專案代碼已上傳至github需要的可以自行下載
目錄
- 1 比賽介紹
- 2 解題思路
- 3 比賽資料集
- 4 模型訓練
- 5 更改detect.py檔案
- 6 上傳檔案
1 比賽介紹
專案鏈接:零基礎入門CV - 街景字符編碼識別
一、賽題資料
賽題來源自Google街景影像中的門牌號資料集(The Street View House Numbers Dataset, SVHN),并根據一定方式采樣得到比賽資料集,
資料集報名后可見并可下載,該資料來自真實場景的門牌號,訓練集資料包括3W張照片,驗證集資料包括1W張照片,每張照片包括顏色影像和對應的編碼類別和具體位置;為了保證比賽的公平性,測驗集A包括4W張照片,測驗集B包括4W張照片
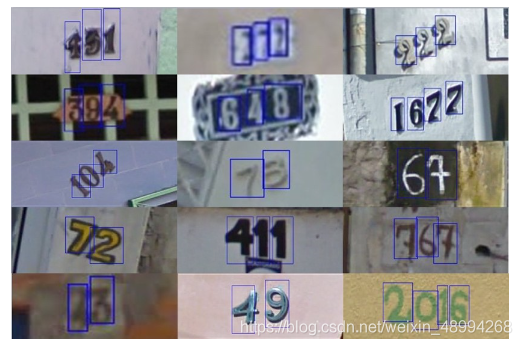
需要注意的是本賽題需要選手識別圖片中所有的字符,為了降低比賽難度,我們提供了訓練集、驗證集和測驗集中字符的位置框,
所有的資料(訓練集、驗證集和測驗集)的標注使用JSON格式,并使用檔案名進行索引,如果一個檔案中包括多個字符,則使用串列將欄位進行組合,
二、評測標準
評價標準為準確率,選手提交結果與實際圖片的編碼進行對比,以編碼整體識別準確率為評價指標,結果越大越好,具體計算公式如下:

三、結果提交
提交前請確保預測結果的格式與sample_submit.csv中的格式一致,以及提交檔案后綴名為csv,
file_name, file_code
0010000.jpg,451
0010001.jpg,232
0010002.jpg,45
0010003.jpg,67
0010004.jpg,191
0010005.jpg,892
2 解題思路
從下載好的資料看,本題為數字識別,為識別類任務,這種任務的選擇有很多,可以用cnn、VGG,具體的可以參看手寫數字識別,
在參看大賽論壇后發現幾個高分模型是使用yolo系列把識別漢字當作檢測類別來做,
參考1:yolov5加全域nms 第八名方案分享
參考2:真正零基礎,單模型非融合,上93的最簡單技巧
參考3:街景字符識別
本題采用yolov5進行解題,
3 比賽資料集
下載比賽資料:
mchar_train.zip
mchar_train.json
mchar_val.zip
mchar_val.json
mchar_test_a.zip
mchar_sample_submit_A.csv
本次賽題已經將訓練檔案分為訓練集與測驗集,我們這里重新給它進行劃分,首先將訓練集與測驗集所有圖片放入all_images檔案夾中(由于訓練集與測驗集中的圖片名有重合,所以在整合時將測驗集的圖片名稍作更改加上前綴val,以防資料覆寫):
import os
import shutil
train_image_path = './data/mchar_train/'#下載好的存盤路徑
val_image_path = './data/mchar_val/'
dst_image_path = '../coco/all_images/'#檔案整合后的位置
train_image_list = os.listdir(train_image_path)
val_image_list = os.listdir(val_image_path)
for img in train_image_list:
shutil.copy(train_image_path+img, dst_image_path+img)
for img in val_image_list:
shutil.copy(val_image_path+img, dst_image_path+'val_'+img)
將json型別的標簽轉為txt型別的標簽并存放到all_labels檔案夾中:
import os
import cv2
import json
train_image_path = './data/mchar_train/'#下載好的資料集位置
val_image_path = './data/mchar_val/'
train_annotation_path = './data/mchar_train.json'
val_annotation_path = './data/mchar_val.json'
train_data = json.load(open(train_annotation_path))
val_data = json.load(open(val_annotation_path))
label_path = '../coco/all_labels/'
for key in train_data:
f = open(label_path+key.replace('.png', '.txt'), 'w')
img = cv2.imread(train_image_path+key)
shape = img.shape
label = train_data[key]['label']
left = train_data[key]['left']
top = train_data[key]['top']
height = train_data[key]['height']
width = train_data[key]['width']
for i in range(len(label)):
x_center = 1.0 * (left[i]+width[i]/2) / shape[1]
y_center = 1.0 * (top[i]+height[i]/2) / shape[0]
w = 1.0 * width[i] / shape[1]
h = 1.0 * height[i] / shape[0]
# label, x_center, y_center, w, h
f.write(str(label[i]) + ' ' + str(x_center) + ' ' + str(y_center) + ' ' + str(w) + ' ' + str(h) + '\n')
f.close()
for key in val_data:
f = open(label_path+'val_'+key.replace('.png', '.txt'), 'w')
img = cv2.imread(val_image_path+key)
shape = img.shape
label = val_data[key]['label']
left = val_data[key]['left']
top = val_data[key]['top']
height = val_data[key]['height']
width = val_data[key]['width']
for i in range(len(label)):
x_center = 1.0 * (left[i]+width[i]/2) / shape[1]
y_center = 1.0 * (top[i]+height[i]/2) / shape[0]
w = 1.0 * width[i] / shape[1]
h = 1.0 * height[i] / shape[0]
# label, x_center, y_center, w, h
f.write(str(label[i]) + ' ' + str(x_center) + ' ' + str(y_center) + ' ' + str(w) + ' ' + str(h) + '\n')
f.close()
所有的訓練檔案準備完畢,接著參看《yolov5訓練自己的資料集(一文搞定訓練)》制作自己的資料集,里面包含資料集的重新劃分的腳本,按照該博客更改自己的coco.yaml,
4 模型訓練
采用yolov5x模型為預訓練模型,設定epochs,batch_size,image-size(32的整數倍),進行訓練,
可以自行調節訓練引數,可以在選擇分數不錯的模型設為預訓練模型進一步訓練,
訓練結束后我們使用輸出的權重檔案best.pt進行預測,
5 更改detect.py檔案
本次需要提交csv格式的預測結果,我們更改原來的detect.py檔案以滿足我們的需求:參看《yolov5-detect.py決議與重寫》
import argparse
import time
from pathlib import Path
import os
import cv2
import torch
import torch.backends.cudnn as cudnn
from numpy import random
from models.experimental import attempt_load
from utils.datasets import LoadStreams, LoadImages
from utils.general import check_img_size, check_requirements, check_imshow, non_max_suppression, apply_classifier, \
scale_coords, xyxy2xywh, strip_optimizer, set_logging, increment_path
from utils.plots import plot_one_box
from utils.torch_utils import select_device, load_classifier, time_synchronized
import pandas as pd
def detect(save_img=False):
source, weights, view_img, save_txt, imgsz = opt.source, opt.weights, opt.view_img, opt.save_txt, opt.img_size
save_img = not opt.nosave and not source.endswith('.txt') # save inference images
webcam = source.isnumeric() or source.endswith('.txt') or source.lower().startswith(
('rtsp://', 'rtmp://', 'http://'))
file_name = []
file_code = []
# result = dict()
# Directories
save_dir = Path(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok)) # increment run
(save_dir if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Initialize
set_logging()
device = select_device(opt.device)
half = device.type != 'cpu' # half precision only supported on CUDA
# Load model
model = attempt_load(weights, map_location=device) # load FP32 model
stride = int(model.stride.max()) # model stride
imgsz = check_img_size(imgsz, s=stride) # check img_size
if half:
model.half() # to FP16
# Second-stage classifier
classify = False
if classify:
modelc = load_classifier(name='resnet101', n=2) # initialize
modelc.load_state_dict(torch.load('weights/resnet101.pt', map_location=device)['model']).to(device).eval()
# Set Dataloader
vid_path, vid_writer = None, None
if webcam:
view_img = check_imshow()
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadStreams(source, img_size=imgsz, stride=stride)
else:
dataset = LoadImages(source, img_size=imgsz, stride=stride)
# Get names and colors
names = model.module.names if hasattr(model, 'module') else model.names
colors = [[random.randint(0, 255) for _ in range(3)] for _ in names]
# Run inference
if device.type != 'cpu':
model(torch.zeros(1, 3, imgsz, imgsz).to(device).type_as(next(model.parameters()))) # run once
t0 = time.time()
for path, img, im0s, vid_cap in dataset:
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
# Inference
t1 = time_synchronized()
pred = model(img, augment=opt.augment)[0]
# Apply NMS
pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes, agnostic=opt.agnostic_nms)
t2 = time_synchronized()
# Apply Classifier
if classify:
pred = apply_classifier(pred, modelc, img, im0s)
# Process detections
for i, det in enumerate(pred): # detections per image
if webcam: # batch_size >= 1
p, s, im0, frame = path[i], '%g: ' % i, im0s[i].copy(), dataset.count
else:
p, s, im0, frame = path, '', im0s, getattr(dataset, 'frame', 0)
s += '%gx%g ' % img.shape[2:] # print string
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
# Write results
x_value = dict()
for *xyxy, conf, cls in reversed(det):
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
cls = torch.tensor(cls).tolist()
x_value[xywh[0]] = int(cls)
# Print time (inference + NMS)
print(f'{s}Done. ({t2 - t1:.3f}s)')
file_name.append(os.path.split(path)[-1])
res = ''
for key in sorted(x_value):
res += str(x_value[key])
file_code.append(res)
save_csv_path=str(os.getcwd())+'\\'+str(save_dir)+'\\submission.csv'
print(save_csv_path)
sub = pd.DataFrame({"file_name": file_name, 'file_code': file_code})
sub.to_csv(save_csv_path, index=False)
print(f'Done. ({time.time() - t0:.3f}s)')
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='weights/best.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='data/mchar_test_a', help='source') # file/folder, 0 for webcam
parser.add_argument('--img-size', type=int, default=160, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='display results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default='runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
opt = parser.parse_args()
print(opt)
check_requirements(exclude=('pycocotools', 'thop'))
with torch.no_grad():
if opt.update: # update all models (to fix SourceChangeWarning)
for opt.weights in ['yolov5s.pt', 'yolov5m.pt', 'yolov5l.pt', 'yolov5x.pt']:
detect()
strip_optimizer(opt.weights)
else:
detect()
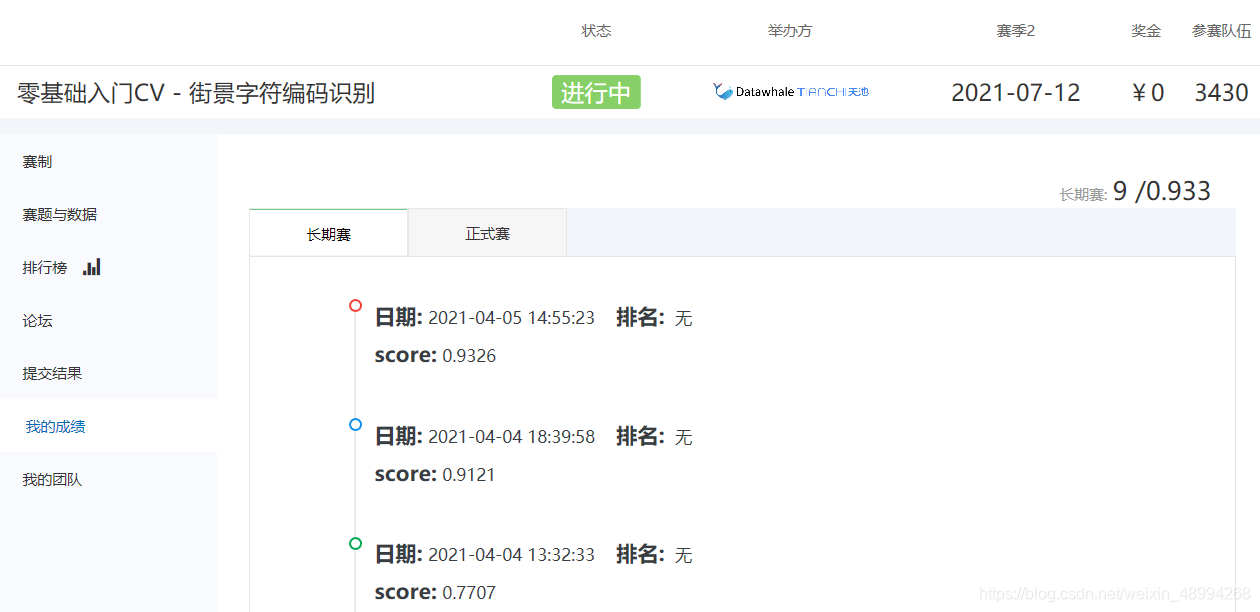
6 上傳檔案
目前得分0.933
展望:從nms和anchor上繼續改進,加入多尺度多模型融合
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/272958.html
標籤:AI
上一篇:5G OFDM科普
下一篇:Tomcat 啟動例外: java.lang.ClassFormatError: Truncated class file錯誤解決