前言
老讀者都知道,Alice是一個愛看書的程式員,之前已經為大家分享過2篇跟書有關的文章,一篇是《推薦10本大資料領域必讀的經典好書(火速收藏)》,為大家推薦了一些從很經典的大資料書籍(還專門為大家準備了電子版),另外一篇是《簡單談談最近在看的幾本書「資料中臺,用戶畫像」》,第二篇更多是站在讀者的角度,分析評判書的可讀性,并寫了自己的讀后感,雖然帶來的效果并沒有第一篇那么好,但是卻收到不少小伙伴的好評!最近,又淘到2本不錯的好書,想借本期文章為大家好好“品”一下,希望大家能夠受益!
大資料分析 : 資料倉庫專案實戰

相信大家看到封面,第一眼應該是被左上角的“硅谷”所吸引,作為“尚大”畢業的學生,對于其資料的硬核程度,與靠著自學一路走來的小伙伴們一樣,有目共睹,作為它出版的第一本書,相信大家也同樣期待 ~
大資料發展至今,早已不是一個新興詞語,大資料的應用已經無處不在!正如本書前言所述,在大資料時代,我們面臨的不僅是海量的資料,更重要的是海量資料所帶來的資料的采集、存盤、處理等方方面面的問題,為了更快速、更全面地展示大資料的實踐應用,這本書以一個資料倉庫專案為切入點,帶領大家一步步揭開大資料的面紗!
相信很多非大資料行業的小伙伴不是很理解,資料倉庫是啥?
如果是回答新手上路的萌新,我會回答資料倉庫專案是學習大資料的重要基石,你可以通過以搭建數倉為主線,從搭建之初的框架選型、資料服務的整體策劃到資料的流向,資料的采集、存盤和計算,循序漸進,一步步展開,進行細致剖析,簡單理解,就是完整跟著把這個專案做一遍,大資料基本常用的技術你都玩過了 ~
如果有一定開發經驗,但是在作業中未接觸到大資料行業的“老司機”來問這個問題,我會基于自己大量閱讀和實踐的認知,告訴他:資料倉庫是大多數企業“試水”大資料的首先切入點,為啥?一方面資料倉庫主要編程語言以SQL為主,所以經常搞數倉的就容易被人戲稱是 SQLBoy,哈哈開個玩笑 ~ 無論是 Hive 還是 SparkSQL,都是通過高度標準化的 SQL 進行開發的,這樣的好處就很明顯,對于很多從傳統資料倉庫,例如做后臺開發,向大資料轉型的開發人員和團隊來說,是一種較為平滑的過渡;另一方面,資料倉庫理論和方法論已經非常成熟,在大資料平臺上實作資料倉庫遵循的依然是這些理論,只是在不同的業務,專案中實作的細節上有所不同!所以,如果完整跟著做了一個專案,在大腦中形成自己的一套“數倉理論”,再去學習其他的專案或者技術點,相信會有起到“觸類旁通”的效果,事半功倍!
當然,在大資料領域扎根多年的“老鳥”應該是不會問我這么“稚嫩”的問題,但 “ A true master is an eternal student ”,真正的大師,永遠都懷著一顆學徒的心,我會袒露心聲:現在大資料生態圈用“百花齊放”真的不為過,舉一些當前大資料開發主流的框架,例如采集:Flume,Kafka,Sqoop;存盤:MySQL,Hadoop,HBase;計算:Hive,Tez;即席查詢:Presto,Druid,Kylin;可視化:Superset;任務調度:Azkaban;元資料管理:Atlas 等等,我們很少在真實的一個企業級專案中均有所涉及,但如果有一個不算復雜的專案能把一個完整的技術堆疊串聯起來,我相信不管是對于專案本身的業務的拓展理解還是自身技術堆疊的積累,都會有不少的提升!除此之外,書中還有對于數倉學習中需要掌握的一些理論,例如范式理論,星型,雪花和星座模型區別,表如何分層,數倉如何建模,以及常用的術語都有一定的講解,但不是非常詳細,如果想要全面了解數倉,建議去看《資料倉庫工具箱》,想要數倉工具箱電子版可以私聊我,當然這就是后話了~
或許你看到這里,會對專案的架構感興趣,那我就分享一下最近看了硅谷的教程,依葫蘆畫瓢的2張架構圖,分別是離線和實時的數倉架構設計,而這本書就是按照離線的架構介紹的,
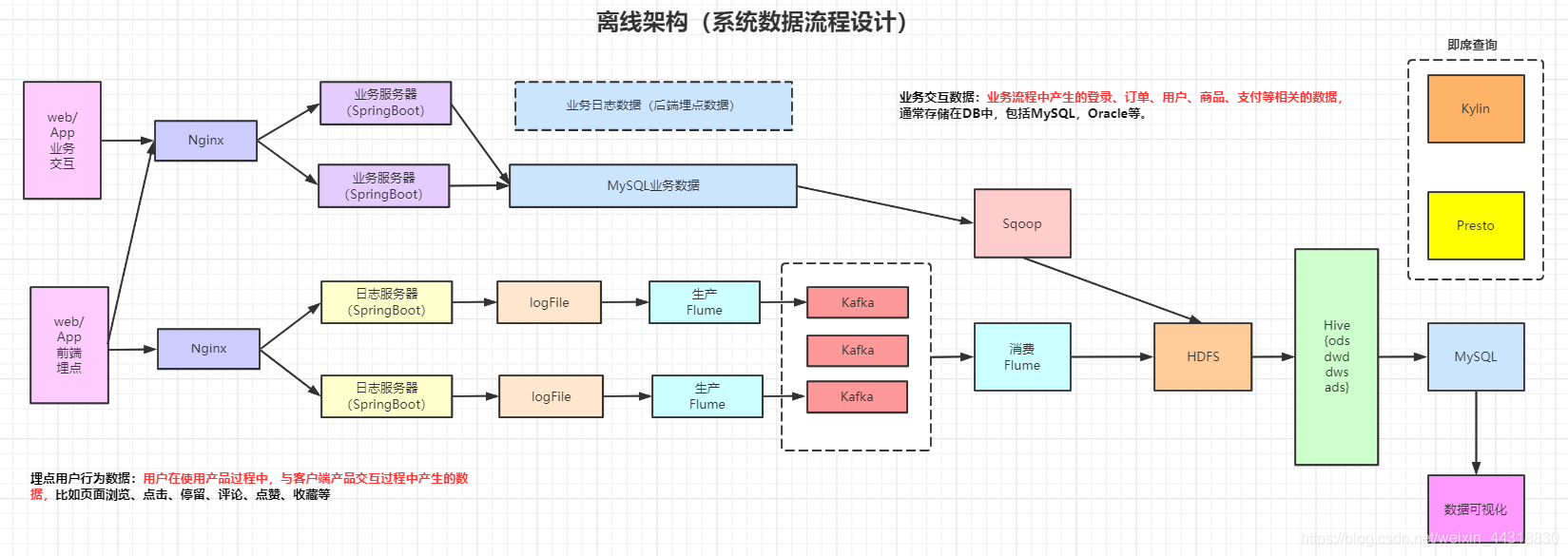
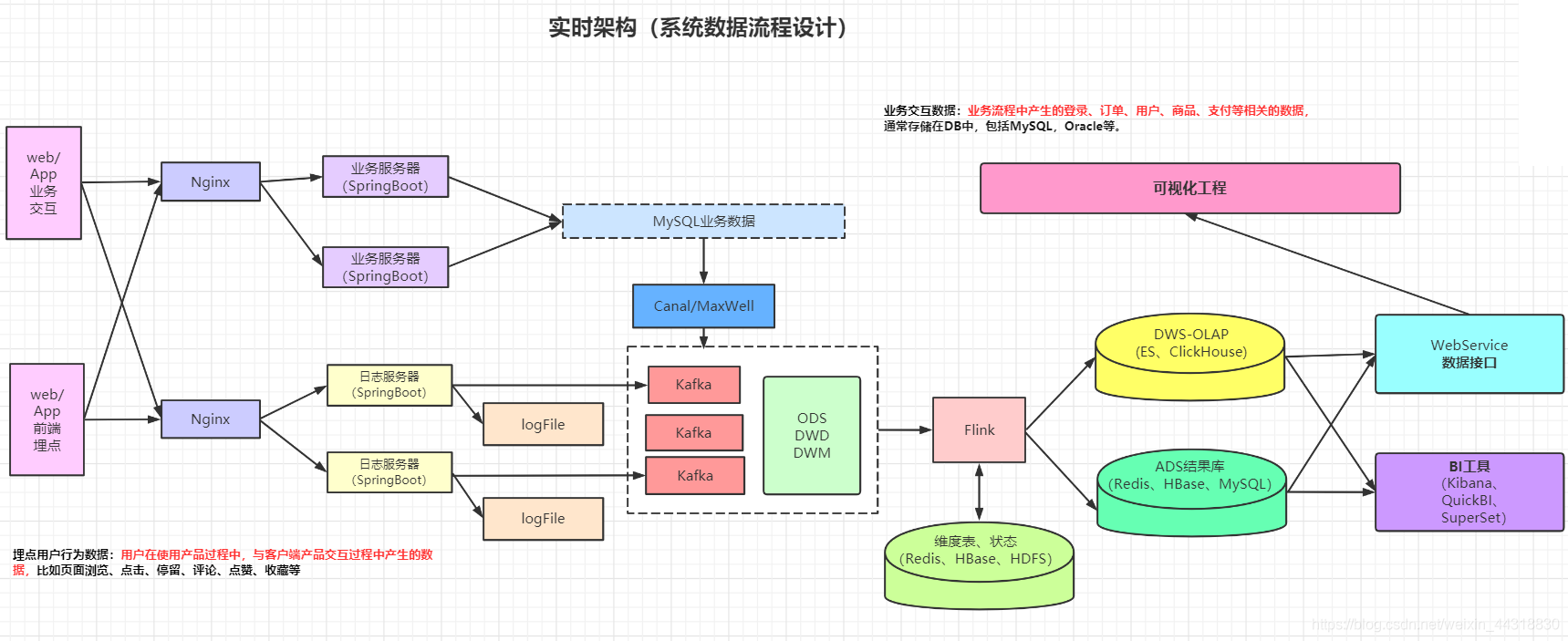
這本書比較適合初級程式員 或者 大資料萌新,要求讀者具有一定的編程基礎,例如 Java 和 SQL ,另外專案配套的相關內容早已在B站上有對應的視頻公開 ~ 想找電子書的朋友可以用“無限卡”去 wx讀書上白嫖 ~
大資料平臺架構與原型實作:資料中臺建設實戰

這本書的作者是一位架構師,擁有 14 年 IT 系統開發和架構經驗,在大資料、企業級應用架構,SaaS、分布式存盤和領域驅動設計等方面都有不錯的實踐經驗,當時買這本書的主要原因是它因為在豆瓣上口碑不錯,再加上近幾年資料中臺越來越火,幾乎所有的大廠都有自己的中臺,而自己作為一個大資料萌新,對于“熱門新鮮”的技術一直都很敏感,所以當時就很爽快地買來看了,
讓我驚喜的是,這本書對于中臺的介紹應該是我目前為止看過的所有資料里介紹的最透徹的,光技術中臺一個知識點,就從技術體系,組織架構,以及需要具備的能力和建設策略,讓之前從沒有認真思考過“資料中臺”來源的我,開始思索其未來的發展,但美中不足的地方是,書中大篇幅的實際系統部署內容,對于開發能力薄弱的讀者不是很友好,但這也不能埋怨作者,畢竟就像現在資料中臺的概念滿天飛,最終的落地卻是一大難題,如果整本書光吹理論而不將其落到實際的操作上,整本書的價值將大打折扣!
說一些我認為受益比較大的地方,在第4章架構與原型設計,在第一小節,介紹大資料平臺架構設計的時候,介紹了一些業界已經較為成熟的架構模式,例如 Lambda架構,Kappa架構 以及 Smack 架構,在此之前,我最多也只是在公司內部技術分享會上聽到其他人談到會有點印象,但是自己卻從未去主動了解過,我在幾乎0基礎的情況下,閱讀這些架構的設計理念和應用,還是比較的容易,這可能跟自學能力有關,另外我比較欣賞的一點就是,作者作為一個高級架構師,對于技術本身的理解非常深入,尤其在做技術選型的時候,從數倉分層的設計與構建,資料存盤系統的選擇對比,不同場景下作業流的作業調度,部署提交,專案構建…每一個點都需要有一定的知識儲備,這些都能了然于胸,離不開平時大量的實踐和積累,我的目標是未來能成為大資料架構師,別的不說,至少通過作者的閱讀,我學會了新的思考方式!
借用彩食鮮CTO、鯤鵬會榮譽導師,蘇寧科技集團原副總裁喬新亮老師的評論,本書涵蓋了大資料平臺建設的全部環節,通讀下來,整體上實操性很強,架構原理融于了工程原型的搭建程序,對于希望自己動手實踐的讀者會很有幫助,同時在操作步驟中介紹了相應的邏輯與設計,有助于讀者更好地領會背后的原理,在今天這個時代,我們不見得要自己搭建整個平臺,但是了解原理可以讓自己作業起來事半功倍,不管是自己搭建,還是利用成熟平臺,懂得原理,明白實踐,再開始在企業中搭建資料驅動內部經營的完善體系就會胸有成竹、游刃有余!
小結
本期內容我為大家推薦了2本非常認可,喜歡的技術書籍,同時也希望大家在平時閱讀的時候,多輸出,多思考,這樣往往能夠對書中想要表達的核心思想理解得更透徹,好了,本篇內容就到這里,我是【大資料夢想家】,一個堅信技術成就自我的“后浪”,你知道的越多,你不知道的也越多!如果本文對您有所啟發,不妨點個三連,我們下一期,不見不散~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/271957.html
標籤:其他
上一篇:【ECharts系列|02可視化大屏】 輿情分析,人口分析及警情警力活動情況的實作【下篇】
下一篇:西南大學電子資訊907初試經驗