文章目錄
- 1. 強化學習的應用場景
- 1.1. 四個成熟場景
- 1.2. 幾個強化學習仿真環境
- 1.2.1. Gridworld
- 1.2.2. Neural MMOs
- 1.2.3. Lab
- 2. 強化學習的基礎知識和常用術語
- 2.1. 常用術語表
- 2.2. 強化學習的目的
- 2.3. 兩個基本模型
- 2.3.1. 多臂賭博機
- 2.3.2. 馬爾科夫決策程序
- 3. 經典強化學習演算法和深度強化學習
- 3.1. 經典強化學習演算法
- 3.2. 深度強化學習
- 4. 強化學習的學習資料
1. 強化學習的應用場景
1.1. 四個成熟場景
在入門強化學習之前,我們先來具體的看看,目前強化學習可以做一些什么事情,
如下面四張圖,分別是強化學習應用于:
- 王者榮耀絕悟挑戰;
- 訓練機械臂投籃;
- Alpha Go與柯潔下圍棋;
- 個性化序列推薦系統,

強化學習是機器學習的一個分支,它會訓練一個智能體用來探索周圍環境,在圖一的王者榮耀中,這個智能體是英雄,例如阿軻、公孫離;在圖二的投籃中,這個智能體是機械臂;在圖三中,這個智能體是下圍棋的Alpha Go;在圖四的推薦系統中,這個智能體是推薦演算法;

智能體在一開始是很笨的,在與周圍環境的不斷互動中才會逐漸變得“聰明”起來,例如在上面的圖中,智能體首先是用很笨拙的方法去跨越障礙,在多次失敗之后,才學會了如何跳的更高去越過障礙物,
1.2. 幾個強化學習仿真環境
1.2.1. Gridworld
這里介紹三個Gridworld環境:
-
Gym MiniGrid
最基礎的GridWorld就是走迷宮,例如下圖紅色的智能體走到綠色的位置就算是找到了迷宮出口,除此之外還有其他的有意思的迷宮配置,可以玩一玩,

-
Multi Drones Monitoring
Multi Drones Monitoring是Multi-agent Reinforcement Learning中的一個小模塊,提供了多個基于智能體的grid world小環境
-
MAgent
這是一個用于研究環境中大量智能體的競爭和協作問題的GridWorld環境

1.2.2. Neural MMOs
Neural MMOs 是由OpenAI開源的一個大型的復雜MA游戲場景,在這張大地圖中,由于資源有限,agent要學著合作/競爭活下去

1.2.3. Lab
Lab是一個由DeepMind開源的強化學習環境,是一張雷神之錘III競技場(Quake III Arena)的地圖,由兩個隊伍,每隊由兩個智能體組成,在室內和戶外兩個場景下以第一人稱視角競爭玩奪旗的游戲,

2. 強化學習的基礎知識和常用術語
2.1. 常用術語表
| 英文 | 中文 | 解釋 |
|---|---|---|
| RL | 強化學習 | 即 Reinforcement Learning 的首字母縮寫 |
| Agent | 智能體 | 強化學習演算法,或強化學習演算法的作用目標 |
| Environment | 環境 | Agent的作用空間,可以認為除Agent外的一切皆為環境, |
| Action | 行為 | 也稱動作、策略、決策,指的是Agent的輸出,作用于環境 |
| State / Observation | 狀態 | Observation指的是被Agent觀測到的部分環境的狀態,State指的是整個環境的狀態,一般情況下,未特定說明的“狀態”、“State”均指“Observation”,也就是被Agent觀測到的部分環境的狀態,表示為: S S S |
| Reward | 反饋 | 量化后的反饋也稱獎勵,反饋指的是Action作用于Environment后,對環境中的某一個特定的變數產生的影響,表示為: R R R |
| Episode | 回合 | 也稱試驗(Trial),是指一次完整的強化學習訓練 |
| Trajectory | 軌跡 | 是指在一個 episode 中產生的 Observation-Action 序列,表示為: τ = ( s 0 , a 0 , s 1 , a 1 , . . . , s n , a n ) \tau=(s_0,a_0,s_1,a_1,...,s_n,a_n) τ=(s0?,a0?,s1?,a1?,...,sn?,an?) |
| Value Function | 價值函式 | 是指某一個 π \pi π可以得到的反饋的期望,表示為: v π v_\pi vπ? |
| Policy Function | 策略函式 | 策略(Policy)用于根據 Observation 確定具體的 Action,表示為: π \pi π |
| Stochastic Policy | 隨機性策略 | 隨機性策略會得到多個Action以及它們的概率,對所有Action根據概率抽選,最終確定一個輸出Action |
| Deterministic Policy | 確定性策略 | 確定性策略會得到多個Action以及它們的概率,但只輸出概率最高的那個Action |
| Exploration | 探索 | 是指Agent會嘗試新的Action來得到可能存在的更優策略,即得到Reward更大的策略, |
| Exploitation | 利用 | 是指Agent不再嘗試新的Action,只采取已知的可以得到最高Reward的策略, |
| Trade-Off | 權衡 | Agent在初始的時候需要偏向于Exploration來得到合適的策略,在學習的程序中高Reward的策略被逐漸學習出來,這時候就需要偏向于Exploitation,更多的利用已知的策略,而不是把時間浪費在找新策略上, |
| Planning | 規劃 | Planning是指Agent可以獲得整個環境的詳細資訊,此時 Agent 能夠計算出一個完美的模型,只需要知道當前的狀態,就能夠尋找到最優解, |
| Learning | 學習 | Learning是指 Agent 無法獲得完整的環境資訊,只能通過不斷地與環境互動,逐漸改進其策略, |
| Discount Factor | 折扣因子 | 折扣因子是用于保證馬爾科夫決策程序即時性的一個引數,表示為: γ \gamma γ |
| Bellman Equation | 貝爾曼方程 | 貝爾曼等式是一種計算價值函式(Q和V)的工具,它描述了當前狀態與未來狀態的迭代關系 |
| MAB | 多臂賭博機 | Multi-Armed Bandit,一個基礎的強化學習場景 |
| MDP | 馬爾科夫決策程序 | Markov Decision Process,一個基礎的強化學習場景,是帶有 Action 和 Reward 的狀態轉移程序 |
| Q / Action-Value Function | Q 函式 / 動作值函式 | 表示 Agent 在某個 State 采取某個 Action 時得到的累計 Reward 期望值 |
| V / State-Value function | V 函式 / 狀態值函式 | 表示 Agent 在某個 State 時具有的累計 Reward 期望值 |
| Value Iteration | 價值迭代 | 利用 V 函式求取最優策略的方法 |
| Policy Iteration | 策略迭代 | 利用 Q 函式求取最優策略的方法 |
| Model-Free RL | 無模型的強化學習 | Model-Free RL 直接讓 Agent 在環境中做出 Action,通過不斷試錯來找到針對特定環境的最佳策略 π \pi π, |
| Model-Based RL | 基于模型的強化學習 | Model-Based RL通過對環境進行理解,建立一個環境模型,Agent可以在模型中對下一步的狀態和反饋做出預測,找出最佳策略,再在現實環境中做出動作 |
| Policy-Based RL | 基于概率的強化學習 | Policy-Based RL中Agent在某一狀態時的所有可能Action都有一定概率被選中,只是不同Action有不同的概率,最侄訓得到一個隨機性策略 |
| Value-Based RL | 基于價值的強化學習 | Value-Based RL中會對Agent在某一狀態時的所有可能Action,按對應得到的Reward進行排序,并選用Reward最高的Action,最侄訓得到一個確定性策略 |
| Monte-Carlo RL | 回合更新的強化學習 | MC 方法每次都需要采樣一條完整的軌跡 τ \tau τ 之后才能對 π \pi π 或 v π v_\pi vπ? 進行更新 |
| Temporal-Difference RL | 單步更新的強化學習 | TD 可以在每完成一步(得到一個Observation,采取一個Action并得到反饋值)之后就對策略或價值函式進行更新 |
| On-Policy RL | 同軌強化學習 | On-Policy RL需要Agent直接與環境互動,即學習程序中所用到的資料與樣本,都是Agent從環境中觀測到的, |
| Off-Policy RL | 離軌強化學習 | Off-Policy RL不需要Agent直接與環境互動,即可以通過別的方法獲取資料進行學習,不需要Agent直接通過觀測環境獲得, |
2.2. 強化學習的目的
強化學習中包含了兩個物體和三個關系,可以用下圖表示:
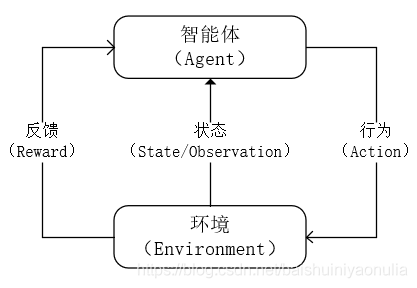
在強化學習程序中,智能體(Agent) 跟 環境(Environment) 一直在互動,智能體(Agent) 在 環境(Environment) 中獲取到 環境的狀態(State/Observation),并根據它做出一個 行為(Action),這個 行為(Action) 會導致 智能體(Agent) 所處的 環境的狀態(Observation) 發生變化,并且 智能體(Agent) 會從 環境(Environment) 的變化中得到一定的 反饋(Reward),該 反饋(Reward) 用于 智能體(Agent) 判斷自己剛才的 行為(Action) 是否合理,
顯而易見,Agent 采取的 Action 能獲得越高的 Reward,說明Agent越成功,強化學習的目的就是讓一個智能體(Agent) 在一個復雜不確定的環境(Environment)里面去極大化它能獲得的反饋(Reward),
2.3. 兩個基本模型
2.3.1. 多臂賭博機
多臂賭博機(Multi-Armed Bandit, MAB)問題可以說是強化學習的開端,最原始的強化學習演算法就是從多臂賭博機問題引出來的,目前為止,主流的Bandit演算法主要有兩類:(1)貪心演算法,例如: ? ? greedy \epsilon-\text{greedy} ??greedy;(2)置信演算法,例如:UCB(Upper Confidence Bound),
下面我們就來講講什么是多臂賭博機問題:
賭博機又稱老虎機,它是一種通過搖動搖臂(Arms)來獲得回報(Reward)的機器,每個賭博機只有一條搖臂,多個賭博機放在一起就是多臂賭博機,如下圖所示是一個3臂賭博機:
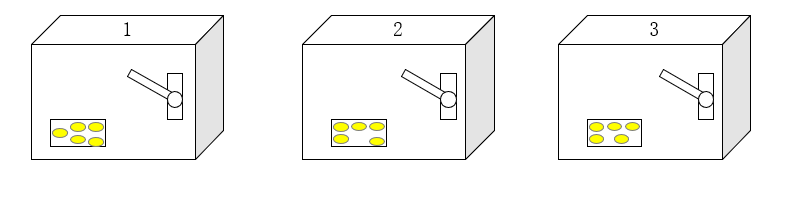
上面的三個賭博機搖出金幣的概率分布各不相同,也就是說它們的期望 Reward 不同,我們希望構造一個 Agent,自動去找出搖動哪一個賭博機的搖臂可以獲得最高的 Reward,
我們把搖動三個賭博機的 Action 分別命名為 a = [0, 1, 2],每次搖動搖臂(pull arm)后都會獲得一個回報 r,多次搖動搖臂后動作 a 的值函式 q(a) 可以表示為:
q
(
a
)
=
E
[
R
t
∣
A
t
=
a
]
q(a)=\mathbb{E}[R_t | A_t=a]
q(a)=E[Rt?∣At?=a]
注意在多臂賭博機問題中,由于每次搖動搖臂后Agent的State是不變的(Agent看到的還是那三個賭博機),因此動作值函式
q(s,a)可以簡寫為q(a)
在獲取了每個搖臂的 q(a) 之后,就可以利用Bandit演算法來選擇動作了,這里我們介紹兩種Bandit演算法(策略):
-
?
?
\epsilon-
??貪心策略
? ? \epsilon- ??貪心策略設定一個概率值 ? \epsilon ?用于指定探索的程度,并規定下一個時間步要執行的動作有 1 ? ? 1-\epsilon 1??的概率選用能使 q q q 值最大的動作 a a a,有 ? \epsilon ?的概率選擇其他動作: a = { arg?max ? a q ( s , a ) , P(1- ? ) o t h e r w i s e , P( ? ) a=\begin{cases} \argmax_a q(s,a), \text{P(1-$\epsilon$)}\\ otherwise, \text{P($\epsilon$)}\\ \end{cases} a=????aargmax?q(s,a),P(1-?)otherwise,P(?)? - UCB1策略
UCB1策略計算了 q ( s , a ) q(s,a) q(s,a)的置信區間上界,即 q ( s , a ) q(s,a) q(s,a)的最大期望值,然后取能使 q ( s , a ) q(s,a) q(s,a)最大的動作: a = arg?max ? a ( q ( s , a ) + c ln ? n n a ) a=\argmax_a\biggl(q(s,a)+c\sqrt{\frac{\ln n}{n_a}}\biggr) a=aargmax?(q(s,a)+cna?lnn? ?)其中 q ( s , a ) q(s,a) q(s,a) 是指動作 a a a的 q q q值, c c c是一個可調引數用于指定探索的程度, n n n是指所有動作的執行次數, n a n_a na?是指動作 a a a的執行次數
此時有了 q(a) ,也有了利用 q(a) 來選擇 a 的策略,Agent就可以利用Bandit策略來根據 q(a) 選擇搖動哪個搖臂 a ,從而獲得最大的 r 了,
下面我們來模擬一個episode,在這個episode中我們利用了 ? \epsilon ? 為 0.1 的 ? ? \epsilon- ??貪心策略:
- 搖動3個搖臂各一次,得到
[
a
1
,
a
2
,
a
3
]
[a_1,a_2,a_3]
[a1?,a2?,a3?] 的 Reward
[
2
,
4
,
6
]
[2,4,6]
[2,4,6]:
q ( a 0 ) = E [ R 0 = 2 ∣ A 1 = a 1 ] = 2 q(a_0)=\mathbb{E}[R_0=2|A_1=a_1]=2 q(a0?)=E[R0?=2∣A1?=a1?]=2 q ( a 1 ) = E [ R 1 = 4 ∣ A 2 = a 2 ] = 4 q(a_1)=\mathbb{E}[R_1=4|A_2=a_2]=4 q(a1?)=E[R1?=4∣A2?=a2?]=4 q ( a 2 ) = E [ R 2 = 6 ∣ A 3 = a 2 ] = 6 q(a_2)=\mathbb{E}[R_2=6|A_3=a_2]=6 q(a2?)=E[R2?=6∣A3?=a2?]=6 - 根據 ? ? \epsilon- ??貪心策略,有0.9的概率選擇可以獲得最大q值的動作,0.1的概率選擇其他動作,假設此時選擇可以獲得最大q值的動作 q ( a 2 ) = 6 q(a_2)=6 q(a2?)=6,則有當前的最優動作為: a = arg?max ? a q ( a 2 ) = a 2 a=\argmax_a q(a_2)=a_2 a=aargmax?q(a2?)=a2?搖動 a 2 a_2 a2?得到 Reward 0 0 0 更新 q ( a 2 ) q(a_2) q(a2?): q ( a 0 ) = E [ R 0 = 2 ∣ A 1 = a 1 ] = 2 q(a_0)=\mathbb{E}[R_0=2|A_1=a_1]=2 q(a0?)=E[R0?=2∣A1?=a1?]=2 q ( a 1 ) = E [ R 1 = 4 ∣ A 2 = a 2 ] = 4 q(a_1)=\mathbb{E}[R_1=4|A_2=a_2]=4 q(a1?)=E[R1?=4∣A2?=a2?]=4 q ( a 2 ) = E [ R 2 = 6 , 0 ∣ A 4 = a 2 ] = 6 + 0 2 = 3 q(a_2)=\mathbb{E}[R_2=6,0|A_4=a_2]=\frac{6+0}{2}=3 q(a2?)=E[R2?=6,0∣A4?=a2?]=26+0?=3
- 根據 ? ? \epsilon- ??貪心策略,有0.9的概率選擇可以獲得最大q值的動作,0.1的概率選擇其他動作,假設此時選擇可以獲得最大q值的動作 q ( a 1 ) = 4 q(a_1)=4 q(a1?)=4,則有當前的最優動作為: a = arg?max ? a q ( a 1 ) = a 1 a=\argmax_a q(a_1)=a_1 a=aargmax?q(a1?)=a1?搖動 a 1 a_1 a1?得到 Reward 10 10 10 更新 q ( a 1 ) q(a_1) q(a1?): q ( a 0 ) = E [ R 0 = 2 ∣ A 1 = a 1 ] = 2 q(a_0)=\mathbb{E}[R_0=2|A_1=a_1]=2 q(a0?)=E[R0?=2∣A1?=a1?]=2 q ( a 1 ) = E [ R 1 = 4 , 10 ∣ A 5 = a 2 ] = 4 + 10 2 = 7 q(a_1)=\mathbb{E}[R_1=4,10|A_5=a_2]=\frac{4+10}{2}=7 q(a1?)=E[R1?=4,10∣A5?=a2?]=24+10?=7 q ( a 2 ) = E [ R 2 = 6 , 0 ∣ A 4 = a 2 ] = 6 + 0 2 = 3 q(a_2)=\mathbb{E}[R_2=6, 0|A_4=a_2]=\frac{6+0}{2}=3 q(a2?)=E[R2?=6,0∣A4?=a2?]=26+0?=3
- 根據 ? ? \epsilon- ??貪心策略,有0.9的概率選擇可以獲得最大q值的動作,0.1的概率選擇其他動作,假設此時選擇其他動作 q ( a 0 ) = 2 q(a_0)=2 q(a0?)=2,則有當前的動作為: a = arg?max ? a q ( a 0 ) = a 0 a=\argmax_a q(a_0)=a_0 a=aargmax?q(a0?)=a0?搖動 a 0 a_0 a0?得到 Reward 2 2 2 更新 q ( a 0 ) q(a_0) q(a0?): q ( a 0 ) = E [ R 0 = 2 , 2 ∣ A 6 = a 1 ] = 2 + 2 2 = 2 q(a_0)=\mathbb{E}[R_0=2,2|A_6=a_1]=\frac{2+2}{2}=2 q(a0?)=E[R0?=2,2∣A6?=a1?]=22+2?=2 q ( a 1 ) = E [ R 1 = 4 , 10 ∣ A 5 = a 2 ] = 4 + 10 2 = 7 q(a_1)=\mathbb{E}[R_1=4,10|A_5=a_2]=\frac{4+10}{2}=7 q(a1?)=E[R1?=4,10∣A5?=a2?]=24+10?=7 q ( a 2 ) = E [ R 2 = 6 , 0 ∣ A 4 = a 2 ] = 0 + 6 2 = 3 q(a_2)=\mathbb{E}[R_2=6, 0|A_4=a_2]=\frac{0+6}{2}=3 q(a2?)=E[R2?=6,0∣A4?=a2?]=20+6?=3
- 類似的,重復步驟2-4,Agent 就可以估算出三個搖臂的期望q值
- 學習結束后,Agent 只需搖動期望最高的一個搖臂即可得到最高的Reward,
到此,多臂賭博機問題就找到了求解方法,也就是最原始的強化學習,
2.3.2. 馬爾科夫決策程序
馬爾科夫決策程序(Markov Decision Process,MDP)是強化學習的基礎,相比于多臂賭博機問題,馬爾科夫決策程序多了狀態轉移及其決策程序,
我們先來認識一下狀態、狀態轉移以及決策三個概念:
- 狀態
實際上狀態并沒有一個標準的定義,它可以是任何有助于馬爾科夫鏈做決策的量, - 狀態轉移
形象地說,把自己看著 Agent ,我們從早上醒來,看到的狀態是在臥室,刷牙時眼睛里看到的狀態是在衛生間,出門后是在路上,到辦公室后是在辦公室,Agent的狀態無時無刻不在改變, - 決策
所謂決策,就是Agent根據未來可能轉移到的狀態的好壞(通過Reward衡量),來決定是否要轉移到某個狀態,
下面就是一個馬爾科夫決策程序示意圖:

在上圖中,我們可以找出多條軌跡,用來描述Agent的行為,例如: τ 1 = S 1 → a = a 1 , r = r 1 S 2 → a = a 2 , r = r 2 S 3 → a = a 3 , r = r 3 S 4 τ 2 = S 1 → a = a 4 , r = r 4 S 3 → a = a 3 , r = r 3 S 4 \begin{aligned} \tau_1 & = S_1 \xrightarrow{a=a_1,r=r_1}S_2\xrightarrow{a=a_2,r=r_2}S_3\xrightarrow{a=a_3,r=r_3}S_4 \\ \tau_2 & = S_1 \xrightarrow{a=a_4,r=r_4}S_3\xrightarrow{a=a_3,r=r_3}S_4 \\ \end{aligned} τ1?τ2??=S1?a=a1?,r=r1? ?S2?a=a2?,r=r2? ?S3?a=a3?,r=r3? ?S4?=S1?a=a4?,r=r4? ?S3?a=a3?,r=r3? ?S4?? τ 2 \tau_2 τ2?沒有進入過狀態 S 2 S_2 S2?,可能是因為Agent認為要遲到了,從 S 1 S_1 S1?轉移狀態到 S 2 S_2 S2?的Reward太低,所以直接轉移狀態到了 S 3 S_3 S3?,
馬爾科夫決策程序的量化計算中有一個重要引數稱為折扣因子(Discount Factor) γ \gamma γ,之所以要引入這樣一個引數,有著以下三個理由:
- 有些馬爾可夫程序是帶環的,沒有起始,折扣因子可以避免無窮的反饋;
- 折扣因子可以使馬爾科夫程序模擬真實的人類行為,使馬爾科夫程序更加傾向于選擇近期的高Reward狀態;
- 折扣因子是可以調整的,例如當折扣因子設為0時,就相當于只關注了下一步反饋,當折扣因子設為1時,就相當于對未來并沒有折扣,未來的每一步獲得的Reward都是一樣的,
在有了Agent所處的狀態 S S S、折扣因子 γ \gamma γ、狀態轉移時的回報 R R R之后,我們就可以用貝爾曼方程來定義馬爾科夫決策程序的折扣累計回報期望值了:
- 基于狀態值函式
V
π
(
s
)
V_\pi(s)
Vπ?(s)的定義
在策略 π \pi π 下,狀態s的值函式定義為從狀態 S S S 出發,并采用策略 π \pi π 的折扣積累回報的期望 V π ( s ) = E π [ G t ∣ S t = s ] = E π [ ∑ k = 0 ∞ γ k R t + k + 1 ∣ S t = s ] \begin{aligned}V_\pi(s) &=\mathbb{E}_\pi[G_t|S_t=s] \\ &=\mathbb{E}_\pi[\sum_{k=0}^{\infty}\gamma^k R_{t+k+1}|S_t=s] \\ \end{aligned} Vπ?(s)?=Eπ?[Gt?∣St?=s]=Eπ?[k=0∑∞?γkRt+k+1?∣St?=s]? - 基于行為值函式
Q
π
(
s
,
a
)
Q_\pi(s,a)
Qπ?(s,a)的定義
在策略 π \pi π 下,在狀態s采取動作a的行為值函式定義為從狀態 S S S 出發,并采用策略 π \pi π 的折扣積累回報的期望 Q π ( s , a ) = E π [ G t ∣ S t = s , A t = a ] = E π [ ∑ k = 0 ∞ γ k R t + k + 1 ∣ S t = s , A t = a ] \begin{aligned}Q_\pi(s,a) &=\mathbb{E}_\pi[G_t|S_t=s,A_t=a] \\ &=\mathbb{E}_\pi[\sum_{k=0}^{\infty}\gamma^k R_{t+k+1}|S_t=s,A_t=a] \\ \end{aligned} Qπ?(s,a)?=Eπ?[Gt?∣St?=s,At?=a]=Eπ?[k=0∑∞?γkRt+k+1?∣St?=s,At?=a]?
假設有如下的馬爾科夫決策程序:
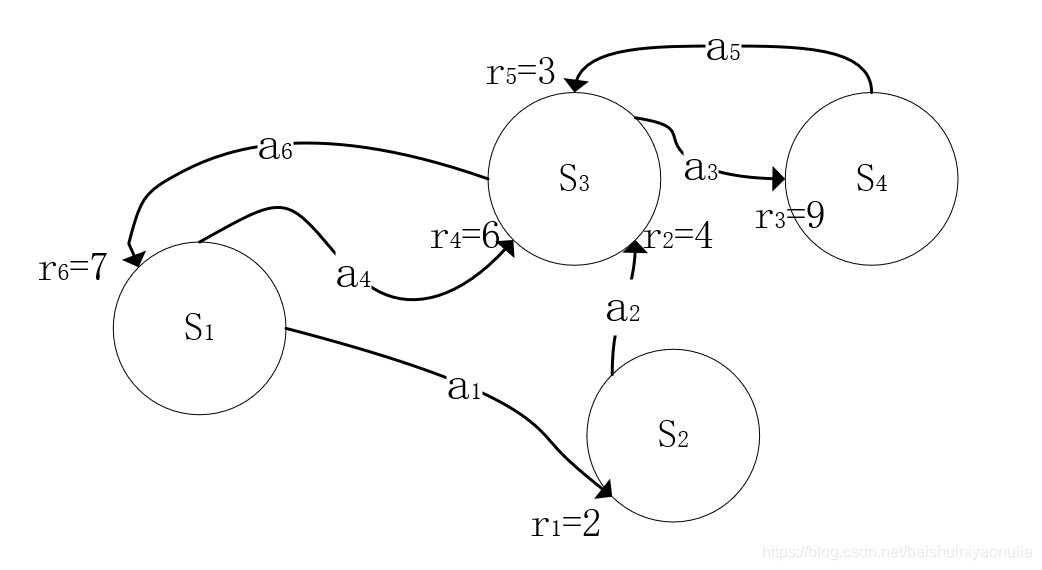
假設Agent正處于狀態
S
1
S_1
S1?,目標任務是Agent到達
S
4
S_4
S4?然后回到
S
1
S_1
S1?,則在
S
1
S_1
S1?時會有如下兩條軌跡可以完成該任務:
τ
1
=
S
1
→
a
=
a
1
,
r
=
2
S
2
→
a
=
a
2
,
r
=
4
S
3
→
a
=
a
3
,
r
=
9
S
4
→
a
=
a
5
,
r
=
3
S
3
→
a
=
a
6
,
r
=
7
S
1
\tau_1 = S_1\xrightarrow{a=a_1,r=2}S_2\xrightarrow{a=a_2,r=4}S_3\xrightarrow{a=a_3,r=9}S_4\xrightarrow{a=a_5,r=3}S_3\xrightarrow{a=a_6,r=7}S_1
τ1?=S1?a=a1?,r=2
?S2?a=a2?,r=4
?S3?a=a3?,r=9
?S4?a=a5?,r=3
?S3?a=a6?,r=7
?S1?
τ
2
=
S
1
→
a
=
a
4
,
r
=
6
S
3
→
a
=
a
3
,
r
=
9
S
4
→
a
=
a
5
,
r
=
3
S
3
→
a
=
a
6
,
r
=
7
S
1
\tau_2 = S_1\xrightarrow{a=a_4,r=6}S_3\xrightarrow{a=a_3,r=9}S_4\xrightarrow{a=a_5,r=3}S_3\xrightarrow{a=a_6,r=7}S_1
τ2?=S1?a=a4?,r=6
?S3?a=a3?,r=9
?S4?a=a5?,r=3
?S3?a=a6?,r=7
?S1?設折扣因子的值為0.2,則這兩條軌跡的折扣累計回報期望為:
Q
π
(
s
,
a
)
τ
1
=
E
π
[
G
t
∣
S
t
=
s
,
A
t
=
a
]
=
E
π
[
∑
k
=
0
∞
γ
k
R
t
+
k
+
1
∣
S
t
=
s
,
A
t
=
a
]
=
1
5
(
0.
2
0
×
2
+
0.
2
1
×
4
+
0.
2
2
×
9
+
0.
2
3
×
3
+
0.
2
4
×
7
)
=
0.63904
\begin{aligned}Q_\pi(s,a)_{\tau_1} &=\mathbb{E}_\pi[G_t|S_t=s,A_t=a] \\ &=\mathbb{E}_\pi[\sum_{k=0}^{\infty}\gamma^k R_{t+k+1}|S_t=s,A_t=a] \\ &=\frac{1}{5}(0.2^0\times 2 + 0.2^1\times4+0.2^2\times9+0.2^3\times3+0.2^4\times7)\\ &=0.63904 \\ \end{aligned}
Qπ?(s,a)τ1???=Eπ?[Gt?∣St?=s,At?=a]=Eπ?[k=0∑∞?γkRt+k+1?∣St?=s,At?=a]=51?(0.20×2+0.21×4+0.22×9+0.23×3+0.24×7)=0.63904?
Q
π
(
s
,
a
)
τ
2
=
E
π
[
G
t
∣
S
t
=
s
,
A
t
=
a
]
=
E
π
[
∑
k
=
0
∞
γ
k
R
t
+
k
+
1
∣
S
t
=
s
,
A
t
=
a
]
=
1
4
(
0.
2
0
×
6
+
0.
2
1
×
9
+
0.
2
2
×
3
+
0.
2
3
×
7
)
=
1.994
\begin{aligned}Q_\pi(s,a)_{\tau_2} &=\mathbb{E}_\pi[G_t|S_t=s,A_t=a] \\ &=\mathbb{E}_\pi[\sum_{k=0}^{\infty}\gamma^k R_{t+k+1}|S_t=s,A_t=a] \\ &=\frac{1}{4}(0.2^0\times 6 + 0.2^1\times9+0.2^2\times3+0.2^3\times7)\\ &=1.994 \\ \end{aligned}
Qπ?(s,a)τ2???=Eπ?[Gt?∣St?=s,At?=a]=Eπ?[k=0∑∞?γkRt+k+1?∣St?=s,At?=a]=41?(0.20×6+0.21×9+0.22×3+0.23×7)=1.994?
顯然,當 Agent 處于狀態 S 1 S_1 S1? 時,應當采取動作 a 4 a_4 a4?才能獲取更高的 Reward,
3. 經典強化學習演算法和深度強化學習
3.1. 經典強化學習演算法
所謂經典強化學習演算法,指的是表格型的強化學習演算法,這種演算法適用于的狀態空間離散有限的馬爾科夫決策程序,有限代表有終止狀態,這樣 q ( s , a ) q_(s,a) q(?s,a)或者 v ( s ) v_(s) v(?s)的值均可以存盤在一張表格中,這就是表格型方法的名稱由來,
例如一張Q表格,用來存盤
q
(
s
,
a
)
q(s,a)
q(s,a):
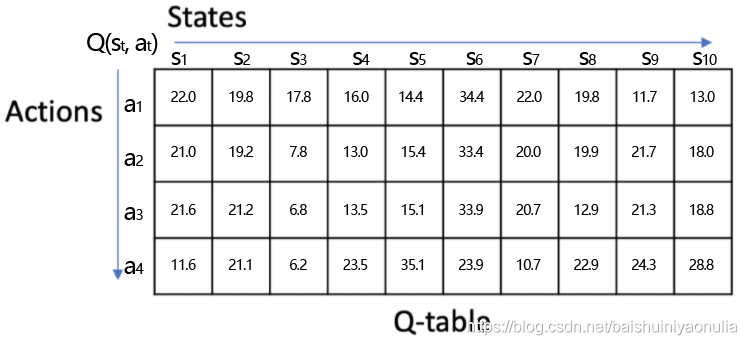
上表中Q函式的值表示當Agent在某個State時選擇了某個Action,后續總共能得到多少Reward,根據這個表格,Agent就可以知道在當前的State下選擇哪個Action可以得到更大的Q值,
例如在Agent處于狀態 s 4 s_4 s4?時,選擇動作 a 4 a_4 a4?就會有最大的Q值: Q ( s t = s 4 , a t = a 4 ) = 23.5 Q(s_t=s_4,a_t=a_4)=23.5 Q(st?=s4?,at?=a4?)=23.5
常見的表格型強化學習方法有:
- 動態規劃 Dynamic Programing
動態規劃 DP 是一種model-based的強化學習方法,它使用價值函式來結構化地組織對最優策略的搜索,由貝爾曼最優化方程計算最優價值函式,從而得到最優策略,DP又分為包括策略迭代、價值迭代兩種方法 - 蒙特卡洛 Monte Carlo
蒙特卡洛 MC 是一種model-free的強化學習方法,它從馬爾可夫決策程序采樣樣本的經驗回報中學習價值函式, - 時序差分 Temporal-Difference
時序差分 TD 是一種model-free的強化學習方法,它結合了MC與DP演算法,采用自舉法(更新基于已存在的估計)更新,TD中兩個著名的方法是Saras(同軌時序差分控制)、Q-Learning(離軌時序差分控制)
推薦閱讀:強化學習 - 基于表格型的求解方法
3.2. 深度強化學習
深度強化學習方法就是利用神經網路提取輸入特征 或 用神經網路擬合值函式 Q ( s , a ) Q(s,a) Q(s,a)和 V ( s ) V(s) V(s),它適用于狀態空間連續或狀態數無窮多的馬爾科夫決策程序,
之所以提出深度強化學習方法,是因為:
- 神經網路具有很強的特征提取能力
這樣的能力使得強化學習演算法可以直接從真實世界接收輸入,例如看游戲螢屏、看棋盤, - 神經網路具有很強的泛化能力
神經網路可以通過擬合離散資料泛化得到連續的空間,例如下圖: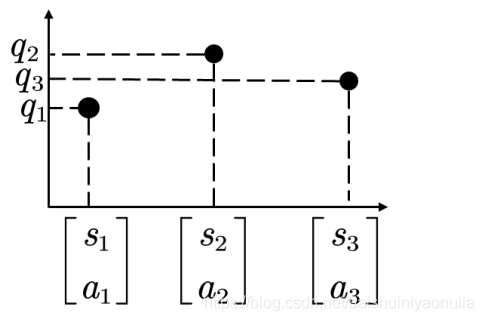
神經網路可以只根據這三個 q ( s , a ) q(s,a) q(s,a)值取泛化得到連續空間上的無窮多 q ( s , a ) q(s,a) q(s,a)值,
常見的深度強化學習演算法有:
- Policy Gradient
包括:PG (Policy Gradient)、
TRPO (Trust Region Policy Optimization)、
PPO (Proximal Policy Optimization)、
DPPO (Distributed Proximal Policy Optimization); - Deep Q Network
包括:DQN (Deep Q Network)、
Dueling DQN (Dueling Deep Q Network)、
Double DQN (Double Deep Q Network); - Actor-Critic
包括:AC (Actor-Critic)、
A3C (Asynchronous Advantage Actor-Critic)、
DDPG (Deep Deterministic Policy Gradient) 、
TD3 (Twin Delayed Deep Deterministic policy gradient algorithm)、
SAC (Soft Actor-Critic);
4. 強化學習的學習資料
視頻:
- 【莫煩Python】強化學習 Reinforcement Learning
- 【李宏毅】2020 最新課程 (完整版) 強化學習
- Stanford CS234: Reinforcement Learning
書籍:
- Reinforcement Learning: An Introduction (Second Edition)
- 深入淺出強化學習:原理入門
論文:
- Reinforcement Learning:A Survey
- Reinforcement Learning An Introduction
- A Brief Survey of Deep Reinforcement Learning
- Deep Reinforcement Learing: An Overview
- 主流強化學習演算法論文綜述:DQN、DDPG、TRPO、A3C、PPO、SAC、TD3
這一節推薦了很多相關資料,之所以要看這么多,不是因為強化學習本身很復雜,是因為不同人有不同理解,從不同角度對強化學習進行全方位的學習,才能有更深入和正確的理解,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/274824.html
標籤:其他