這篇文章用到了transformer來對視頻幀進行時序資訊探索,網路結構是基于原型網路進行改進的,代碼已開源,
paper: https://arxiv.org/abs/2101.06184
code: https://github.com/tobyperrett/trx
Motivation
在該文章之前,小樣本學習方法都是將query視頻和support集視頻中最好的 視頻相比,或是和所有視頻匹配,最后取平均,該方法帶來的問題是,同一個動作不同的視頻有著不同的長度和速度,因此此種匹配方式不太符合視頻的特點,因此作者提出了TRX來解決該問題,同時作者還探索了視頻的時序關系,
方法
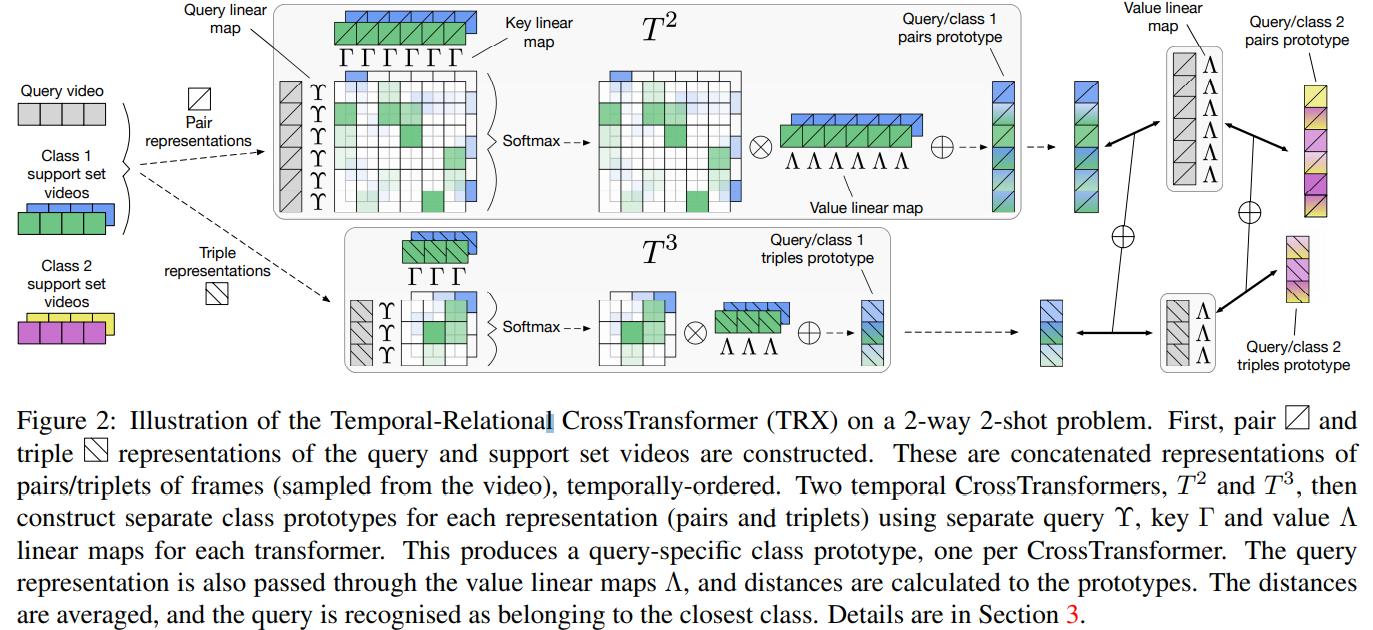
首先對視頻進行稀疏采樣,每個視頻采樣8幀,使用resnet50提取幀特征,得到一個8×2048的特征,因為動作在不同時刻有著不同的外觀、很難用單幀表示,因此需要用至少兩幀表示(論文中作者通過實驗驗證了選取2幀和3幀效果最好),
接來下先介紹取2幀的操作,公式(1)中Φ是一個卷積操作,將C×W×3的特征轉換為D維特征(此處D=2048),選取兩幀特征,進行拼接得到動作
Q
p
{Q_p}
Qp?,
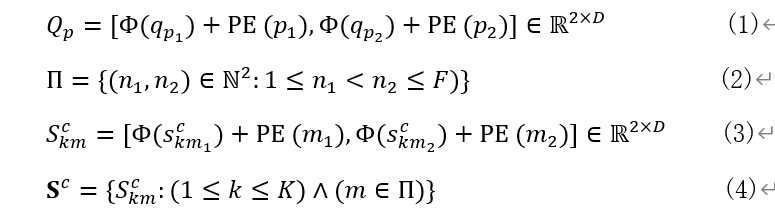
公式(2)、(3)、(4)描述了如何構建support集的動作表征,對于第c類中的第k個視頻,挑選任意兩幀,計算
S
k
m
c
{S_{km}^c}
Skmc?作為動作特征,將第c類動作中的k個視頻的
S
k
m
c
{S_{km}^c}
Skmc?進行拼接,得到第c類動作的表征
S
c
{S^c}
Sc,
基于spatial CrossTransformer作者提出temporal CrossTransformer,前者基于影像像素塊,后者基于視頻影像對,CrossTransformer包含 Υ Υ Υ,Γ和Λ,分別將2×D的特征轉化為 d k d_k dk?維和 d v d_v dv?維,
定義query視頻和support集視頻 S k m c {S_{km}^c} Skmc?的相似度為 a k m p c {a_{kmp}^c} akmpc?,公式(6),其中L是一個標準的正則化層,對其應用一個softmax層獲得一個注意力向量 a k m p c {a_{kmp}^c} akmpc?,對 S k m c {S_{km}^c} Skmc?做一個value映射得到 v k m c {v_{km}^c} vkmc?=Λ? S k m c {S_{km}^c} Skmc?,接著將前面得到的注意力向量與其結合得到公式(8), t p c t_p^c tpc?即代表與搜索視頻p對應的第c類prototype,最后T計算查詢視頻 Q p Q_p Qp?和支持集視頻 S c S^c Sc的距離,通過公式(10)定義這二者的距離,
該程序其實和self-attention有點類似,只不過其query、key和value不是來自同一輸入,因此將其稱為cross-transformer,
Υ
Υ
Υ和Γ講特征經過線性變換后轉化為
d
k
d_k
dk?維特征,即query_key和support_key,通過點積操作求得二者之間的相似度即
a
k
m
p
c
{a_{kmp}^c}
akmpc?,Λ是將特征轉化為
d
v
d_v
dv?維,即得到query_value和support_value,query_value往后傳用于計算與prototype之間的距離,而前面求得的相似度經過softmax層轉化為分數后,作為一個注意力向量與support_value相乘,這樣便得到了query-specific prototype,最后計算歐式距離,距離最小的類即為query類別,
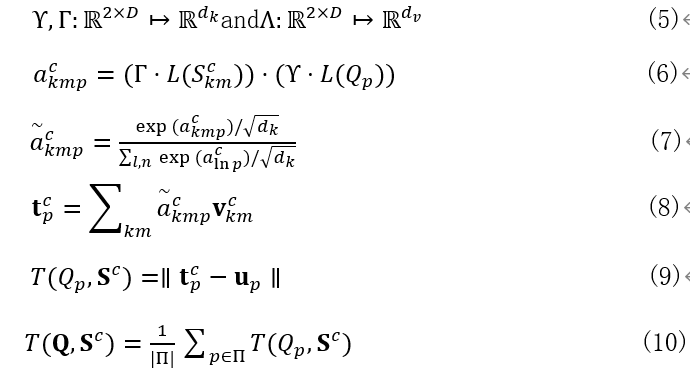
訓練時,每個query-class距離取負作為損失進行傳播,在預測時,選取最小距離的類作為query視頻的類,即
a
r
g
?
m
i
n
T
(
Q
p
,
S
c
)
arg? minT(Q_p,S^c)
arg?minT(Qp?,Sc)
Temporal Relational CrossTransformers
前面講的是從query視頻中選取一對將其與support視頻比較,但是想要找到一對能最好的表示該視頻動作是一件非常困哪的任務,因為作者提出構建多個隨機選取的幀對來進行比較,同時作者通過考慮任意長度的有序子序列將temporal crossTransformer擴展到temporal Relational CrossTransformer,流程和temporal crossTransformer是一樣的,不過考慮了3幀、4幀等情況,
Π
ω
=
{
(
n
1
,
…
,
n
ω
)
∈
N
ω
:
?
i
(
1
≤
n
i
<
n
i
+
1
≤
F
)
}
\Pi^{\omega}=\left\{\left(n_{1}, \ldots, n_{\omega}\right) \in \mathbb{N}^{\omega}: \forall i\left(1 \leq n_{i}<n_{i+1} \leq F\right)\right\}
Πω={(n1?,…,nω?)∈Nω:?i(1≤ni?<ni+1?≤F)} (11)
Q
p
ω
=
[
Φ
(
q
p
1
)
+
PE
?
(
p
1
)
,
…
,
Φ
(
q
p
ω
)
+
PE
?
(
p
ω
)
]
∈
R
ω
×
D
Q_{p}^{\omega}=\left[\Phi\left(q_{p_{1}}\right)+\operatorname{PE}\left(p_{1}\right), \ldots, \Phi\left(q_{p_{\omega}}\right)+\operatorname{PE}\left(p_{\omega}\right)\right] \in \mathbb{R}^{\omega \times D}
Qpω?=[Φ(qp1??)+PE(p1?),…,Φ(qpω??)+PE(pω?)]∈Rω×D (12)
Υ
ω
,
Γ
ω
:
R
ω
×
D
?
R
d
k
\Upsilon^{\omega}, \Gamma^{\omega}: \mathbb{R}^{\omega \times D} \mapsto \mathbb{R}^{d_{k}}
Υω,Γω:Rω×D?Rdk? and
Λ
ω
:
R
ω
×
D
?
R
d
v
\Lambda^{\omega}: \mathbb{R}^{\omega \times D} \mapsto \mathbb{R}^{d_{v}}
Λω:Rω×D?Rdv? (13)
T
Ω
(
Q
,
S
c
)
=
∑
ω
∈
Ω
T
ω
(
Q
ω
,
S
c
ω
)
\mathbf{T}^{\Omega}\left(Q, \mathbf{S}^{c}\right)=\sum_{\omega \in \Omega} T^{\omega}\left(\mathbf{Q}^{\omega}, \mathbf{S}^{c \omega}\right)
TΩ(Q,Sc)=∑ω∈Ω?Tω(Qω,Scω) (14)
實驗
作者在四個資料集上進行了實驗,也是行為識別里非常常用的四個資料集:UCF101、HMDB51、Kinectics和Something to Something,
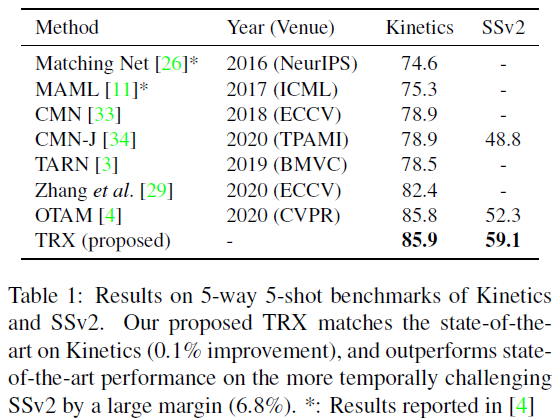
結論
1、Trx采用兩幀或3幀特征進行拼接表示動作特征;將簡單的拼接操作使用類似卷積等網路提取出兩幀之間的運動資訊;
2、損失函式簡單地采用的是query到prototype的距離乘以-1,在loss設計上進行改進,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/271882.html
標籤:其他