文章目錄
- 一、學前必備知識
- 二、使用 Centos7 進行 Hadoop 集群的搭建與配置
- 1、Hadoop 集群詳解
- 2、搭建集群前的準備作業
- 3、配置 Hadoop 集群
- 4、啟動并關閉 Hadoop 集群
- 5、查看 Hadoop 集群的基本資訊
- 6、在 Hadoop 集群中運行程式
一、學前必備知識
- 2021年 全網最細大資料學習筆記(一):初識 Hadoop
- 2021年 全網最細大資料學習筆記(二):Hadoop 偽分布式安裝
二、使用 Centos7 進行 Hadoop 集群的搭建與配置
1、Hadoop 集群詳解
Hadoop 集群中可以有成百上千個節點,但各個節點的角色,也就是說各節點的分工是怎樣的呢?可以從三個角度對 Hadoop 集群節點進行分類,分別為:
- 基本角色劃分:Hadoop 集群,可以分為兩大類角色:Master 和 slave,即主人和奴隸,
- 從 HDFS 的角度劃分:將節點劃分為一個 NameNode 和若干個 DataNode,其中 NameNode 作為主服務器,管理檔案系統的命名空間和客戶端對檔案系統的訪問操作;DataNode 管理存盤的資料,
- 從YARN (MapReduce2) 的角度劃分:將節點劃分為一個 Resource Manager 和若干個 Node Manager,Resource Manager 負責所有資源的監控、分配和管理,Node Manager 負責每一個節點的維護,
注意:如果從 MapReduce 角度劃分的話,可以將節點分為一個 JobTracker 和若干個 TaskTracker,主節點上的 JobTracker 負責調度構成一個作業的所有任務,這些任務分布在不同的從節點上,主節點監控它們的執行情況,并且重新執行之前的失敗任務;從節點上的 TaskTracker 僅負責由主節點指派的任務,當一個 Job 被提交時,JobTracker 接收到提交作業和配置資訊之后,就會將配置資訊等分發給從節點,同時調度任務并監控 TaskTracker 的執行,
Hadoop 集群示意圖如下圖所示:
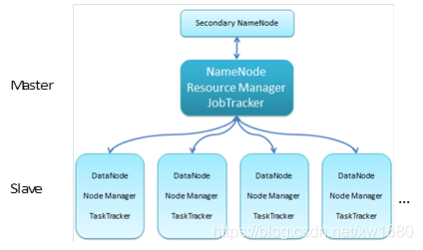
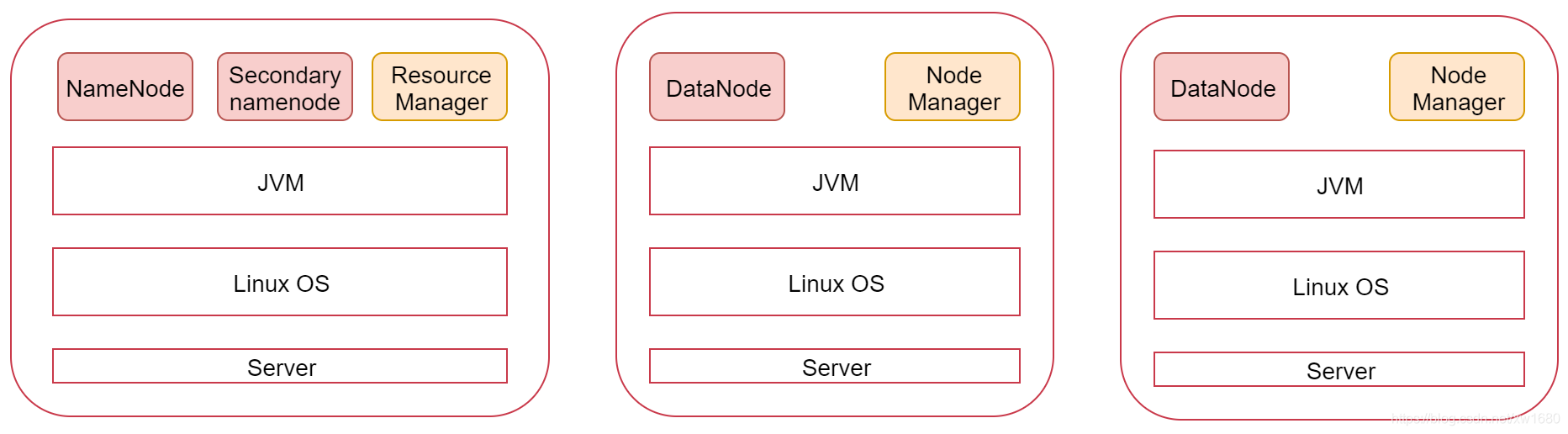
我們也可以看一下下面這張圖,圖里面表示是三個節點,左邊這一個是主節點,右邊的兩個是從節點,Hadoop 集群是支持主從架構的,不同節點上面啟動的行程默認是不一樣的,
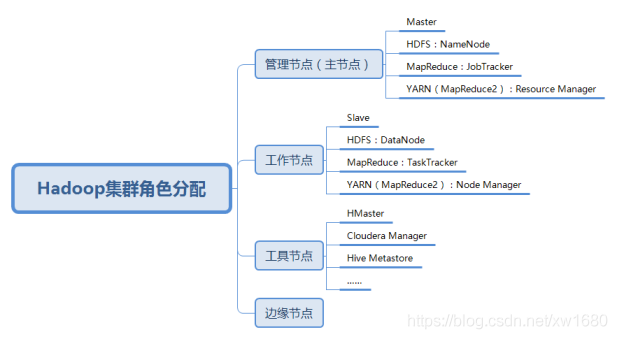
除了上面介紹的主節點(也稱為管理節點) NameNode,和作業節點 DataNode 以外,Hadoop 集群中還有工具節點和邊緣節點,其中,工具節點主要用于運行非管理行程的其他行程,例如 HMaster、Cloudera Manager、Hive Metastore 等,邊緣節點用于集群中啟動作業的客戶端集群,邊緣節點的數量取決于作業負載的型別和數量,綜上所述,Hadoop 集群的角色種類如下圖所示:
2、搭建集群前的準備作業
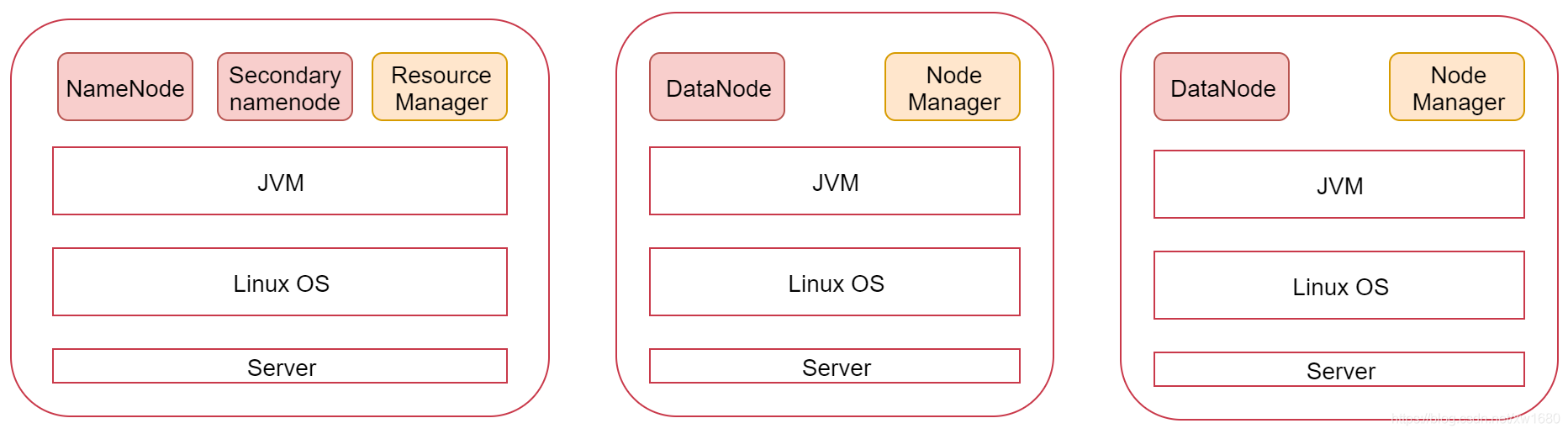
本小節根據圖中的規劃實作一個一主兩從的 Hadoop 集群,環境準備:三個節點 bigdata01 192.168.61.100、bigdata02 192.168.61.101、bigdata03 192.168.61.102,這里的話筆者是在原有 bigdata01 的基礎上克隆(通過克隆的方式創建多個節點,具體克隆的步驟在這就不再贅述了)了兩臺機器,分別命名為 bigdata02 和 bigdata03,接下來就要對這兩臺新的機器進行基礎環境的配置,如:ip、hostname、firewalld、ssh 免密碼登錄、JDK,說明:由于筆者在 2021年 全網最細大資料學習筆記(二):Hadoop 偽分布式安裝 一文中已經詳細介紹了這些基礎環境的配置,這里也不再贅述,
筆者現在已經具備三臺 linux 機器了,里面都是全新的環境,這三臺機器的 ip、hostname、firewalld、ssh免密碼登錄、JDK 這些基礎環境已經配置 ok,這些基礎環境配置好以后還沒完,還有一些配置需要完善,
-
配置 /etc/hosts,因為需要在主節點遠程連接兩個從節點,所以需要讓主節點能夠識別從節點的主機名,使用主機名遠程訪問,默認情況下只能使用 ip 遠程訪問,想要使用主機名遠程訪問的話需要在節點的 /etc/hosts 檔案中配置對應機器的 ip 和主機名資訊,所以在這里我們就需要在 bigdata01 的 /etc/hosts 檔案中配置下面資訊,最好把當前節點資訊也配置到里面,這樣這個檔案中的內容就通用了,可以直接拷貝到另外兩個從節點,命令:vi /etc/hosts,添加下面的內容:

修改 bigdata02 的 /etc/hosts 檔案:

修改 bigdata03 的 /etc/hosts 檔案:

-
集群節點之間時間同步,集群只要涉及到多個節點的就需要對這些節點做時間同步,如果節點之間時間不同步相差太多,會應該集群的穩定性,甚至導致集群出問題,首先在 bigdata01 節點上操作,yum install -y ntpdate、ntpdate -u ntp.sjtu.edu.cn,把這個同步時間的操作添加到 linux 的 crontab 定時器中,每分鐘執行一次:vi /etc/crontab
* * * * * root /usr/sbin/ntpdate -u ntp.sjtu.edu.cn查看命令的路徑可以使用 which xxxx,如下:

然后在 bigdata02 和 bigdata03 節點上配置時間同步, -
SSH 免密碼登錄完善,注意:針對免密碼登錄,目前只實作了自己免密碼登錄自己,最終需要實作主機點可以免密碼登錄到所有節點,所以還需要完善免密碼登錄操作,首先在 bigdata01 機器上執行下面命令,將公鑰資訊拷貝到兩個從節點:
scp ~/.ssh/authorized_keys bigdata02:~/ scp ~/.ssh/authorized_keys bigdata03:~/然后在 bigdata02 和 bigdata03 上執行
cat ~/authorized_keys >> ~/.ssh/authorized_keys驗證一下效果,在 bigdata01 節點上使用 ssh 遠程連接兩個從節點,如果不需要輸入密碼就表示是成功的,此時主機點可以免密碼登錄到所有節點,
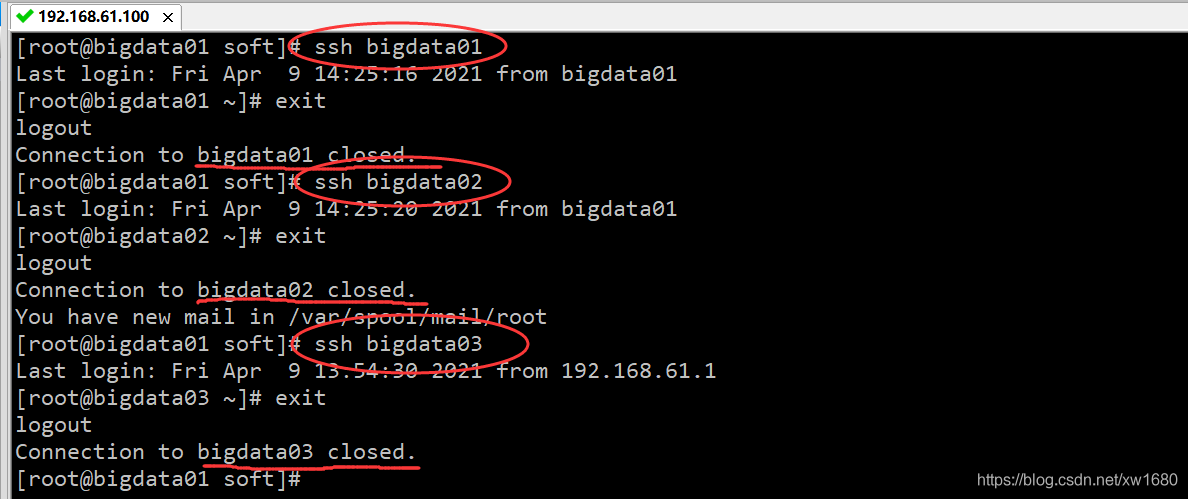
3、配置 Hadoop 集群
OK,那到這為止,集群中三個節點的基礎環境就都配置完畢了,接下來就需要在這三個節點中安裝 Hadoop 了,首先在 bigdata01 節點上安裝,
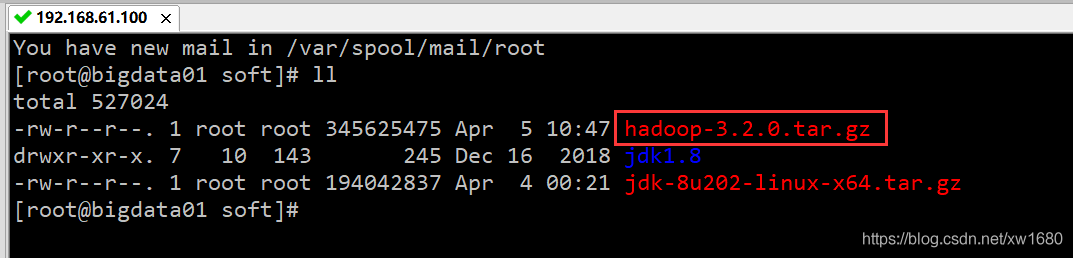
(1) 把 hadoop-3.2.0.tar.gz 安裝包上傳到 linux 機器的 /data/soft 目錄下,命令:
(2) 解壓 hadoop 安裝包,命令:tar -zxvf hadoop-3.2.0.tar.gz,配置一下環境變數 vi /etc/profile,
export JAVA_HOME=/data/soft/jdk1.8
export HADOOP_HOME=/data/soft/hadoop-3.2.0
export PATH=.:$JAVA_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$PATH
設定立即生效:source /etc/profile,
(3) 修改 hadoop 相關組態檔,進入組態檔所在目錄:cd hadoop-3.2.0/etc/hadoop/、修改 hadoop-env.sh 檔案,在檔案末尾增加環境變數資訊,命令:vi hadoop-env.sh,添加內容如下:
export JAVA_HOME=/data/soft/jdk1.8
export HADOOP_LOG_DIR=/data/hadoop_repo/logs/hadoop
修改 core-site.xml 檔案,注意 fs.defaultFS 屬性中的主機名需要和主節點的主機名保持一致:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop_repo</value>
</property>
</configuration>
修改 hdfs-site.xml 檔案,把 hdfs 中檔案副本的數量設定為 2,最多為 2,因為現在集群中有兩個從節點,還有 secondaryNamenode 行程所在的節點資訊:
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata01:50090</value>
</property>
</configuration>
修改 mapred-site.xml,設定 mapreduce 使用的資源調度框架:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改 yarn-site.xml,設定 yarn 上支持運行的服務和環境變數白名單,注意,針對分布式集群在這個組態檔中還需要設定resourcemanager的hostname,否則nodemanager找不到resourcemanager節點,
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata01</value>
</property>
</configuration>
修改 workers檔案,增加所有從節點的主機名,一個一行,vi workers

修改啟動腳本,修改 start-dfs.sh,stop-dfs.sh 這兩個腳本檔案,命令:cd /data/soft/hadoop-3.2.0/sbin,vi start-dfs.sh,vi stop-dfs.sh 在檔案前面增加如下內容:
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
修改 start-yarn.sh,stop-yarn.sh 這兩個腳本檔案,在檔案前面增加如下內容:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
(4) 把 bigdata01 節點上將修改好配置的安裝包拷貝到其他兩個從節點:
cd /data/soft/
scp -rq hadoop-3.2.0 bigdata02:/data/soft/
scp -rq hadoop-3.2.0 bigdata03:/data/soft/
(5) 在 bigdata01 節點上格式化 HDFS:
cd /data/soft/hadoop-3.2.0
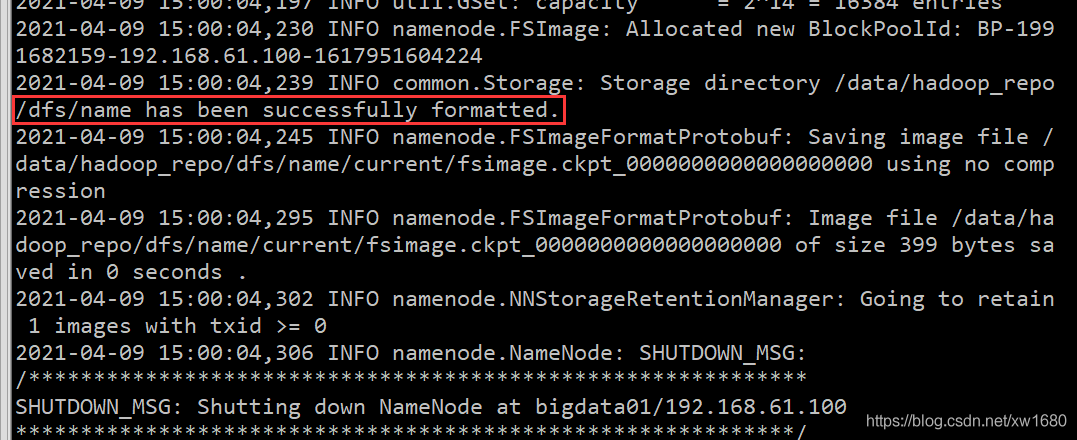
bin/hdfs namenode -format
如果在后面的日志資訊中能看到這一行,則說明 namenode 格式化成功,
4、啟動并關閉 Hadoop 集群
1、啟動 Hadoop 集群
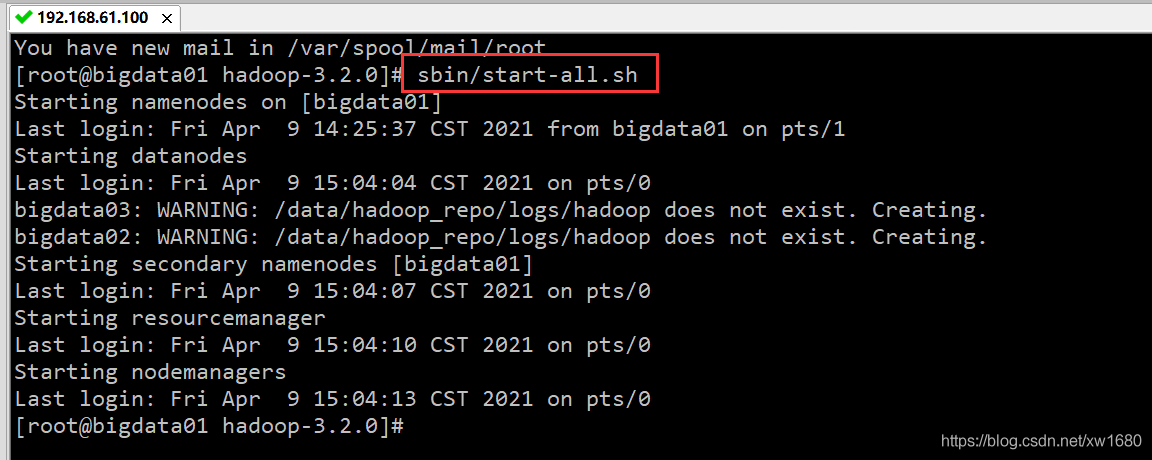
啟動 Hadoop 集群的命令可以分為 start-dfs.sh 和 start-yarn.sh 分別用以啟動 HDFS 檔案系統和 YARN,或者直接使用 start-all.sh 命令,下面通過 start-all.sh 命令啟動 Hadoop 集群,結果如下圖所示:
2、關閉 Hadoop 集群
關閉 Hadoop 集群的命令為 stop-all.sh,執行結果如下圖所示:
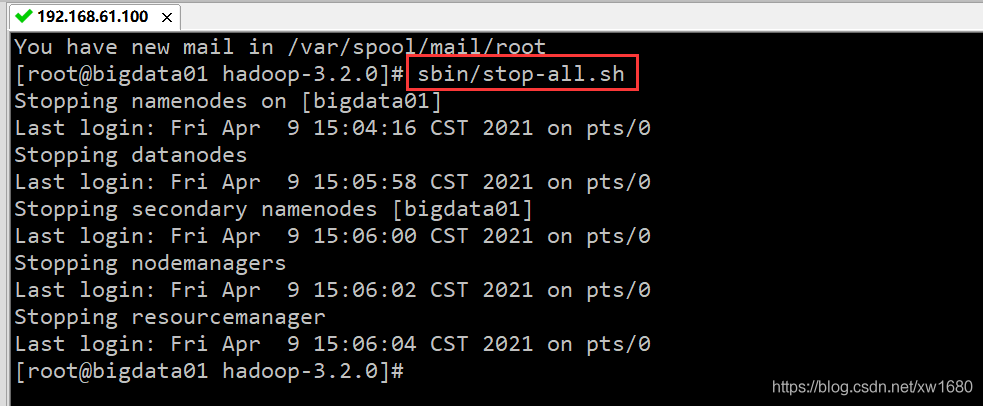
3、驗證 Hadoop 集群是否啟動成功
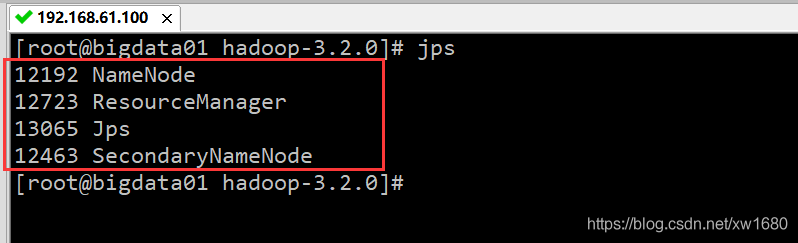
可以通過 jps 命令查看 Hadoop 是否啟動成功,首先查看 bigdata01 機器,在 bigdata01 服務器執行 jps 命令后,如果顯示的結果是下圖所示的四個行程的名稱:ResourceManager、NameNode、Jps 和SecondaryNameNode,則表示 bigdata01 服務器啟動成功:
下面查看 bigdata02 服務器的 Hadoop 是否啟動成功,通過 SSH 連接 bigdata02,然后查看 bigdata02 已啟動的服務,結果如下圖所示:
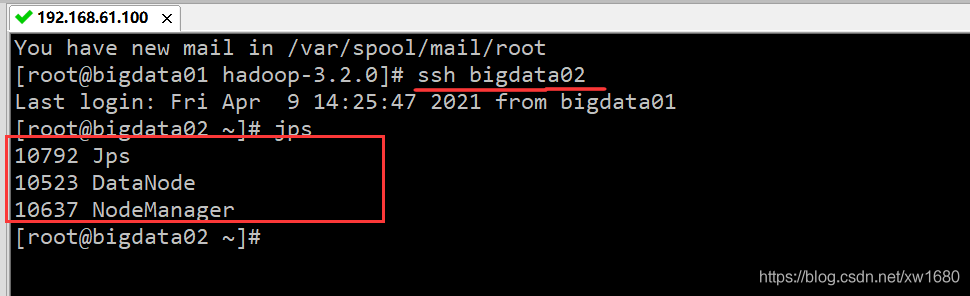
從上圖中可知,bigdata02 節點開啟了三個行程:NodeManager、Jps 和 DataNode,表明 bigdata02 節點啟動了 Hadoop,接下來再檢查一下 bigdata03,首先使用 exit 命令退出 bigdata01 與 bigdata02 的連接,然后連接 bigdata03,再使用 jps 命令查看啟動行程,結果如下圖所示:
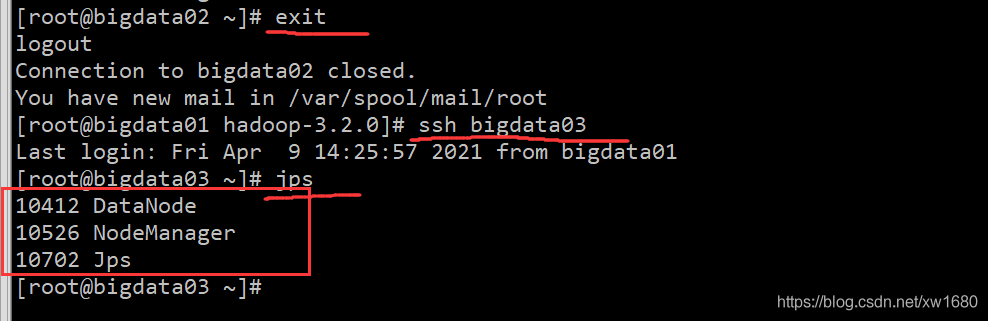
從上圖中可知,bigdata03 節點同樣開啟了三個行程:NodeManager、Jps 和 bigdata03,表明 bigdata03 節點啟動了 Hadoop,
5、查看 Hadoop 集群的基本資訊
1、查詢集群的 HDFS 資訊
用戶可以通過 HDFS 監控界面檢查當前的 HDFS 與 DataNode 的運行情況,打開瀏覽器,在地址欄中輸入:http://bigdata01:9870,按回車鍵即可看到 HDFS 的監控界面,如下圖所示:
該界面提供了如下資訊:
- Overview 記錄了 NameNode 的啟動時間、版本號、編譯版本等一些基本資訊,
- Summary 是集群資訊,提供了當前集群環境的一些有用資訊,從圖中可知所有 DataNode 節點的基本存盤資訊,例如硬碟大小以及有多少被 HDFS 使用等一些資料資訊,同時還標注了當前集群環境中 DataNode 的資訊,對活動狀態的 DataNode 也專門做了標記,
- NameNode Storage 提供了 NameNode 的資訊,最后的 State 表示此節點為活動節點,可正常提供服務,
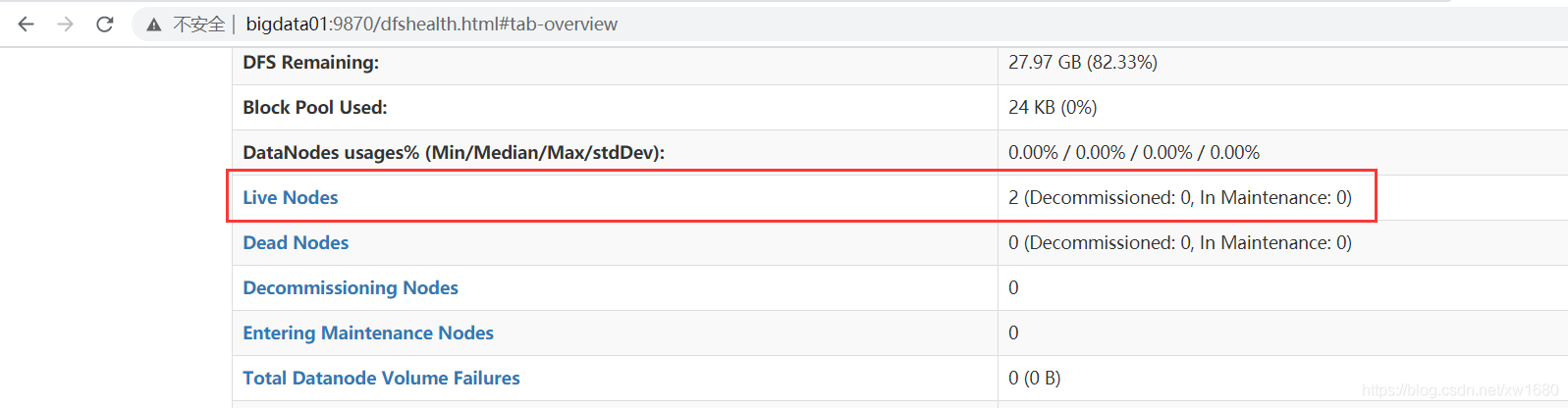
單擊 Datanodes,可以查看當前啟動的 DataNode 個數,如下圖所示:
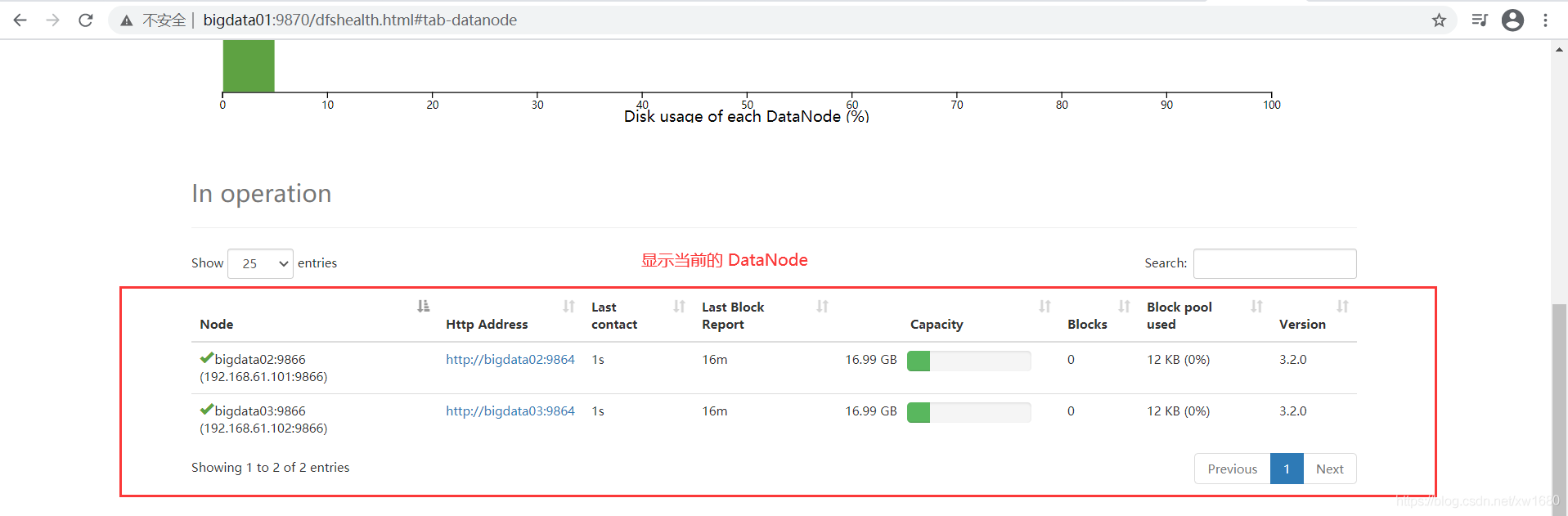
從上圖中可以看到 DataNode 節點有 bigdata02 和 bigdata03 兩個,
2、查詢集群的 YARN 資訊
通過網址 http://bigdata01:8088,可以查看到 YARN 的監控界面,打開 Master 節點的瀏覽器,在地址欄中輸入:http://bigdata01:8088,按回車鍵即可看到 YARN 的監控界面,如下圖所示:
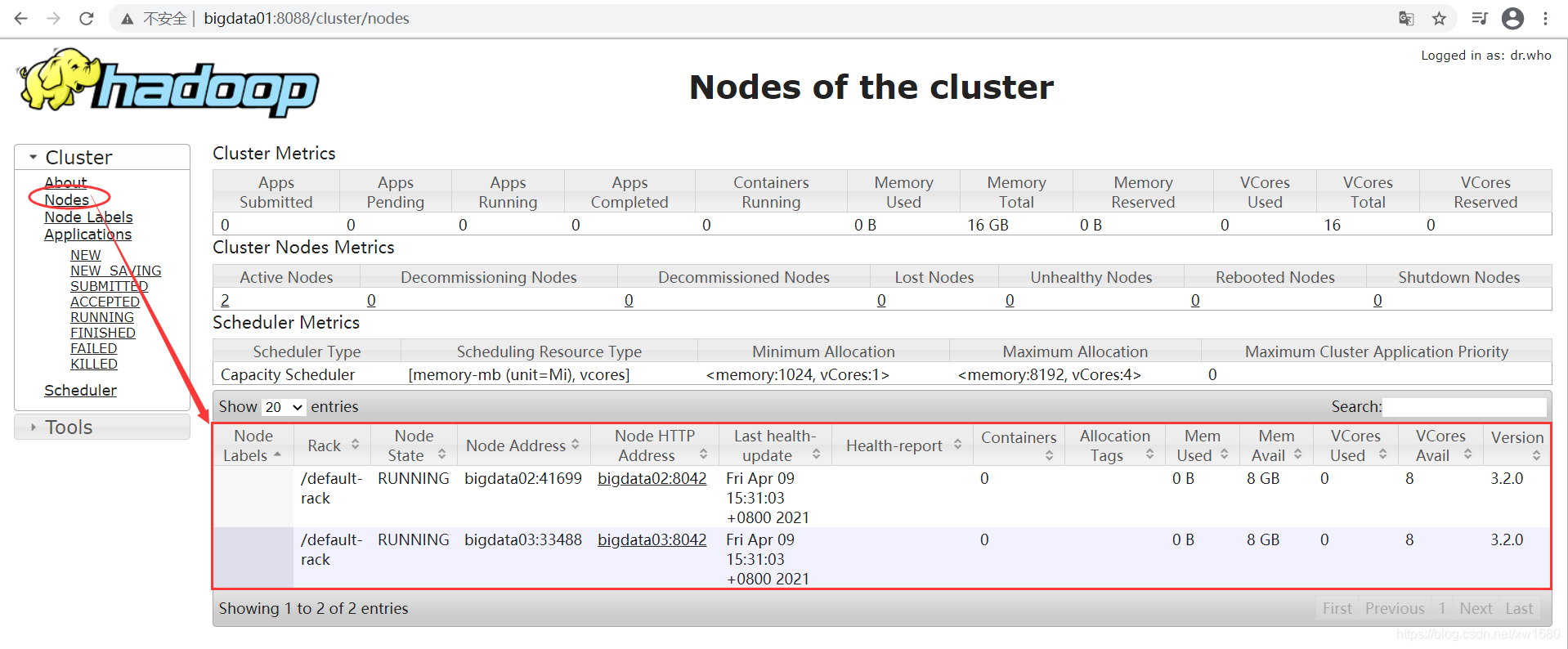
從上圖中可知,當前共有 2 個節點 Nodes,分別為:bigdata02 和 bigdata03,
6、在 Hadoop 集群中運行程式
通過上面的步驟,Hadoop 集群已經安裝完畢,下面通過在 Hadoop 集群上運行一個 MapReduce 程式,以幫助讀者初步理解分布式計算,在 Hadoop 中自帶了一些 MapReduce 示例程式,其中有一個用于計算圓周率的 Java 程式包,下面運行此程式,該 jar 包檔案的位置和檔案名是:
/data/soft/hadoop-3.2.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.0.jar
在 bigdata01 的終端輸入如下命令:
hadoop jar /data/soft/hadoop-3.2.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.0.jar pi 10 10
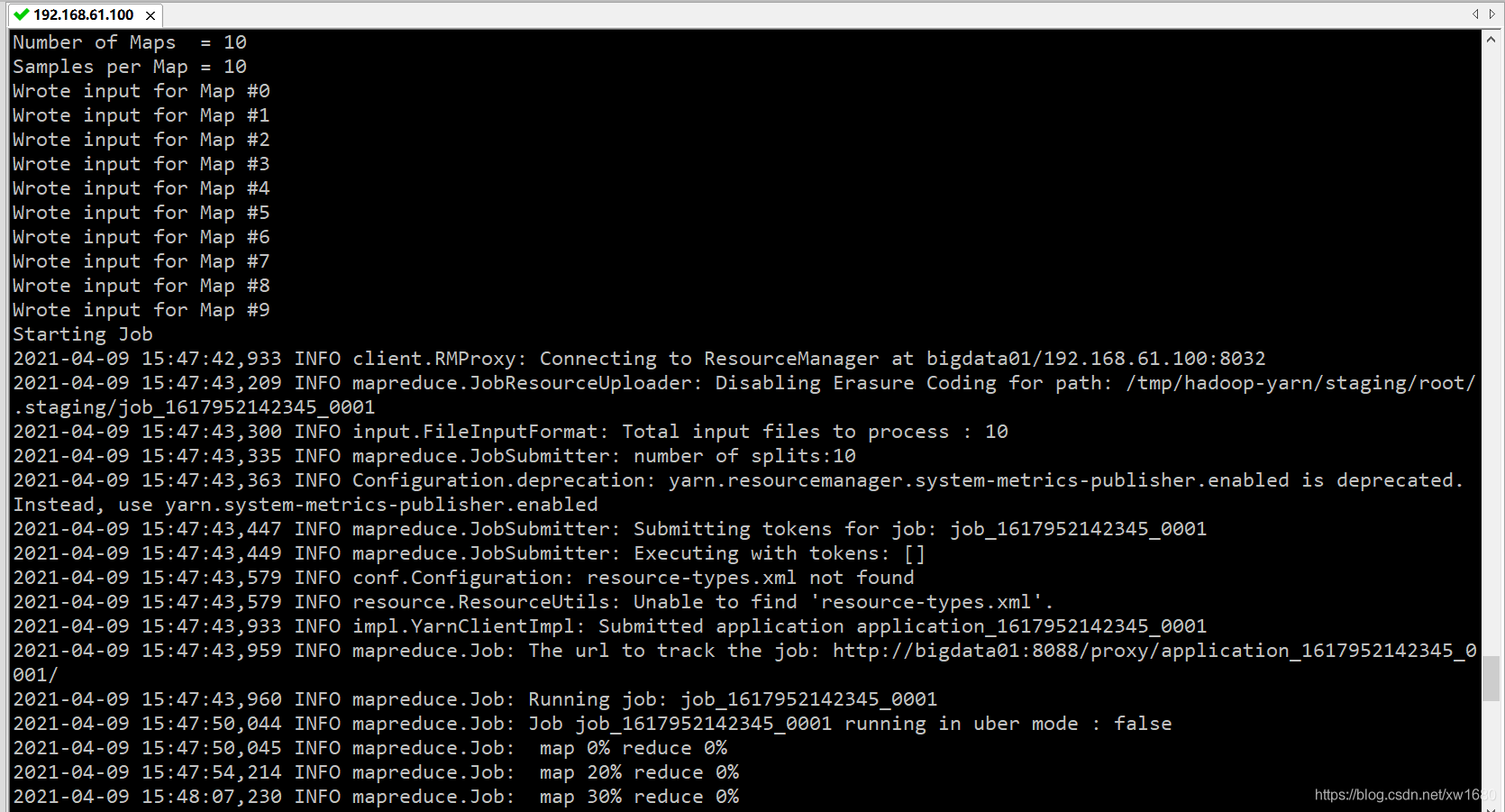
其中,pi 是類名,后面的兩個 10 都是運行引數,第一個 10 表示 Map 次數,第二個 10 表示隨機生成點的次數,執行程序中出現下圖所示的資訊時,則表明程式正常運行:
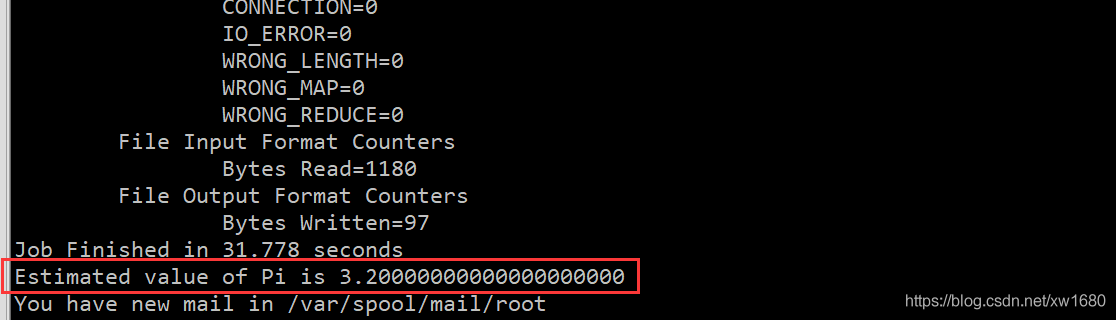
程式執行結果如下圖所示,可以看到,計算出來的 pi 值近似等于 3.2,
需要注意,執行 Hadoop MapReduce 程式,是驗證 Hadoop 系統是否正常啟動的最后一個環節,即使通過 jps 和 Web 方式驗證了 Hadoop 集群系統已經啟動,并且能夠查看到狀態資訊,也不一定意味著系統可以正常作業,例如,當防火墻沒有關閉時,MapReduce 程式執行不會成功,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/274534.html
標籤:其他
上一篇:H5新特性