初始SIMD
- 前言
- AVX基礎介紹
- 矩陣乘加速
- 總結
前言
完成了計算機系統原理之后來做一個總結,本次實驗時繼多執行緒之后繼續研究矩陣乘優化的內容,主要使用SIMD指令集并與上次實驗的多執行緒進行對比,
SIMD即單指令集多資料(Single Instruction Multiple Data),說的簡單一點就是一種向量運算,想象一下在單指令單資料上你要做一個op需要幾步?你得先取指譯碼,然后訪問記憶體獲得運算元,然后才能進行計算吧,Intel告訴我們可以用SIMD一下子完成128bit,或者256bit,甚至是512bit資料的運算,怎么理解這樣的一個資料結構呢,可以把它想象成一個可以同時按位計算的陣列,既然是個陣列說明也可以通過索引訪問資料,這里有個誤區是這個資料結構本身表現出來的數沒有太多意義,如一個__m128 a存放了4個float型別的數,那么a就是一個類似陣列的東西,
AVX基礎介紹
MMX和SSE用的不多這里就以AVX為例了如果想看完整的更深層的建議看Intel官網https://software.intel.com/content/www/us/en/develop/home.html
資料型別
| 資料型別 | 描述 |
|---|---|
| __m128 | 包含四個float型別數字的向量 |
| __m128d | 包含兩個double型別數字的向量 |
| __m128i | 包含若干個int型別數字的向量 |
| __m256 | 包含八個float型別數字的向量 |
| __m256d | 包含四個double型別數字的向量 |
| __m256i | 包含若干個int型別數字的向量 |
訪存操作
| 資料型別 | 描述 |
|---|---|
| _mm256_load_ps/pd | 從對齊的記憶體地址加載浮點向量 |
| _mm256_load_si256 | 從對齊的記憶體地址加載整形向量 |
| _mm256_loadu_ps/pd | 從未對齊的記憶體地址加載浮點向量 |
| _mm256_loadu_si256 | 從未對齊的記憶體地址加載整形向量 |
寫入的操作把load換成store即可,這里需要知道SIMD是要求對齊的,可以用align對齊,當然你也可以用上述的不對齊時的操作寫代碼,但是據我測驗似乎時間花費更多,
加減乘
| 資料型別 | 描述 |
|---|---|
| _mm256_add_ps/pd | 對兩個浮點向量做加法 |
| _mm256_sub_ps/pd | 對兩個浮點向量做減法 |
| _mm256_mul_ps/pd | 對兩個浮點向量做乘法 |
| _mm256_hadd_ps/pd | 水平方向對兩個浮點向量做加法 |
| _mm256_hsud_ps/pd | 垂直方向對兩個浮點向量做加法 |
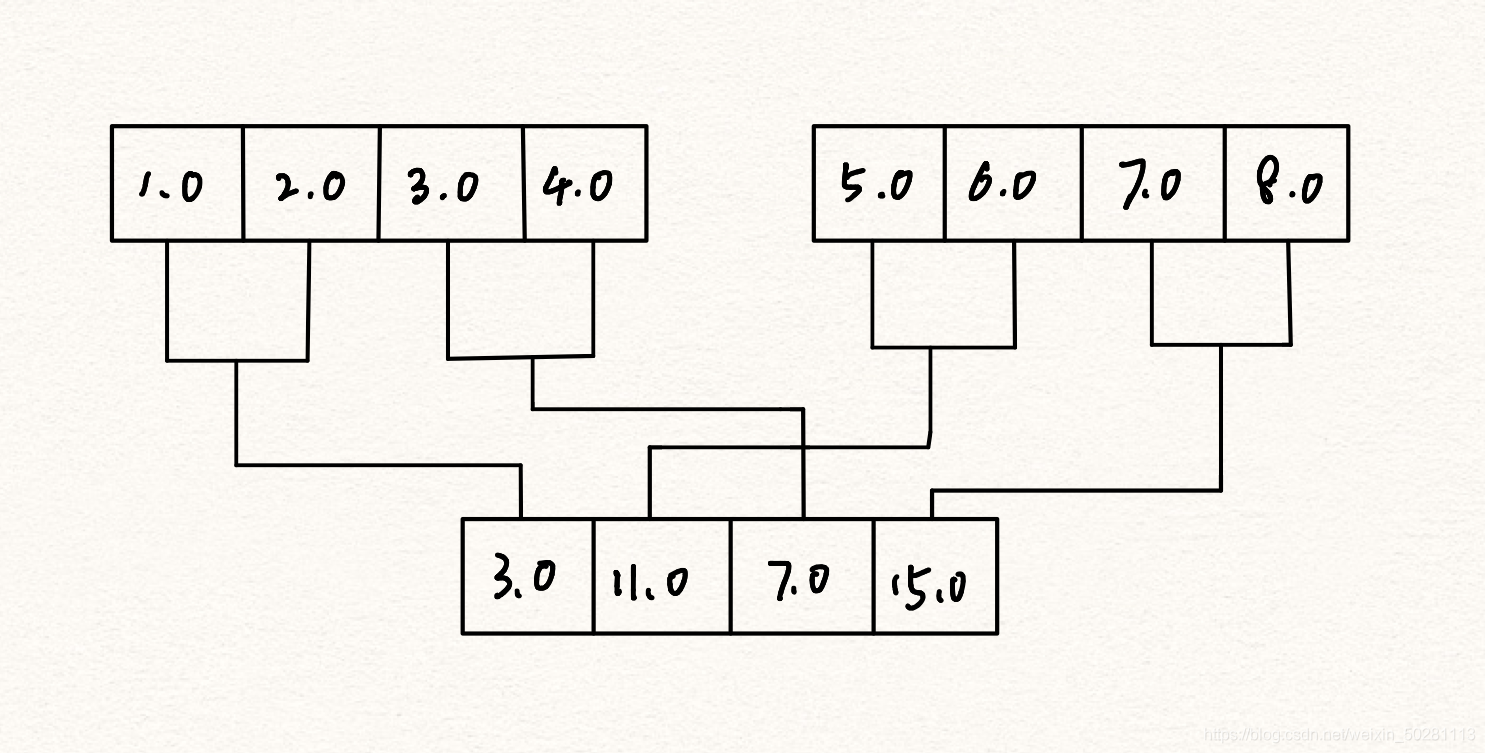
這里解釋一下水平方向時怎么操作的,如下圖,
矩陣乘加速
沒錯又是我們的老朋友矩陣乘,有了上述的基礎知識已經完全可以寫出一個入門級的SIMD優化代碼了,
int main() {
double* A, * B, * C;
A = new double[M * N];
B = new double[N * P];
C = new double[M * P];
for (int i = 0; i < M; i++) {
for (int j = 0; j < N; j++) {
A[i * N + j] = i * N + j;
}
}
for (int i = 0; i < N; i++) {
for (int j = 0; j < P; j++) {
B[i * P + j] = i * P + j;
}
}
avxmul(A, B, C); //avx+轉置
return 0;
}
//avx+轉置
void avxmul(double* A, double* B, double* C) {
for (int i = 0; i < M; i++) {
int c = i * P;
for (int j = 0; j < P; j++) {
C[c + j] = 0;
}
}
clock_t start, end;
int i, j, k;
double temp;
start = clock();
double* B1 = T(B);
for (i = 0; i < M; i++) {
for (j = 0; j < P; j++) {
temp = 0; double t[4] = { 0 };
int a = i * N; int b = j * N;
for (k = 0; k < N && k + 4 <= N; k += 4) {
_mm256_store_pd(&t[0],
_mm256_mul_pd(_mm256_load_pd(&A[a + k]), _mm256_load_pd(&B1[b + k])));
temp += t[0] + t[1] + t[2] + t[3];
}
C[i * P + j] = temp;
}
}
end = clock();
cout << "avx+轉置時間: " << (double)(end - start) / CLOCKS_PER_SEC
* 1000 << "ms" << endl;
}
總結
本次實驗我們以 SIMD(單指令多資料)為主要研究物件,實作了矢量加和矩陣乘的優化,在實驗程序中我們不斷在探討 SIMD 與 SIMT(單指令多執行緒)計算機系統-SIMD 程式設計與性能分析之間的區別與聯系,
從單個執行緒看,假設我們用 SSE 正在處理一個四維向量(指令向量化處理是 SIMD 的核心),這條指令最快在一個 cycle 就能完成,但是在SIMT 架構中則需要把這個四維向量分解開,一個 cycle 處理一個資料,最快也需要 4 個 cycle,但這也需要比起 SIMT 四倍的邏輯單元,換而言之在同等算力進行對比下,其實 SIMD 可以拿出更少的執行緒個數來實作 SIMT 的算力,這也是為什么在我們的實驗中 SIMD 往往優化程度更好的原因,
但是當我們增加執行緒數的時候,SIMD 的優勢將會逐漸減少,而倘若 SIMD 單純把向量維度擴大時,浪費也會增加,所以現在一些架構會對 16 個執行緒分成四組的 SIMD 解決這個問題,當然不管是 SIMD 還是 SIMT 都存在不少的局限,SIMD 需要嚴格按照維數的整數倍去實作,否則會造成邏輯單元的浪費,而 SIMT 則需要在計算機的可以使用的邏輯單元數內實作執行緒數的創建,否則執行緒數的增加將不能導致速度加快,反而需要大量的分支跳轉影響了效率,這里也體現了演算法設計上面的折衷思想,這種折衷既與演算法本身有關,又與對應的硬體有關,
經過上面的陳述仿佛 SIMD 和SIMT 存在不同程度的對立,但是這并不意味著 SIMD 就不能與 SIMT 進行“合作優化”,我們設計了同時使用 SIMD 與 SIMT 的演算法,演算法思路也很簡單,只需要思考在多執行緒下每個執行緒是否支持 SIMD 即可,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/274723.html
標籤:其他
下一篇:C語言學習筆記----2