本文已收錄github:https://github.com/BigDataScholar/TheKingOfBigData,里面有大資料高頻考點,Java一線大廠面試題資源,上百本免費電子書籍,作者親繪大資料生態圈思維導圖…持續更新,歡迎star!
前言
阿里巴巴也曾創建過一個開源專案叫作 Druid(簡稱阿里Druid),它是一個資料庫連接池的專案,而本期內容介紹的是一個分布式的支持實時分析的資料存盤系統(Data Store),Druid 設計之初的想法就是為分析而生,它在處理資料的規模、資料處理的實時性方面,比傳統的 OLAP 系統有了顯著的性能改進,而且擁抱主流的開源生態,包括 Hadoop 等,多年以來,Druid 一直是非常活躍的開源專案!

Druid
Druid 簡介
Druid 是一個高性能的實時分析資料庫,它在 PB 級資料處理、毫秒級查詢、資料實時處理方面,比傳統的 OLAP 系統有顯著的性能提升,
Druid 的官方網站是 http://druid.io
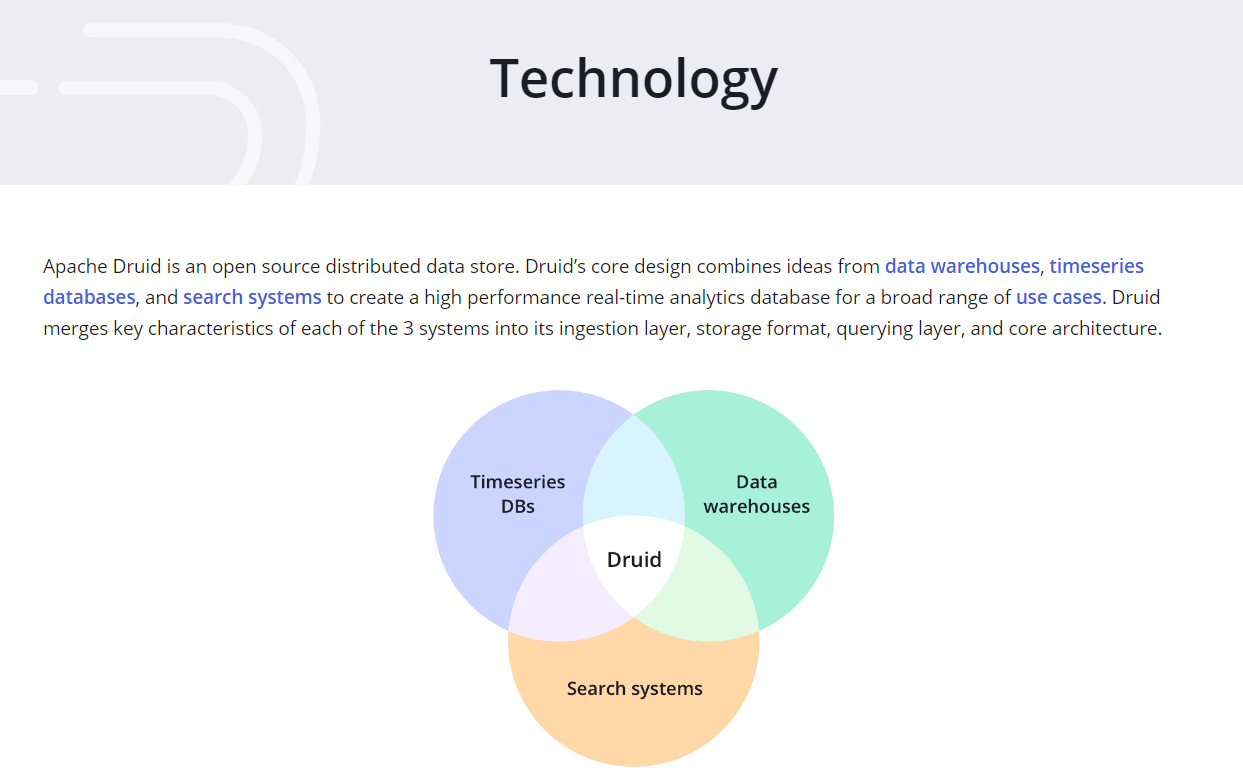
Druid 的三個設計原則
- 快速查詢(Fast Query):部分資料的聚合(Partial Aggregate)+記憶體化(In-emory)+索引(Index),
- 水平擴展能力(Horizontal Scalability):分布式資料(Distributed Data)+ 并行化查詢(Parallelizable Query)
- 實時分析(Realtime Analytics):不可變的過去,只追加的未來(Immutable Past,Append-Only Future)
1. 快速查詢(Fast Query)
對于資料分析場景,大部分情況下,我們只關心一定粒度聚合的資料,而非每一行原始資料的細節情況,因此,資料聚合粒度可以是1 分鐘、5 分鐘、1 小時或1 天等,部分資料聚合(Partial Aggregate)給 Druid 爭取了很大的性能優化空間,
資料記憶體化也是提高查詢速度的殺手锏,記憶體和硬碟的訪問速度相差近百倍,但記憶體的大小是非常有限的,因此在記憶體使用方面要精細設計,比如Druid 里面使用了 Bitmap 和各種壓縮技術,
另外,為了支持 Drill-Down 某些維度,Druid 維護了一些倒排索引,這種方式可以加快 AND 和 OR 等計算操作,
2、水平擴展能力(Horizontal Scalability)
Druid 查詢性能在很大程度上依賴于記憶體的優化使用,資料可以分布在多個節點的記憶體中,因此當資料增長的時候,可以通過簡單增加機器的方式進行擴容,為了保持平衡,Druid按照時間范圍把聚合資料進行磁區處理,對于高基數的維度,只按照時間切分有時候是不夠的(Druid 的每個Segment 不超過2000 萬行),故Druid 還支持對Segment 進一步磁區, 歷史Segment 資料可以保存在深度存盤系統中,存盤系統可以是本地磁盤、HDFS 或遠程的云服務,如果某些節點出現故障,則可借助Zookeeper 協調其他節點重新構造資料,
Druid 的查詢模塊能夠感知和處理集群的狀態變化,查詢總是在有效的集群架構中進行,集群上的查詢可以進行靈活的水平擴展,
3、實時分析(Realtime Analytics)
Druid 提供了包含基于時間維度資料的存盤服務,并且任何一行資料都是歷史真實發生的事件,因此在設計之初就約定事件一但進入系統,就不能再改變,
對于歷史資料 Druid 以Segment 資料檔案的方式組織,并且將它們存盤到深度存盤系統中,例如檔案系統或亞馬遜的S3 等,當需要查詢這些資料的時候,Druid 再從深度存盤系統中將它們裝載到記憶體供查詢使用,
Druid 特點
Druid具有如下技術特點:
- 列式存盤格式
Druid使用面向列的存盤,這意味著它只需要加載特定查詢所需的精確列,這為僅查看幾列的查詢提供了巨大的速度提升,此外,每列都針對其特定資料型別進行了優化,支持快速掃描和聚合,
- 高可用性與高可拓展性
Druid采用分布式、SN(share-nothing)架構,管理類節點可配置HA,作業節點功能單一,不相互依賴,這些特性都使得Druid集群在管理、容錯、災備、擴容等方面變得十分簡單,Druid通常部署在數十到數百臺服務器的集群中,并且可以提供數百萬條記錄/秒的攝取率,保留數萬億條記錄,以及亞秒級到幾秒鐘的查詢延遲,
- 大規模的并行查詢
Druid可以在整個集群中進行大規模的并行查詢,
- 實時攝取或批量處理
實時流資料分析,區別于傳統分析型資料庫采用的批量匯入資料進行分析的方式,Druid提供了實時流資料分析,采用LSM(Long structure-merge)-Tree結構使 Druid 擁有極高的實時寫入性能;同時實作了實時資料在亞秒級內的可視化,
- 自愈、自平衡、易操作
作為運營商,要將群集擴展或縮小,只需添加或洗掉服務器,群集將在后臺自動重新平衡,無需任何停機時間,如果任何Druid服務器發生故障,系統將自動路由損壞,直到可以更換這些服務器,Druid旨在全天候運行,無需任何原因計劃停機,包括配置更改和軟體更新,
- 云原生,容錯的架構,不會丟失資料
一旦 Druid 攝取了您的資料,副本就會安全地存盤在深層存盤(通常是云存盤,HDFS或共享檔案系統)中,即使每個Druid服務器都出現故障,您的資料也可以從深層存盤中恢復,對于僅影響少數 Druid 服務器的更有限的故障,復制可確保在系統恢復時仍可進行查詢,
- 亞秒級的OLAP查詢分析
Druid采用了列式存盤、倒排索引、位圖索引等關鍵技術,能夠在亞秒級別內完成海量資料的過濾、聚合以及多維分析等操作,
- 豐富的資料分析功能
針對不同用戶群體,Druid提供了友好的可視化界面、類SQL查詢語言以及REST 查詢介面,
Druid 的使用場景
了解了 Druid 有哪些常見的特點,我們還需要知道它具體的使用場景,
如果您的用例符合以下的幾個描述,Druid 可能是一個不錯的選擇:
- 插入率非常高,但更新不常見
- 大多數查詢都是聚合和報告查詢(“分組依據”查詢),您可能還有搜索和掃描查詢,
- 查詢延遲定位為100毫秒到幾秒鐘
- 資料有一個時間組件(Druid包括與時間特別相關的優化和設計選擇),
- 可能有多個表,但每個查詢只能訪問一個大的分布式表,查詢可能會觸發多個較小的“查找”表,
- 有高基數資料列(例如URL,用戶ID),需要對它們進行快速計數和排名,
- 希望從 Kafka,HDFS,平面檔案或物件存盤(如Amazon S3)加載資料,
要是感覺看的不是很懂,簡潔地總結一下:
- 適用于將清洗好的記錄實時錄入,但不需要更新操作的場景
- 適用于支持寬表,不用join的場景(換句話說就是一張單表)
- 適用于實時性要求高的場景
- 適用于對資料質量的敏感度不高的場景
當然以上列舉的都是 Druid 的適用情況,為了方便我們之后做技術選型,我們還需要知道它不支持哪些操作,
- 不支持精確去重
- 不支持 Join(只能進行 semi-join)
- 不支持根據主鍵的單條記錄更新
所以如果不能接受這幾點,則可以考慮放棄使用 Druid 了,
那 Druid 的常見應用領域有哪些呢 ?
- 點擊流分析(網路和移動分析)
- 風險/欺詐分析
- 網路遙測分析(網路性能監控)
- 服務器指標存盤
- 供應鏈分析(制造指標)
- 應用程式性能指標
- 商業智能/ OLAP
關于更詳細的描述,建議大家去多瀏覽官網https://druid.apache.org/use-cases,這里不做過多贅述 ,
下面來侃侃 Druid 的 架構 ~
Druid架構
Druid 采用多行程,分布式的架構;其架構易于運維及部署,便于部署在云環境中,每個 Druid 行程都可以被獨立地配置和橫向擴展,這種設計一方面賦予了Druid集群 最大的靈活性和可擴展性,另一方面以提供了更高的容錯性:避免了個別組件的失效影響了系統的其他模塊,
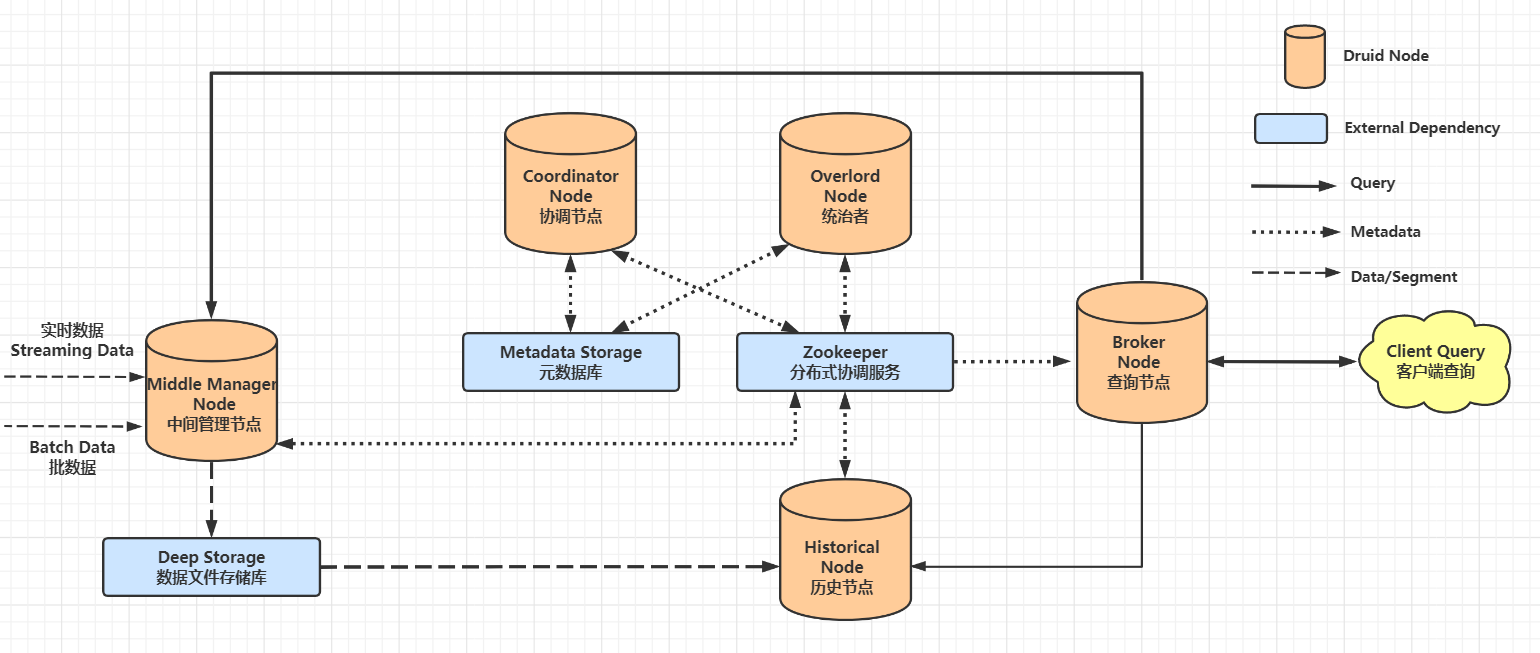
Druid的總體架構包含如下四類節點,
- 中間管理節點(MiddleManager Node):及時攝入實時資料,并生成 Segment 資料檔案,
- 歷史節點(Historical Node):加載已生成的資料檔案,以供用戶查詢資料,
- 查詢節點(Broker Node):對外提供資料查詢服務,并同時從中間管理節點與歷史節點中查詢資料,合并后回傳呼叫方,
- 協調節點(Coordinator Node):負責歷史節點的資料負載均衡,以及通過規則(Rule)管理資料的生命周期,
集群還包含如下三類外部依賴:
-
元資料庫(Metadata Storage):存盤Druid 集群的元資料資訊,比如,Segment 的相關資訊,一般使用 MySQL 或 PostgreSQL 存盤,
-
分布式協調服務(Zookeeper):為 Druid 集群提供一致性協調服務的組件,通常為 Zookeeper,
-
資料檔案存盤庫(Deep Storage):存放生成的 Segment 資料檔案,并提供歷史服務器下載功能,對于單節點集群,可以是本地磁盤,而對于分布式集群,一般是 HDFS 或 NFS ,
Druid 資料結構
基于 DataSource 和 Segment 的 Druid 資料結構與 Druid 架構相輔相成,它們共同成就了 Druid 的高性能優勢,
DataSource相當于關系型資料庫中的表(Table),DataSource的結構如下,
- 時間列:表明每行資料的時間值,默認使用UTC時間格式且精確到毫秒級,
- 維度列:維度來自OLAP的概念,用來標識資料行的各個類別資訊,
- 指標列:用于聚合和計算的列,通常是一些數字,計算操作包括Count、Sum等,
DataSource 結構如表所示:
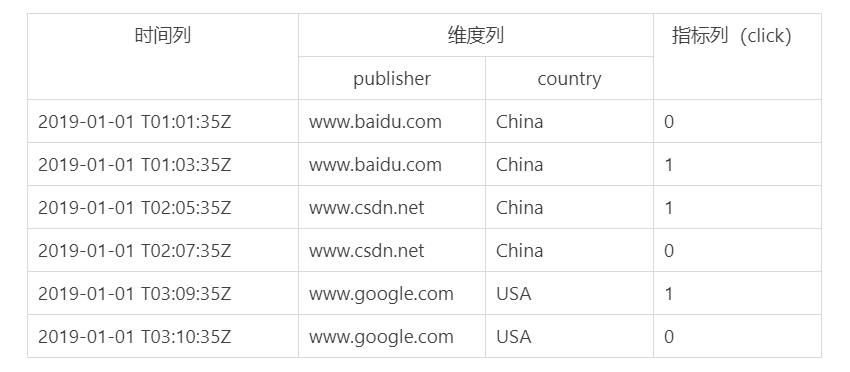
無論是實時攝取資料還是批量處理資料,Druid 在基于 DataSource 結構存盤資料時,可選擇對任意的指標列進行聚合操作,該聚合操作主要基于維度列與時間列,表顯示的是 DataSource 聚合后的資料結構,
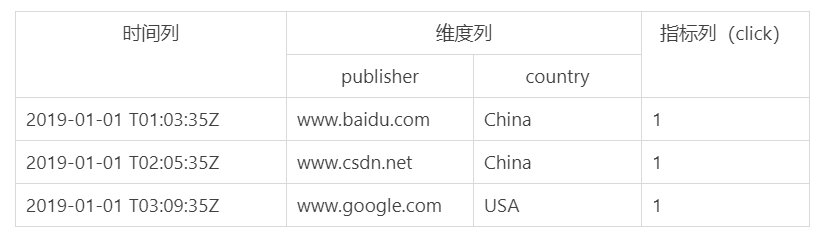
在資料存盤時便可對資料進行聚合操作是 Druid 的特點,該特點使得 Druid 不僅能夠節省存盤空間,而且能夠提高聚合查詢的效率,
DataSource是一個邏輯概念,Segment是資料的實際物理存盤格式,Druid將不同時間范圍內的資料存盤在不同的 Segment 資料塊中,這便是所謂的資料橫向切割,按照時間橫向切割資料,避免了全表查詢,極大地提高了效率,
在Segment中,采用列式存盤格式對資料進行壓縮存盤(Bitmap壓縮技術),這便是所謂的資料縱向切割,
Druid 安裝
接下來為大家介紹如何安裝 Druid,本次我們演示安裝的是單機版,
安裝部署
我們可以選擇去官網 https://druid.apache.org/下載
另外我們也可以選擇https://imply.io/,從 imply頁面下載 Druid 最新版本的安裝包,因為 imply 集成了Druid ,提供了 Druid 從部署到配置再到各種可視化工具的完整解決方案,所以這里我們使用了第 2 種方法 ~
(1)將 imply-2.7.10.tar.gz上傳到 node01 節點的的 /opt/software 目錄下,并解壓到/export/servers目錄下,
[root@node01 software]# tar -zxvf imply-2.7.10.tar.gz -C ../servers/
(2)修改imply-2.7.10的名稱為imply,
[root@node01 servers]# mv imply-2.7.10 imply
(3)修改組態檔
① 修改 Druid 的 ZK 配置
[root@node01 servers]# vim imply/conf/druid/_common/common.runtime.properties
需要修改的內容如下
druid.zk.service.host=node01:2181,node02:2181,node03:2181
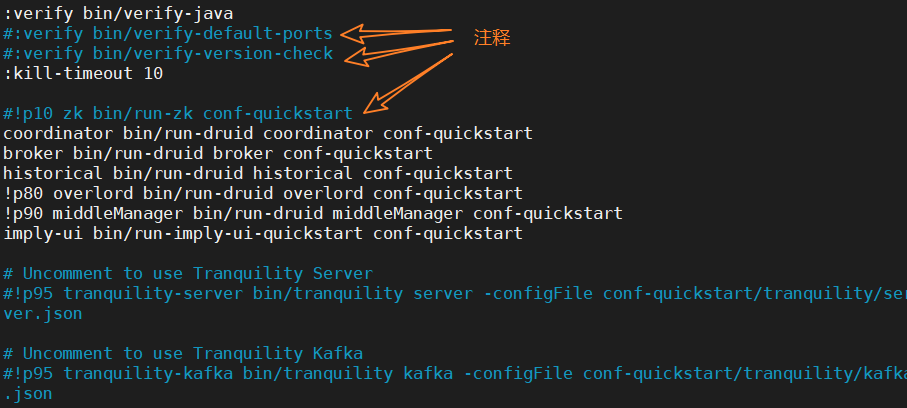
② 修改啟動命令引數,使其不校驗、不啟動內置ZK,
(4)啟動
① 啟動 Zookeeper
[root@node01 imply]# zk_startall.sh
② 通過 bin 目錄下的 supervise 命令啟動 imply
[root@node01 imply]$ bin/supervise -c conf/supervise/quickstart.conf
說明:每啟動一個服務均會列印出一條日志,我們可以在/opt/module/imply/var/sv/目錄下查看服務啟動時的日志資訊,
(1)啟動成功之后呢,我們可以通過 ip:埠的方式進行訪問,以我當前所安裝 Druid 的節點 node01 為例,當我訪問node01:9095/datasets,便可以在網頁上看到如下界面:
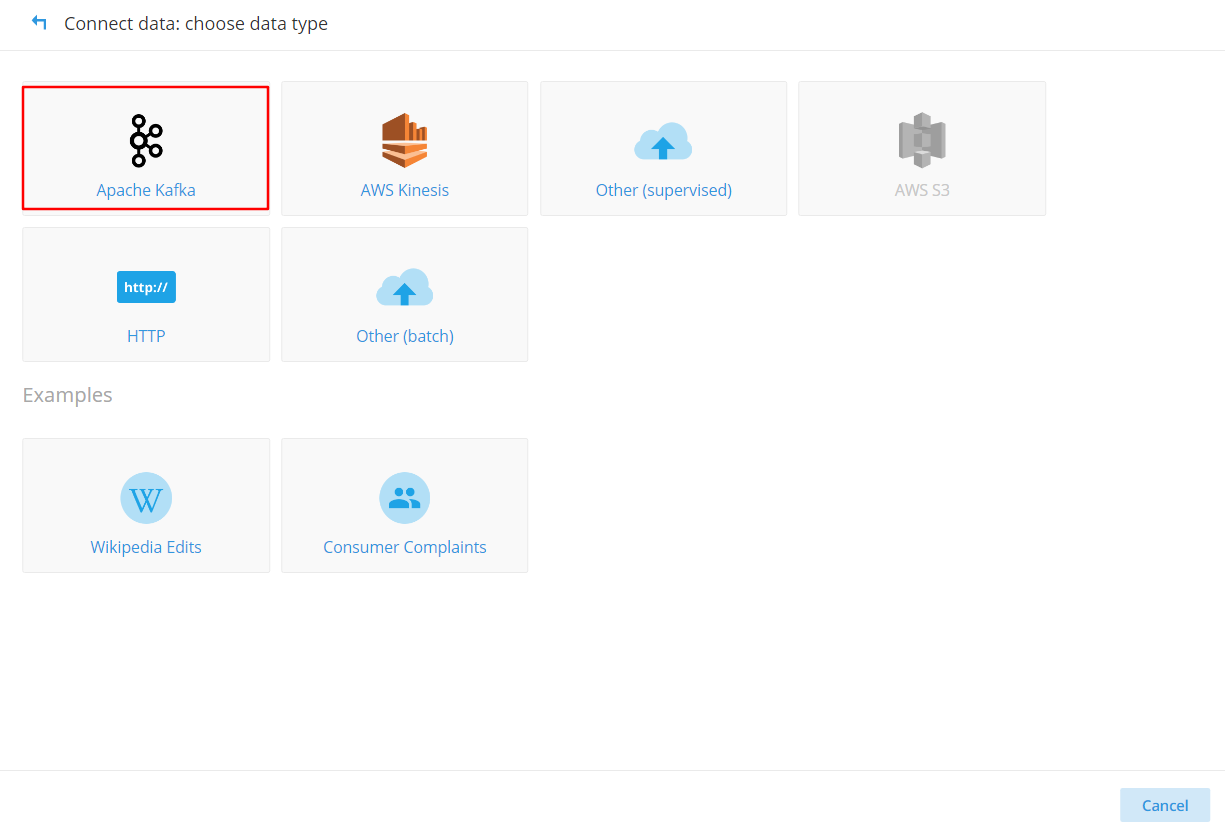
(2)單擊“Load data”按鈕,然后單擊“Apache Kafka”按鈕:
(3)添加 Kafka 集群和主題資訊,并選擇合適的格式化形式
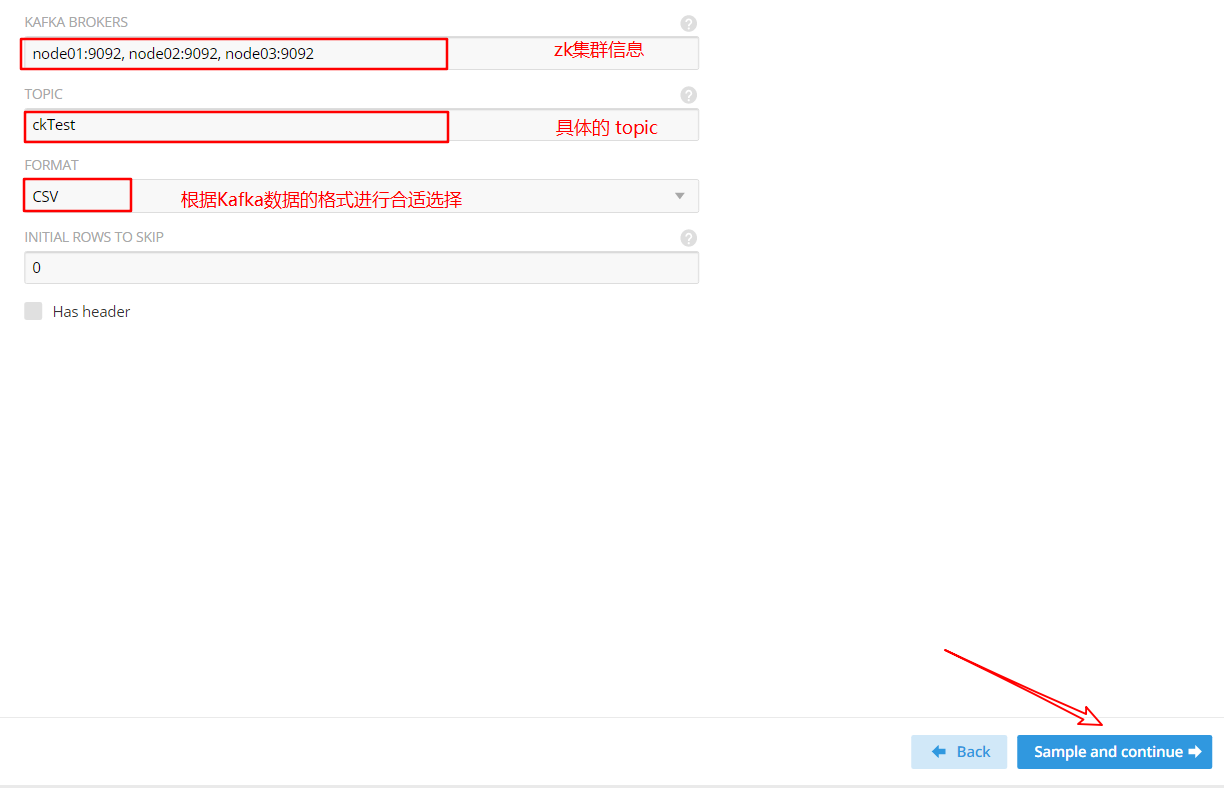
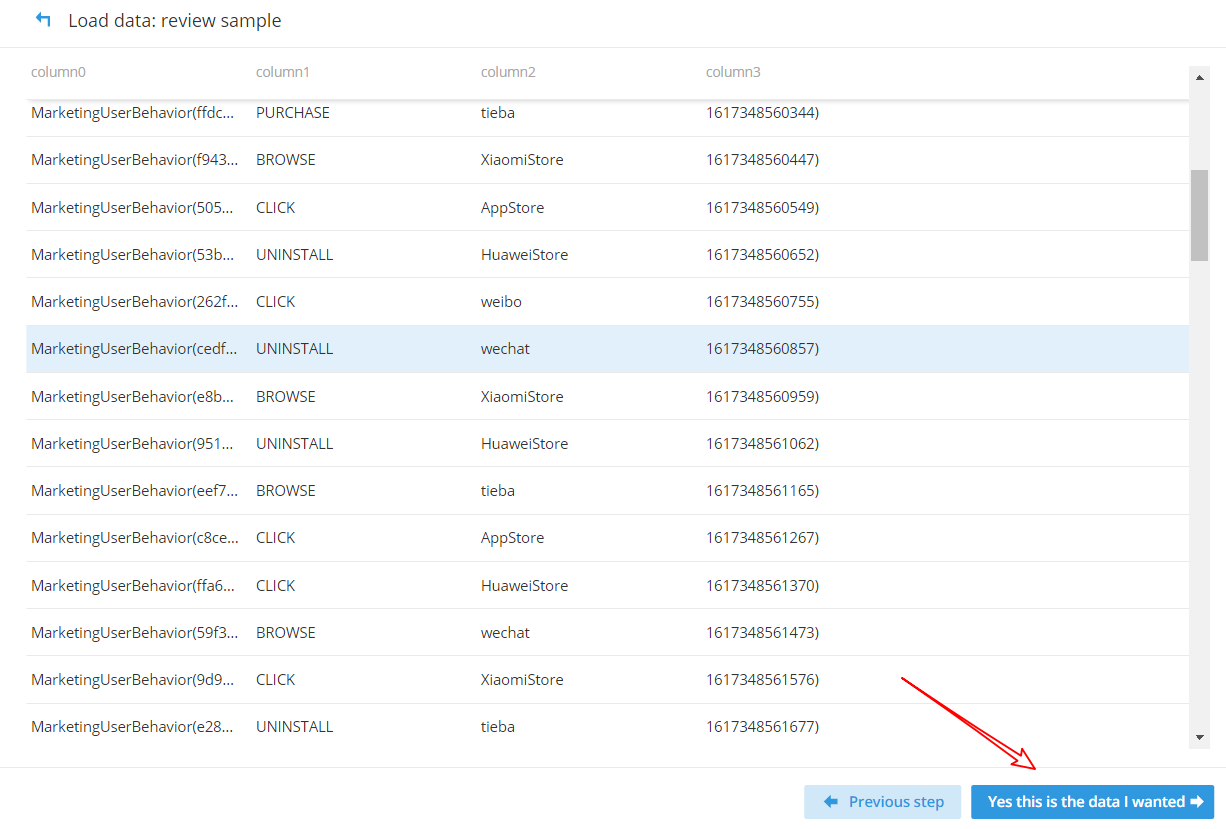
(4)確認資料樣本格式
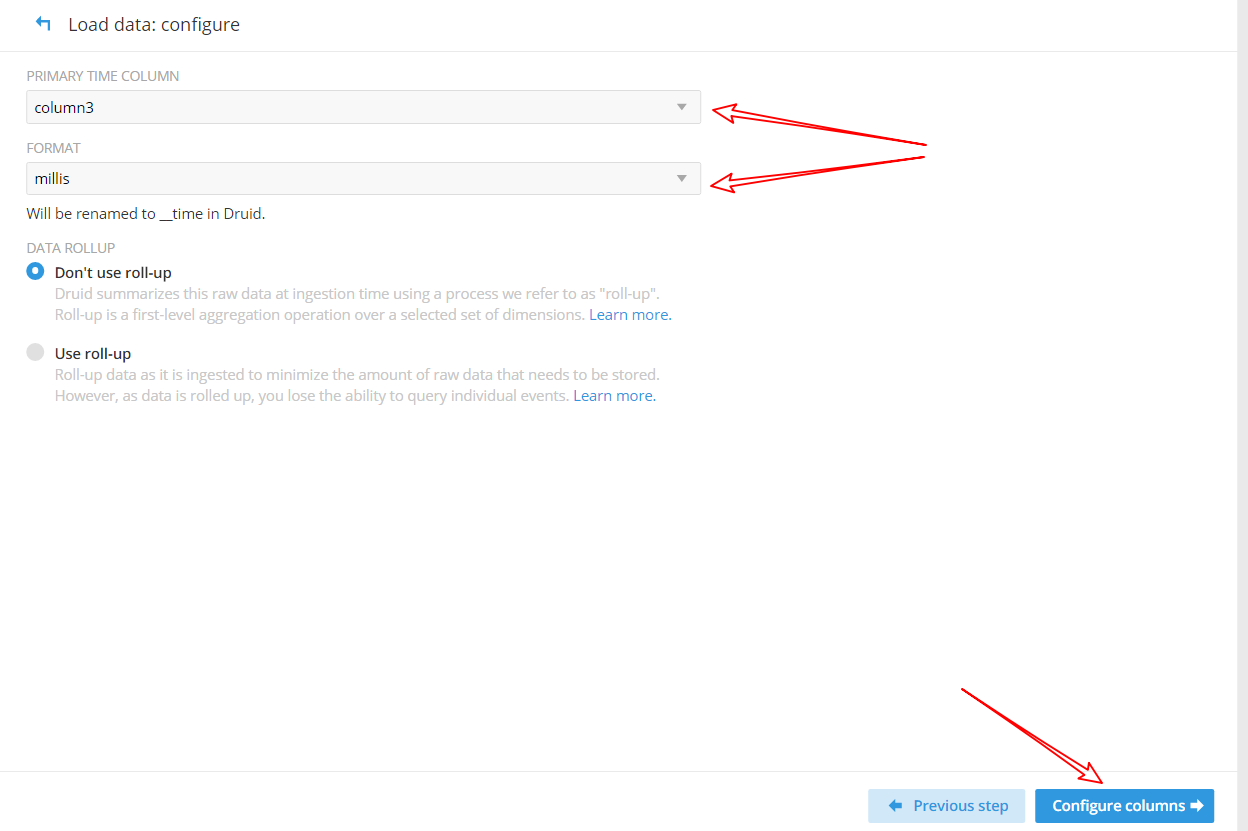
(5)加載資料,必須要有時間欄位
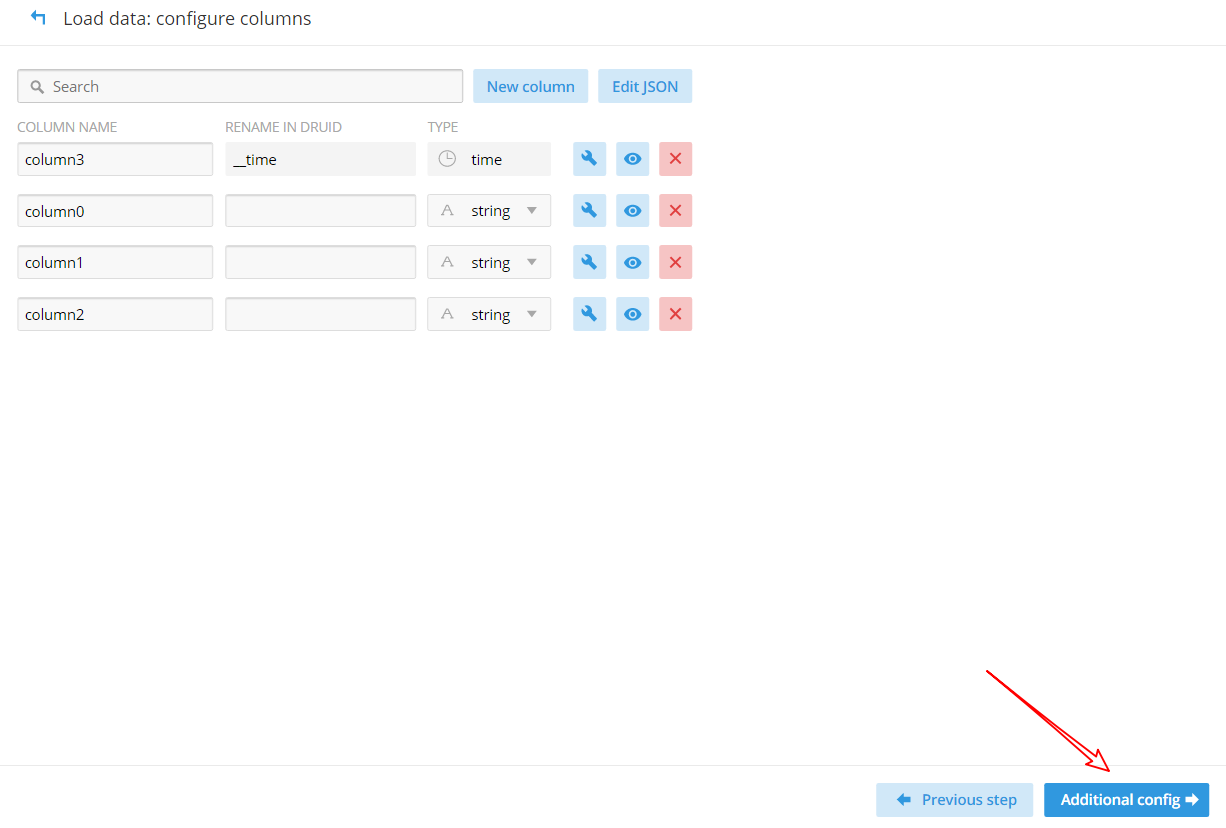
(6)配置要加載的列
(7)配置 Kafka 資料源
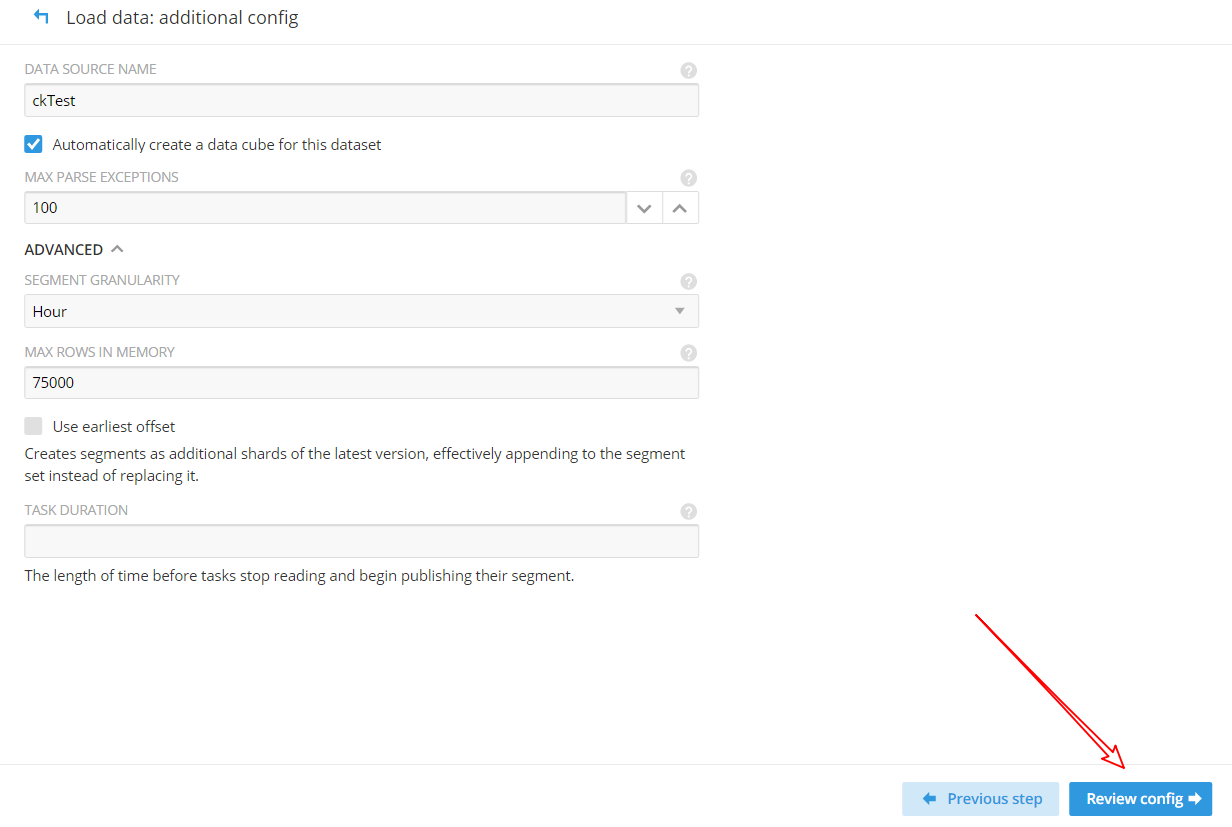
(8)確認加載資料的配置
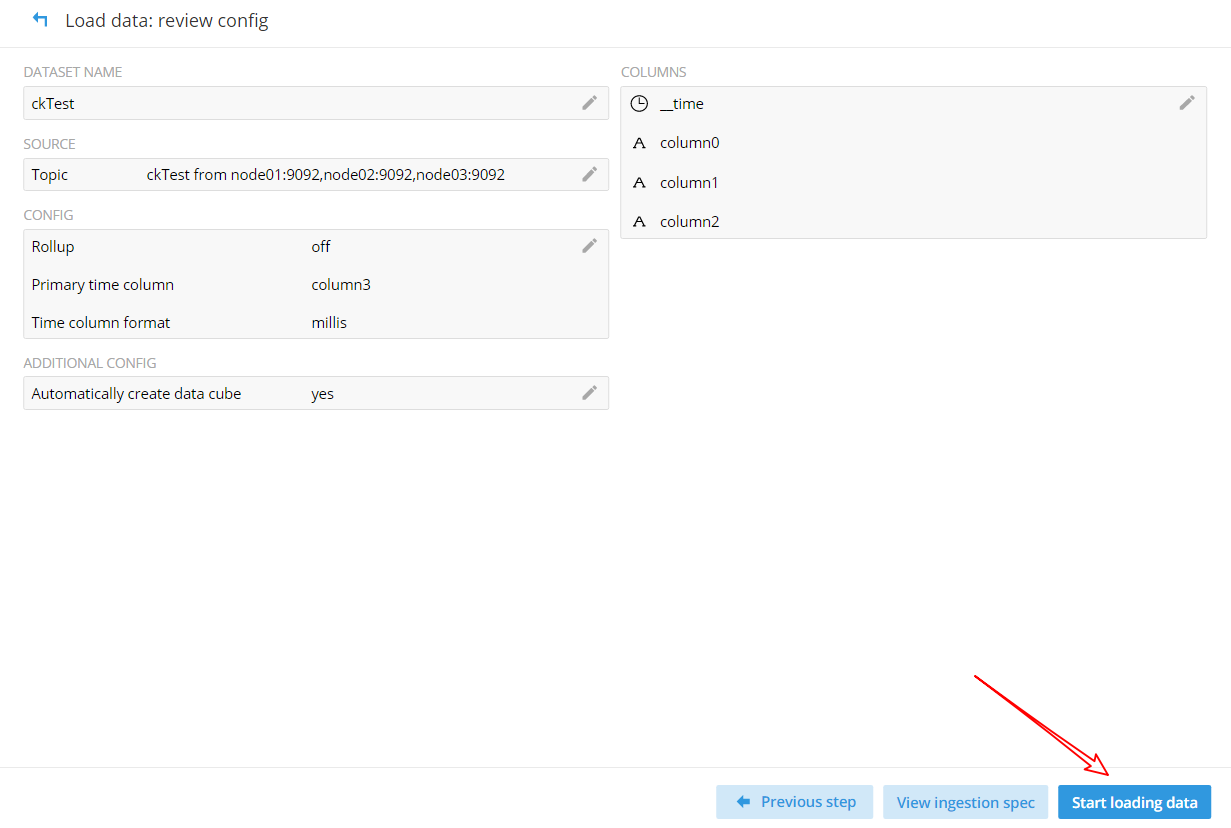
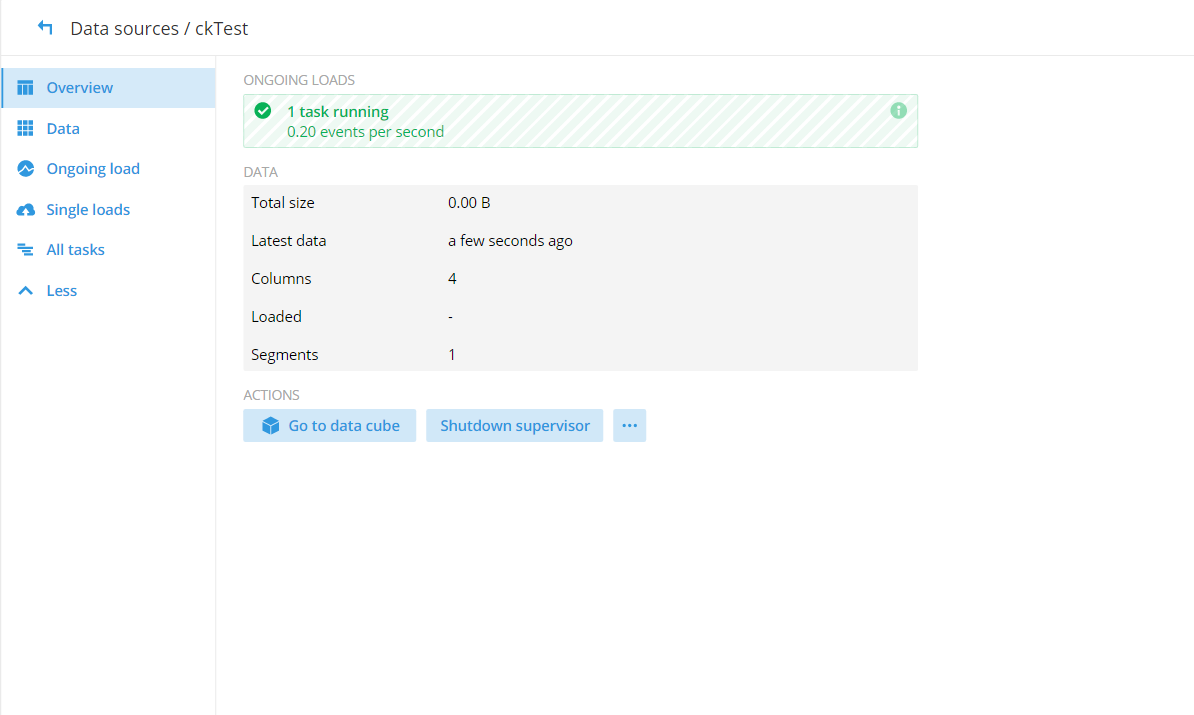
(9)連接 Kafka 的 topics_start,剛開始會顯示 Connecting,加載完成之后便會顯示如下圖所示:
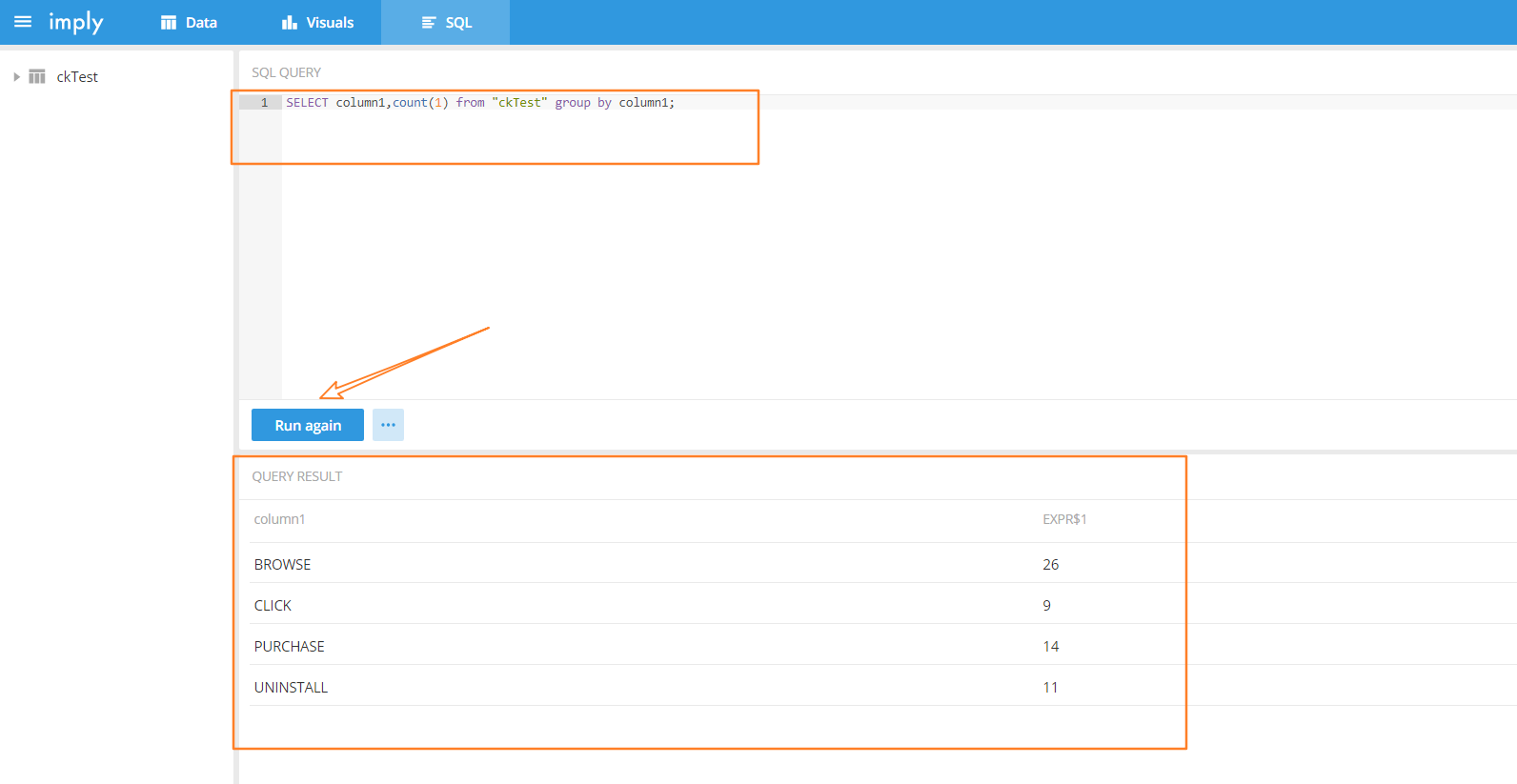
(10)選擇 SQL
因為 topic 為ckTest里存盤的都是用戶行為資料,這里我寫了一個 SQL 獲取每種渠道所對應的資料量,如下所示:
巨人的肩膀
1、hhttps://druid.apache.org/ Druid 官網
2、https://www.jianshu.com/p/6f822e0f538c《Druid基本概念及架構介紹》
3、https://zhuanlan.zhihu.com/p/82038648《Apache Druid 簡介》
4、https://blog.csdn.net/weixin_40735752/article/details/88218571《Druid.IO簡介系列之二:Druid系統架構》
小結
本期文章為大家介紹了 Druid 的簡介,特點,使用場景,架構與資料結構,并用一個簡單的 demo 為大家演示了 Druid 的具體使用,當然關于 Druid 值得探索的內容還有很多,限于文章篇幅不作過多介紹,希望大家能看完之后養成一種“自我驅動型學習”的能力,這才是最重要的!有疑問也歡迎找我探討 ~ 你知道的越多,你不知道的也越多 ~ 我是 夢想家,我們下一期見!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/273689.html
標籤:其他