1、簡介
- 一種多模式串匹配演算法, 可以快速從主串中同時找出所有包含的所有模式串.
- 對比KMP是單模式匹配, 雖然可以使用單模式串匹配演算法逐個進行查找模式串, 但是實際場景中,若模式串的數量可能很大,并且要匹配的文本內容很多,導致匹配的時長過長.
- 時間復雜度:
- 字典樹的生成(只需要處理一次即可):
O(模式串數量 x 模式串長度) - 構建失敗指標(只需要處理一次即可):
O(節點個數 x 樹高) - 模式匹配程序(進行多次):
O( 主串長度 x 樹高), 如果模式串長度不是很長, 則字典樹很扁,則AC自動機的搜索程序復雜度趨近于O(n)
- 字典樹的生成(只需要處理一次即可):
- 應用場景: 對發表的文章或者評論可以過濾出內容中包含的所有敏感詞條,
2、預備知識
2.1 字典樹
- 字典樹又叫前綴樹
- 它本質是一顆多叉樹, 除了根節點, 每個節點存放一個字符, 從根節點到某一節點,路徑上經過的字符連接起來,就是該節點對應的字串,
- 在實作上一般為了知道一個節點是否是一個合法的單詞結尾, 會在該節點上打上標記.
- 將每個字串插入字典樹后, 每個字串的公共前綴都將作為一個字符節點保存,
- 常應用于詞頻統計 和 前綴匹配.
字典樹影片演示網站地址
- 可以嘗試插入
he、she、hers、his、shy等字串

2.2 樹的廣度遍歷
- 就是按層級遍歷, 在字典樹構造失敗指標的程序中, 需要使用BFS遍歷順序依次對每個節點構建失敗指標
樹的BFS遍歷偽代碼:
queue = Queue()
queue.put(self.root) # 先把根節點入隊
# 只要佇列不為空, 就每次取出隊頭節點, 然后將該節點的所有子節點依次入隊, 依次回圈完成BFS遍歷
while not queue.empty():
# 取出隊頭消費
parentNode = queue.get()
.....
# 獲取所有將該節點所有子節點依次入隊
for childrenNode in parentNode.getAllChildrenNode():
queue.put(childrenNode)
3、AC自動機代碼實作
3.1 構建字典樹
- 其實字典樹并沒有太多的約束規則, 所以生成字典樹程序也是非常簡單的.
1、AC字典樹節點設計:
class Node:
def __init__(self) -> None:
# 失敗指標
self.fail: Node = None
# 哈希表存放所有子節點, key是字符, value是對應的Node節點
self.next: Dict[str, Node] = {}
# 標記單詞結尾: 如果該節點是單詞結尾, 用set集合存放其單詞長度
self.wordLenSet = set()
2、將一個單詞插入字典樹:
def insert(self, pattern):
# 從根節點開始, 從cur指標遍歷字典樹
cur = self.root
# 遍歷每一個字符
for c in pattern:
# 如果該節點的孩子節點中不存在該字符, 則新建并插入
if not cur.next.get(c):
cur.next[c] = Node()
# 指向下一個字符節點
cur = cur.next.get(c)
# 最后cur指向最后一個字符節點, 將其標記為單詞結尾
cur.wordLenSet.add(len(pattern))
比如將模式串 he、she、hers、his、shy依次插入字典樹后, 并構建成AC字典樹如下
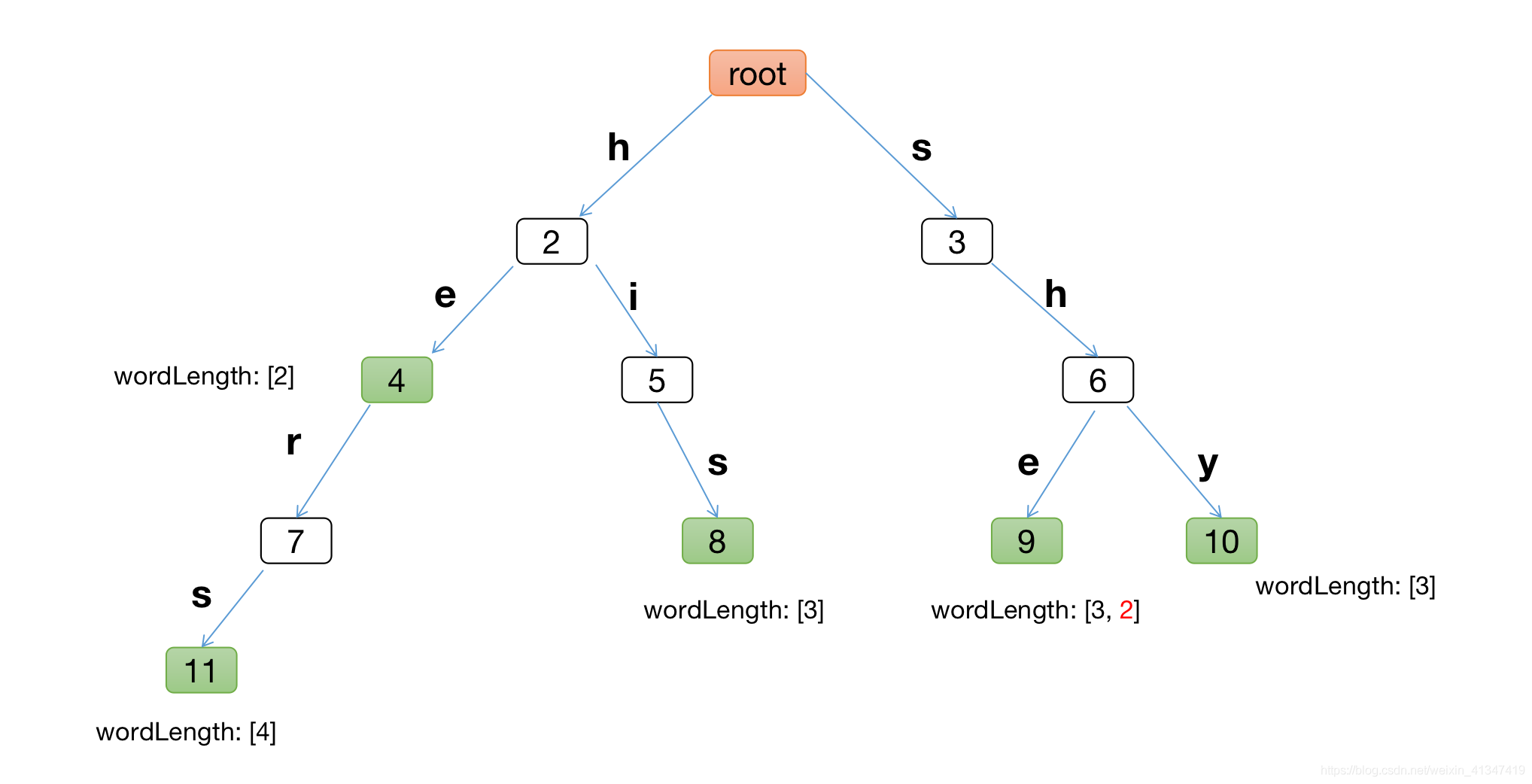
3.2 構建失敗fail指標
什么失敗指標
- 比如如果
節點A的fail指標指向節點B, 那么節點B的代表的單詞是節點A代表的單詞的最長后綴 - 它表示的是在主串發生匹配失敗時, 下一步應該跳轉的節點, 然后繼續去匹配.
假設下圖是構建好的失敗指標的字典樹:
- 比如節點9代表的單詞就是she, 那么節點9的失敗指標指向節點4, 因為節點4代表的單詞是節點9代表的單詞的最長后綴
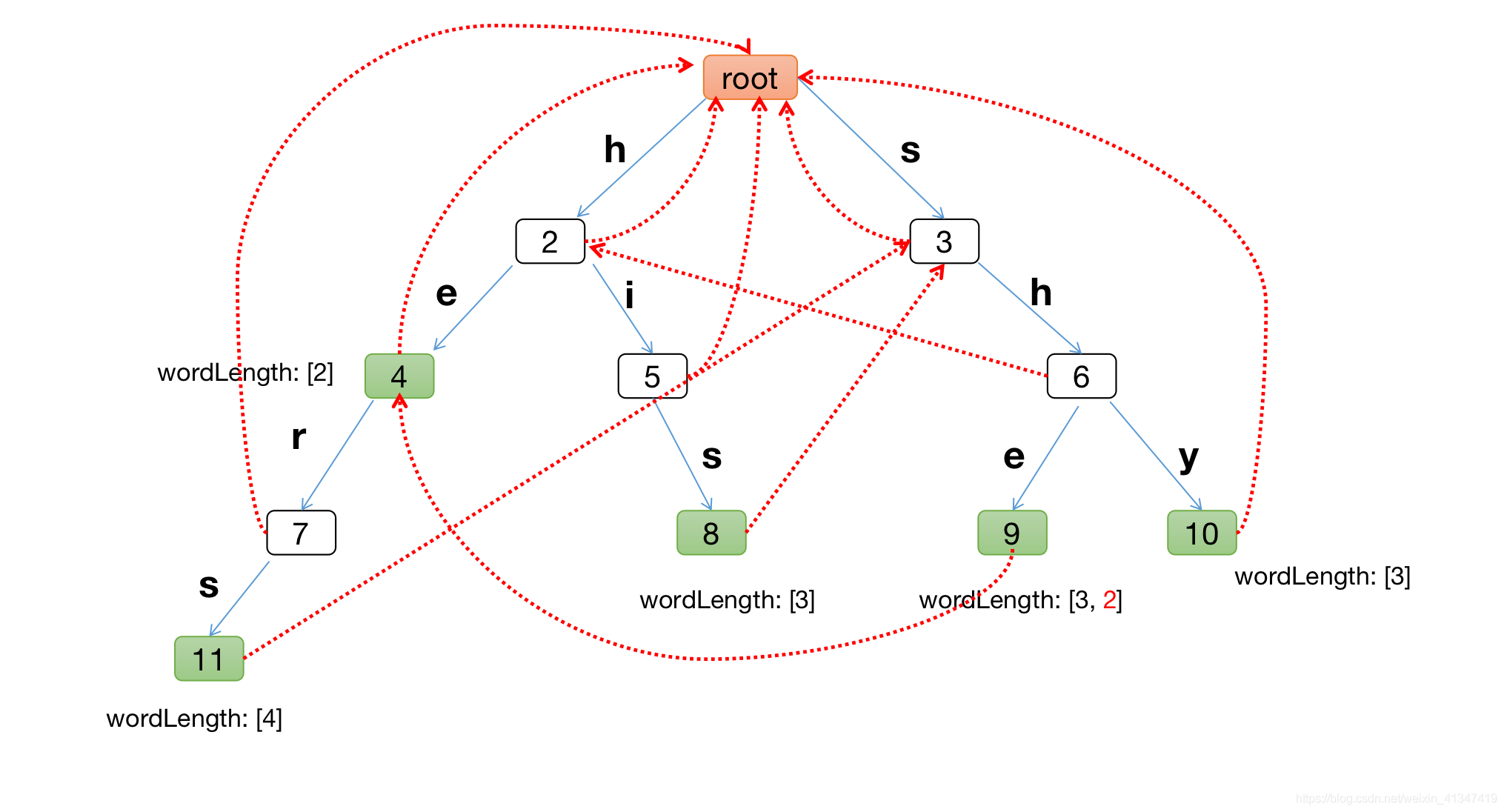
失敗指標有什么用?
- 因為通過預處理得到了每個節點的失敗指標指向, 這樣在主串某個節點進行匹配失敗的時候, 不用再重新從根節點出發進行匹配, 減少了匹配的程序, 提高了搜索效率
AC自動機構建失敗指標程序影片演示:
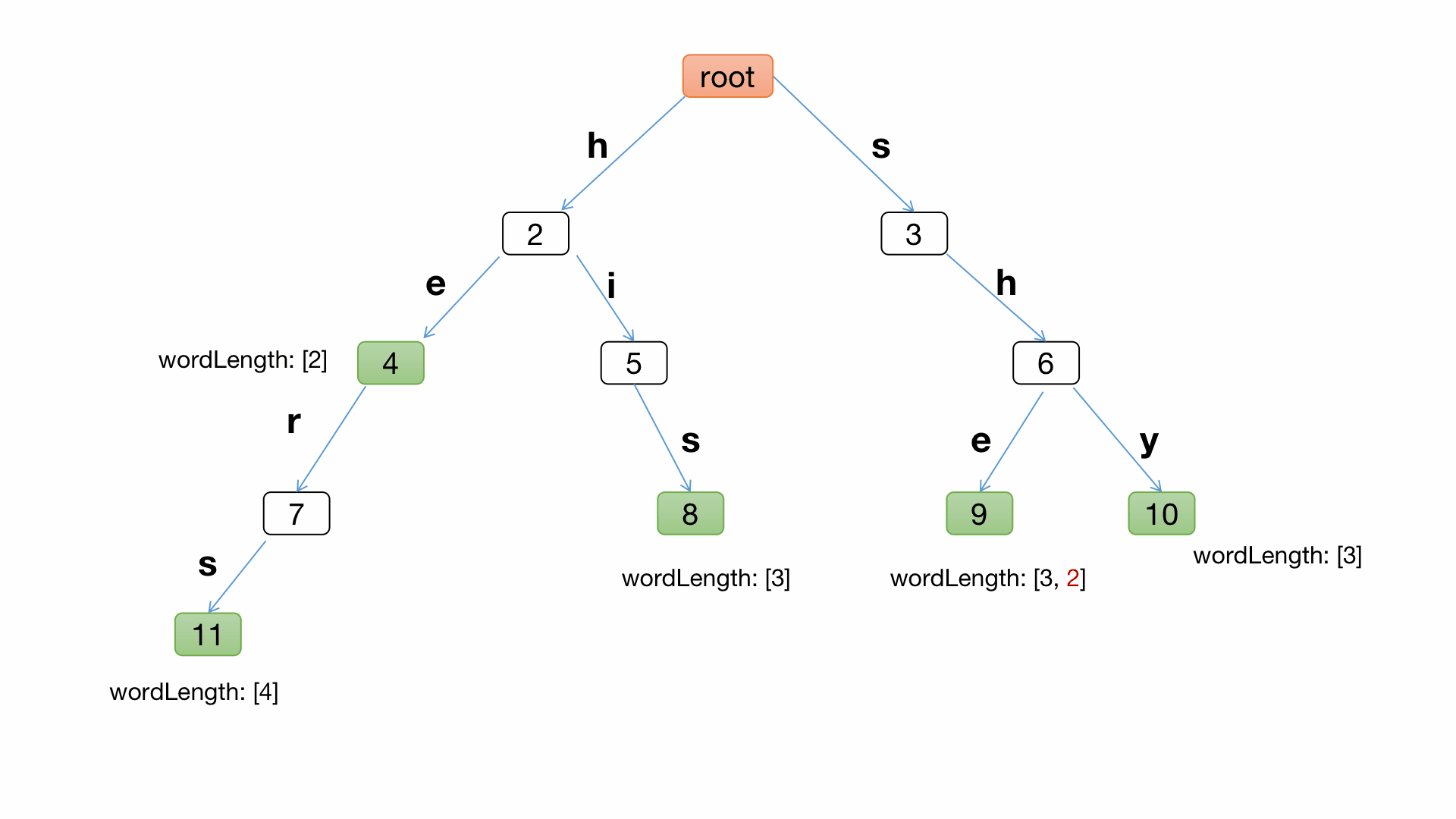
代碼實作
- 肉眼對每個節點的構建失敗指標很容易, 因為一眼就能看出在樹中最長后綴是否存在
- 而代碼實作需要基于BFS廣度遍歷 和 父節點的失敗指標去得到每個節點的失敗指標指向
- 核心在于pFail指標的回退, 每一次只需要判斷當前的pFail指標的孩子節點是否存在該字符, 如果存在則讓節點的失敗指標指向它, 因為父節點的失敗指標pFail就代表了它此時指向的最長后綴, 只需在判斷最新的一位就知道此時是不是該節點此時的最長后綴. 但是如果不存在, 需要繼續回退
pFail=pFail.fail, 從pFail的失敗指標開始繼續尋找, 以此回圈回退.
def buildFial(self):
queue = Queue()
queue.put(self.root)
# 對字典樹進行BFS遍歷對每個節點的所有孩子節點構建失敗指標
while not queue.empty():
parentNode: Node = queue.get()
# 對每個孩子節點構建失敗指標
for c, node in parentNode.next.items():
# 孩子節點node的父節點的失敗指標
pFail = parentNode.fail
# 回圈判斷其父節點的失敗指標下是否存在該字符,如果有指向它并退出, 否則最侄訓退到指向根節點
while pFail is not None and not pFail.next.get(c):
pFail = pFail.fail
# 如果pFail為null說明回退到了根節點說明在樹上不存在最長后綴,直接指向root
if pFail is None:
node.fail = self.root
else:
node.fail = pFail.next.get(c)
# 把失敗指標存放的單詞長度也添加進來這個失配的節點,方便后面快速獲取到所有匹配的模式串
if len(node.fail.wordLenSet) > 0:
node.wordLenSet.update(node.fail.wordLenSet)
#
queue.put(node)
3.3 進行模式匹配
- 模式匹配規程中,先按常規的字典樹的查找程序進行匹配,如果在某個節點匹配失敗,則回退到失敗指標繼續匹配,回退結束后, 如果匹配成功, 并且該節點存盤了模式串的資訊(比如模式串的長度集合), 則可以根據當前遍歷索引
i - wordLen + 1計算得到每個模式串在主串索引的起始位置index, 所以[index, index + wordLen]就是其在主串的索引范圍
比如對主串 ishery 進行搜索匹配找出的所有的模式串程序
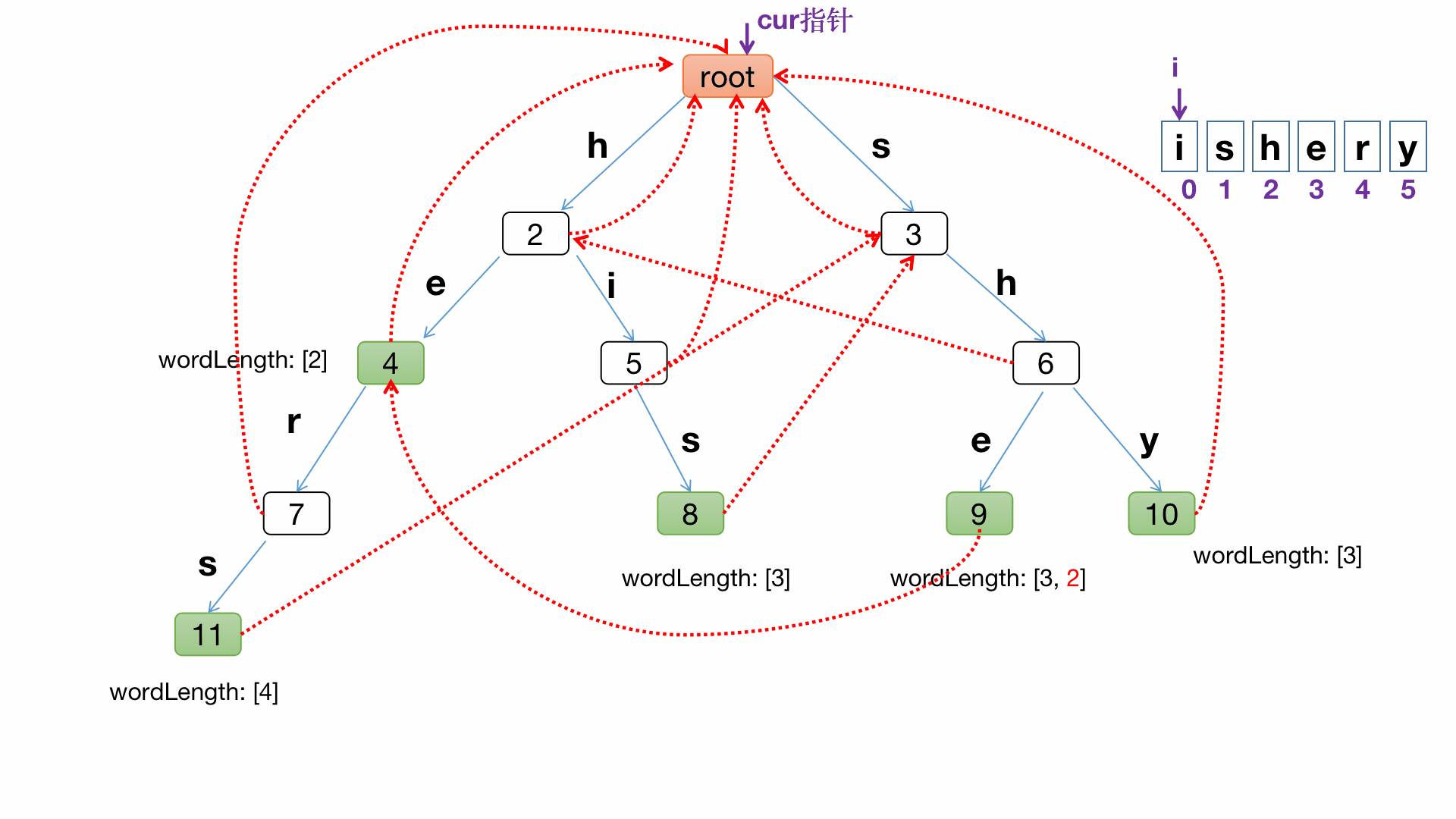
代碼實作
# 搜索主串, 找出其中所有包含的模式串
def search(self, text):
cur = self.root
for i in range(len(text)):
# 如果該節點不存在該字符, 則從失敗指標繼續判斷, 不斷回退直到找到或者回退到根節點
while cur.fail and cur.next.get(text[i]) is None:
cur = cur.fail
if cur.next.get(text[i]):
cur = cur.next.get(text[i])
# 如果匹配成功并且該節點是單詞結尾, 用 i - 單詞長度即可獲得模式串在主串的位置
if len(cur.wordLenSet) > 0:
for wordLen in cur.wordLenSet:
index = i - wordLen + 1
match = text[index:i+1]
print(f"匹配到了模式串: {match}, 其實索引為: {index}")
4、完整代碼實作(Python)
from queue import Queue
from typing import Dict
class Node:
def __init__(self) -> None:
# 失敗指標
self.fail: Node = None
# 哈希表存放所有子節點, key是字符, value是對應的Node節點
self.next: Dict[str, Node] = {}
# 如果該節點是單詞結尾, 用set結合存放其單詞長度
self.wordLenSet = set()
class AcTree:
def __init__(self, patternList) -> None:
self.root = Node()
# 將所有單詞插入字典樹
for e in patternList:
self.insert(e)
# 對字典樹構建失敗指標
self.buildFial()
def insert(self, pattern):
# 從根節點開始, 從cur指標遍歷字典樹
cur = self.root
# 遍歷每一個字符
for c in pattern:
# 如果該節點的孩子節點中不存在該字符, 則新建并插入
if not cur.next.get(c):
cur.next[c] = Node()
# 指向下一個字符節點
cur = cur.next.get(c)
# 最后cur指向最后一個字符節點, 將其標記為單詞結尾
cur.wordLenSet.add(len(pattern))
def buildFial(self):
queue = Queue()
queue.put(self.root)
# 對字典樹進行BFS遍歷對每個節點的所有孩子節點構建失敗指標
while not queue.empty():
parentNode: Node = queue.get()
# 對每個孩子節點構建失敗指標
for c, node in parentNode.next.items():
# 孩子節點node的父節點的失敗指標
pFail = parentNode.fail
# 回圈判斷其父節點的失敗指標下是否存在該字符,如果有指向它并退出, 否則最侄訓退到指向根節點
while pFail is not None and not pFail.next.get(c):
pFail = pFail.fail
# 如果pFail為null說明回退到了根節點說明在樹上不存在最長后綴,直接指向root
if pFail is None:
node.fail = self.root
else:
node.fail = pFail.next.get(c)
# 把失敗指標存放的單詞長度也添加進來這個失配的節點,方便后面快速獲取到所有匹配的模式串
if len(node.fail.wordLenSet) > 0:
node.wordLenSet.update(node.fail.wordLenSet)
#
queue.put(node)
# 搜索主串, 找出其中所有包含的模式串
def search(self, text):
cur = self.root
for i in range(len(text)):
# 如果該節點不存在該字符, 則從失敗指標繼續判斷, 不斷回退直到找到或者回退到根節點
while cur.fail and cur.next.get(text[i]) is None:
cur = cur.fail
if cur.next.get(text[i]):
cur = cur.next.get(text[i])
# 如果匹配成功并且該節點是單詞結尾, 用 i - 單詞長度即可獲得模式串在主串的位置
if len(cur.wordLenSet) > 0:
for wordLen in cur.wordLenSet:
index = i - wordLen + 1
match = text[index:i+1]
print(f"匹配到了模式串: {match}, 其實索引為: {index}")
if __name__ == '__main__':
# 測驗
ac = AcTree(["he", "she", "hers", "his", "shy"])
ac.search("ishery")
打賞

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/275120.html
標籤:其他
上一篇:2021省選游記