Kubernetes實戰模擬一(wordpress基礎版)
Kubernetes實戰模擬二(wordpress高可用)
Kubernetes實戰模擬三(wordpress健康檢查和服務質量QoS)
Kubernetes實戰模擬四(wordpress升級更新)
原始碼地址:https://github.com/nangongchengfeng/Kubernetes/tree/main/wordpress-example
Kubernetes實戰模擬二,已經優化架構,已經采取分離,可以實作高可用,并優化軟策略,防止單點故障
接下來,慢慢實作健康檢查和服務質量
版本3
思路:分別對2個pod的進行埠檢查,判斷pod是否正常和流量提供,測驗性能,設定資源限制
健康檢查:主要檢查pod提供正常服務
資源限制:后期可以根據這個設定HPA,防止宿主資源不足,被驅逐
1、Pod的健康檢查,也叫做探針,探針的種類有兩種,
1)、livenessProbe,健康狀態檢查,周期性檢查服務是否存活,檢查結果失敗,將重啟容器,
2)、readinessProbe,可用性檢查,周期性檢查服務是否可用,不可用將從service的endpoints中移除,
livenessProbe (存活檢查) # 如果檢查失敗,將殺死容器,根據Pod的restartPolicy來操作
readinessProbe(就緒檢查) # 如果檢查失敗,kubernetes會把Pod從service endpoints中剔除
2、探針的檢測方法,
1)、exec,執行一段命令,
2)、httpGet,檢測某個http請求的回傳狀態碼,
3)、tcpSocket,測驗某個埠是否能夠連接,
3、startupProbe檢測
判斷容器內的應用程式是否已啟動,如果提供了啟動探測,則禁用所有其他探測,直到它成功為止,如果啟動探測失敗,kubelet將殺死容器,容器將服從其重啟策略,如果容器沒有提供啟動探測,則默認狀態為成功,
注意:不要將startupProbe和readinessProbe混淆,
配置Probe
Probe中有很多精確和詳細的配置,通過它們你能準確的控制liveness和readiness檢查:
initialDelaySeconds:容器啟動后第一次執行探測是需要等待多少秒,
periodSeconds:執行探測的頻率,默認是10秒,最小1秒,
timeoutSeconds:探測超時時間,默認1秒,最小1秒,
successThreshold:探測失敗后,最少連續探測成功多少次才被認定為成功,默認是1,對于liveness必須是1,最小值是1,
failureThreshold:探測成功后,最少連續探測失敗多少次才被認定為失敗,默認是3,最小值是1,HTTP probe中可以給
httpGet設定其他配置項:
host:連接的主機名,默認連接到pod的IP,你可能想在http header中設定”Host”而不是使用IP,
scheme:連接使用的schema,默認HTTP,
path: 訪問的HTTP server的path,
httpHeaders:自定義請求的header,HTTP運行重復的header,
port:訪問的容器的埠名字或者埠號,埠號必須介于1和65525之間,
命名空間:(namespace.yaml)
apiVersion: v1
kind: Namespace
metadata:
name: kube-examplemysql資源清單
mysql.yaml
apiVersion: v1
kind: Service
metadata:
name: wordpress-mysql
namespace: kube-example
labels:
app: wordpress
spec:
selector:
app: wordpress
tier: mysql
ports:
- port: 3306
targetPort: dbport
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: wordpress-mysql
namespace: kube-example
labels:
app: wordpress
tier: mysql
spec:
replicas: 1
template:
metadata:
name: wordpress-mysql
labels:
app: wordpress
tier: mysql
spec:
containers:
- name: mysql
image: mysql:5.7
args:
- --default_authentication_plugin=mysql_native_password
- --character-set-server=utf8mb4
- --collation-server=utf8mb4_unicode_ci
ports:
- containerPort: 3306
name: dbport
env:
- name: MYSQL_ROOT_PASSWORD
value: rootPassW0rd
- name: MYSQL_DATABASE
value: wordpress
- name: MYSQL_USER
value: wordpress
- name: MYSQL_PASSWORD
value: wordpress
imagePullPolicy: IfNotPresent
startupProbe: #首次啟動探測(如果沒有成功,不會運行下面livenessProbe)
tcpSocket:
port: 3306
failureThreshold: 2 #探測成功后,最少連續探測失敗多少次才被認定為失敗,默認是3,最小值是1,
initialDelaySeconds: 20 # 容器啟動后第一次執行探測是需要等待多少秒
timeoutSeconds: 10 # 探測超時時間,默認1秒,最小1秒,
periodSeconds: 10 # 執行探測的頻率,默認是10秒,最小1秒,
restartPolicy: Always
selector:
matchLabels:
app: wordpress
tier: mysql
因為這個是模擬環境,現在資料沒有持續化,如果加上下面的檢測,如果pod的有問題,直接重啟,資料都會丟失,這個后期資料持久化,我們可以加上面
livenessProbe:
tcpSocket:
port: 3306 # 訪問的容器的埠名字或者埠號
initialDelaySeconds: 10
timeoutSeconds: 5
failureThreshold: 5
periodSeconds: 5
successThreshold: 3 #探測失敗后,最少連續探測成功多少次才被認定為成功,默認是1,對于liveness必須是1,最小值是1,Wordpress 清單
wordpress.yaml
我們的應用現在還有一個非常重要的功能沒有提供,那就是健康檢查,我們知道健康檢查是提高應用健壯性非常重要的手段,當我們檢測到應用不健康的時候我們希望可以自動重啟容器,當應用還沒有準備好的時候我們也希望暫時不要對外提供服務,所以我們需要添加我們前面經常提到的 liveness probe 和 rediness probe 兩個健康檢測探針,檢查探針的方式有很多,我們這里當然可以認為如果容器的 80 埠可以成功訪問那么就是健康的,對于一般的應用提供一個健康檢查的 URL 會更好,這里我們添加一個如下所示的可讀性探針,為什么不添加存活性探針呢?這里其實是考慮到線上錯誤排查的一個問題,如果當我們的應用出現了問題,然后就自動重啟去掩蓋錯誤的話,可能這個錯誤就會被永遠忽略掉了,所以其實這是一個折衷的做法,不使用存活性探針,而是結合監控報警,保留錯誤現場,方便錯誤排查,但是可讀寫探針是一定需要添加的:
apiVersion: v1
kind: Service
metadata:
name: wordpress
namespace: kube-example
spec:
selector:
app: wordpress
tier: frontend
ports:
- port: 80
name: web
targetPort: wdport
type: ClusterIP
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: wordpress
namespace: kube-example
labels:
app: wordpress
tier: frontend
spec:
selector:
matchLabels:
app: wordpress
tier: frontend
replicas: 4 #多副本+pod的反親合力可以實作pod的高可用
template:
metadata:
name: wordpress
labels:
app: wordpress
tier: frontend
spec:
containers:
- name: wordpress
image: wordpress:5.3.2-apache
ports:
- containerPort: 80
name: wdport
env:
- name: WORDPRESS_DB_HOST
value: wordpress-mysql:3306
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_PASSWORD
value: wordpress
imagePullPolicy: IfNotPresent
startupProbe: #首次啟動探測(如果沒有成功,不會運行下面livenessProbe)
httpGet:
port: 80
failureThreshold: 2 #探測成功后,最少連續探測失敗多少次才被認定為失敗,默認是3,最小值是1,
initialDelaySeconds: 10 # 容器啟動后第一次執行探測是需要等待多少秒
timeoutSeconds: 10 # 探測超時時間,默認1秒,最小1秒,
periodSeconds: 5 # 執行探測的頻率,默認是10秒,最小1秒,
readinessProbe: # (就緒檢查) # 如果檢查失敗,kubernetes會把Pod從service endpoints中剔除
httpGet:
port: 80
initialDelaySeconds: 10
timeoutSeconds: 5
failureThreshold: 5
periodSeconds: 5
successThreshold: 3
affinity:
podAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
podAffinityTerm:
topologyKey: kubernetes.io/hostname
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- wordpress
restartPolicy: Always
上面為什么不用livenessProbe檢測,首先如果livenessProbe檢測失敗,會直接重啟pod的,會毀壞錯誤的資訊,不方便我們排查問題,我們有多個副本,如果一個出問題,其余會正常作業
livenessProbe: #(存活檢查) # 如果檢查失敗,將殺死容器,根據Pod的restartPolicy來操作
httpGet:
port: 80
initialDelaySeconds: 15
timeoutSeconds: 5
periodSeconds: 5
failureThreshold: 5PDB策略
pdb.yaml
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: wordpress-pdb
namespace: kube-example
spec:
maxUnavailable: 1
selector:
matchLabels:
app: wordpress
tier: frontend
服務質量 QoS
QoS 是 Quality of Service 的縮寫,即服務質量,為了實作資源被有效調度和分配的同時提高資源利用率,Kubernetes 針對不同服務質量的預期,通過 QoS 來對 Pod 進行服務質量管理,對于一個 Pod 來說,服務質量體現在兩個具體的指標:CPU 和記憶體,當節點上記憶體資源緊張時,Kubernetes 會根據預先設定的不同 QoS 類別進行相應處理,
QoS 主要分為 Guaranteed、Burstable 和 Best-Effort三類,優先級從高到低,我們先分別來介紹下這三種服務型別的定義,
Guaranteed(有保證的)
屬于該級別的 Pod 有以下兩種:
- Pod 中的所有容器都且僅設定了 CPU 和記憶體的 limits
- Pod 中的所有容器都設定了 CPU 和記憶體的 requests 和 limits ,且單個容器內的
requests==limits(requests不等于0)
Burstable(不穩定的)
Pod 中只要有一個容器的 requests 和 limits 的設定不相同,那么該 Pod 的 QoS 即為 Burstable,
Best-Effort(盡最大努力)
如果 Pod 中所有容器的 resources 均未設定 requests 與 limits,該 Pod 的 QoS 即為 Best-Effort,
fortio 部署
wget https://github.com/fortio/fortio/releases/download/v1.4.4/fortio-1.4.4-1.x86_64.rpm
rpm -ivh fortio-1.4.4-1.x86_64.rpm
nohup fortio server &
tail -f nohup.out開始測壓
命令列
fortio load -c 5 -n 20 -qps 0 http://www.baidu.com
#命令解釋如下:
-c 表示并發數
-n 一共多少請求
-qps 每秒查詢數,0 表示不限制
Web控制臺
web 控制臺方式就是提供給習慣使用 web 界面操作的同學一個途徑來使用 Fortio,因為是基于 web 方式,所以就需要首先啟動一個 web server,這樣客戶端瀏覽器才可以訪問到 web server 提供的操作界面進行負載壓測,默認情況 fortio server 會啟動 8080 埠,如下圖所示:
打開瀏覽器,輸入 http://IP:8080/fortio,訪問 Fortio server:
根據實作生成環境訪問人數和次數模擬
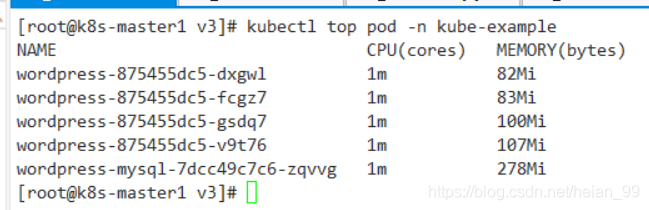
測驗前
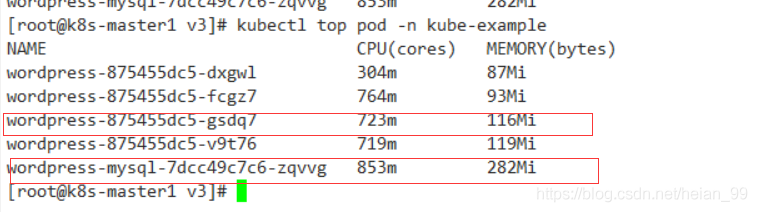
測驗后
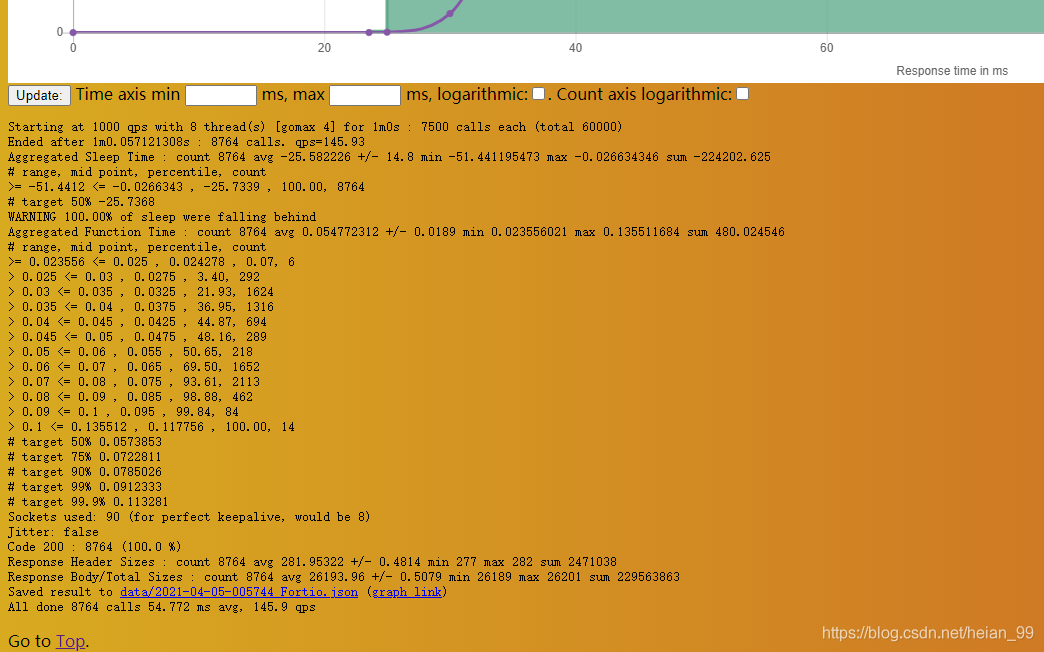
資源限制
采用Guaranteed(有保證的),防止宿主機資源不夠被優先驅逐
wordpress
resources:
limits:
cpu: 800m
memory: 150Mi
requests:
cpu: 800m
memory: 150Mimysql
resources:
limits:
cpu: 1000m
memory: 400Mi
requests:
cpu: 1000m
memory: 400Mi此版本實作健康檢查和服務質量QoS
問題
(1)自動擴縮容
(2)滾動更新策略
(3)資料持久化
(4)mysql賬號密碼注入等
這些一些列問題,都會在后面的版本架構中優化
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/273346.html
標籤:其他
下一篇:zabbix監控的報警機制