決策樹原理
決策樹(Decision Tree)是根據一系列規則對資料進行分類的程序,實際上決策樹的生成程序就是使用滿足劃分準則的特征不斷的將資料集劃分為純度更高,不確定性更小的子集的程序,對于當前資料集的每一次的劃分,都希望根據某特征劃分之后的各個子集的純度更高,不確定性更小,在學習之前先了解幾個概念,
資訊量:
香農被稱為“資訊論之父”,他認為“資訊就是用來消除不確定的性的東西”,也就是資訊量越大,不確定性就越小,資訊量的大小與事件發生的概率成反比,
資訊量的公式為:l(x)= -log2P(x) ,其中P(x)為事件發生的概率,
熵
熵也叫香農熵,指的是所有可能發生事件所帶來的資訊量的期望,也可以理解為熵描述的是資訊的無序程度,資訊越無序,熵越大,
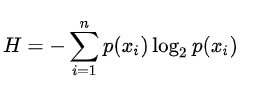
P(xi)表示Xi事件發生的概率,n為X中所有類別的個數,
資訊增益
資訊增益實際上就指的是資料集被劃分前后熵的差值,在決策資料中使用資訊增益來決定使用哪個資料特征值作為節點進行分割,在決策樹構建的程序中我們總是希望當前集合往最快到達純度更高的子集合方向發展,因此我們總是選擇使得資訊增益最大的特征來劃分當前資料集,
資訊增益 = 熵(前) - 熵(后)
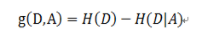
決策樹的構建
基于ID3演算法的決策樹實作
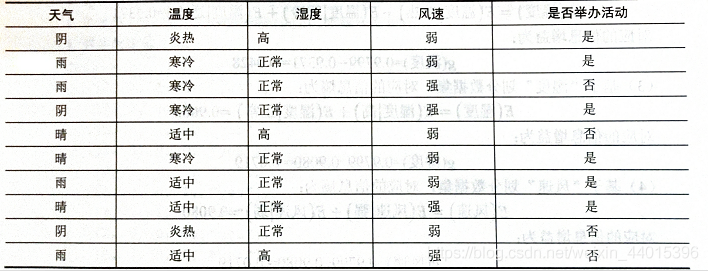
表中共有四個屬性:天氣、溫度、濕度、風速,2個類別標簽,典型的二分類問題,
10個樣本中,“是”的標簽有6個,“否”的標簽有4個,
1.計算當前熵E = - 6/10 * log2(6/10) + -4/10 * log2(4/10)
根據熵的計算公式,對每個屬性分別計算其對應的資訊熵,
2.以“天氣”為例,該屬性共有3中取值,
“晴”出現3次,其中“是”標簽有2個,“否”標簽有1個,則天氣為晴是對應的資訊熵為:
E(天氣|晴)=3/10 * [- 2/3 * log2(2/3) + -1/3 * log2(1/3)]
E(天氣|陰)=
E(天氣|雨)=
以下同理…
3.基于“天氣”劃分資料集,對應總的資訊熵為:
E(天氣) = E(天氣|晴) + E(天氣|陰) + E(天氣|雨)
4.對應的資訊增益為:
G(天氣) = E - E(天氣)
同理,求出其他幾個屬性的資訊熵,資訊增益,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/273353.html
標籤:其他
上一篇:Vue-Router
下一篇:求生存系列:序言