歷史熱門文章:
- 七種方式教你在SpringBoot初始化時搞點事情
- Java序列化的這三個坑千萬要小心
- 可以和面試官聊半個小時的volatile原理
- Java中七個潛在的記憶體泄露風險,你知道幾個?
- JDK 16新特性一覽
- 啥?用了并行流還更慢了
- InnoDB自增原理都搞不清楚,還怎么CRUD?
前言
在一場面試中最能打動面試官的其實是細節,候選人對細節的了解程度決定了留給面試官的印象到底是“基礎扎實”還是“基礎薄弱”,如果候選人能夠舉一反三主動闡述自己對一些技術細節的理解和總結,那無疑是面試程序中的一大亮點,HashMap是一個看著簡單,但其實里面有很多技術細節的資料結構,在一場高端的面試中即使不問任何紅黑樹(Java 8中HashMap引入了紅黑樹來處理極端情況下的哈希碰撞)相關的問題,也會有很多的技術細節值得挖掘,
把書讀薄
在Java 7中HashMap實作有1000多行,到了Java 8中增長為2000多行,雖然代碼行數不多,但代碼中有比較多的位運算,以及其他的一些細枝末節,導致這部分代碼看起來很復雜,理解起來比較困難,但是如果我們跳出來看,HashMap這個資料結構是非常基礎的,我們大腦中首先要有這樣一幅圖:
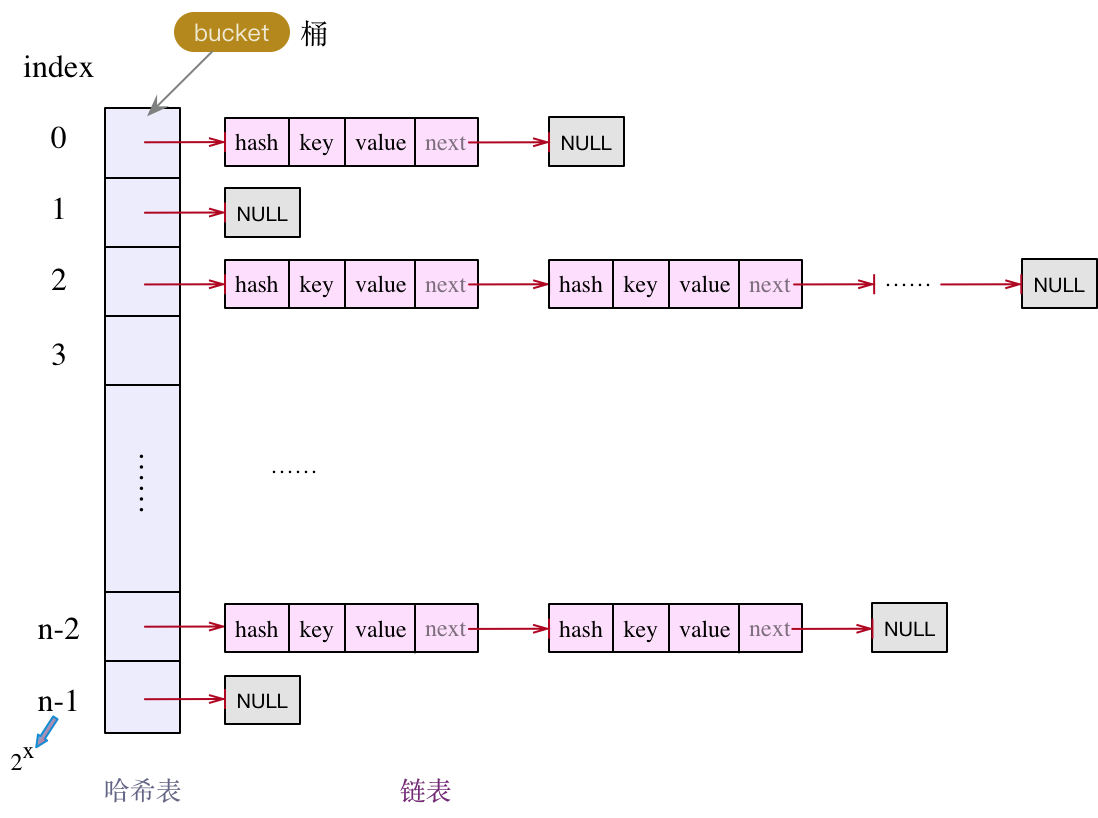
圖片來源:https://www.cnblogs.com/tianzhihensu/p/11972780.html
這張圖囊括了HashMap中最基礎的幾個點:
Java中HashMap的實作的基礎資料結構是陣列,每一對key->value的鍵值對組成Entity類以雙向鏈表的形式存放到這個陣列中- 元素在陣列中的位置由
key.hashCode()的值決定,如果兩個key的哈希值相等,即發生了哈希碰撞,則這兩個key對應的Entity將以鏈表的形式存放在陣列中 - 呼叫
HashMap.get()的時候會首先計算key的值,繼而在陣列中找到key對應的位置,然后遍歷該位置上的鏈表找相應的值,
當然這張圖中沒有體現出來的有兩點:
- 為了提升整個
HashMap的讀取效率,當HashMap中存盤的元素大小等于桶陣列大小乘以負載因子的時候整個HashMap就要擴容,以減小哈希碰撞,具體細節我們在后文中講代碼會說到 - 在
Java 8中如果桶陣列的同一個位置上的鏈表數量超過一個定值,則整個鏈表有一定概率會轉為一棵紅黑樹,
整體來看,整個HashMap中最重要的點有四個:初始化,資料尋址-hash方法,資料存盤-put方法,擴容-resize方法,只要理解了這四個點的原理和呼叫時機,也就理解了整個HashMap的設計,
把書讀厚
在理解了HashMap的整體架構的基礎上,我們可以試著回答一下下面的幾個問題,如果對其中的某幾個問題還有疑惑,那就說明我們還需要深入代碼,把書讀厚,
HashMap內部的bucket陣列長度為什么一直都是2的整數次冪HashMap默認的bucket陣列是多大HashMap什么時候開辟bucket陣列占用記憶體HashMap何時擴容?- 桶中的元素鏈表何時轉換為紅黑樹,什么時候轉回鏈表,為什么要這么設計?
Java 8中為什么要引進紅黑樹,是為了解決什么場景的問題?HashMap如何處理key為null的鍵值對?
new HashMap()
在JDK 8中,在呼叫new HashMap()的時候并沒有分配陣列堆記憶體,只是做了一些引數校驗,初始化了一些常量
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
tableSizeFor的作用是找到大于cap的最小的2的整數冪,我們假設n(注意是n,不是cap哈)對應的二進制為000001xxxxxx,其中x代表的二進制位是0是1我們不關心,
n |= n >>> 1;執行后n的值為:

可以看到此時n的二進制最高兩位已經變成了1(1和0或1異或都是1),再接著執行第二行代碼:

可見n的二進制最高四位已經變成了1,等到執行完代碼n |= n >>> 16;之后,n的二進制最低位全都變成了1,也就是n = 2^x - 1其中x和n的值有關,如果沒有超過MAXIMUM_CAPACITY,最后會回傳一個2的正整數次冪,因此tableSizeFor的作用就是保證回傳一個比入參大的最小的2的正整數次冪,
在JDK 7中初始化的代碼大體一致,在HashMap第一次put的時候會呼叫inflateTable計算桶陣列的長度,但其演算法并沒有變:
// 第一次put時,初始化table
private void inflateTable(int toSize) {
// Find an power of 2 >= toSize
int capacity = roundUpToPowerOf2(toSize);
threshold = (int)Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry(capacity);
initHashSeedAsNeeded(capacity);
}
這里我們也回答了開頭提出來的問題:
HashMap什么時候開辟bucket陣列占用記憶體?答案是在HashMap第一次put的時候,無論Java 8還是Java 7都是這樣實作的,這里我們可以看到兩個版本的實作中,桶陣列的大小都是2的正整數冪,至于為什么這么設計,看完后文你就明白了,
hash
在HashMap這個特殊的資料結構中,hash函式承擔著尋址定址的作用,其性能對整個HashMap的性能影響巨大,那什么才是一個好的hash函式呢?
- 計算出來的哈希值足夠散列,能夠有效減少哈希碰撞
- 本身能夠快速計算得出,因為
HashMap每次呼叫get和put的時候都會呼叫hash方法
下面是Java 8中的實作:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
這里比較重要的是(h = key.hashCode()) ^ (h >>> 16),這個位運算其實是將key.hashCode()計算出來的hash值的高16位與低16位繼續異或,為什么要這么做呢?
我們知道hash函式的作用是用來確定key在桶陣列中的位置的,在JDK中為了更好的性能,通常會這樣寫:
index =(table.length - 1) & key.hash();
回憶前文中的內容,table.length是一個2的正整數次冪,類似于000100000,這樣的值減一就成了000011111,通過位運算可以高效尋址,這也回答了前文中提到的一個問題,HashMap內部的bucket陣列長度為什么一直都是2的整數次冪?好處之一就是可以通過構造位運算快速尋址定址,
回到本小節的議題,既然計算出來的哈希值都要與table.length - 1做與運算,那就意味著計算出來的hash值只有低位有效,這樣會加大碰撞幾率,因此讓高16位與低16位做異或,讓低位保留部分高位資訊,減少哈希碰撞,
我們再看Java 7中對hash的實作:
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
Java 7中為了避免hash值的高位資訊丟失,做了更加復雜的異或運算,但是基本出發點都是一樣的,都是讓哈希值的低位保留部分高位資訊,減少哈希碰撞,
put
在Java 8中put這個方法的思路分為以下幾步:
- 呼叫
key的hashCode方法計算哈希值,并據此計算出陣列下標index - 如果發現當前的桶陣列為
null,則呼叫resize()方法進行初始化 - 如果沒有發生哈希碰撞,則直接放到對應的桶中
- 如果發生哈希碰撞,且節點已經存在,就替換掉相應的
value - 如果發生哈希碰撞,且桶中存放的是樹狀結構,則掛載到樹上
- 如果碰撞后為鏈表,添加到鏈表尾,如果鏈表超度超過
TREEIFY_THRESHOLD默認是8,則將鏈表轉換為樹結構 - 資料
put完成后,如果HashMap的總數超過threshold就要resize
具體代碼以及注釋如下:
public V put(K key, V value) {
// 呼叫上文我們已經分析過的hash方法
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
// 第一次put時,會呼叫resize進行桶陣列初始化
n = (tab = resize()).length;
// 根據陣列長度和哈希值相與來尋址,原理上文也分析過
if ((p = tab[i = (n - 1) & hash]) == null)
// 如果沒有哈希碰撞,直接放到桶中
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
// 哈希碰撞,且節點已存在,直接替換
e = p;
else if (p instanceof TreeNode)
// 哈希碰撞,樹結構
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 哈希碰撞,鏈表結構
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 鏈表過長,轉換為樹結構
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
// 如果節點已存在,則跳出回圈
break;
// 否則,指標后移,繼續后回圈
p = e;
}
}
if (e != null) { // existing mapping for key
// 對應著上文中節點已存在,跳出回圈的分支
// 直接替換
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
// 如果超過閾值,還需要擴容
resize();
afterNodeInsertion(evict);
return null;
}
相比之下Java 7中的put方法就簡單不少
public V put(K key, V value) {
// 如果 key 為 null,呼叫 putForNullKey 方法進行處理
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K, V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key
|| key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K, V> e = table[bucketIndex]; // ①
table[bucketIndex] = new Entry<K, V>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length); // ②
}
這里有一個小細節,HashMap允許putkey為null的鍵值對,但是這樣的鍵值對都放到了桶陣列的第0個桶中,
resize()
resize是整個HashMap中最復雜的一個模塊,如果在put資料之后超過了threshold的值,則需要擴容,擴容意味著桶陣列大小變化,我們在前文中分析過,HashMap尋址是通過index =(table.length - 1) & key.hash();來計算的,現在table.length發生了變化,勢必會導致部分key的位置也發生了變化,HashMap是如何設計的呢?
這里就涉及到桶陣列長度為2的正整數冪的第二個優勢了:當桶陣列長度為2的正整數冪時,如果桶發生擴容(長度翻倍),則桶中的元素大概只有一半需要切換到新的桶中,另一半留在原先的桶中就可以,并且這個概率可以看做是均等的,

通過這個分析可以看到如果在即將擴容的那個位上key.hash()的二進制值為0,則擴容后在桶中的地址不變,否則,擴容后的最高位變為了1,新的地址也可以快速計算出來newIndex = oldCap + oldIndex;
下面是Java 8中的實作:
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// 如果oldCap > 0則對應的是擴容而不是初始化
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 沒有超過最大值,就擴大為原先的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
// 如果oldCap為0, 但是oldThr不為0,則代表的是table還未進行過初始化
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
// 如果到這里newThr還未計算,比如初始化時,則根據容量計算出新的閾值
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
// 遍歷之前的桶陣列,對其值重新散列
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
// 如果原先的桶中只有一個元素,則直接放置到新的桶中
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
// 如果原先的桶中是鏈表
Node<K,V> loHead = null, loTail = null;
// hiHead和hiTail代表元素在新的桶中和舊的桶中的位置不一致
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
// loHead和loTail代表元素在新的桶中和舊的桶中的位置一致
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
// 新的桶中的位置 = 舊的桶中的位置 + oldCap, 詳細分析見前文
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
Java 7中的resize方法相對簡單許多:
- 基本的校驗之后
new一個新的桶陣列,大小為指定入參 - 桶內的元素根據新的桶陣列長度確定新的位置,放置到新的桶陣列中
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
boolean oldAltHashing = useAltHashing;
useAltHashing |= sun.misc.VM.isBooted() &&
(newCapacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
boolean rehash = oldAltHashing ^ useAltHashing;
transfer(newTable, rehash);
table = newTable;
threshold = (int) Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K, V> e : table) {
//鏈表跟table[i]斷裂遍歷,頭部往后遍歷插入到newTable中
while (null != e) {
Entry<K, V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
總結
在看完了HashMap在Java 8和Java 7的實作之后我們回答一下前文中提出來的那幾個問題:
-
HashMap內部的bucket陣列長度為什么一直都是2的整數次冪答:這樣做有兩個好處,第一,可以通過
(table.length - 1) & key.hash()這樣的位運算快速尋址,第二,在HashMap擴容的時候可以保證同一個桶中的元素均勻的散列到新的桶中,具體一點就是同一個桶中的元素在擴容后一般留在原先的桶中,一般放到了新的桶中, -
HashMap默認的bucket陣列是多大答:默認是16,即時指定的大小不是2的整數次冪,
HashMap也會找到一個最近的2的整數次冪來初始化桶陣列, -
HashMap什么時候開辟bucket陣列占用記憶體答:在第一次
put的時候呼叫resize方法 -
HashMap何時擴容?答:當
HashMap中的元素熟練超過閾值時,閾值計算方式是capacity * loadFactor,在HashMap中loadFactor是0.75 -
桶中的元素鏈表何時轉換為紅黑樹,什么時候轉回鏈表,為什么要這么設計?
答: 當同一個桶中的元素數量大于等于8的時候元素中的鏈表轉換為紅黑樹,反之,當桶中的元素數量小于等于6的時候又會轉為鏈表,這樣做的原因是避免紅黑樹和鏈表之間頻繁轉換,引起性能損耗
-
Java 8中為什么要引進紅黑樹,是為了解決什么場景的問題?答:引入紅黑樹是為了避免
hash性能急劇下降,引起HashMap的讀寫性能急劇下降的場景,正常情況下,一般是不會用到紅黑樹的,在一些極端場景下,假如客戶端實作了一個性能拙劣的hashCode方法,可以保證HashMap的讀寫復雜度不會低于O(lgN)public int hashCode() { return 1; } -
HashMap如何處理key為null的鍵值對?答:放置在桶陣列中下標為0的桶中
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/273651.html
標籤:AI