為什么這期要叫暴力爬蟲呢?因為筆者認為基于selenium方法非常的簡單粗暴!!理由有兩點:
1.在selenium方法下,我們可以通過呼叫瀏覽器驅動來實作模擬滑鼠點擊、滑輪下滑以及輸入文本等操作,就像真正的用戶正在操作瀏覽器一樣(如此一來便可以解決某些需要用戶登錄才能獲取界面的網站),而且在訪問網站層面,它的安全性是高于requests方法的,因為它不需要構造一個虛擬請求,所有的操作都是真實發生的,
2.selenium獲取網頁資訊的方法是基于網頁的elements而不是network,網頁的編排規則一般是:network 下顯示了服務器回應給瀏覽器的檔案,這些檔案可能包含html、json等格式,瀏覽器拿到這些檔案后,組裝成 elements,顯示出來,簡單理解為,elements是封裝得最好的資訊,我們在網頁上看得到的,elements中都有,即“所見即可得”,在這種情況下,獲取到的資料文本就不需要再經過復雜的決議,
目前selenium只支持通過Firefox和Chrome兩款瀏覽器進行操作,本文以Firefox為例進行介紹,
安裝Firefox驅動
根據作業系統下載Firefox驅動的壓縮包,Firefox驅動的中文下載網站:https://liushilive.github.io/github_selenium_drivers/md/Firefox.html
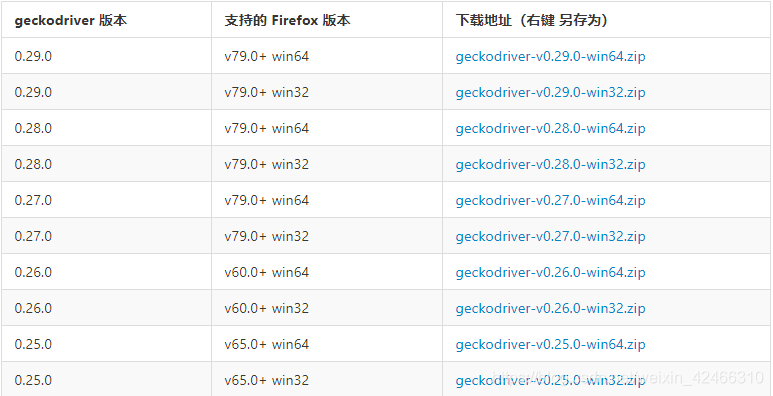
下載好壓縮包后,解壓得到geckodriver.exe檔案,將該檔案安裝到Python的環境檔案夾中site-packages,也可以單獨對該檔案配置環境變數,具體的配置方法請參考這篇文章:https://blog.csdn.net/eerty2588/article/details/107041770
匯入selenium的相關方法
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains ##引入ActionChains滑鼠操作類
設定目標內容,分析網站結構***
需求場景:因為今年是建dang百年,筆者想去dang的出生地‘’嘉興南湖‘’旅游,所以想先到微博上看看相關的評價,
我們以mobile端的微博為例(網站地址:https://m.weibo.cn/)對#嘉興南湖#下的內容進行爬取,首先手工打開網頁模擬一遍操作流程:
1.打開網頁,得到首頁資訊
微博mobile版的首頁如下,網頁最上端即搜索欄

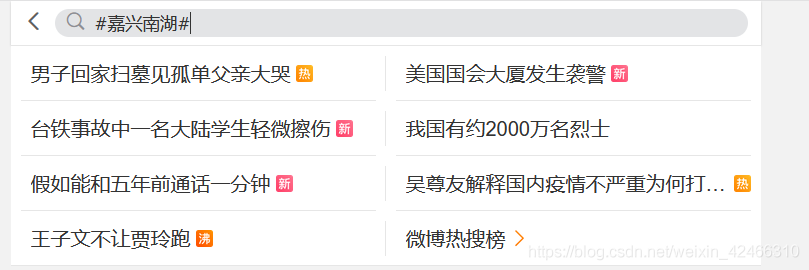
2.用滑鼠點擊搜索欄,輸入搜索內容
然而我們發現,這個搜索欄并不是直接可以輸入文本的,我們需要用滑鼠點一下,進入到如下圖所示的這一個輸入界面,在這個輸入框中,可以直接敲鍵盤輸入‘#嘉興南湖#’的內容,之后再敲一下鍵盤上的回車,
3.分析話題下的用戶內容***
敲回車之后得到的頁面是這樣的,微博默認以“綜合”評價的方式對用戶資料進行排列,但我們想以時間的順序有先有后地來瀏覽用戶評論內容,因此點擊“實時”按鈕,
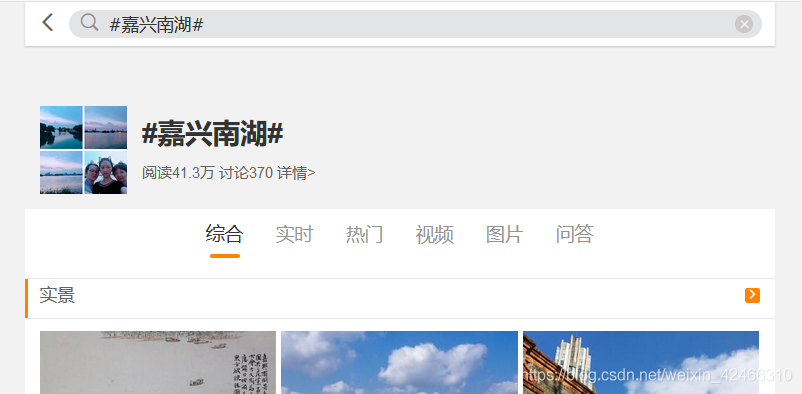
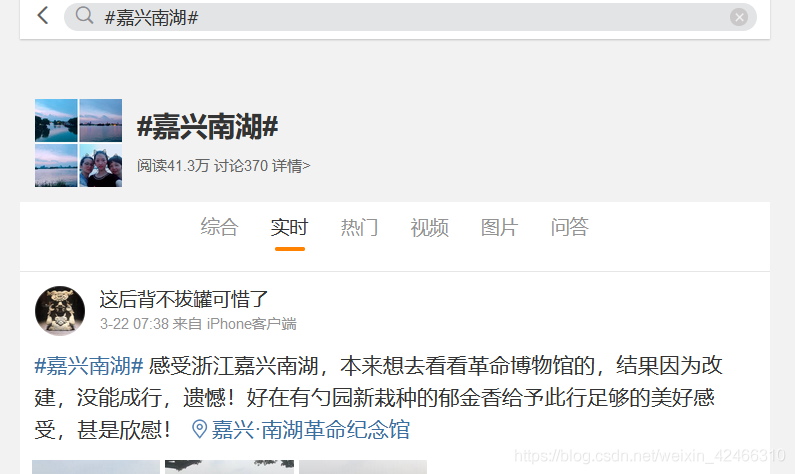
得到在以時間先后順序排列下的用戶內容呈現界面,接下來就是去定位用戶的評論資訊,我們發現:一個用戶的評論,由以下幾個部分組成:
①用戶名
②發布時間
③發布工具(手機型號或者網頁型別)
④評論內容
⑤所附圖片
⑥轉發數
⑦評論數
⑧點贊數
由于圖片無法直接獲取顯示到Python的console中,因此我們決定爬取用戶名、發布時間、發布工具、評論內容、轉發數、評論數和點贊數這幾個方面的資訊,

4.翻頁獲取新內容***
確定了要獲取內容后,并不是萬事大吉了!因為我們不確定當前頁面是否包含了所有的評論資訊,所以先把頁面滑輪拉到頁面底端,果然出現了一個加載中…,這意味著在微博動態頁面加載的技術框架下,當前頁面并沒有包含所有評論內容,需要我們不斷地下滑滑輪到頁面底端,獲取到新的微博內容,最后,在下翻了N多次之后,終于找到了最早的一篇微博,發表在2010年的10月8日,此時即使把滑輪滑到底部,微博也不會再加載出新的頁面,這時候,我們所處的頁面已經包含了#嘉興南湖#話題之下的所有內容!!! 接下來便總結一下我們所需要做的作業,
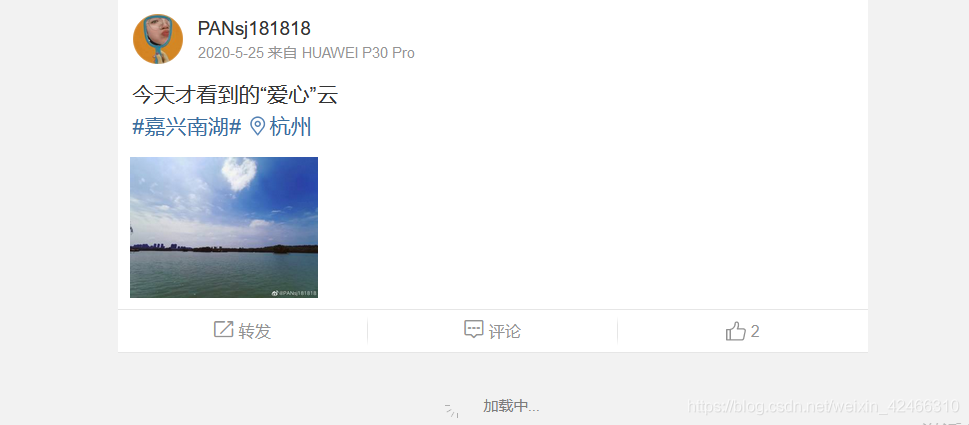
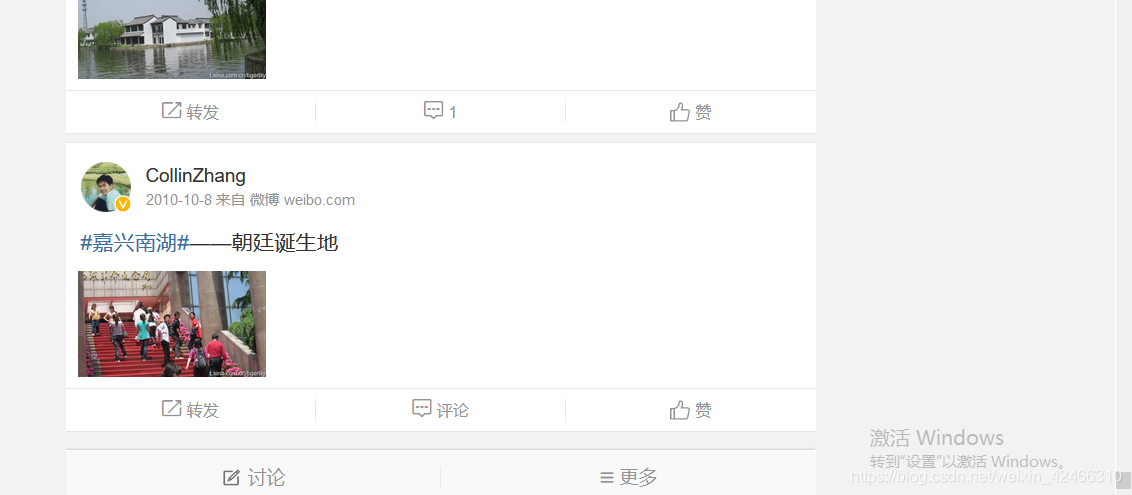
總結所需要做的作業
1.需要模擬登陸網頁,可以通過selenium庫中的webdriver方法來構造driver變數實作,
driver=webdriver.Firefox()
driver.get('https://m.weibo.cn/')
2.需要實作模擬滑鼠分別點擊剛進去微博首頁的搜索欄、以及在#嘉興南湖#話題之下的實時按鈕,這一步通過呼叫click()方法實作,具體步驟是:①通過selenium的find_elemens_by_xpath/id/css/class_name等方法定位搜索欄和實時按鈕所屬地址;②通過click()方法點擊
driver.find_element_by_class_name('m-search').click() #模擬滑鼠點擊微博首頁搜索欄
driver.find_element_by_xpath('/html/body/div[1]/div[1]/div[1]/div[3]/div[2]/div[1]/div/div/div/ul/li[2]/span').click() #模擬滑鼠點擊實時按鈕
3.需要實作模擬鍵盤輸入內容并敲回車鍵,這一步通過send_keys()方法實作,輸入文本的步驟就是找到輸入框地址,然后send_keys("【文本內容】"),模擬回車鍵則是send_keys(Keys.ENTER),
driver.find_element_by_xpath('/html/body/div/div[1]/div[1]/div[1]/div/div/div[2]/form/input').send_keys('#嘉興南湖#') #找到輸入框地址并輸入#嘉興南湖#
driver.find_element_by_xpath('/html/body/div/div[1]/div[1]/div[1]/div/div/div[2]/form/input').send_keys(Keys.ENTER) #模仿敲下回車鍵
4.需要滑動滑輪至頁面底端
這個沒什么好說的,直接上執行代碼,執行一次,滑輪自動滑到頁面底端,等微博內容加載完畢之后,再執行一次,重復上述操作,
driver.execute_script("window.scrollTo(0,document.body.scrollHeight);")
5.需要定位每一篇微博內容構成元素的地址:這里為了方便,我們皆以xpath的方法進行定位,這里推薦一個定位xPath的神器——xPath Finder,可從Firefox插件市場下載并進行拓展,用了這個插件后,用滑鼠點擊網頁特定的元素,就會自動地在頁面左下角顯示該元素的xPath,可大大提高作業效率,

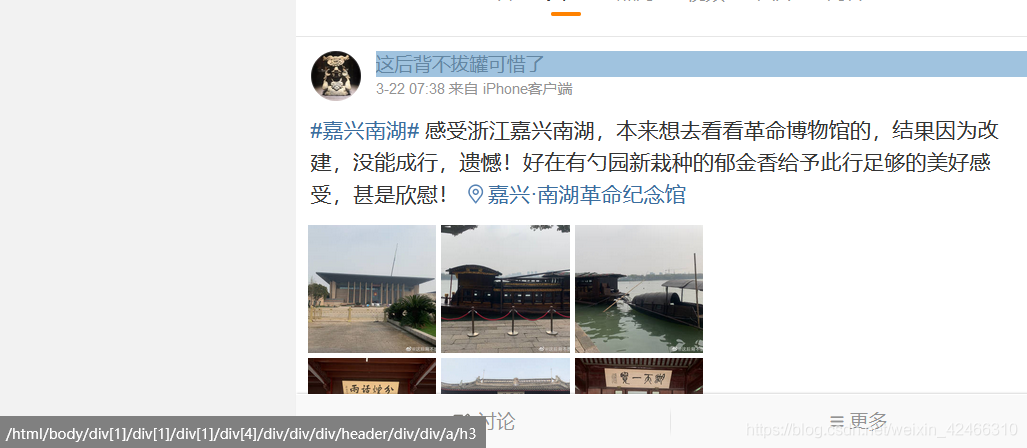
在定位好各元素的xPath之后,就可以分別獲取并將其賦值變數,注意,這里用的是find_elements_by_xpath方法而不是find_element_by_xpath,因為筆者發現find_element_by_xpath通常無法獲取到正確內容,正因為如此,獲取到的目標是一個串列型資料,需要在后面加上一個[0].text以得到內容,
##獲取第一篇微博中的各個元素資訊##
headers=driver.find_elements_by_xpath('/html/body/div[1]/div[1]/div[1]/div[4]/div/div/div/header/div/div/a/h3')[0].text
date=driver.find_elements_by_xpath('/html/body/div[1]/div[1]/div[1]/div[4]/div/div/div/header/div/div/h4/span[1]')[0].text
phone=driver.find_elements_by_xpath('/html/body/div[1]/div[1]/div[1]/div[4]/div/div/div/header/div/div/h4/span[2]')[0].text
content=driver.find_elements_by_xpath('/html/body/div[1]/div[1]/div[1]/div[4]/div/div/div/article/div/div[1]')[0].text
zhuanfa=driver.find_elements_by_xpath('/html/body/div[1]/div[1]/div[1]/div[4]/div/div/div/footer/div[1]/h4')[0].text
pinglun=driver.find_elements_by_xpath('/html/body/div[1]/div[1]/div[1]/div[4]/div/div/div/footer/div[2]/h4')[0].text
dianzan=driver.find_elements_by_xpath('/html/body/div[1]/div[1]/div[1]/div[4]/div/div/div/footer/div[3]/h4')[0].text
重難點
1.如何判斷滑輪已經翻到頁面底部?
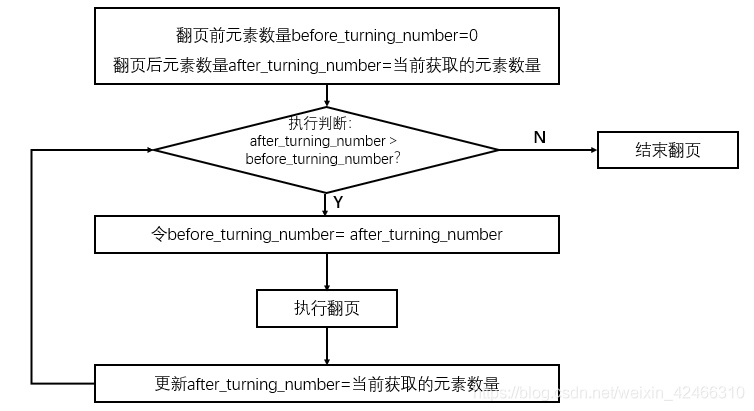
對于這個問題,筆者的解決辦法是去拿執行翻頁操作之前微博內容對應的class_name或者id_name數量和執行完翻頁操作之后的數量做比較,如果在執行完翻頁之后,發現后者數量大于前者,說明這一個翻頁是有效的,如果發現二者數量依然相等,說明翻頁已經到了頁面最低端,不需要再進行翻頁了,為了方便理解,演算法規則如下圖所示,在最后的實作代碼中,我是以每一個微博內容所對應的class_name"weibo-text" 來作為變數進行計算的,
2.如何設計爬取微博內容的回圈結構
我們觀察第一篇微博內容的xpath是
’/html/body/div[1]/div[1]/div[1]/div[4]/div/div/div/article/div/div[1]’,
用xPath_Finder再點一下第二篇微博內容,xpath變為了
’/html/body/div[1]/div[1]/div[1]/div[5]/div/div/div/article/div/div[1]’,
那么便可以認為,決定微博內容順序的標簽在第四個div[]中,并且順序排列是以4為初始數值,之后每一篇微博數值遞增1的方法去實作,那么在最終的程式實作中,只需要構建類似一個for i in range(4,xxx):div[+str(i)+] 的回圈便可以實作,對于range的上限,正常的思路是通過計算頁面中每一篇微博所對應的class_name數量確定總數,但是筆者實踐下來發現這個數目其實并不太對,因此我解決的思路有點笨:通過判定執行出錯的次數來判定微博是否已經提取完畢,如果提取完畢后,依然執行driver.find_elements_by_xpath,這時候程式就會報錯,每報錯一次,通過try except 的方法執行累加計算,累計報錯次數就+1,設定一個小的閾值(比如5),當報錯達到5次之后,就退出回圈結束程式,這樣一來初始上限可以大膽地設定為任意一個超級大的數,比如1000000,
專案代碼實作
完整程式和相關注釋如下
from selenium import webdriver
import time
import pandas as pd
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains ##引入ActionChains滑鼠操作類
def get_comments_from_weibo():
driver=webdriver.Firefox() #呼叫Firefox瀏覽器
#driver.set_headless() #無頁面顯示操作,為了方便觀察程式運行狀態,這個可以不加
driver.get('https://m.weibo.cn/') #訪問微博頁面
time.sleep(2) #設定一個休息時間,模擬人類正常的訪問操作,也給頁面留出足夠的加載時間,下同
driver.find_element_by_class_name('m-search').click() #點擊搜索欄
time.sleep(2)
driver.find_element_by_xpath('/html/body/div/div[1]/div[1]/div[1]/div/div/div[2]/form/input').send_keys('#嘉興南湖#') #在輸入框中輸入#嘉興南湖#
time.sleep(1)
driver.find_element_by_xpath('/html/body/div/div[1]/div[1]/div[1]/div/div/div[2]/form/input').send_keys(Keys.ENTER) #模仿回車鍵輸入
time.sleep(3)
driver.find_element_by_xpath('/html/body/div[1]/div[1]/div[1]/div[3]/div[2]/div[1]/div/div/div/ul/li[2]/span').click() #點擊實時按鈕
time.sleep(3)
before_turning_number=0
global weibo_df
weibo_df=pd.DataFrame(columns=['headers','date','phone','content','zhuanfa','pinglun','dianzan']) #設定一個用戶存盤獲取內容的df
after_turning_number=len(driver.find_elements_by_class_name('weibo-text'))
row_number=0
error_number=0 #設定初始錯誤次數為0
##翻頁到底程式段##
while after_turning_number>before_turning_number:
before_turning_number=after_turning_number
driver.execute_script("window.scrollTo(0,document.body.scrollHeight);") #執行下滑滑輪到底端操作
time.sleep(3) #執行翻頁后的等待時間可以結合自身的網路情況適當延長
after_turning_number=len(driver.find_elements_by_class_name('weibo-text'))
else:
print('翻頁結束')
time.sleep(3)
##抽取用戶資訊、用戶評論內容程式段##
for i in range(4,1000000):
if error_number<5: #當錯誤次數小于5時,執行獲取微博內容的命令
try:
headers=driver.find_elements_by_xpath('/html/body/div[1]/div[1]/div[1]/div['+str(i)+']/div/div/div/header/div/div/a/h3')[0].text
date=driver.find_elements_by_xpath('/html/body/div[1]/div[1]/div[1]/div['+str(i)+']/div/div/div/header/div/div/h4/span[1]')[0].text
phone=driver.find_elements_by_xpath('/html/body/div[1]/div[1]/div[1]/div['+str(i)+']/div/div/div/header/div/div/h4/span[2]')[0].text
content=driver.find_elements_by_xpath('/html/body/div[1]/div[1]/div[1]/div['+str(i)+']/div/div/div/article/div/div[1]')[0].text
zhuanfa=driver.find_elements_by_xpath('/html/body/div[1]/div[1]/div[1]/div['+str(i)+']/div/div/div/footer/div[1]/h4')[0].text
pinglun=driver.find_elements_by_xpath('/html/body/div[1]/div[1]/div[1]/div['+str(i)+']/div/div/div/footer/div[2]/h4')[0].text
dianzan=driver.find_elements_by_xpath('/html/body/div[1]/div[1]/div[1]/div['+str(i)+']/div/div/div/footer/div[3]/h4')[0].text
weibo_df.loc[row_number]=[headers,date,phone,content,zhuanfa,pinglun,dianzan]
row_number=row_number+1
except:
error_number=error_number+1 #錯誤次數加1
continue #繼續執行回圈
else:
break
get_comments_from_weibo()
得到的結果如下
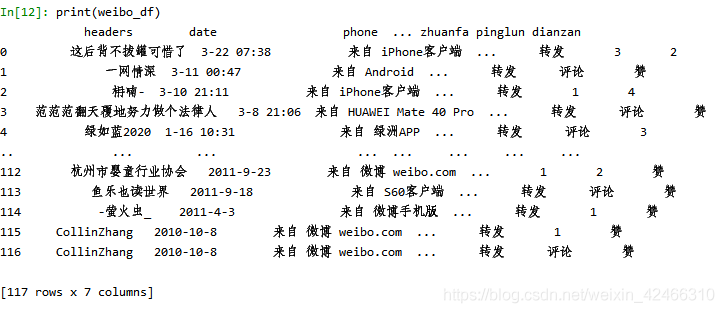

根據以上所得到的的內容便可以進行進一步的詞頻統計和語意關聯分析等文本分析,在此就不再贅述,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/272605.html
標籤:AI