在閱讀《Redis設計與實作》8.2字串物件中,當字串長度小于32位元組,字串物件將使用emstr編碼,大于32位元組,字串使用raw,

驗證:當小于44個位元組的時候使用embstr,大于44的時候位raw
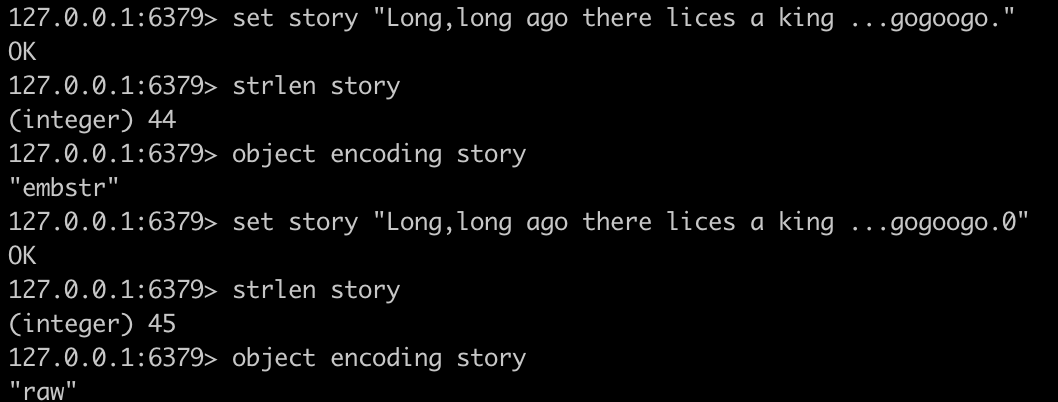
原始碼創建stringObject的邏輯
在redis原始碼中3.0、3.2以及4.0中,代碼創建的邏輯是與REDIS_ENCODING_EMBSTR_SIZE_LIMIT 39進行比較,如果小于39的話創建的是embstr,否則位raw
#define REDIS_ENCODING_EMBSTR_SIZE_LIMIT 39
robj *createStringObject(char *ptr, size_t len) {
if (len <= REDIS_ENCODING_EMBSTR_SIZE_LIMIT)
return createEmbeddedStringObject(ptr,len);
else
return createRawStringObject(ptr,len);
}
//創建embstr
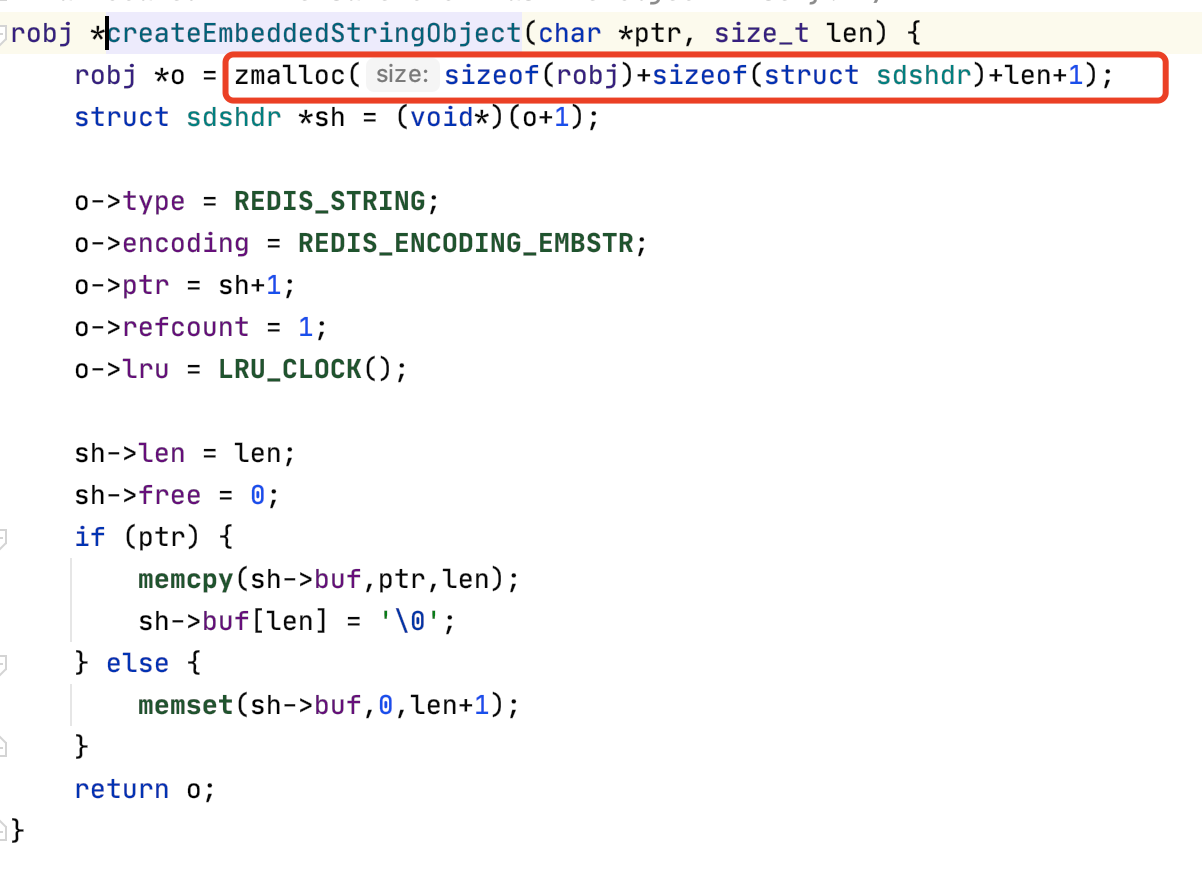
robj *createEmbeddedStringObject(char *ptr, size_t len) {
robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr)+len+1);
struct sdshdr *sh = (void*)(o+1);
o->type = REDIS_STRING;
o->encoding = REDIS_ENCODING_EMBSTR;
o->ptr = sh+1;
o->refcount = 1;
o->lru = LRU_CLOCK();
sh->len = len;
sh->free = 0;
if (ptr) {
memcpy(sh->buf,ptr,len);
sh->buf[len] = '\0';
} else {
memset(sh->buf,0,len+1);
}
return o;
}
//創建raw
robj *createObject(int type, void *ptr) {
robj *o = zmalloc(sizeof(*o));
o->type = type;
o->encoding = REDIS_ENCODING_RAW;
o->ptr = ptr;
o->refcount = 1;
/* Set the LRU to the current lruclock (minutes resolution). */
o->lru = LRU_CLOCK();
return o;
}redis使用jemalloc記憶體分配器,這個比glibc的malloc要好不少,還省記憶體,在這里可以簡單理解,jemalloc會分配8,16,32,64等位元組的記憶體,所以embstr最小分配64位元組,其中16個位元組值得是redisObject所占的位元組數,
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */
int refcount;
void *ptr;
} robj;其中sdshr中len與free這兩個變數所占用8個位元組,/0占用一個位元組,buff最多占用,64-8-16-1=39剩下的39個位元組,這個默認39就是這樣來的,
struct sdshdr {
unsigned int len;
unsigned int free;
char buf[];
};那么圖中44位的設定又是怎么一回事呢?對比分支3.0與5.0、6.0發現設定的這個值有發生了一些變化,
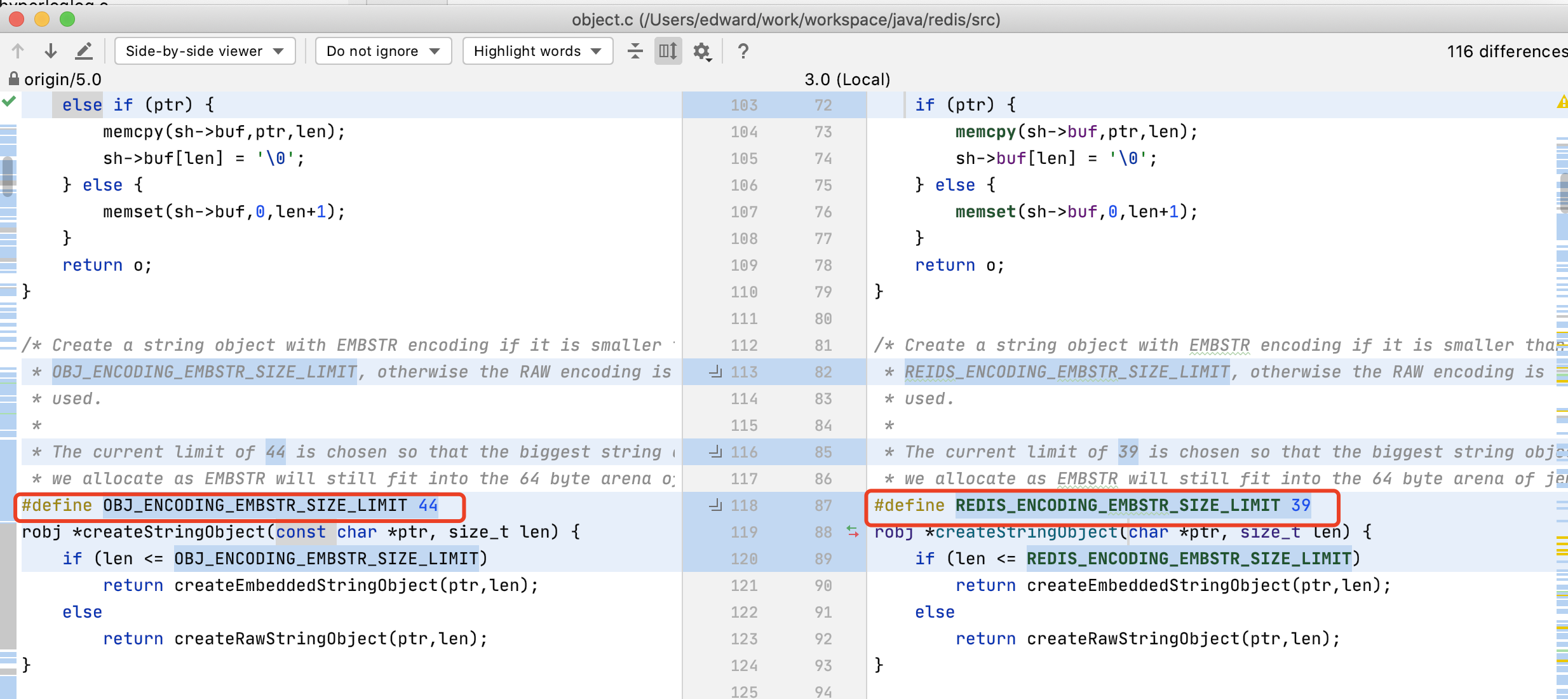
在git的redis迭代程序中commit,進行了一系列的記憶體優化,原因是sdshdr,里面的len和free記錄了這個sds的長度和空閑空間,但是這樣的處理十分粗糙,使用的unsigned int可以表示很大的范圍,但是對于很短的sds有很多的空間被浪費了(兩個unsigned int 8個位元組),而這個commit則將原來的sdshdr改成了sdshdr16,sdshdr32,sdshdr64,里面的unsigned int 變成了uint8_t,uint16_t.,,,(還加了一個char flags)這樣更加優化小sds的記憶體使用,其中將原來的8個位元組變為,uint8 len、alloc、以及char flags,總計3個位元組,由原來的8位元組縮減為3位元組,剩余的5位元組+39,所以總共是44個位元組,
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};embstr的優勢
1、embstr和raw都使用redisObject結構和sdshdr結構來表示字串物件,但是raw會分別兩次創建redisObject結構與sdshdr結構,記憶體不一定是連續的,而embstr直接創建一塊連續的記憶體
2、embstr開辟連續的記憶體可以帶來的優勢:
- 記憶體釋放是embstr只需要釋放一次,而raw需要釋放兩次
- emstr查找的更快

為什么redis小等于39位元組的字串是embstr編碼,大于39是raw編碼?
Redis的embstr與raw編碼方式不再以39位元組為界了!
《Redis設計與實作》
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/271886.html
標籤:其他
上一篇:JVM虛擬機學習系列之一(Java虛擬機的發展史和java發展重大事件)
下一篇:物聯網簡史