文章目錄
- 一、Linux 作業系統的安裝
- 二、在 Ubuntu 20.04.2.0 中 進行 Hadoop 偽分布式安裝
- 1、Ubuntu 20.04.2.0 安裝 jdk
- 2、配置 SSH 無密碼登錄
- 3、Hadoop 的下載與安裝
- 4、Hadoop 環境配置
- 5、啟動與關閉 Hadoop
- 6、查看 Hadoop 的基本資訊
- 6.1、查看 HDFS Web 界面
- 6.2、查看 YARN Web 界面
- 三、在 Centos7 中 進行 Hadoop 偽分布式安裝
一、Linux 作業系統的安裝
- 2021年 全網最細 Windows 系統安裝虛擬機Vmware15 及 CentOS7系統和遠程登錄
- 2021年全網最細 VirtualBox 虛擬機安裝 Ubuntu 20.04.2.0 LTS及Ubuntu的相關配置
二、在 Ubuntu 20.04.2.0 中 進行 Hadoop 偽分布式安裝
在安裝 Hadoop 之前,需要先安裝兩個程式,分別為:
(1) JDK,Hadoop 使用的是 Java 寫的程式,Hadoop 的編譯及 MapReduce 的運行都需要使用 JDK,因此在安裝 Hadoop 之前,必須先安裝 JDK,
(2) SSH(安全外殼協議),推薦安裝 OpenSSH,Hadoop 需要通過 SSH 無密碼連接 Slave 串列中各臺主機的守護行程,因此 SSH 也是必須安裝的,
本節介紹 JDK 的檢查與安裝,
1、Ubuntu 20.04.2.0 安裝 jdk
在安裝 JDK 之前,可以首先檢查一下系統是否安裝了 JDK,檢查方法如下,打開終端,輸入以下內容,來檢查 JDK 是否可用:
javac
如果沒有安裝 JDK 的話,執行結果如下圖所示:
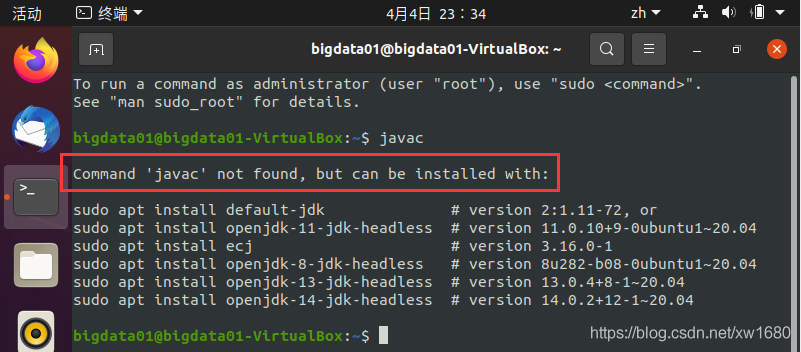
如果上述命令回傳 Command 'java' not found 或者類似的錯誤,這時需要下載并安裝 JDK,本篇博文用的 jdk 版本為:jdk-8u202-linux-x64.tar.gz,如果讀者要安裝其他版本的 jdk,可以自行到官網進行下載,jdk 下載比較簡單,這里博主就不再贅述,不想下載也可以直接從下面的網盤中進行獲取,鏈接如下:
鏈接:https://pan.baidu.com/s/1M_uFasC58iLB5HtzmnZWdQ
提取碼:i8yt
復制這段內容后打開百度網盤手機App,操作更方便哦--來自百度網盤超級會員V6的分享
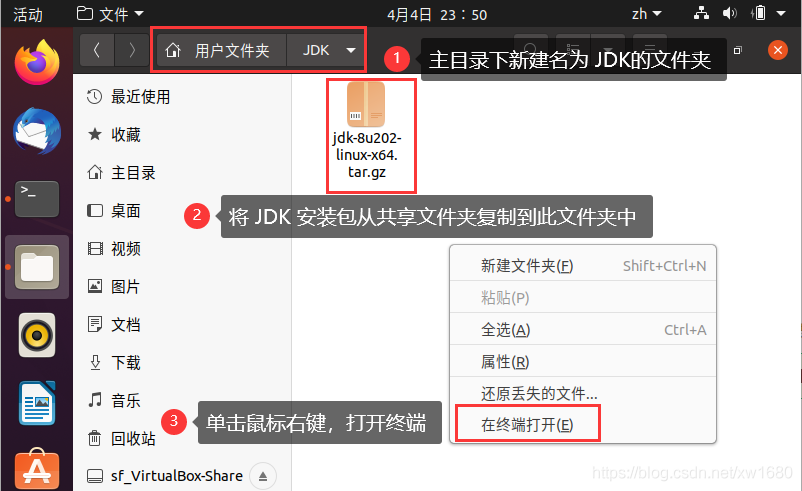
(1) 將下載好的 JDK 安裝包放到共享檔案夾中 (在 2021年全網最細 VirtualBox 虛擬機安裝 Ubuntu 20.04.2.0 LTS及Ubuntu的相關配置 一文中詳細介紹了如何設定了共享檔案夾,博主 Windows 10 系統的共享檔案夾路徑為 D:\VirtualBox-Share,Ubuntu 系統中的共享檔案夾名為 sf_VirtualBox-Share)
然后在 Ubuntu 系統的 home 目錄(也稱為主目錄)下,新建檔案夾名為 JDK,將 JDK 安裝包復制此 JDK 檔案夾中,復制好之后,在此檔案夾空白處單擊滑鼠右鍵,選擇 在終端打開,打開終端,如下圖所示:
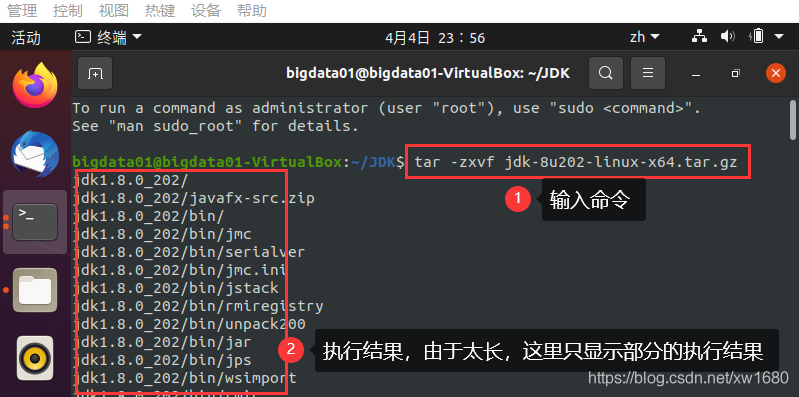
(2) 解壓 JDK 安裝包,將安裝包 jdk-8u202-linux-x64.tar.gz 解壓到當前檔案夾,命令如下:
tar -zxvf jdk-8u202-linux-x64.tar.gz
命令及執行結果如下圖所示:
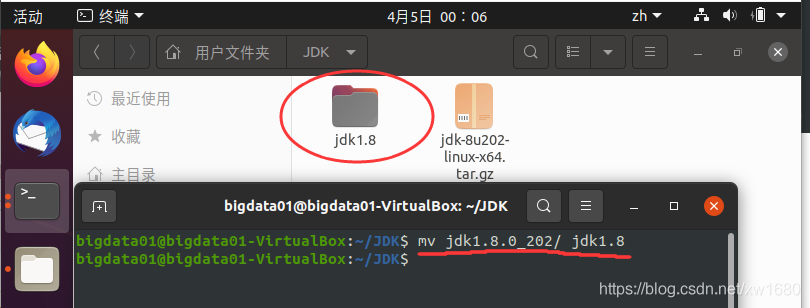
解壓完成后,在當前檔案夾中,得到名為 jdk1.8.0_191 的檔案夾,為了后期設定環境變數更加方便,將名字重命名為 jdk1.8,如下圖所示:
說明:解壓即安裝,
(3) 設定環境變數,編輯組態檔,首先需要打開組態檔,然后將環境變數添加到檔案末尾,
在終端輸入如下命令,打開組態檔,
sudo gedit /etc/profile
然后按照提示,輸入 root 用戶的密碼,輸入密碼后,敲擊回車進入檔案編輯界面,如下圖所示:
將下面的命令輸入到組態檔中:
export JAVA_HOME=/home/bigdata01/JDK/jdk1.8
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
注意,JAVA_HOME 后面的為解壓后的 JDK 檔案夾,讀者需要根據實際情況進行修改,組態檔修改完成后,Ctrl + s 即可保存然后退出,重新加載組態檔,命令如下:
source /etc/profile
驗證是否安裝 JDK 成功,輸入如下命令查詢 JDK 版本:
java -version
執行結果如下圖所示:
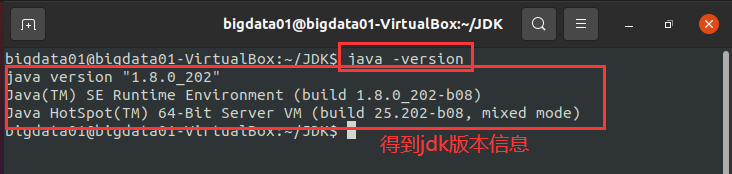
如上圖所示的執行結果中,顯示了 JDK 的版本資訊,則說明 JDK 安裝成功,
說明:也可以使用 sudo vi /etc/profile 命令打開組態檔,然后按照提示,輸入 root 用戶的密碼,輸入密碼后,敲擊回車進入檔案編輯界面,使用快捷鍵 <Shift+g> 將游標移到檔案末尾,按 i 鍵進入編輯狀態,將上面的命令輸入到組態檔中,組態檔修改完成后,按 Esc 退出編輯狀態,輸入 :wq 命令,敲擊回車之后即可保存并退出,最后重新加載組態檔即可,
2、配置 SSH 無密碼登錄
SSH 為 Secure Shell 的縮寫,即安全外殼協議,為建立在應用層基礎上的安全協議,Hadoop 使用 SSH 連接,這是目前較為可靠,專為遠程登錄其他服務器提供的安全性協議,通過 SSH 會對所有傳輸的資料進行加密,利用 SSH 協議可以防止遠程管理系統時資訊外泄的問題,
Hadoop 是由很多臺服務器組成的,當啟動 Hadoop 時,NameNode 必須與 DataNode 連接并管理這些節點(DataNode),此時系統會要求用戶輸入密碼,為了讓系統順利運行而不用手動輸入密碼,可以將 SSH 設定為無密碼登錄,
注意:無密碼登錄不是不需要密碼,而是使用 SSH Key 來進行身份驗證,
1、安裝SSH
打開終端,輸入命令:sudo apt-get install ssh
在輸入 Y 或 y 后,系統會自動安裝 SSH,安裝完成如下圖所示:
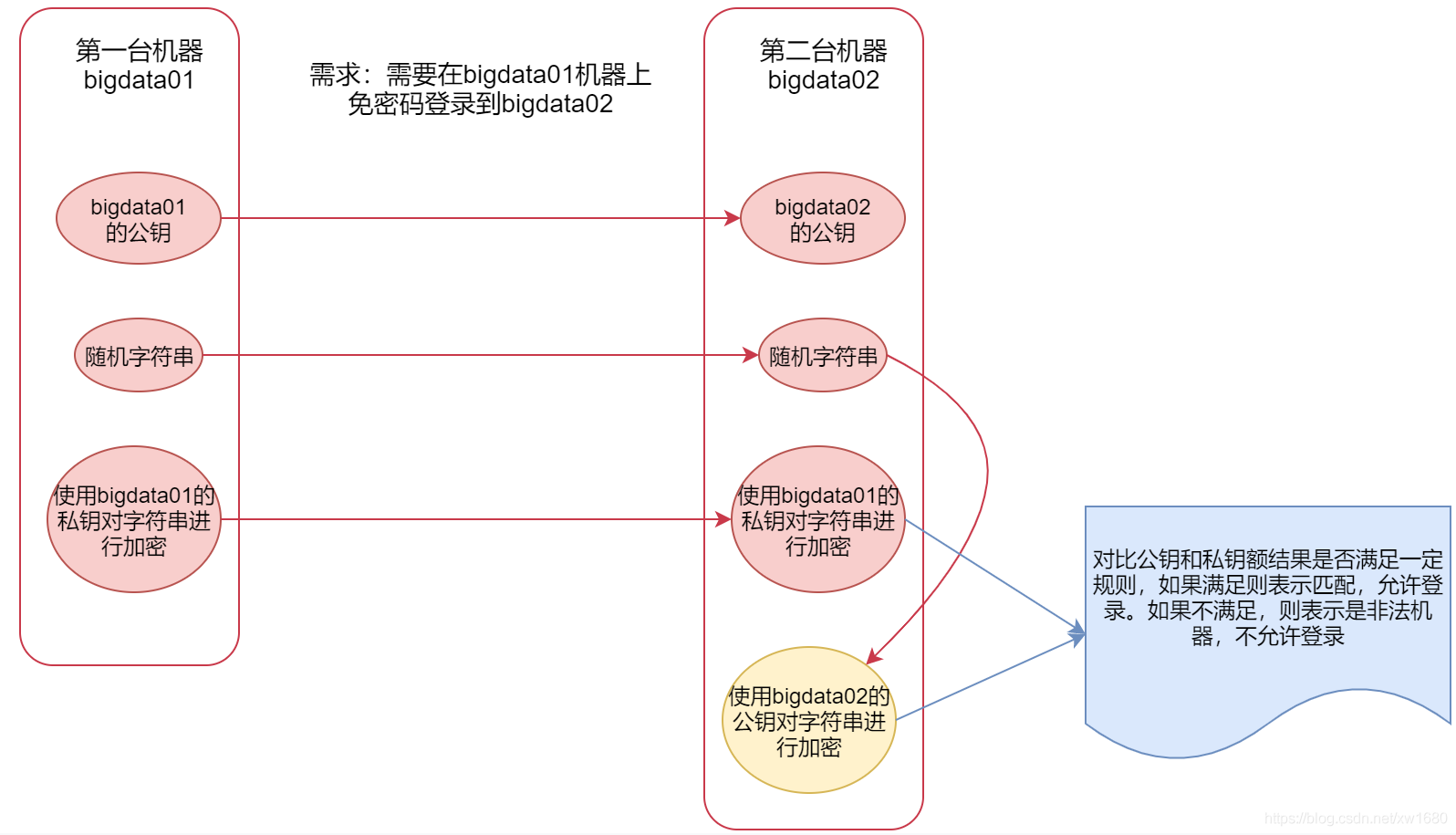
2、SSH 無密碼登錄的原理
在配置 SSH 之前,首先介紹一下 SSH 免密登錄的原理,以 Server A 要免密登錄 Server B 為例,如下圖所示:
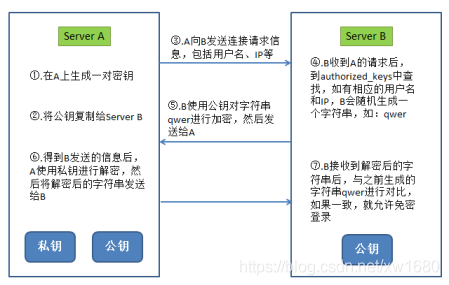
3、配置 SSH 無密碼登錄
-
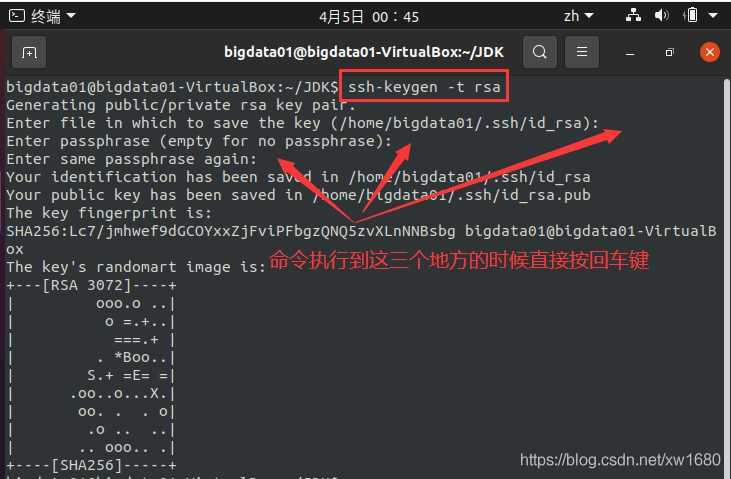
產生 SSH Key,接著在終端輸入命令:ssh-keygen -t rsa,注意:注意ssh-keygen后引數的大小寫,比如“-t”與“-T”表示不同意思,其中,ssh-keygen代表生成密鑰;-t表示生成指定型別的密鑰型別;rsa是rsa密鑰認證,
此條命令運行后出現暫停時,按回車鍵即可,并且會產生兩個密鑰檔案,即在 .ssh 檔案夾(此檔案夾在用戶的根目錄下,即 /home/bigdata01) 下創建 id_rsa 和 id_rsa.pub 兩個檔案,這是 SSH 的一對私鑰和公鑰,類似于鑰匙和鎖,下面要做的就是把 id_rsa.pub(公鑰)放到許可證檔案中去,
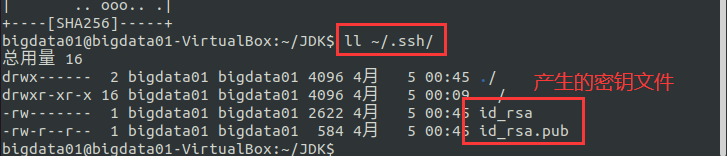
使用ll ~/.ssh查看產生的 SSH Key(密鑰):
-
將 id_rsa.pub(公鑰) 放到許可證檔案(authorized_keys)中,命令:cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
-
更改權限,命令如下:
chmod 755 ~ chmod 700 ~/.ssh chmod 600 ~/.ssh/authorized_keys -
驗證 SSH 是否安裝成功,以及是否可以免密碼登錄本機,首先,驗證SSH是否安裝成功,輸入命令:ssh -Version,執行結果如圖所示:
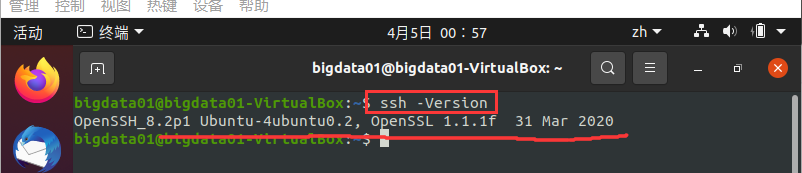
出現上圖所示的執行結果,則表示 SSH 安裝成功,注意:命令“ssh -Version”中的V是大寫的 -
接下來,驗證是否可以免密碼登錄本機,命令:ssh bigdata01-VirtualBox,執行結果如下圖所示:
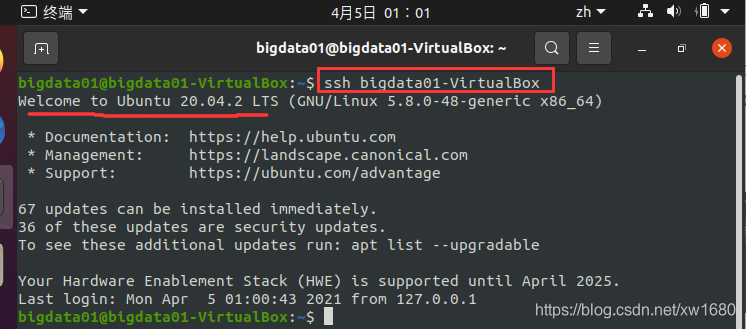
說明:bigdata01-VirtualBox 為筆者的主機名,讀者可以使用 hostname 命令查看自己的主機名,如上圖所示,沒有要求輸入登錄密碼,則表示 SSH 已經成功實作無密碼登錄了, -
退出 SSH 連接,代碼如下:exit,執行結果如下圖所示:

說明:在 Hadoop 的安裝程序中,是否無密碼登錄不是特別重要的,但是如果不配置無密碼登錄,每次啟動 Hadoop 都需要輸入密碼來登錄到每臺機器的 DataNode 上,但是 Hadoop 集群動輒擁有數百或上千臺機器,因此一般來說都會配置 SSH 的無密碼登錄,
3、Hadoop 的下載與安裝
在介紹 Hadoop 的安裝之前,先介紹一下 Hadoop 對各個節點的角色定義,
Hadoop 可以分別從三個角度將主機劃分為兩種角色,第一,最基本的劃分為 Master 和 Slave,即主人與奴隸;第二,從 HDFS 的角度,將主機劃分為 NameNode 和 DataNode(在分布式檔案系統中,目錄的管理很重要,管理目錄相當于主人,而 NameNode 就是目錄管理者);第三,從 MapReduce 的角度,將主機劃分為 JobTracker 和 TaskTracker(一個 Job 可以劃分為多個Task),
1、Hadoop的安裝模式
Hadoop 有三種安裝模式,分別為:單機模式、偽分布式和完全分布式(集群),
其中,安裝單機模式的 Hadoop 無須配置,在這種方式下,Hadoop 被認為是一個單獨的 Java 行程,這種方式經常用來測驗,
本篇博文主要介紹偽分布式的 Hadoop 安裝,可以把偽分布式的 Hadoop 看作是只有一個節點的集群,在這個集群中,這個節點既是 Master,也是 Slave;既是 NameNode,也是 DataNode;既是 JobTracker,也是 TaskTracker,關于完全分布式的 Hadoop 下篇博文再進行介紹,
2、Hadoop 的下載
本篇博文中使用的 Hadoop 的安裝版本為 Hadoop 3.2.0,下載 Hadoop 的網址為:https://hadoop.apache.org/releases.html,如下圖所示:
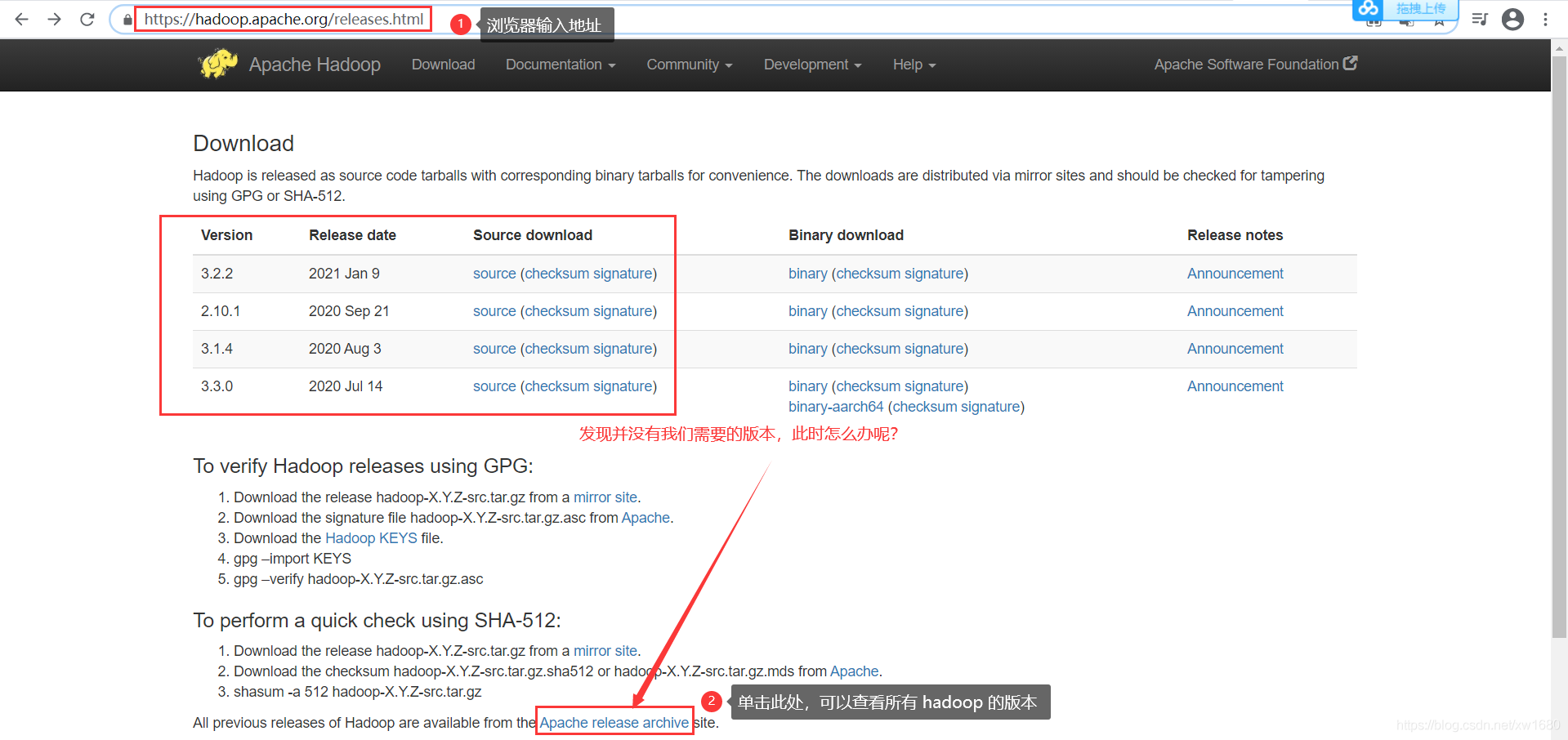
單擊后,進入一個新的頁面,向下拉動瀏覽器的滾動條,找到我們需要的 hadoop 版本,如下圖所示:
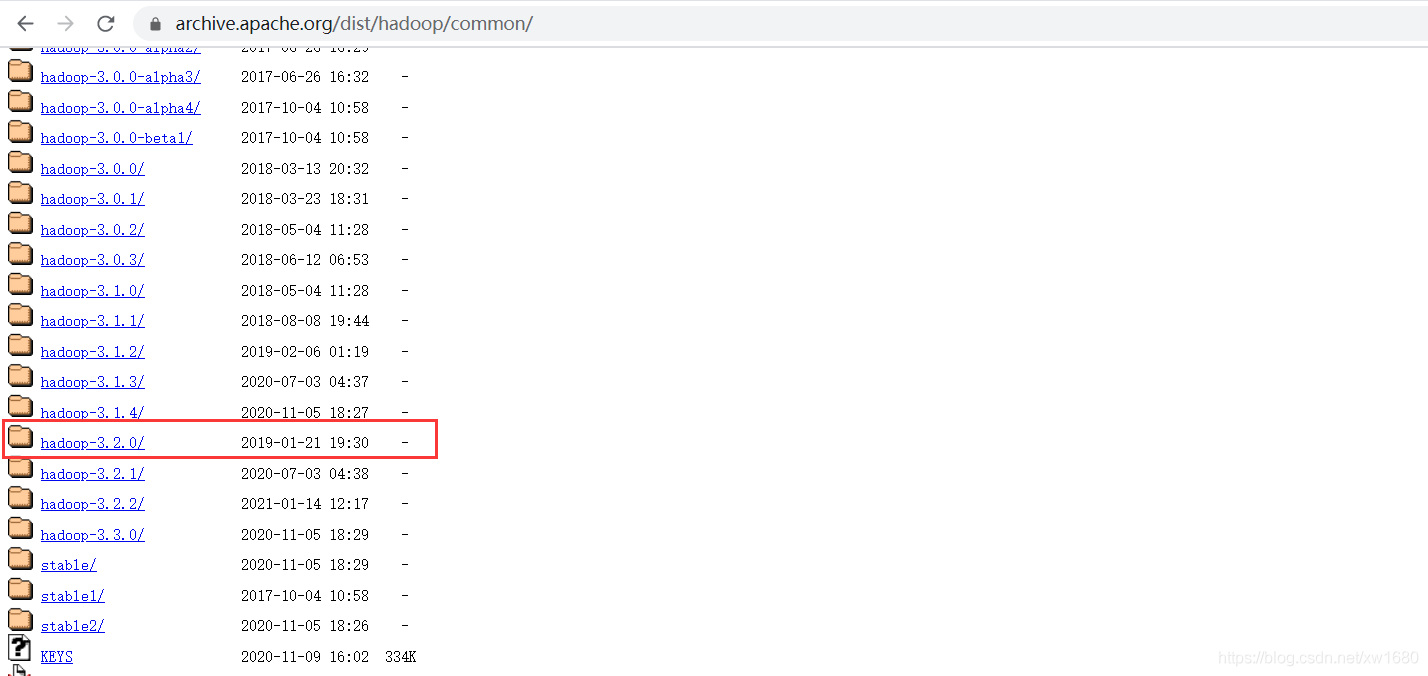
找到我們需要的 hadoop 版本之后,滑鼠左鍵點擊,進入到新的界面,然后選擇 hadoop-3.2.0.tar.gz 進行下載,如下圖所示:
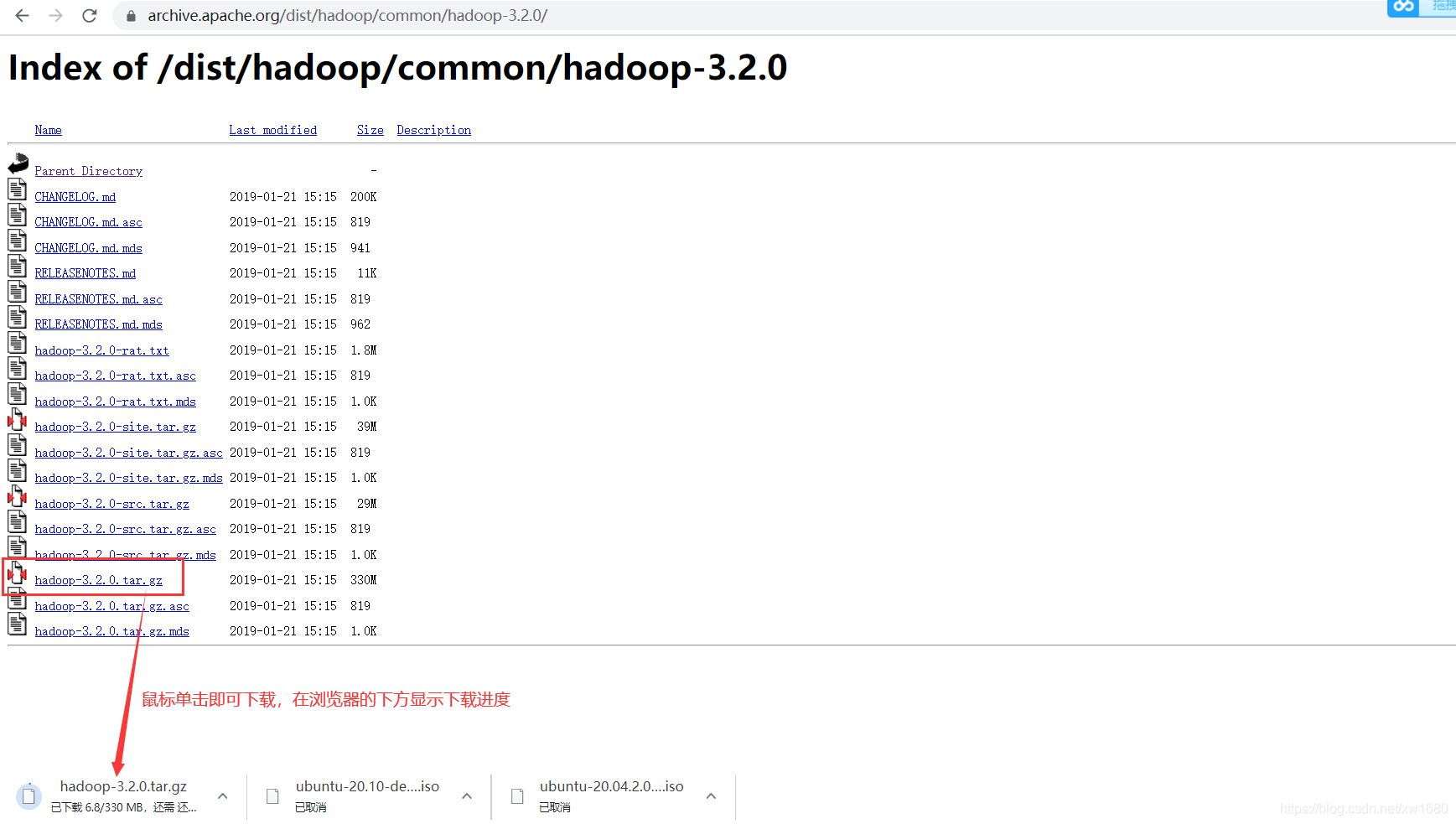
注意:如果發現這個國外的地址下載比較慢,可以使用國內的鏡像地址下載,但是這些國內的鏡像地址中提供的安裝包版本可能不全,如果沒有找到我們需要的版本,那還是要老老實實到官網下載,
這些國內的鏡像地址里面不僅僅有 Hadoop 的安裝包,里面包含了大部分 Apache 組織中的軟體安裝包:
地址1:https://mirrors.tuna.tsinghua.edu.cn/apache/
將下載好的安裝包 hadoop-3.2.0.tar.gz 復制到共享檔案夾中,以便 Ubuntu 系統可以對此安裝包進行下一步的操作,
3、Hadoop 的安裝
Hadoop 的安裝步驟如下:
解壓縮 Hadoop 安裝包,將安裝包從共享檔案夾復制到主目錄下,打開終端,輸入如下命令,將 Hadoop 安裝包解壓縮到當前目錄下,命令:tar -zxvf hadoop-3.2.0.tar.gz
命令執行后,系統開始解壓縮 hadoop-3.2.0.tar.gz 檔案,螢屏上不斷顯示解壓程序資訊,如上圖所示(由于篇幅問題,只顯示部分解壓資訊),當解壓完成后,系統將在主目錄下創建 hadoop-3.2.0 子目錄,此為 Hadoop 的安裝目錄,
查看一下 Hadoop 安裝目錄中的安裝檔案,輸入命令:
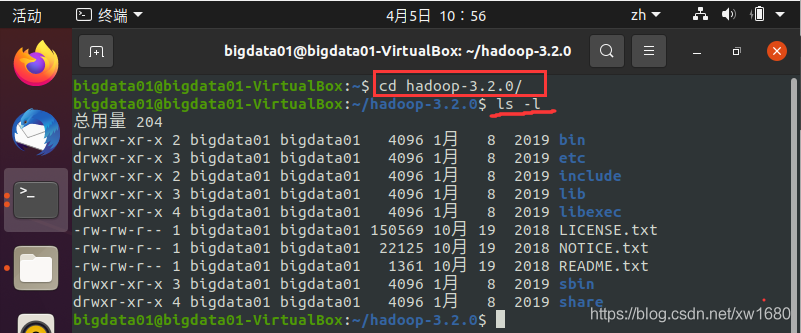
安裝檔案的目錄及目錄下常用檔案說明如下表所示:


至此,Hadoop 安裝完畢,但是要使用 Hadoop,還需要進行一系列的配置,
4、Hadoop 環境配置
1、配置 IP 和主機名
下面分別通過命令查看本機的 IP 地址和主機名,并將 IP 地址和主機名寫進 /etc/hosts 組態檔中,步驟如下:
(1) 查看本機的 IP 地址,命令如下:
sudo apt install net-tools
ifconfig
或者直接使用
ip addr
執行結果如下圖所示:
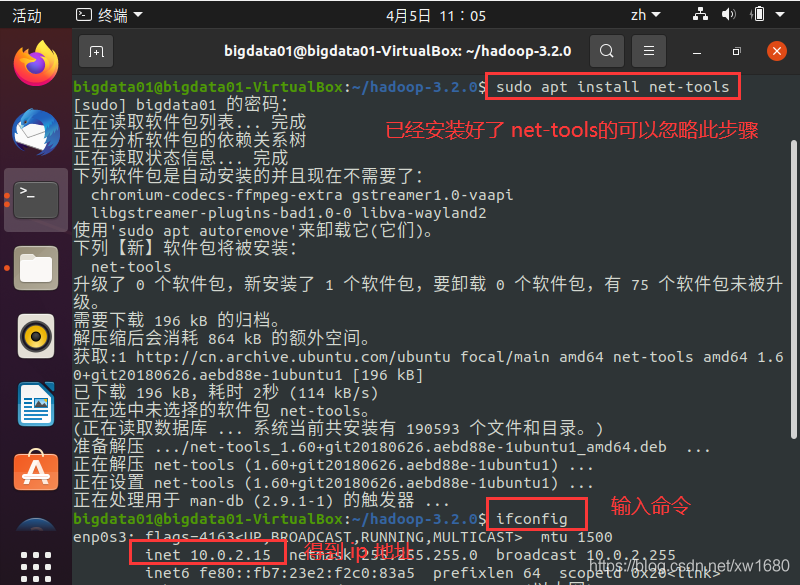
從上圖中可知本機的 IP 地址為 10.0.2.15,說明:此 IP 地址為虛擬機自動分配的地址,可以自己另行設定,
(2) 查看本機的主機名,命令如下:
hostname
執行結果如下圖所示:
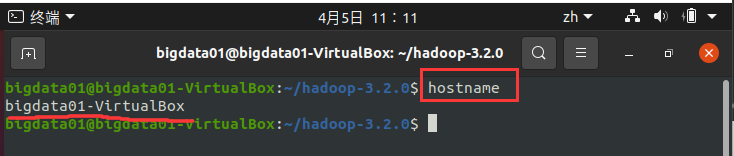
從上圖中可知本機的主機名為 bigdata01-VirtualBox,
(3) 將 IP 地址和主機名寫進 /etc/hosts 組態檔中,打開 /etc/hosts 命令如下:
sudo gedit /etc/hosts
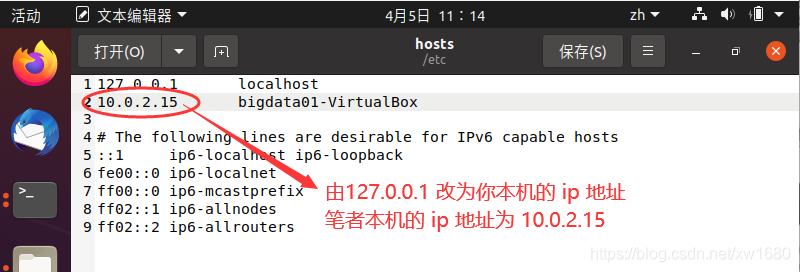
修改完成后,單擊保存按鈕,關閉檔案,
2、設定 Hadoop 環境變數
運行 Hadoop 必須設定很多環境變數,可是如果每次登錄時都必須重新設定就會很煩瑣,因此,可以在 ~/.bashre 檔案中設定每次登錄時都會自動運行一次環境變數設定,設定步驟如下:
(1) 在終端輸入如下命令:
sudo gedit ~/.bashrc
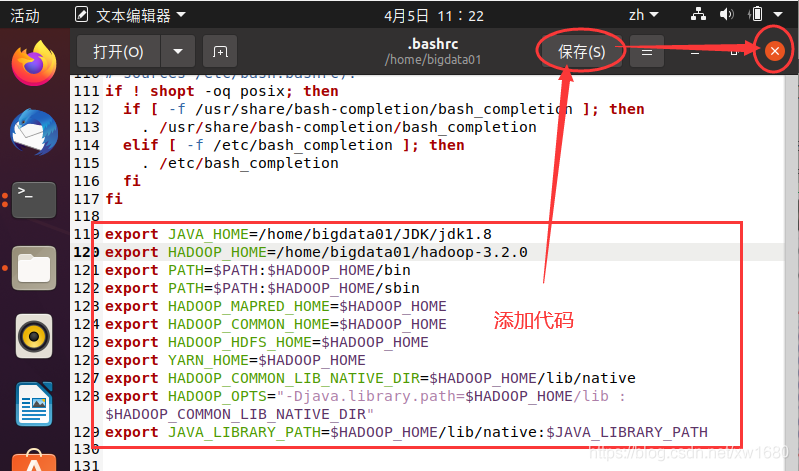
執行命令之后,就會打開 ~/.bashrc 檔案,在原有代碼的最下方的位置添加如下代碼:
# 設定JDK安裝路徑,
export JAVA_HOME=/home/bigdata01/JDK/jdk1.8
# 設定Hadoop的安裝目錄,
export HADOOP_HOME=/home/bigdata01/hadoop-3.2.0
# 設定PATH
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
# 設定Hadoop其他環境變數 將這些環境變數設定為$HADOOP_HOME,
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
# 鏈接庫的設定
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
編輯好 ~/.bashrc 檔案后,單擊 保存 按鈕后,再關閉 gedit,如下圖所示:
(2) 使設定生效,在終端輸入命令:source ~/.bashrc,或者重啟系統,也會使得設定生效,
(3) 使用 hadoop version 命令測驗是否配置成功,執行結果如下圖所示:
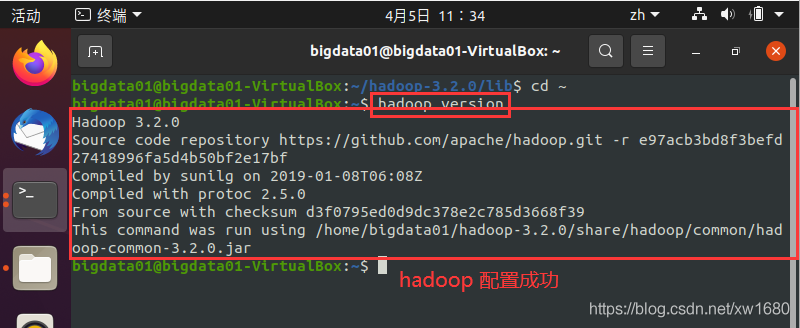
出現上圖所示的結果,則說明 Hadoop 環境已經配置成功了,
3、修改 Hadoop 組態檔
接下來要進行 Hadoop 的配置設定,需要修改的組態檔有:Hadoop-env.sh、core-site.xml、yarn-site.xml、mapred-site.xml 和 hdfs-site.xml,最后還要修改一下 /etc/profile 檔案,
(1) 修改 Hadoop-env.sh 檔案,Hadoop-env.sh 是 Hadoop 的組態檔,在此檔案中需要設定 Java 的安裝路徑,首先通過終端打開 Hadoop-env.sh 檔案,代碼如下:
sudo gedit ./hadoop-3.2.0/etc/hadoop/hadoop-env.sh
Hadoop-env.sh 檔案打開后,找到 # export JAVA_HOME 處(可以使用快捷鍵 <CTRL+F> 查找),在等號后面添加 JDK 的安裝位置,并將 export 前面的 # 號刪掉,如下圖所示:
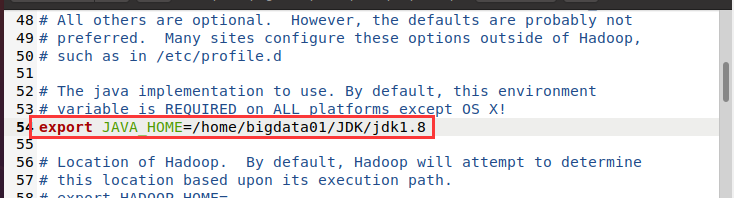
修改完畢后,單擊 保存 按鈕,關閉 Hadoop-env.sh 檔案,
(2) 修改 core-site.xml 檔案,通過終端打開 core-site.xml 檔案,代碼如下:
sudo gedit ./hadoop-3.2.0/etc/hadoop/core-site.xml
core-site.xml 檔案打開后,需要設定 HDFS 的默認名稱、地址和埠號,將如下代碼添加到 <configuration> 和 </configuration> 之間
<!-- 配置HDFS的主節點,NameNode -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://10.0.2.15:9000</value>
</property>
<!-- 配置HADOOP運行時產生檔案的存盤目錄 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/bigdata01/hadoop-3.2.0/dataNode_1_dir</value>
</property>
如下圖所示:
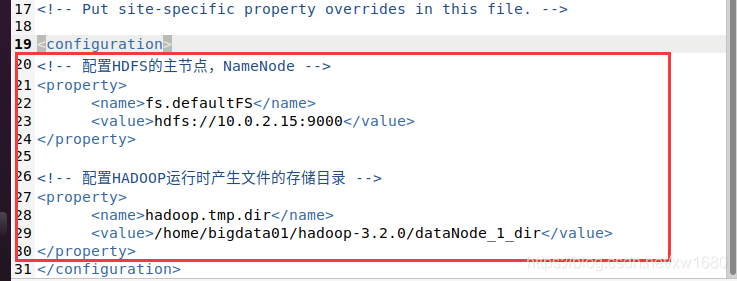
說明:代碼中的 10.0.2.15 為筆者的虛擬機的 IP 地址,讀者可以通過 ifconfig 命令查看本機的 IP 地址,XML檔案中,<!--、--> 中間的內容為注釋,修改完畢后,單擊 保存 按鈕,關閉 core-site.xml 檔案,
(3) 修改 yarn-site.xml 檔案,YARN 的站點組態檔是 yarn-site.xml,通過終端打開 yarn-site.xml 檔案的代碼如下:
sudo gedit ./hadoop-3.2.0/etc/hadoop/yarn-site.xml
YARN-site.xml 檔案打開后,將如下代碼添加到 <configuration> 和</configuration> 之間,代碼如下:
<!--配置ReourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>10.0.2.15</value>
</property>
<!--配置NodeManager執行任務的方式:shuffle:洗牌 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
修改完畢后,單擊 保存 按鈕,關閉 YARN-site.xml 檔案,如果 YARN 集群有多個節點,還需要配置 yarn.resourcemanager.address 等引數,
(4) 修改 mapred-site.xml 檔案,mapred-site.xml 為計算框架檔案,用于設定監控 Map 與 Reduce 程式的 JobTracker 任務分配情況以及 TaskTracker 任務運行情況,打開 mapred-site.xml 檔案,命令如下:
sudo gedit ./hadoop-3.2.0/etc/hadoop/mapred-site.xml
mapred-site.xml 檔案打開后,將如下代碼添加到 <configuration> 和</configuration> 之間,設定 mapreduce 的框架為 yarn,
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
修改完畢后,單擊 保存 按鈕,關閉 mapred-site.xml 檔案,
(5) 修改 hdfs-site.xml 檔案,hdfs-site.xml 用于設定 HDFS 分布式檔案系統,該檔案指定與 HDFS 相關的配置資訊,需要修改 HDFS 默認的塊的副本屬性,因為 HDFS 默認情況下每個資料塊保存 3 個副本,而在偽分布式模式下運行時,由于只有一個資料節點,所以需要將副本個數改為1;否則 Hadoop 程式會報錯,打開 hdfs-site.xml 檔案,命令如下:
sudo gedit ./hadoop-3.2.0/etc/hadoop/hdfs-site.xml
同樣,hdfs-site.xml 檔案打開后,將如下代碼添加到 <configuration> 和 </configuration> 之間,
<!-- 指定DataNode存儲block的副本數量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 指定namenode資料存盤目錄 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/bigdata01/hadoop-3.2.0/hadoop_data/hdfs/namenode</value>
</property>
<!-- 指定datanode資料存盤目錄 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/bigdata01/hadoop-3.2.0/hadoop_data/hdfs/datanode</value>
</property>
<!-- 指定ip地址 -->
<property>
<name>dfs.http.address</name>
<value>10.0.2.15:50070</value>
</property>
修改完畢后,單擊 保存 按鈕,關閉 hdfs-site.xml 檔案,注意:將dfs.replication配置成超過3的數是沒有意義的,因為HDFS的最大副本數就是3,
(6) 修改 /etc/profile 檔案,
sudo gedit /etc/profile
export HADOOP_HOME=./hadoop-3.2.0
:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
如下圖所示:

4、創建并格式化檔案系統
在上面的小節,hdfs-site.xml 檔案中,指定了 NameNode 和 DataNode 的資料存盤目錄,但是這兩個目錄并沒有創建,在本小節中,創建 NameNode 和 DataNode 的資料存盤目錄,并進行格式化,創建 NameNode 和 DataNode 的資料存盤目錄,命令如下:
- 創建 NameNode 資料存盤目錄,mkdir -p ./hadoop-3.2.0/hadoop_data/hdfs/namenode
- 創建 DataNode 資料存盤目錄,mkdir -p ./hadoop-3.2.0/hadoop_data/hdfs/datanode
- 創建 HADOOP 運行時產生檔案的存盤目錄,mkdir -p ./hadoop-3.2.0/dataNode_1_dir/datanode
- 如果 NameNode 目錄中已經有資料,那么可以將 HDFS 進行格式化,命令:hdfs namenode -format
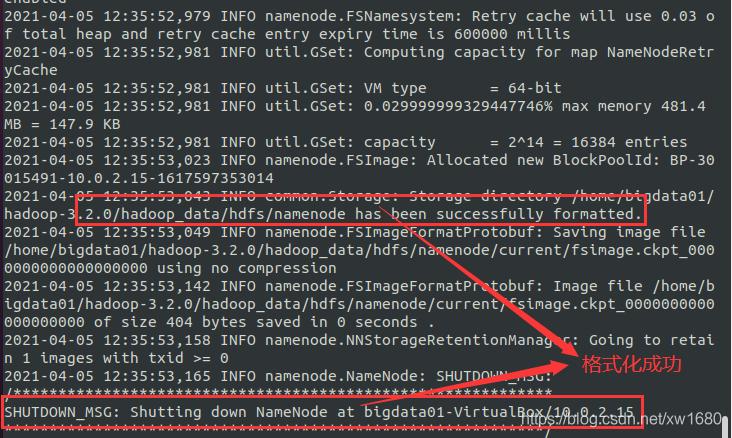
5、啟動與關閉 Hadoop
通過前面的小節,已經完成了 Hadoop 偽分布式單節點的安裝,現在開始啟動 Hadoop,使用命令 start-all.sh,來同時啟動 HDFS 和 YARN,執行結果如下圖所示:
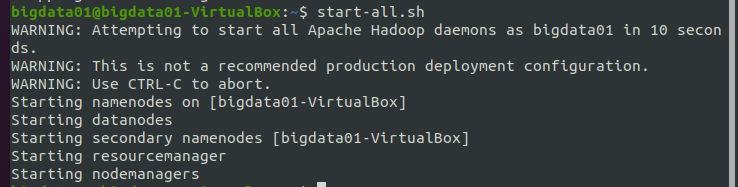
說明:start-all.sh命令可以拆分為start-dfs.sh和start-yarn.sh,分別用來啟動HDFS和YARN,在啟動Hadoop時,用這兩種方式都可以,
下面通過 jps 命令檢驗一下是否全部開啟 Hadoop 的守護行程,執行結果如圖所示:
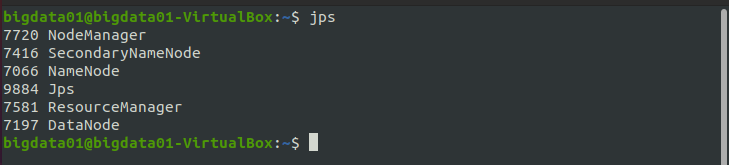
在上圖的結果圖中,DataNode、SecondaryNameNode 和 NameNode 是檔案系統 HDFS 的行程,NodeManager、ResourceManager 是 YARN 的行程,只有這 5 個行程全部啟動,才說明 Hadoop 啟動成功了,
關閉 Hadoop 的命令:stop-all.sh,執行結果如下圖所示:
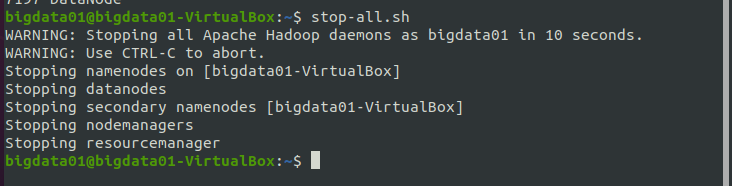
說明:stop-all.sh命令可以拆分為stop-dfs.sh和stop-yarn.sh,分別用來關閉HDFS和YARN,在關閉Hadoop時,使用“stop-all.sh”或者“stop-dfs.sh”+“stop-yarn.sh”這兩種方式都可以,
6、查看 Hadoop 的基本資訊
6.1、查看 HDFS Web 界面
HDFS Web 界面可以檢查當前 HDFS 與 DataNode 的運行情況,打開步驟如下,打開瀏覽器 Firefox,在瀏覽器的地址欄中輸入:10.0.2.15:50070,向下滑動頁面,可以看到活動節點,如下圖所示:
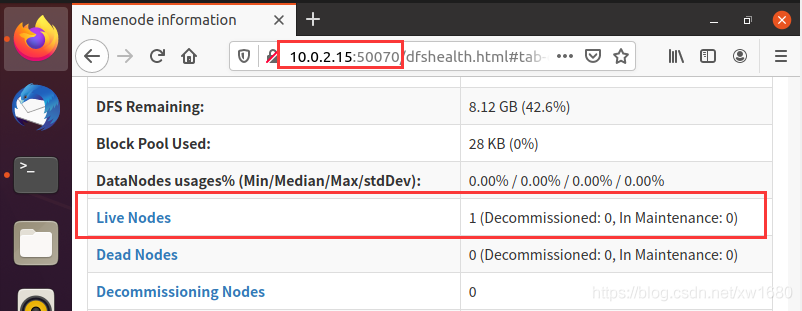
說明:10.0.2.15 為筆者虛擬機中的 IP 地址,讀者應根據實際情況進行替換,
6.2、查看 YARN Web 界面
YARN Web 界面也被稱為 Hadoop ResourceManager Web 界面,在此頁面中,可以查看當前 Hadoop 的狀態;Node 節點;應用程式、行程的運行狀態,打開 YARN 的 Web 界面的步驟如下,
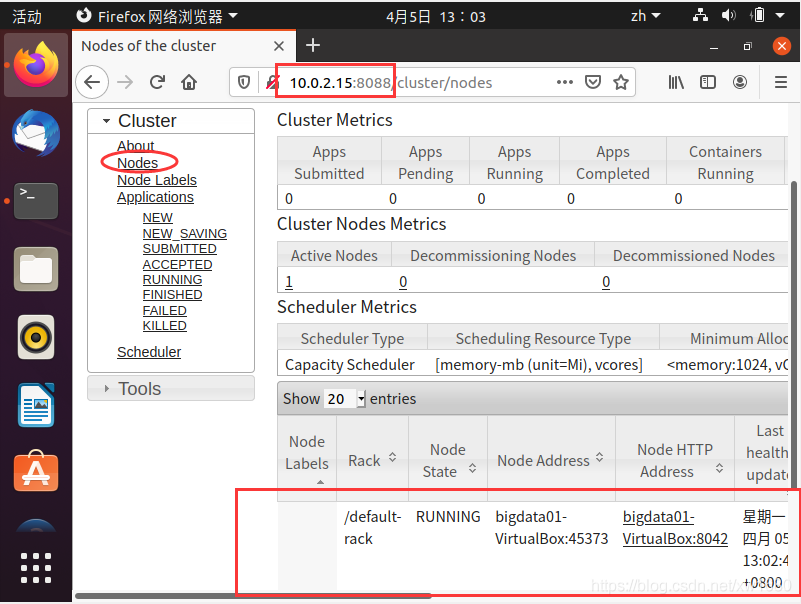
打開瀏覽器 Firefox,在瀏覽器的地址欄中輸入:10.0.2.15:8088,單擊 Nodes 鏈接,顯示當前已經運行的節點,因為本篇博文中安裝的是偽分布式的 Hadoop,所以會看到當前只有一個節點,如下圖所示:
三、在 Centos7 中 進行 Hadoop 偽分布式安裝
-
設定靜態 ip:vi /etc/sysconfig/network-scripts/ifcfg-ens33(不同系統 ens 后的數字不一樣,讀者需根據自己本機實際情況)
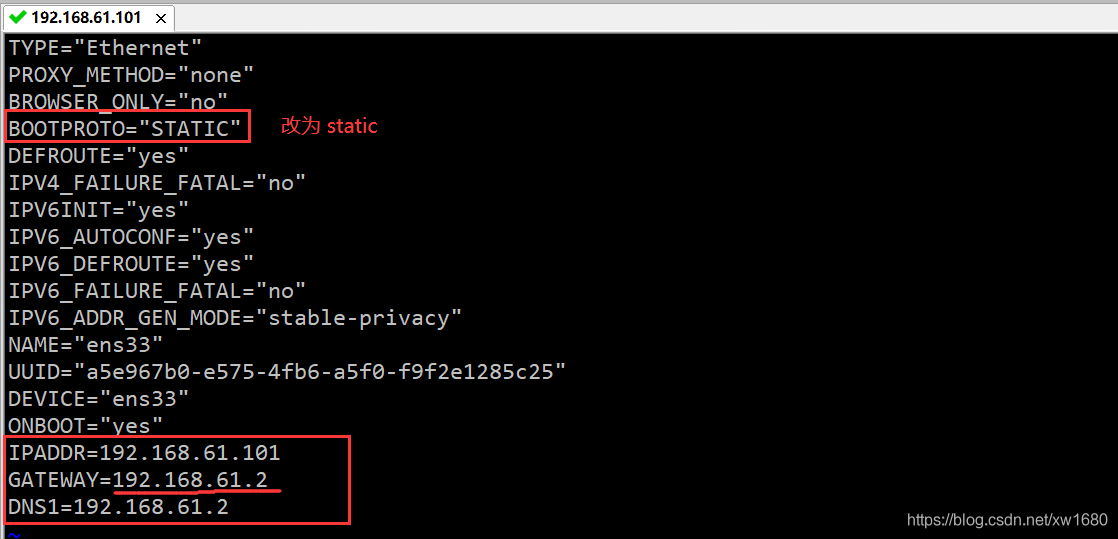
注意:IPADDR 的值,192.168.61 都是取自虛擬機中虛擬網路編輯器中子網地址的值,最后的 101 是我自己取的,這個值可以取 3~254 之間的任意一個數值,建議大家也按照我這個取值為 101,這樣方便統一,后期和我在博客中使用的都是一樣的,GATEWAY 的值是取自虛擬網路編輯器中 NAT 設定里面的網關的值,DNS1 的值和 GATEWAY 的值一樣即可,
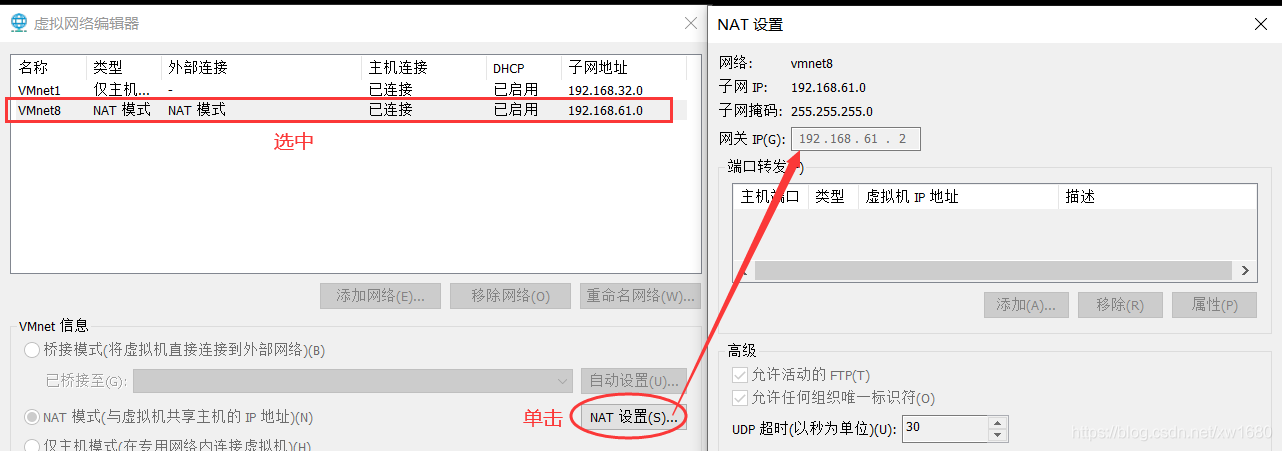
最后:service network restart,如下圖所示:

-
hostname:設定臨時主機名和永久主機名,臨時:hostname bigdata01、永久:vi /etc/hostname 將里面的主機名改為 bigdata01,緊接著重啟查看:reboot -h now、hostname,

-
firewalld:臨時關閉防火墻+永久關閉防火墻,臨時:systemctl stop firewalld、永久:systemctl disable firewalld、確認是否從開機啟動項中關閉了:systemctl list-unit-files | grep firewalld
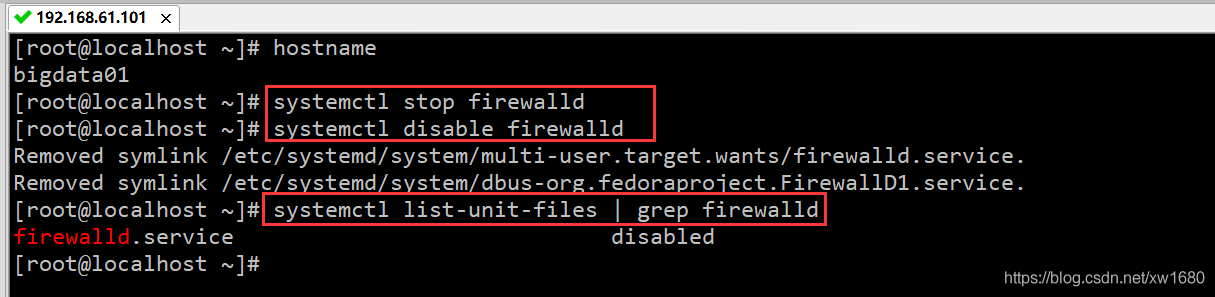
注意:針對不同版本的 centos 系統,關閉防火墻的命令是不一樣的,目前的兩大主流版本是 centos6 和 centos7,他們兩個關閉防火墻的命令也是不一樣的,剛剛博主演示的是 centos7 中防火墻關閉的命令,如果你遇到了 centos6,也想關閉防火墻的話可以自己百度一下命令,后續博主也會在 Linux 從菜鳥到精通專欄 中繼續更新 Centos6 的相關操作, -
ssh 免密碼登錄,在上面 Ubuntu 中詳細介紹過,這里博主就不再贅述,
1、ssh-keygen -t rsa、注意:執行這個命令以后,在 Centos 需要連續按 4 次回車鍵回到 linux 命令列才表示這個操作執行結束,在按回車的時候不需要輸入任何內容,
2、把公鑰拷貝到需要免密碼登錄的機器上面:cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys -
安裝 JDK,先:mkdir -p /data/soft、把 JDK 的安裝包上傳到 /data/soft/ 目錄下
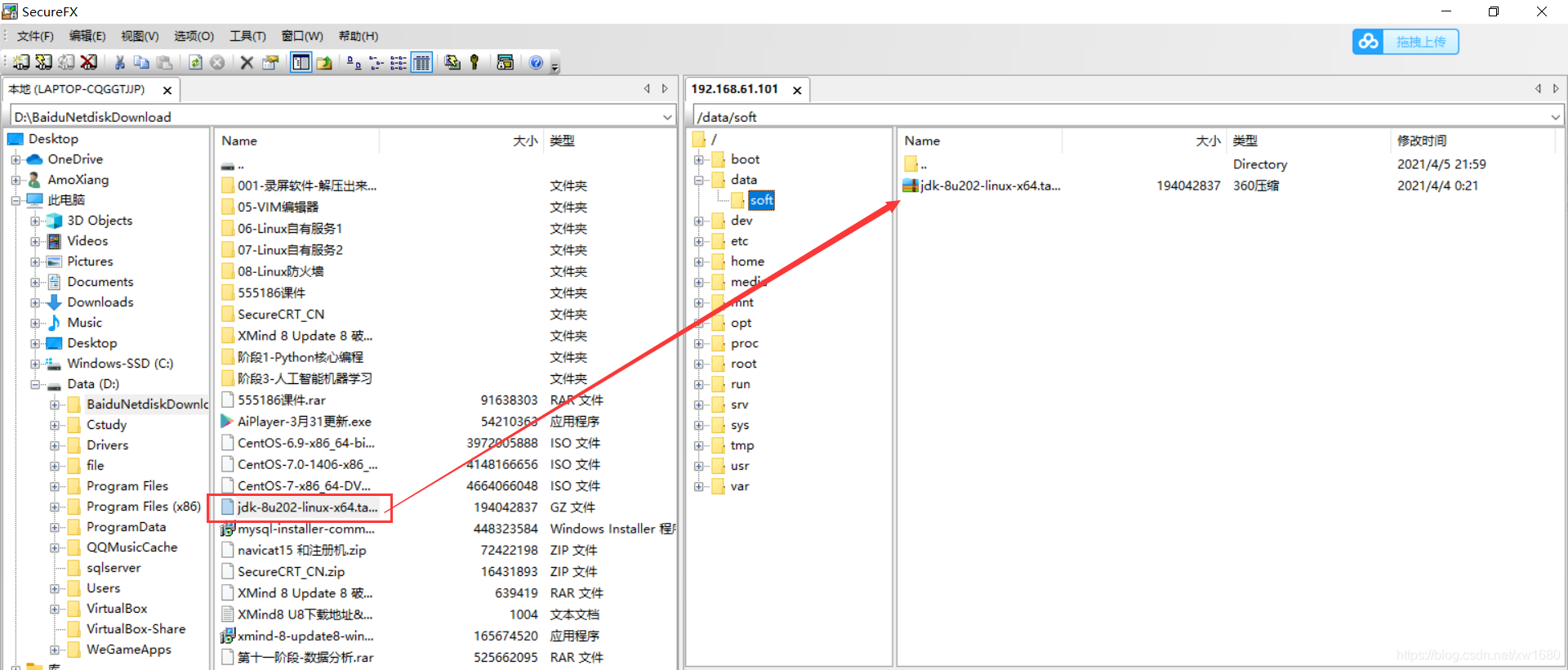
解壓 jdk 安裝包:tar -zxvf jdk-8u202-linux-x64.tar.gz
重命名 jdk:mv jdk1.8.0_202/ jdk1.8
配置環境變數 JAVA_HOME:vi /etc/profile

立即生效:source /etc/profile
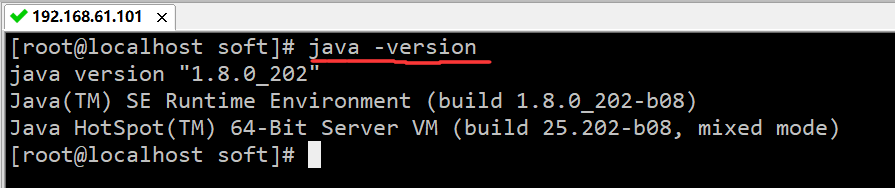
驗證:java -version
-
把 hadoop 的安裝包上傳到 /data/soft 目錄下,解壓 hadoop 安裝包:tar -zxvf hadoop-3.2.0.tar.gz
-
配置一下環境變數 vi /etc/profile

-
修改 Hadoop 相關組態檔,進入組態檔所在目錄:cd etc/hadoop/
先修改 hadoop-env.sh,執行命令:vi hadoop-env.sh,如下圖所示:

修改 core-site.xml 檔案,注意 fs.defaultFS 屬性中的主機名需要和你配置的主機名保持一致,執行 vi core-site.xml 命令,添加內容如下:<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://bigdata01:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/data/hadoop_repo</value> </property> </configuration>修改 hdfs-site.xml 檔案,把 hdfs 中檔案副本的數量設定為1,因為現在偽分布集群只有一個節點,首先:vi hdfs-site.xml,添加內容如下:
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>修改 mapred-site.xml,設定 mapreduce 使用的資源調度框架,首先:vi mapred-site.xml,添加內容如下:
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>修改 yarn-site.xml,設定 yarn 上支持運行的服務和環境變數白名單,首先:vi yarn-site.xml,添加內容如下:
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> </configuration>修改 workers,設定集群中從節點的主機名資訊,在這里就一臺集群,所以就填寫 bigdata01 即可,首先:vi workers,然后將里面的 localhost 改為 bigdata01,
-
格式化 HDFS,cd /data/soft/hadoop-3.2.0、bin/hdfs namenode -format,如下圖所示:
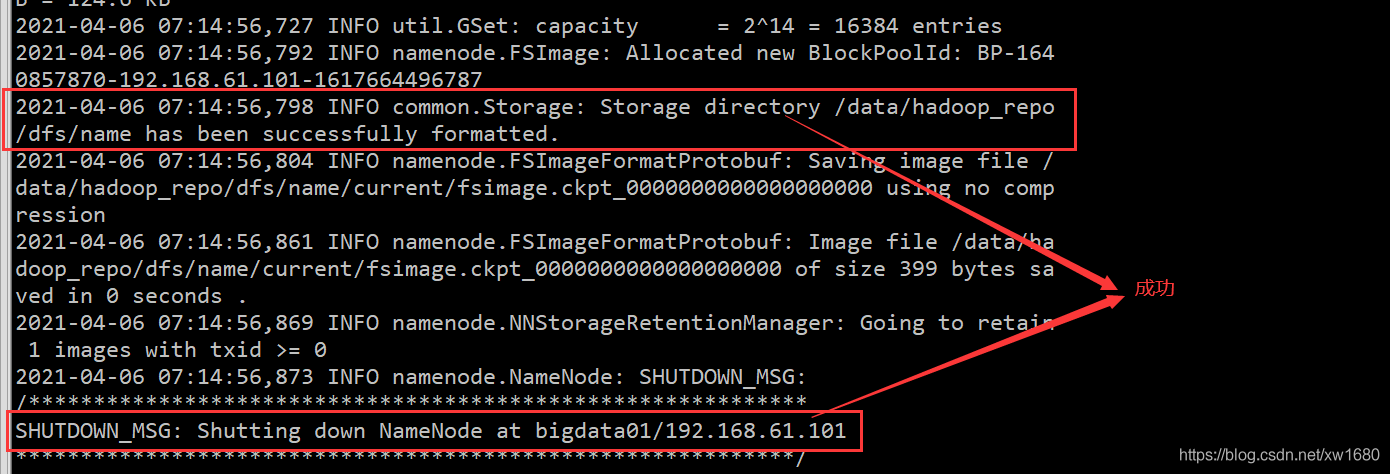
如果提示錯誤,一般都是因為組態檔的問題,當然需要根據具體的報錯資訊去分析問題,注意:格式化操作只能執行一次,如果格式化的時候失敗了,可以修改組態檔后再執行格式化,如果格式化成功了就不能再重復執行了,否則集群就會出現問題,如果確實需要重復執行,那么需要把/data/hadoop_repo目錄中的內容全部洗掉,再執行格式化, -
啟動偽分布集群,使用 sbin 目錄下的 start-all.sh 腳本,
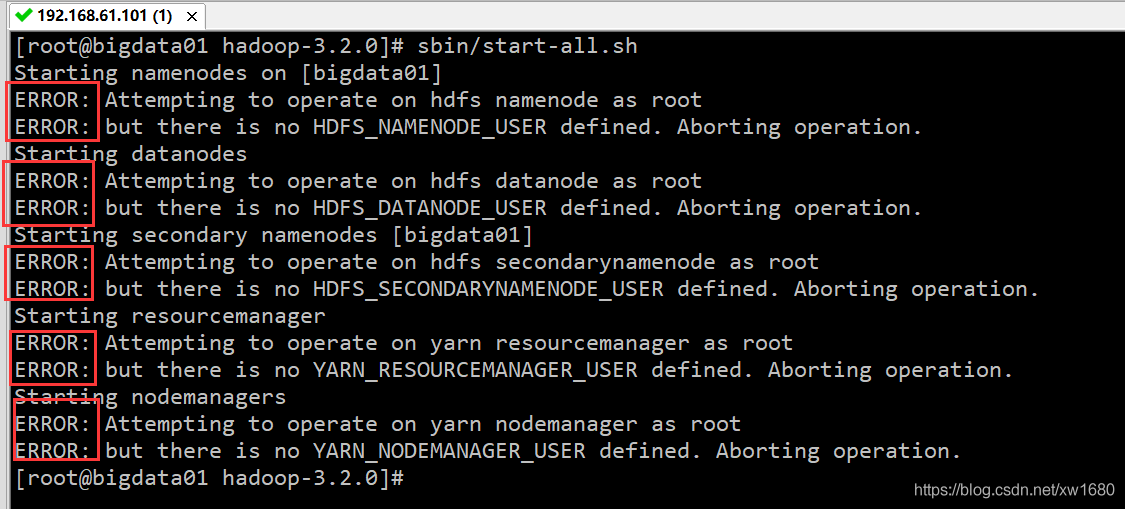
執行的時候發現有很多 ERROR 資訊,提示缺少 HDFS 和 YARN 的一些用戶資訊,解決方案如下:修改 sbin 目錄下的 start-dfs.sh,stop-dfs.sh 這兩個腳本檔案,在檔案前面增加如下內容:cd sbin/vi start-dfs.sh,增加以下內容:
HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=rootvi stop-dfs.sh,增加以下內容:
HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root修改 sbin 目錄下的 start-yarn.sh,stop-yarn.sh 這兩個腳本檔案,在檔案前面增加如下內容,vi start-yarn.sh,增加以下內容:
YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=rootvi stop-yarn.sh,增加以下內容:
YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root再啟動集群:
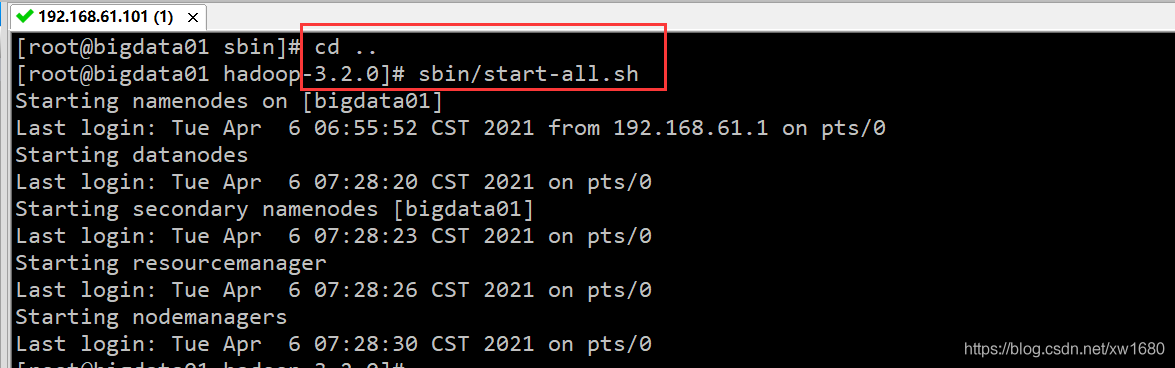
-
驗證集群行程資訊,執行 jps 命令可以查看集群的行程資訊,去掉 jps 這個行程之外還需要有 5 個行程才說明集群是正常啟動的,
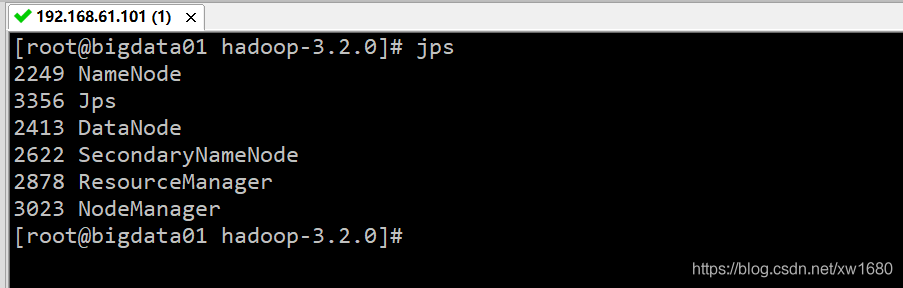
-
還可以通過 webui 界面來驗證集群服務是否正常,HDFS webui 界面:http://192.168.61.101:9870
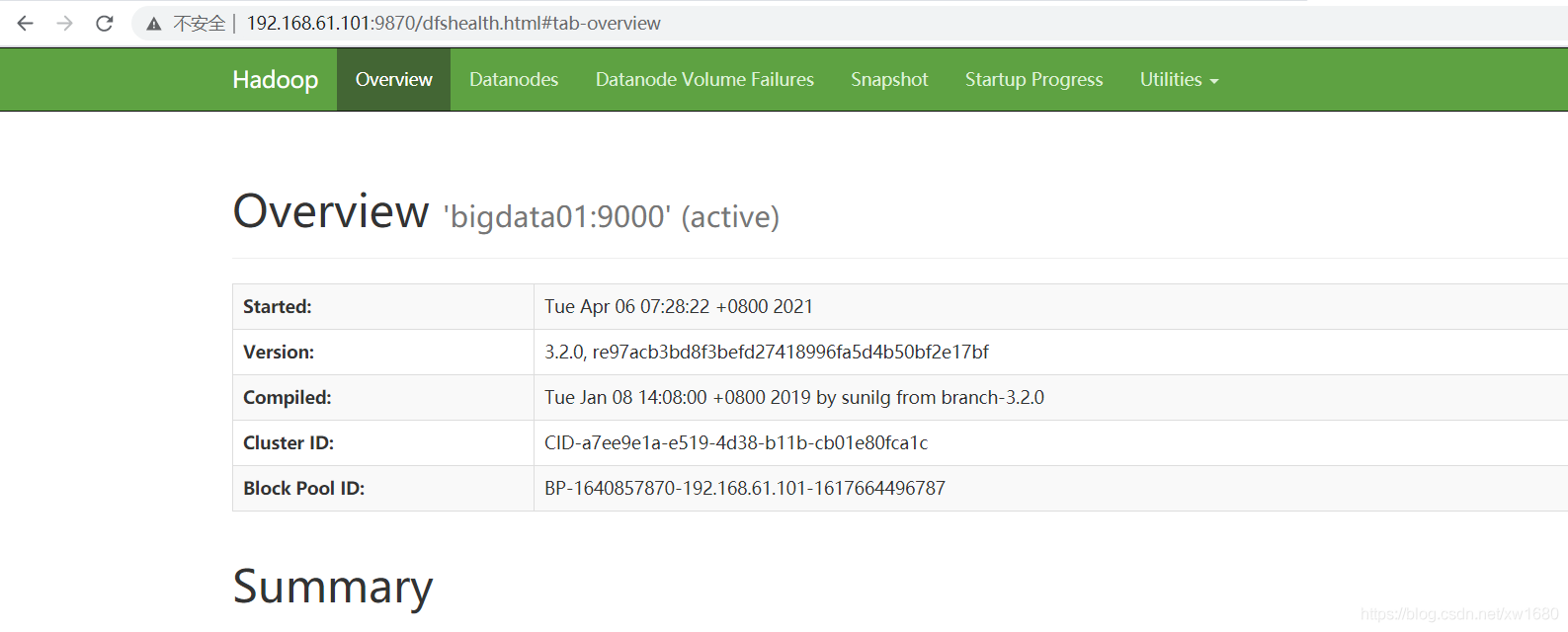
YARN webui 界面:http://192.168.61.101:8088
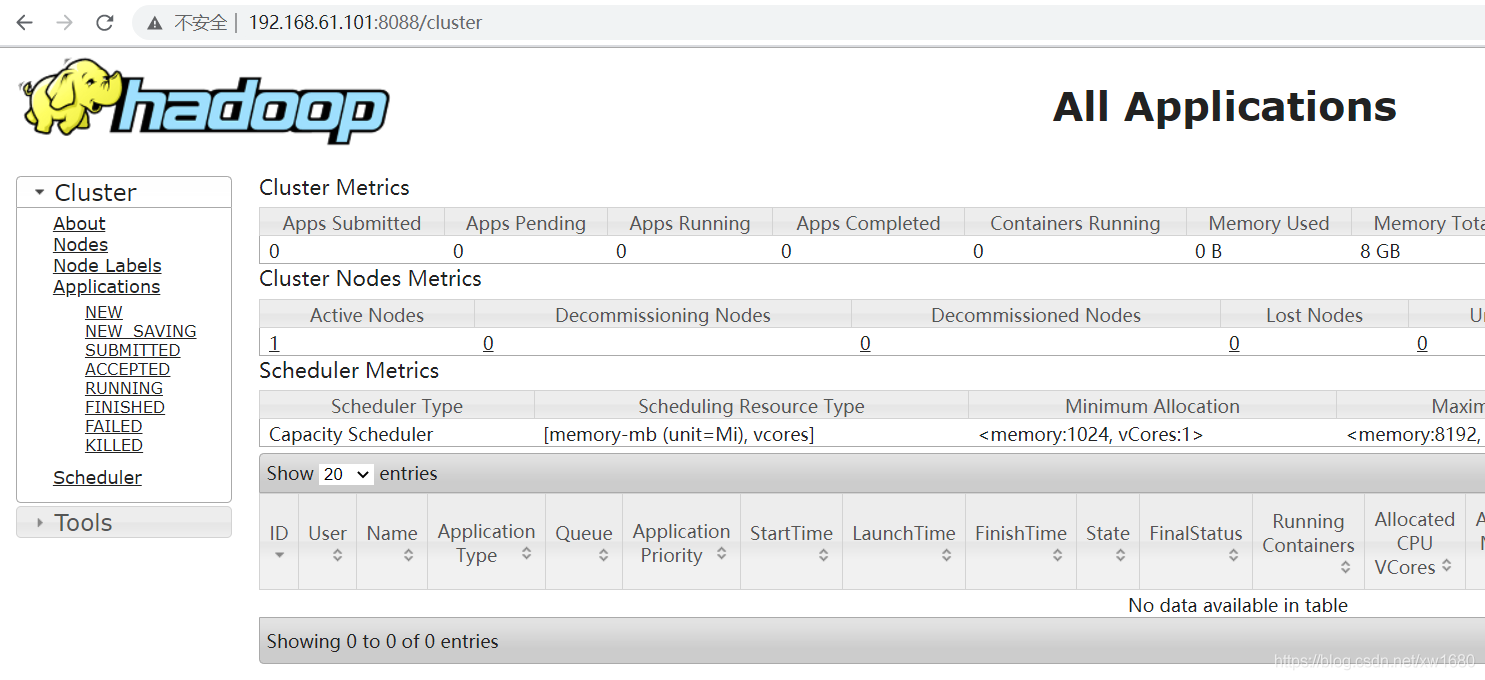
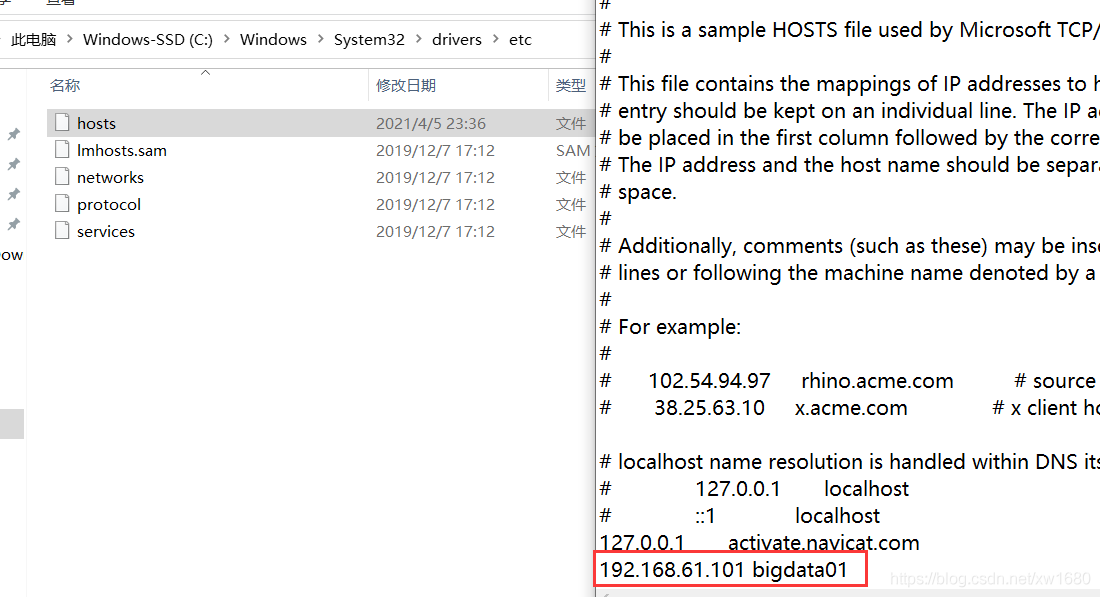
如果想通過主機名訪問,則需要修改 Windows 機器中的 hosts 檔案,檔案所在位置為:C:\Windows\System32\drivers\etc\HOSTS,在檔案中增加下面內容,這個其實就是 Linux 虛擬機的 ip 和主機名,在這里做一個映射之后,就可以在 Windows 機器中通過主機名訪問這個 Linux 虛擬機了,
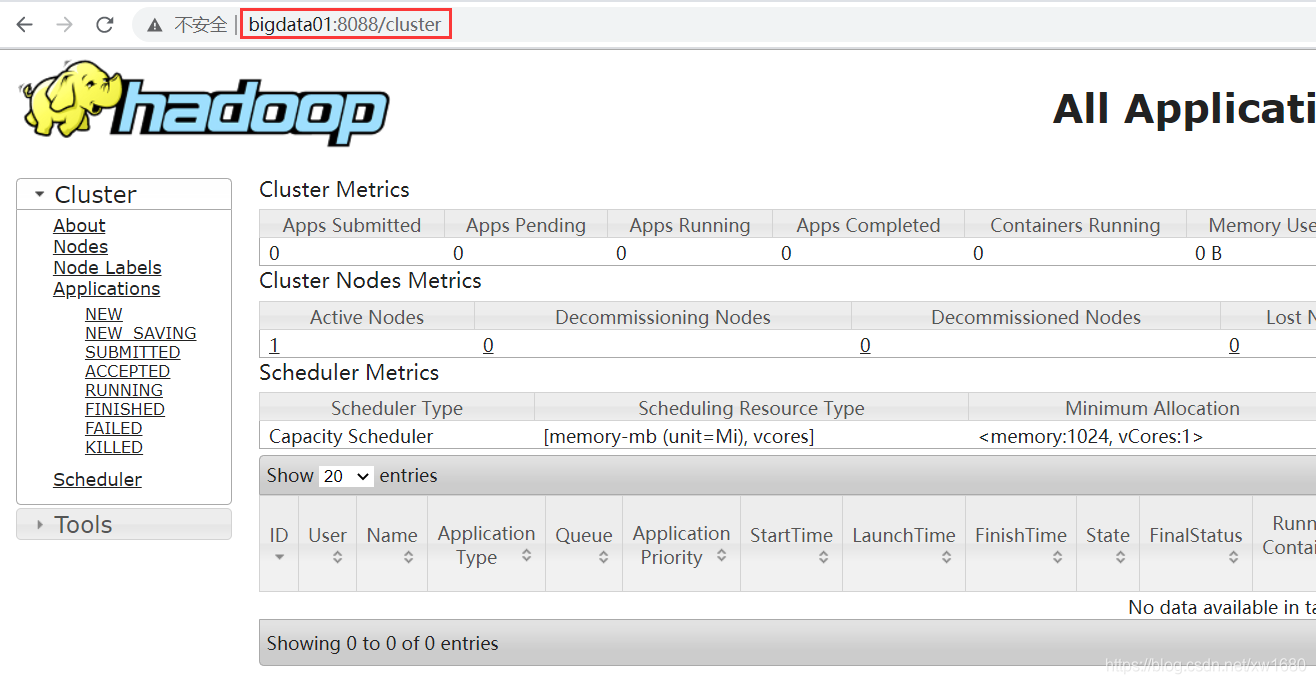
使用 http://bigdata01:8088/cluster YARN webui 界面,如下圖所示:
-
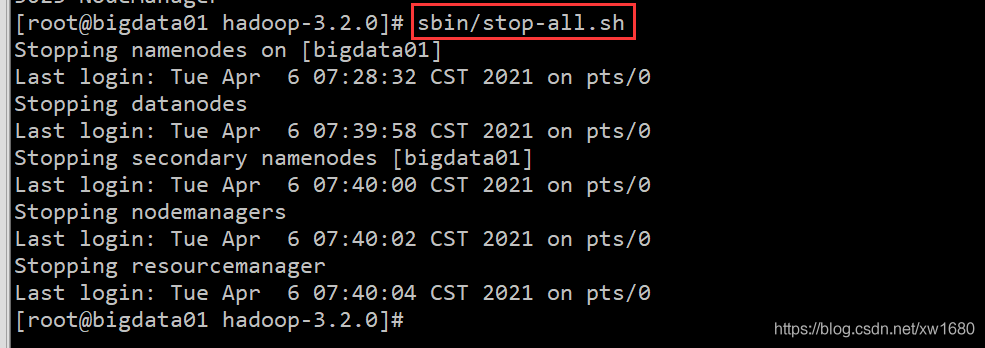
停止集群,如果修改了集群的組態檔或者是其它原因要停止集群,可以使用命令:sbin/stop-all.sh,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/272800.html
標籤:其他