文章目錄
- 基于鳶尾花(iris)資料集的資料可視化
- 1、資料匯入
- 2、查看樣本資料
- 3、特征與標簽組合的散點可視化
- 3.1、 散點圖
- 3.2、 箱型圖
- 3.2、 三維散點圖
關于比賽最新進展&更多的知識點解讀
關注公眾號“不太靈光的程式員”
基于鳶尾花(iris)資料集的資料可視化
資料挖掘是從大量歷史資料中抽取潛在的,有價值的知識或規則的程序,資料可視化對于快速分析資料,表示高維資料方面非常直觀,有效,
我們選擇鳶花資料(iris)進行方法的嘗試訓練,該資料集一共包含5個變數,其中4個特征變數,1個目標分類變數,
共有150個樣本,目標變數為 花的類別 其都屬于鳶尾屬下的三個亞屬,分別是山鳶尾 (Iris-setosa),變色鳶尾(Iris-versicolor)和維吉尼亞鳶尾(Iris-virginica),
包含的三種鳶尾花的四個特征,分別是花萼長度(cm)、花萼寬度(cm)、花瓣長度(cm)、花瓣寬度(cm),這些形態特征在過去被用來識別物種,
| 變數 | 描述 |
|---|---|
| sepal length | 花萼長度(cm) |
| sepal width | 花萼寬度(cm) |
| petal length | 花瓣長度(cm) |
| petal width | 花瓣寬度(cm) |
| target | 鳶尾的三個亞屬類別,‘setosa’(0), ‘versicolor’(1), ‘virginica’(2) |
1、資料匯入
# coding=gbk
# 基礎函式庫
import numpy as np
import pandas as pd
# 繪圖函式庫
import matplotlib.pyplot as plt
import seaborn as sns
# 我們利用 sklearn 中自帶的 iris 資料作為資料載入,并利用Pandas轉化為DataFrame格式
from sklearn.datasets import load_iris
?
# 得到資料特征
data = load_iris()
# 得到資料對應的標簽
iris_target = data.target
# 利用Pandas轉化為DataFrame格式
iris_features = pd.DataFrame(data=data.data, columns=data.feature_names)
# 利用.info()查看資料的整體資訊
iris_features.info()
2、查看樣本資料
# 進行簡單的資料查看,我們可以利用 .head() 頭部.tail()尾部
# 可以設定查看的資料條數
print(iris_features.head(20))
print(iris_features.tail(20))
# 查看是否存在缺失值
print(pd.isnull(iris_features))
# 其對應的類別標簽為,其中0,1,2分別代表'setosa', 'versicolor', 'virginica'三種不同花的類別,
print(iris_target)
# 利用value_counts函式查看每個類別數量
print(pd.Series(iris_target).value_counts())
# 對于特征進行一些統計描述
print(iris_features.describe())
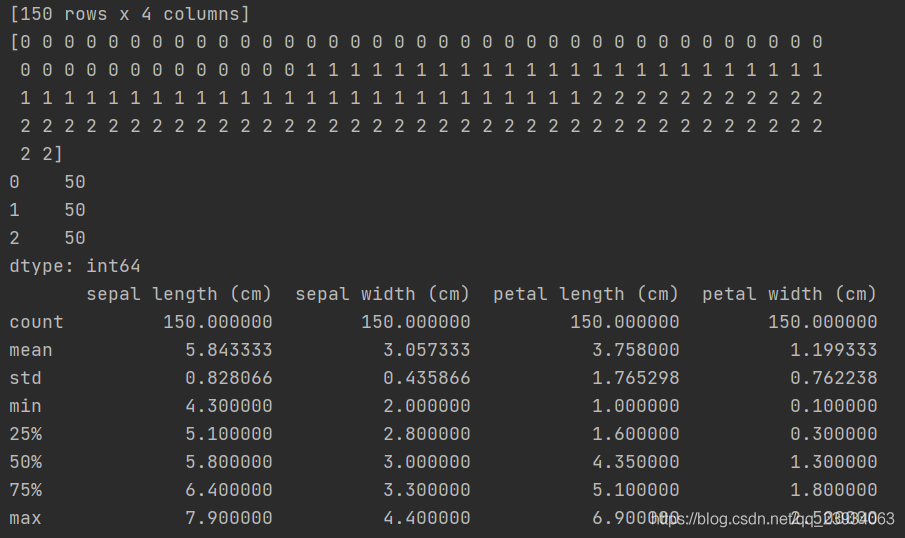
3、特征與標簽組合的散點可視化
3.1、 散點圖
散點圖是指資料點在直角坐標系平面上的分布圖,散點圖表示因變數隨自變數而變化的大致趨勢,通常用于回歸分析,據此可以選擇合適的函式對資料點進行回歸擬合,
多組散點圖通常用于聚類,能直觀地看出每組資料點的分布,
從下面的圖片可以發現,在2D情況下不同的特征組合對于不同類別的花的散點分布,以及大概的區分能力,
# 合并標簽和特征資訊
# 進行淺拷貝,防止對于原始資料的修改
iris_all = iris_features.copy()
iris_all['target'] = iris_target
?
# 特征與標簽組合的散點可視化
sns.pairplot(data=iris_all, diag_kind='hist', hue='target')
plt.show()
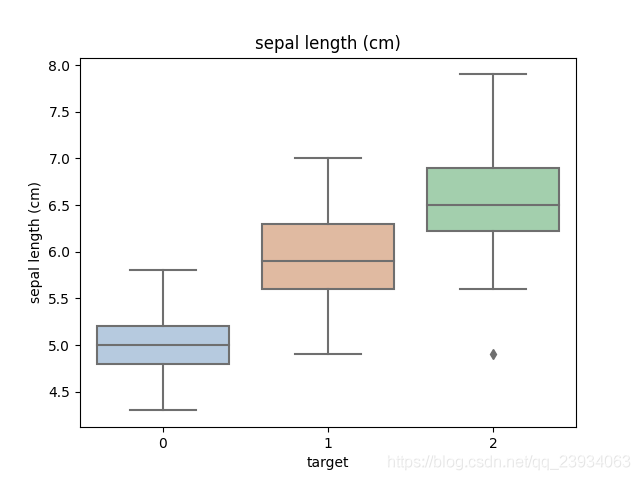
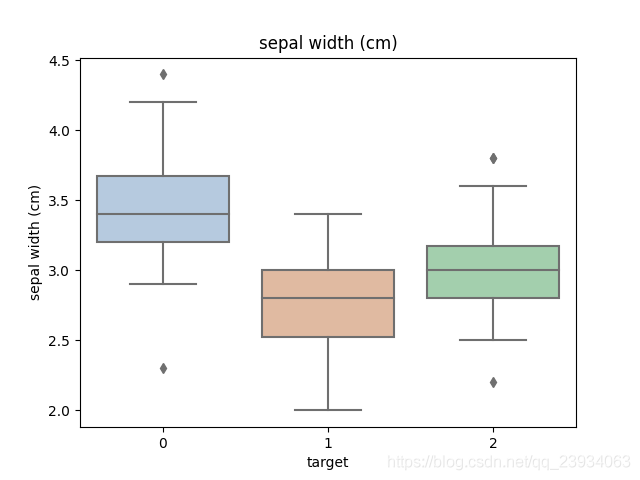
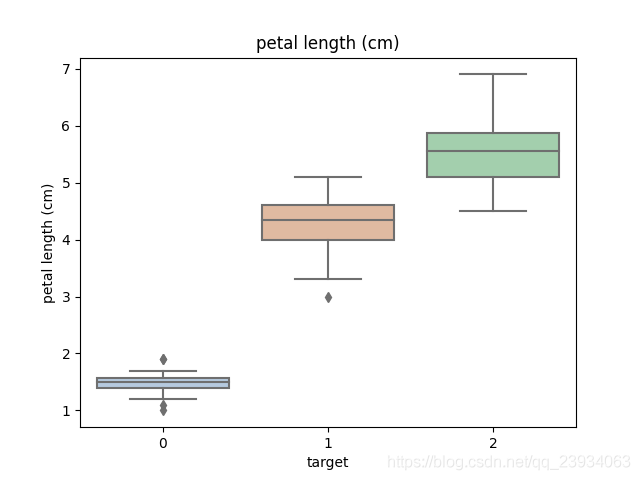
3.2、 箱型圖
箱線圖(Boxplot)也稱箱須圖(Box-whisker Plot),它是用一組資料中的最小值、第一四分位數、中位數、第三四分位數和最大值來反映資料分布的中心位置和散布范圍,可以粗略地看出資料是否具有對稱性,通過將多組資料的箱線圖畫在同一坐標上,則可以清晰地顯示各組資料的分布差異,為發現問題、改進流程提供線索,
箱線圖作為描述統計的工具之一,其功能有獨特之處,主要有以下幾點:
1.直觀明了地識別資料中的例外值
2.利用箱線圖判斷資料批的偏態和尾重
3.利用箱線圖比較幾批資料的形狀
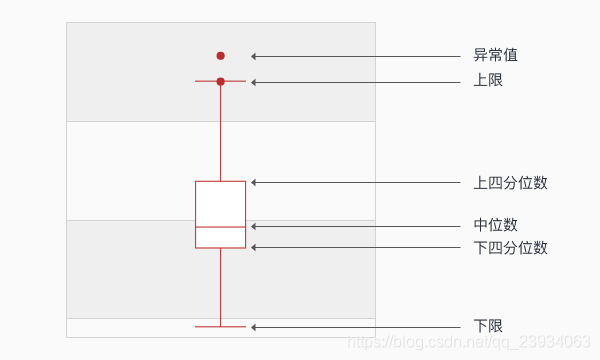
利用箱型圖我們也可以得到不同類別在不同特征上的分布差異情況,
for col in iris_features.columns:
sns.boxplot(x='target', y=col, saturation=0.5, palette='pastel', data=iris_all)
plt.title(col)
plt.show()
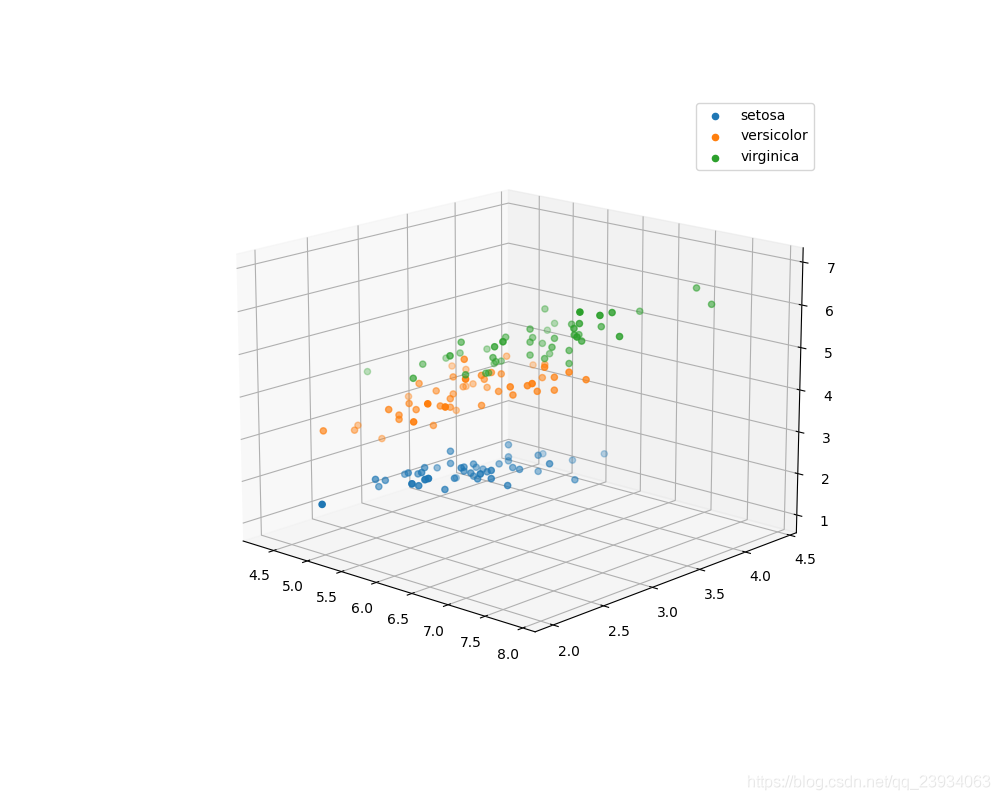
3.2、 三維散點圖
在盡量保證原始資料分布不變的情況下,使用質量較高的可視化樣本,通過對約簡后的資料集進行可視化,來達到有效減少可視化時間的目的,
同時三維模型還支持用戶互動性操作,
# 選取其前三個特征繪制三維散點圖
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, projection='3d')
iris_all_class0 = iris_all[iris_all['target'] == 0].values
iris_all_class1 = iris_all[iris_all['target'] == 1].values
iris_all_class2 = iris_all[iris_all['target'] == 2].values
# 'setosa'(0), 'versicolor'(1), 'virginica'(2)
ax.scatter(iris_all_class0[:, 0], iris_all_class0[:, 1], iris_all_class0[:, 2], label='setosa')
ax.scatter(iris_all_class1[:, 0], iris_all_class1[:, 1], iris_all_class1[:, 2], label='versicolor')
ax.scatter(iris_all_class2[:, 0], iris_all_class2[:, 1], iris_all_class2[:, 2], label='virginica')
plt.legend()
plt.show()
通過對散點圖、箱型圖、三維散點圖的分析,我們可以更直觀的了解資料,
我們從可視化的可以發現’setosa’(0)特征的邊界清晰,‘versicolor’(1)和 ‘virginica’(2)這兩個類別的特征,其特征的邊界具有一定的模糊性(邊界類別混雜,沒有明顯區分邊界),對后面建模的預測能力上會有影響,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/274878.html
標籤:其他