文章目錄
- 前言
- 語音識別原理
- 信號處理,聲學特征提取
- 識別字符,組成文本
- 聲學模型
- 語言模型
- 詞匯模型
- 語音聲學特征提取:MFCC和LogFBank演算法的原理
- 實戰一 ASR語音識別模型
- 系統的流程
- 基于HTTP協議的API介面
- 客戶端
- 未來
- 實戰二 調百度和科大訊飛API
- 實戰三 離線語音識別 Vosk
前言
首先,cv君下血本費時整理了AI在音視頻領域的大量的方向,形成本文綜述,從原理到底層演算法,到上層應用,統統透析~本系列由于綜述文章過長的原因,所以分開寫了,文章附帶大量的演算法原理+代碼實作教學,歡迎關注,一起AI,

語音識別原理

首先是語音識別和語音喚醒等任務,一聽到你就會想起科大訊飛,中國百度等平臺,由于
這兩家企業在中國語音領域占用80+市場,所以他們做得很優秀,不過由于高精技術無法開源,其他企業只得花費大量的金錢去購買其API,而無法研究語音識別等應用,導致民間語音識別發展較慢,今天我們來一飽眼福吧!
信號處理,聲學特征提取
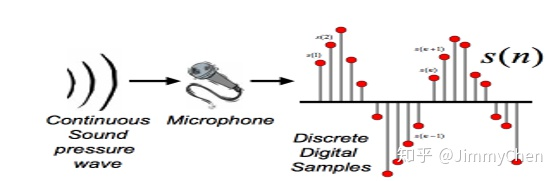
我們都知道聲音信號是連續的模擬信號,要讓計算機處理首先要轉換成離散的數字信號,進行采樣處理,正常人聽覺的頻率范圍大約在20Hz~20KHz之間,為了保證音頻不失真影響識別,同時資料又不會太大,通常的采樣率為16KHz,
語音采樣
在數字化的程序中,我們首先要判斷端頭,確定語音的開始和結束,然后要進行降噪和過濾處理(除了人聲之外,存在很多的噪音),保證讓計算機識別的是過濾后的語音資訊,獲得了離散的數字信號之后,為了進一步的處理我們還需要對音頻信號 分幀,因為離散的信號單獨計算資料量太大了,按點去處理容易出現毛刺,同時從微觀上來看一段時間內人的語音信號一般是比較平穩的,稱為 短時平穩性,所以會需要將語音信號分幀,便于處理,
我們的每一個發音,稱為一個 音素,是語音中的最小單位,
比如普通話發音中的元音,輔音,不同的發音變化是由于人口腔肌肉的變化導致的,
這種口腔肌肉運動相對于語音頻率來說是非常緩慢的,所以我們為了保證信號的短時平穩性,
分幀的長度應當小于一個音素的長度,當然也不能太小否則分幀沒有意義,
通常一幀為20~50毫秒,同時幀與幀之間有交疊冗余,避免一幀的信號在兩個端頭被削弱了影響識別精度,常見的比如 幀長為25毫秒,兩幀之間交疊15毫秒,也就是說每隔25-15=10毫秒取一幀,幀移為10毫秒,分幀完成之后,信號處理部分算是完結了,
隨后進行的就是整個程序中極為關鍵的特征提取,將原始波形進行識別并不能取得很好的識別效果,而需要進行頻域變換后提取的特征引數用于識別,常見的一種變換方法是提取MFCC特征,根據人耳的生理特性,把每一幀波形變成一個多維向量,可以簡單地理解為這個向量包含了這幀語音的內容資訊,
實際應用中,這一步有很多細節,聲學特征也不止有MFCC這一種,具體這里不講,但是各種特征提取方法的核心目的都是統一的:盡量描述語音的根本特征,盡量對資料進行壓縮,
比如下圖示例中,每一幀f1,f2,f3…轉換為了14維的特征向量,然后整個語音轉換為了14*N(N為幀數)的向量矩陣,
一幀一幀的向量如果不太直觀,還可以用下圖的頻譜圖表示語音,每一列從左到右都是一個25毫秒的塊,相比于原始聲波,從這種資料中尋找規律要容易得多,
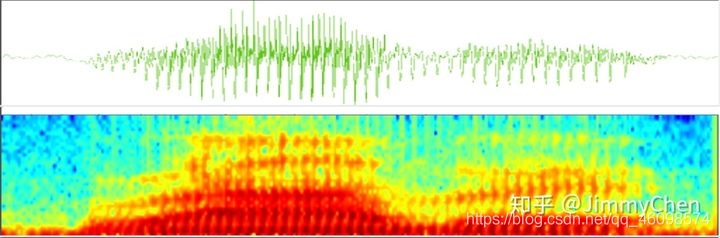
不過頻譜圖主要用作語音研究,語音識別還是需要用一幀一幀的特征向量,
識別字符,組成文本
特征提取完成之后,就進入了特征識別,字符生成環節,這部分的核心作業就是從 每一幀當中找出當前說的音素,再由多個音素組成單詞,再由單詞組成文本句子, 其中最難的當然是從每一幀中找出當前說的音素,因為我們每一幀是小于一個音素的,多個幀才能構成一個音素,如果最開始就錯了則后續很難糾正,
怎么判斷每一個幀屬于哪個音素了?最容易實作的辦法就是概率,看哪個音素的概率最大,則這個幀就屬于哪個音素,那如果每一幀有多個音素的概率相同怎么辦,畢竟這是可能的,每個人口音、語速、語氣都不同,人也很難聽清楚你說的到底是Hello還是Hallo,而我們語音識別的文本結果只有一個,不可能還讓人參與選擇進行糾正,
這時候多個音素組成單詞的統計決策,單詞組成文本的統計決策就發揮了作用,它們也是同樣的基于概率:音素概率相同的情況下,再比較組成單詞的概率,單詞組成之后再比較句子的概率,
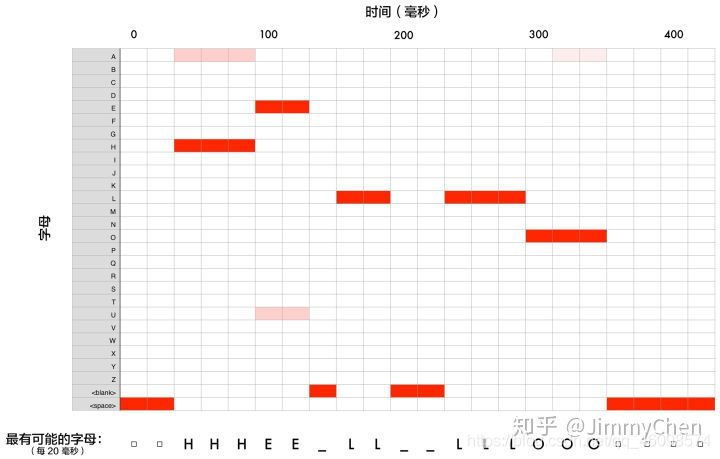
比如以上那個詞很有可能是「HHHEE_LL_LLLOOO」,但它同時認為我說的也可能是「HHHUU_LL_LLLOOO」,或者甚至是「AAAUU_LL_LLLOOO」,我們可以遵循一些步驟來整理這個輸出,首先,我們將用單個字符替換任何重復的字符:
· HHHEE_LL_LLLOOO 變為 HE_L_LO
· HHHUU_LL_LLLOOO 變為 HU_L_LO
· AAAUU_LL_LLLOOO 變為 AU_L_LO
然后,我們將洗掉所有空白:
· HE_L_LO 變為 HELLO
· HU_L_LO 變為 HULLO
· AU_L_LO 變為 AULLO
這讓我們得到三種可能的轉寫——「Hello」、「Hullo」和「Aullo」,最終根據單詞概率我們會發現Hello是最可能的,所以輸出Hello的文本,上面的例子很明確的描述怎么從幀到音素,再從音素到單詞,概率決定一切,那這些概率是怎么獲得的了?難道為了識別一種語言我們把人類幾千上百年說過的所有音素,單詞,句子都統計出來,然后再計算概率?傻子都知道這是不可能的,那怎么辦,這時我們就需要模型:
聲學模型
發聲的基本音素狀態和概率,盡量獲得不同人、不同年紀、性別、口音、語速的發聲語料,同時盡量采集多種場景安靜的,嘈雜的,遠距離的發聲語料生成聲學模型,為了達到更好的效果,針對不同的語言,不同的方言會用不同的聲學模型,在提高精度的同時降低計算量,
語言模型
單詞和陳述句的概率,使用大量的文本訓練出來,如果模型中只有兩句話“今天星期一”和“明天星期二”,那我們就只能識別出這兩句,而我們想要識別更多,只需要涵蓋足夠的語料就行,不過隨之而來的就是模型增大,計算量增大,所以我們實際應用中的模型通常是限定應用域的,同比如智能家居的,導航的,智能音箱的,個人助理的,醫療的等等,降低計算量的同時還能提高精度,
詞匯模型
針對語言模型的補充,語言詞典和不同的發音標注,比如定期更新的地名,人名,歌曲名稱,熱詞,某些領域的特殊詞匯等等,
語言模型和聲學模型可以說是語音識別中最重要的兩個部分,語音識別中一個很重要的作業就是訓練模型,有不識別的句子我們就加進去重新訓練,不過我們在訓練和計算概率時會發現一個問題,假設某條句子S出現的概率為P(S),其中單詞序列為W1,W2,W3 …, Wn
P(S) = P(W1,W2,W3 …, Wn) 展開為每個詞出現的條件概率相乘
= P(W1)·P(W2|W1)·P(W3|W1,W2)···P(Wn|W1,W2,W3 …, Wn-1)
從計算上看第一個詞的條件概率P(W1)很好計算,第二個詞P(W2|W1)在已知第一個詞的情況下,還不太麻煩,第三個詞開始變得很難了,因為涉及到三個變數W1,W2,W3,每一個詞都可能是一種語言字典的大小,到了Wn基本無法估計了,計算量太大了,
這時我們有很多簡化但是有效的方法進行計算,比如說HMM隱馬爾科夫模型Hidden Markov Model,
隱馬爾科夫模型基于了兩個最大的假設:一是內部狀態的轉移只與
上一狀態有關,另一是輸出值只與當前狀態(或當前的狀態轉移)有關,就把問題簡化了,
也就是說一個句子中某個單詞序列出現的概率只和前面的一個單詞有關,這樣計算量就被大大簡化了,
P(S) = P(W1)·P(W2|W1)·P(W3|W2)···P(Wn|Wn-1)
如上圖示例,基于隱馬爾科夫演算法生成語言模型,我們只要按照實際要求構造出對應的模型,模型中涵蓋足夠的語料,就能解決各種語音識別問題,
語音識別程序其實就是在模型的狀態網路中搜索一條最佳路徑,語音對應這條路徑的概率最大,這稱之為“解碼”,路徑搜索的演算法是一種動態規劃剪枝的演算法,稱之為Viterbi演算法,用于尋找全域最優路徑,
如此一來整個語音識別的流程就很清晰了,再來回顧以下整個步驟:
信號處理:模數轉換,識別端頭,降噪等等,信號表征:信號分幀,特征提取,向量化等等,
模式識別:尋找最優概率路徑,聲學模型識別音素,詞匯模型和語言模型識別單詞和句子,
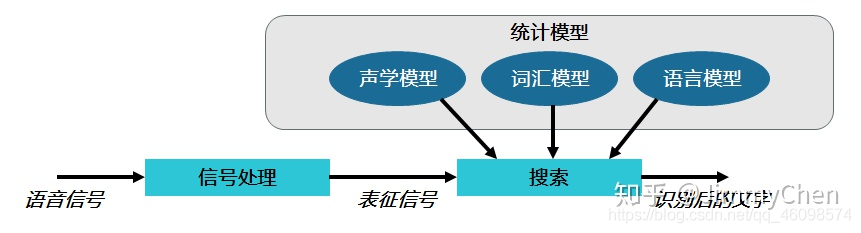 最后將語音識別成文本,
最后將語音識別成文本,
語音聲學特征提取:MFCC和LogFBank演算法的原理
幾乎任何做自動語音識別的系統,第一步就是對語音信號,進行特征的提取,通過提取語音信號的相關特征,有利于識別相關的語音資訊,并丟棄攜帶的其他不相關的所有資訊,如背景噪聲、情緒等,
我們都知道,人類說話是通過體內的發聲器產生的初始聲音,
被包括舌頭和牙齒在內的其他物體形成的聲道的形狀進行濾波,
從而產生出各種各樣的語音的,傳統的語音特征提取演算法正是基于這一點,
通過一些數字信號處理演算法,能夠更準確地包含相關的特征,
從而有助于后續的語音識別程序,常見的語音特征提取演算法有MFCC、FBank、LogFBank等,
1 MFCC
MFCC的中文全稱是“梅爾頻率倒譜系數”,這種語音特征提取演算法是這幾十年來,最常用的演算法之一,這種演算法是通過在聲音頻率中,對非線性梅爾刻度的對數能量頻譜,進行線性變換得到的[1],
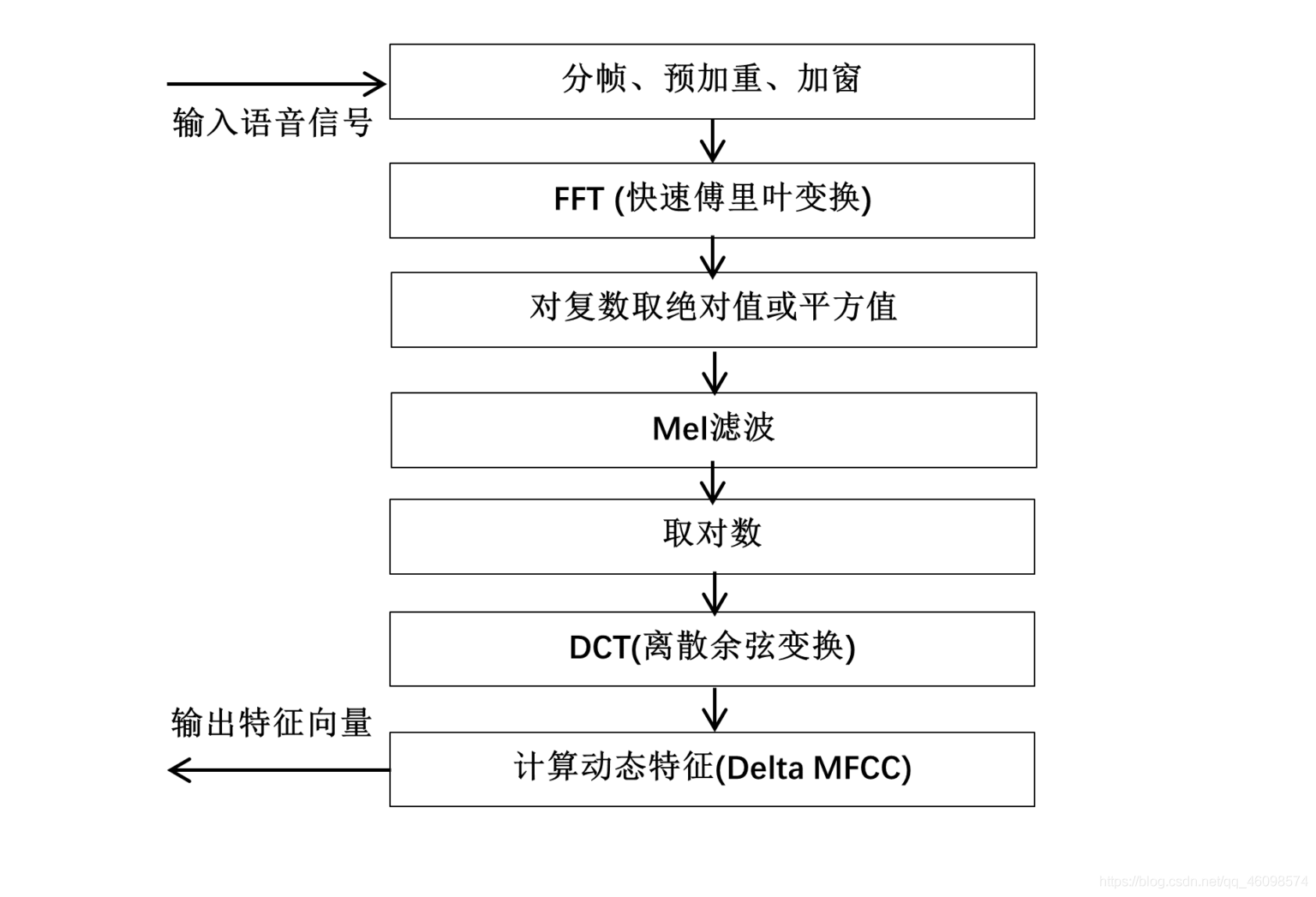
MFCC特征提取演算法的主體流程如下:
MFCC演算法流程圖1 MFCC演算法流程
1.1 分幀
由于存盤在計算機硬碟中的原始wav音頻檔案是不定長的,
我們首先需要將其按一定方法切分為固定長度的多個小片段,也就是分幀,根據語音信號變化迅速的特性,每一幀的時間長度一般取10-30毫秒,以保證一幀內有足夠多的周期,且變化不會過于劇烈,因此,更適合這種適用于分析平穩信號的傅里葉變換,由于數字音頻的采樣率不同,分幀所得的每一幀向量的維度也不同,
為了避免時間窗的邊界導致資訊遺漏的問題,因此,在對從信號中取每一幀的時間窗進行偏移的時候,幀和幀之間需要有一部分的重疊區域,這個時間窗的偏移量,我們一般取為幀長的一半,即每一步都偏移一幀的大約二分之一之后的位置,作為時間窗取下一幀的最終位置,這樣做的好處是,避免了幀與幀之間的特性變化過大,
通常來說,我們選取時間窗長度為25毫秒,時間窗的偏移量為10毫秒,
1.2 預加重
由于聲音信號從人的聲門發出后,存在12dB/倍頻程的衰減,在通過口唇輻射后,
還存在6dB/倍頻程的衰減,因而在進行快速傅里葉變換之后,
高頻信號部分中的成分較少,所以,對語音信號進行預加重操作,
其主要目的是加強語音信號的每一幀中,那些高頻部分的信號
,以提高其高頻信號的解析度,我們需要通過采用如下公式的一階高通濾波器進行預加重操作:
H(z)=1?α×z?1(1)
S(n)=S(n)?α×S(n?1)?n∈N(2)
在上式中,α是預加重的系數,其一般的取值范圍是0.9 < α < 1.0,通常取0.97,n表示當前處理的是第n幀,其中,第一個n=0的幀需要特別處理,
1.3 加窗
在之前的分幀程序中,直接將一個連續的語音信號切分為若干個片段,
會造成截斷效應產生的頻譜泄漏,加窗操作的目的是消除每個幀的短時信號在其兩
端邊緣處出現的信號不連續性問題,MFCC演算法中,選取的窗函式通常是漢
明窗,也可以使用矩形窗和漢寧窗,需要注意的是,預加重必須在加窗之前進行,
漢明窗的窗函式為:
W(n)=0.53836?0.46164×cos(2πnN?1)(0≤n≤N,n=0,1,2,…,N)(3)
加窗程序為:
S′(n)=W(n)×S(n)(4)
1.4 快速傅里葉變換
在經過上述的一系列的處理程序之后,我們得到的仍然是時域的信號,而時域中可直接獲取的語音資訊量較少,在進行進一步的語音信號特征提取時,還需要將每一幀的時域信號對應轉換到其頻域信號,對于存盤在計算機上的語音信號,我們需要使用離散的傅里葉變換,由于普通的離散傅里葉變換的計算復雜度較高,通常使用快速傅里葉變換來實作,由于MFCC演算法經過分幀之后,每一幀都是短時間內的時域信號,所以這一步也成為短時快速傅里葉變換,
P(n)=∑N?1k=0S(n)×e?j?2πknN(0<n<N)(5)
根據奈奎斯特定理,如果要再次從離散的數字信號無損地轉換到模擬信號上,
在對模擬信號進行采樣時,我們需要采用模擬信號最高頻率值的2倍以上的采樣率,
對模擬信號進行模數轉換的采樣,對于語音識別常用的16kHz采樣率音頻,
傅里葉變換之后的頻率范圍為0到8kHz之間,
1.5 計算幅度譜(對復數取模)
在完成了快速傅里葉變換之后,得到的語音特征是一個復數矩陣,
它是一個能量譜,由于能量譜中的相位譜包含的資訊量極少,
所以我們一般選擇丟棄相位譜,而保留幅度譜,
丟棄相位譜保留幅度譜的方法一般是兩種,對每一個復數求絕對值或者求平方值,
P′(n)=P2(n)???√(6)
P′(n)=P2(n)(7)
1.6 Mel濾波
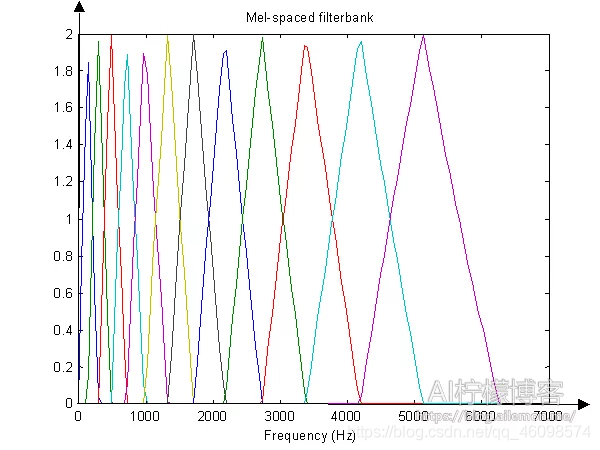
Mel濾波的程序是MFCC和fBank特征的關鍵之一,
Mel濾波器是由20個三角形帶通濾波器組成的,將線性頻率轉換為非線性分布的Mel頻率,
Mel濾波器原理圖圖2 Mel濾波器原理圖
Mel倒譜公式:
Mel(f)=2595×log10(1+f700)=1125×ln(1+f700)(8)
梅爾濾波器:
Bm[k]=?????????0k?fm?1fm?fm?1fm+1?kfm+1?fmk<fm?1或k>fm+1fm?1≤k≤fmfm≤k≤fm+1(9)
Mel濾波公式:
Em=ln(∑N?1k=0P(k)×Hm(k))(10)
經過Mel濾波之后,Em即為得到的fBank特征,
1.7 取對數
在得到上一步的fBank特征之后,由于人耳對聲音的感受是成對數值增長的,
所以需要將數值再進行一次對數運算,以模擬人耳的感受,
我們需要對縱軸通過取對數進行縮放,可以放大低能量處的能量差異,
1.8 離散余弦變換
離散余弦變換是MFCC相對于fBank所特有的一步特征提取運算,在上一步取了對數之后,我們還需要對得到的N維特征向量值,再進行一次離散余弦變換(DCT),做DCT的根本原因是,不同階數信號值之間具有一定的相關性,而我們需要去掉這種相關性,將信號再映射到低維的空間中,由于最有效的特征聚集在前12個特征里,所以在實際中,一般僅保留前12-20個結果值,通常取13個,這樣一來,就進一步壓縮了資料, 離散余弦變換公式如下:
Ci=2N??√∑Nj=1Ej×cos(π?iN?(j?0.5)),?i∈1,M
1.9 計算動態特征
上述MFCC演算法僅僅體現了MFCC的靜態特征,而其動態特征還需要使用靜態特征的差分來表示,通過將得到的動態的特征,和前一步得到的靜態特征相結合,可以有效地提高這種語音識別系統的識別性能, 差分引數的計算公式:
dt=?????????Ct+1?Ct∑Kk=1k(Ct+k?Ct?k)2∑Kk=1k2√Ct?Ct?1t<Kothert≥Q?K(12)
式中,dt是第t個一階差分值,Ct是第t個倒譜系數值,Q是倒譜系數的最大階數,K是一階差分的時間差,一般可取1或取2,二階差分則將上式的結果再代入進行計算即可,
最后,再將靜態特征和動態特征的一階、二階差分值合并起來,
當靜態特征是13維的特征向量時,合并動態特征后,總共有39維特征,
2 logfBank
logfBank特征提取演算法類似于MFCC演算法,都是基于fBank特征提取結果的基礎上,再進行一些處理的,不過logfBank跟MFCC演算法的主要區別在于,是否再進行離散余弦變換,logfBank特征提取演算法在跟上述步驟一樣得到fBank特征之后,直接做對數變換作為最終的結果,計算量相對MFCC較小,且特征的相關性較高,所以傳統的語音識別技術常常使用MFCC演算法,
隨著DNN和CNN的出現,尤其是深度學習的發展
,由于fBank以及logfBank特征之間的相關性可以更好地被神經網路利用,
以提高最終語音識別的準確率,降低WER,因此,可以省略掉離散余弦變換這一步驟,
3 總結
本文主要介紹了MFCC和LogFBank語音特征提取演算法的數學原理及計算程序方法,之后AI檸檬博客還將更新另一種語音識別特征提取演算法:語譜圖特征,敬請期待!
實戰一 ASR語音識別模型
ASRT是一套基于深度學習實作的語音識別系統,全稱為Auto Speech Recognition Tool,由AI檸檬博主開發并在GitHub上開源(GPL 3.0協議),本專案聲學模型通過采用卷積神經網路(CNN)和連接性時序分類(CTC)方法,使用大量中文語音資料集進行訓練,將聲音轉錄為中文拼音,并通過語言模型,將拼音序列轉換為中文文本,演算法模型在測驗集上已經獲得了80%的正確率,基于該模型,在Windows平臺上實作了一個基于ASRT的語音識別應用軟體,取得了較好應用效果,這個應用軟體包含Windows 10 UWP商店應用和Windows 版.Net平臺桌面應用,也一起開源在GitHub上了,
ASRT專案主頁:
https://asrt.ailemon.me
ASRT專案檔案:
https://asrt.ailemon.me/docs/
GitHub專案地址:
語音識別核心系統
https://github.com/nl8590687/ASRT_SpeechRecognition
語音識別客戶端應用
Windows桌面版 https://github.com/nl8590687/ASRT_SpeechClient_WPF
Windows 10 UWP版 https://github.com/nl8590687/ASRT_SpeechClient_UWP
Java Web版 https://github.com/nl8590687/ASRT_SpeechClient_JavaWeb
Python SDK
https://github.com/nl8590687/ASRT_SDK_Python3
近年來,深度學習在人工智能領域興起,其對語音識別也產生了深遠影響,深層的神經網路逐步替代了原來的GMM-HMM模型,在人類的交流和知識傳播中,大約 70% 的資訊是來自于語音,未來,語音識別將必然成為智能生活里重要的一部分,它可以為語音助手、語音輸入等提供必不可少的基礎,這將會成為一種新的人機互動方式,因此,我們需要讓機器聽懂人的聲音,
我們的語音識別系統的聲學模型采用了深度全卷積神經網路,直接將語譜圖作為輸入,模型結構上,借鑒了影像識別中效果最好的網路配置VGG,這種網路模型有著很強的表達能力,可以看到非常長的歷史和未來資訊,相比RNN在魯棒性上更出色,在輸出端,這種模型可以和CTC方案可以完美結合,以實作整個模型的端到端訓練,將聲音波形信號直接轉錄為中文普通話拼音序列,在語言模型上,通過最大熵隱含馬爾可夫模型,將拼音序列轉換為中文文本,并且,為了通過網路提供服務給所有的用戶,本專案還使用了Python的HTTP協議基礎服務器包,提供基于網路HTTP協議的語音識別API,客戶端軟體通過網路,呼叫該API實作語音識別功能,
目前,該語音識別系統在考慮朝著語音識別框架方向發展,以方便研究人員隨時上手研究新模型,使用新資料集等,
系統的流程
特征提取 將普通的wav語音信號通過分幀加窗等操作轉換為神經網路需要的二維頻譜影像信號,即語譜圖,
聲學模型 基于Keras和TensorFlow框架,使用這種參考了VGG的深層的卷積神經網路作為網路模型,并訓練,
CTC解碼 在語音識別系統的聲學模型的輸出中,往往包含了大量連續重復的符號,因此,我們需要將連續相同的符合合并為同一個符號,然后再去除靜音分隔標記符,得到最終實際的語音拼音符號序列,
語言模型 使用統計語言模型,將拼音轉換為最終的識別文本并輸出,拼音轉文本的本質被建模為一條隱含馬爾可夫鏈,這種模型有著很高的準確率,(其原理請看:https://blog.ailemon.me/2017/04/27/statistical-language-model-chinese-pinyin-to-words/)
基于HTTP協議的API介面
本專案使用了Python內置的http.server包來實作了一個基礎的基于http協議的API服務器,通過將聲學模型和語言模型連接起來,使用該服務器程式,可以直接實作一個簡單的API服務器,通過POST方式進行資料互動,
這是POST引數串列:
引數名 說明
token 服務器對連接的客戶端進行認證用的口令,避免其被非法呼叫
fs 指示傳送的wav波形信號的頻率是多少,單位:Hz
wavs 一個包含了全部語音波形信號的串列
客戶端
本專案的客戶端分為兩種,均為Windows客戶端,一個是UWP客戶端,另一個是WPF客戶端,原始碼均需要使用VS2017來開發和編譯,使用C#和XAML撰寫,專案包含有界面邏輯和錄音模塊、語音識別API呼叫模塊,并包含對wav檔案的raw格式進行的決議,
客戶端通過自動控制錄音的中斷時間、兩個錄音模塊連續交替錄音,以及異步發送請求操作,最終按照先后順序將回傳結果顯示在界面的文本框中,實作了長時間連續語音識別的功能,
未來
未來的ASRT,還要加入針對說話人進行識別的功能,也就是做一個說話人識別系統,用來實作AI的“認主”行為,讓AI知曉現在是誰在說話,這將是AI實際應用時很多場景下會面臨的一個問題,不過這個專案截至發稿前,暫時還沒有動工,有感興趣的小伙伴歡迎提前關注一波~
ASRT專案主頁:
https://asrt.ailemon.me
ASRT專案檔案:
https://asrt.ailemon.me/docs/
GitHub專案地址:
語音識別核心系統
https://github.com/nl8590687/ASRT_SpeechRecognition
語音識別客戶端應用
Windows桌面版 https://github.com/nl8590687/ASRT_SpeechClient_WPF
Windows 10 UWP版 https://github.com/nl8590687/ASRT_SpeechClient_UWP
Java Web版 https://github.com/nl8590687/ASRT_SpeechClient_JavaWeb
Python SDK
https://github.com/nl8590687/ASRT_SDK_Python3
說話人識別系統
https://github.com/nl8590687/ASRT_SpeakerRecognition
import platform as plat
import os
import time
from general_function.file_wav import *
from general_function.file_dict import *
from general_function.gen_func import *
from general_function.muti_gpu import *
import keras as kr
import numpy as np
import random
from keras.models import Sequential, Model
from keras.layers import Dense, Dropout, Input, Reshape, BatchNormalization # , Flatten
from keras.layers import Lambda, TimeDistributed, Activation,Conv2D, MaxPooling2D,GRU #, Merge
from keras.layers.merge import add, concatenate
from keras import backend as K
from keras.optimizers import SGD, Adadelta, Adam
from readdata24 import DataSpeech
abspath = ''
ModelName='261'
NUM_GPU = 2
class ModelSpeech(): # 語音模型類
def __init__(self, datapath):
'''
初始化
默認輸出的拼音的表示大小是1428,即1427個拼音+1個空白塊
'''
MS_OUTPUT_SIZE = 1428
self.MS_OUTPUT_SIZE = MS_OUTPUT_SIZE # 神經網路最終輸出的每一個字符向量維度的大小
#self.BATCH_SIZE = BATCH_SIZE # 一次訓練的batch
self.label_max_string_length = 64
self.AUDIO_LENGTH = 1600
self.AUDIO_FEATURE_LENGTH = 200
self._model, self.base_model = self.CreateModel()
self.datapath = datapath
self.slash = ''
system_type = plat.system() # 由于不同的系統的檔案路徑表示不一樣,需要進行判斷
if(system_type == 'Windows'):
self.slash='\\' # 反斜杠
elif(system_type == 'Linux'):
self.slash='/' # 正斜杠
else:
print('*[Message] Unknown System\n')
self.slash='/' # 正斜杠
if(self.slash != self.datapath[-1]): # 在目錄路徑末尾增加斜杠
self.datapath = self.datapath + self.slash
def CreateModel(self):
'''
定義CNN/LSTM/CTC模型,使用函式式模型
輸入層:200維的特征值序列,一條語音資料的最大長度設為1600(大約16s)
隱藏層:卷積池化層,卷積核大小為3x3,池化視窗大小為2
隱藏層:全連接層
輸出層:全連接層,神經元數量為self.MS_OUTPUT_SIZE,使用softmax作為激活函式,
CTC層:使用CTC的loss作為損失函式,實作連接性時序多輸出
'''
input_data = Input(name='the_input', shape=(self.AUDIO_LENGTH, self.AUDIO_FEATURE_LENGTH, 1))
layer_h1 = Conv2D(32, (3,3), use_bias=False, activation='relu', padding='same', kernel_initializer='he_normal')(input_data) # 卷積層
#layer_h1 = Dropout(0.05)(layer_h1)
layer_h2 = Conv2D(32, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h1) # 卷積層
layer_h3 = MaxPooling2D(pool_size=2, strides=None, padding="valid")(layer_h2) # 池化層
#layer_h3 = Dropout(0.05)(layer_h3) # 隨機中斷部分神經網路連接,防止過擬合
layer_h4 = Conv2D(64, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h3) # 卷積層
#layer_h4 = Dropout(0.1)(layer_h4)
layer_h5 = Conv2D(64, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h4) # 卷積層
layer_h6 = MaxPooling2D(pool_size=2, strides=None, padding="valid")(layer_h5) # 池化層
#layer_h6 = Dropout(0.1)(layer_h6)
layer_h7 = Conv2D(128, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h6) # 卷積層
#layer_h7 = Dropout(0.15)(layer_h7)
layer_h8 = Conv2D(128, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h7) # 卷積層
layer_h9 = MaxPooling2D(pool_size=2, strides=None, padding="valid")(layer_h8) # 池化層
#layer_h9 = Dropout(0.15)(layer_h9)
layer_h10 = Conv2D(128, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h9) # 卷積層
#layer_h10 = Dropout(0.2)(layer_h10)
layer_h11 = Conv2D(128, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h10) # 卷積層
layer_h12 = MaxPooling2D(pool_size=1, strides=None, padding="valid")(layer_h11) # 池化層
#layer_h12 = Dropout(0.2)(layer_h12)
layer_h13 = Conv2D(128, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h12) # 卷積層
#layer_h13 = Dropout(0.3)(layer_h13)
layer_h14 = Conv2D(128, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h13) # 卷積層
layer_h15 = MaxPooling2D(pool_size=1, strides=None, padding="valid")(layer_h14) # 池化層
#test=Model(inputs = input_data, outputs = layer_h12)
#test.summary()
layer_h16 = Reshape((200, 3200))(layer_h15) #Reshape層
#layer_h16 = Dropout(0.3)(layer_h16) # 隨機中斷部分神經網路連接,防止過擬合
layer_h17 = Dense(128, activation="relu", use_bias=True, kernel_initializer='he_normal')(layer_h16) # 全連接層
inner = layer_h17
#layer_h5 = LSTM(256, activation='relu', use_bias=True, return_sequences=True)(layer_h4) # LSTM層
rnn_size=128
gru_1 = GRU(rnn_size, return_sequences=True, kernel_initializer='he_normal', name='gru1')(inner)
gru_1b = GRU(rnn_size, return_sequences=True, go_backwards=True, kernel_initializer='he_normal', name='gru1_b')(inner)
gru1_merged = add([gru_1, gru_1b])
gru_2 = GRU(rnn_size, return_sequences=True, kernel_initializer='he_normal', name='gru2')(gru1_merged)
gru_2b = GRU(rnn_size, return_sequences=True, go_backwards=True, kernel_initializer='he_normal', name='gru2_b')(gru1_merged)
gru2 = concatenate([gru_2, gru_2b])
layer_h20 = gru2
#layer_h20 = Dropout(0.4)(gru2)
layer_h21 = Dense(128, activation="relu", use_bias=True, kernel_initializer='he_normal')(layer_h20) # 全連接層
#layer_h17 = Dropout(0.3)(layer_h17)
layer_h22 = Dense(self.MS_OUTPUT_SIZE, use_bias=True, kernel_initializer='he_normal')(layer_h21) # 全連接層
y_pred = Activation('softmax', name='Activation0')(layer_h22)
model_data = Model(inputs = input_data, outputs = y_pred)
#model_data.summary()
labels = Input(name='the_labels', shape=[self.label_max_string_length], dtype='float32')
input_length = Input(name='input_length', shape=[1], dtype='int64')
label_length = Input(name='label_length', shape=[1], dtype='int64')
# Keras doesn't currently support loss funcs with extra parameters
# so CTC loss is implemented in a lambda layer
#layer_out = Lambda(ctc_lambda_func,output_shape=(self.MS_OUTPUT_SIZE, ), name='ctc')([y_pred, labels, input_length, label_length])#(layer_h6) # CTC
loss_out = Lambda(self.ctc_lambda_func, output_shape=(1,), name='ctc')([y_pred, labels, input_length, label_length])
model = Model(inputs=[input_data, labels, input_length, label_length], outputs=loss_out)
model.summary()
# clipnorm seems to speeds up convergence
#sgd = SGD(lr=0.0001, decay=1e-6, momentum=0.9, nesterov=True, clipnorm=5)
#ada_d = Adadelta(lr = 0.01, rho = 0.95, epsilon = 1e-06)
opt = Adam(lr = 0.001, beta_1 = 0.9, beta_2 = 0.999, decay = 0.0, epsilon = 10e-8)
#model.compile(loss={'ctc': lambda y_true, y_pred: y_pred}, optimizer=sgd)
model.build((self.AUDIO_LENGTH, self.AUDIO_FEATURE_LENGTH, 1))
model = ParallelModel(model, NUM_GPU)
model.compile(loss={'ctc': lambda y_true, y_pred: y_pred}, optimizer = opt)
# captures output of softmax so we can decode the output during visualization
test_func = K.function([input_data], [y_pred])
#print('[*提示] 創建模型成功,模型編譯成功')
print('[*Info] Create Model Successful, Compiles Model Successful. ')
return model, model_data
def ctc_lambda_func(self, args):
y_pred, labels, input_length, label_length = args
y_pred = y_pred[:, :, :]
#y_pred = y_pred[:, 2:, :]
return K.ctc_batch_cost(labels, y_pred, input_length, label_length)
def TrainModel(self, datapath, epoch = 2, save_step = 1000, batch_size = 32, filename = abspath + 'model_speech/m' + ModelName + '/speech_model'+ModelName):
'''
訓練模型
引數:
datapath: 資料保存的路徑
epoch: 迭代輪數
save_step: 每多少步保存一次模型
filename: 默認保存檔案名,不含檔案后綴名
'''
data=DataSpeech(datapath, 'train')
num_data = data.GetDataNum() # 獲取資料的數量
yielddatas = data.data_genetator(batch_size, self.AUDIO_LENGTH)
for epoch in range(epoch): # 迭代輪數
print('[running] train epoch %d .' % epoch)
n_step = 0 # 迭代資料數
while True:
try:
print('[message] epoch %d . Have train datas %d+'%(epoch, n_step*save_step))
# data_genetator是一個生成器函式
#self._model.fit_generator(yielddatas, save_step, nb_worker=2)
self._model.fit_generator(yielddatas, save_step)
n_step += 1
except StopIteration:
print('[error] generator error. please check data format.')
break
self.SaveModel(comment='_e_'+str(epoch)+'_step_'+str(n_step * save_step))
self.TestModel(self.datapath, str_dataset='train', data_count = 4)
self.TestModel(self.datapath, str_dataset='dev', data_count = 4)
def LoadModel(self,filename = abspath + 'model_speech/m'+ModelName+'/speech_model'+ModelName+'.model'):
'''
加載模型引數
'''
self._model.load_weights(filename)
self.base_model.load_weights(filename + '.base')
def SaveModel(self,filename = abspath + 'model_speech/m'+ModelName+'/speech_model'+ModelName,comment=''):
'''
保存模型引數
'''
self._model.save_weights(filename+comment+'.model')
self.base_model.save_weights(filename + comment + '.model.base')
f = open('step'+ModelName+'.txt','w')
f.write(filename+comment)
f.close()
def TestModel(self, datapath='', str_dataset='dev', data_count = 32, out_report = False, show_ratio = True):
'''
測驗檢驗模型效果
'''
data=DataSpeech(self.datapath, str_dataset)
#data.LoadDataList(str_dataset)
num_data = data.GetDataNum() # 獲取資料的數量
if(data_count <= 0 or data_count > num_data): # 當data_count為小于等于0或者大于測驗資料量的值時,則使用全部資料來測驗
data_count = num_data
try:
ran_num = random.randint(0,num_data - 1) # 獲取一個亂數
words_num = 0
word_error_num = 0
nowtime = time.strftime('%Y%m%d_%H%M%S',time.localtime(time.time()))
if(out_report == True):
txt_obj = open('Test_Report_' + str_dataset + '_' + nowtime + '.txt', 'w', encoding='UTF-8') # 打開檔案并讀入
txt = ''
for i in range(data_count):
data_input, data_labels = data.GetData((ran_num + i) % num_data) # 從亂數開始連續向后取一定數量資料
# 資料格式出錯處理 開始
# 當輸入的wav檔案長度過長時自動跳過該檔案,轉而使用下一個wav檔案來運行
num_bias = 0
while(data_input.shape[0] > self.AUDIO_LENGTH):
print('*[Error]','wave data lenghth of num',(ran_num + i) % num_data, 'is too long.','\n A Exception raise when test Speech Model.')
num_bias += 1
data_input, data_labels = data.GetData((ran_num + i + num_bias) % num_data) # 從亂數開始連續向后取一定數量資料
# 資料格式出錯處理 結束
pre = self.Predict(data_input, data_input.shape[0] // 8)
words_n = data_labels.shape[0] # 獲取每個句子的字數
words_num += words_n # 把句子的總字數加上
edit_distance = GetEditDistance(data_labels, pre) # 獲取編輯距離
if(edit_distance <= words_n): # 當編輯距離小于等于句子字數時
word_error_num += edit_distance # 使用編輯距離作為錯誤字數
else: # 否則肯定是增加了一堆亂七八糟的奇奇怪怪的字
word_error_num += words_n # 就直接加句子本來的總字數就好了
if(i % 10 == 0 and show_ratio == True):
print('Test Count: ',i,'/',data_count)
txt = ''
if(out_report == True):
txt += str(i) + '\n'
txt += 'True:\t' + str(data_labels) + '\n'
txt += 'Pred:\t' + str(pre) + '\n'
txt += '\n'
txt_obj.write(txt)
#print('*[測驗結果] 語音識別 ' + str_dataset + ' 集語音單字錯誤率:', word_error_num / words_num * 100, '%')
print('*[Test Result] Speech Recognition ' + str_dataset + ' set word error ratio: ', word_error_num / words_num * 100, '%')
if(out_report == True):
txt = '*[測驗結果] 語音識別 ' + str_dataset + ' 集語音單字錯誤率: ' + str(word_error_num / words_num * 100) + ' %'
txt_obj.write(txt)
txt_obj.close()
except StopIteration:
print('[Error] Model Test Error. please check data format.')
def Predict(self, data_input, input_len):
'''
預測結果
回傳語音識別后的拼音符號串列
'''
batch_size = 1
in_len = np.zeros((batch_size),dtype = np.int32)
in_len[0] = input_len
x_in = np.zeros((batch_size, 1600, self.AUDIO_FEATURE_LENGTH, 1), dtype=np.float)
for i in range(batch_size):
x_in[i,0:len(data_input)] = data_input
base_pred = self.base_model.predict(x = x_in)
#print('base_pred:\n', base_pred)
#y_p = base_pred
#for j in range(200):
# mean = np.sum(y_p[0][j]) / y_p[0][j].shape[0]
# print('max y_p:',np.max(y_p[0][j]),'min y_p:',np.min(y_p[0][j]),'mean y_p:',mean,'mid y_p:',y_p[0][j][100])
# print('argmin:',np.argmin(y_p[0][j]),'argmax:',np.argmax(y_p[0][j]))
# count=0
# for i in range(y_p[0][j].shape[0]):
# if(y_p[0][j][i] < mean):
# count += 1
# print('count:',count)
base_pred =base_pred[:, :, :]
#base_pred =base_pred[:, 2:, :]
r = K.ctc_decode(base_pred, in_len, greedy = True, beam_width=100, top_paths=1)
#print('r', r)
r1 = K.get_value(r[0][0])
#print('r1', r1)
#r2 = K.get_value(r[1])
#print(r2)
r1=r1[0]
return r1
pass
def RecognizeSpeech(self, wavsignal, fs):
'''
最終做語音識別用的函式,識別一個wav序列的語音
'''
#data = self.data
#data = DataSpeech('E:\\語音資料集')
#data.LoadDataList('dev')
# 獲取輸入特征
#data_input = GetMfccFeature(wavsignal, fs)
#t0=time.time()
data_input = GetFrequencyFeature3(wavsignal, fs)
#t1=time.time()
#print('time cost:',t1-t0)
input_length = len(data_input)
input_length = input_length // 8
data_input = np.array(data_input, dtype = np.float)
#print(data_input,data_input.shape)
data_input = data_input.reshape(data_input.shape[0],data_input.shape[1],1)
#t2=time.time()
r1 = self.Predict(data_input, input_length)
#t3=time.time()
#print('time cost:',t3-t2)
list_symbol_dic = GetSymbolList(self.datapath) # 獲取拼音串列
r_str=[]
for i in r1:
r_str.append(list_symbol_dic[i])
return r_str
pass
def RecognizeSpeech_FromFile(self, filename):
'''
最終做語音識別用的函式,識別指定檔案名的語音
'''
wavsignal,fs = read_wav_data(filename)
r = self.RecognizeSpeech(wavsignal, fs)
return r
pass
@property
def model(self):
'''
回傳keras model
'''
return self._model
if(__name__=='__main__'):
#import tensorflow as tf
#from keras.backend.tensorflow_backend import set_session
#os.environ["CUDA_VISIBLE_DEVICES"] = "1"
#進行配置,使用70%的GPU
#config = tf.ConfigProto()
#config.gpu_options.per_process_gpu_memory_fraction = 0.95
#config.gpu_options.allow_growth=True #不全部占滿顯存, 按需分配
#set_session(tf.Session(config=config))
datapath = abspath + ''
modelpath = abspath + 'model_speech'
if(not os.path.exists(modelpath)): # 判斷保存模型的目錄是否存在
os.makedirs(modelpath) # 如果不存在,就新建一個,避免之后保存模型的時候炸掉
system_type = plat.system() # 由于不同的系統的檔案路徑表示不一樣,需要進行判斷
if(system_type == 'Windows'):
datapath = 'E:\\語音資料集'
modelpath = modelpath + '\\'
elif(system_type == 'Linux'):
datapath = abspath + 'dataset'
modelpath = modelpath + '/'
else:
print('*[Message] Unknown System\n')
datapath = 'dataset'
modelpath = modelpath + '/'
ms = ModelSpeech(datapath)
#ms.LoadModel(modelpath + 'm261/speech_model261_e_0_step_98000.model')
ms.TrainModel(datapath, epoch = 50, batch_size = 16, save_step = 500)
#ms.TestModel(datapath, str_dataset='test', data_count = 128, out_report = True)
#r = ms.RecognizeSpeech_FromFile('E:\\語音資料集\\ST-CMDS-20170001_1-OS\\20170001P00241I0053.wav')
#r = ms.RecognizeSpeech_FromFile('E:\\語音資料集\\ST-CMDS-20170001_1-OS\\20170001P00020I0087.wav')
#r = ms.RecognizeSpeech_FromFile('E:\\語音資料集\\wav\\train\\A11\\A11_167.WAV')
#r = ms.RecognizeSpeech_FromFile('E:\\語音資料集\\wav\\test\\D4\\D4_750.wav')
#print('*[提示] 語音識別結果:\n',r)
部分代碼介紹
實戰二 調百度和科大訊飛API
現在演示的是識別音頻檔案的內容,
token獲取見官網,這邊調包沒什么含金量,
Python 技術篇-百度語音API鑒權認證獲取Access Token
注:下面的 token 是我自己申請的,建議按照我的文章自己來申請專屬的,
import requests
import os
import base64
import json
apiUrl='http://vop.baidu.com/server_api'
filename = "16k.pcm" # 這是我下載到本地的音頻樣例檔案名
size = os.path.getsize(filename) # 獲取本地語音檔案尺寸
file1 = open(filename, "rb").read() # 讀取本地語音檔案
text = base64.b64encode(file1).decode("utf-8") # 對讀取的檔案進行base64編碼
data = {
"format":"pcm", # 音頻格式
"rate":16000, # 采樣率,固定值16000
"dev_pid":1536, # 普通話
"channel":1, # 頻道,固定值1
"token":"24.0c828682d414bf79b08f89c4c7dcd83a.2592000.1562739150.282335-16470175", # 重要,鑒權認證Access Token,需要自己來申請
"cuid":"DC-85-DE-F9-08-59", # 隨便一個值就好了,官網推薦是個人電腦的MAC地址
"len":size, # 語音檔案的尺寸
"speech":text, # base64編碼的語音檔案
}
try:
r = requests.post(apiUrl, data = json.dumps(data)).json()
print(r)
print(r.get("result")[0])
except Exception as e:
print(e)
科大訊飛同樣的方式,參見官網教程,
實戰三 離線語音識別 Vosk
Vosk 支持30多種語言,并且現在做的不錯,在離線語音里面不錯了,https://github.com/alphacep/vosk-api
帶Android python,c++ 的pc版本,等等web部署方案
Android 的話,就需要你安裝Android 包,然后還要下載編譯工具,gradle
cd android
gradle build
即可編譯,編譯成功后會生成apk安裝包,手機就能安裝,離線使用了,
部分代碼:
/**
* Adds listener.
*/
public void addListener(RecognitionListener listener) {
synchronized (listeners) {
listeners.add(listener);
}
}
/**
* Removes listener.
*/
public void removeListener(RecognitionListener listener) {
synchronized (listeners) {
listeners.remove(listener);
}
}
/**
* Starts recognition. Does nothing if recognition is active.
*
* @return true if recognition was actually started
*/
public boolean startListening() {
if (null != recognizerThread)
return false;
recognizerThread = new RecognizerThread();
recognizerThread.start();
return true;
}
這邊實戰的比較簡單,后續我做了很多優化,支持Android,python ,c++,java語言等部署,歡迎咨詢我,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/271921.html
標籤:AI
下一篇:[Python影像處理] 三十九.Python影像分類萬字詳解(貝葉斯影像分類、KNN影像分類、DNN影像分類)