說到ConcurrentHashMap,首先就要聊聊HashMap了
HashMap
HashMap的原始碼決議看這里
JDK1.8之前
HashMap的底層是陣列+鏈表結合在一起使用,
- HashMap 通過 key 的hashCode 經過哈希函式處理過后得到 hash 值;
- 然后通過 (n - 1) & hash 判斷當前元素存放的位置(n 指的是陣列的長度);
- 如果當前位置存在元素的話,就判斷該元素與要存入的元素的 hash值以及 key是否相同;
- 如果相同的話,直接覆寫;
- 不相同就通過拉鏈法解決沖突,
JDK1.8之后
HashMap的底層資料結構為陣列+鏈表+紅黑樹實作
當鏈表的長度大于閾值(默認為8)時,將鏈表轉化為紅黑樹,以減少搜索的時間,
將鏈表轉換成紅黑樹前會判斷,如果當前陣列的長度小于 64,那么會選擇先進行陣列擴容,而不是轉換為紅黑樹,
ConcurrentHashMap
JDK5中添加了新的concurrent包,在執行緒安全的基礎上提供了更好的寫并發能力,但同時降低了對讀一致性的要求,
ConcurrentHashMap是java.util.concurrent下的類;
在并發編程中,ConcurrentHashMap是一個經常被使用的資料結構,它的實際與實作非常精巧,大量利用volatile,final,CAS等技術來減少鎖競爭對于性能的影響,
簡單的對比
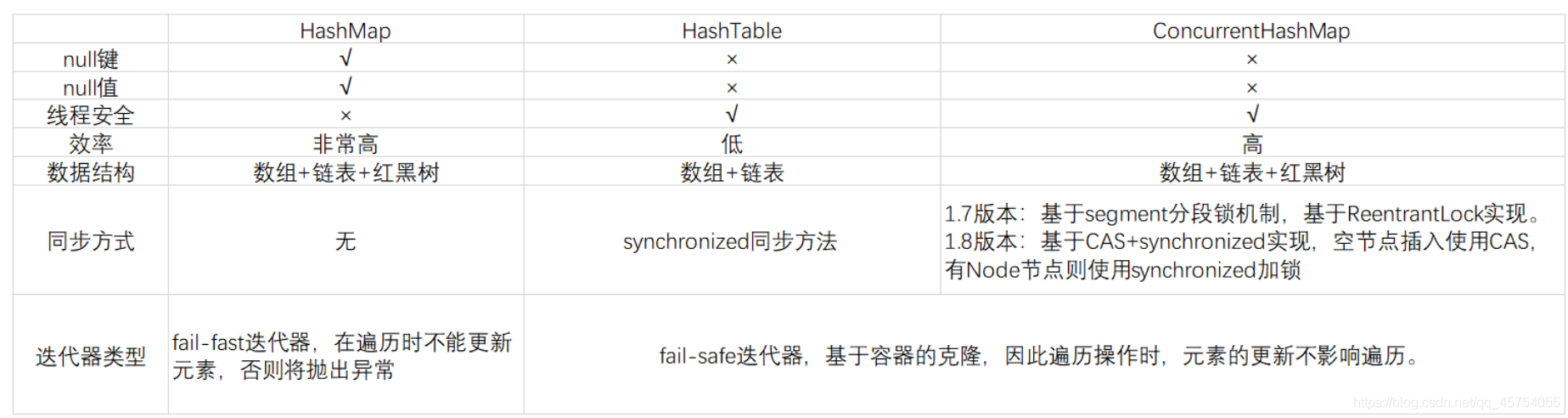
- HashTable 是一個執行緒安全的類,它使用synchronized來鎖住整張Hash表來實作執行緒安全,每次鎖住整張表讓執行緒獨占,相當于所有執行緒進行讀寫時都去競爭同一把鎖,效率比較低
- HashMap 不是一個執行緒安全的類
- ConcurrentHashMap可以做到讀取資料不加鎖,并且其內部的結構可以讓其在進行寫操作的時候能夠將鎖的粒度保持地盡量地小,允許多個修改操作并發進行,其關鍵在于使用了鎖分離技術,它使用了多個鎖來控制對hash表的不同部分進行的修改,只要不爭奪同一把鎖,它們就可以并發進行,
JDK1.7

- 底層的資料結構還是陣列+鏈表,鏈表的結點是HashEntry
- 采用了segment分段鎖技術,在多執行緒并發更新操作時,對同一個segment進行同步加鎖,保證資料安全,
- 同步的實作方式使基于ReentrantLock(Segment繼承自ReentrantLock)
- 存在Hash沖突時,鏈表的查詢效率低
JDK1.8
ContcurrentHashMap基于JDK1.8的原始碼剖析
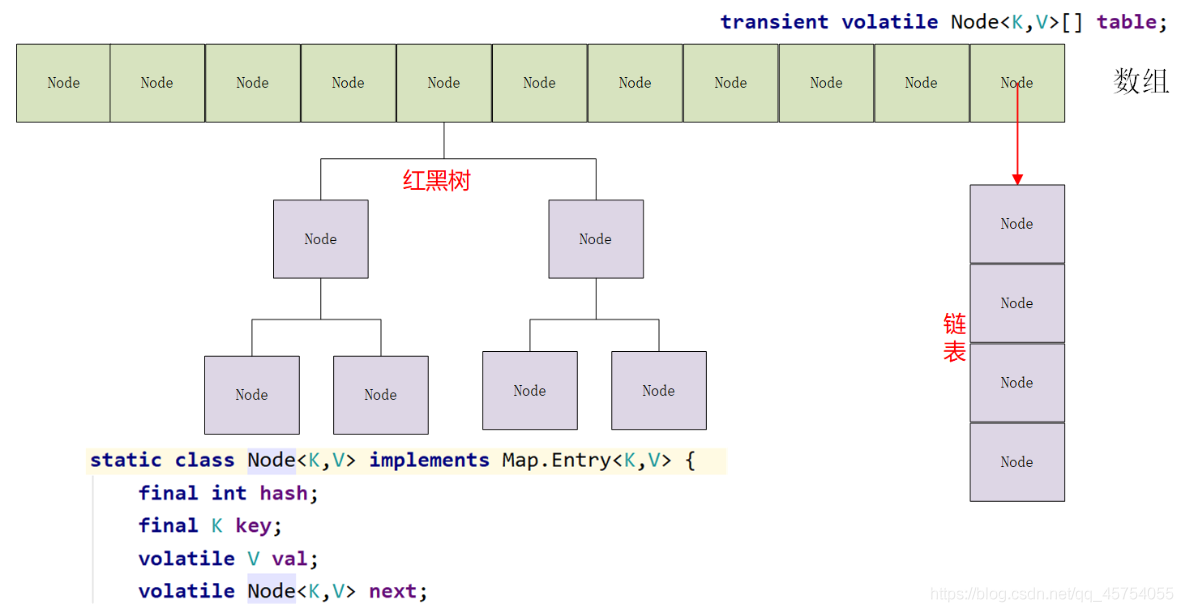
- 底層的資料結構與HashMap1.8版本一樣,都是基于陣列+鏈表+紅黑樹
- 支持多執行緒的并發操作,實作的原理是CAS+synchronized保證并發更新
- 檢索操作不用加鎖,get方法是非阻塞的
put方法
public V put(K key, V value) {
//實際呼叫的是putVal(key,value,false)
//無論key在表中所對應的值是否存在,都使用value進行更新
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
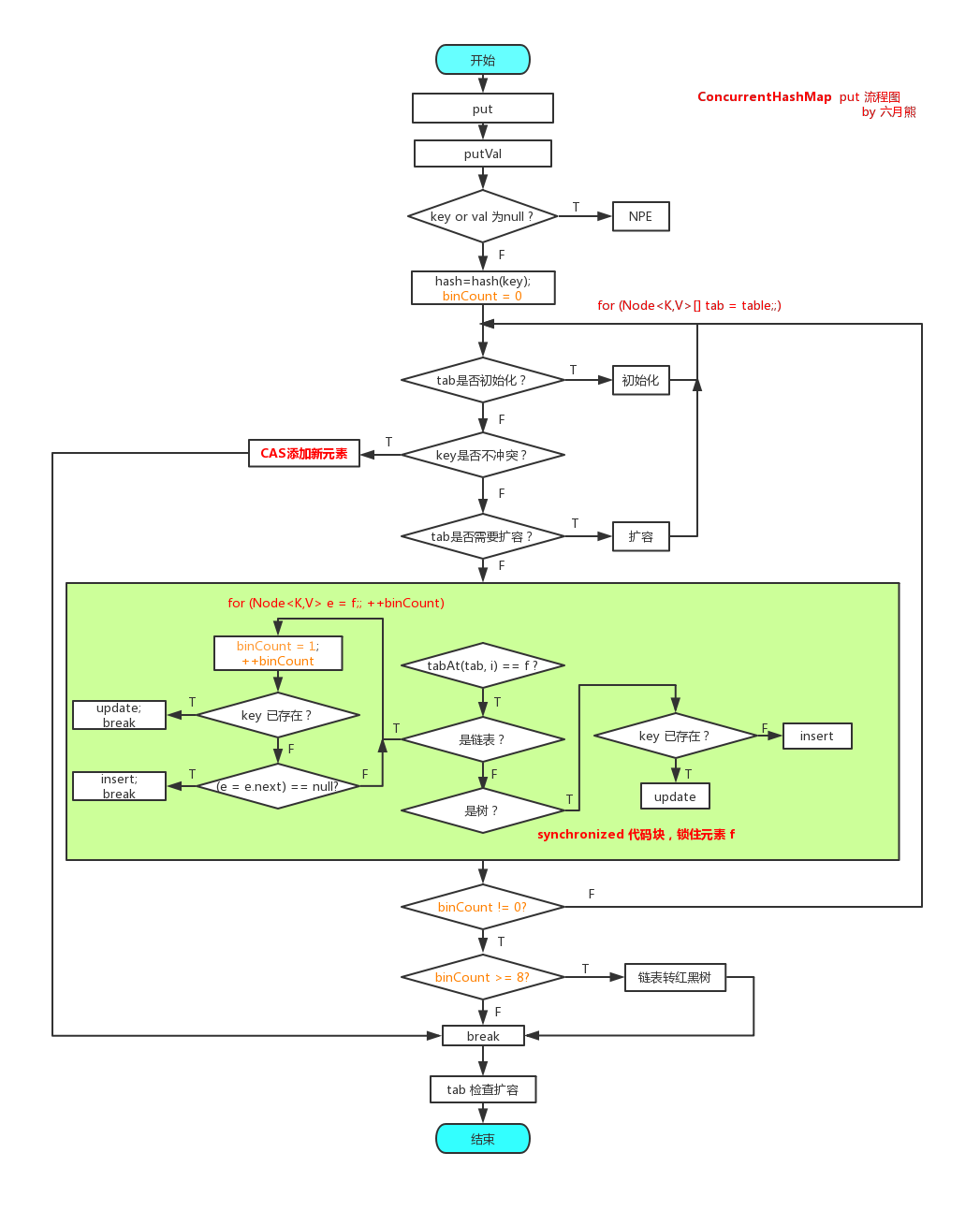
final V putVal(K key, V value, boolean onlyIfAbsent) {
//key和value的值必須是非null的
if (key == null || value == null) throw new NullPointerException();
//計算key的hash值用來定位元素的位置
int hash = spread(key.hashCode());
int binCount = 0;
//table 參考指向的是ConcurrentHashMap中 所有元素所存在的陣列的參考 所以下面依次將遍歷
for (ConcurrentHashMap.Node<K,V>[] tab = table;;) {
ConcurrentHashMap.Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();//table為空,則初始化table,首次初始化默認的陣列長度為16
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 判斷key對應的陣列位置上是否為null,若尚未發生hash碰撞,即進行CAS操作,new 一個 Node<K,V>存放到tab中,退出for回圈;
if (casTabAt(tab, i, null,
new ConcurrentHashMap.Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//判斷是否需要擴容
else if ((fh = f.hash) == MOVED) // MOVED = -1
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {//加鎖
if (tabAt(tab, i) == f) {
if (fh >= 0) {//當作鏈表處理
binCount = 1;
for (ConcurrentHashMap.Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {// key 存在,更新
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
ConcurrentHashMap.Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new ConcurrentHashMap.Node<K,V>(hash, key,
value, null);//key 不存在,鏈表中追加新元素
break;
}
}
}
//按照紅黑樹的方式進行插入
else if (f instanceof ConcurrentHashMap.TreeBin) {
ConcurrentHashMap.Node<K,V> p;
binCount = 2;
//key不存在則putTreeVal方法直接添加新元素并回傳null,key存在則回傳對應節點p并做val更新
if ((p = ((ConcurrentHashMap.TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
//當插入鏈表后值大于8的時候要轉為紅黑樹
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
//size++
addCount(1L, binCount);
return null;
}
put方法流程圖
1.7和1.8版本都存在的特性
- ConcurrentHashMap的key和value都不能為null
- 鍵值迭代器為弱一致性迭代器,創建迭代器后,可以對元素進行更新,對元素更新不會影響遍歷;
- 讀操作沒有加鎖,value是voliate修飾的,保證了可見性
- 讀寫分離提高效率:多執行緒對不同的Node/Segment 的插入和洗掉是可以并發、并行執行的,對同一個Node/Segment的寫操作是互斥的,讀操作都是無鎖的操作,可以并發、并行執行,
HashMap,HashTable和ConcurrentHashMap的區別:
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/275112.html
標籤:其他