OCR,光學字符識別(OPTICAL CHARACTER RECOGNITION),作為計算機視覺領域的經典問題之一
它指對影像中的文字進行檢測識別(包括文字檢測+文字識別),并獲取文本的結果,常見于拍照檢查、檔案識別、證照票據識別、車牌識別、自然場景下的文本定位識別等,相關技術在數字時代得到了廣泛的應用,
如下圖是OCR識別結果:
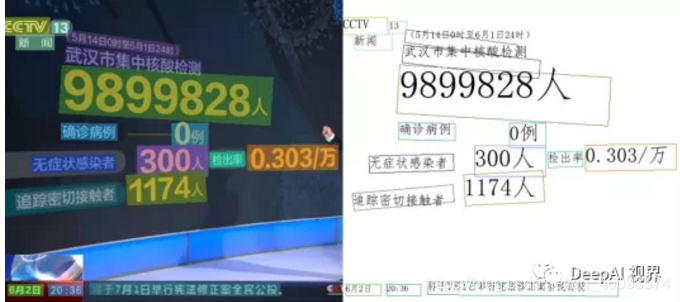
作為計算機視覺領域的OCR識別在訓練的時候當然也會需要大量的圖片資料來供神經網路的學習,一般需要數以千萬計的圖片才能訓練一個文字識別系統,才能達到識別文字的目的,但是如果采用人工標注會浪費大量的人力財力,導致入不敷出,本文接下來介紹一種能夠根據場景生成大量的文字圖片的工具,
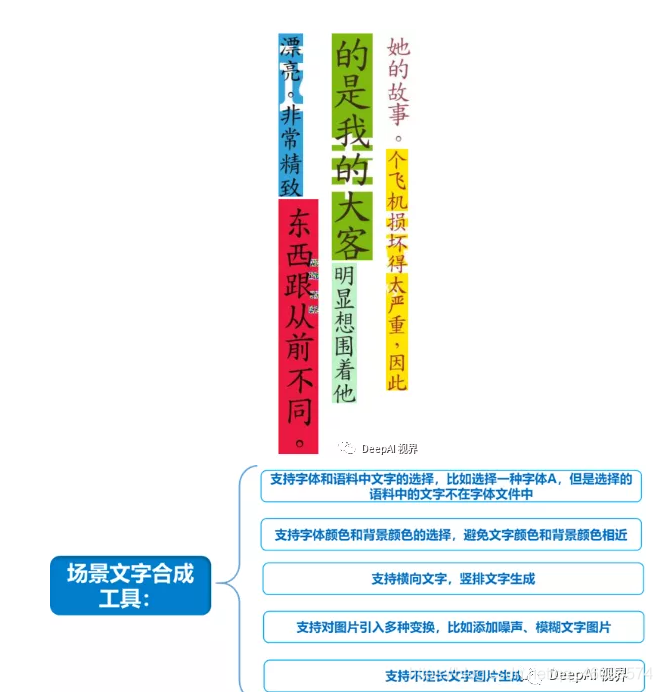
一、總體預覽,它主要具有如下功能:
- 生成橫、豎排文字,
- 生成彩色圖片的文字圖,
- 能夠選擇生成文字的語料,
- 能夠生成定長或者不定長的文字圖片,
- 對生成的文字圖片引入多種變換,比如增加文字的隨機傾斜角度,模擬小圖放大,大圖放小,上下左右運動模糊等功能,


話不多說,先上圖展示一波文字合成的效果,如下是生成圖片的效果展示:
圖片
橫排文字:

二、模塊決議
場景文字合成工具,它具體包括如下幾個模塊,字符選擇單元,字體選擇單元,背景圖片選擇單元,字體顏色選擇單元,以及資料增強單元,
第一, 構建字典檔案,首先是要根據自己的場景文字,確定要生成哪些字符到圖片上,建立一個生成字符的字典檔案,
圖片第二, 構建語料檔案,由于文字識別一般會采用雙向的LSTM來對語料進行學習,這樣通過前后文的語意資訊提高文字識別的準確率,所以需要一個具有語意資訊的語料檔案(語料檔案需要和場景類似),
- 獲取語料檔案以后,需要對語料檔案進行字符過濾,過濾掉不在字典檔案中的字符,
圖片2. 語料的切分,經過字符的過濾以后,確保語料中的字符都會出現在字典檔案中,接下來就需要進行語料的切分,切分成定長或者是不定長的語料,字符長度一般設定在1-25以內
elif mode == 'split':
corpus = []
with codecs.open(output, mode='r', encoding='utf-8') as f:
# 按行讀取語料
print('正在讀取語料...')
for line in f:
corpus.append(line)
with codecs.open('split_sentences.txt', mode='w', encoding='utf-8') as output:
widgets = ["正在分行語料: ", progressbar.Percentage(), " ", progressbar.Bar(), " ", progressbar.ETA()]
pbar = progressbar.ProgressBar(maxval=len(corpus), widgets=widgets).start()
for i, line in enumerate(corpus):
row = line
# if np.random.randint(0, 1000) < 2: # 0.2%的概率加空白行
# output.write('\n')
# 對大于max_row_len的句子進行分行,直到最后小于max_row_len
while len(row) > max_row_len:
# 長句子分行
# 偶爾出現單字
spliter = np.random.random_integers(1, max_row_len-1)
output.write(row[0:spliter] + '\n')
# if np.random.randint(0, 1000) < 2: # 0.2%的概率加空白行
# output.write('\n')
row = row[spliter:]
#每行會含有一個換行符,去掉換行符
if len(row)>=6:
re_punctuation = "[{}]+".format(punctuation)
row = re.sub(re_punctuation, "", row)
if len(row)>=6:
output.write(row)
pbar.update(i)
pbar.finish()
- 經過字符過濾,語料分割以后生成的語料檔案格式如下:
圖片
第三, 字體檔案的選擇,比如你想在圖片上生成楷體、宋體或明體等,需要你下載字體檔案,當然在我的github上,我收集整理了700多種字體,有需要的可以自行下載,
圖片
- 由于每個字體檔案所支持的字符種類不一樣,如果不加判斷的直接使用該字體,如果字典中的字符正好該字體不支持的字符,那么生成的圖片上就不會顯示該字符,出現亂碼或者是空字符的情況,在本代碼中采用了加了判斷,會防止以上情況的發生,具體可以詳細的精度代碼,
- 如下是代碼中的對每個加載的字體檔案支持的字符進行顯示,

第四, 圖片背景的選擇,此時仍然需要你根據自己的場景來收集背景圖片,將其存入檔案夾中,比如你做的是車牌識別,那么你的背景圖片基本就是藍色、綠色等,你只需要收集這和這類背景圖相似的放入檔案夾即可,

第五, 字體顏色的生成,你可以設定生成文字的字體顏色,假設你的場景中的文字只有白色,那么你只需要設定成白色字體即可,當然如果你的場景是自然場景,什么樣子的字體顏色都有,這個時候就需要使用本文提出的演算法來解決這類問題,防止字體的顏色和背景的顏色相近,導致生成的圖片無用情況,
- 本代碼對字體顏色的選擇采用了kmeans聚類的方法,首先對背景進行設定聚類中心,加載彩色圖片的字體顏色庫,該顏色庫包含9882中字體顏色,計算每個聚類中心和當前所選取顏色距離的標準差之和,隨機選擇顏色距離的標準差較大的100種顏色作為字體的顏色,可以有效防止了背景顏色和字體顏色相近的情況,
第六,如下圖是根據以上各個模塊生成的文字圖片,

最后附上Github 原始碼:
https://github.com/zcswdt/Color_OCR_image_generator
這么好的東西,記得star哦~
有任何疑問,歡迎下方公眾號聯系我~(公眾號有大量好文和百份AI資料哦)

最全的深度學習資料分享、最前沿的AI科技分享、深度學習技術交流群、計算機視覺與自然語言處理方向實戰專案與原始碼分享~
附贈我的csdn,歡迎來看實戰文~
https://blog.csdn.net/qq_46098574
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/272164.html
標籤:AI