1 簡介
RocketMQ是一款分布式、佇列模型的訊息中間件,由阿里巴巴自主研發的一款適用于高并發、高可靠性、海量資料場景的訊息中間件,早期開源2.x版本名為Metaq,迭代3.x版本,更名為RocketMQ,16年開始貢獻到Apache,
經過1年多的范訓,最終成為Apache頂級的開源專案,更新非常頻繁,社區活躍度也非常高;目前4.8.0-release版本,RocketMQ參考借鑒了優秀的開源訊息中間件Apache - Kafka,其訊息的路由集群劃分都借鑒了Kafka優秀的設計思路,并結合自身的 “雙十一” 場景進行了合理的擴展和API豐富,
附上官網地址: http://rocketmq.apache.org/
2 特點
2.1 核心特點
- 支持集群模型、負載均衡、水平擴展能力
- 億級別的訊息堆積能力
- 采用零拷貝的原理、順序寫盤、隨機讀(索引檔案)
- 豐富的API使用
- 代碼優秀,底層通信框架采用Netty NIO框架
- NameServer 代替 Zookeeper
- 強調集群無單點,可擴展,任意一點高可用,水平可擴展
- 訊息失敗重試機制、訊息可查詢
- 開源社區活躍度、是否足夠成熟(經過雙十一考驗)
2.2 專業術語
- Producer:訊息生產者,負責產生訊息,一般由業務系統負責產生訊息,
- Consumer:訊息消費者,負責消費訊息,一般是后臺系統負責異步消費,
- Push Consumer:Consumer的一種,需要向Consumer物件注冊監聽,
- Pull Consumer:Consumer的一種,需要主動請求Broker拉取訊息,
- Producer Group:生產者集合,一般用于發送一類訊息,
- Consumer Group:消費者集合,一般用于接受一類訊息進行消費,
- Broker : MQ訊息服務(中轉角色,用于訊息存盤與生產消費轉發),
3 核心原理
3.1 三種模型
3.1.1 佇列模型
就像我們理解佇列一樣,訊息中間件的佇列模型就真的只是一個佇列,

如果使用 廣播模式 的話,我們需要將一個訊息發送給多個消費者(比如此時我需要將資訊發送給短信系統和郵件系統),這個時候單個佇列即不能滿足需求了,
當然你可以讓 Producer 生產訊息放入多個佇列中,然后每個佇列去對應每一個消費者,問題是可以解決,創建多個佇列并且復制多份訊息是會很影響資源和性能的,而且,這樣子就會導致生產者需要知道具體消費者個數然后去復制對應數量的訊息佇列,這就違背我們訊息中間件的解耦這一原則,
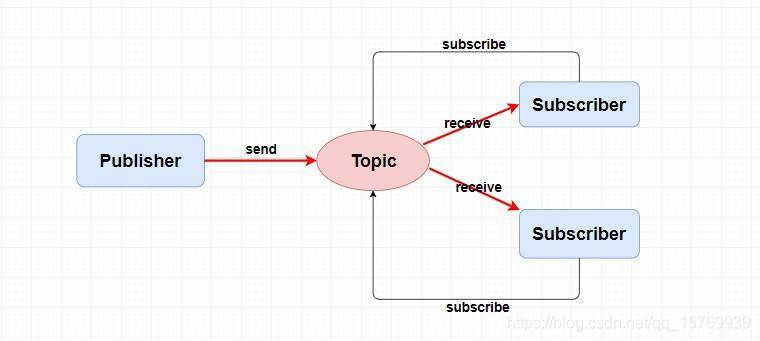
3.1.2 主題模型
也可以稱為發布訂閱模型,
在主題模型中,訊息的生產者稱為發布者(Publisher),訊息的消費者稱為訂閱者(Subscriber),存放訊息的容器稱為主題(Topic),
其中,發布者將訊息發送到指定主題中,訂閱者需要提前訂閱主題才能接受特定主題的訊息,
3.1.3 訊息模型
RockerMQ 中的訊息模型就是按照主題模型所實作的,
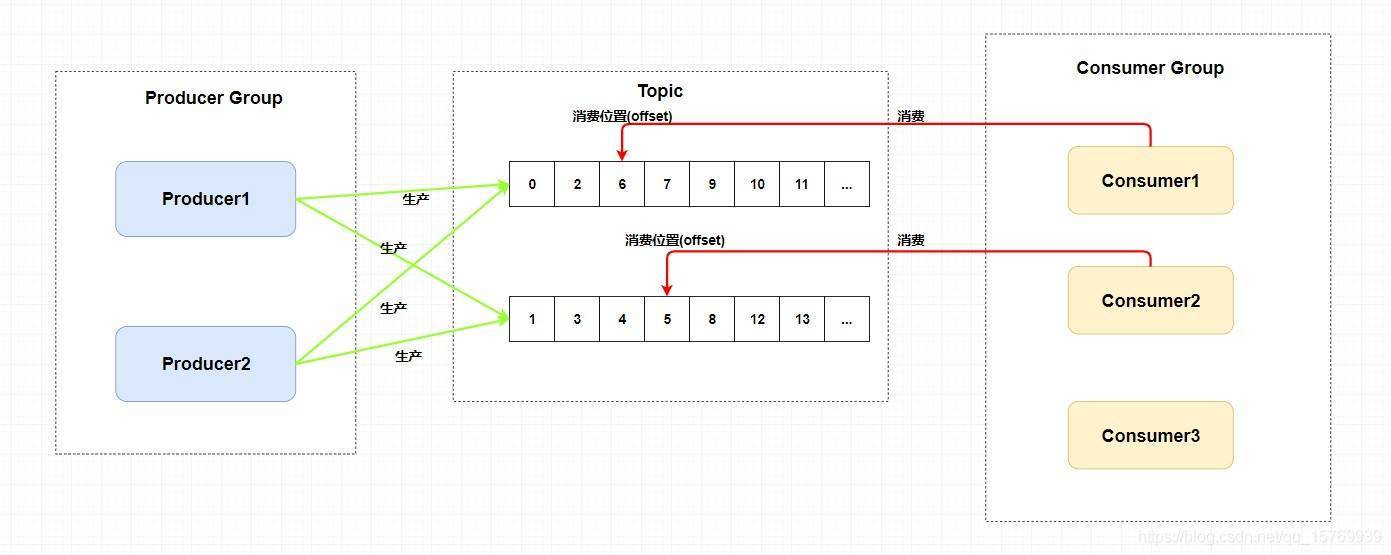
我們可以看到在整個圖中有 Producer Group、Topic、Consumer Group 三個角色,我來分別介紹一下他們,
- Producer Group 生產者組:代表某一類的生產者,比如我們有多個秒殺系統作為生產者,這多個合在一起就是一個 Producer Group 生產者組,它們一般生產相同的訊息,
- Consumer Group 消費者組:代表某一類的消費者,比如我們有多個短信系統作為消費者,這多個合在一起就是一個 Consumer Group 消費者組,它們一般消費相同的訊息,
- Topic 主題:代表一類訊息,比如訂單訊息,物流訊息等等,
你可以看到圖中生產者組中的生產者會向主題發送訊息,而主題中存在多個佇列,生產者每次生產訊息之后是指定主題中的某個佇列發送訊息的,
每個主題中都有多個佇列(這里還不涉及到 Broker),集群消費模式下,一個消費者集群多臺機器共同消費一個 topic 的多個佇列,一個佇列只會被一個消費者消費,如果某個消費者掛掉,分組內其它消費者會接替掛掉的消費者繼續消費,就像上圖中 Consumer1 和 Consumer2 分別對應著兩個佇列,而 Consuer3 是沒有佇列對應的,所以一般來講要控制消費者組中的消費者個數和主題中佇列個數相同,
所以總結來說,RocketMQ 通過使用在一個 Topic 中配置多個佇列并且每個佇列維護每個消費者組的消費位置實作了主題模式/發布訂閱模式,
3.2 架構
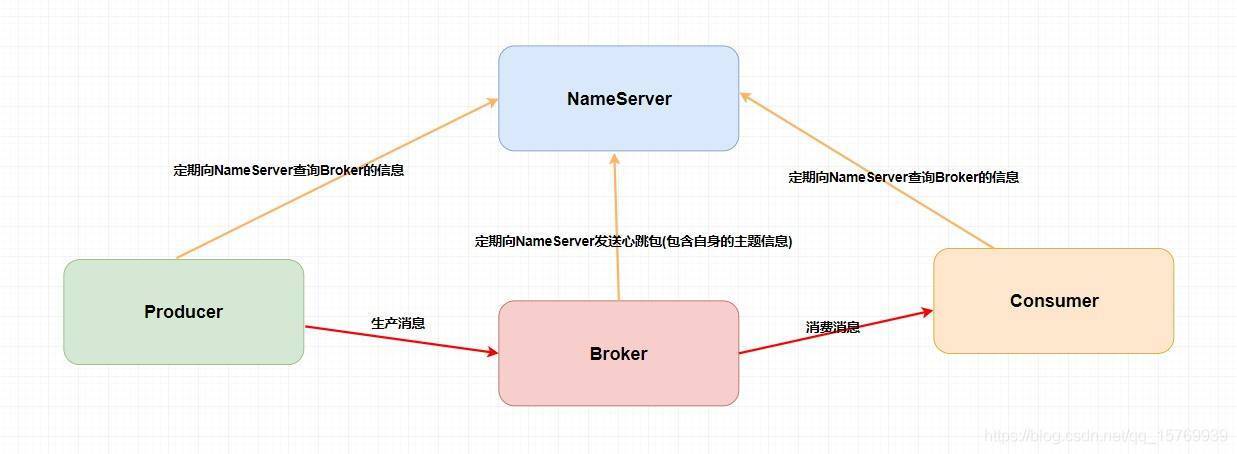
RocketMQ 技術架構中有四大角色 NameServer、Broker、Producer、Consumer,我來向大家分別解釋一下這四個角色是干啥的,
-
Broker:主要負責訊息的存盤、投遞和查詢以及服務高可用保證,說白了就是訊息佇列服務器嘛,生產者生產訊息到 Broker,消費者從 Broker 拉取訊息并消費,
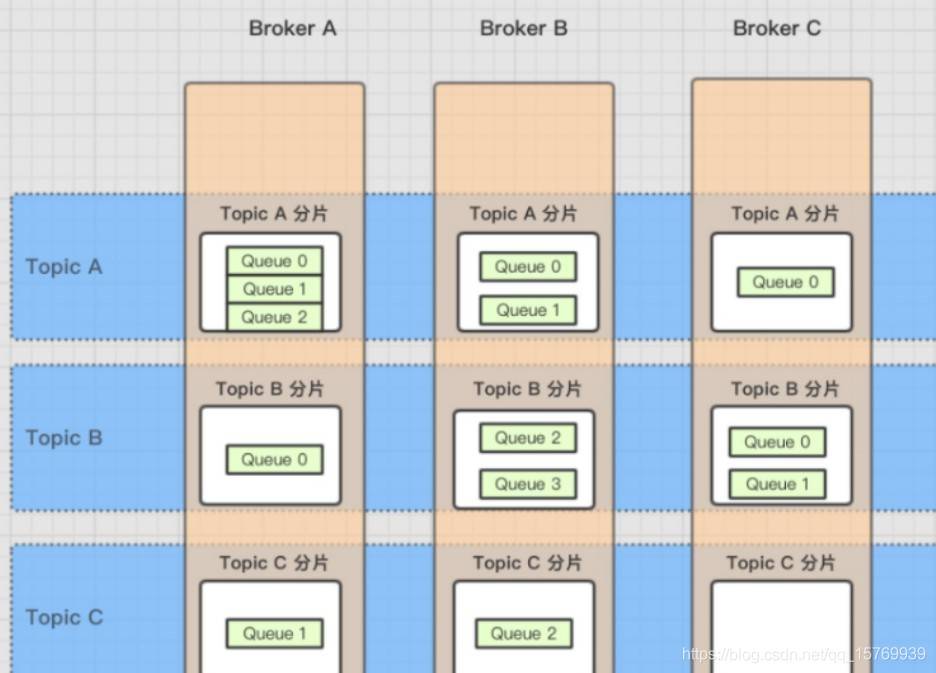
這里,我還得普及一下關于 Broker、Topic 和佇列的關系,上面我講解了 Topic 和佇列的關系——一個 Topic 中存在多個佇列,那么這個 Topic 和佇列存放在哪呢?
一個 Topic 分布在多個 Broker 上,一個 Broker 可以配置多個 Topic,它們是多對多的關系,
如果某個 Topic 訊息量很大,應該給它多配置幾個佇列(上文中提到了提高并發能力),并且盡量多分布在不同 Broker 上,以減輕某個 Broker 的壓力,
Topic 訊息量都比較均勻的情況下,如果某個 broker 上的佇列越多,則該 broker 壓力越大,
所以說我們需要配置多個 Broker,
-
NameServer:不知道你們有沒有接觸過 ZooKeeper 和 Spring Cloud 中的 Eureka,它其實也是一個注冊中心,主要提供兩個功能:Broker 管理和路由資訊管理,說白了就是 Broker 會將自己的資訊注冊到 NameServer 中,此時 NameServer 就存放了很多 Broker 的資訊(Broker的路由表),消費者和生產者就從 NameServer 中獲取路由表然后照著路由表的資訊和對應的 Broker 進行通信(生產者和消費者定期會向 NameServer 去查詢相關的 Broker 的資訊),
-
Producer:訊息發布的角色,支持分布式集群方式部署,說白了就是生產者,
-
Consumer:訊息消費的角色,支持分布式集群方式部署,支持以 push 推,pull 拉兩種模式對訊息進行消費,同時也支持集群方式和廣播方式的消費,它提供實時訊息訂閱機制,說白了就是消費者,
簡單化的架構圖:
官網的架構圖:
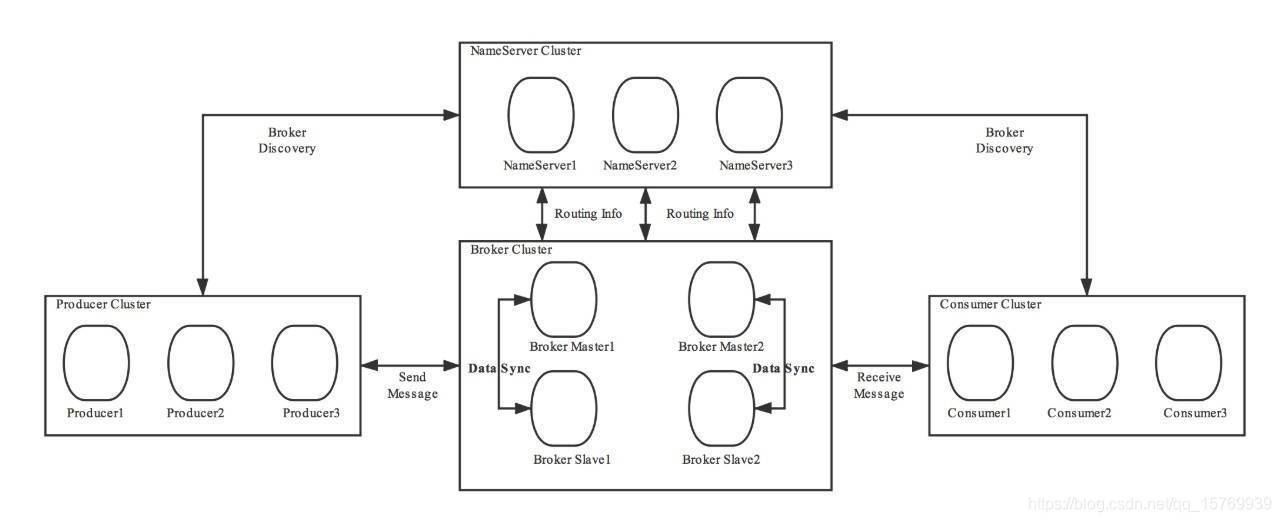
第一、我們的 Broker 做了集群并且還進行了主從部署,由于訊息分布在各個 Broker 上,一旦某個 Broker 宕機,則該 Broker 上的訊息讀寫都會受到影響,所以 RocketMQ 提供了 master/slave 的結構,salve 定時從 master 同步資料(同步刷盤或者異步刷盤),如果 master 宕機,則 slave 提供消費服務,但是不能寫入訊息(后面我還會提到),
第二、為了保證 HA,我們的 NameServer 也做了集群部署,但是請注意它是去中心化的,也就意味著它沒有主節點,你可以很明顯地看出 NameServer 的所有節點是沒有進行 Info Replicate 的,在 RocketMQ 中是通過單個 Broker 和所有 NameServer 保持長連接,并且在每隔 30 秒 Broker 會向所有 Nameserver 發送心跳,心跳包含了自身的 Topic 配置資訊,這個步驟就對應這上面的 Routing Info,
第三、在生產者需要向 Broker 發送訊息的時候,需要先從 NameServer 獲取關于 Broker 的路由資訊,然后通過輪詢的方法去向每個佇列中生產資料以達到負載均衡的效果,
第四、消費者通過 NameServer 獲取所有 Broker 的路由資訊后,向 Broker 發送 Pull 請求來獲取訊息資料,Consumer 可以以兩種模式啟動—— 廣播(Broadcast)和集群(Cluster),廣播模式下,一條訊息會發送給同一個消費組中的所有消費者,集群模式下訊息只會發送給一個消費者,
3.3 存盤機制
- CommitLog:訊息主體以及元資料的存盤主體,存盤 Producer 端寫入的訊息主體內容,訊息內容不是定長的,單個檔案大小默認 1G ,檔案名長度為 20 位,左邊補零,剩余為起始偏移量,比如 00000000000000000000 代表了第一個檔案,起始偏移量為 0,檔案大小為 1G = 1073741824;當第一個檔案寫滿了,第二個檔案為 00000000001073741824,起始偏移量為 1073741824,以此類推,訊息主要是順序寫入日志檔案,當檔案滿了,寫入下一個檔案,
- ConsumeQueue:訊息消費佇列,引入的目的主要是提高訊息消費的性能(我們再前面也講了),由于 RocketMQ 是基于主題 Topic 的訂閱模式,訊息消費是針對主題進行的,如果要遍歷 commitlog 檔案中根據 Topic 檢索訊息是非常低效的,Consumer 即可根據 ConsumeQueue 來查找待消費的訊息,其中,ConsumeQueue(邏輯消費佇列)作為消費訊息的索引,保存了指定 Topic 下的佇列訊息在 CommitLog 中的起始物理偏移量 offset,訊息大小 size 和訊息 Tag 的 HashCode 值,consumequeue 檔案可以看成是基于 topic 的 commitlog 索引檔案,故 consumequeue 檔案夾的組織方式如下:topic/queue/file 三層組織結構,具體存盤路徑為:$HOME/store/consumequeue/{topic}/{queueId}/{fileName},同樣 consumequeue 檔案采取定長設計,每一個條目共 20 個位元組,分別為 8 位元組的 commitlog 物理偏移量、4 位元組的訊息長度、8 位元組 tag hashcode,單個檔案由 30W 個條目組成,可以像陣列一樣隨機訪問每一個條目,每個 ConsumeQueue 檔案大小約 5.72M;
- IndexFile:IndexFile(索引檔案)提供了一種可以通過 key 或時間區間來查詢訊息的方法,這里只做科普不做詳細介紹,
總結來說,整個訊息存盤的結構,最主要的就是 CommitLoq 和 ConsumeQueue,而 ConsumeQueue 你可以大概理解為 Topic 中的佇列,
RocketMQ 采用的是混合型的存盤結構,即為 Broker 單個實體下所有的佇列共用一個日志資料檔案來存盤訊息,有意思的是在同樣高并發的 Kafka 中會為每個 Topic 分配一個存盤檔案,這就有點類似于我們有一大堆書需要裝上書架,RockeMQ 是不分書的種類直接成批的塞上去的,而 Kafka 是將書本放入指定的分類區域的,
而 RocketMQ 為什么要這么做呢?原因是提高資料的寫入效率,不分 Topic 意味著我們有更大的幾率獲取成批的訊息進行資料寫入,但也會帶來一個麻煩就是讀取訊息的時候需要遍歷整個大檔案,這是非常耗時的,
所以,在 RocketMQ 中又使用了 ConsumeQueue 作為每個佇列的索引檔案來提升讀取訊息的效率,我們可以直接根據佇列的訊息序號,計算出索引的全域位置(索引序號*索引固定?度20),然后直接讀取這條索引,再根據索引中記錄的訊息的全域位置,找到訊息,
4 相關資訊
- 博文不易,辛苦各位猿友點個關注和贊,感謝
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/274180.html
標籤:其他