文章目錄
- 1.先決條件
- 1.1 支持平臺
- 1.2 jdk及hadoop安裝包
- 1.3 Xshell 7與Xftp 7工具安裝
- 2.具體安裝步驟
- 2.1 網路配置
- 2.2 Xshell連接
- 2.3 Xftp傳輸
- 2.4 jdk環境配置
- 2.5 ssh服務配置
- 2.6 hadoop配置
- 2.7 hadoop單機模式操作方法
1.先決條件
1.1 支持平臺
GNU/Linux是產品開發和運行的平臺, Hadoop已在有2000個節點的GNU/Linux主機組成的集群系統上得到驗證,
所以首先我們需要下載Linux的ISO安裝包安裝,具體安裝參考我的上一篇博客:
VirtualBox虛擬機以及CentOS系統的安裝【詳細】
1.2 jdk及hadoop安裝包
可以去官網下載或者下載我上傳的資源,我所用的具體版本如下圖所示:

資源鏈接
提取碼:2kd5
1.3 Xshell 7與Xftp 7工具安裝
主要作用是用Xshell 7進行虛擬機各項操作,用Xftp 7將本地的jdk及hadoop安裝包傳輸到虛擬機上
兩個工具均可以在官網下載,選擇個人使用方式可以免費下載
2.具體安裝步驟
2.1 網路配置
需要注意的是在參考上篇博客安裝CentOS設定網路連接時兩個網關都要打開,具體如下:
啟動之前進行網路設定
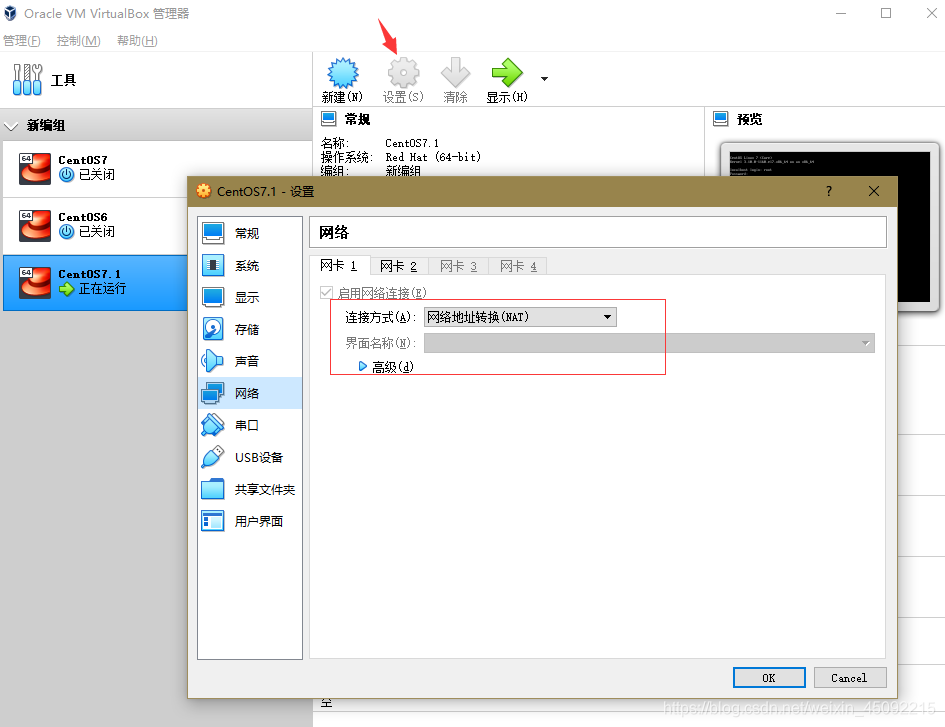
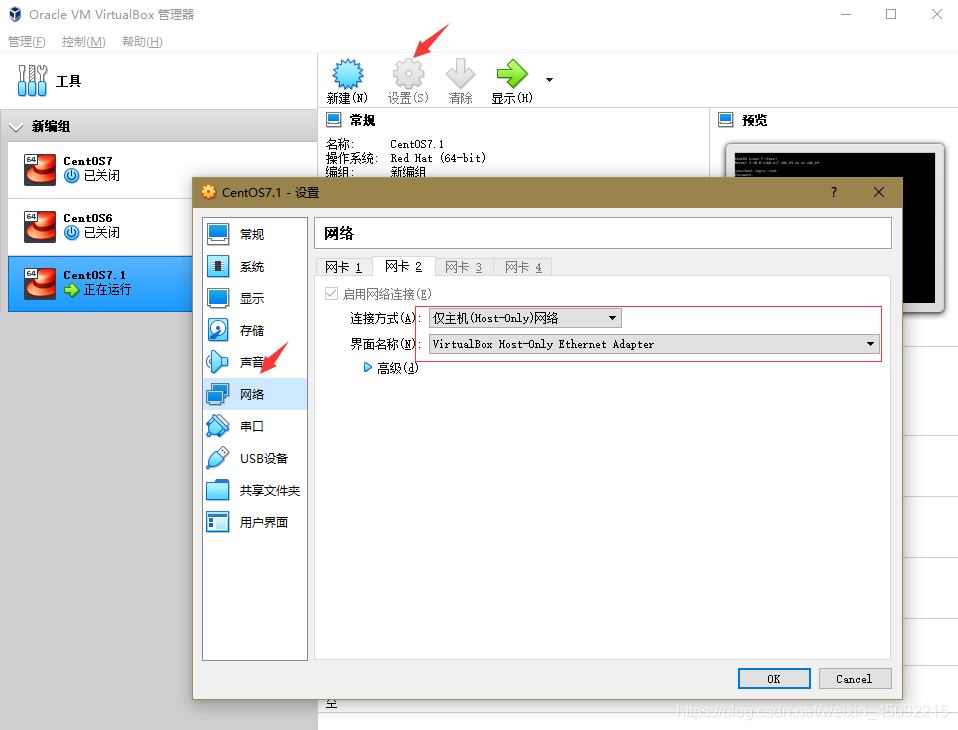
然后點擊啟動,進行到下列步驟時注意將兩個網關打開并對第二個網路進行手動配置
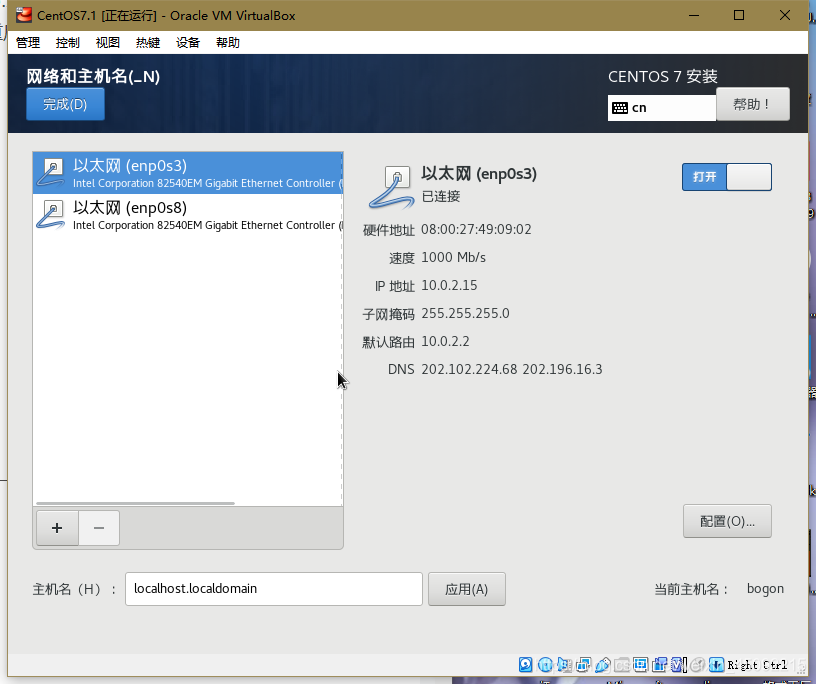
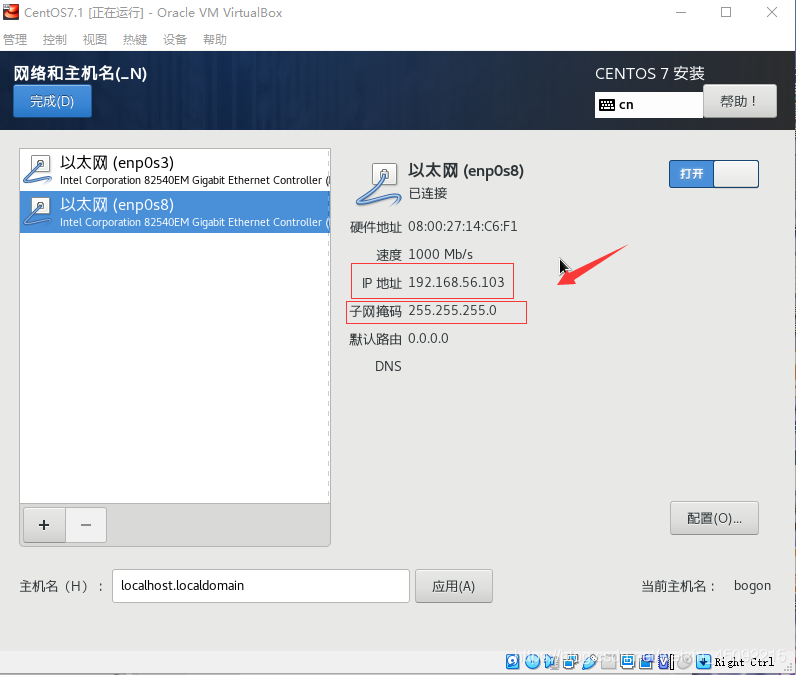
點擊配置,手動配置Ipv4,將框內地址填入對用項,點擊保存,
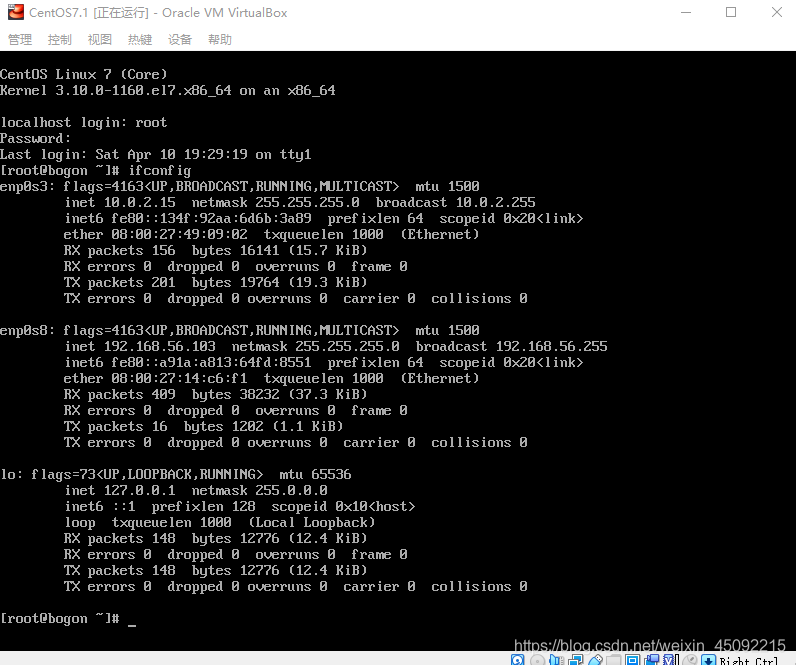
Centos安裝后,點擊啟動,在終端登錄root賬戶后,輸入ifconfig命令,檢查網路配置,如果不存在,執行命令yum install net-tools.x86_64,彈出y/n的話,選擇y,
執行
vi /etc/sysconfig/network-scripts/ifcfg-enp0s8
把onboot=no改成yes
點擊insert鍵(即鍵盤i鍵),上下移動到那里改好之后,按esc建退出編輯模式,然后再按:wq就可以保存退出了,注意有:
不出意外,網路已經配置好了,
重啟虛擬機或者重啟網卡服務
service network restart
登錄后 再次輸入ifconfig命令,已經有了反饋資訊,如圖將框內IP地址記下
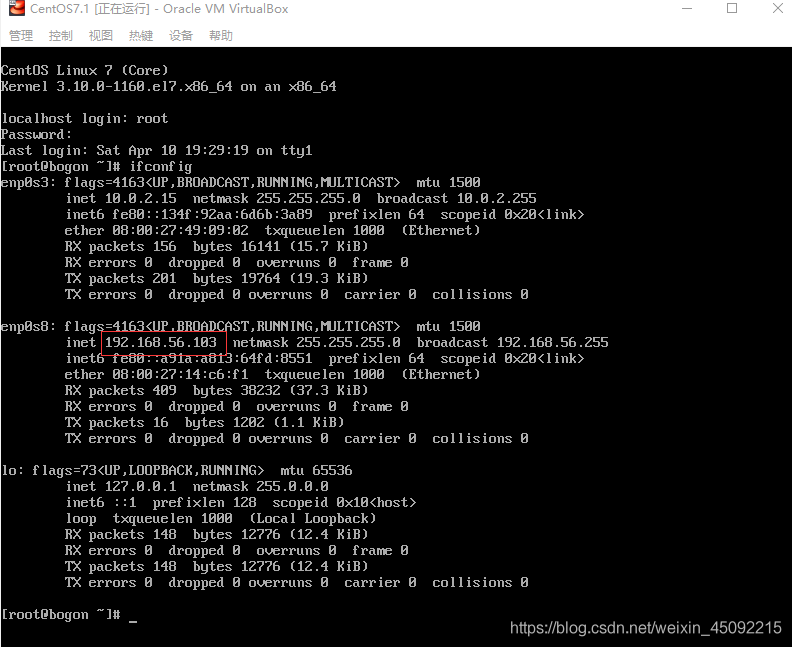
2.2 Xshell連接
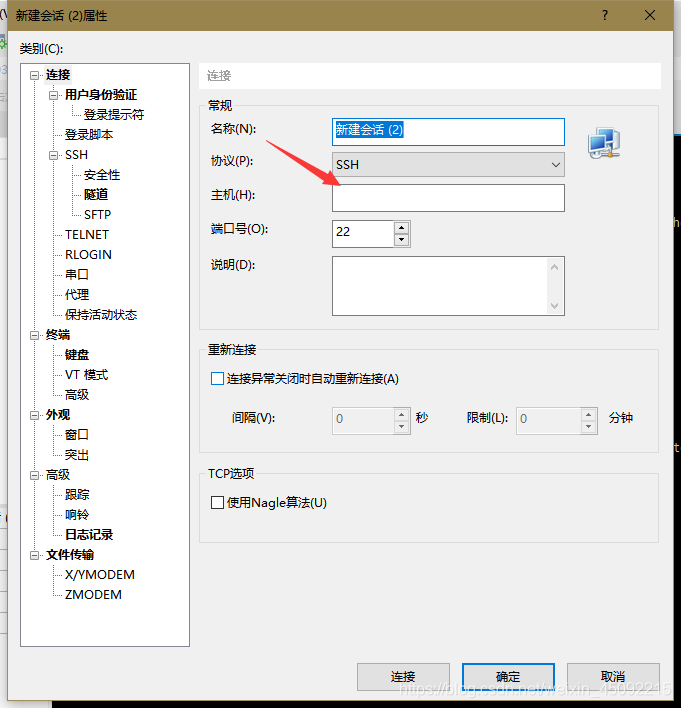
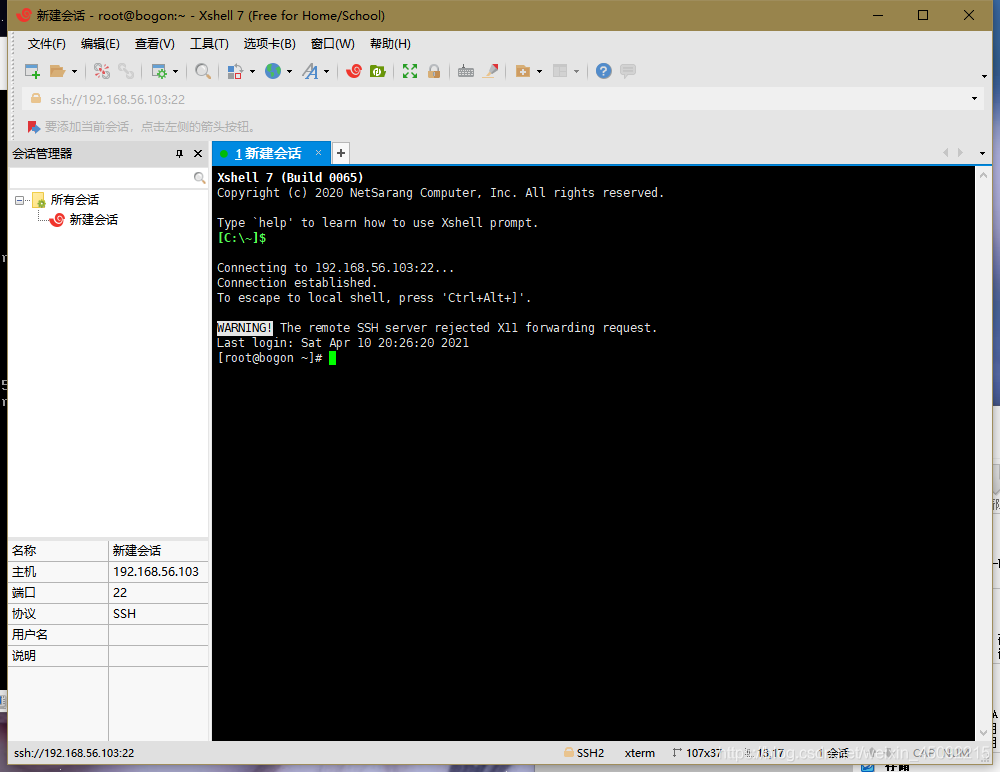
打開Xshell,新建連接,將IP地址寫入下圖框內,即可在本地建立與虛擬機的連接,后續對虛擬機的各項操作均可在Xshell終端中進行,
2.3 Xftp傳輸
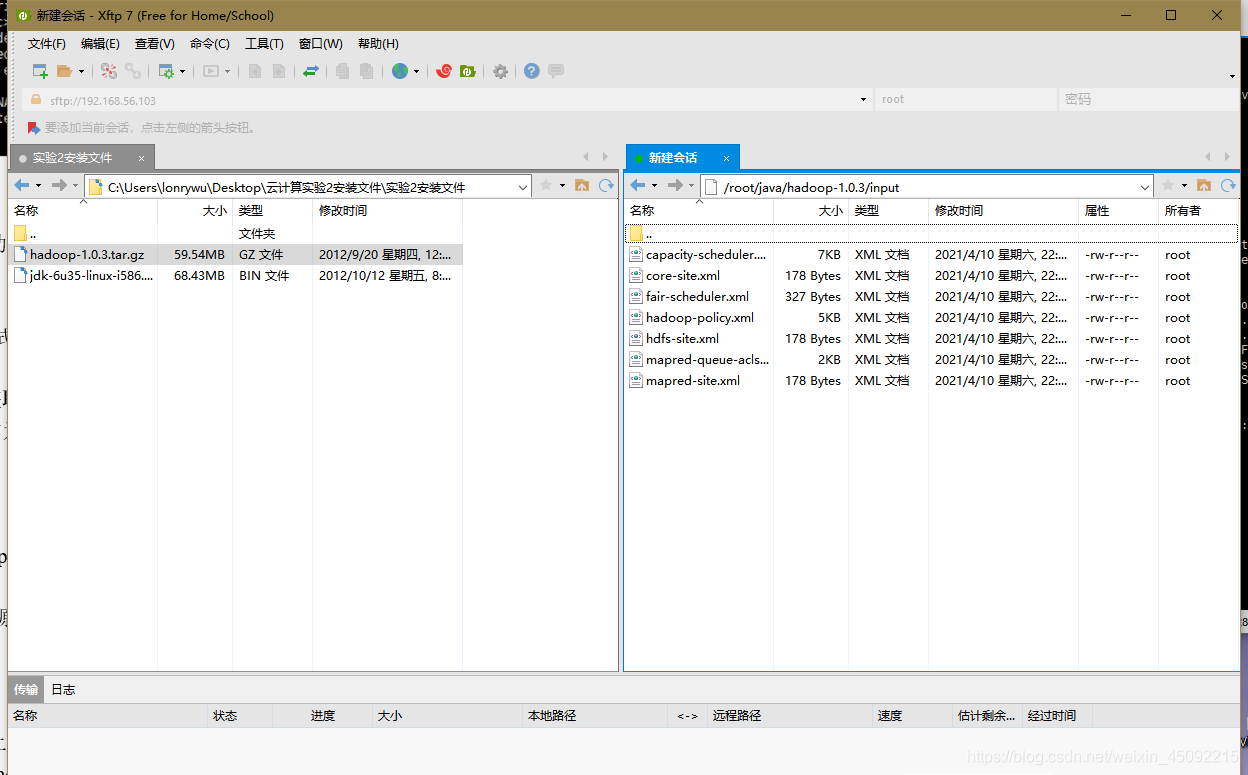
點擊下圖按鈕,新建檔案傳輸,自動呼叫Xftp進行檔案傳輸
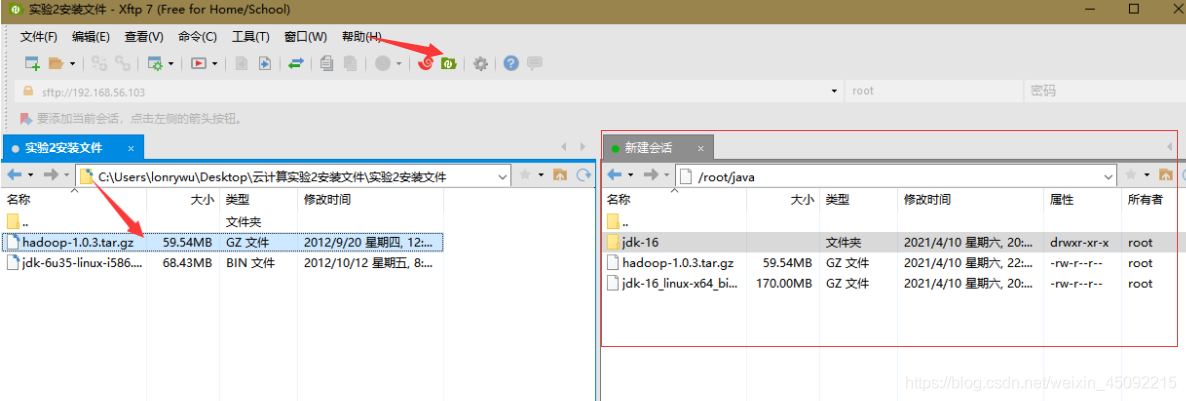
在右側root檔案夾下新建java子檔案夾,找到本地檔案右鍵->傳輸,即可將兩個壓縮包上傳到虛擬機
2.4 jdk環境配置
輸入以下命令檢測是否默認安裝jdk,沒有反饋資訊說明沒有安裝
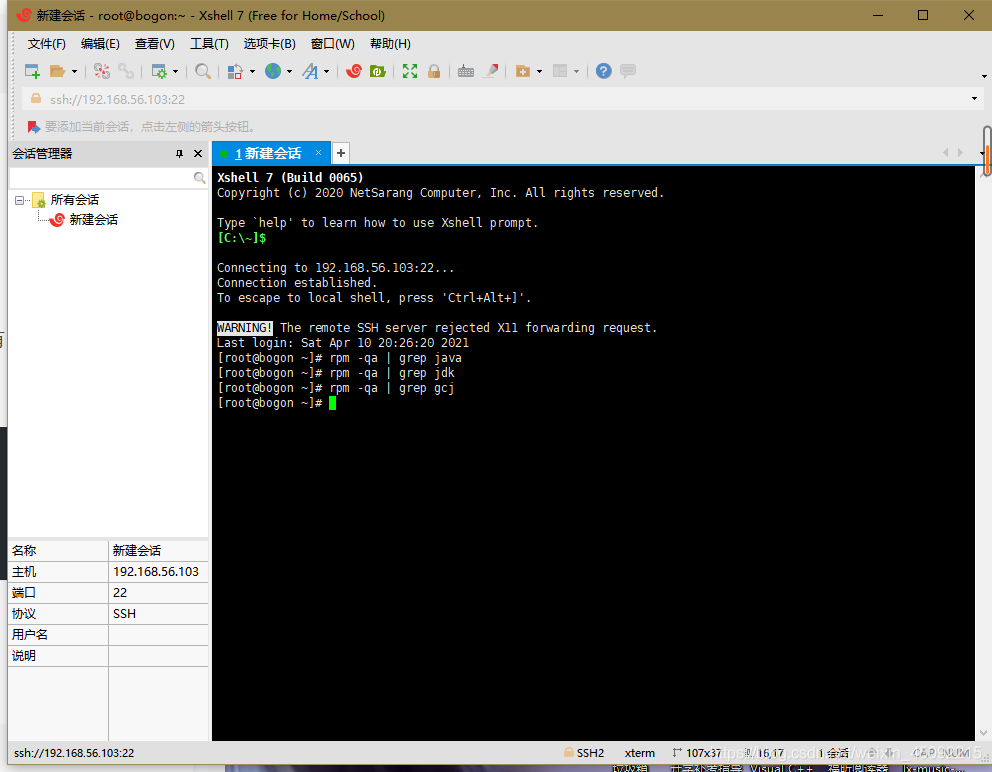
使用
> cd 對應檔案夾路徑
將目錄切換到java子檔案夾下,
使用如下命令開始解壓jdk壓縮包
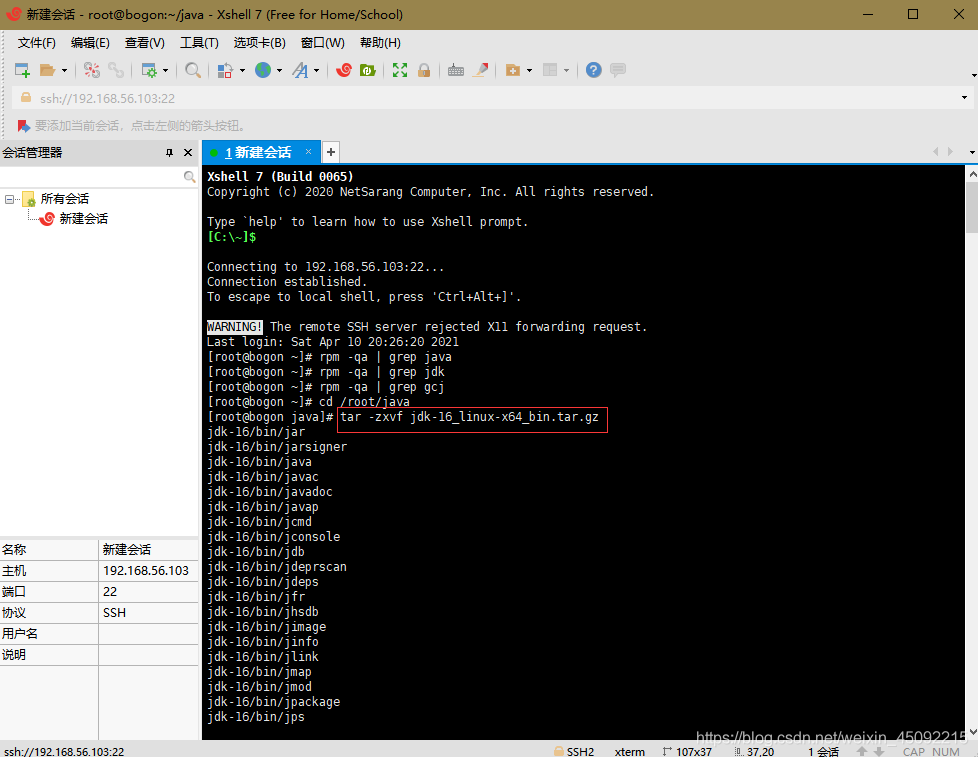
通過/etc/profile 配置環境變數
[root@bogon ~]# vi /etc/profile
進入編輯模式(i),添加以下代碼,然后保存退出(esc+:+wq)
#最后添加以下內容,注意查看自己的路徑及jdk版本
export JAVA_HOME=/root/java/jdk-16
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
讓/etc/profile檔案修改后立即生效 ,可以使用如下命令:
[root@bogon ~]# source /etc/profile
檢測是否安裝成功:
[root@bogon ~]# java -version

2.5 ssh服務配置
ssh 必須安裝并且保證 sshd一直運行,以便用Hadoop 腳本管理遠端Hadoop守護行程
檢查是否安裝ssh服務:
> [root@bogon ~]# rpm -qa|grep ssh
若已經安裝會顯示相應版本

沒有安裝,使用以下命令安裝
[root@bogon ~]# yum install openssh-server
開啟sshd服務
[root@bogon ~]# sudo service sshd start
為了免去每次開啟 CentOS 時,都要手動開啟 sshd 服務,可以將 sshd 服務添加至自啟動串列中,輸入
[root@bogon ~]# systemctl enable sshd.service
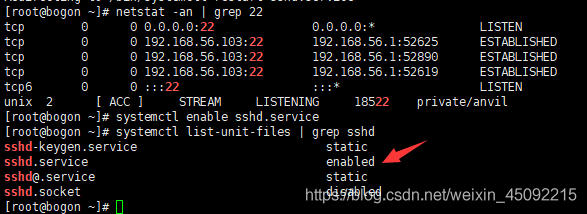
可以通過輸入
[root@bogon ~]# systemctl list-unit-files | grep sshd
查看是否開啟了sshd 服務自啟動
2.6 hadoop配置
為了獲取Hadoop的發行版,從Apache的某個鏡像服務器上下載最近的穩定發行版,
這里我們使用安裝包中的穩定版hadoop-1.0.3.tar.gz
如之前解壓jdk操作一樣,將放置在java檔案夾下的hadoop-1.0.3.tar.gz解壓
具體操作為終端切換到java路徑下,使用以下命令解壓壓縮包
tar -zxvf hadoop-1.0.3.tar.gz
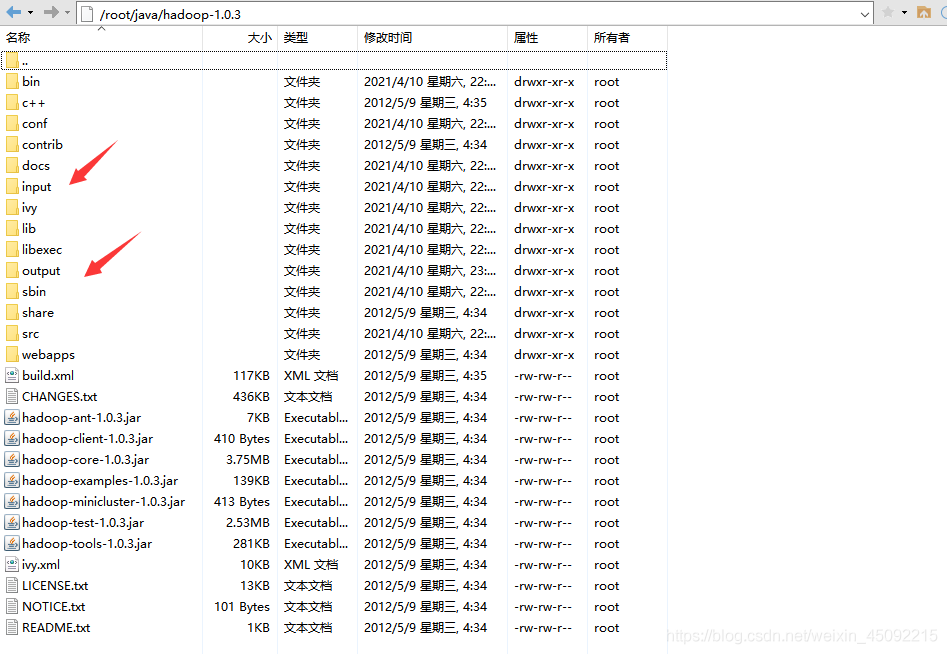
解壓結果如下
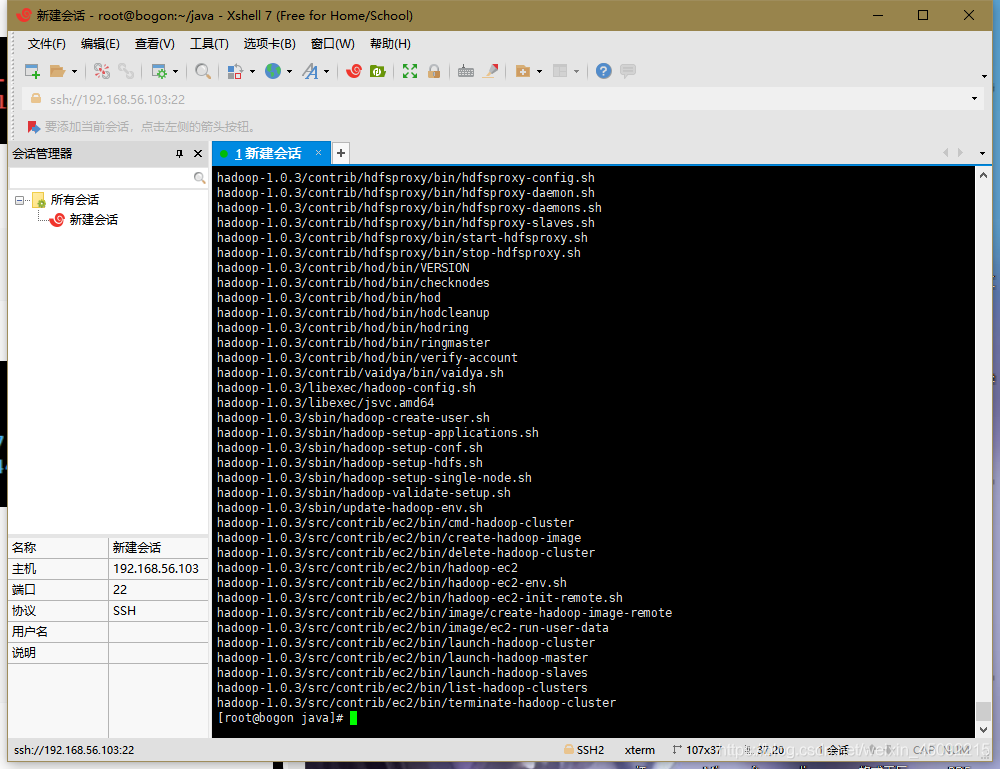
嘗試如下命令:
[root@bogon java]# cd /root/java/hadoop-1.0.3
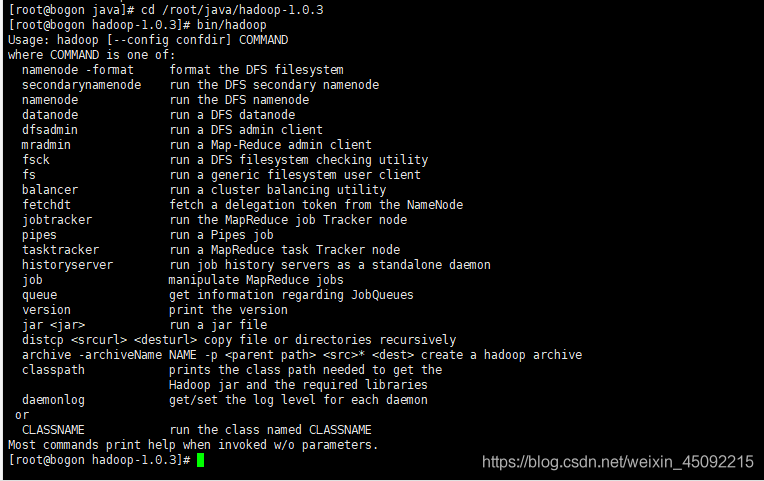
[root@bogon hadoop-1.0.3]# bin/hadoop
將會顯示hadoop 腳本的使用檔案
2.7 hadoop單機模式操作方法
默認情況下,Hadoop被配置成以非分布式模式運行的一個獨立Java行程,這對除錯非常有幫助,
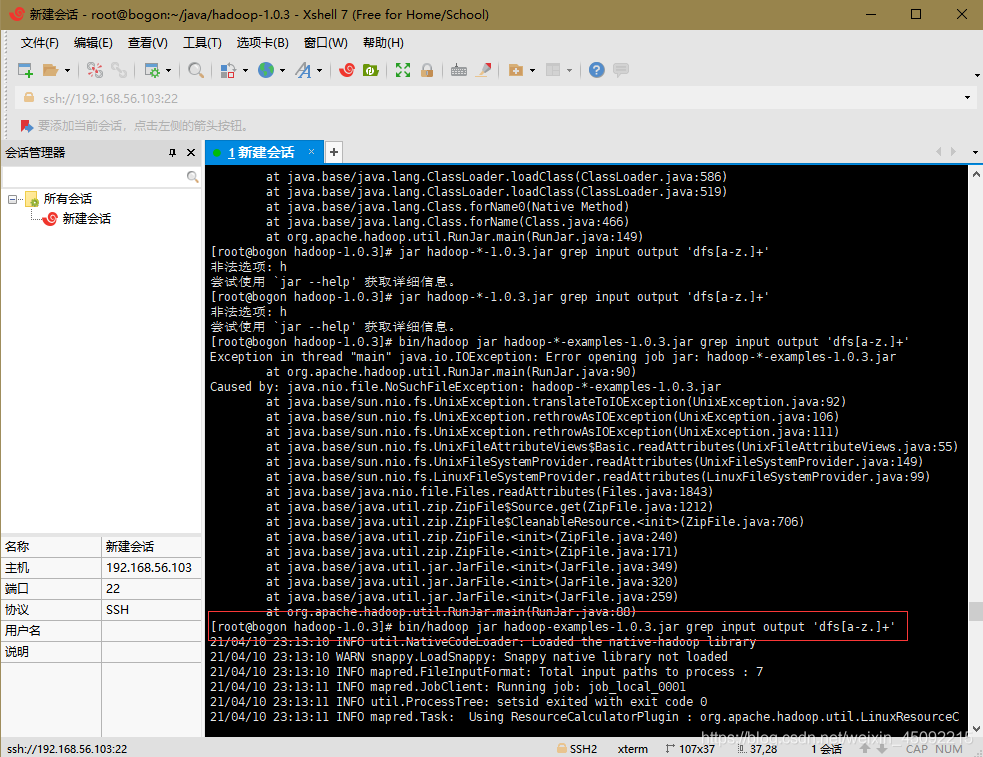
以下命令即運行了一次hadoop程式并獲取了輸出,
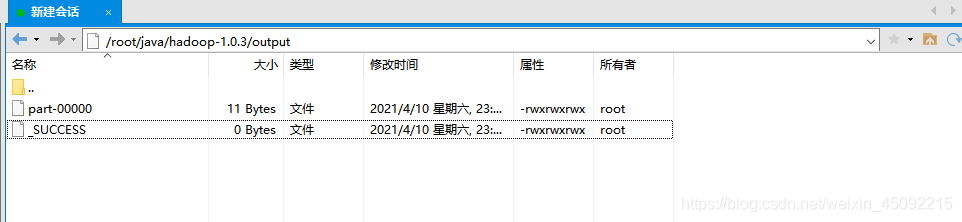
下面的實體將已解壓的 conf 目錄拷貝作為輸入,查找并顯示匹配給定正則運算式的條目,輸出寫入到指定的output目錄
[root@bogon hadoop-1.0.3]# mkdir input
[root@bogon hadoop-1.0.3]# cp conf/*.xml input
[root@bogon hadoop-1.0.3]# bin/hadoop jar hadoop-examples-1.0.3.jar grep input output 'dfs[a-z.]+'
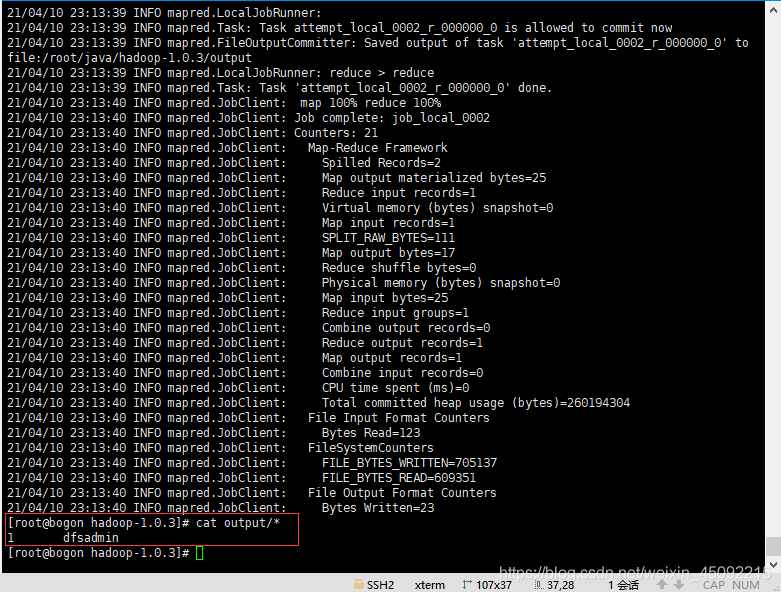
[root@bogon hadoop-1.0.3]# cat output/*
以下顯示該hadoop程式運行結果
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/275101.html
標籤:其他
上一篇:私有云的搭建(永久掛載)
下一篇:5G NSA網路注冊流程