資料結構篇
- 資料結構是資料的組織形式,可以用來表征特定的物件資料,在計算機程式設計中,操作的物件是各式各樣的資料,這些資料往往擁有不同的資料結構,例如陣列、結構體、指標和鏈表等,
- 資料結構+演算法+程式設計語言=程式,
- 資料結構是演算法實作的基礎,
1、資料結構概述
資料結構是計算機中對資料的一種存盤和組織方式,同時也泛指相互之間存在一種或多種特定關系的資料的集合,
1.1 什么是資料結構?
-
資料結構是計算機存盤、組織資料的方式,資料結構是指相互之間存在一種或多種特定關系的資料元素的集合,通常情況下,精心選擇的資料結構可以帶來更高的運行或者存盤效率,資料結構往往同高效的檢索演算法和索引技術有關,
-
業界許多專家都對其有相關定義,具體不多做贅述……
-
筆者理解的資料結構:一個資料結構是由資料元素依據某種邏輯聯系組織起來的,對資料元素間邏輯關系的描述稱為資料的邏輯結構,由于資料必須在計算機記憶體儲,資料的存盤結構是其在計算機內的表示,也就是資料結構的實作形式,
1.2 一些基本概念
- 資料(Data):資料是資訊的載體,能夠被計算機識別、存盤和加工處理,是計算機程式加工的“原材料”,
- 資料元素(Data Element):資料元素是資料的基本單位,也稱為元素、結點、頂點、記錄等,
- 一般來說,一個資料元素可以由若干個資料項組成,資料項是具有獨立含義的最小標識單位,資料項也可稱為欄位、域、屬性等,
- 資料結構(Data Structure):資料結構指的是資料之間的相互關系,也就是資料的組織形式,
1.3 資料結構的內容
-
資料的邏輯結構(Logical Structure):也就是資料元素(Data Element)之間的邏輯關系,資料的邏輯結構是從邏輯關系上描述資料的,與資料在計算機中如何存盤無關,也就是獨立于計算機的抽象概念,
-
資料的存盤結構(Storage Structure):也就是資料元素(Data Element)及其邏輯關系在計算機存盤器中的表示形式,
-
資料的運算:也就是能夠對資料施加操作,資料的運算基礎在于資料的邏輯結構上,每種邏輯結構都可以歸納一個運算的集合,
-
具體案例:
- 某班級學生成績表
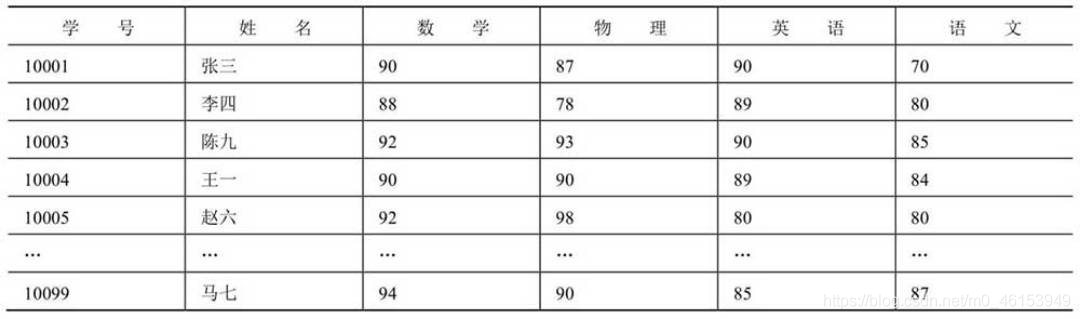
-
每一行可以看作是一個資料元素(Data Element),也可以稱為記錄或者結點,這個資料元素由學號、姓名、數學成績、物理成績、英語成績和語文成績等資料項構成,
-
這個表中的邏輯關系:
-
對表中任意一個結點,直接前趨(Immediate Predecessor)結點最多只有一個,直接前趨結點也就是與它相鄰且在它前面的結點,
- 對表中任意一個結點,直接后繼(Immediate Successor)結點最多只有一個,直接后繼結點也就是與它相鄰且在它后面的結點,
-
表中只有第一個結點沒有直接前趨,也就是開始結點,
- 表中只有最后一個結點沒有直接后繼,也就是終端結點,
-
例如,表中“張三”所在的結點就是開始結點,“馬七”所在的結點就是終端結點,表中間的“陳九”所在結點的直接前趨結點是“李四”所在的結點,表中間的“陳九”所在結點的直接后繼結點是“王一”所在的結點,這些結點關系就構成了某班級學生成績表的邏輯結構,
-
再來看一下資料的存盤結構:
-
我們知道資料的存盤結構是資料元素及其邏輯關系在計算機存盤器中的表示形式,
- 這就需要采用計算機語言來進行描述,例如,是每個結點按照順序依次存盤在一片連續的存盤單元中呢,還是存盤在分散的空間而使用指標將這些結點鏈接起來呢?
-
這方面的內容將在后面進行詳細講述,
-
再來看一下資料的運算:
-
拿到這個表之后,會進行哪些操作呢?一般來說,主要包括如下操作:
-
查找某個學生的成績,
-
-
對于新入學的學生,在表中增加一個結點來存放,
- 對于退學的學生,將其結點從表中洗掉,
-
其實,資料的邏輯結構、存盤結構和運算是一個整體,單獨地去理解這三者中的任何一個都是不全面的,這主要表現在如下兩點:
- (1)同一個邏輯結構可以有不同的存盤結構,
- (2)同一種邏輯結構也可以有不同的資料運算集合,
1.4 資料結構的分類
- 資料結構的分類:分為線性結構與非線性結構,
- 線性結構就是表中各個結點具有線性關系,用資料結構的語言來描述,線性結構應該包括如下幾點:
- 線性結構是非空集,
- 線性結構有且僅有一個開始結點和一個終端結點,
- 線性結構所有結點都最多只有一個直接前趨結點和一個直接后繼結點,
- 典型的線性結構:線性表、堆疊、佇列、串,
- 非線性結構就是表中各個結點之間具有多個對應關系,用資料結構的語言來描述,非線性結構應該包括如下幾點:
- 非線性結構是非空集,
- 非線性結構的一個結點可能有多個直接前趨結點和多個直接后繼結點,
- 典型的非線性結構:陣列、廣義表、樹結構、圖結構,
-
資料結構的存盤方式:順序存盤方式、鏈式存盤方式、索引存盤方式、散列存盤方式,
-
順序存盤方式:就是在一塊連續的存盤區域一個接著一個地存放資料,
-
一般采用陣列或結構陣列來描述,
-
鏈接存盤方式:不要求邏輯上相鄰的結點在物理位置上相鄰,結點間的邏輯關系由附加的指標欄位表示,一個結點的指標欄位往往指向下一個結點的存放位置,
- 一般在原資料項中增加指標型別來表示結點之間的位置關系,
-
索引存盤方式:采用附加的索引表的方式來存盤結點資訊,
-
索引存盤方式中索引項的一般形式如下所示:
( 關 鍵 字 . 地 址 ) (關鍵字.地址) (關鍵字.地址) -
其中,關鍵字是能夠唯一標識一個結點的資料項,
-
索引存盤方式還可以細分為兩類:稠密索引、稀疏索引,
-
-
散列存盤方式:根據結點的關鍵字直接計算出該結點的存盤地址的一種存盤方式,
在實際應用中,需要根據具體資料結構來確定采用哪種資料結構,
1.5 資料型別
-
資料型別:就是一個值的集合以及在這些值上定義的一系列操作的總稱,
-
抽象資料型別(ADT): 資料的組織及其相關的操作,可以看作是資料的邏輯結構及其在邏輯結構上定義的操作,
-
一個抽象資料型別可以定義為如下形式:
ADT 抽象資料型別名{ 資料物件:<資料物件的定義> 資料關系:<資料關系的定義> 基本操作:<基本操作的定義> } ADT 抽象資料型別名 -
抽象資料型別一般具有兩個特征:資料抽象、資料封裝,
-
1.6 常用的資料結構
- 陣列:將具有相同型別的若干變數有序地組織在一起的集合,
- 堆疊(Stack): 一種特殊的線性表,它只能在一個表的一個固定端進行資料結點的插入和洗掉操作,
- 堆疊按照后進先出的原則來存盤資料,也就是說,先插入的資料將被壓入堆疊底,最后插入的資料在堆疊頂,讀出資料時,從堆疊頂開始逐個讀出,
- 堆疊中沒有資料時,稱為空堆疊,
- 佇列(Queue):一種只允許在一端進行插入操作,而在另一端進行洗掉操作的線性表,
- 進行插入操作的一端稱為隊尾,進行洗掉操作的一端稱為隊頭,
- 佇列中沒有元素時,稱為空佇列,
- 鏈表(Linked List):一種資料元素按照鏈式存盤結構進行存盤的資料結構,這種存盤結構具有在物理上存在非連續的特點,
- 樹(Tree):包括n個結點的有窮集合K,
- 在樹結構中,有且僅有一個根結點,該結點沒有前驅結點,
- 在樹結構中的其他結點都有且僅有一個前驅結點,而且可以有m個后繼結點,m≥0,
- 圖(Graph): 一種非線性的資料結構,圖在實際生活中有很多例子,比如交通運輸網,地鐵網路,社交網路等等都可以抽象成圖結構,
- 堆(Heap):其實就是一棵完全二叉樹(若設二叉樹的深度為h,除第 h 層外,其它各層 (1~h-1) 的結點數都達到最大個數,第 h 層所有的結點都連續集中在最左邊),
- 散串列(Hash):一個包含關鍵字的具有固定大小的陣列,它能夠以常數時間執行插入,洗掉和查找操作,
2、線性表
2.1 什么是線性表?
從邏輯上來看,線性表就是由n(n≥0)個資料元素a1,a2,…,an組成的有限序列,
- 幾點說明:
- 資料元素的個數為n,也稱為表的長度,當n=0時稱為空表,
- 如果一個線性表非空,也就是n>0,則可以簡單地記作(a1,a2,……,an),
- 資料元素ai(1≤i≤n)表示各個元素,不同的場合,其含義也不盡相同,
- 線性表栗子:
- 英文字母表就是最簡單的線性表,英文字母表(A,B,C,…,Z)中,每個英文字符就是一個資料元素,也稱為資料結點,
- 另外,如前面所示的某班級學生成績表也是一個線性表,其中的資料元素就是某個學生的記錄,包括學號、姓名、各個科目的成績等,
- 對于一個非空的線性表,具有如下所示的邏輯結構特征:
- 有且僅有一個開始結點a1,沒有直接前趨結點,有且僅有一個直接后繼結點a2,
- 有且僅有一個終結結點an,沒有直接后繼結點,有且僅有一個直接前趨結點an-1,
- 其余的內部結點ai(2≤i≤n-1)都有且僅有一個直接前趨結點ai-1和一個直接后繼結點ai+1,
- 對于同一線性表,各資料元素ai必須具有相同的資料型別,即同一線性表中各資料元素具有相同的型別,每個資料元素的長度相同,
2.2 線性表的基本運算
- 1.初始化
- 初始化表(InitList)也就是構造一個空的線性表L,
- 2.計算表長
- 計算表長(ListLength)也就是計算線性表L中結點的個數
- 3.獲取結點
- 獲取結點(GetNode)就是取出線性表L中第i個結點的資料,這里1≤i≤ListLength(L),
- 4.查找結點
- 查找結點(LocateNode)就是在線性表L中查找值為x的結點,并回傳該結點在線性表L中的位置,如果在線性表中沒有找到值為x的結點,則回傳一個錯誤標志,這里需要注意的是,線性表中有可能含有多個與x值相同的結點,那么這時就只回傳第一次查找到的結點,
- 5.插入結點
- 插入結點(InsertList)就是在線性表L的第i個位置上插入一個新的結點,使得其后的結點編號依次加1,這時,插入1個新結點之后,線性表L的長度將變為n+1,
- 6.洗掉結點
- 洗掉結點(DeleteList)就是洗掉線性表L中的第i個結點,使得其后的所有結點編號依次減1,這時,洗掉1個結點之后,線性表L的長度將變為n-1,
在計算機中線性表可以采用兩種方式來保存,一種是順序存盤結構,另一種是鏈式存盤結構,
順序存盤結構的線性表稱為順序表,鏈式存盤的線性表稱為鏈表,
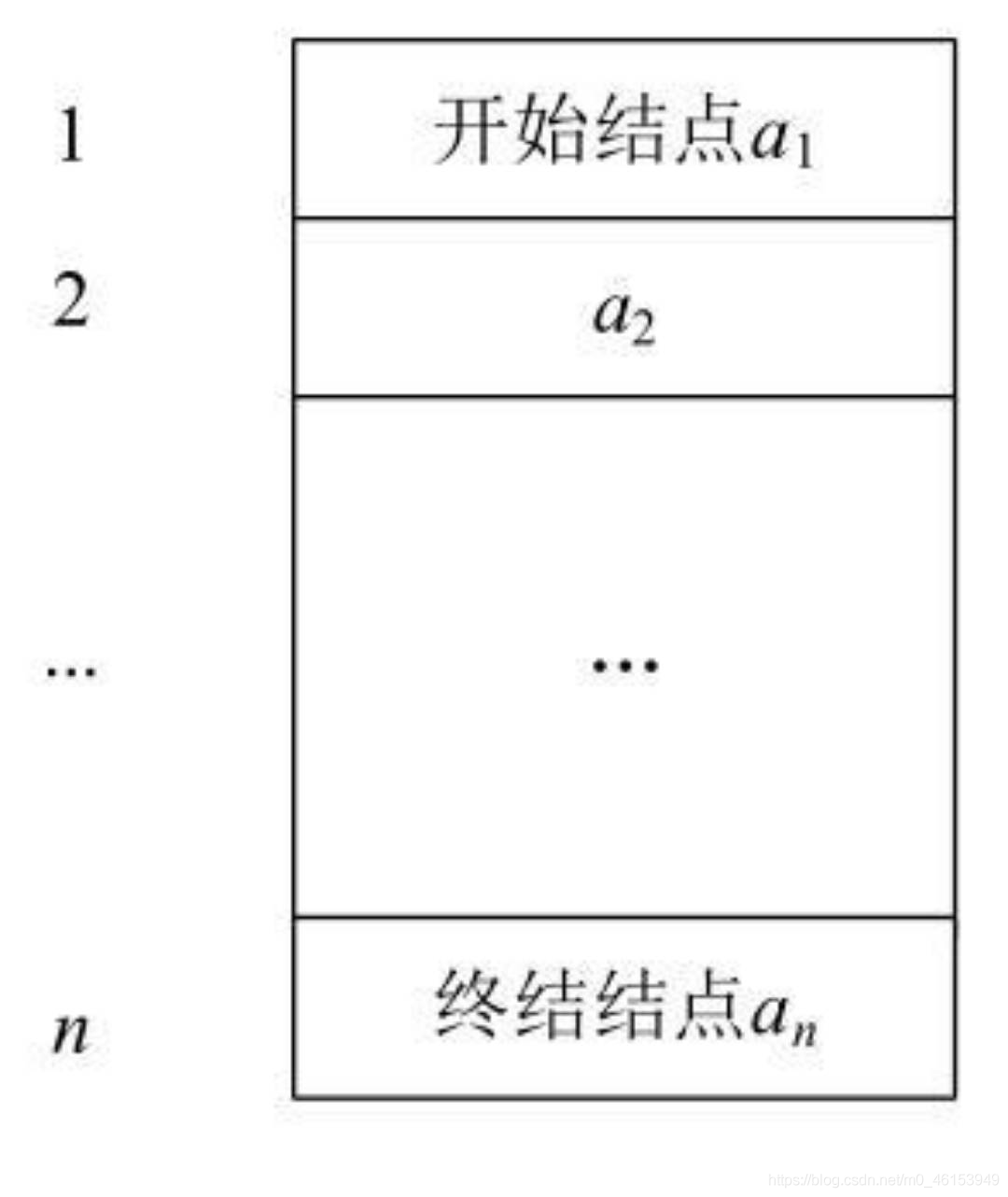
2.3 順序表結構
- 按照順序存盤方式存盤的線性表稱為順序表,
- 該線性表的結點按照邏輯次序依次存放在計算機的一組連續的存盤單元中,
-
由于順序表是依次存放的,只要知道了該順序表的首地址以及每個資料元素所占用的存盤長度,很容易計算出任何一個資料元素(也就是資料結點)的位置,
-
假設順序表中所有結點的型別相同,則每個結點所占用存盤空間的大小亦相同,每個結點占用c個存盤單元,其中第1個單元的存盤地址則是該結點的存盤地址,并設順序表中開始結點a1的存盤地址(簡稱為基地址)是LOC(a1),那么結點ai的存盤地址LOC(ai)可通過下式計算得到,
L O C ( a i ) = L O C ( a 1 ) + ( i ? 1 ) ? c ( 1 ≤ i ≤ n ) LOC(a_i)=LOC(a_1)+(i-1)*c (1≤i≤n) LOC(ai?)=LOC(a1?)+(i?1)?c (1≤i≤n)
2.4 順序表結構的程式設計
- 準備作業
- 準備需要使用的變數和資料結構,
- 具體代碼:
#define MAXLEN 100 // 定義順序表的最大長度
typedef struct
{
char kay[10]; // 結點的關鍵字
char name[20];
int age;
}DATA; // 定義結點型別
typedef struct // 定義順序表結構
{
DATA ListData[MAXLEN + 1]; // 保存順序表的結構陣列
int ListLen; // 順序表已存在的結點數量
}SLType;
// 在這里可以認為該順序表是一個班級學生的記錄,
// 其中,key為學號,name為學生的名稱,age為年齡,
- 初始化線性表
- 創建一個空的順序表,
- 具體代碼:
void SLInit(SLType *SL) // 初始化順序表
{
SL->ListLen = 0; // 初始化為空表
}
- 計算順序表的長度
- 計算線性表L中的結點個數,
- 具體代碼:
int SLLength(SLType *SL)
{
return (SL->ListLen); // 回傳順序表的元素數量
}
-
插入結點
- 在線性表第i個位置插入一個新結點,使得其后的結點編號加1,
- 具體代碼:
// 本演算法將實作將元素data插入到順序表SL中的第i個位置
int SLInsert(SLType *SL, int i, DATA data)
{
int j;
if (SL->ListLen >= MAXLEN) // 當前存盤空間已滿,不能插入
{
printf("順序表已滿,不能插入結點! \n");
return 0; // 回傳0表示不能插入
}
if (i<1 || i > SL->ListLen - 1) // 判斷i的范圍是否有效
{
printf("插入元素序號錯誤,不能插入元素! \n");
return 0; // 回傳0,表示插入失敗
}
for (j = SL->ListLen; j >= i; j--) // 將順序表中的資料向后移動
{
SL->ListData[i + 1] = SL->ListData[i];
}
SL->ListData[i] = data; // 插入結點
SL->ListLen++; // 順序表長度加1
return i; // 插入成功,回傳i
}
- 追加結點
- 在線性表的末尾再增加一個資料結點,
- 具體代碼:
int SLAdd(SLType *SL, DATA data) // 增加元素到順序表尾部
{
if (SL->ListLen >= MAXLEN) // 順序表已滿
{
printf("順序表已滿,不能再添加結點了! \n");
return 0;
}
SL->ListData[++SL->ListLen] = data;
return 1;
}
- 洗掉結點
- 洗掉線性表中的第i個結點,使其后所有結點編號依次減1,
- 具體代碼:
// 本演算法將實作洗掉順序表SL中的第i個位置的元素
int SLDelete(SLType *SL, int i)
{
int j;
if (i<1 || i > SL->ListLen) // 判斷i的范圍是否有效
{
printf("洗掉結點序號錯誤,不能洗掉結點! \n");
return 0; // 回傳0,表示洗掉失敗
}
for (j = i; j < SL->ListLen; j--) // 將順序表中的資料向前移動
{
SL->ListData[i] = SL->ListData[i+1];
}
SL->ListLen--; // 順序表長度減1
return 1; // 洗掉成功,回傳1
}
- 查找結點
- ①按序號查找結點,序號:陣列的下標號,
- 具體實作:
DATA *SLFindByNum(SLType *SL, int i) // 根據序號回傳資料元素
{
if (i<1 || i > SL->ListLen + 1) // 元素序號不正確
{
printf("結點序號錯誤,不能回傳結點! \n");
return NULL; // 不成功,回傳0
}
return &(SL->ListData[i]);
}
- ②按關鍵字查找結點,
- 此處以上文中的key為關鍵字,key為學生的學號,
- 具體實作:
DATA *SLFindByCont(SLType *SL, char *key) // 根據關鍵字查詢結點
{
int i;
for (i = 1; i <= SL->ListLen; i++)
{
if (strcmp(SL->ListData[i].key,key)==0) // 如果找到所需結點
{
return i; // 回傳結點序號
}
}
return 0; // 搜索整個順序表后未找到,回傳0
}
- strcmp() 函式用于對兩個字串進行比較(區分大小寫),頭檔案:string.h
- 顯示所有結點
- 掃描順序表,輸出各元素的值,
- 具體代碼:
int SLAll(SLType *SL) // 顯示順序表中所有的結點
{
int i;
for (i = 1; i <= SL->ListLen; i++)
{
printf("(%s, %s, %d) \n", SL->ListData[i].key, SL->ListData[i].name, SL->ListData[i].age);
}
return 0;
}
- 案例:對某班級學生學號、姓名和年齡資料進行順序表操作,
- 完整代碼:
#include <stdio.h>
#include <string.h>
#define MAXLEN 100 // 定義順序表的最大長度
typedef struct
{
char key[10]; // 結點的關鍵字
char name[20];
int age;
}DATA; // 定義結點型別
typedef struct // 定義順序表結構
{
DATA ListData[MAXLEN + 1]; // 保存順序表的結構陣列
int ListLen; // 順序表已存在的結點數量
}SLType;
void SLInit(SLType *SL) // 初始化順序表
{
SL->ListLen = 0; // 初始化為空表
}
int SLLength(SLType *SL)
{
return (SL->ListLen); // 回傳順序表的元素數量
}
// 本演算法將實作將元素data插入到順序表SL中的第i個位置
int SLInsert(SLType *SL, int i, DATA data)
{
int j;
if (SL->ListLen >= MAXLEN) // 當前存盤空間已滿,不能插入
{
printf("順序表已滿,不能插入結點! \n");
return 0; // 回傳0表示不能插入
}
if (i<1 || i > SL->ListLen - 1) // 判斷i的范圍是否有效
{
printf("插入元素序號錯誤,不能插入元素! \n");
return 0; // 回傳0,表示插入失敗
}
for (j = SL->ListLen; j >= i; j--) // 將順序表中的資料向后移動
{
SL->ListData[i + 1] = SL->ListData[i];
}
SL->ListData[i] = data; // 插入結點
SL->ListLen++; // 順序表長度加1
return i; // 插入成功,回傳i
}
int SLAdd(SLType *SL, DATA data) // 增加元素到順序表尾部
{
if (SL->ListLen >= MAXLEN) // 順序表已滿
{
printf("順序表已滿,不能再添加結點了! \n");
return 0;
}
SL->ListData[++SL->ListLen] = data;
return 1;
}
// 本演算法將實作洗掉順序表SL中的第i個位置的元素
int SLDelete(SLType *SL, int i)
{
int j;
if (i<1 || i > SL->ListLen) // 判斷i的范圍是否有效
{
printf("洗掉結點序號錯誤,不能洗掉結點! \n");
return 0; // 回傳0,表示洗掉失敗
}
for (j = i; j < SL->ListLen; j--) // 將順序表中的資料向前移動
{
SL->ListData[i] = SL->ListData[i+1];
}
SL->ListLen--; // 順序表長度減1
return 1; // 洗掉成功,回傳1
}
DATA *SLFindByNum(SLType *SL, int i) // 根據序號回傳資料元素
{
if (i<1 || i > SL->ListLen + 1) // 元素序號不正確
{
printf("結點序號錯誤,不能回傳結點! \n");
return NULL; // 不成功,回傳0
}
return &(SL->ListData[i]);
}
DATA *SLFindByCont(SLType *SL, char *key) // 根據關鍵字查詢結點
{
int i;
for (i = 1; i <= SL->ListLen; i++)
{
if (strcmp(SL->ListData[i].key,key)==0) // 如果找到所需結點
{
return i; // 回傳結點序號
}
}
return 0; // 搜索整個順序表后未找到,回傳0
}
int SLAll(SLType *SL) // 顯示順序表中所有的結點
{
int i;
for (i = 1; i <= SL->ListLen; i++)
{
printf("(%s, %s, %d) \n", SL->ListData[i].key, SL->ListData[i].name, SL->ListData[i].age);
}
return 0;
}
int main()
{
int i;
SLType SL; // 定義順序表
DATA data; // 定義節點保存資料型別
DATA *pdata; // 定義結點保存指標
char key[10]; // 保存關鍵字
printf("順序表操作演示: \n");
SLInit(&SL); // 初始化順序表
printf("初始化順序表完成! \n");
do { //回圈添加資料結點
printf("輸入要添加的結點(學號 姓名 年齡): \n");
fflush(stdin); // 清空輸入緩沖區
scanf("%s %s %d", &data.key, &data.name, &data.age);
if (data.age) // 如果年齡不為0
{
if (!SLAdd(&SL, data)) // 若添加結點失敗
{
break; // 退出死回圈
}
}
else { // 若年齡為0
break; //退出死回圈
}
} while (1);
printf("\n順序表中的結點順序為:\n");
SLAll(&SL); // 顯示所有結點資料
fflush(stdin); // 清空輸入緩沖區
printf("\n要取出的結點的序號:");
scanf("%d", &i); // 輸入結點序號
pdata = SLFindByNum(&SL, i); // 按序號查找結點
if (pdata) // 若回傳的結點指標不為空
{
printf("第%d個結點為:(%s ,%s ,%d) \n", i, pdata->key, pdata->name, pdata->age);
}
fflush(stdin); // 清空輸入緩沖區
printf("\n要查找的結點的關鍵字:");
scanf("%s", key); // 輸入關鍵字
i = SLFindByCont(&SL, key); // 按關鍵字查找結點,回傳結點序號
pdata = SLFindByNum(&SL, i); // 按序號查找結點
if (pdata) // 若回傳的結點指標不為空
{
printf("第%d個結點為:(%s ,%s ,%d) \n", i, pdata->key, pdata->name, pdata->age);
}
getchar();
return 0;
}
順序表結構的存盤方式非常容易理解,操作也十分方便,但是順序表結構有如下一些缺點:
- 在插入或者洗掉結點時,往往需要移動大量的資料,影響運行效率,
- 如果表比較大,有時難以分配足夠的連續存盤空間,往往導致記憶體分配失敗,而無法存盤,
為了克服順序表結構的以上缺點,可以采用鏈表結構,
2.5 什么是鏈表結構?
- 鏈表結構是一種動態存盤分配的結構形式,可以根據需要動態申請所需的記憶體單元,
- 最常用的鏈表結構:單鏈表、雙向鏈表和回圈串列,
- 鏈表中每個結點都包括如下兩部分:
- 資料部分:保存的是該結點的實際資料,
- 地址部分:保存的是下一個結點的地址,
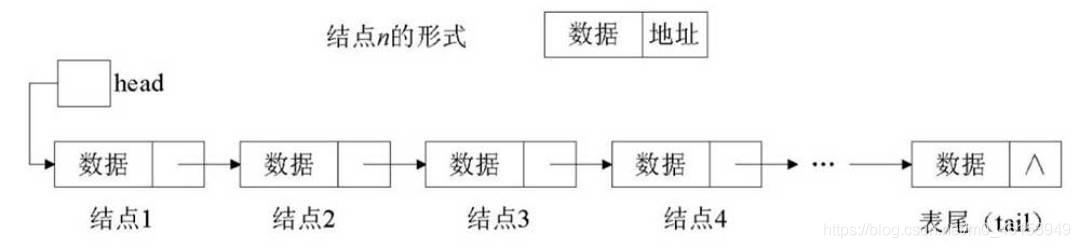
- 鏈表結構是由許多結點構成,
- 在進行鏈表操作時:
- 首先需要定義1個“頭指標”變數(一般以head表示),該指標變數指向鏈表結構的第一個結點;
- 第1個結點的地址部分又指向第2個結點……直到最后一個結點;
- 最后一個結點不再指向其他結點,稱為“表尾”;
- 一般在表尾的地址部分放一個空地址NULL,鏈表到此結束,
- 鏈表結構的優點:
- 動態資料結構:鏈表是一種動態資料結構,因此它可以在運行時通過分配和取消分配記憶體來增長和縮小,所以沒有必要給出鏈表的初始大小,
- 易于插入和洗掉:在鏈表中進行插入和洗掉節點真的很容易,與陣列不同,我們不必在插入或洗掉元素后移位元素,在鏈表中,我們只需要更新節點下一個指標中的地址,
- 記憶體利用率高:由于鏈表的大小可以在運行時增加或減少,因此沒有記憶體浪費,在陣列的情況下,存在大量的記憶體浪費,就像我們宣告一個大小為10的陣列并且只存盤6個元素,那么浪費了4個元素的空間,鏈表中沒有這樣的問題,因為只在需要時才分配記憶體,
注意:用戶可以malloc函式動態分配結點的存盤空間,當洗掉某個結點時,應該使用free函式釋放其占用的記憶體空間,
-
鏈表結構的缺點:
- 記憶體的使用:與陣列相比,在鏈表中存盤元素需要更多記憶體,因為在鏈表中每個節點都包含一個指標,它需要額外的記憶體,
- 遍歷困難,不易于查詢:鏈表中的元素或節點遍歷很困難,訪問元素的效率低,我們不能像索引一樣隨機訪問任何元素,例如,如果我們想要訪問位置n的節點,那么我們必須遍歷它之前的所有節點,因此,訪問節點所需的時間很長,
- 反向遍歷困難:在鏈表中反向遍歷非常困難,在雙鏈表的情況下,后指標需要更容易但額外的記憶體因此浪費記憶體,
-
單鏈表:向上面的鏈式結構一樣,每個結點中只包含一個指標,
-
雙向鏈表:若每個結點包含兩個指標,一個指向下一個結點,另一個指向上一個結點,這就是雙向鏈表,
-
單回圈鏈表:在單鏈表中,將終端結點的指標域NULL改為指向表頭結點或開始結點即可構成單回圈鏈表,
-
多重鏈的回圈鏈表:如果將表中結點鏈在多個環上,將構成多重鏈的回圈鏈表,
2.6 鏈表結構的程式設計
- 準備作業
- 準備需要使用的變數和資料結構,
- 具體代碼:
typedef struct
{
char key[10]; // 關鍵字
char name[20];
int age;
}Data;
typedef struct Node // 定義鏈表結構
{
Data nodeData; // 資料域nodeData
struct Node *nextNode; // 指標域nextNode
}CLType;
-
尾插法
- 將新結點插入到當前鏈表的表尾,
- 由于一般情況下鏈表只有一個頭指標head,所以要在末尾添加結點就需要從頭指標head開始逐個檢查,直到找到最后一個結點(即表尾),

- 追加結點的操作步驟如下:
- (1)首先分配記憶體空間,保存新增的結點,
- (2)從頭指標head開始逐個檢查,直到找到最后一個結點(即表尾),
- (3)將表尾結點的地址設定為新增結點的地址,
- (4)將新增結點的地址部分設定為空地址NULL,即新增結點成為表尾,
- 具體代碼:
CLType *CLAddEnd(CLType * head, Data nodeData) // 尾插法
{
CLType *node, *htemp;
if (!(node = (CLType *)malloc(sizeof(CLType))))
{
printf("申請記憶體失敗!\n");
return NULL; // 分配記憶體失敗
}
else {
node->nodeData = nodeData; // 保存資料
node->nextNode = NULL; // 設定結點指標為空,即為表尾
if (head == NULL) // 頭指標
{
head = node;
return head;
}
htemp = head;
while (htemp->nextNode != NULL) // 查找鏈表的末尾
{
htemp = htemp->nextNode;
}
htemp->nextNode = node;
return head;
}
}
-
頭插法
- 將新結點插入到當前鏈表的表頭,
- 插入頭結點的步驟如下:
- (1)首先分配記憶體空間,保存新增的結點,
- (2)使新增結點指向頭指標head所指向的結點,
- (3)然后使頭指標head指向新增結點,

- 具體代碼:
CLType *CLAddFirst(CLType * head, Data nodeData) // 頭插法
{
CLType *node;
if (!(node = (CLType *)malloc(sizeof(CLType))))
{
printf("申請記憶體失敗!\n");
return NULL; // 分配記憶體失敗
}
else {
node->nodeData = nodeData; // 保存資料
node->nextNode = head; // 指向頭指標所指向的結點
head=node; // 頭指標指向新增結點
return head;
}
}
-
查找結點
- 在鏈表中查找需要的元素,
- ①按序號查找結點,序號:陣列的下標號,
- 具體實作:
CLType *CLFindByNum(CLType *head, int i) // 根據序號回傳資料元素
{
int j = 1; // 計數,初始為1
CLType *htemp=head->nextNode; // 頭結點指標賦值給htemp
if (i == 0)
return head; // 若i為0,回傳頭結點
if (i < 1)
return NULL; // 若i無效,回傳NULL
while (htemp && j > i) { // 從第一個結點開始查找,查找第i個結點
htemp = htemp->nextNode;
j++;
}
return htemp; // 回傳第i個結點的指標
}
-
②按關鍵字查找結點,
- 具體代碼:
CLType *CLFindNode(CLType *head, char *key) // 查找結點
{
CLType *htemp;
htemp = head; // 保存鏈表頭指標
while (htemp) // 若結點有效,進行查找
{
if (strcmp(htemp->nodeData.key, key) == 0) // 判斷結點關鍵字與傳入關鍵字是否相同
{
return htemp; //回傳該結點指標
}
htemp = htemp->nextNode; // 處理下一結點
}
return NULL; // 回傳空指標
}
-
插入結點
-
在鏈表中間插入結點,
-
插入節點操作步驟:
- (1)首先分配記憶體空間,保存新增的結點,
- (2)找到要插入的邏輯位置,也就是位于哪兩個結點之間,
- (3)修改插入位置結點的指標,使其指向新增結點,而使新增結點指向原插入位置所指向的結點,
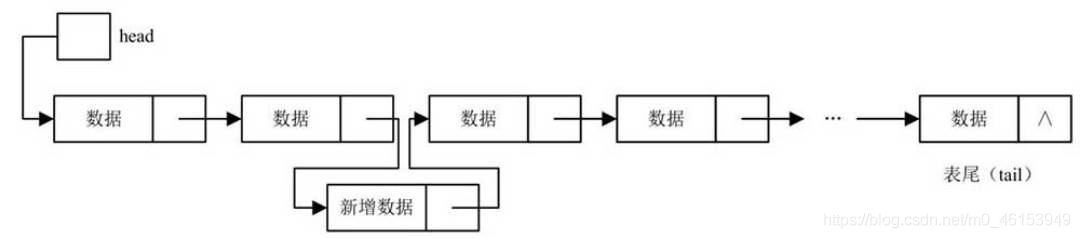
- 具體代碼:
-
CLType *CLInsertNode(CLType *head, char *findkey, Data nodeData) // 插入結點
{
CLType *node, *nodetemp;
if (!(node = (CLType *)malloc(sizeof(CLType)))) // 分配保存結點的內容
{
printf("申請記憶體失敗! \n");
return 0; // 分配記憶體失敗
}
node->nodeData = nodeData;
nodetemp = CLFindNode(head, findkey); // 保存結點中的資料
if (nodetemp) // 若找到要插入的結點
{
node->nextNode = nodetemp->nextNode; // 新插入結點指向關鍵字結點的下一結點
nodetemp->nextNode = node; // 設定關鍵結點指向新插入結點
}
else {
printf("未找到正確的插入位置! \n");
free(node); // 釋放記憶體
}
return head; // 回傳頭指標
}
-
洗掉結點
- 將鏈表中的某個結點洗掉,
- 洗掉結點的操作步驟如下:
- (1)查找需要洗掉的結點,
- (2)使前一結點指向當前結點的下一結點,
- (3)洗掉結點,

- 具體代碼:
int CLDeleteNode(CLType *head, char * key)
{
CLType *node, *htemp; // node保存洗掉結點的前一結點
htemp = head;
node = head;
while (htemp)
{
if (strcmp(htemp->nodeData.key, key) == 0) // 找到關鍵字,執行洗掉操作
{
node->nextNode = htemp->nextNode; // 使前一結點指向當前結點的下一結點
free(htemp); // 釋放記憶體
return 1;
}
else {
node=htemp; // 指向當前結點
htemp = htemp->nextNode; // 指向下一結點
}
}
return 0; // 未洗掉
}
- 計算鏈表的長度
- 統計鏈表中結點的數量,
- 具體代碼:
int CLLength(CLType *head) // 計算鏈表長度
{
CLType *htemp;
int Len = 0;
htemp = head;
while (htemp) // 遍歷鏈表
{
Len++; // 累加結點數量
htemp = htemp->nextNode; // 處理下一結點
}
return Len; // 回傳結點數量
}
- 顯示所有結點
- 掃描順序表,輸出各元素的值,
- 具體代碼:
void CLAllNode(CLType *head) // 遍歷鏈表
{
CLType *htemp;
Data nodeData;
htemp = head;
printf("當前鏈表共有%d個結點,鏈表所有資料如下: \n", CLLength(head));
while (htemp) // 回圈處理鏈表的每個節點
{
nodeData = htemp->nodeData; // 獲取結點資料
printf("結點(%s, %s, %d) \n", nodeData.key, nodeData.name, nodeData.age);
htemp = htemp->nextNode; // 處理下一結點
}
}
- 案例:使用鏈表操作實作用戶管理
- 具體代碼:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct
{
char key[10]; // 關鍵字
char name[20];
int age;
}Data;
typedef struct Node // 定義鏈表結構
{
Data nodeData; // 資料域nodeData
struct Node *nextNode; // 指標域nextNode
}CLType;
CLType *CLAddEnd(CLType * head, Data nodeData) // 尾插法
{
CLType *node, *htemp;
if (!(node = (CLType *)malloc(sizeof(CLType))))
{
printf("申請記憶體失敗!\n");
return NULL; // 分配記憶體失敗
}
else {
node->nodeData = nodeData; // 保存資料
node->nextNode = NULL; // 設定結點指標為空,即為表尾
if (head == NULL) // 頭指標
{
head = node;
return head;
}
htemp = head;
while (htemp->nextNode != NULL) // 查找鏈表的末尾
{
htemp = htemp->nextNode;
}
htemp->nextNode = node;
return head;
}
}
CLType *CLAddFirst(CLType * head, Data nodeData) // 頭插法
{
CLType *node;
if (!(node = (CLType *)malloc(sizeof(CLType))))
{
printf("申請記憶體失敗!\n");
return NULL; // 分配記憶體失敗
}
else {
node->nodeData = nodeData; // 保存資料
node->nextNode = head; // 指向頭指標所指向的結點
head=node; // 頭指標指向新增結點
return head;
}
}
CLType *CLFindNode(CLType *head, char *key) // 查找結點
{
CLType *htemp;
htemp = head; // 保存鏈表頭指標
while (htemp) // 若結點有效,進行查找
{
if (strcmp(htemp->nodeData.key, key) == 0) // 判斷結點關鍵字與傳入關鍵字是否相同
{
return htemp; //回傳該結點指標
}
htemp = htemp->nextNode; // 處理下一結點
}
return NULL; // 回傳空指標
}
CLType *CLInsertNode(CLType *head, char *findkey, Data nodeData) // 插入結點
{
CLType *node, *nodetemp;
if (!(node = (CLType *)malloc(sizeof(CLType)))) // 分配保存結點的內容
{
printf("申請記憶體失敗! \n");
return 0; // 分配記憶體失敗
}
node->nodeData = nodeData;
nodetemp = CLFindNode(head, findkey); // 保存結點中的資料
if (nodetemp) // 若找到要插入的結點
{
node->nextNode = nodetemp->nextNode; // 新插入結點指向關鍵字結點的下一結點
nodetemp->nextNode = node; // 設定關鍵結點指向新插入結點
}
else {
printf("未找到正確的插入位置! \n");
free(node); // 釋放記憶體
}
return head; // 回傳頭指標
}
int CLDeleteNode(CLType *head, char * key)
{
CLType *node, *htemp; // node保存洗掉結點的前一結點
htemp = head;
node = head;
while (htemp)
{
if (strcmp(htemp->nodeData.key, key) == 0) // 找到關鍵字,執行洗掉操作
{
node->nextNode = htemp->nextNode; // 使前一結點指向當前結點的下一結點
free(htemp); // 釋放記憶體
return 1;
}
else {
node=htemp; // 指向當前結點
htemp = htemp->nextNode; // 指向下一結點
}
}
return 0; // 未洗掉
}
int CLLength(CLType *head) // 計算鏈表長度
{
CLType *htemp;
int Len = 0;
htemp = head;
while (htemp) // 遍歷鏈表
{
Len++; // 累加結點數量
htemp = htemp->nextNode; // 處理下一結點
}
return Len; // 回傳結點數量
}
void CLAllNode(CLType *head) // 遍歷鏈表
{
CLType *htemp;
Data nodeData;
htemp = head;
printf("當前鏈表共有%d個結點,鏈表所有資料如下: \n", CLLength(head));
while (htemp) // 回圈處理鏈表的每個節點
{
nodeData = htemp->nodeData; // 獲取結點資料
printf("結點(%s, %s, %d) \n", nodeData.key, nodeData.name, nodeData.age);
htemp = htemp->nextNode; // 處理下一結點
}
}
int main()
{
int i;
CLType *node, *head=NULL;
Data nodeData;
char key[10], findkey[10];
printf("鏈表測驗,先輸入鏈表中的資料,格式為:關鍵字 姓名 年齡 \n");
do {
fflush(stdin); // 清空輸入緩沖區
scanf("%s", nodeData.key);
if (strcmp(nodeData.key, "0") == 0)
{
break; // 若輸入為0,則退出
}
else {
scanf("%s %d", nodeData.name, &nodeData.age);
head = CLAddEnd(head, nodeData); // 尾插法
}
} while (1);
CLAllNode(head); // 顯示所有結點
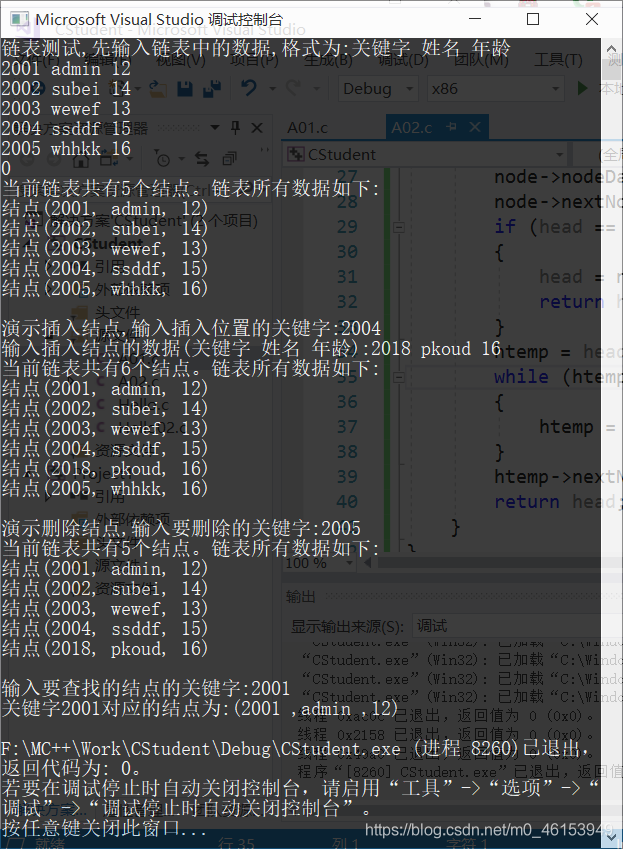
printf("\n演示插入結點,輸入插入位置的關鍵字:");
scanf("%s", findkey); // 輸入插入位置的關鍵字
printf("輸入插入結點的資料(關鍵字 姓名 年齡):");
scanf("%s %s %d", nodeData.key, nodeData.name, &nodeData.age); // 輸入插入節點的資料
head = CLInsertNode(head, findkey, nodeData); // 呼叫插入函式
CLAllNode(head); // 顯示所有結點
printf("\n演示洗掉結點,輸入要洗掉的關鍵字:");
fflush(stdin); // 清空輸入緩沖區
scanf("%s", key);
CLDeleteNode(head, key); // 呼叫洗掉結點函式
CLAllNode(head); // 顯示所有結點
printf("\n輸入要查找的結點的關鍵字:");
fflush(stdin); // 清空輸入緩沖區
scanf("%s", key); // 輸入關鍵字
node = CLFindNode(head, key); // 按關鍵字查找結點,回傳結點指標
if (node) // 若回傳的結點指標有效
{
nodeData = node->nodeData; // 獲取結點資料
printf("關鍵字%s對應的結點為:(%s ,%s ,%d) \n", key, nodeData.key, nodeData.name,nodeData.age);
}
else { // 若結點指標無效
printf("在鏈表中未找到關鍵字為%s的結點! \n", key);
}
return 0;
}
- 測驗資料:
2001 admin 12
2002 subei 14
2003 wewef 13
2004 ssddf 15
2005 whhkk 16
3、堆疊與佇列
3.1 什么是堆疊?
堆疊(Stack):只允許在一端進行插入和洗掉操作的線性表,
- 堆疊結構可以分為兩類,
- 順序堆疊結構:即使用一組地址連續的記憶體單元依次保存堆疊中的資料,在程式中,可以定義一個指定大小的結構陣列來作為堆疊,序號為0的元素就是堆疊底,再定義一個變數top保存堆疊頂的序號即可,
- 鏈式堆疊結構:即使用鏈表形式保存堆疊中各元素的值,鏈表首部(head指標所指向元素)為堆疊頂,鏈表尾部(指向地址為NULL)為堆疊底,
- 在堆疊結構中只能在一端進行操作,該操作端稱為堆疊頂,另一端稱為堆疊底,也就是說,保存和取出資料都只能從堆疊結構的一端進行,從資料的運算角度來分析,堆疊結構是按照“后進先出”(Last In Firt Out,LIFO)的原則處理結點資料的,
- 堆疊頂(Top):允許進行插入和洗掉的那一端,
- 堆疊底(Bottom):不允許進行插入和洗掉的那一端,
- 空堆疊:不包含任何元素的空表,
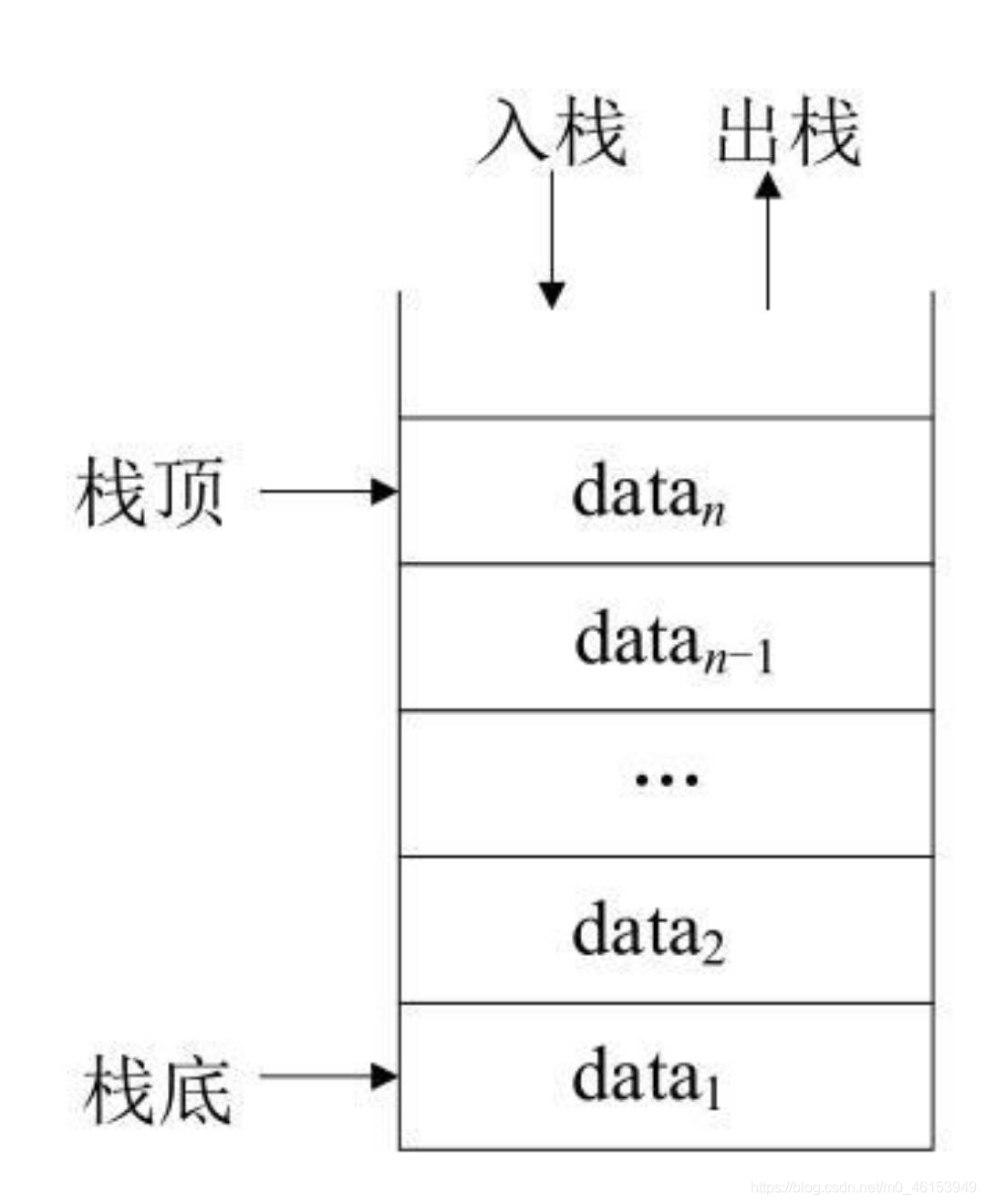
堆疊結構在日常生活中有很多例子,例如,當倉庫中堆放貨物時,先來的貨物放在里面,后來的貨物放在外面;而要取出貨物時,總是先取外面的,最后才能取到里面放的貨物,也就是說,后放入貨物先取出,
- 堆疊結構的基本操作:
- 入堆疊(Push):將資料保存到堆疊頂的操作,進行入堆疊操作前,先修改堆疊頂指標,使其向上移動一個元素位置,然后將資料保存到堆疊頂指標所指的位置,
- 出堆疊(Pop):將堆疊頂資料彈出的操作,通過修改堆疊頂指標,使其指向堆疊中的下一個元素,
- 初始化堆疊(InitStack):構造一個空堆疊 S,分配記憶體空間,
- 銷毀堆疊(DestroyStack):銷毀并釋放堆疊 S 所占用的記憶體空間,
- 讀堆疊頂元素(GetTop):若堆疊 S 非空,則用 x 回傳堆疊頂元素,
- 判空(StackEmpty):判斷一個堆疊 S 是否為空,若S為空,則回傳true,否則回傳false,
3.2 堆疊結構程式設計
- 準備作業
- 準備需要使用的變數和資料結構,
- 具體代碼:
#define MAXLEN 50
typedef struct
{
char name[10];
int age;
}DATA;
typedef struct stack
{
DATA data[SIZE + 1]; // 資料元素
int top; // 堆疊頂
}StackType;
- 初始化堆疊結構
- 創建一個空的順序堆疊,
- 具體操作步驟如下:
- (1)按符號常量SIZE指定的大小申請一塊記憶體空間,用來保存堆疊中的資料,
- (2)設定堆疊頂指標的值為0,表示是一個空堆疊,
- 具體代碼:
StackType *STInit()
{
StackType *p;
if (p = (StackType *)malloc(sizeof(StackType))) // 申請堆疊記憶體
{
p->top = 0; // 設定堆疊頂為0
return p; // 回傳指向堆疊的指標
}
return NULL;
}
- 判斷空堆疊
- 判斷堆疊是否為空,
- 具體代碼:
int STIsEmpty(StackType *s) // 判斷堆疊是否為空
{
int t;
t = (s->top == 0);
return t;
}
- 判斷堆疊滿
- 判斷堆疊結構是否為滿,
- 具體代碼:
int STIsFull(StackType *s) // 判斷堆疊是否為滿
{
int t;
t = (s->top == MAXLEN);
return t;
}
- 清空堆疊
- 清空堆疊中的所有資料,將堆疊頂指標top設定為0,表示執行清空堆疊操作,
- 具體代碼:
void STClear(StackType *s) // 清空堆疊
{
s->top = 0;
}
- 釋放空間
- 釋放堆疊結構所占的記憶體單元,
- 使用free()函式釋放所分配的記憶體,
- 具體代碼:
void STFree(StackType *s) // 釋放堆疊所占的空間
{
if (s)
{
free(s);
}
}
- 入堆疊操作
- 將資料元素保存到堆疊結構,
- 入堆疊操作的具體步驟如下:
- (1)首先判斷堆疊頂top,如果top大于或等于SIZE,則表示溢位,進行出錯處理,
- (2)設定top=top+1(堆疊頂指標加1,指向入堆疊地址),
- (3)將入堆疊元素保存到top指向的位置,
- 具體代碼:
int PushST(StackType *s, DATA data) // 入堆疊操作
{
if ((s->top + 1) > MAXLEN)
{
printf("堆疊溢位! \n");
return 0;
}
s->data[++s->top] = data;
return 1;
}
- 出堆疊操作
- 從堆疊頂彈出一個資料元素,
- 出堆疊操作的具體步驟如下:
- (1)首先判斷堆疊頂top,如果top等于0,則表示為空堆疊,進行出錯處理,
- (2)將堆疊頂指標top所指位置的元素回傳,
- (3)設定top=top-1,也就是使堆疊頂指標減1,指向堆疊的下一個元素,原來堆疊頂元素被彈出,
- 具體代碼:
DATA PopST(StackType *s) // 出堆疊操作
{
if (s->top == 0)
{
printf("堆疊為空! \n");
exit(0);
}
return (s->data[s->top--]);
}
- 讀取堆疊頂資料
- 顯示堆疊頂結點資料的內容,
- 具體代碼:
DATA PeekST(StackType *s) // 讀取堆疊頂資料
{
if (s->top == 0)
{
printf("堆疊為空! \n");
exit(0);
}
return (s->data[s->top]);
}
- 案例:使用堆疊實作學生資料操作,
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAXLEN 50 // 最大長度
#define SIZE 100
typedef struct
{
char name[10];
int age;
}DATA;
typedef struct stack
{
DATA data[SIZE + 1]; // 資料元素
int top; // 堆疊頂
}StackType;
StackType *STInit()
{
StackType *p;
if (p = (StackType *)malloc(sizeof(StackType))) // 申請堆疊記憶體
{
p->top = 0; // 設定堆疊頂為0
return p; // 回傳指向堆疊的指標
}
return NULL;
}
int STIsEmpty(StackType *s) // 判斷堆疊是否為空
{
int t;
t = (s->top == 0);
return t;
}
int STIsFull(StackType *s) // 判斷堆疊是否為滿
{
int t;
t = (s->top == MAXLEN);
return t;
}
void STClear(StackType *s) // 清空堆疊
{
s->top = 0;
}
void STFree(StackType *s) // 釋放堆疊所占的空間
{
if (s)
{
free(s);
}
}
int PushST(StackType *s, DATA data) // 入堆疊操作
{
if ((s->top + 1) > MAXLEN)
{
printf("堆疊溢位! \n");
return 0;
}
s->data[++s->top] = data;
return 1;
}
DATA PopST(StackType *s) // 出堆疊操作
{
if (s->top == 0)
{
printf("堆疊為空! \n");
exit(0);
}
return (s->data[s->top--]);
}
DATA PeekST(StackType *s) // 讀取堆疊頂資料
{
if (s->top == 0)
{
printf("堆疊為空! \n");
exit(0);
}
return (s->data[s->top]);
}
int main()
{
StackType *stack;
DATA data, data2;
stack = STInit(); // 初始化堆疊
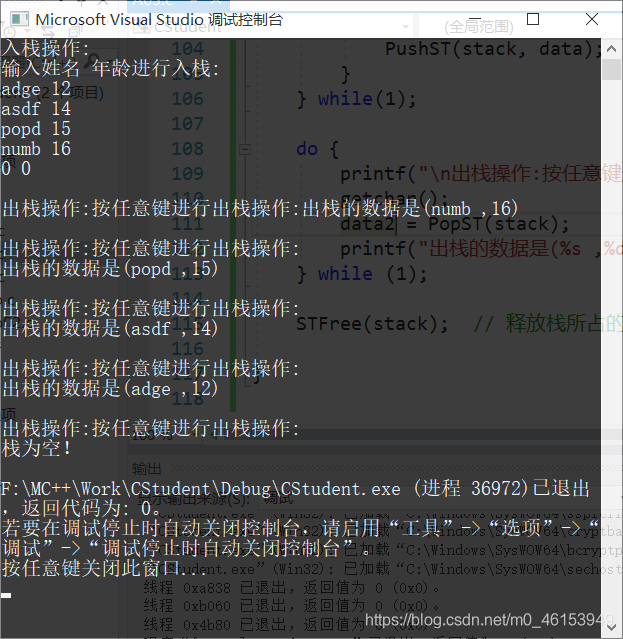
printf("入堆疊操作: \n");
printf("輸入姓名 年齡進行入堆疊: \n");
do {
scanf("%s %d", data.name, &data.age);
if (strcmp(data.name, "0") == 0)
{
break; // 若輸入為0,則退出
}
else {
PushST(stack, data);
}
} while(1);
do {
printf("\n出堆疊操作:按任意鍵進行出堆疊操作:");
getchar();
data2 = PopST(stack);
printf("出堆疊的資料是(%s ,%d) \n", data2.name, data2.age);
} while (1);
STFree(stack); // 釋放堆疊所占的空間
return 0;
}
- 測驗資料:
adge 12
asdf 14
popd 15
numb 16
3.3 什么是佇列?
一種操作受限的線性表,只允許在表的一端進行插入,而在表的另一端進行洗掉,
- 佇列結構可以分為兩類:
- 順序佇列結構:即使用一組地址連續的記憶體單元依次保存佇列中的資料,
在程式中,可以定義一個指定大小的結構陣列來作為佇列, - 鏈式佇列結構:即使用鏈表形式保存佇列中各元素的值,
- 順序佇列結構:即使用一組地址連續的記憶體單元依次保存佇列中的資料,
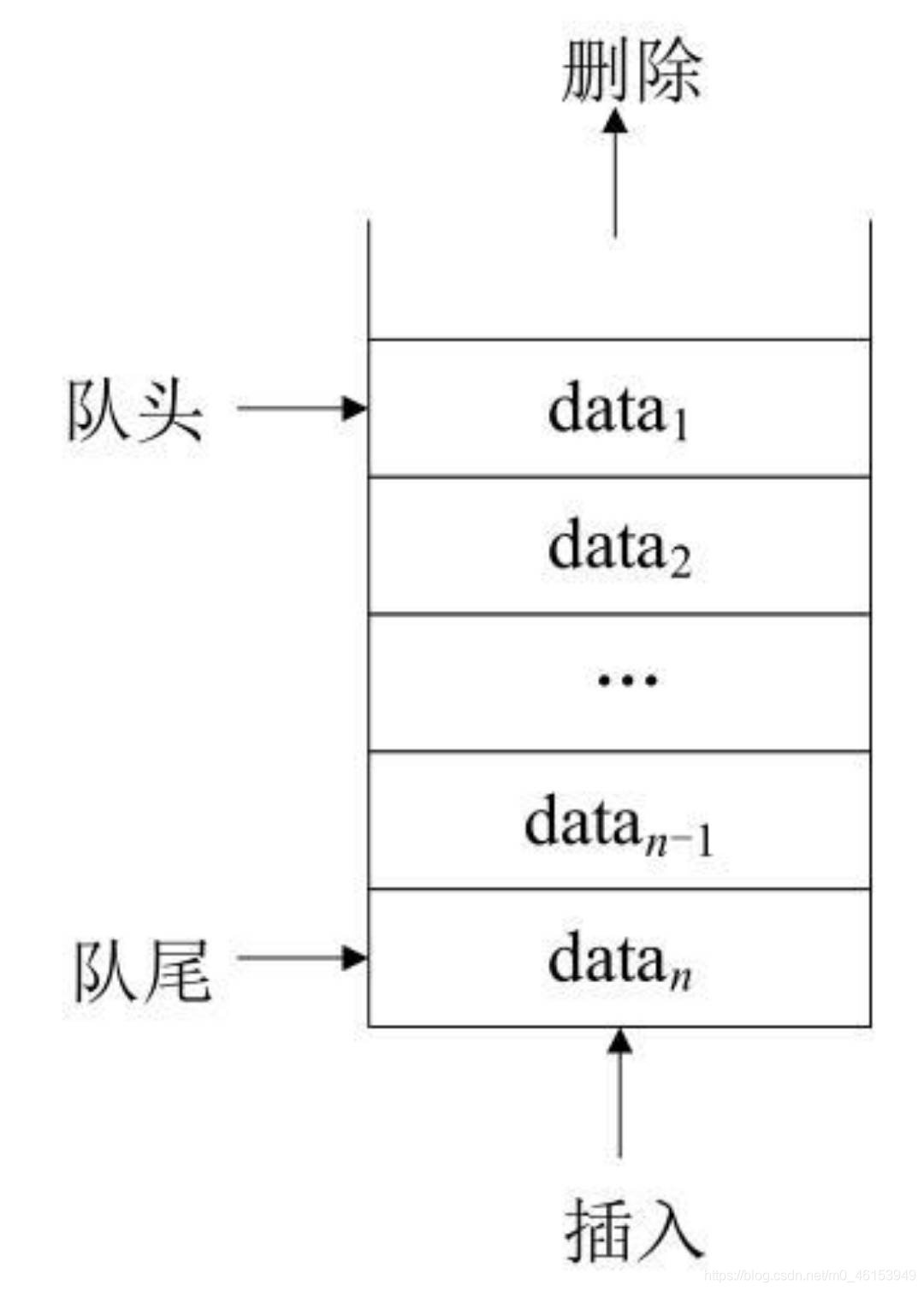
- 從圖中可以看出,在佇列結構中允許對兩端進行操作,但是兩端的操作不同,
- 在表的一端只能進行洗掉操作,稱為隊頭;
- 在表的另一端只能進行插入操作,稱為隊尾,
- 如果佇列中沒有資料元素,則稱為空佇列,
- 從資料的運算角度來分析,佇列結構是按照“先進先出”(First In First Out,FIFO)的原則處理結點資料,
佇列結構在日常生活中有很多例子,例如銀行的電子排號系統,先來的人取的號靠前,后來的人取的號靠后,這樣,先來的人將最先得到服務,后來的人將后得到服務,一切按照“先來先服務”的原則,
- 佇列結構的基本操作:
- 初始化佇列(InitQueue):構造一個空佇列Q,
- 銷毀佇列(DestroyQueue):銷毀并釋放佇列Q所占用的記憶體空間,
- 入佇列(EnQueue):將一個元素添加到隊尾(相當于到佇列最后排隊等候),
- 出佇列(DeQueue):將隊頭的元素取出,同時洗掉該元素,使后一個元素成為隊頭,
- 讀隊頭元素(GetHead):若佇列Q非空,則將隊頭元素賦值給x,
- 判佇列空(QueueEmpty):若佇列Q為慷訓傳true,否則回傳false,
不是任何對線性表的操作都可以作為佇列的操作,比如:不可以隨便讀取佇列中的某個資料,
3.4 佇列結構程式設計
- 準備作業
- 準備需要使用的變數和資料結構,
- 具體代碼:
#define QUEUELEN 15
typedef struct
{
char name[10];
int age;
}DATA;
typedef struct
{
DATA data[QUEUELEN]; //佇列陣列
int head; // 隊頭
int tail; // 隊尾
}SQType;
- 初始化佇列結構
- 創建一個空的順序佇列,
- 順序佇列的初始化操作步驟如下:
- (1)按符號常量QUEUELEN指定的大小申請一塊記憶體空間,用來保存佇列中的資料,
- (2)設定head=0和tail=0,表示是一個空堆疊,
- 具體代碼:
SQType *SQTypeInit()
{
SQType *q;
if (q = (SQType *)malloc(sizeof(SQType))) // 申請記憶體
{
q->head = 0; // 設定隊頭
q->tail = 0; // 設定隊尾
return q;
}
else {
return NULL; // 回傳空
}
}
- 判斷空佇列
- 判斷一個佇列是否為空,
- 具體代碼:
int SQTypeIsEmpty(SQType *q) // 判斷空佇列
{
int temp;
temp = q->head == q->tail;
return (temp);
}
- 判斷滿佇列
- 判斷佇列是否為滿,
- 具體代碼:
int SQTypeIsFull(SQType *q) // 判斷滿佇列
{
int temp;
temp = q->tail == QUEUELEN;
return (temp);
}
- 清空佇列
- 清楚佇列中的所有資料,
- 具體代碼:
void SQTypeClear(SQType *q) // 清空佇列
{
q->head = 0; // 設定隊頭
q->tail = 0; // 設定隊尾
}
- 釋放空間
- 釋放佇列所占的記憶體單元,
- 具體代碼:
void SQTypeFree(SQType *q) // 釋放佇列
{
if (q != NULL)
{
free(q);
}
}
- 入隊
- 將資料元素保存到佇列中,
- 入佇列操作的具體步驟如下:
- (1)首先判斷佇列頂tail,如果tail等于QUEUELEN,則表示溢位,進行出錯處理,否則執行以下操作,
- (2)設定tail=tail+1(佇列頂指標加1,指向入佇列地址),
- (3)將入佇列元素保存到tail指向的位置,
- 具體代碼:
int InSQType(SQType *q, DATA data) // 入佇列
{
if (q->tail == QUEUELEN)
{
printf("佇列已滿!操作失敗! \n");
return 0;
}
else {
q->data[q->tail++] = data; // 將元素入隊
return (1);
}
}
- 出佇列
- 從佇列頂端彈出資料元素,
- 出佇列操作的具體步驟如下:
- (1)判斷佇列head,如果head等于tail,則表示為空佇列,進行出錯處理,否則執行下面的步驟,
- (2)從佇列首部取出隊頭元素(實際是回傳隊頭元素的指標),
- (3)設修改隊頭head的序號,使其指向后一個元素,
- 具體代碼:
DATA *OutSQType(SQType *q) // 出佇列
{
if (q->head == q->tail)
{
printf("\n佇列為空!操作失敗! \n");
exit(0);
}
else {
return &(q->data[q->head++]);
}
}
- 讀取結點資料
- 讀取佇列中的結點的資料,讀取結點資料的操作僅僅是顯示佇列中的資料內容,
- 具體代碼:
DATA *PeekSQType(SQType *q) // 讀取結點資料
{
if (SQTypeIsEmpty(q))
{
printf("\n空佇列! \n");
return NULL;
}
else {
return &(q->data[q->head]);
}
}
- 計算佇列的長度
- 統計佇列中資料結點的個數,
- 具體代碼:
int SQTypeLen(SQType *q) // 計算佇列長度
{
int temp;
temp = q->tail - q->head;
return (temp);
}
- 案例:使用佇列實作學生資料操作,
- 具體代碼:
#include <stdio.h>
#define QUEUELEN 15
typedef struct
{
char name[10];
int age;
}DATA;
typedef struct
{
DATA data[QUEUELEN]; //佇列陣列
int head; // 隊頭
int tail; // 隊尾
}SQType;
SQType *SQTypeInit()
{
SQType *q;
if (q = (SQType *)malloc(sizeof(SQType))) // 申請記憶體
{
q->head = 0; // 設定隊頭
q->tail = 0; // 設定隊尾
return q;
}
else {
return NULL; // 回傳空
}
}
int SQTypeIsEmpty(SQType *q) // 判斷空佇列
{
int temp;
temp = q->head == q->tail;
return (temp);
}
int SQTypeIsFull(SQType *q) // 判斷滿佇列
{
int temp;
temp = q->tail == QUEUELEN;
return (temp);
}
void SQTypeClear(SQType *q) // 清空佇列
{
q->head = 0; // 設定隊頭
q->tail = 0; // 設定隊尾
}
void SQTypeFree(SQType *q) // 釋放佇列
{
if (q != NULL)
{
free(q);
}
}
int InSQType(SQType *q, DATA data) // 入佇列
{
if (q->tail == QUEUELEN)
{
printf("佇列已滿!操作失敗! \n");
return 0;
}
else {
q->data[q->tail++] = data; // 將元素入隊
return (1);
}
}
DATA *OutSQType(SQType *q) // 出佇列
{
if (q->head == q->tail)
{
printf("\n佇列為空!操作失敗! \n");
exit(0);
}
else {
return &(q->data[q->head++]);
}
}
DATA *PeekSQType(SQType *q) // 讀取結點資料
{
if (SQTypeIsEmpty(q))
{
printf("\n空佇列! \n");
return NULL;
}
else {
return &(q->data[q->head]);
}
}
int SQTypeLen(SQType *q) // 計算佇列長度
{
int temp;
temp = q->tail - q->head;
return (temp);
}
int main()
{
SQType *stack;
DATA data, *data2;
stack = SQTypeInit(); // 初始化佇列
printf("入佇列操作: \n");
printf("輸入姓名 年齡進行入隊操作: \n");
do {
scanf("%s %d", data.name, &data.age);
if (strcmp(data.name, "0") == 0)
{
break; // 若輸入為0,停止入隊
}
else {
InSQType(stack, data);
}
} while (1);
do {
printf("出隊操作:按任意鍵進行出隊操作:\n");
getchar();
data2 = OutSQType(stack);
printf("出佇列的資料為(%s ,%d) \n", data2->name, data2->age);
} while (1);
SQTypeFree(stack); // 釋放佇列所占的記憶體空間
return 0;
}
- 測驗案例:
qeqwe 12
gfdsg 45
fddgf 63
dsgff 32
rgyhp 15
4、樹結構
樹(Tree)結構是一種描述非線性層次關系的資料結構,
4.1 什么是樹?
- 樹是n個資料結點的集合,在該集合中包含一個根結點,根結點之下則分布著一些互不交叉的子集合,這些子集合也是根結點的子樹,
- 當n=0時,稱為空樹,
- 當n > 1時,其余結點可分為m(m > 0)個互不相交的有限集合T1, T2,…, Tm,其中每個集 合本身又是一棵樹,并且稱為根結點的子樹,
- 非空樹結構的基本特征:
- 有且僅有一個根節點;
- 沒有后繼的結點稱為“葉子結點”(或終端結點);
- 有后繼的結點稱為“分支結點”(或非終端結點);
- 除了根節點外,任何一個結點都有且僅有一個前驅;
- 每個結點可以有0個或多個后繼,
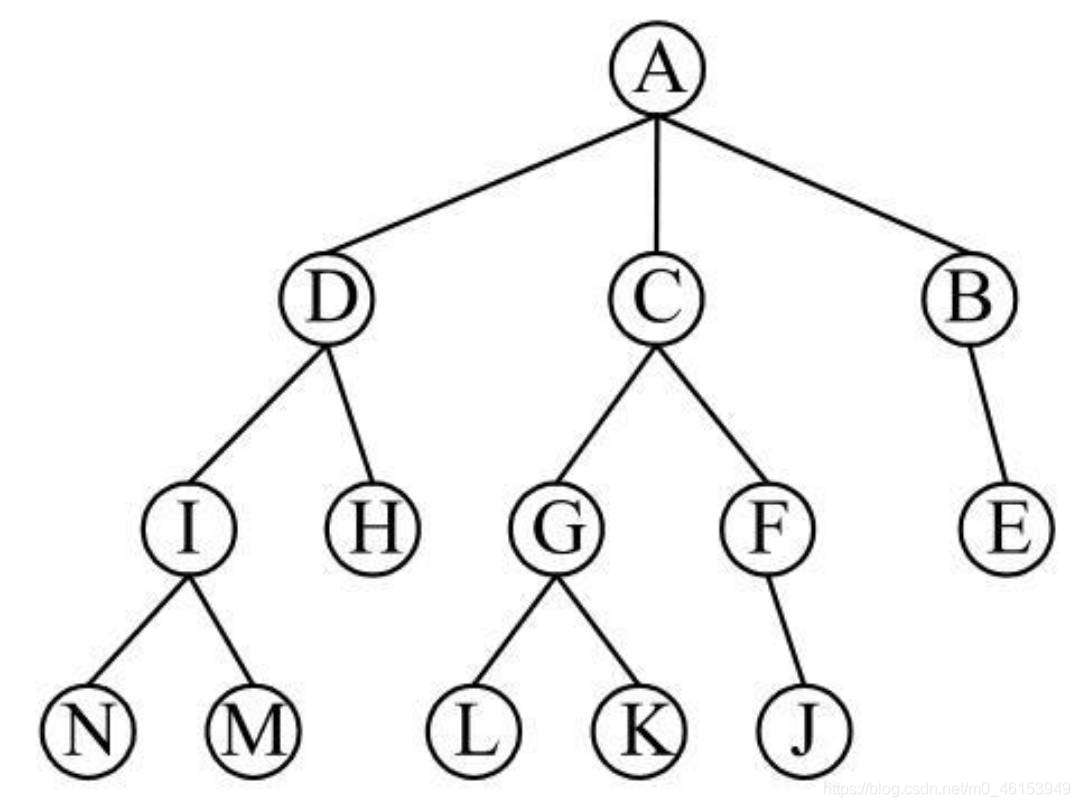
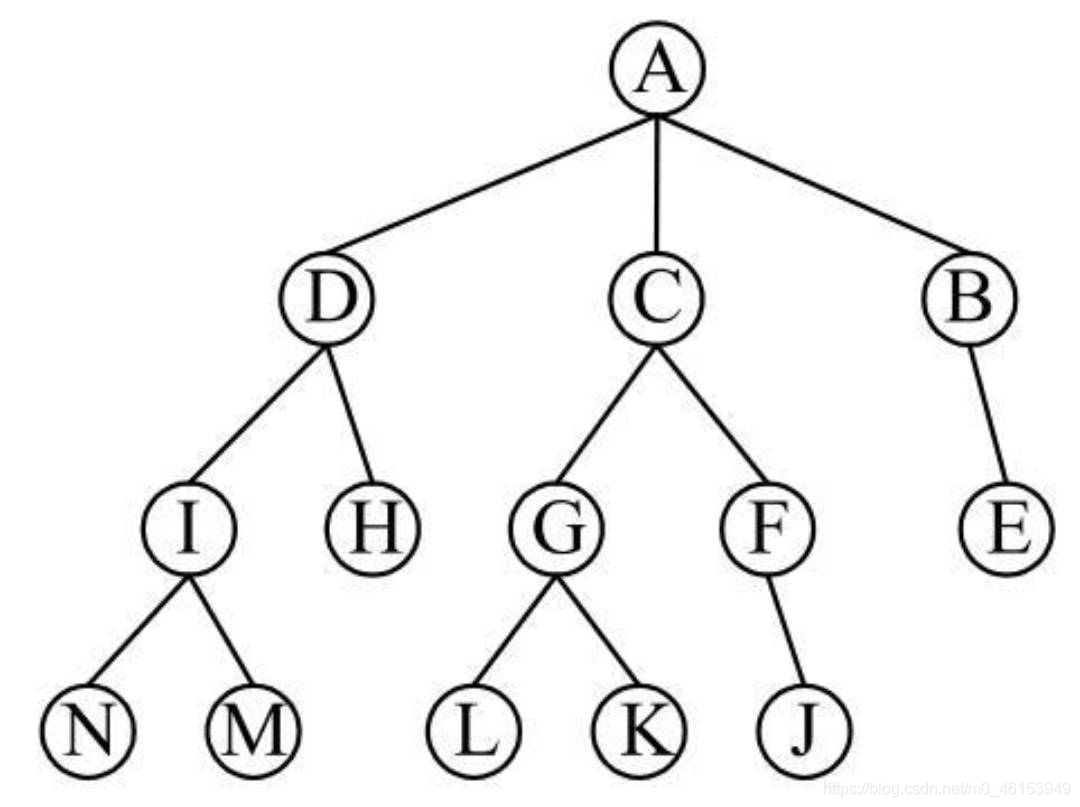
- 對照此圖,可以知道:
- A是樹的根結點;
- 根結點A有3個直接后繼結點B、C和D;
- 結點B、C、D只有一個直接前驅結點A,
4.2 樹的基本概念
- 父結點和子結點:每個結點的子樹的根稱為該結點的子結點,相應地,該結點被稱為子結點的父結點,
- 兄弟結點:具有同一父結點的結點稱為兄弟結點,
- 結點的度:一個結點所包含子樹的數量,
- 樹的度:是指該樹所有結點中最大的度,
- 葉結點:樹中度為零的結點稱為葉結點或終端結點,
- 分支結點:樹中度不為零的結點稱為分支結點或非終端結點,
- 結點的層數:結點的層數從樹根開始計算,根結點為第1層、依次向下為第2、3、…、n層,樹是一種層次結構,每個結點都處在一定的層次上,
- 樹的深度:樹中結點的最大層數稱為樹的深度,
- 有序樹:若樹中各結點的子樹(兄弟結點)是按一定次序從左向右安排的,稱為有序樹,
- 無序樹:若樹中各結點的子樹(兄弟結點)未按一定次序安排,稱為無序樹,
- 森林(forest):n(n>0)棵互不相交的樹的集合,
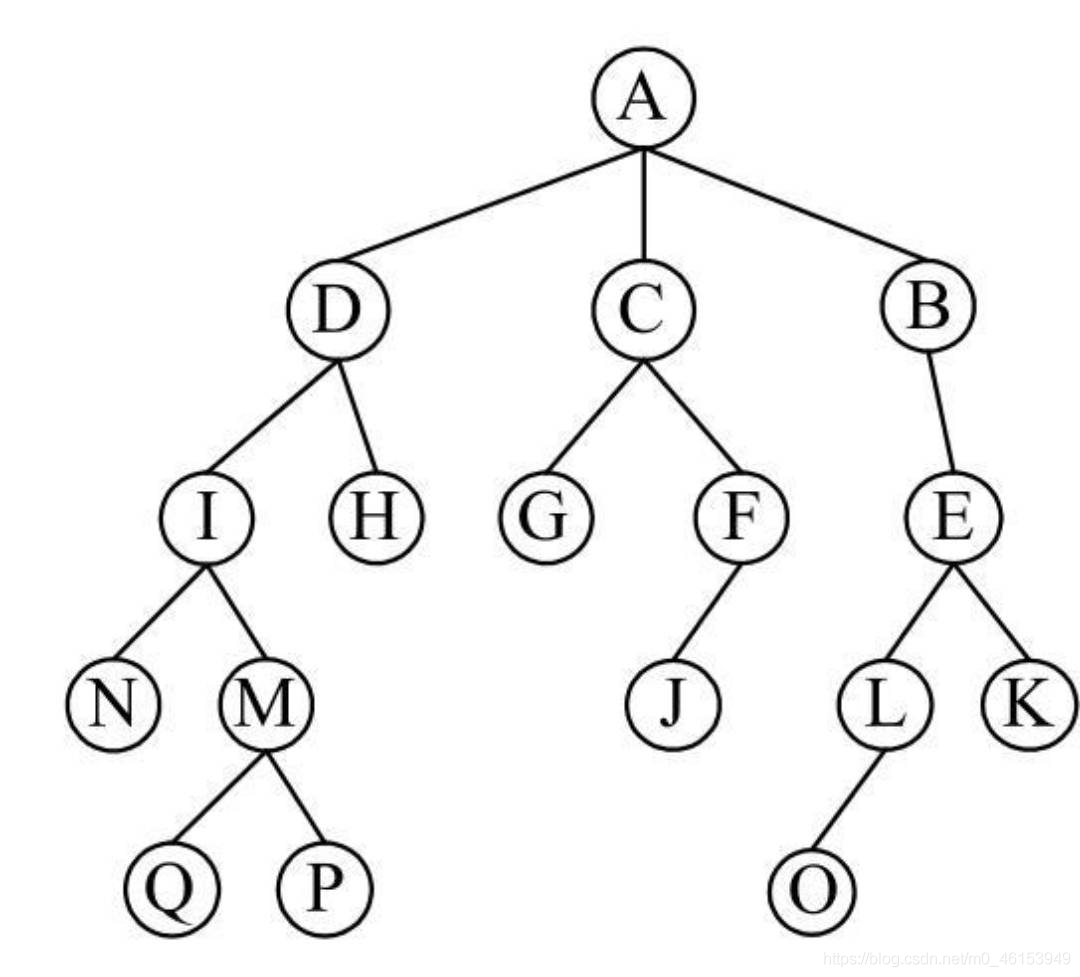
- 上圖展示了一個基本的樹結構:
- 其中,結點A為根結點,
- 結點A有3個子樹,因此,結點A的度為3,
- 同理,結點E有兩個子樹,結點E的度為2,
- 所有結點中,結點A的度為3最大,因此整個樹的度為3,
- 結點E是結點K和結點L的父結點,結點K和結點L是結點E的子結點,結點K和結點L之間為兄弟結點,
- 在這個樹結構中,結點G、結點H、結點K、結點J、結點N、結點O、結點P和結點Q都是葉結點,
- 其余的都是分支結點,整個樹的深度為4,
- 除去根結點A,留下的子樹就構成了一個森林,
樹結構一般采用層次括號法,層次括號法的基本規則如下:
- 根結點放入一對圓括號中,
- 根結點的子樹由左至右的順序放入括號中,
- 對子樹做上述相同的處理,
- 這樣,同層子樹與它的根結點用圓括號括起來,同層子樹之間用逗號隔開,最后用閉括號括起來按照這種方法,下圖所示的樹結構可以表示成如下形式:
- (A(B(E)),(C(F(J)),(G(K,L))),(D(H),(I(M,N))))
4.3 什么是二叉樹?
-
二叉樹是樹結構的一種特殊形式,它是n個結點的集合,每個結點最多只能有兩個子結點,
-
二叉樹的子樹仍然是二叉樹,
-
二叉樹一個結點上對應的兩個子樹分別稱為左子樹和右子樹,
-
由于子樹有左右之分,因此二叉樹是有序樹,
- 在普遍的樹結構中,結點的最大度數沒有限制,而二叉樹結點的最大度數為2,
- 另外,樹結構中沒有左子樹和右子樹的區分,而二叉樹中則有這個區別,
-
一個二叉樹結構也可以是空的,此時空二叉樹中沒有資料結點,也就是一個空集合,
-
如果二叉樹結構中僅包含一個結點,那么這也是一個二叉樹,樹根便是該結點自身,
-
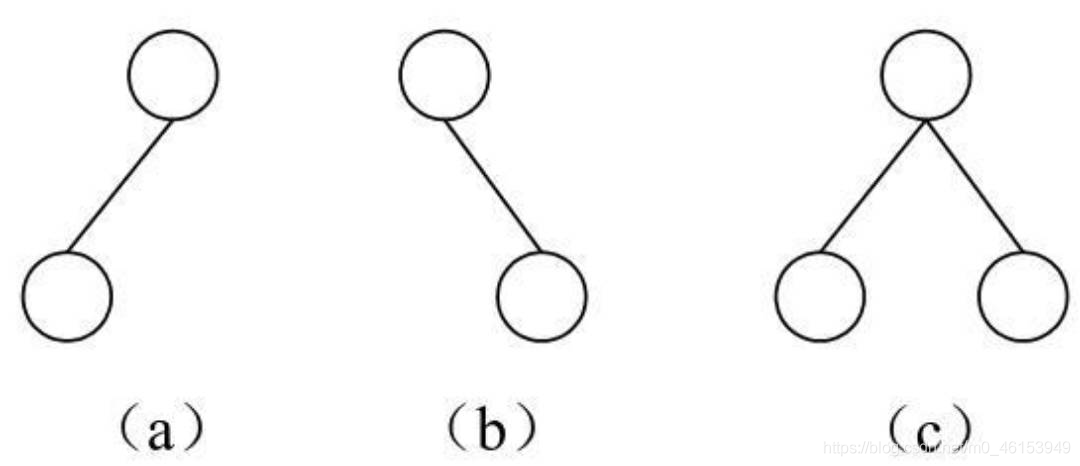
依照子樹的位置的個數,二叉樹還有如下圖所示的幾種形式:
- 圖(a)只有一個子結點且位于左子樹位置,右子樹位置為空;
- 圖(b)只有一個子結點且位于右子樹位置,左子樹位置為空;
- 圖?具有完整的兩個子結點,也就是左子樹和右子樹都存在,
對于一般的二叉樹來說,在樹結構中可能包含上述的各種形式,按照上述二叉樹的幾種形式來看,為了研究的方便,二叉樹還可以進一步細分為兩種特殊的型別,滿二叉樹和完全二叉樹,
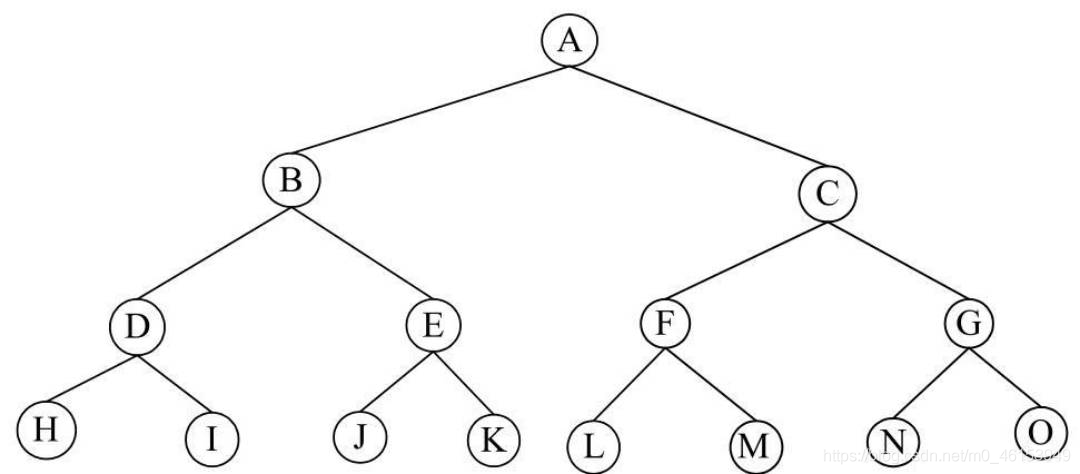
- 對于滿二叉樹,就是在二叉樹中除最下一層的葉結點外,每層的結點都有2個子結點,典型的滿二叉樹如下圖所示:
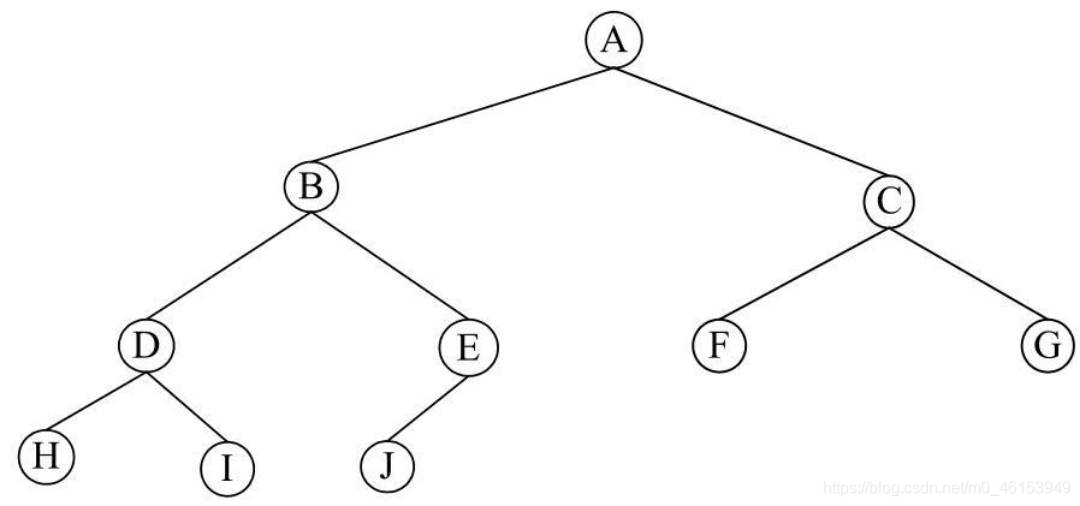
- 至于完全二叉樹,就是在二叉樹中除二叉樹最后一層外,其他各層的結點數都達到最大個數,且最后一層葉結點按照從左向右的順序連續存在,只缺最后一層右側若干結點,典型的完全二叉樹如圖2-17所示,
從上面的滿二叉樹和完全二叉樹的定義可以知道,滿二叉樹一定是完全二叉樹,而完全二叉樹不一定是滿二叉樹,因為沒有達到完全滿分支的結構,
- 對于完全二叉樹,如果樹中包含n個結點,假設這些結點按照順序方式存盤,對于任意一個結點m來說,具有如下性質:
- 如果m!=1,則結點m的父結點的編號為m/2,
- 如果2m≤n,則結點m的左子樹根結點的編號為2m;
- 若2m>n,則無左子樹,進一步也就沒有右子樹,
- 如果2m+1≤n,則結點m的右子樹根結點編號為2m+1;若2m+1>n,則無右子樹,
- 另外,對于該完全二叉樹來說,其深度為[log2n]+1,
樹結構可以分為順序存盤結構和鏈式存盤結構兩種,
- 順序存盤方式是最基本的資料存盤方式,
- 樹結構的順序存盤一般也是采用一維結構陣列來表示,關鍵是定義合適的次序來存放樹中各個層次的資料,
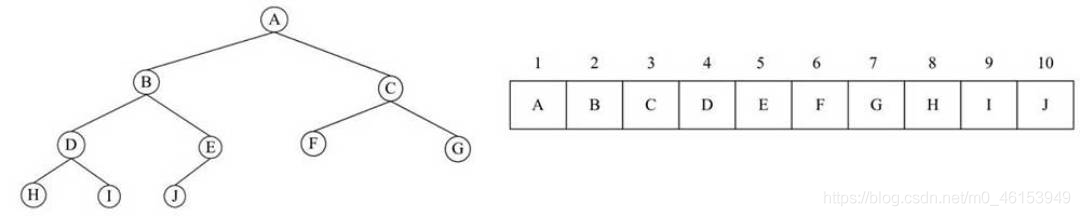
- 如上圖,這是一個完全二叉樹,
- 每個結點的資料為字符型別,
- 如果采用順序存盤方式,可以將其按層來存盤,
- 即先存盤根結點,然后從左至右依次存盤下一層結點的資料,直到所有的結點資料完全存盤,
- 右側即為這種存盤的形式,
- 上述完全二叉樹順序存盤結構的資料定義,可以采用如下形式:
#define MAXLen 100 // 最大結點數
typedef char DATA; // 元素型別
typedef DATA SeqBinTree[MAXLen];
SeqBinTree SBT; // 定義保存二叉樹陣列
- 各個結點之間的位置關系:
- 對于結點D,位于陣列的第4個位置,則其父結點的編號為4/2=2,也就是結點B,
- 結點D左子結點的編號為2×4=8,也就是結點H,
- 結點D右子結點的編號為2×4+1=9,也就是結點I,
- 對于非完全二叉樹,為了仍然可以使用的完全二叉樹的性質,往往將一個非完全二叉樹填充為一個完全二叉樹,
- 下圖(a)為一個典型的非完全二叉樹,將缺少的部分填上一個空的資料結點來構成圖(b)的完全二叉樹,
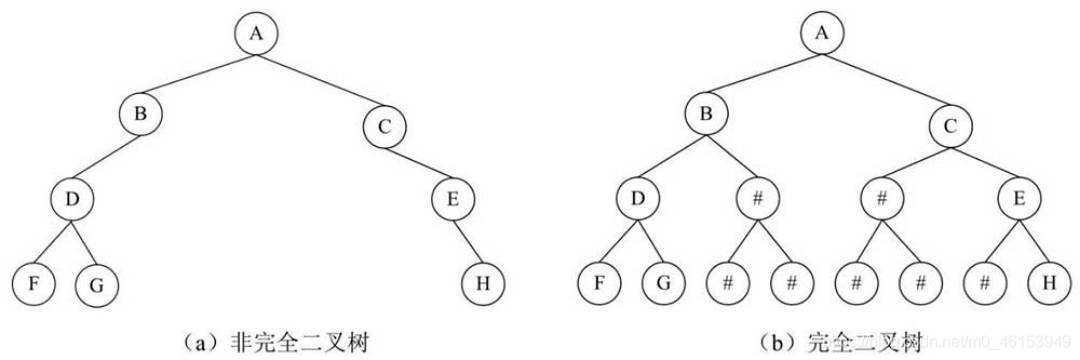
- 這樣,圖(b)再按照完全二叉樹的順序存盤方式來存盤,如下圖所示:

這種存盤方式最大的缺點,就是浪費存盤空間,這是因為其中填充了大量的無用資料,因此,順序存盤方式一般只適用于完全二叉樹的情況,對于更為一般的情況,建議采用鏈式存盤方式,
-
二叉樹的鏈式存盤
- 二叉樹的鏈式存盤結構包含結點元素以及分別指向左子樹和右子樹的指標,
- 典型的二叉樹的鏈式存盤結構如圖所示:

- 二叉樹的鏈式存盤結構定義示例代碼如下:
typedef struct ChainTree
{
DATA NodeData; // 元素資料
struct ChainTree *LSonNode; // 左子樹結點
struct ChainTree *RSonNode; // 右子樹結點
}ChinaTreeType;
ChinaTreeType *root = NULL; // 定義二叉樹根結點指標
- 為了后續計算的方便,也可以保存一個該結點的父結點的指標,
- 此時二叉樹的鏈式存盤結構包含結點元素、指向父結點的指標以及分別指向左子樹和右子樹的指標,
- 這種帶父結點的二叉樹鏈式存盤結構如圖所示:

- 帶父結點的二叉樹鏈式存盤結構定義示例代碼如下:
typedef struct ChainTree
{
DATA NodeData; // 元素資料
struct ChainTree *LSonNode; // 左子樹結點
struct ChainTree *RSonNode; // 右子樹結點
struct ChainTree *ParentNode; // 父結點指標
}ChinaTreeType;
ChinaTreeType *root = NULL; // 定義二叉樹根結點指標
4.4 二叉樹的程式設計
- 準備作業
- 準備需要使用的變數和資料結構,
- 具體代碼:
#define MAXLEN 100 // 最大長度
typedef char DATA; // 元素型別
typedef struct CBT
{
DATA data; // 元素資料
struct CBT* left; // 左子樹結點指標
struct CBT* right; // 右子樹結點指標
}CBTType;
- 初始化二叉樹
- 將一個結點設定為二叉樹的根結點,
- 具體代碼:
CBTType* InitTree() // 初始化二叉樹的根結點
{
CBTType* node;
if (node = (CBTType*)malloc(sizeof(CBTType))) // 申請記憶體
{
printf("請輸入一個根結點的資料:\n");
scanf("%s", &node->data);
node->left = NULL;
node->right = NULL;
if (node != NULL) // 如果根結點不為空
{
return node;
}
else {
return NULL;
}
}
return NULL;
}
- 查找結點
- 遍歷二叉樹中的每一個結點,逐個比較,當找到目標資料結點時回傳該資料的結點的指標,
- 具體代碼:
CBTType *TreeFindNode(CBTType *treeNode, DATA data) // 查找結點
{
CBTType *ptr;
if (treeNode == NULL)
{
return NULL;
}
else {
if (treeNode->data == data)
{
return treeNode;
}
else {
if (ptr = TreeFindNode(treeNode->left, data)) // 分別向左右子樹遞回查找
{
return ptr;
}
else if (ptr = TreeFindNode(treeNode->right, data))
{
return ptr;
}
else {
return NULL;
}
}
}
}
- 添加結點
- 在二叉樹中添加結點資料,指定其父結點,以及添加的結點是左子樹還是右子樹,
- 具體代碼:
void AddTreeNode(CBTType* treeNode) // 添加結點
{
CBTType *pnode, *parent;
DATA data;
char menusel;
if (pnode = (CBTType *)malloc(sizeof(CBTType))) // 分配記憶體
{
printf("輸入二叉樹的結點資料:\n");
fflush(stdin); // 清空輸入緩沖區
scanf("%s", &pnode->data);
pnode->left = NULL; // 設定左子樹為空
pnode->right = NULL; // 設定右子樹為空
printf("輸入該結點的父結點資料:");
fflush(stdin); // 清空輸入緩沖區
scanf("%s", &data);
parent = TreeFindNode(treeNode, data); // 查找指定資料的結點
if (!parent) // 如果未找到
{
printf("未找到該資料的父結點!\n");
free(pnode); // 釋放創建的結點記憶體
return;
}
printf("1.添加該結點到左子樹結點.\n2.添加該節點到右子樹.\n");
do {
menusel = getch(); // 輸入選擇項
menusel -= '0';
if (menusel == 1 || menusel == 2)
{
if (parent == NULL)
{
printf("不存在父結點,請先設定父結點!\n");
}
else {
switch (menusel)
{
case 1: // 添加到左結點
if (parent->left) // 左子樹不為空
{
printf("左子樹結點不為空!\n");
}
else {
parent->left = pnode;
}
break;
case 2: // 添加到右結點
if (parent->right) // 右子樹不為空
{
printf("右子樹結點不為空!\n");
}
else {
parent->right = pnode;
}
break;
default:
printf("輸入了無效引數!\n");
}
}
}
} while (menusel != 1 && menusel != 2);
}
}
- 獲取左子樹
- 回傳當前結點的左子樹的值,
- 具體代碼:
CBTType *TreeLeftNode(CBTType *treeNode) // 獲取左子樹
{
if (treeNode)
{
return treeNode->left; // 回傳值
}
else {
return NULL;
}
}
- 獲取右子樹
- 回傳當前結點的右子樹的值,
- 具體代碼:
CBTType *TreeRightNode(CBTType *treeNode) // 獲取右子樹
{
if (treeNode)
{
return treeNode->right; // 回傳值
}
else {
return NULL;
}
}
- 判斷空樹
- 判斷二叉樹結構是否為空,
- 具體代碼:
CBTType *TreeIsEmpty(CBTType *treeNode) // 判斷空樹
{
if (treeNode)
{
return 0; // 回傳值
}
else {
return 1;
}
}
- 計算二叉樹的深度
- 計算二叉樹中結點的最大層數,
- 具體代碼:
int TreeDepth(CBTType *treeNode) // 計算二叉樹深度
{
int depleft, depright;
if (treeNode == NULL) {
return 0;
}
else {
depleft = TreeDepth(treeNode->left); // 左子樹深度
depright = TreeDepth(treeNode->right); // 右子樹深度
if (depleft > depright)
{
return depleft + 1;
}
else {
return depright + 1;
}
}
}
- 清空二叉樹
- 將二叉樹變為空樹,用遞回實作,
- 具體代碼:
void ClearTree(CBTType *treeNode) // 清空二叉樹
{
if (treeNode)
{
ClearTree(treeNode->left); // 清空左子樹
ClearTree(treeNode->right); // 清空右子樹
free(treeNode); // 釋放當前結點所占記憶體
treeNode = NULL;
}
}
- 顯示結點資料
- 顯示當前結點的資料內容,
- 具體代碼:
void TreeNodeData(CBTType *p) // 顯示結點資料
{
printf("%c ", p->data); // 輸出結點資料
}
- 按層遍歷二叉樹
- 逐個查找二叉樹中的所有結點,
- 由于二叉樹是一種層次結構,所以,可以按層來遍歷整個二叉樹,
- 按層遍歷:先從第1層(根結點)進入佇列,再從第1根結點的左右子樹(第2層)進入佇列……這樣回圈處理,即可逐層遍歷,
- 具體代碼:
void LevelTree(CBTType *treeNode, void(*TreeNodeData)(CBTType *p)) // 按層遍歷
{
CBTType *p;
CBTType *q[MAXLEN]; //定義順序堆疊
int head = 0, tail = 0;
if (treeNode) // 如果隊首指標不為空
{
tail = (tail + 1) % MAXLEN; // 計算回圈佇列隊尾序號
q[tail] = treeNode; // 將二叉樹根指標進隊
}
while (head != tail) // 佇列不為空,進行回圈
{
head = (head + 1) % MAXLEN; // 計算回圈佇列隊首序號
p = q[head]; // 獲取隊首元素
TreeNodeData(p); // 處理隊首元素
if (p->left != NULL) // 如果結點存在左子樹
{
tail = (tail + 1) % MAXLEN; // 計算回圈佇列隊尾序號
q[tail] = p->left; // 將左子樹指標進隊
}
if (p->right != NULL) // 如果結點存在右子樹
{
tail = (tail + 1) % MAXLEN; // 計算回圈佇列隊尾序號
q[tail] = p->right; // 將右子樹指標進隊
}
}
}
- 按遞回遍歷二叉樹
- 按遞回遍歷可分為先序遍歷、中序遍歷、后序遍歷,
- 先序遍歷:即先訪問根結點,再按先序遍歷左子樹,最后按先序遍歷右子樹,先序遍歷也稱為先根次序遍歷,簡稱為DLR遍歷,
- 中序遍歷:即先按中序遍歷左子樹,再訪問根結點,最后按中序遍歷右子樹,中序遍歷也稱為中根次序遍歷,簡稱為LDR遍歷,
- 后序遍歷:即先按后序遍歷左子樹,再按后序遍歷右子樹,最后訪問根結點,后序遍歷也稱為后根次數遍歷,簡稱為LRD遍歷,
- 具體代碼:
void DLRTree(CBTType *treeNode, void(*TreeNodeData)(CBTType *p)) // 先序遍歷
{
if (treeNode)
{
TreeNodeData(treeNode); // 顯示結點資料
DLRTree(treeNode->left, TreeNodeData); // 先序遍歷左子樹
DLRTree(treeNode->right, TreeNodeData); // 先序遍歷右子樹
}
}
void LDRTree(CBTType *treeNode, void(*TreeNodeData)(CBTType *p)) // 中序遍歷
{
if (treeNode)
{
LDRTree(treeNode->left, TreeNodeData); // 中序遍歷左子樹
TreeNodeData(treeNode); // 顯示結點資料
LDRTree(treeNode->right, TreeNodeData); // 中序遍歷右子樹
}
}
void LRDTree(CBTType *treeNode, void(*TreeNodeData)(CBTType *p)) // 后序遍歷
{
if (treeNode)
{
LRDTree(treeNode->left, TreeNodeData); // 后序遍歷左子樹
LRDTree(treeNode->right, TreeNodeData); // 后序遍歷右子樹
TreeNodeData(treeNode); // 顯示結點資料
}
}
- 案例:二叉樹的各種操作及四種遍歷
- 具體代碼:
#include <stdio.h>
#include <stdlib.h>
#include <conio.h>
#define MAXLEN 100 // 最大長度
typedef char DATA; // 元素型別
typedef struct CBT
{
DATA data; // 元素資料
struct CBT* left; // 左子樹結點指標
struct CBT* right; // 右子樹結點指標
}CBTType;
CBTType* InitTree() // 初始化二叉樹的根結點
{
CBTType* node;
if (node = (CBTType*)malloc(sizeof(CBTType))) // 申請記憶體
{
printf("請輸入一個根結點的資料:\n");
scanf("%s", &node->data);
node->left = NULL;
node->right = NULL;
if (node != NULL) // 如果根結點不為空
{
return node;
}
else {
return NULL;
}
}
return NULL;
}
CBTType *TreeFindNode(CBTType *treeNode, DATA data) // 查找結點
{
CBTType *ptr;
if (treeNode == NULL)
{
return NULL;
}
else {
if (treeNode->data == data)
{
return treeNode;
}
else {
if (ptr = TreeFindNode(treeNode->left, data)) // 分別向左右子樹遞回查找
{
return ptr;
}
else if (ptr = TreeFindNode(treeNode->right, data))
{
return ptr;
}
else {
return NULL;
}
}
}
}
void AddTreeNode(CBTType* treeNode) // 添加結點
{
CBTType *pnode, *parent;
DATA data;
char menusel;
if (pnode = (CBTType *)malloc(sizeof(CBTType))) // 分配記憶體
{
printf("輸入二叉樹的結點資料:\n");
fflush(stdin); // 清空輸入緩沖區
scanf("%s", &pnode->data);
pnode->left = NULL; // 設定左子樹為空
pnode->right = NULL; // 設定右子樹為空
printf("輸入該結點的父結點資料:");
fflush(stdin); // 清空輸入緩沖區
scanf("%s", &data);
parent = TreeFindNode(treeNode, data); // 查找指定資料的結點
if (!parent) // 如果未找到
{
printf("未找到該資料的父結點!\n");
free(pnode); // 釋放創建的結點記憶體
return;
}
printf("1.添加該結點到左子樹結點.\n2.添加該節點到右子樹.\n");
do {
menusel = getch(); // 輸入選擇項
menusel -= '0';
if (menusel == 1 || menusel == 2)
{
if (parent == NULL)
{
printf("不存在父結點,請先設定父結點!\n");
}
else {
switch (menusel)
{
case 1: // 添加到左結點
if (parent->left) // 左子樹不為空
{
printf("左子樹結點不為空!\n");
}
else {
parent->left = pnode;
}
break;
case 2: // 添加到右結點
if (parent->right) // 右子樹不為空
{
printf("右子樹結點不為空!\n");
}
else {
parent->right = pnode;
}
break;
default:
printf("輸入了無效引數!\n");
}
}
}
} while (menusel != 1 && menusel != 2);
}
}
CBTType *TreeLeftNode(CBTType *treeNode) // 獲取左子樹
{
if (treeNode)
{
return treeNode->left; // 回傳值
}
else {
return NULL;
}
}
CBTType *TreeRightNode(CBTType *treeNode) // 獲取右子樹
{
if (treeNode)
{
return treeNode->right; // 回傳值
}
else {
return NULL;
}
}
CBTType *TreeIsEmpty(CBTType *treeNode) // 判斷空樹
{
if (treeNode)
{
return 0; // 回傳值
}
else {
return 1;
}
}
int TreeDepth(CBTType *treeNode) // 計算二叉樹深度
{
int depleft, depright;
if (treeNode == NULL) {
return 0;
}
else {
depleft = TreeDepth(treeNode->left); // 左子樹深度
depright = TreeDepth(treeNode->right); // 右子樹深度
if (depleft > depright)
{
return depleft + 1;
}
else {
return depright + 1;
}
}
}
void ClearTree(CBTType *treeNode) // 清空二叉樹
{
if (treeNode)
{
ClearTree(treeNode->left); // 清空左子樹
ClearTree(treeNode->right); // 清空右子樹
free(treeNode); // 釋放當前結點所占記憶體
treeNode = NULL;
}
}
void TreeNodeData(CBTType *p) // 顯示結點資料
{
printf("%c ", p->data); // 輸出結點資料
}
void LevelTree(CBTType *treeNode, void(*TreeNodeData)(CBTType *p)) // 按層遍歷
{
CBTType *p;
CBTType *q[MAXLEN]; //定義順序堆疊
int head = 0, tail = 0;
if (treeNode) // 如果隊首指標不為空
{
tail = (tail + 1) % MAXLEN; // 計算回圈佇列隊尾序號
q[tail] = treeNode; // 將二叉樹根指標進隊
}
while (head != tail) // 佇列不為空,進行回圈
{
head = (head + 1) % MAXLEN; // 計算回圈佇列隊首序號
p = q[head]; // 獲取隊首元素
TreeNodeData(p); // 處理隊首元素
if (p->left != NULL) // 如果結點存在左子樹
{
tail = (tail + 1) % MAXLEN; // 計算回圈佇列隊尾序號
q[tail] = p->left; // 將左子樹指標進隊
}
if (p->right != NULL) // 如果結點存在右子樹
{
tail = (tail + 1) % MAXLEN; // 計算回圈佇列隊尾序號
q[tail] = p->right; // 將右子樹指標進隊
}
}
}
void DLRTree(CBTType *treeNode, void(*TreeNodeData)(CBTType *p)) // 先序遍歷
{
if (treeNode)
{
TreeNodeData(treeNode); // 顯示結點資料
DLRTree(treeNode->left, TreeNodeData); // 先序遍歷左子樹
DLRTree(treeNode->right, TreeNodeData); // 先序遍歷右子樹
}
}
void LDRTree(CBTType *treeNode, void(*TreeNodeData)(CBTType *p)) // 中序遍歷
{
if (treeNode)
{
LDRTree(treeNode->left, TreeNodeData); // 中序遍歷左子樹
TreeNodeData(treeNode); // 顯示結點資料
LDRTree(treeNode->right, TreeNodeData); // 中序遍歷右子樹
}
}
void LRDTree(CBTType *treeNode, void(*TreeNodeData)(CBTType *p)) // 后序遍歷
{
if (treeNode)
{
LRDTree(treeNode->left, TreeNodeData); // 后序遍歷左子樹
LRDTree(treeNode->right, TreeNodeData); // 后序遍歷右子樹
TreeNodeData(treeNode); // 顯示結點資料
}
}
void main()
{
CBTType *root = NULL; // root為指向二叉樹根結點的指標
char menusel;
void(*TreeNodeDatal)(); // 指向函式的指標
TreeNodeDatal = TreeNodeData; // 指向具體操作的函式
root = InitTree(); // 設定根元素
do { // 添加結點
printf("請選擇選單添加二叉樹的結點!\n");
printf("0.退出\t");
printf("1.添加二叉樹的結點!\n");
menusel = getch();
switch (menusel)
{
case '1':
AddTreeNode(root); // 添加結點
break;
case '0':
break;
default:
break;
}
} while (menusel != '0');
// 遍歷二叉樹
do {
printf("選擇二叉樹遍歷序號,輸入0表示退出:\n"); // 顯示選單
printf("1.先序遍歷DLR\t");
printf("2.中序遍歷LDR\t");
printf("3.后序遍歷LRD\t");
printf("4.按層遍歷\n");
menusel = getch();
switch (menusel)
{
case '0':
break;
case '1': // 先序遍歷
printf("\n先序遍歷結果:");
DLRTree(root, TreeNodeDatal);
printf("\n");
break;
case '2': // 中序遍歷
printf("\n中序遍歷結果:");
LDRTree(root, TreeNodeDatal);
printf("\n");
break;
case '3': // 后序遍歷
printf("\n后序遍歷結果:");
LRDTree(root, TreeNodeDatal);
printf("\n");
break;
case '4': // 按層遍歷
printf("\n按層遍歷結果:");
LevelTree(root, TreeNodeDatal);
printf("\n");
break;
default:
break;
}
} while (menusel != '0');
printf("\n二叉樹深度為:%d\n", TreeDepth(root)); // 二叉樹深度
ClearTree(root); // 清空二叉樹
root = NULL;
}
5、 圖結構
圖(Graph)結構也是一種非線性資料結構,圖結構在實際生活中具有非常多的例子,例如,通信網路、交通網路、人際關系網路等都可以歸結為圖結構,
5.1 什么是圖?
- 上文的樹結構的一個基本特點:資料元素之間具有層次關系,每一層的元素可以和多個下層元素關聯,但是只能和一個上層元素關聯,如果把這個規則進一步擴展,也就是說,每個資料元素之間可以任意關聯,這就構成了一個圖結構,
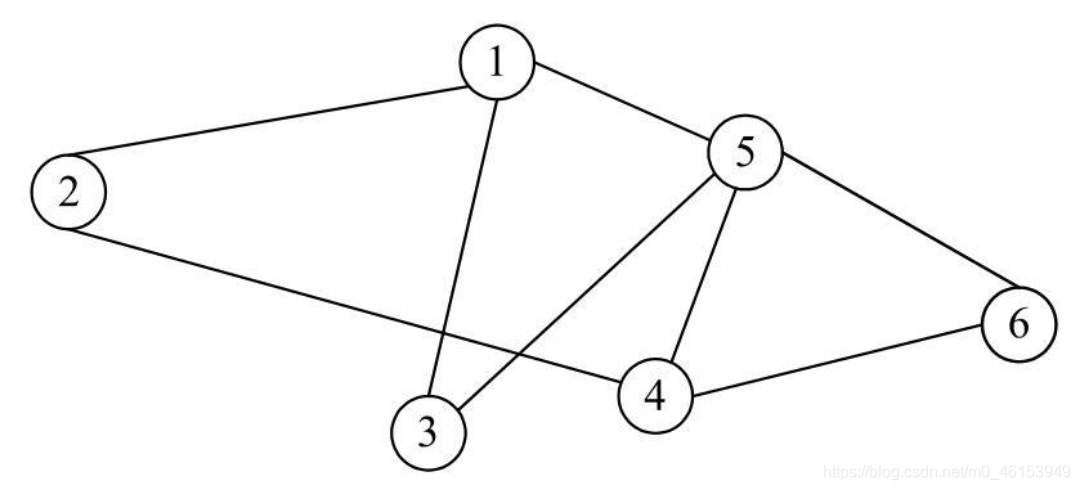
-
一個典型的圖結構包括如下兩個部分:
- 頂點(Vertex):圖中的資料元素,
- 邊(Edge):圖中連接這些頂點的線,
-
所有的頂點構成一個頂點集合,所有的邊構成邊集合,一個完整的圖結構就是由頂點集合和邊集合組成,圖結構在數學上一般記為如下所示的形式:
G=(V,E) 或者 G=(V(G),E(G)) -
其中,V(G)表示圖結構中所有頂點的集合,頂點可以用不同的數字或者字母來表示,E(G)是圖結構中所有邊的集合,每條邊由所連接的兩個頂點表示,
注意:圖結構中頂點集合V(G)必須為非空,即必須包含一個頂點,而圖結構中邊集合E(G)可以為空,此時表示沒有邊,
-
例如,對于上文所示的圖結構,對應的頂點集合和邊集合如下:
V(G)={V1,V2,V3,V4,V5,V6} E(G)={(V1,V2),(V1,V3),(V1,V5),(V2,V4),(V3,V5),(V4,V5),(V4,V6),(V5,V6)}
5.2 圖的基本概念
-
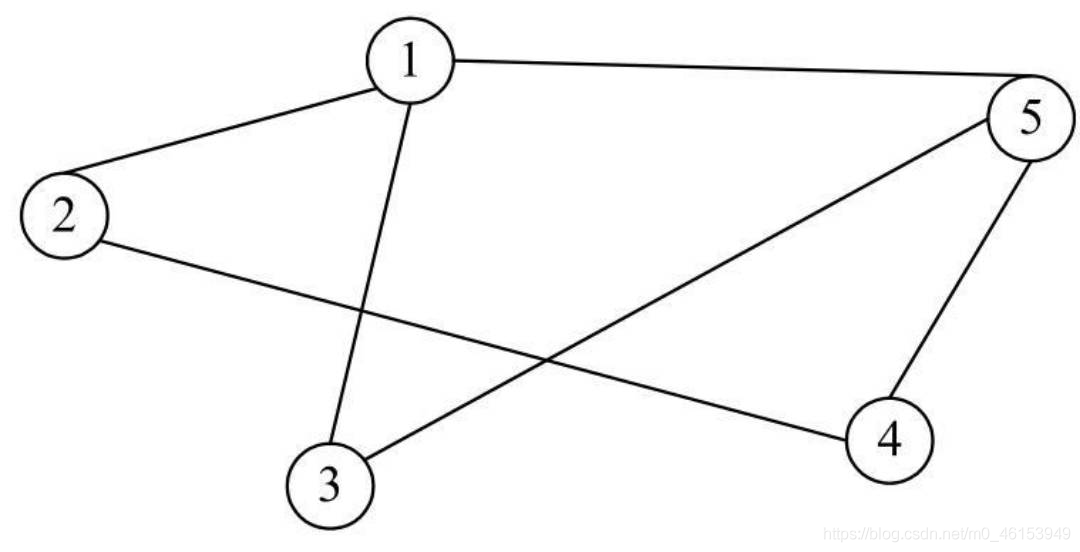
無向圖:如果一個圖結構中所有的邊都沒有方向性,這種圖便被稱為無向圖,
-
由于無向圖中的邊沒有方向性,在表示邊時對兩個頂點的順序沒有要求,例如頂點V1和頂點V5之間的邊,可以表示為(V1,V5),也可以表示為(V5,V1),
-
即下圖對應的頂點集合和邊集合如下:
V(G)={V1,V2,V3,V4,V5} E(G)={(V1,V2),(V1,V5),(V2,V4),(V3,V5),(V4,V5),(V1,V3)}
-
-
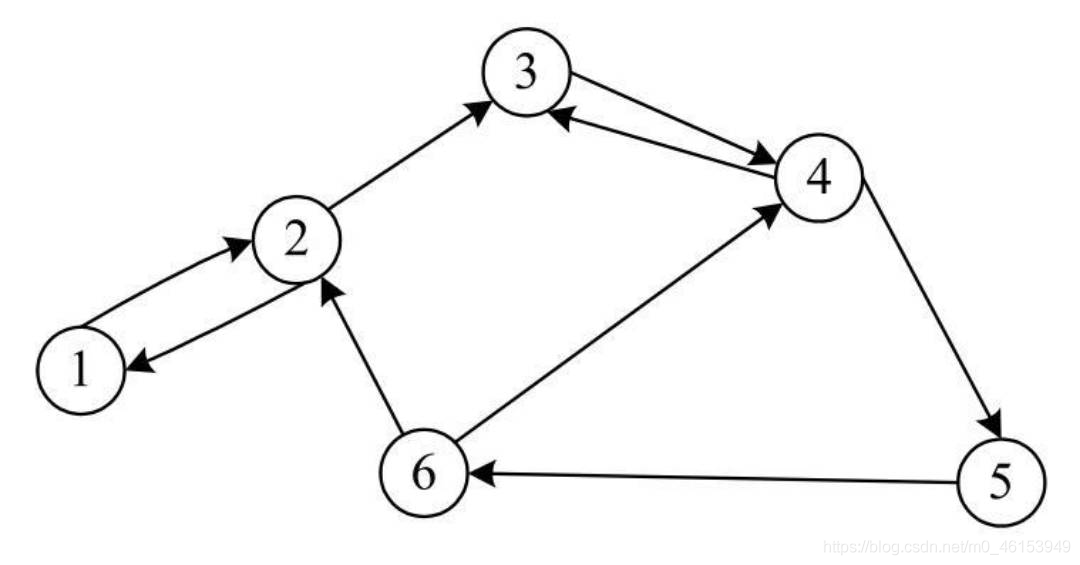
有向圖:如果一個圖結構中邊是有方向性的,這種圖便被稱為有向圖,
-
由于有向圖中的邊有方向性,所以在表示邊時對兩個頂點的順序有所要求,
-
為了與無向圖區分,這里采用尖括號表示有向邊,
-
例如,<V3,V4>表示從頂點V3到頂點V4的一條邊,而<V4,V3>表示從頂點V4到頂點V3的一條邊,<V3,V4>和<V4,V3>表示的是兩條不同的邊,
-
即下圖對應的頂點集合和邊集合如下:
V(G)={V1,V2,V3,V4,V5,V6} E(G)={<V1,V2>,<V2,V1>,<V2,V3>,<V3,V4>,<V4,V3>,<V4,V5>,<V5,V6>,<V6,V4>,<V6,V2>}
-
- 簡單圖:①不存在重復邊;②不存在頂點到自身的邊,
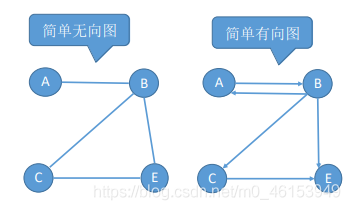
- 多重圖:圖G中某兩個結點之間的邊數多于 一條,又允許頂點通過同一條邊和自己關聯, 則G為多重圖,
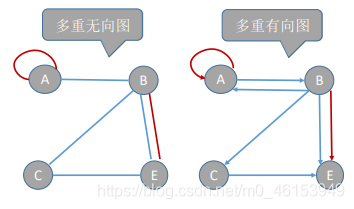
-
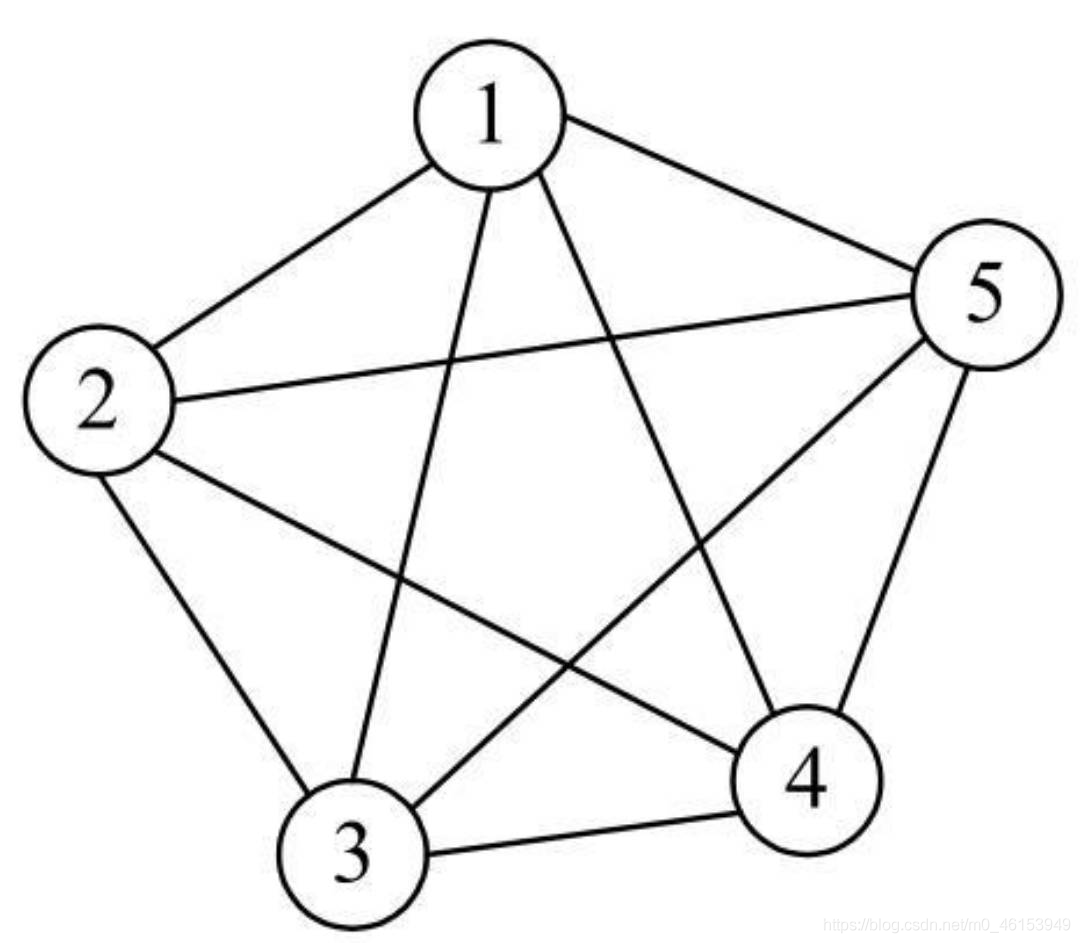
無向完全圖:在無向圖中,每兩個頂點之間都存在一條邊,
- 對于1個包含n個頂點的無向完全圖,其總的邊數為n(n-1)/2,
- 無向完全圖如下:
-
有向完全圖:在有向圖中,每兩個頂點之間都存在方向相反的兩條邊,
- 對于一個包含n個頂點的有向完全圖,其總的邊數為n(n-1),是無向完全圖的兩倍,因為每兩個頂點之間需要兩條邊,
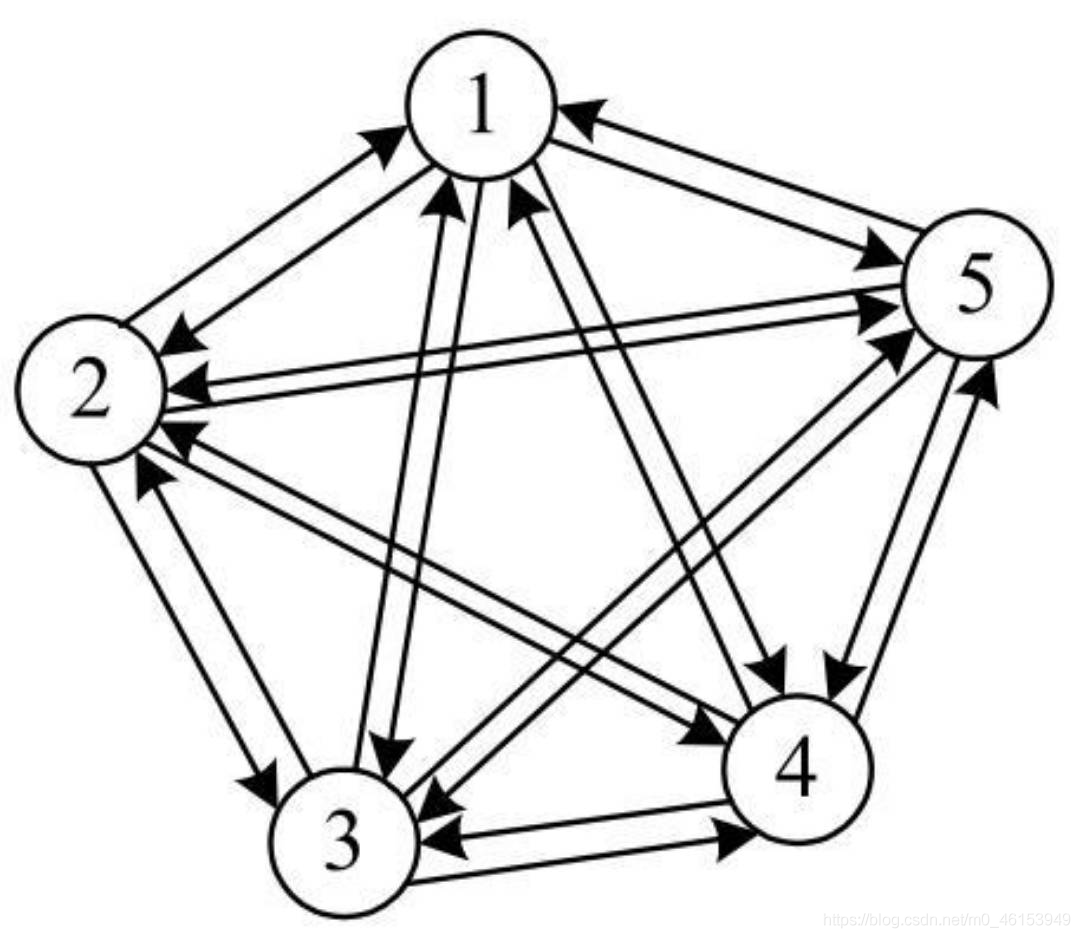
-
頂點的度、入度和出度
- 連接頂點的邊的數量稱為頂點的度,
- 頂點的度在有向圖和無向圖中具有不同的意義,
- 對于無向圖,一個頂點V的度比較簡單,是連接該頂點的邊的數量,記為D(V),例如,下圖所示的無向圖中,頂點V4的度為2,而V5的度為3,
- 對于有向圖,根據連接頂點V的邊的方向性,一個頂點的度有入度和出度之分,
- 入度是以該頂點為端點的入邊數量,記為ID(V),
- 出度是以該頂點為端點的出邊數量,記為OD(V),
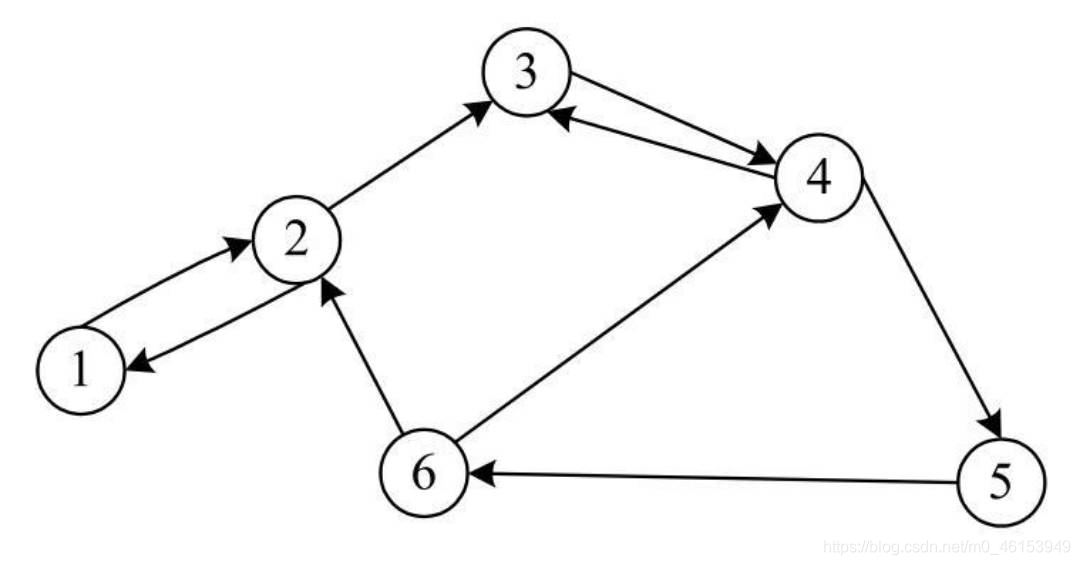
- 在有向圖中,一個頂點V的度便是入度和出度之和,即D(V)=ID(V)+OD(V),
- 例如,下圖所示的有向圖中,頂點V3的入度為2,出度為1,因此,頂點V3的度為3,
-
鄰接頂點:圖結構中一條邊的兩個頂點,
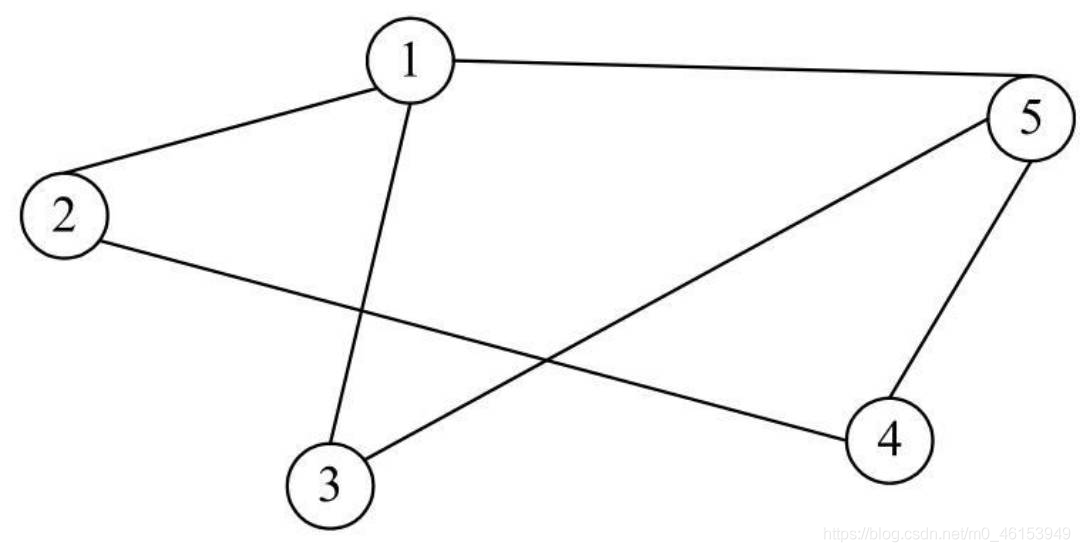
- 對于無向圖,鄰接頂點比較簡單,例如,在下所示的無向圖中,頂點V1、V5互為鄰接頂點,另外,頂點V1的鄰接頂點有頂點V2、頂點V3和頂點V5,
- 對于有向圖則稍微復雜一些,根據連接頂點V的邊的方向性,兩個頂點分別被稱為起始頂點(起點或始點)和結束頂點(終點),有向圖的鄰接頂點可分為兩類,
- 入邊鄰接頂點:連接該頂點的邊中的起始頂點,例如,對于組成<V1,V2>這條邊的兩個頂點,V1是V2的入邊鄰接頂點,
- 出邊鄰接頂點:連接該頂點的邊中的結束頂點,例如,對于組成<V1,V2>這條邊的兩個頂點,V2是V1的出邊鄰接頂點,
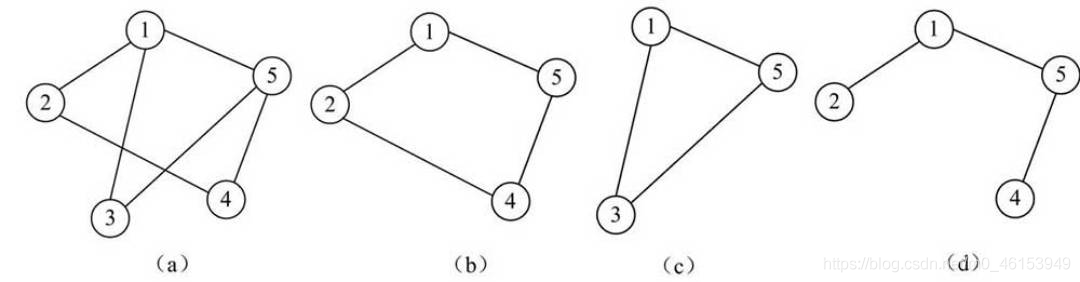
- 子圖:子圖的概念類似于子集合,由于一個完整的圖結構包括所有的頂點和邊,因此任意一個子圖的頂點和邊都應該是完整圖結構的子集合,
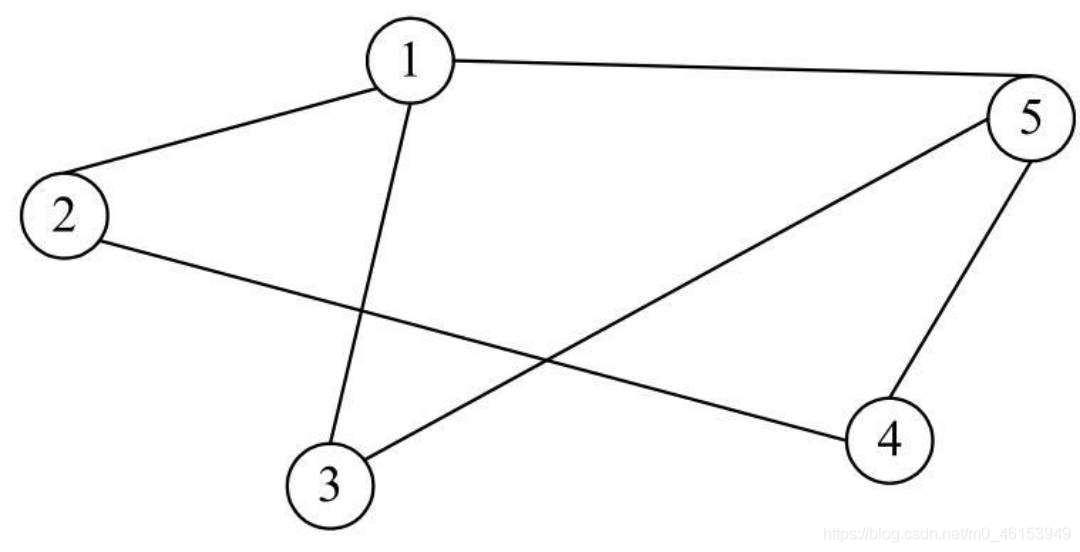
- 例如,下圖中的圖(a)為一個無向圖結構,圖(b)、圖(c)和圖(d)均為圖(a)的子圖,
- 這里需要強調的是,只有頂點集合是子集的,或者只有邊集合是子集的,都不是子圖,
- 路徑、路徑長度和回路:
- 路徑就是圖結構中兩個頂點之間的連線,路徑上邊的數量稱之為路徑長度,
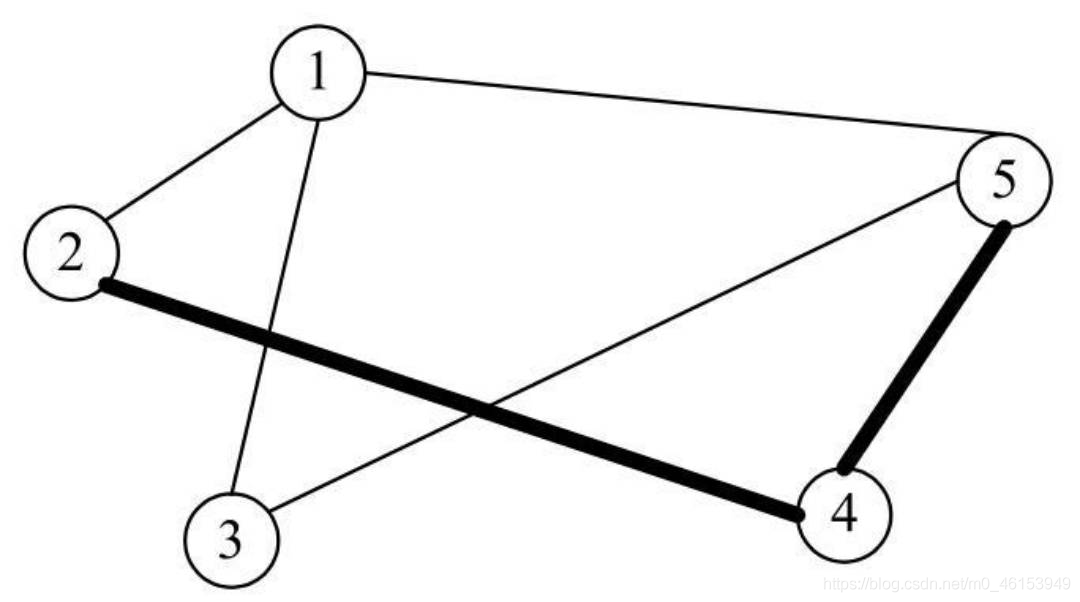
- 具體如下圖,粗線部分顯示的是頂點V5到V2之間的一條路徑,這條路徑途經的頂點為V4,途經的邊依次為(V5,V4)、(V4,V2),路徑長度為2,
- 同樣,也可以在該圖中找到頂點V5到V2之間的其他路徑,分別如下所示:
- 路徑(V5,V1)、(V1,V2),途經頂點V1,路徑長度為2,
- 路徑(V5,V3)、(V3,V1)、(V1,V2),途經頂點V1和V3,路徑長度為3,
- 圖結構中的路徑還可以細分為如下幾種形式:
- 簡單路徑:在圖結構中,如果一條路徑上頂點不重復出現,稱為簡單路徑,
- 環:在圖結構中,如果路徑的第一個頂點和最后一個頂點相同,稱為環,有時也稱為回路,
- 簡單回路:在圖結構中,如果除第一個頂點和最后一個頂點相同外,其余各頂點都不重復的回路稱為簡單回路,
-
連通、連通圖、連通分量:
-
如果圖結構中兩個頂點之間有路徑,則稱這兩個路徑是連通的,
-
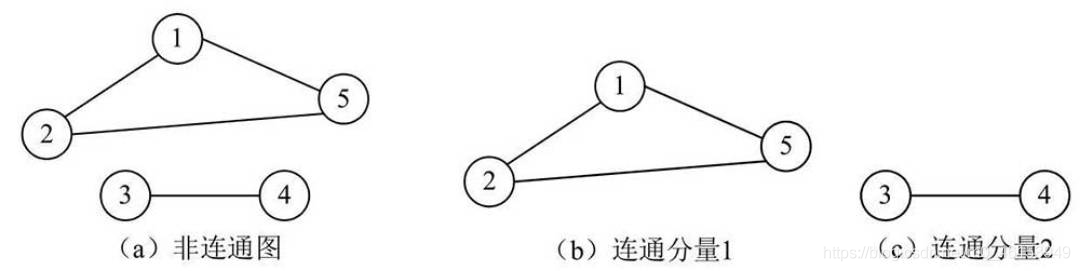
如果無向圖中任意兩個頂點都是連通的,那么這個圖便稱為連通圖,
-
如果無向圖中包含兩個頂點是不連通的,那么這個圖便稱為非連通圖,
-
無向圖的極大連通子圖稱為該圖的連通分量,
-
對于一個連通圖,其連通分量有且只有一個,就是該連通圖自身,而對于一個非連通圖,則有可能存在多個連通分量,
-
對于n個頂點的無向圖G, 若G是連通圖,則最少有 n-1 條邊 若G是非連通圖,則最多可能有
C n ? 1 2 C_{n-1}^{2} Cn?12?
條邊, -
例如,在下圖中,圖(a)為一個非連通圖,因為頂點V2和頂點V3之間沒有路徑,這個非連通圖中的連通分量包括兩個,分別為圖(b)和圖(c),
-
-
- 強連通圖、強連通分量:
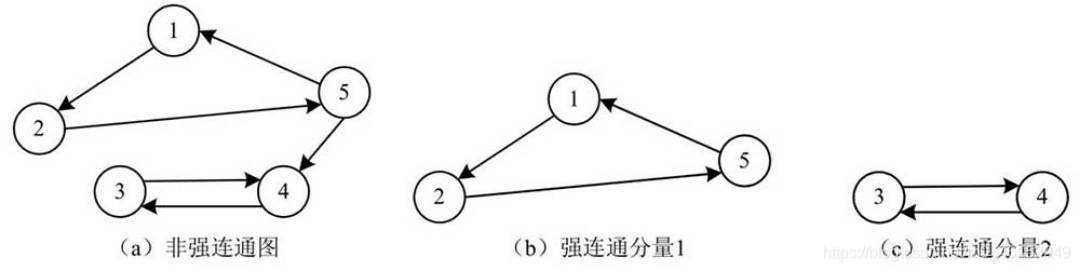
- 如果有向圖中任意兩個頂點都是連通的,則稱該圖為強連通圖,
- 如果有向圖中包含兩個頂點不是連通的,則稱該圖為非強連通圖,
- 有向圖的極大強連通子圖稱為該圖的強連通分量,
- 極大強連通子圖:子圖必須強連通,同時 保留盡可能多的邊,
- 強連通圖有且只有一個強連通分量,那就是該圖自身,而對于一個非強連通圖,則有可能存在多個強連通分量,
- 對于n個頂點的有向圖G, 若G是強連通圖,則最少有 n 條邊(形成回路),
- 例如,在下圖中,圖(a)為一個非強連通圖,因為其中頂點V2和頂點V3之間沒有路徑,這個非強連通圖中的強連通分量包括兩個,分別為圖(b)和圖(c),
-
邊的權、網:
- 邊的權:在一個圖中,每條邊都可以標上具有某種含義的數值,該數值稱為該邊的權值,
-
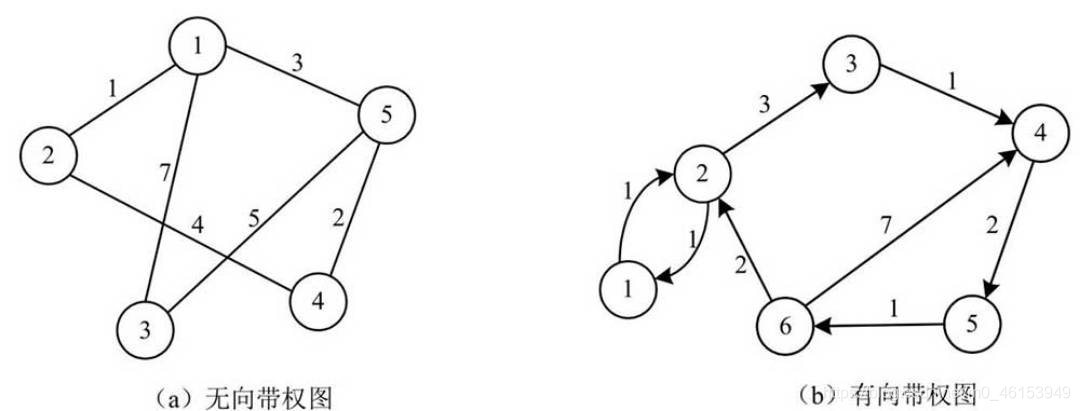
帶權圖/網:邊上帶有權值的圖稱為帶權圖,也稱網,
- 帶權路徑長度:當圖是帶權圖時,一條路徑上所有邊的權值之和,稱為該路徑的帶權路徑長度,
- 無向圖中加入權值,稱為無向帶權圖;
- 有向圖中加入權值,稱為有向帶權圖,
- 無向帶權圖和有向帶權圖如下圖所示:
-
生成樹、生成森林:
- 生成樹: 包含圖中全部頂點的一個極小連通子圖,
- 極小連通子圖:邊盡可能的少, 但要保持連通,
- 若圖中頂點數為n,則它的生成樹含有 n-1 條邊,對生成樹而言,若砍去它的一條邊,則會變成非連通 圖,若加上一條邊則會形成一個回路,
- 生成森林:在非連通圖中,連通分量的生成樹構成了非連通圖的生成森林,
- 生成樹: 包含圖中全部頂點的一個極小連通子圖,
-
樹、有向樹
- 樹:不存在回路,且連通的無向圖,
- 有向樹:一個頂點的入度為0,其余頂點的入度均為1的有向圖,即有向樹,
- n個頂點的樹,必有n-1條邊,n個頂點的圖,若 |E|>n-1,則一定有回路,
-
邊數很少的圖稱為稀疏圖,反之稱為稠密圖,
5.3 圖的存盤結構
-
鄰接矩陣
-
采用結構陣列的形式來單獨保存頂點資訊,然后采用二維陣列的形式保存頂點之間的關系,這種保存頂點之間關系的陣列稱為鄰接矩陣(Adjacency Matrix),
-
對于一個包含n個頂點的圖,可以使用如下陳述句來宣告1個陣列保存頂點資訊,再宣告1個鄰接矩陣保存邊的權,
char Vertex[n]; //保存頂點資訊(序號或字母) int EdgeWeight[n][n]; //鄰接矩陣,保存邊的權- 對于陣列Vertex,其中每一個陣列元素用來保存頂點資訊,可以是序號或者字母,
- 而鄰接矩陣EdgeVeight用來保存邊的權或者連接關系,
- 在表示連接關系時,該二維陣列中的元素EdgeVeight[ i ] [ j ]=1表示(Vi,Vj)或<Vi,Vj>構成一條邊,如果EdgeVeight[ i ] [ j ]=0表示(Vi,Vj)或<Vi,Vj>不構成一條邊,
-
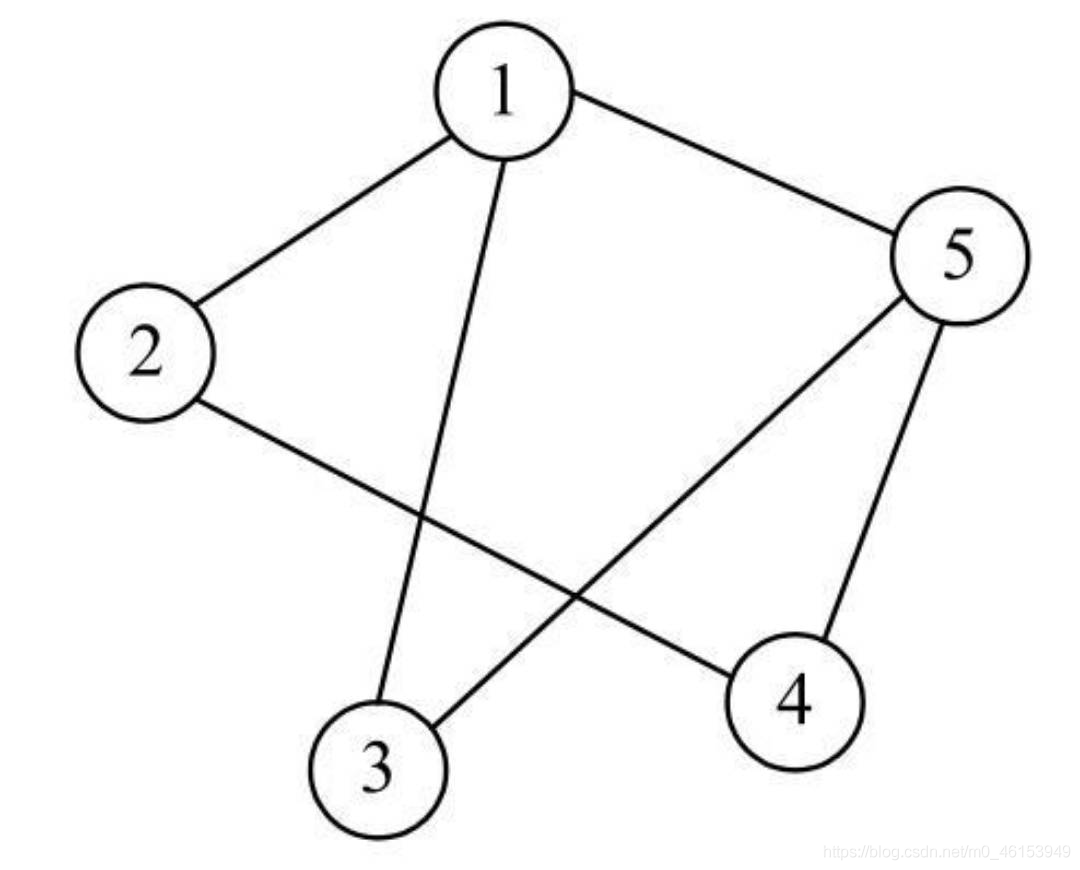
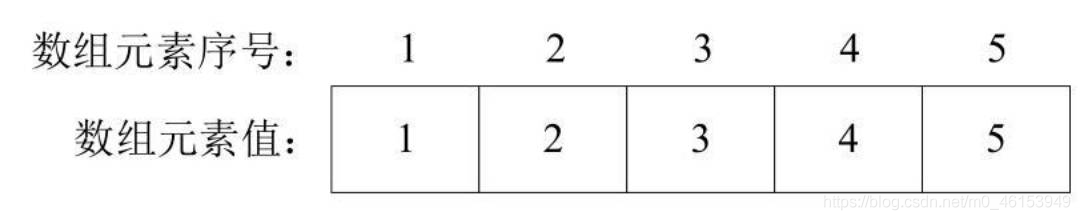
對于下圖所示的無向圖,可以采用一維陣列來保存頂點,保存的形式如圖2所示:
-
-
程式示例代碼如下:
Vertex[1]=1; Vertex[2]=2; Vertex[3]=3; Vertex[4]=4; Vertex[5]=5; -
對于鄰接矩陣,可以按照下圖所示的形式進行存盤,
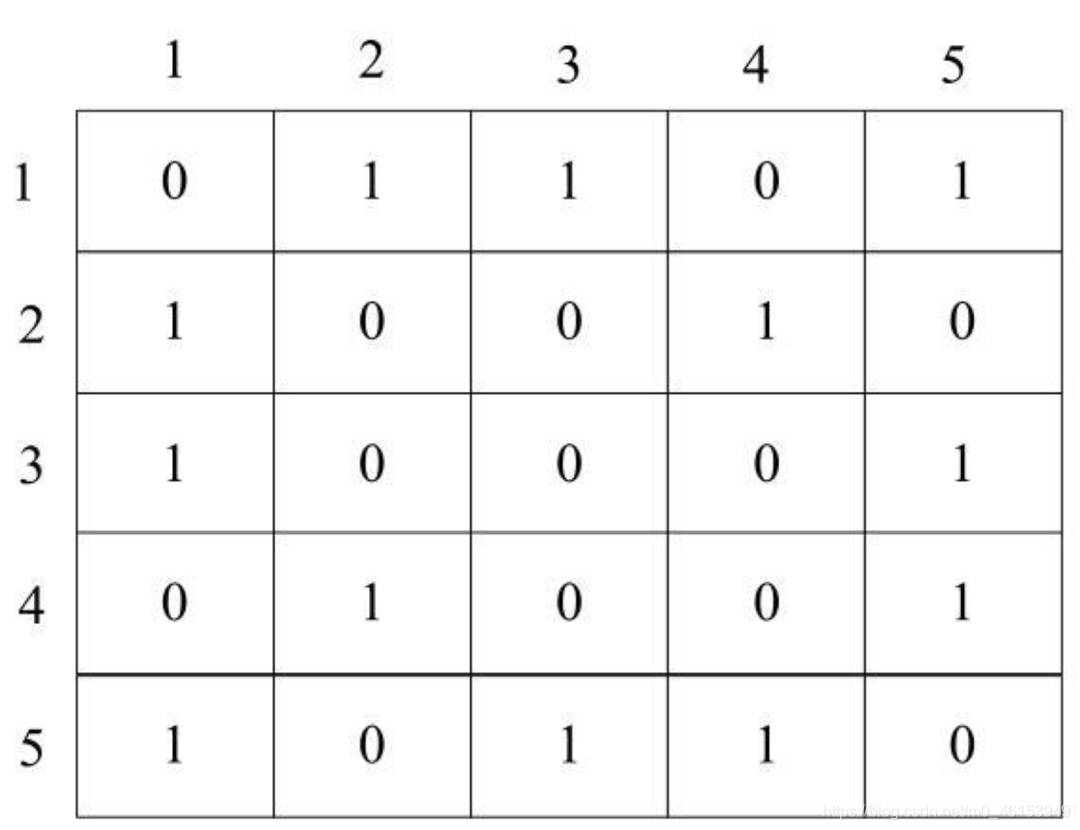
- 對于有邊的兩個頂點,在對應的矩陣元素中填入1,例如,V1和V3之間存在一條邊,因此EdgeVeight[1] [3]中保存1,而V3和V1之間存在一條邊,因此EdgeVeight[3] [1]中保存1,由此可見,對于無向圖,其鄰接矩陣左下角和右上角是對稱的,
-
對于有向圖,如下所示:
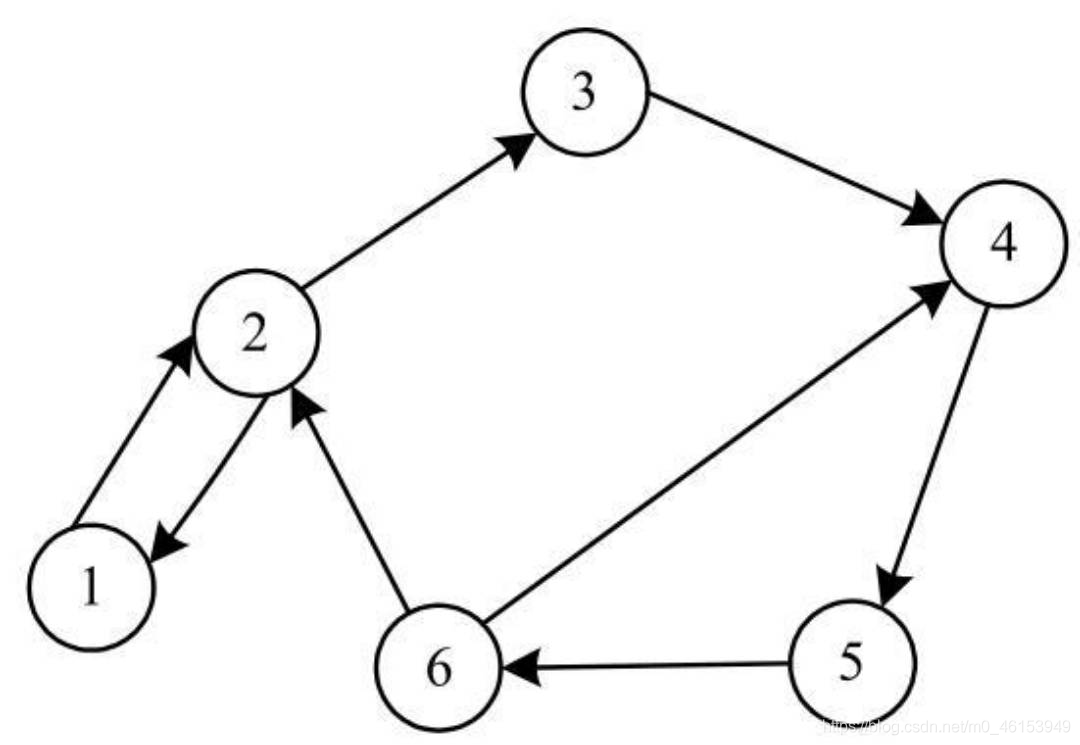
- 保存頂點的一維陣列形式不變,如圖1所示,而對于鄰接矩陣,仍然采用二維陣列,其保存形式如下圖所示,對于有邊的兩個頂點,在對應的矩陣元素中保存1,

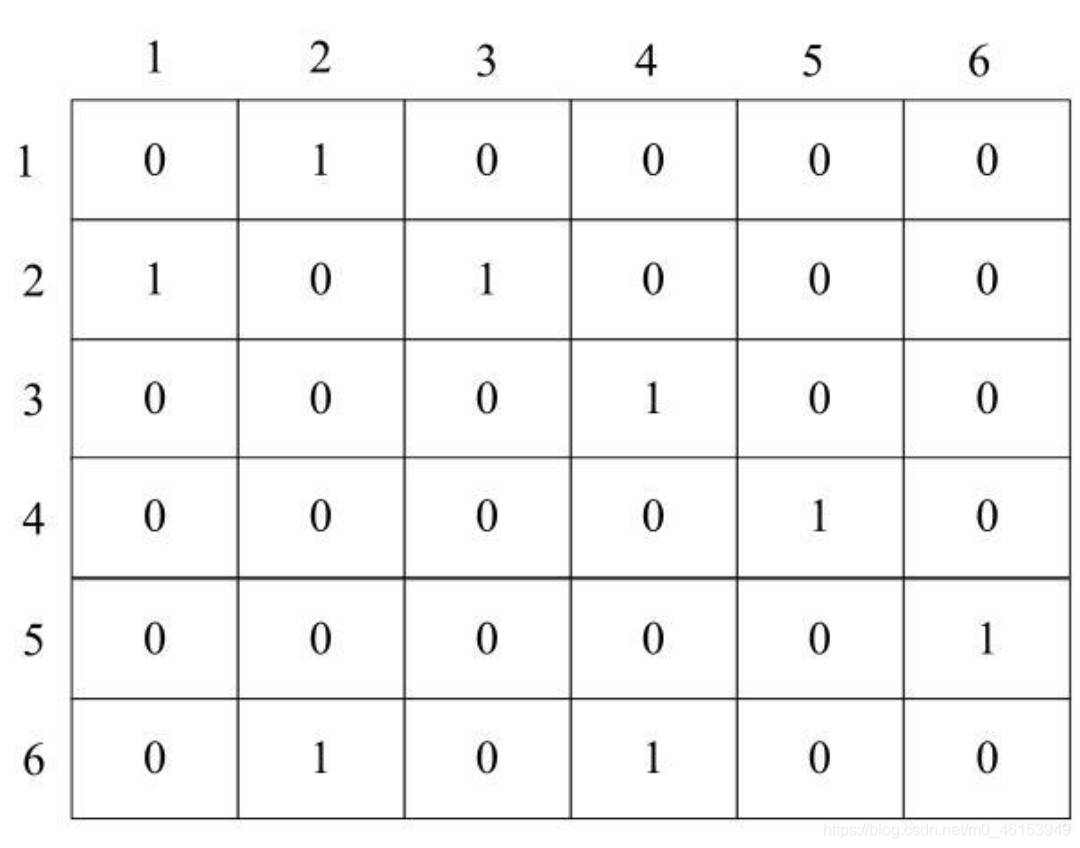
- 頂點V2到頂點V3存在一條邊,因此在EdgeVeight[2] [3]中保存1,而頂點V3到頂點V2不存在邊,因此在EdgeVeight[3] [2]中保存0,
-
對于有向帶權圖:
- 鄰接矩陣中可以保存相應的權值,即,有邊的項保存對應的權值,而無邊的項則保存一個特殊的符號Z,
- 例如下圖:
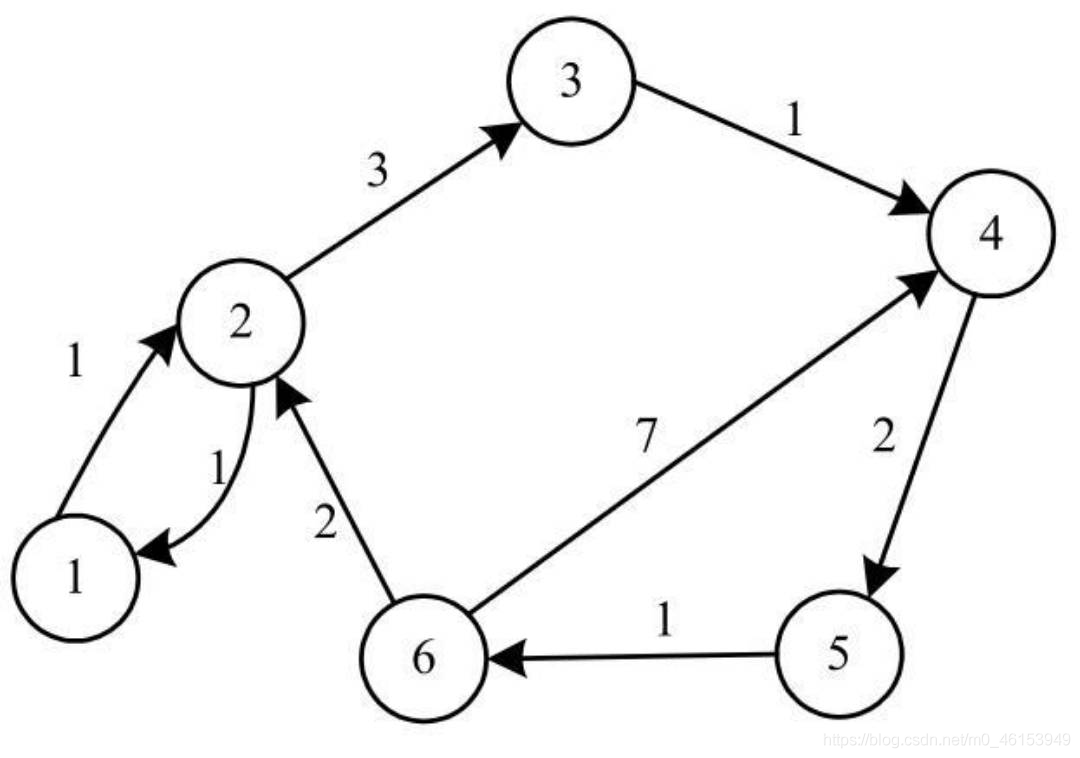
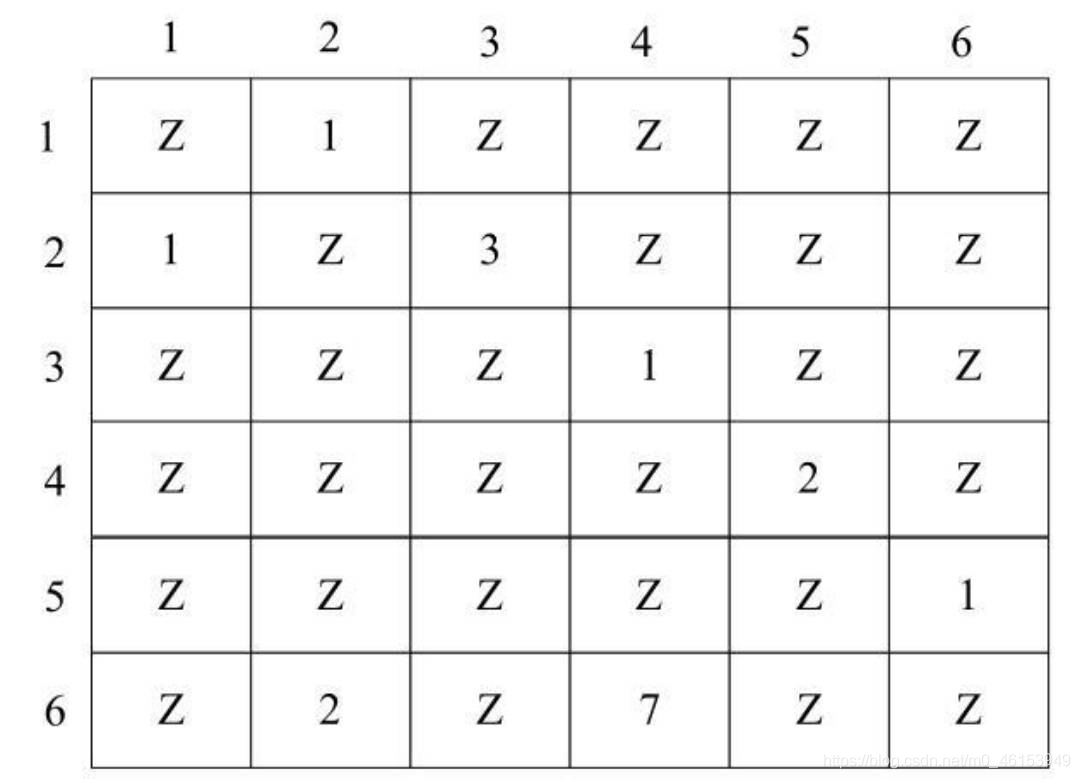
注意:在實際程式中為了保存帶權值的圖,需要定義一個最大值MAX,其值大于所有邊的權值之和,用MAX來替代特殊的符號Z保存在二維陣列中,
5.4 圖的程式設計
- 準備作業
- 準備需要使用的變數和資料結構,
- 具體代碼:
#define MaxNum 20 // 圖的最大頂點數
#define MaxValue 65535 // 最大值(可設為一個最大整數)
typedef struct
{
char Vertex[MaxNum]; // 保存頂點資訊(序號或字母)
int GType; // 圖的型別(0:無向圖,1:有向圖)
int VertexNum; // 頂點的數量
int EdgeNum; // 邊的數量
int Edgeweight[MaxNum][MaxNum]; // 保存邊的權
int isTrav[MaxNum]; // 遍歷標志
}GraphMatrix; // 定義鄰接矩陣圖結構
- 創建圖
- 初始化一個圖,
- 具體代碼:
void CreateGraph(GraphMatrix *GM) // 創建鄰接矩陣圖
{
int i, j, k;
int weight; // 權
char EstartV, EendV; // 邊的起始頂點
printf("輸入圖中各頂點資訊\n");
for (i = 0; i < GM->VertexNum; i++) // 輸入頂點
{
getchar();
printf("第%d個頂點:", i + 1);
scanf("%c", &(GM->Vertex[i])); // 保存到各頂點陣列元素中
}
printf("輸入構成各邊的頂點及權值:\n");
for (k = 0; k < GM->EdgeNum; k++) // 輸入邊的資訊
{
getchar();
printf("第%d條邊:", k + 1);
scanf("%c %c %d", &EstartV, &EendV, &weight);
for (i = 0; EstartV != GM->Vertex[i]; i++); // 在已有頂點中查找始點
for (j = 0; EendV != GM->Vertex[j]; j++); // 在已有頂點中查找終點
GM->Edgeweight[i][j] = weight; // 對應位置保存權值,表示有一條邊
if (GM->GType == 0) // 若是無向圖
{
GM->Edgeweight[j][i] = weight; // 在對角位置保存權值
}
}
}
- 清空圖
- 將一個圖結構變成空圖,即將矩陣的各元素設定為MaxValue即可,
- 具體代碼:
void ClearGraph(GraphMatrix *GM)
{
int i, j;
for (i = 0; i < GM->VertexNum; i++) // 清空矩陣
{
for (j = 0; j < GM->VertexNum; j++)
{
GM->Edgeweight[i][j] = MaxValue; // 設定矩陣中各元素的值為Maxvalue
}
}
}
- 顯示圖
- 顯示鄰接矩陣,
- 具體代碼:
void OutGraph(GraphMatrix *GM) // 輸出鄰接矩陣
{
int i, j;
for (j = 0; j < GM->VertexNum; j++)
{
printf("\t%c", GM->Vertex[j]); // 在第1行輸出頂點資訊
}
printf("\n");
for (i = 0; i < GM->VertexNum; i++)
{
printf("%c", GM->Vertex[i]);
for (j = 0; j < GM->VertexNum; j++)
{
if (GM->Edgeweight[i][j] == MaxValue) // 若權值為最大值
{
printf("\tZ"); // 用表示無窮大
}
else {
printf("\t%d", GM->Edgeweight[i][j]); // 輸出邊的權值
}
}
printf("\n");
}
}
- 遍歷圖
- 逐個訪問圖中的所有頂點,
- 具體代碼:
void DeepTraOne(GraphMatrix *GM, int n) // 從第n個結點開始,深度遍歷圖
{
int i;
GM->isTrav[n] = 1; // 標記該頂點已處理過
printf("->%c", GM->Vertex[n]); // 輸出結點資料
//添加處理結點的操作
for (i = 0; i < GM->VertexNum; i++)
{
if (GM->Edgeweight[n][i] != MaxValue && !GM->isTrav[n])
{
DeepTraOne(GM, i); // 遞回進行遍歷
}
}
}
void DeepTraGraph(GraphMatrix *GM) // 深度優先遍歷
{
int i;
for (i = 0; i < GM->VertexNum; i++) // 清除各頂點遍歷標志
{
GM->isTrav[i] = 0;
}
printf("深度優先遍歷結點:");
for (i = 0; i < GM->VertexNum; i++)
{
if (!GM->isTrav[i]) // 若該點未遍歷
{
DeepTraOne(GM, i); // 呼叫函式遍歷
}
}
printf("\n");
}
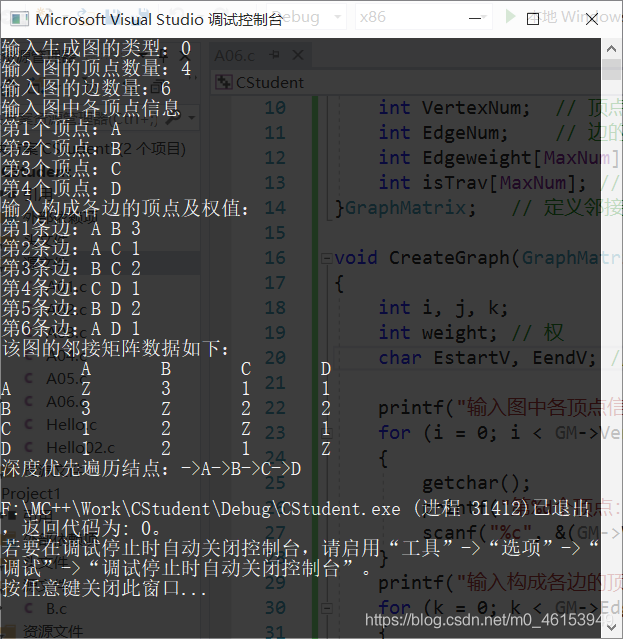
- 案例:使用深度遍歷實作圖操作
- 具體代碼:
#include <stdio.h>
#define MaxNum 20 // 圖的最大頂點數
#define MaxValue 65535 // 最大值(可設為一個最大整數)
typedef struct
{
char Vertex[MaxNum]; // 保存頂點資訊(序號或字母)
int GType; // 圖的型別(0:無向圖,1:有向圖)
int VertexNum; // 頂點的數量
int EdgeNum; // 邊的數量
int Edgeweight[MaxNum][MaxNum]; // 保存邊的權
int isTrav[MaxNum]; // 遍歷標志
}GraphMatrix; // 定義鄰接矩陣圖結構
void CreateGraph(GraphMatrix *GM) // 創建鄰接矩陣圖
{
int i, j, k;
int weight; // 權
char EstartV, EendV; // 邊的起始頂點
printf("輸入圖中各頂點資訊\n");
for (i = 0; i < GM->VertexNum; i++) // 輸入頂點
{
getchar();
printf("第%d個頂點:", i + 1);
scanf("%c", &(GM->Vertex[i])); // 保存到各頂點陣列元素中
}
printf("輸入構成各邊的頂點及權值:\n");
for (k = 0; k < GM->EdgeNum; k++) // 輸入邊的資訊
{
getchar();
printf("第%d條邊:", k + 1);
scanf("%c %c %d", &EstartV, &EendV, &weight);
for (i = 0; EstartV != GM->Vertex[i]; i++); // 在已有頂點中查找始點
for (j = 0; EendV != GM->Vertex[j]; j++); // 在已有頂點中查找終點
GM->Edgeweight[i][j] = weight; // 對應位置保存權值,表示有一條邊
if (GM->GType == 0) // 若是無向圖
{
GM->Edgeweight[j][i] = weight; // 在對角位置保存權值
}
}
}
void ClearGraph(GraphMatrix *GM)
{
int i, j;
for (i = 0; i < GM->VertexNum; i++) // 清空矩陣
{
for (j = 0; j < GM->VertexNum; j++)
{
GM->Edgeweight[i][j] = MaxValue; // 設定矩陣中各元素的值為Maxvalue
}
}
}
void OutGraph(GraphMatrix *GM) // 輸出鄰接矩陣
{
int i, j;
for (j = 0; j < GM->VertexNum; j++)
{
printf("\t%c", GM->Vertex[j]); // 在第1行輸出頂點資訊
}
printf("\n");
for (i = 0; i < GM->VertexNum; i++)
{
printf("%c", GM->Vertex[i]);
for (j = 0; j < GM->VertexNum; j++)
{
if (GM->Edgeweight[i][j] == MaxValue) // 若權值為最大值
{
printf("\tZ"); // 用表示無窮大
}
else {
printf("\t%d", GM->Edgeweight[i][j]); // 輸出邊的權值
}
}
printf("\n");
}
}
void DeepTraOne(GraphMatrix *GM, int n) // 從第n個結點開始,深度遍歷圖
{
int i;
GM->isTrav[n] = 1; // 標記該頂點已處理過
printf("->%c", GM->Vertex[n]); // 輸出結點資料
//添加處理結點的操作
for (i = 0; i < GM->VertexNum; i++)
{
if (GM->Edgeweight[n][i] != MaxValue && !GM->isTrav[n])
{
DeepTraOne(GM, i); // 遞回進行遍歷
}
}
}
void DeepTraGraph(GraphMatrix *GM) // 深度優先遍歷
{
int i;
for (i = 0; i < GM->VertexNum; i++) // 清除各頂點遍歷標志
{
GM->isTrav[i] = 0;
}
printf("深度優先遍歷結點:");
for (i = 0; i < GM->VertexNum; i++)
{
if (!GM->isTrav[i]) // 若該點未遍歷
{
DeepTraOne(GM, i); // 呼叫函式遍歷
}
}
printf("\n");
}
void main()
{
GraphMatrix GM; // 定義保存鄰接表結構的圖
printf("輸入生成圖的型別:");
scanf("%d", &GM.GType); // 圖的種類
printf("輸入圖的頂點數量:");
scanf("%d", &GM.VertexNum); // 輸入圖頂點數
printf("輸入圖的邊數量:");
scanf("%d", &GM.EdgeNum); // 輸入圖邊數
ClearGraph(&GM); // 清空圖
CreateGraph(&GM); // 生成鄰接表結構的圖
printf("該圖的鄰接矩陣資料如下:\n");
OutGraph(&GM); // 輸出鄰接矩陣
DeepTraGraph(&GM); // 深度優先搜索遍歷圖
}
參考文獻
- [1]. 2020年王道考研資料結構考研復習指導.王道論壇
- [2]. C/C++常用演算法手冊(第三版).劉亞冬
- [3]. 資料結構(C語言版).嚴蔚敏(黑版)
- [4]. 演算法筆記.胡凡
- [5]. 資料結構習題與決議(第3版).李春葆
- [6]. 資料結構與演算法(C語言版).胡明
全文僅用于個人備考復習,不可商用,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/274721.html
標籤:其他
上一篇:手動安裝MySQL5.7版本