預測服務基于華為分析服務(Analytics Kit)上報的用戶行為資料和屬性,結合機器學習技術,實作特定目標人群的精準預測,針對預測生成的細分受眾群體,開展和優化相關運營舉措,如通過A/B測驗評估運營活動效果、遠程配置特定受眾群體的專屬套餐等,可有效幫助產品提高用戶留存,增加轉化,
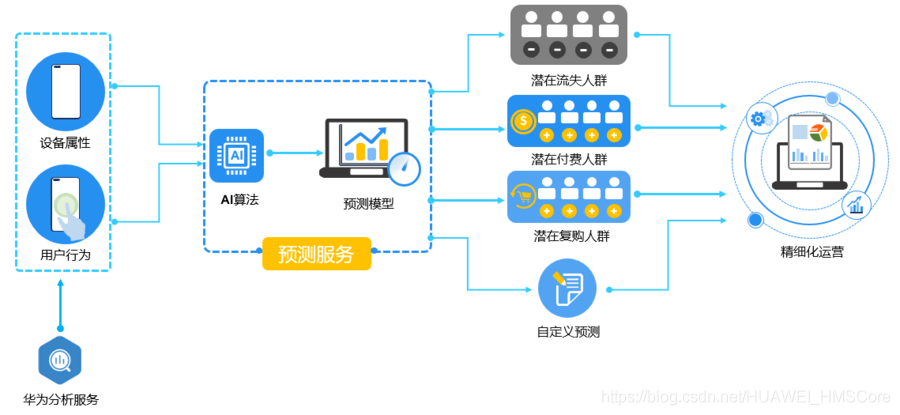
使用預測服務前,需要先集成華為分析服務的SDK,這樣系統才可以順利開展流失、付費、復購以及自定義預測任務,在詳情界面可以查看相關預測人群的高中低概率對應人群數量,及其相應的屬性分布(比如詳情頁的高概率流失人群,表示該人群在未來7日內有較高概率流失,您可以通過相關卡片,觀察其行為特點并制定針對性運營計劃),
預測任務和預測詳情界面如下所示:
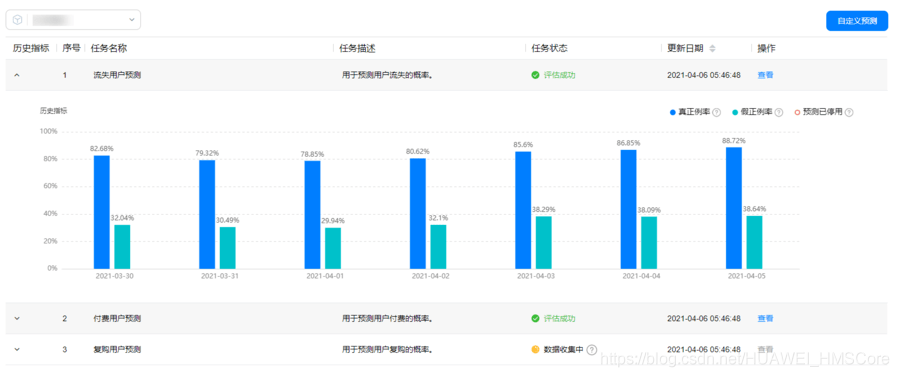
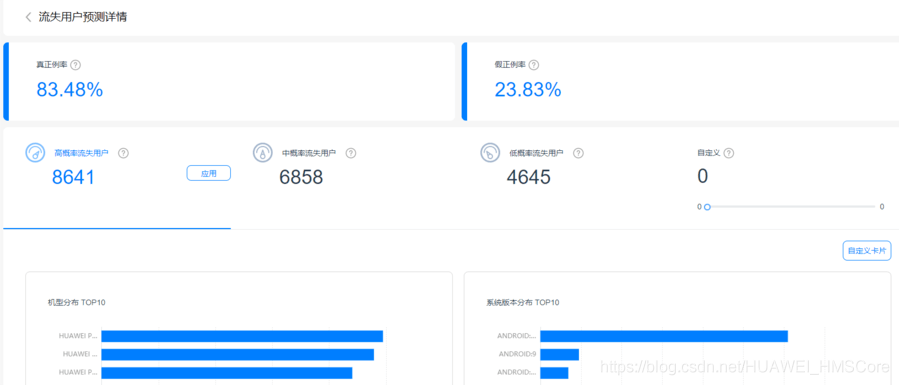
*資料為模擬
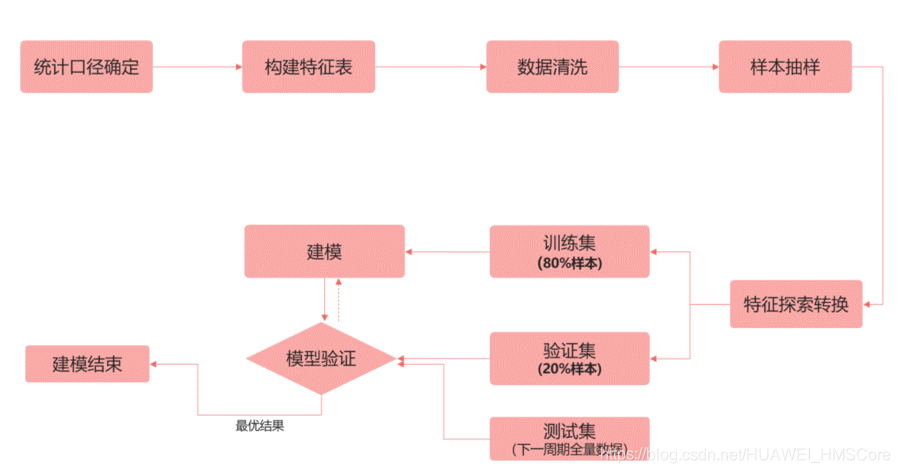
預測模型構建流程
在構建預測模型的時候,首先是確定我們要預測什么,即確立預測的統計口徑,然后根據統計口徑圍繞用戶特點尋找對應相關的特征,通過清洗和采樣得到資料集,我們把資料集二八分得到訓練集和驗證集,在線下進行不斷實驗找到最優特征和引數,最后根據相關資料在線上調度訓練預測任務,
具體流程圖如下所示:
特征、模型選擇和調優
特征探索
專案初期,我們分析資料,從屬性、行為、需求三方面入手,尋找與業務有可能相關的變數,構建特征表,比如用戶近7天的活躍天數、使用時長等行為資料,
在確定特征之后,下一步就是在實驗中進行模型的選擇和調優了,業界常用的樹形模型有xgboost、隨機森林、GBDT等,把我們的資料集用這幾種模型進行訓練,發現在隨機森林上效果較好,其采用bagging策略提高模型擬合能力和泛化能力,
除了模型引數,也要考慮采樣比,尤其是對于付費預測這種正負樣本懸殊的情況(大約1:100),綜合考慮Accuracy和Recall, 付費訓練時將正負樣本比例采樣至1.5:1, 以提高模型付費用戶召回率,
超參與特征確立
訓練出了合適的模型,但并非所有特征都是有用的,無用特征除了可能會影響模型效果,也會減慢訓練速度,在初期版本中,通過實驗確定合適的超參和特征,特征按照特征重要性排序選擇權重較大的,在線上版本中配置對應的超參和特征,
在版本上線之后還需要不斷觀察資料、分析資料、補充特征,我們在后續版本中主要新增了事件特征與趨勢特征,補充后總計400+特征,
自動超搜索參
在挖掘出更多的特征之后,如果都是全量特征訓練可能效果未必會好,而且也會非常耗時,同時,可能每個App訓練時可能最優的超參和特征并不相同,最好是每個App分開訓練且使用自己最優的超參和特征,
為了解決這些問題,我們增加了自動的超參搜索,可以在配置好的引數空間里搜索,找到并保存合適的訓練引數,搜索完之后的最優超參保存在如下結構的hive表中,
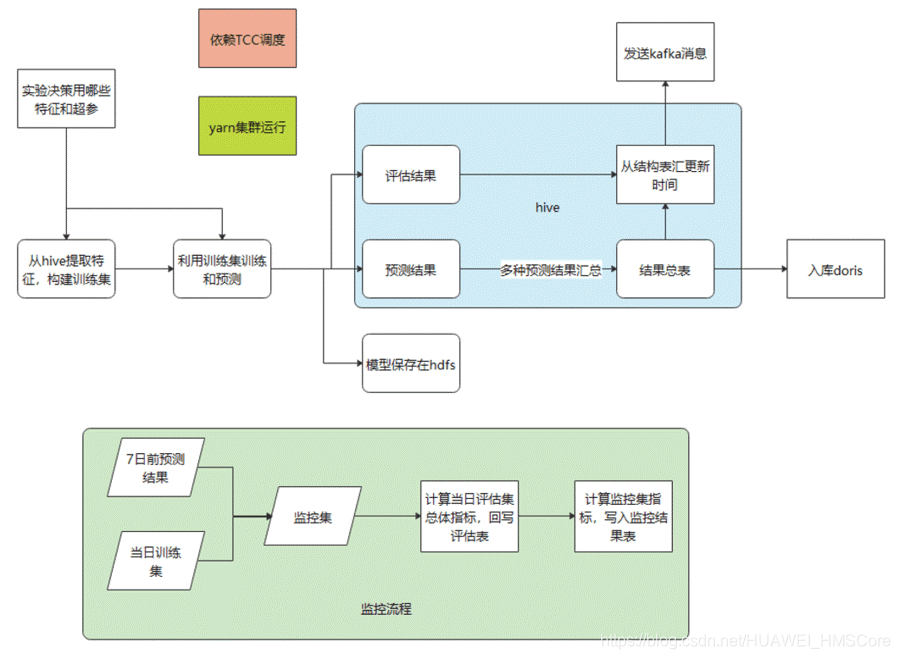
當前的整體流程以及外部依賴如下所示:
未來方向
在未來提高模型效果上,我們也有很多思考,預研的方向大致如下:
l 神經網路
當前的特征規模不斷擴大(400+),而用戶行為的規律又十分復雜,除了使用原有的樹形模型,也在嘗試利用神經網路強大的表達能力,結合行為特征訓練出更準確的預測模型,
l 聯邦學習
對于各App、各租戶資料不可互通的問題,可以通過橫向聯邦學習聯合各個App、各個租戶間的模型,在資料不互通的前提下協同訓練,
l 時序特征
不同App的用戶每周上報數百個事件(涵蓋1000+種類),訪問近百個頁面,通過這些時序資料可以構造出不同用戶的長短期行為特征,提高不同場景預測的準確率,用戶訪問頁面的行為有較高的時序特點,可以加工成時間序列特征,有較高的研究價值,
l 特征挖掘和加工
對目前的特征集擴充、補充,一方面挖掘更多的相關特征比如平均使用間隔、設備屬性、安裝渠道、國家省市等特征,另一方面基于現有特征通過離散化、歸一化、開方、平方、笛卡爾積、多重笛卡爾積等等方法構造更多新特征,
欲了解更多華為預測服務詳情,請點擊>>
>>訪問華為開發者聯盟官網,了解更多相關內容
>>獲取開發指導檔案
>>華為移動服務開源倉庫地址:GitHub、Gitee
關注我們,第一時間了解華為移動服務最新技術資訊~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/273682.html
標籤:其他