戶可以在創建 RDD 時指定 RDD的分片個數,默認分片個數與 CPU 核心個數相同,
磁區計算函式
Spark 中 RDD 的計算是以分片為單位的,每個 RDD 都會實作計算函式以達到分片計算,計算函式會對迭代器進行復合,不需要保存每次計算的結果,
RDD的分片函式(Partitioner)
當前 Spark 中實作了兩種型別的分片函式,一個是基于哈希的HashPartitioner,另外一個是基于范圍的 RangePartitioner,只有對于key-value的RDD,才會有Partitioner,非key-value的 RDD的Parititioner的值是None,Partitioner函式不但決定了RDD本身的分片數量,也決定了parent RDD Shuffle輸出時的分片數量,
RDD相互依賴
RDD 的每次轉換都會生成一個新的 RDD,因此 RDD 之間就會形成類似于流水線一樣的前后依賴關系,在部分磁區資料丟失時,Spark 可以通過這個依賴關系重新計算丟失的磁區資料,而不是對 RDD 的所有磁區進行重新計算,
優先位置串列
就是存盤讀取每個Partition的優先位置串列,對于一個 HDFS 檔案來說,這個串列保存的就是每個 Partition 所在的塊的位置,按照“移動資料不如移動計算”的理念,Spark 在進行任務調度的時候,會盡可能地將計算任務分配到其所要處理資料塊的存盤位置,
創建RDD
基于資料集合創建RDD
parallelize 函式可以將一個可迭代物件轉換為RDD物件,需要傳入一個可迭代物件,還可以指定磁區數,如果不指定則采用默認值defaultParallelism ,count函式回傳RDD中元素的個數,
這個代碼是必須要寫入到我們的代碼塊里面的,它的作用是為了找到本地的spark的環境進行相關的操作,spark背景關系的呼叫:
import findspark
findspark.init()
from pyspark import SparkContext
sc = SparkContext() # 加載檔案
data = [1, 2, 3, 4, 5]
distData_1 = sc.parallelize(data) # parallelize函式創建RDD
distData_2 = sc.parallelize(data, 2) # 指定磁區數創建RDD,指定2個磁區
a=distData_2.count() # count函式回傳RDD中元素的個數,
b=distData_1.count()
print(a)
print(b)

紅色警告是正常的!如果你看起來不舒服可以去花一定的時間去解決但是我感覺得沒有必要
基于外部資料源創建RDD
textFile 函式可以將一個外部資料源轉換為RDD物件,檔案的一行資料就是RDD的一個元素,需要傳入該資料源的url,可以是本地檔案,也可以是hdfs中的檔案,如果是本地檔案,則在url前面加file:///,如果是hdfs上的檔案,則在url前面加hdfs:/// ,count函式回傳RDD中元素的個數,
distFile1 = sc.textFile(“file:///home/camel/Repos/spark/README.md”) # 本地檔案
distFile2 = sc.textFile(“hdfs:///test/output”) # hdfs上的檔案
distFile1.count() # 此時的count函式回傳的是文本的行數
Python統計檔案總字數

#1.常規思路,代碼如下
file=open("/home/camel/Repos/spark/README.md")
lines=file.readlines()
count=0
for line in lines:
count+=len(line.split(' '))
#2.使用map函式和reduce函式統計,代碼如下
from functools import reduce
from operator import add
file=open("/home/camel/Repos/spark/README.md")
lines=file.readlines()
count =reduce(add,map(lambda line:len(line.split(' ')),lines))
Spark統計一個文本單詞的思路跟Python中使用map函式和reduce函式的思路是一致的,具體代碼如下:
logFile='/home/hadoop/data/README.md'
logData = sc.textFile(logFile).cache() # 資料快取
numAs = logData.filter(lambda s: 'a' in s).count() # 元素過濾
numBs = logData.filter(lambda s: 'b' in s).count()
print("Lines with a:%i,lines with b: %i" % (numAs, numBs))

RDD算子-轉換和動作
作用于RDD上的Operation分為轉換(transformantion)和動作(action), Spark中的所有“轉換”都是惰性的,在執行“轉換”操作,并不會提交Job,只有在執行“動作”操作,所有operation才會被提交到cluster中真正的被執行,這樣可以大大提升系統的性能,
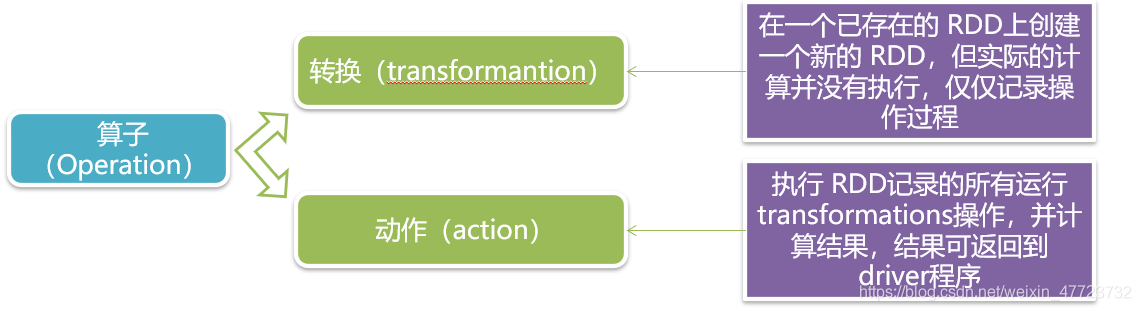
RDD算子(主要操作)
RDD擁有的操作比MR豐富的多,不僅僅包括Map、Reduce操作,還包括filter、sort、join、save、count等操作,所以Spark比MR更容易方便完成更復雜的任務,

轉換操作 map
map 轉換算子與Python中的map函式類似,該方法是將指定的函式作用在RDD的每個磁區的每個元素上,其實就是我們Python語法,只是在Python里面可能對這一方面的語法沒有過于的要求,用法如下:
rdd = sc.parallelize(["b", "a", "c"])
a=rdd.map(lambda x: (x, 1)).collect()
print(a)

轉換操作 flatMap
flatMap 操作和map操作有點類似,flatMap轉換首先將map函式應用于該RDD的所有元素,然后將結果平坦化(可以理解為將型別為元組的元素逐個放出來),從而回傳新的RDD,用法如下:
rdd = sc.parallelize([2, 3, 4])
a=rdd.map(lambda x: [(x, x), (x, x)]).collect()
b=rdd.flatMap(lambda x: [(x, x), (x, x)]).collect()
print(a)
print(b)

我們發現有點不一樣,一個回傳的是串列嵌套串列,一個是串列里面嵌套元組
轉換操作 filter
filter 轉換算子與Python中的filter函式類似,該方法是用指定的函式作為過濾條件,在RDD的所有磁區中篩選出符合條件的元素,用法如下:
rdd = sc.parallelize([1, 2, 3, 4, 5])
a=rdd.filter(lambda x: x % 2 == 0).collect()
print(a)
這里按照演算法進行篩選出偶數,并回傳一個串列集
轉換操作 union
union 轉換算子與Python中的集合中的union函式類似,該方法是對一個RDD和引數RDD求并集后,回傳一個新的RDD,只不過這里的union不會去重,用法如下:
rdd1 = sc.parallelize([1, 2, 3, 4])
rdd2 = sc.parallelize([3, 4, 5, 6])
print(rdd1.union(rdd2).collect())
轉換操作 intersection
intersection 轉換算子與Python中的集合中的intersection函式類似,該方法是對一個RDD和引數RDD求交集后,回傳一個新的RDD,用法如下:
a=rdd1 = sc.parallelize([1, 2, 3, 4])
b=rdd2 = sc.parallelize([3, 4, 5, 6])
c=rdd1.intersection(rdd2).collect()
print(c) 
轉換操作 distinct
distinct 轉換算子有點類似于SQL陳述句中的distinct,或者可以理解為將一個Python串列轉成集合(set(a_list)), distinct在RDD中回傳包含不同元素的新RDD,用法如下:
rdd2 = sc.parallelize([3, 4, 5, 6, 3, 4])
a=rdd2.distinct().collect()
print(a)
轉換操作 sortBy
sortBy 轉換算子與Python中的sort函式類似,該方法是對一個RDD和根據指定的key進行排序,回傳一個新的RDD,默認是升序排列,如果要降序排列,則添加引數ascending=False,用法如下:
tmp = [("a", 1), ("b", 2), ("1", 3), ("d", 4), ("2", 5)]
a=sc.parallelize(tmp).sortBy(lambda x: x[0]).collect()
b=sc.parallelize(tmp).sortBy(lambda x: x[1]).collect()
c=sc.parallelize(tmp).sortBy(lambda x: x[1], ascending=False).collect()
print(a)
print(b)
print(c)
注意我們在進行排序的時候,針對一個鍵值對的型別進行排序,我我們的思想就是就是將一個串列里面的元組進行RDD轉換,最終利用lambda函式進行排序,得到我們需要的結果,默認是TRUE:從小到大
這里給出一個問題?如果是一個單純的一維陣列,我們需要去排序又該如何去做,答案是sort即可!語法參考Python即可
轉換操作 glom
glom 轉換算子回傳通過將每個磁區中的所有元素合并到串列中得到新的RDD,用法如下:
data = [1, 2, 3, 4, 5, 6, 7, 8, 9]
rdd = sc.parallelize(data, 4)
rdd = rdd.glom()
a=rdd.collect()
print(a)
這里我們來看,首先分了四個區,那么一個區又該容納多少個元素,這個是需要我們考慮的嗎?顯然不用嗎,系統會根據具體的元素數量,根據特定的演算法組合,結合出最佳的組合串列,
比如這種就很明顯了,10個元素,分成5個區,自動給每個區添加2個元素
data = [1, 2, 3, 4, 5, 6, 7, 8, 9,10]
rdd = sc.parallelize(data, 5)
rdd = rdd.glom()
a=rdd.collect()
print(a)

轉換操作 mapPartitions
mapPartitions 操作類似于map操作,只不過map是作用于每一個元素,mapPartitions是作用于每一個磁區,用法如下:
rdd = sc.parallelize([1, 2, 3, 4], 2)
a=rdd.glom().collect()
def f(iterator): yield sum(iterator)
b=rdd.mapPartitions(f).collect()
print(a)
print(b)
在mapPartitions中,f函式接收到的引數為每個磁區的迭代器,回傳值為求和操作,故回傳值3,7分別為每個磁區的和,
轉換操作 mapPartitionsWithIndex
mapPartitionsWithIndex 類似于mapPartitions算子,區別在于mapPartitionsWithIndex中傳入的函式可接收兩個引數,第一個引數為磁區編號,第二個為對應磁區的元素組成的迭代器,回傳值型別為迭代器(生成器),這個算子可以回傳每個磁區的磁區編號和元素,用法如下:
rdd = sc.parallelize([1, 2, 3, 4], 2)
a=rdd.glom().collect()
def f(splitIndex, iterator): yield (splitIndex, list(iterator))
b=rdd.mapPartitionsWithIndex(f).collect()
print(b)
動作操作
動作操作 collect
collect 回傳一個包含RDD的所有元素的list,是在測驗代碼時最常用的動作算子,類似于Python中print函式的作用,寫法如下:
sc.parallelize([1, 2, 3, 4, 5]).collect()但需要注意的是,在使用這個算子時需要保證這個回傳結果比較小,因為這個算子相當于將 RDD 的所有元素收集到 driver 的客戶端的記憶體中,如果回傳結果比較大,可將結果保存在磁盤中的方式,
動作操作 reduce
reduce 有點類似于Python中的reduce函式,可以通過指定的聚合方法來對RDD中元素進行聚合,寫法如下:
from operator import add
a=sc.parallelize([1, 2, 3, 4, 5]).reduce(add)
b=sc.parallelize((2 for _ in range(10))).map(lambda x: 1).cache().reduce(add)
print(a)
print(b)
這個語法如果是對Python不是特別熟悉的可能看不懂,首先那一個回圈就是產生10個序列,這個序列被后面的map(lambda 賦值了1)一次疊加,計算出總和:10
動作操作 count
count 有點類似于Python中的len函式,count回傳RDD中的元素個數,寫法如下:
sc.parallelize([1, 2, 5, 3]).count()動作操作 take
take(n) 回傳RDD的前n個元素,用法如下:
sc.parallelize([1,2,5,3,6,7,8,9,10],3).take(4)
動作操作 first
first 回傳RDD的第一個值,用法如下:
sc.parallelize([1,2,5,3,6,7,8,9,10],3).first()
動作操作 max
max 回傳RDD的最大值,用法如下:
sc.parallelize([1,2,5,3,6,7,8,9,10],3).max()
動作操作 top
top(num) 回傳RDD中元素的前n個最大值,用法如下:
sc.parallelize([1,2,3,4,6,7,8]).top(3)
動作操作 saveAsTextFile
saveAsTextFile 將RDD中的元素以字串的格式存盤在檔案系統中,寫法如下:
rdd = sc.parallelize((1 for _ in range(50)))
rdd.saveAsTextFile("file:///home/hadoop/data/test01")
print("ok!")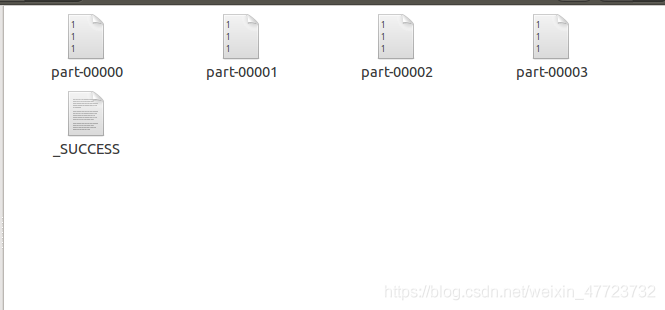
這里隨機產生的50個元素,被轉換為RDD,但是我們保存為檔案的時候,它自動就磁區了,變成了四個檔案,每個檔案12個元素,
動作操作 foreach
foreach( f)遍歷RDD的每個元素,并執行f函式操作,與map算子十分類似,區別在于foreach算子無回傳值,而map算子有回傳值,由于無回傳值,特別適合用于將資料寫入資料庫,存盤在檔案中的操作,用法如下:
rdd = sc.parallelize([3, 4, 5])
a=rdd.foreach(lambda x: print(x))
print(a)
動作操作 foreachPartition
foreachPartition ( f)遍歷RDD的每個磁區,針對每個磁區執行f函式操作,可類比mapPartitions(),用法如下:
rdd = sc.parallelize([3, 4, 5, 6, 7], 3) # 指定3個磁區
a=rdd.foreachPartition(lambda x: print(list(x))) # 將磁區中的元素轉成串列列印出來
print(a)PairRDD
?Spark為包含鍵值對(key-value)型別的RDD提供了一些專有的操作,這些RDD被稱為PairRDD,
?鍵值對RDD是一種常見的資料型別,具有廣泛的應用,像聚合計算等,
?PairRDD提供了并行操作各個鍵或跨節點重新進行資料分組的操作介面,
轉換操作 mapValues
mapValues 在不改變原有Key鍵的基礎上,對Key-Value結構RDD的Vaule值進行一個map操作,磁區保持不變,示例代碼如下:
a = [("a", 1), ("b", 2),("c", 3)]
a_rdd = sc.parallelize(a)
b=a_rdd.mapValues(lambda x: x * 10).collect()
c=a_rdd.mapValues(lambda x: (x, 1)).collect()
print(b)
print(c)
轉換操作 flatMapValues
flatMapValues 對Key-Value結構的RDD先執行mapValue操作,再執行壓平的操作,類似map與flatMap的區別,示例代碼如下:
a = [("a", 1), ("b", 2),("c", 3)]
a_rdd = sc.parallelize(a)
b=a_rdd.mapValues(lambda x: (x, 1)).collect()
c=a_rdd.flatMapValues(lambda x: (x, 1)).collect()
print(b)
print(c)一個是未壓平,一個是壓平后的
轉換操作 groupByKey
groupByKey 是將Pair RDD中的相同Key的值放一個序列中,即根據key值進行分組,示例代碼:
rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
a=rdd.groupByKey().collectAsMap()
print(a) 
我們發現是一個序列,并沒有顯示它的值 ,怎么辦?看下面操作:
上述結果回傳的是一個字典,字典的value是一個可迭代物件,這樣看不好理解,可以先使用mapValues將其元素轉換為list,再用collectAsMap看結果:
rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
a=rdd.groupByKey().collectAsMap()
print(a)
b=rdd.groupByKey().mapValues(list).collectAsMap()
print(b) 轉換操作 reduceByKey
轉換操作 reduceByKey
reduceByKey 先根據Key進行分組,再對分組內的元素的Value進行reduce操作 ,示例代碼如下:
rdd = sc.parallelize([("a", 1), ("b", 3), ("a", 1)])
a=rdd.reduceByKey(lambda x, y:x+y).collectAsMap()
print(a)這個在我們進行成績統計的時候,可以做該相關操作,比如同一個學科的平均分我們就可以,按照這個分組來顯示不同的學科的成績,同時我們還可以用其他的操作來解決我們日常的問題

轉換操作 sortByKey
sortByKey 對原RDD根據Key進行排序,回傳新的RDD,示例代碼如下:
rdd = sc.parallelize([("a", 1), ("b", 3), ("a", 1), ("c", 2) ])
a=rdd.sortByKey().collectAsMap()
print(a)
轉換操作 partitionBy
partitionBy 可以針對Key-Value結構的RDD重新磁區,采用默認的Hash磁區,用法如下:
>>> a = [("a", 1), ("b", 2), ("c", 3), ("d", 4)]
>>> a_rdd = sc.parallelize(a, 2) # 創建RDD的時候指定2個磁區
>>> a_rdd.glom().collect()
[[('a', 1), ('b', 2)], [('c', 3), ('d', 4)]]
>>> a_rdd = a_rdd.partitionBy(3) # 重新磁區,分為3個區
>>> a_rdd.glom().collect()
[[('d', 4)], [('b', 2)], [('a', 1), ('c', 3)]]
轉換操作 keys
keys 回傳一個新的RDD,元素為每個原RDD的所有key,示例代碼:
>>> rdd = sc.parallelize([("a", 1), ("b", 3), ("a", 1), (“c", 2) ])
>>> rdd.keys().collect()
['a', 'b', 'a', 'c']
轉換操作 values
values 回傳一個新的RDD,元素為每個原RDD的所有value,示例代碼:
>>> rdd = sc.parallelize([("a", 1), ("b", 3), ("a", 1), (“c", 2) ])
>>> rdd.keys().collect()
[1, 3, 1, 2]
轉換操作 join
join 與SQL中的join含義一致,根據資料的Key鍵進行連接,示例代碼:
a = sc.parallelize([("a", 1), ("b", 2)])
b = sc.parallelize([("b", 3), ("c", 4)])
c=a.join(b).collect()
print(c)

轉換操作 leftOuterJoin
leftOuterJoin 左外連接,與SQL中的leftJoin含義一致,示例代碼:
>>> a = sc.parallelize([("a", 1), ("b", 2)])
>>> b = sc.parallelize([("b", 3), ("c", 4)])
>>> a.leftOuterJoin(b).collect()
[('b', (2, 3)), ('a', (1, None))]
轉換操作 rightOuterJoin
rightOuterJoin 右外連接,與SQL中的rightOuterJoin含義一致,示例代碼:
>>> a = sc.parallelize([("a", 1), ("b", 2)])
>>> b = sc.parallelize([("b", 3), ("c", 4)])
>>> a.rightOuterJoin(b).collect()
[('b', (2, 3)), ('c', (None, 4))]
動作操作 collectAsMap
collectAsMap 與collect算子相似,collectAsMap算子是將Kev-Value結構的RDD收集到driver端,并回傳成一個字典,有相同鍵會被覆寫,示例代碼:
rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
a=rdd.collectAsMap()
print(a)

動作操作 countByKey
countByKey 和count函式類似,countByKey的作用是統計每個Key鍵的元素數,示例代碼:
>>> rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
>>> rdd.countByKey()
defaultdict(<class 'int'>, {'a': 2, 'b': 1})
>>> rdd.countByKey().items()
[('a', 2), ('b', 1)]
共享變數
閉包問題
累加器是一個類似于rdd的變數,只不過累加器是一個全域的共享變數,累加器可以完成對資訊的聚合操作,在學習累加器之前,我們先來看一個使用Spark做累加的例子,代碼如下:
sum = 0
def fn1(x):
global sum
sum = sum + x
a_rdd = sc.parallelize([1, 2, 3, 4, 5])
a_rdd.foreach(fn1)
print(sum) # 得到的sum是0,而不是元素的累加和

?上述程式得到的結果并不是我們所期望的,sum是在foreach函式外部定義的,也就是在driver程式中定義,而foreach函式是屬于rdd物件的,rdd函式的執行位置是各個worker節點(或者說worker行程),該代碼段是在driver節點上(或者說driver行程上)執行的,所以當counter變數在driver中定義,被在rdd中使用的時候,出現了變數的“跨域”問題,也就是閉包問題,
?對于上面程式中的sum變數,由于在代碼塊和在rdd物件的foreach函式是屬于不同“閉包”的,所以,傳進foreach中的sum是一個副本,初始值都為0,foreach中疊加的是sum的副本,不管副本如何變化,都不會影響到代碼塊中的sum,所以最終列印出來的sum為0,
累加器 Accumulator
累加器是一個全域的共享變數,累加器可以很好地解決上述程式的閉包問題,使用累加器完成相同的功能,代碼如下
sum = sc.accumulator(0) # 創建一個累加器,初值為0
def fn1(x):
global sum
sum += x # 注意這里不能是 sum=sum+x,因為+=是原地操作,+是需要兩個變數型別一致
a_rdd = sc.parallelize([1, 2, 3, 4, 5])
a_rdd.foreach(fn1)
print(sum.value) # sum.value可以獲取累加器的值,此時列印輸出的是15

?累加器是一個write-only的變數,作業節點worker中的task無法讀取這個值,只能在驅動程式中使用value方法來讀取累加器的值,
廣播變數 Broadcast
廣播變數和累加器類似,也是一個共享變數,廣播變數能夠以一種更有效率的方式將一個大資料量輸入集合的副本分配給每個節點,
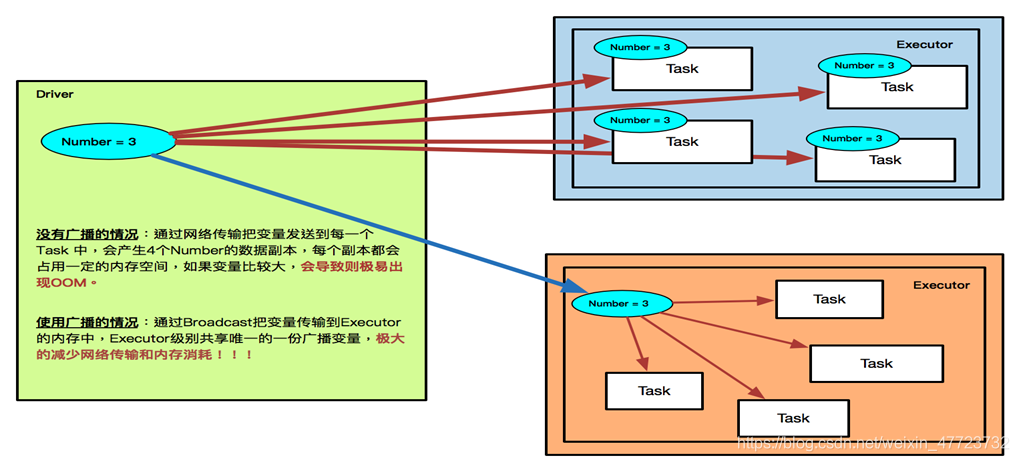
廣播變數示例
SparkContext物件的broadcast方法可以創建廣播變數,廣播變數的value屬性可以獲取該廣播變數的值,unpersist方法可以在執行程式上洗掉此廣播的快取副本,destroy方法可以銷毀廣播變數,一旦廣播變數被銷毀,就不能再使用了,示例代碼如下:
>>> b = sc.broadcast(10) # 創建一個廣播物件
>>> b.value # 獲取廣播物件的值
10
>>> sc.parallelize([1, 2, 3, 4, 5]).map(lambda x: x * b.value).collect()
[10, 20, 30, 40, 50]
>>> b.destroy() # 銷毀廣播變數,銷毀后就不能訪問它的value了
>>> b.value # 但是pyspark中還是能訪問到這個值,這是pyspark的問題,如果是scala確實是無法訪問它的值了
10
>>> sc.parallelize([1, 2, 3, 4, 5]).map(lambda x: x * b.value).collect() # task中確實無法訪問該廣播變數的值了
廣播變數通過兩個方面提高資料共享效率:
1.集群中每個節點(物理機器)只有一個副本,默認的閉包是每個任務一個副本;
2.廣播傳輸是通過BT下載模式實作的,也就是P2P下載,在集群多的情況下,可以極大的提高資料傳輸速率,廣播變數修改后,不會反饋到其他節點,
RDD依賴關系
依賴關系

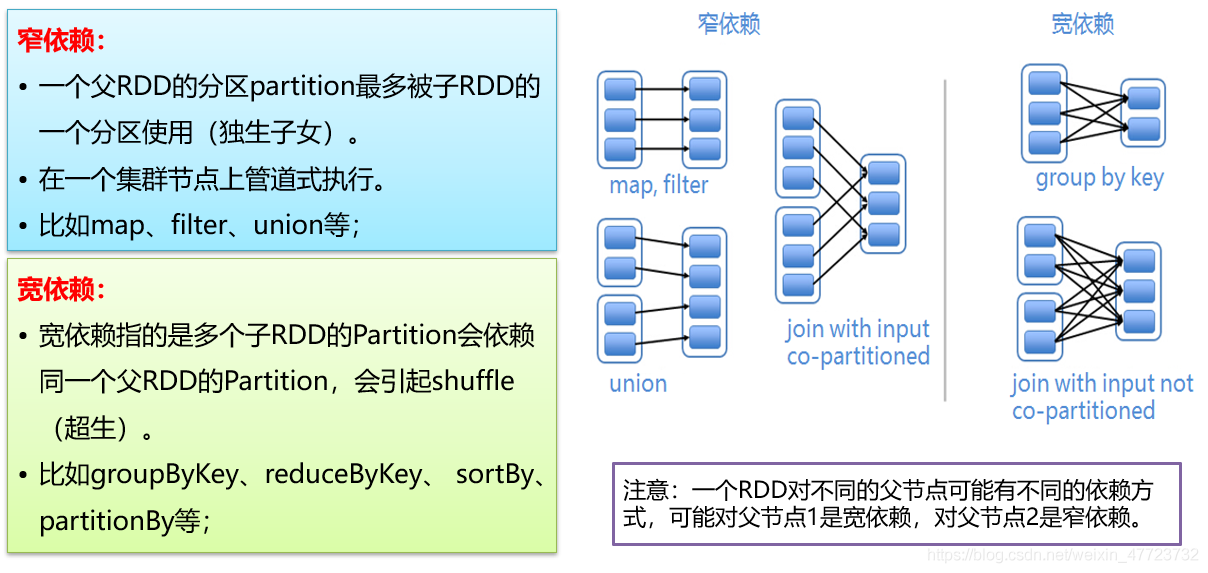

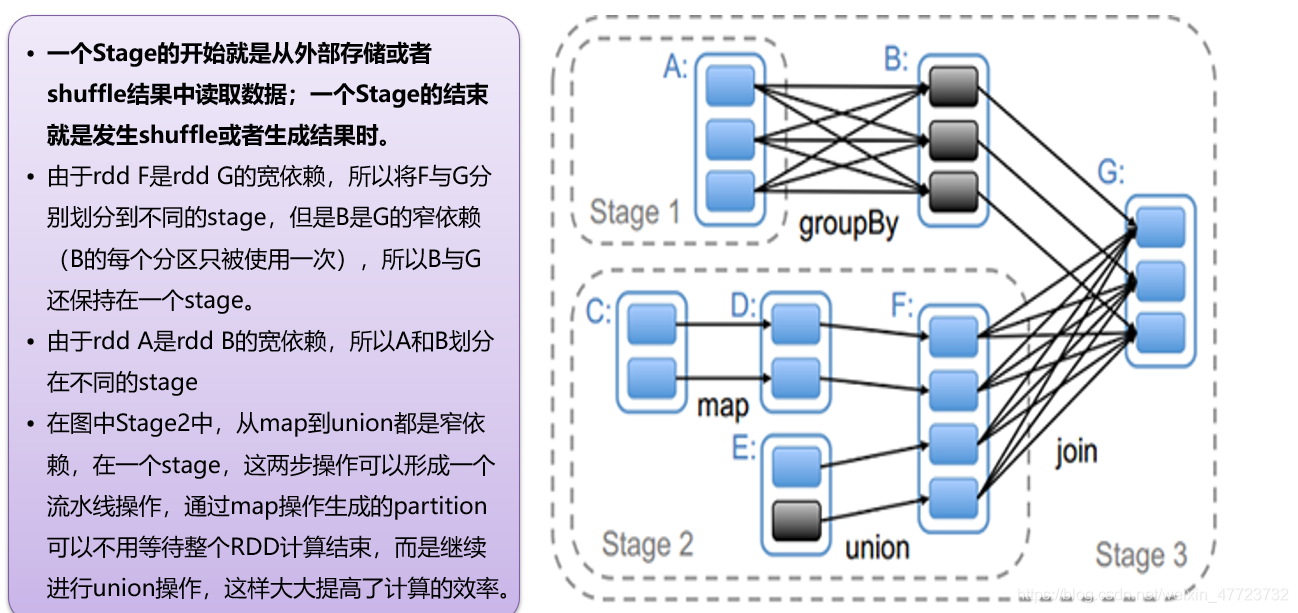
Spark里的每一個轉換操作都會生成一個新的RDD,RDD之間連一條邊,最后這些RDD和他們之間的邊組成一個有向無環圖DAG(Directed Acyclic Graph),
有了計算的DAG圖,Spark內核下一步的任務就是根據DAG圖將計算劃分成任務集,也就是Stage,這樣可以將任務提交到計算節點進行真正的計算,
RDD的持久化
Spark可以對RDD進行持久化操作(即將RDD快取到記憶體中或者磁盤上),當持久化一個 RDD 時,每個節點的其它磁區都可以使用該RDD在記憶體中進行計算,在該資料上的其他 action 操作將直接使用記憶體中的資料,這樣會讓以后的 action 操作計算速度加快(通常運行速度會加速 10 倍),
我們可以使用 persist方法或 cache方法進行持久化,persist方法可以持久化一個RDD在記憶體或磁盤中,支持設定持久化級別StorageLevel;cache方法僅快取到記憶體,本質上是persist(MEMORY_ONLY)的別名,
持久化根據是否使用記憶體,是否在記憶體不足時將RDD丟棄到磁盤,是否以特定于JAVA的序列化格式將資料保留在記憶體中,以及是否在多個節點上復制RDD磁區等情況,又可以劃分為11個持久化存盤等級,這11等級在pyspark.storagelevel.StorageLevel類中定義,
| StorageLevel型別 | 型別描述 | 對應的useDisk, useMemory, deserialized, off_heap, replication |
| MEMORY_ONLY | (默認級別)將RDD以JAVA物件的形式保存到JVM記憶體,如果分片太大,記憶體快取不下,就不快取 | StorageLevel(False, True, False, False, 1) |
| MEMORY_ONLY_2 | (默認級別)將RDD以JAVA物件的形式保存到JVM記憶體,如果分片太大,記憶體快取不下,就不快取,將磁區復制到兩個集群節點上 | StorageLevel(False, True, False, False, 2) |
| MEMORY_ONLY_SER | 將RDD以序列化的JAVA物件形式保存到記憶體 | StorageLevel(False, True, False, False, 1) |
| MEMORY_ONLY_SER_2 | 將RDD以序列化的JAVA物件形式保存到記憶體,將磁區復制到兩個集群節點上 | StorageLevel(False, True, False, False, 2) |
| DISK_ONLY | 將RDD持久化到硬碟 | StorageLevel(True, False, False, False, 1) |
| DISK_ONLY_2 | 將RDD持久化到硬碟,將磁區復制到兩個集群節點上 | StorageLevel(True, False, False, False, 2) |
|
MEMORY_AND_DISK | 將RDD資料集以JAVA物件的形式保存到JVM記憶體中,如果分片太大不能保存到記憶體中,則保存到磁盤上,下次用時重新從磁盤讀取 | StorageLevel(True, True, False, False, 1) |
|
MEMORY_AND_DISK_2 | 將RDD資料集以JAVA物件的形式保存到JVM記憶體中,如果分片太大不能保存到記憶體中,則保存到磁盤上,下次用時重新從磁盤讀取,并將磁區復制到兩個集群節點上 | StorageLevel(True, True, False, False, 2)
|
|
MEMORY_AND_DISK_SER | 與MEMORY_ONLY_SER類似,但當分片太大,不能保存到記憶體中,會將其保存到磁盤中 | StorageLevel(True, True, False, False, 1) |
|
MEMORY_AND_DISK_SER_2 | 與MEMORY_ONLY_SER類似,但當分片太大,不能保存到記憶體中,會將其保存到磁盤中,將磁區復制到兩個集群節點上 | StorageLevel(True, True, False, False, 2) |
| OFF_HEAP | 是否利用java unsafe API實作的記憶體管理,RDD實際被保存到Tachyon | StorageLevel(True, True, True, False, 1) |
注意:表中useDisk使用磁盤, useMemory使用記憶體, deserialized是否以特定于JAVA的序列化格式將資料保留在記憶體中,off_heap是否利用java unsafe API實作的記憶體管理, replication備份的節點數,
RDD的持久化可以使用persist方法和cache方法,cache方法只能快取在記憶體中, persist方法可以快取在磁盤上或者記憶體中,is_cached屬性可以查看當前RDD的持久化狀態,或者使用getStorageLevel方法獲取當前RDD的持久化狀態, unpersist方法可以解除RDD的持久化,示例代碼如下,
>>> from pyspark.storagelevel import StorageLevel # 必須先引入StorageLevel這個類
>>> rdd = sc.parallelize(["b", "a", "c"])
>>> rdd.persist(StorageLevel.MEMORY_ONLY) # 使用persist方法將RDD持久化到記憶體中
ParallelCollectionRDD[27] at parallelize at PythonRDD.scala:194
>>> rdd.is_cached # 查看RDD的持久化狀態
True
>>> rdd.unpersist() # 解除RDD的持久化
ParallelCollectionRDD[27] at parallelize at PythonRDD.scala:194
>>> rdd.is_cached # 查看RDD的持久化狀態
False
>>> rdd.persist(StorageLevel.DISK_ONLY) ) # 使用persist方法將RDD持久化到磁盤上
ParallelCollectionRDD[27] at parallelize at PythonRDD.scala:194



本期的RDD算子就介紹完了,有的同學肯定會有所疑問,如何操作在日常的開發中,其實這個就我們學Python的字串、元組、串列、集合、函式、還有一系列的語法差不多
打好基礎才可以做好后面的作業
每文一語
在對的時間遇見對的你,所言之語皆是春風化雨...........
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/271551.html
標籤:其他
上一篇:[STL]容器小結+函式物件+謂詞+內建函式物件+函式物件配接器+演算法(匯總)
下一篇:從零開始的編程學習