Hadoop集群環境搭建
1環境需求
本文是用過Vmware搭建的三臺linux虛擬機,
Vmware安裝包自取
Mac:鏈接:https://pan.baidu.com/s/1unYcc_hc9SA5O5-QvZFe-A 密碼:h20j
Windows:鏈接:https://pan.baidu.com/s/1Z5y1DsnT-CmWcGHADd6WwQ 密碼:5v0w
2.hadoop集群搭建
2.1linux環境配置(需要三臺linux虛擬機都執行)
2.1.1 關閉防火墻 (本地環境訪問更加方便,不必頻繁的開通網路策略)
#關閉防火墻
systemctl stop firewalld
#開機禁止啟動
systemctl disable firewalld
2.1.2關閉setlinux
sudo vim /etc/sysconfig/selinux
#添加一行這個配置即可
SELINUX=disabled
2.2.3 更改主機名并做IP映射
vi /etc/hostname
# 安裝自己的想法分別添加配置
node01.xx.com
node02.xx.com
node03.xx.com
添加主機名ip映射
vi /etc/hosts
ip1 node01.xx.com node01
ip2 node02.xx.com node02
ip3 node03.xx.com node03
2.2.4 同步時鐘(通過網路進行時鐘同步)
#1.安裝 ntpdate
yum -y install ntpdate
#2.設定阿里云服務器
ntpdate ntp4.aliyun.com
#3.設定定時任務
crontab -e
*/1 * * * * /usr/sbin/ntpdate ntp4.aliyun.com;
2.2.5添加hadoop用戶(賦予sudo權限,以后的大資料相關的安裝使用的都是這個用戶)
#添加用戶
useradd hadoop
#設定密碼 根據提示 輸入密碼即可
passwd hadoop
#添加權限
visudo
#增加如下配置
hadoop ALL=(ALL) ALL
2.2.6 對hadoop定義統一目錄(更加規范)
mkdir -p /xx/soft # 軟體壓縮包存放目錄
mkdir -p /xx/install # 軟體解壓后存放目錄
chown -R hadoop:hadoop /xx # 將檔案夾權限更改為hadoop用戶
#創建完haddoop用戶后記住,以后的操作都使用hadoop用戶即可
#切換hadoop用戶
su hadoop
2.2.7 設定三臺linux服務器免密碼登錄
未來的場景中,三臺linux服務器之間要經過各種互動,如果相互訪問需要密碼,會存在很多麻煩,
以下的操作都是hadoop用戶
#1.三臺機器都聲稱 公鑰和私鑰
ssh-keygen -t rsa
#2.三臺機器執行命令拷貝公鑰到node01服務器
ssh-copy-id node01
#3.降node01的公鑰copy到其他服務器上
#注意.ssh是隱藏檔案 $PWD 是當前檔案目錄,意味copy到其他服務器上的相同目錄下
cd /home/hadoop/.ssh/
scp authorized_keys node02:$PWD
scp authorized_keys node03:$PWD
#4.驗證(看是否還需要密碼,不需要即配置成功)
ssh node02
ssh node03
#5.重啟服務器
sudo shutdown -r now
sudo reboot -h now
3.1 jdk安裝與配置
1.上傳本地包到三臺liunx虛擬機的安裝目錄
#分別上傳安裝包
scp -r /path/jdk1.8.0_141 hadoop@localhost:/xx/soft
#安裝
tar -xzvf jdk-8u141-linux-x64.tar.gz -C /zy/install/
#配置環境
sudo vim /ect/profile
#2.添加環境變數
export JAVA_HOME=/zy/install/jdk1.8.0_141
export PATH=$PATH:$JAVA_HOME/bin
#3.加載配置
source /etc/profile
準備好后建議打個快照,方便后邊環境搭建失敗后恢復,不至于從頭返工
4…hadoop集群搭建
4.1.規劃
如果openssl為fasle,那么所有機器在線安裝openssl即可,執行以下命令,虛擬機聯網之后就可以在線進行安裝了
sudo yum -y install openssl-devel
4.3.修改配置( 組態檔均在/xx/install/hadoop-3.1.4/etc/hadoop/目錄下)
注意以下的配置都是在node01節點操作 切記
4.3.1修改hadoop-env.sh
vim hadoop-env.sh
#添加jdk配置
export JAVA_HOME=/zy/install/jdk1.8.0_141
4.3.2 修改core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<!-- 注意配置到自己的目錄上,不要配置錯誤 -->
<value>/xx/install/hadoop-3.1.4/hadoopDatas/tempDatas</value>
</property>
<!-- 緩沖區大小,實際作業中根據服務器性能動態調整;默認值4096 -->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!-- 開啟hdfs的垃圾桶機制,洗掉掉的資料可以從垃圾桶中回收,單位分鐘;默認值0 -->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
</configuration>
4.3.3 修改hdfs-site.xml
<configuration>
<!-- NameNode存盤元資料資訊的路徑,實際作業中,一般先確定磁盤的掛載目錄,然后多個目錄用,進行分割 -->
<!-- 集群動態上下線
<property>
<name>dfs.hosts</name>
<value>/xx/install/hadoop-3.1.4/etc/hadoop/accept_host</value>
</property>
<property>
<name>dfs.hosts.exclude</name>
<value>/xx/install/hadoop-3.1.4/etc/hadoop/deny_host</value>
</property>
-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node01:9868</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>node01:9870</value>
</property>
<!-- namenode保存fsimage的路徑 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///xx/install/hadoop-3.1.4/hadoopDatas/namenodeDatas</value>
</property>
<!-- 定義dataNode資料存盤的節點位置,實際作業中,一般先確定磁盤的掛載目錄,然后多個目錄用,進行分割 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///xx/install/hadoop-3.1.4/hadoopDatas/datanodeDatas</value>
</property>
<!-- namenode保存editslog的目錄 -->
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///xx/install/hadoop-3.1.4/hadoopDatas/dfs/nn/edits</value>
</property>
<!-- secondarynamenode保存待合并的fsimage -->
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///xx/install/hadoop-3.1.4/hadoopDatas/dfs/snn/name</value>
</property>
<!-- secondarynamenode保存待合并的editslog -->
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:///xx/install/hadoop-3.1.4/hadoopDatas/dfs/nn/snn/edits</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
</configuration>
4.3.4 修改mapred-site.xml
configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node01:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
4.3.5 修改yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 如果vmem、pmem資源不夠,會報錯,此處將資源監察置為false -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
4.3.6修改workers檔案
vim workers
# 替換為如下
node01
node02
node03
4.4 創建檔案存放目錄(都是剛剛修改的組態檔中制定的檔案目錄地址)
node01上執行
mkdir -p /xx/install/hadoop-3.1.4/hadoopDatas/tempDatas
mkdir -p /xx/install/hadoop-3.1.4/hadoopDatas/namenodeDatas
mkdir -p /xx/install/hadoop-3.1.4/hadoopDatas/datanodeDatas
mkdir -p /xx/install/hadoop-3.1.4/hadoopDatas/dfs/nn/edits
mkdir -p /xx/install/hadoop-3.1.4/hadoopDatas/dfs/snn/name
mkdir -p /xx/install/hadoop-3.1.4/hadoopDatas/dfs/nn/snn/edits
4.5 分發安裝包
scp -r hadoop-3.1.4/ node02:$PWD
scp -r hadoop-3.1.4/ node03:$PWD
4.6 hadoop環境變數配置
#三臺機器都要進行配置hadoop的環境變數
vim /etc/profile
#添加如下配置,生效即可
export HADOOP_HOME=/xx/install/hadoop-3.1.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
#驗證
hadoop
4.7 格式化集群
- 要啟動 Hadoop 集群,需要啟動 HDFS 和 YARN 兩個集群,
- 注意:首次啟動HDFS時,必須對其進行格式化操作,本質上是一些清理和準備作業,因為此時的 HDFS 在物理上還是不存在的,格式化操作只有在首次啟動的時候需要,以后再也不需要了
- node01執行一遍即可
#兩個命令都可以
hdfs namenode -format
hadoop namenode –format
出現標注所示,即為成功,
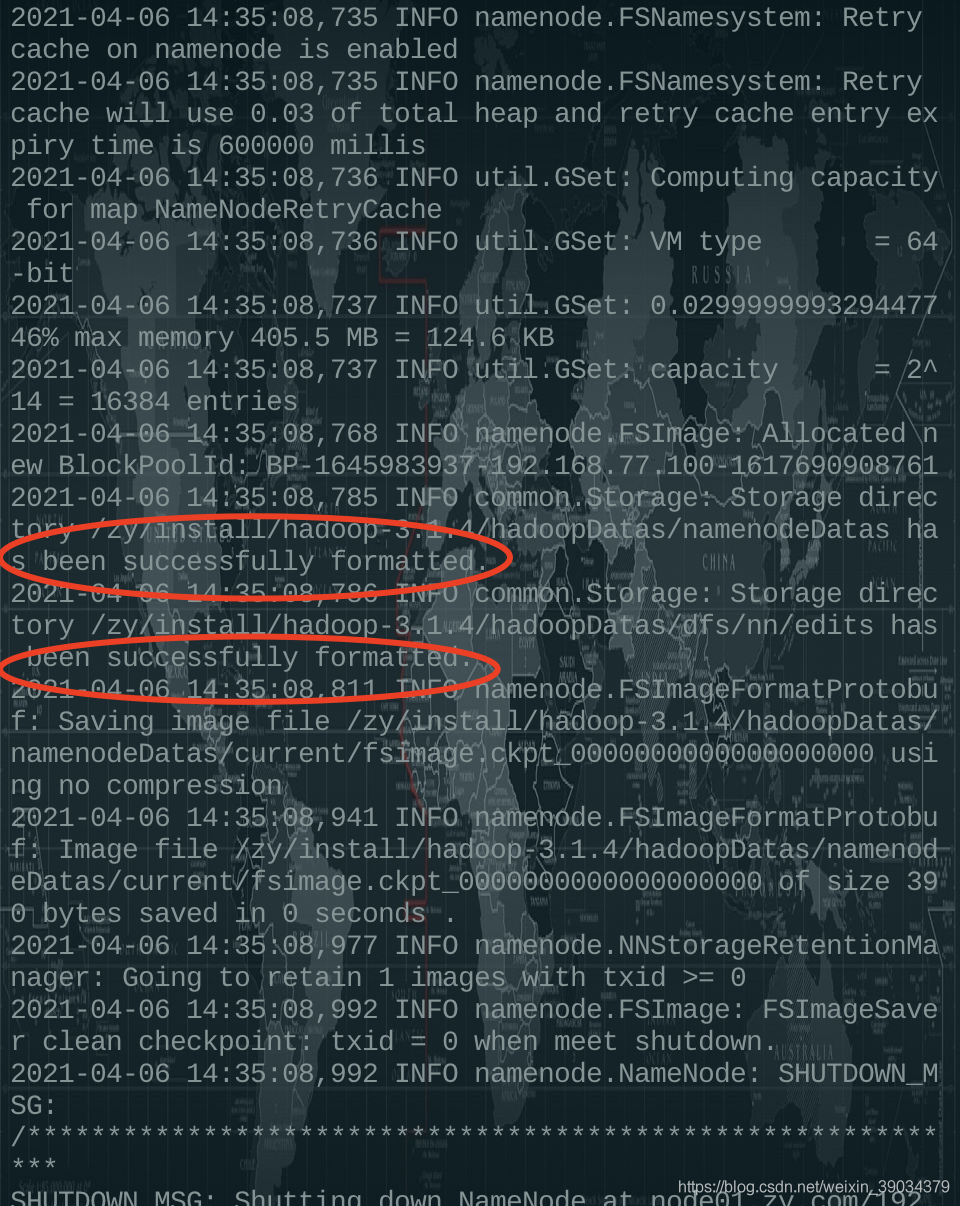
4.8啟動集群
4.8.1 原生 腳本啟動
- 如果配置了 etc/hadoop/workers 和 ssh 免密登錄(上邊步驟均有配置),則可以使用程式腳本啟動所有Hadoop 兩個集群的相關行程,在主節點所設定的機器上執行,
start
start-dfs.sh
start-yarn.sh
mapred --daemon start historyserver
stop
stop-dfs.sh
stop-yarn.sh
mapred --daemon stop historyserver
4.8.2 單個行程逐個啟動
# 根據集群職責的劃分分別在不同的機器上啟動對應的行程即可
hdfs --daemon start namenode
hdfs --daemon start secondarynamenode
hdfs --daemon start datanode
yarn --daemon start resourcemanager
yarn --daemon start nodemanager
4.8.3撰寫一鍵啟動腳本
cd /home/hadoop/bin/
vim hadoop.sh
#!/bin/bash
case $1 in
"start" ){
source /etc/profile;
/kkb/install/hadoop-3.1.4/sbin/start-dfs.sh
/kkb/install/hadoop-3.1.4/sbin/start-yarn.sh
#/kkb/install/hadoop-3.1.4/sbin/mr-jobhistory-daemon.sh start historyserver
/kkb/install/hadoop-3.1.4/bin/mapred --daemon start historyserver
};;
"stop"){
/kkb/install/hadoop-3.1.4/sbin/stop-dfs.sh
/kkb/install/hadoop-3.1.4/sbin/stop-yarn.sh
#/kkb/install/hadoop-3.1.4/sbin/mr-jobhistory-daemon.sh stop historyserver
/kkb/install/hadoop-3.1.4/bin/mapred --daemon stop historyserver
};;
esac
修改腳本權限
chmod 777 hadoop.sh
#START
./hadoop.sh start
#STOP
./hadoop.sh stop
4.9 驗證集群
1.訪問ui界面
###### 1. 訪問web ui界面
- hdfs集群訪問地址
http://ip:9870/
- yarn集群訪問地址
http://ip:8088
- jobhistory訪問地址:
http://ip19888
2.查看行程
- jps
- 自己撰寫腳本
vim xcall
#!/bin/bash
params=$@
for (( i=1 ; i <= 3 ; i = $i + 1 )) ; do
echo ============= node0$i $params =============
ssh node0$i "source /etc/profile;$params"
done
授權
chmod 777 /home/hadoop/bin/xcall
# 執行
xcall jps
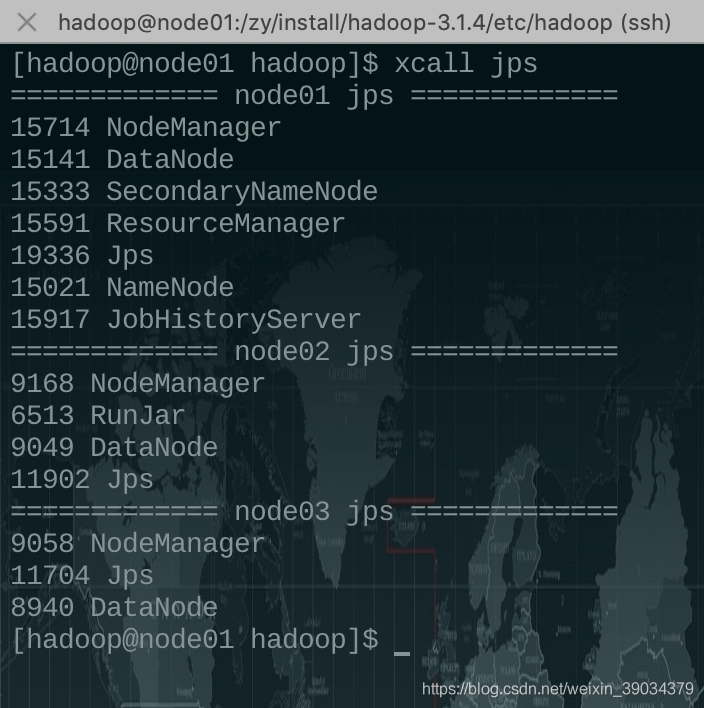
4.8.4 運行mapreduce任務
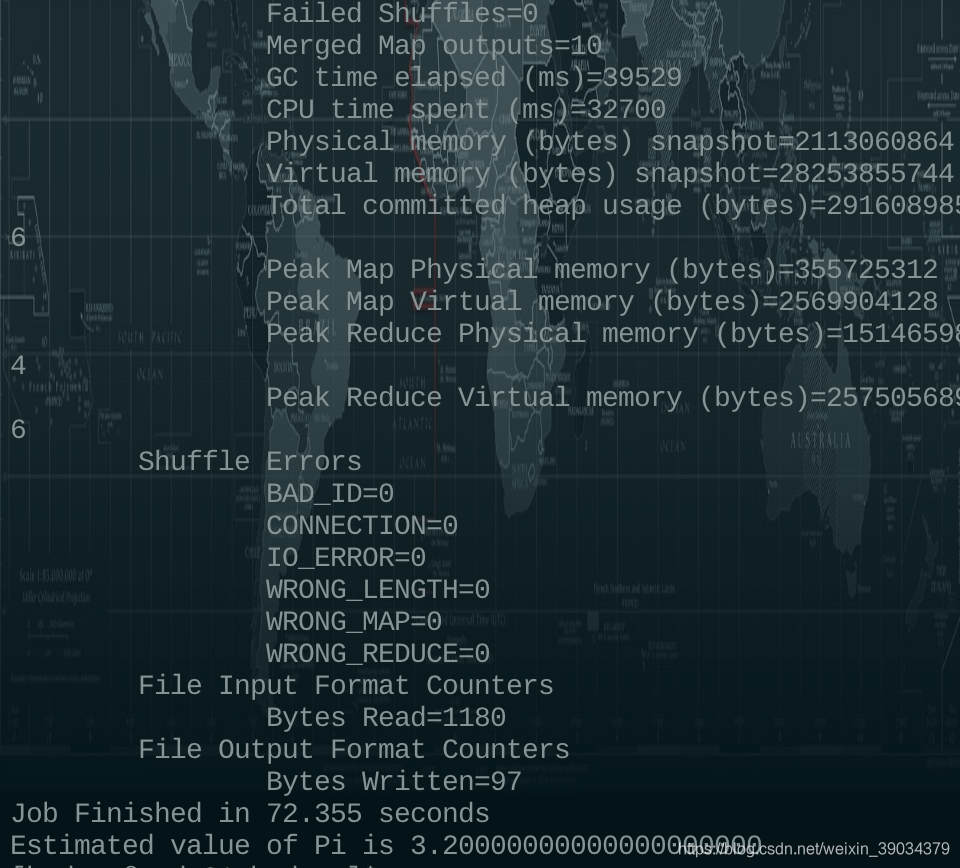
hadoop jar /zy/install/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar pi 5 5
提醒:如果要關閉電腦時,清一定要按照以下順序操作,否則集群可能會出問題
- 關閉hadoop集群
- 關閉虛擬機
- 關閉電腦
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/274177.html
標籤:其他
上一篇:五十六、HBase的優化