
資訊論第一次上機作業
1.影像信源熵的求解
讀入一幅影像,實作求解圖片信源的熵,
'''
1.影像信源熵的求解
讀入一幅影像,實作求解圖片信源的熵,
'''
import math
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
#獲取一個數字陣列中的陣列,以np.matrix形式輸出,原陣列
def get_strlist_data(lines): # 在這里lines = f.readlines()
'''
:param lines: 輸入的是字串形式,這樣更為方便轉化
:return: 字串對應的串列list形式
'''
sizeArry = [] # 創建一個list,用來存盤資料
for line in lines:
line = line.replace("\n", "")
# 因為讀出來的資料每一行都有一個回車符,我們要洗掉
line = float(line)
# 將其轉換為整數
sizeArry.append(line)
# 轉換為numpy 可以識別的陣列
return np.asarray(sizeArry)
def get_file_data(path):
'''
:param path: 需要讀取的圖片所在路徑
:return: 得到字串形式的陣列
'''
# 首先打開檔案從檔案中讀取資料
f = open(path) # path存盤的是我們的目標檔案所在的位置
# 我們先打開目標檔案然后讀取出這個檔案中的每一行
lines = f.readlines()
return get_strlist_data(lines)
#影像資訊矩陣化(灰度圖片)
def ImagetoArray(filename):
im = Image.open(filename)
#im.show()
# 圖片資訊矩陣化
data = np.asarray(im)
data = np.array(data, dtype='float')
return data
#三色道分離操作
def ImagetoArrayRGB(filename,channel):
data=ImagetoArray(filename)
if channel=='r':
return data[:,:,0]
if channel=='g':
return data[:,:,1]
if channel=='b':
return data[:,:,2]
def Entropy(Mat):
M=np.size(Mat)#資料總量
Census=np.zeros(255)
for i in range(np.shape(Mat)[0]):
for j in range(np.shape(Mat)[1]):
Census[int(Mat[i][j])-1]+=1
sum=0
for i in Census:
if i == 0:
continue
else:
sum+=i*math.log(i)
entropy=-sum/M+math.log(M)
return entropy
if __name__=="__main__":
Path='菲謝爾1.jpg'
R=ImagetoArrayRGB(Path,'r')
G=ImagetoArrayRGB(Path,'g')
B=ImagetoArrayRGB(Path, 'b')
print(Entropy(R)+Entropy(G)+Entropy(B))

上圖中的菲謝爾的資訊量為:
15.555038790999852
2.一個發射器發出A,B,C三個訊息
一個發射器發出A,B,C三個訊息,他們的先驗概率和條件概率分別為:
| i | A | B | C |
|---|---|---|---|
| P(i) | 9/27 | 16/27 | 2/27 |
條件概率為:
| P(i/j) | A | B | C |
|---|---|---|---|
| A | 0 | 4/5 | 1/5 |
| B | 1/2 | 1/2 | 0 |
| C | 1/2 | 2/5 | 1/10 |
Q1:求信源熵,
Q2:求信源最大熵,
Q3:求剩余度,
'''
2.一個發射器發出A,B,C三個訊息,他們的先驗概率和條件概率分別為:
i A B C
P(i) 9/27 16/27 2/27
0 4/5 1/5
1/2 1/2 0
1/2 2/5 1/10
'''
import math
def SourceEntropy(a,A):
'''
用于計算信源熵值(條件熵)
:param a: 信源的先驗概率向量
:param A:條件概率
:return: 信源熵
'''
sum=0
l=len(a)#a的元素個數,對應A的行數
for i in range(l):
for j in A[i]:
if j==0:
continue
else:
sum+=a[i]*j*math.log(j)
return -sum
if __name__=="__main__":
a=[9/27,16/27,2/27]
A=[[0,4/5,1/5],[1/2,1/2,0],[1/2,2/5,1/10]]
print('第一問答案:信源熵為'+str(SourceEntropy(a,A)))
B=[[1/3,1/3,1/3],[1/3,1/3,1/3],[1/3,1/3,1/3]]
print('第二問答案:信源最大熵為' + str(SourceEntropy(a, B)))
print('第三問答案:剩余度為'+str(1-SourceEntropy(a,A)/SourceEntropy(a, B)))
結果展示:
第一問答案:信源熵為0.6474323513133665
第二問答案:信源最大熵為1.0986122886681093
第三問答案:剩余度為0.4106816772473262
3.互資訊量和平均互資訊量的求解
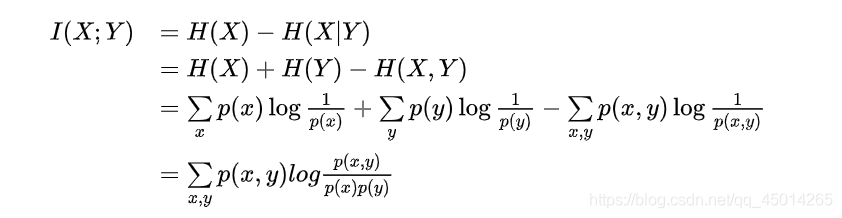
#Q3 互資訊量和平均互資訊量的求解
import math
import numpy as np
def MutualInformation(Px,Py,Pxy):
return Pxy*math.log2(Pxy/(Px*Py))
def AveMutualInformation(PM):
PM=PM/sum(sum(PM))
Px=[sum(PM[i][:]) for i in range(np.shape(PM)[0])]
Py=[sum(PM[:][i]) for i in range(np.shape(PM)[1])]
s=0
for i in range(len(Px)):
for j in range(len(Py)):
if Px[i]==0 or Py[j]==0 or PM[i][j]==0:
continue
else:
s+=MutualInformation(Px[i],Py[j],PM[i][j])
return s
if __name__=='__main__':
ProM=np.array([[1/2,1/2],[1/2,1/2]])
print('矩陣對應的互資訊量為'+str(AveMutualInformation(ProM)))
print(MutualInformation(1/2,1/2,1))
結果展示:
矩陣對應的互資訊量為0.0
2.0
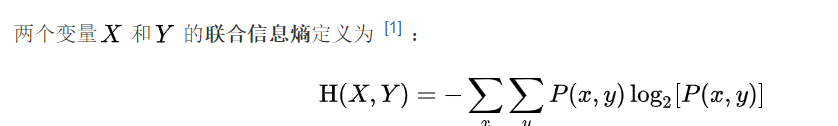
4.聯合熵的求解
已知信源X和信源Y的聯合概率,求解X和Y的聯合熵,
#Q4 已知信源X和信源Y的聯合概率,求解X和Y的聯合熵,
import numpy as np
import math
def JointEntropy(PM):
#先進行歸一化
PM=PM/sum(sum(PM))
s=0
for i in PM:
for j in i:
s+=j*math.log2(j)
return -s
if __name__=='__main__':
PM=np.array([[1/2,1/2],[1/2,1/2]])
print('上述概率矩陣對應的聯合熵為:'+str(JointEntropy(PM)))
結果展示為:
上述概率矩陣對應的聯合熵為:2.0
5.Kraft不等式的分析與判斷
給定信源符號個數,碼元進制數和碼長,判斷唯一可譯碼是否存在,
'''
5.Kraft不等式的分析與判斷
給定信源符號個數,碼元進制數和碼長,判斷唯一可譯碼是否存在
'''
if __name__=="__main__":
NumOfSource=int(input('信源符號個數:'))
Hex=int(input('碼元進制數:'))
Length=int(input('碼長:'))
if Hex**Length==NumOfSource:
print('存在唯一可譯碼,')
else:
print('不存在唯一可譯碼,')
結果展示:
信源符號個數:8
碼元進制數:2
碼長:3
存在唯一可譯碼,
信源符號個數:9
碼元進制數:2
碼長:4
不存在唯一可譯碼,
6.費諾編碼的分析與實作
給定信源各個符號及其發生概率,求解其費諾編碼的碼字,平均碼長和編碼效率,
'''
6.費諾編碼的分析與實作
給定信源各個符號及其發生概率,求解其費諾編碼的碼字,平均碼長和編碼效率
'''
import numpy as np
import math
import re
def Partition(lxh,N):
Norm_lxh=lxh/sum(lxh)
for i in range(len(lxh)):
if sum(Norm_lxh[:i+1])>=1/2:
if abs(sum(Norm_lxh[:i+1])-1/2)>=abs(sum(Norm_lxh[:i])-1/2):
return [[lxh[:i],lxh[i:]],[N[:i],N[i:]]]
else:
return [[lxh[:i+1],lxh[i+1:]],[N[:i+1],N[i+1:]]]
def Tree(lxh,N,filename):
if lxh.size==1:
print(N)
print(N,file=filename)
else:
print(Partition(lxh, N)[1])
print(Partition(lxh,N)[1],file=filename)
for i in range(len(Partition(lxh,N)[0])):
Tree(Partition(lxh,N)[0][i],Partition(lxh,N)[1][i],filename)
def AveLen(P,L):
sum=0
for i in range(len(P)):
sum+=P[i]*L[i]
return sum
def CodeEfficiency(H,L):
return H/L
def Entrify(P):
sum=0
for i in range(len(P)):
if P[i]!=0:
sum+=P[i]*math.log2(P[i])
return -sum
def BiCode(n,k):
#n為長度,k為序號
if k<=2**n:
infor=str(bin(k))
infor=infor[2:]
infor=int((n-len(infor)))*'0'+infor
return infor
else:
raise('編碼錯誤,碼樹無法生成!')
def FenoCode(Num):
Code=[]
for i in Num:
for k in range(0,int(2**i)):
for j in Code:
if re.match(BiCode(i,k),j) or re.match(j,BiCode(i,k)):
break
else:
Code.append(BiCode(i,k))
break
return Code
if __name__=='__main__':
file='recode.log'
mylog = open(file, mode='w', encoding='utf-8')
N=['A','B','C','D','E','F','G']
A=np.array([1/3,1/4,1/12,1/12,1/12,1/12,1/12])
Num=np.zeros(len(N))
Tree(A,N,mylog)
mylog.close()
with open(file,'r') as f:
Infor=f.read()
for i in range(len(Num)):
Num[i]+=Infor.count(N[i])-1
print('-'*30)
print('碼字為:')
Cod=FenoCode(Num)
print(Cod)
for i in range(len(A)):
print(N[i]+' '+str(round(A[i],3))+' '+Cod[i])
print('平均碼長為:'+str(round(AveLen(A,Num),3)))
print('編碼效率為:'+str(round(Entrify(A)/AveLen(A,Num),3)))
結果展示:
[['A', 'B'], ['C', 'D', 'E', 'F', 'G']]
[['A'], ['B']]
['A']
['B']
[['C', 'D'], ['E', 'F', 'G']]
[['C'], ['D']]
['C']
['D']
[['E', 'F'], ['G']]
[['E'], ['F']]
['E']
['F']
['G']
------------------------------
碼字為:
['00', '01', '100', '101', '1100', '1101', '111']
A 0.333 00
B 0.25 01
C 0.083 100
D 0.083 101
E 0.083 1100
F 0.083 1101
G 0.083 111
平均碼長為:2.583
編碼效率為:0.976
7.二進制哈夫曼編碼的分析與實作
給定信源各個符號及其發生概率,求解其二進制哈夫曼編碼碼字,平均碼長,及其編碼效率,
'''
7.二進制哈夫曼編碼的分析與實作
給定信源各個符號及其發生概率,求解其二進制哈夫曼編碼碼字,平均碼長,及其編碼效率,
'''
import numpy as np
import math
import re
def Join(P,N,filename):
if len(N)==1:
return None
else:
P=P/sum(P) #歸一化
P, N = (list(t) for t in zip(*sorted(zip(P, N))))
print(N[0], N[1], sep=' ')
print(N[0],N[1],sep=' ',file=filename)
P=[P[0]+P[1]]+P[2:]
#print(P)
N=[N[0]+' '+N[1]]+N[2:]
#print(N)
Join(P,N,filename)
return None
def AveLen(P,L):
s=0
for i in range(len(P)):
s+=P[i]*L[i]
return s
def CodeEfficiency(H,L):
return H/L
def Entrify(P):
sum=0
for i in range(len(P)):
if P[i]!=0:
sum+=P[i]*math.log2(P[i])
return -sum
def BiCode(n,k):
#n為長度,k為序號
if k<=2**n:
infor=str(bin(k))
infor=infor[2:]
infor=int((n-len(infor)))*'0'+infor
return infor
else:
raise('編碼錯誤,碼樹無法生成!')
def FenoCode(Num):
Code=[]
for i in Num:
for k in range(0,int(2**i)):
for j in Code:
if re.match(BiCode(i,k),j) or re.match(j,BiCode(i,k)):
break
else:
Code.append(BiCode(i,k))
break
return Code
if __name__=='__main__':
mylog = open('recode7.log', mode='w', encoding='utf-8')
P=np.array([0.4,0.2,0.2,0.1,0.1])
M=['a','b','c','d','e']
Join(P,M,mylog)
mylog.close()
Num=np.zeros(len(P))
with open('recode7.log','r') as f:
Infor=f.read()
for i in range(len(Num)):
Num[i]+=Infor.count(M[i])
print('-'*30)
print(Num)
print('碼字為:')
Cod = FenoCode(Num)
print(Cod)
for i in range(len(P)):
print(M[i] + ' ' + str(round(P[i], 3)) + ' ' + Cod[i])
print('平均碼長為:' + str(round(AveLen(P, Num), 3)))
print('編碼效率為:' + str(round(Entrify(P) / AveLen(P, Num), 3)))
結果展示為:
d e
b c
d e a
b c d e a
------------------------------
[2. 2. 2. 3. 3.]
碼字為:
['00', '01', '10', '110', '111']
a 0.4 00
b 0.2 01
c 0.2 10
d 0.1 110
e 0.1 111
平均碼長為:2.2
編碼效率為:0.965
文稿:錦帆遠航
代碼:錦帆遠航
圖片:百度圖片
你的支持(三連)是航航堅持下去的不懈動力哦!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/272162.html
標籤:AI
上一篇:植物大戰僵尸 修改存檔和金錢