Kafka2.8最新情報
--------本文一半翻譯,一半自己總結,翻譯(翻譯連接)了錯了水平太差,總結錯了不要信,
1.1 Kafka2.8取代zookeeper的原因
ZooKeeper是一個檔案一致性系統基礎上的特殊 filesystem/trigger API ,Kafka是 一致性檔案系統上的pub / sub API, 這導致系統的人員去調優、配置、監視、保護和判斷 通信和新能 在兩個日志實作、兩個網路層和兩個安全實作(并且每個都有不同的 distinct tools and monitoring hooks),這都是一些不必要復雜度,這些固有的并且不必要的負責度,加速了kafka的改革,在即將發行的2.8版本Kafka 決定用內部的 quorum service來替代zookeeper 和 controller 的作業,
因此我們第一次使用到沒有zookeeper 的kafka集群,把它叫做 Kafka Raft Metadata mode, 簡稱為 KRaft(pronounced like craft) mode
注:有些功能在此搶先體驗版本中不可用,尚不支持使用ACL和其他安全功能或交易,同樣,在KRaft模式下不支持磁區重新分配和JBOD.
1.2 quorum controller(事件驅動 consensus)
Kafka 新的仲裁機制 將之前放在 Zookeeper 和 Controller 的metadata 資訊 合并放在了 quorum service 之中,Kafka集群再沒有了對外的依賴,所有的組件完全運行在自己的集群之中,
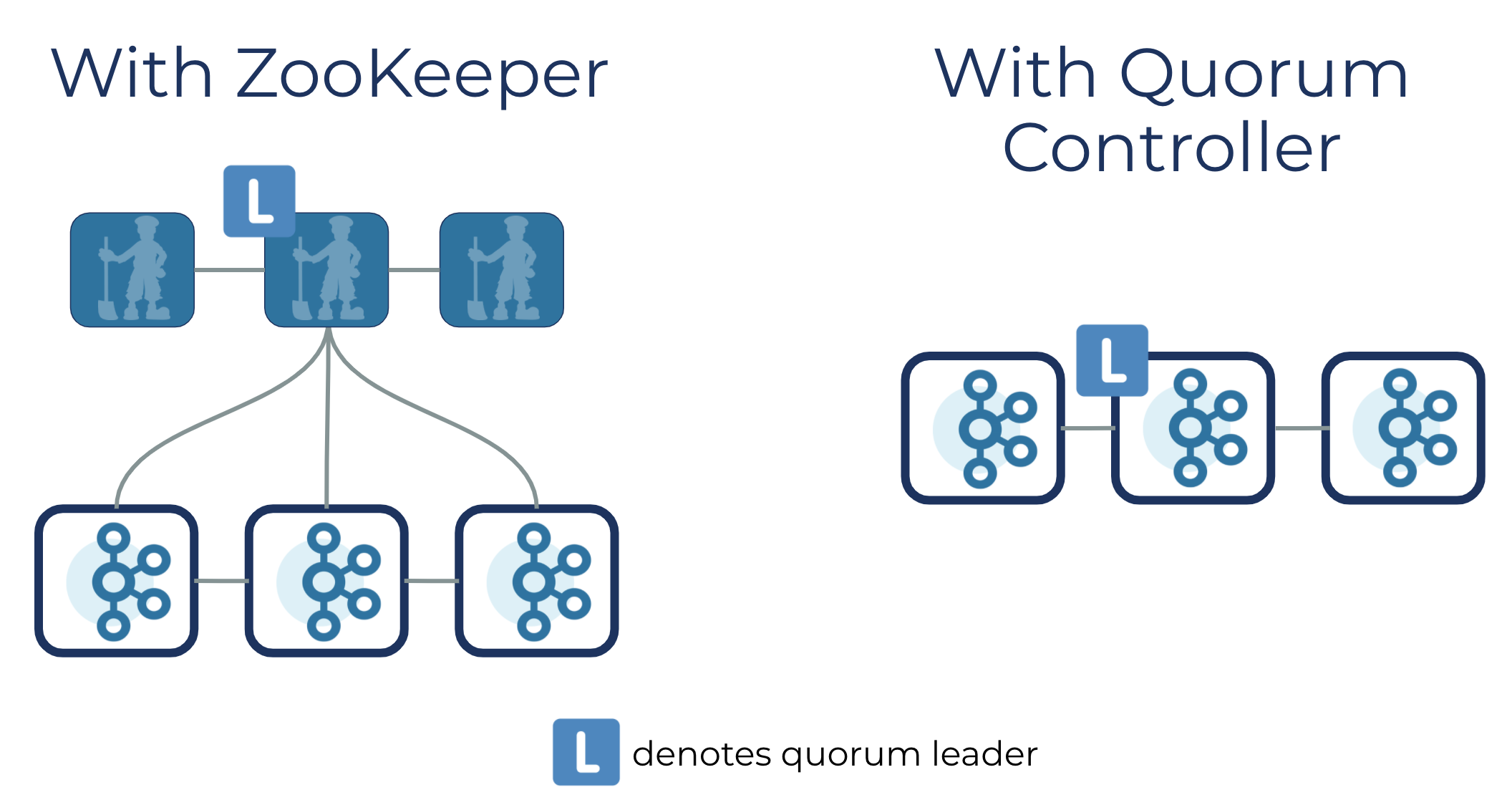
可以詳細的對比一下早些版本的Kafka集群架構,過去必須要在Kafka 集群的元資料必須要在外部Zookeeper 集群和內部Controller 之間進行流動,使得Kafka集群的搭建有著非常沉重的基礎設施,整個元資料的互動都要通過Kafka協議進行互動(也就是RPC),
改為如下所示事件驅動的共識機制進行管理元資料的方式,通過完全的inside 事情開始變得有趣起來,Kafka使用了新的協議 KRaft,來存盤和確保元資料在集群當中能夠精確的進行復制,
KRaft協議和Zookepeer 的ZAB協議、Raft協議非常相似,但是也有著自己的特殊的地方就是有著一套基于事件驅動的體系結構,
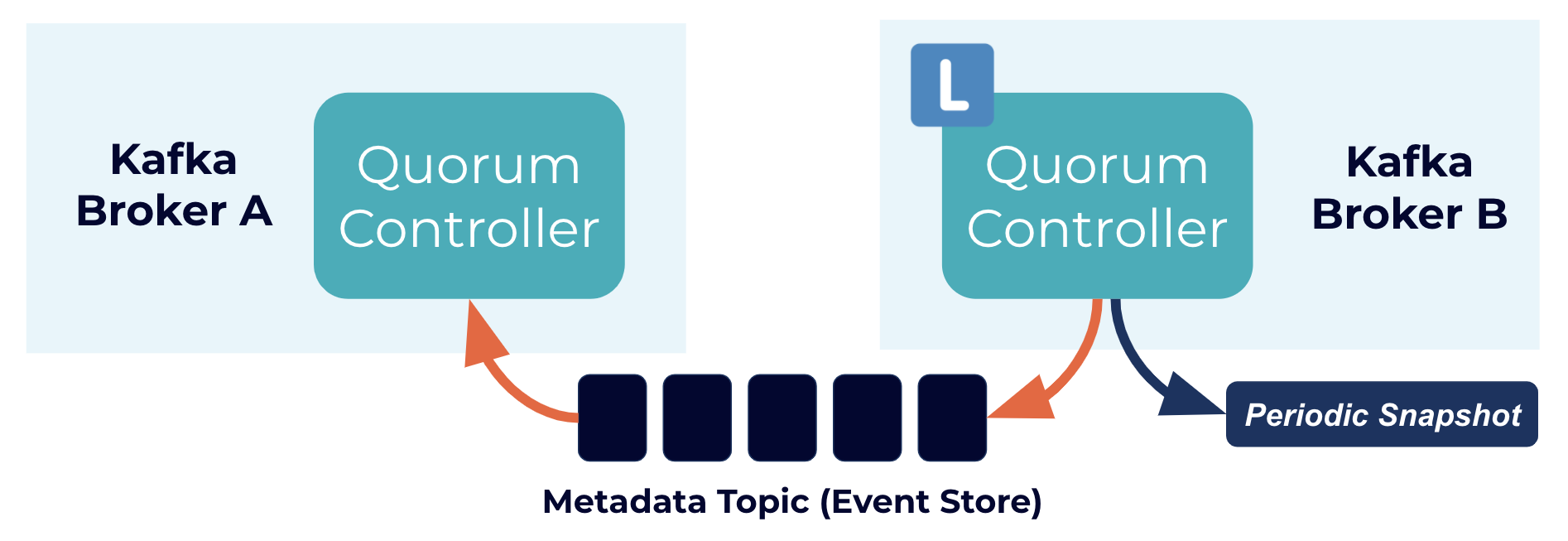
quorum controller 使用的是一種 event-sourced 的存盤模式,該模式可以精準的去創建內部狀態機,
kafka使用一個Metadata Topic (Event Store)來此存盤這些 state,snapshots會定期的去清理這些state,確保資料不會無限的增長,
所有的節點中都會有quorum controller ,但是一個集群中會存在一個 active controller,其他的控制器通過 active controller 存盤的log來回應對應的事件,這樣的話,如果一個controller 因為一個磁區事件而停止,當他重新加入集群的時候可以通過訪問日志能夠快速的趕上它錯過的任何事件,這樣顯著的減少了不可用的事件視窗,縮短了系統最壞情況下的訪問時間,
quorum controller機制,重新啟動而時候不再需要通過controller通過zookeeper 來加載資料,當leader變更的時候,新的active controller 已經獲取了所有的已經提交了存盤在記憶體中的的元資料資訊,此外在KRaft協議中使用了相同的事件驅動機制來跟蹤整個集群的元資料資訊,用了事件驅動的方式和使用實際的log來進行通信的方式來替換RPC進行處理任務,使得Kafka的單個集群可以支持更多的磁區,
1.3 支持百萬磁區
使用Zookeeper 的Kafka集群可以支持 20萬個磁區,使用了quorum的Kafka集群可以支持到200萬個磁區左右,是之前的數十倍之多,
一個Kafka集群的磁區數主要有兩個屬性確定:
- 每個節點的磁區數
- 集群的磁區數
Kafka曾經盡力的優化了單個節點的磁區數(但是這不是真正的瓶頸所在),kafka本身就是一個高可擴展的應用,通過增加新的broker來增加整個系統的容量,這點很重要,正是它的擴展性來決定了系統的上線,然而現在Kakfa的高擴展性卻收到了元資料管理的限制,因素就是如果集群很大的話,Zookeeper 和 Kafka Controller 之間所花費的時間非常長,而quorum controller,通過完全的inside和事件驅動的方式完美的解決了這個問題,元資料的轉移現在完全都是瞬時的操作,不會影響到系統的性能,和擴展性,
性能對比:
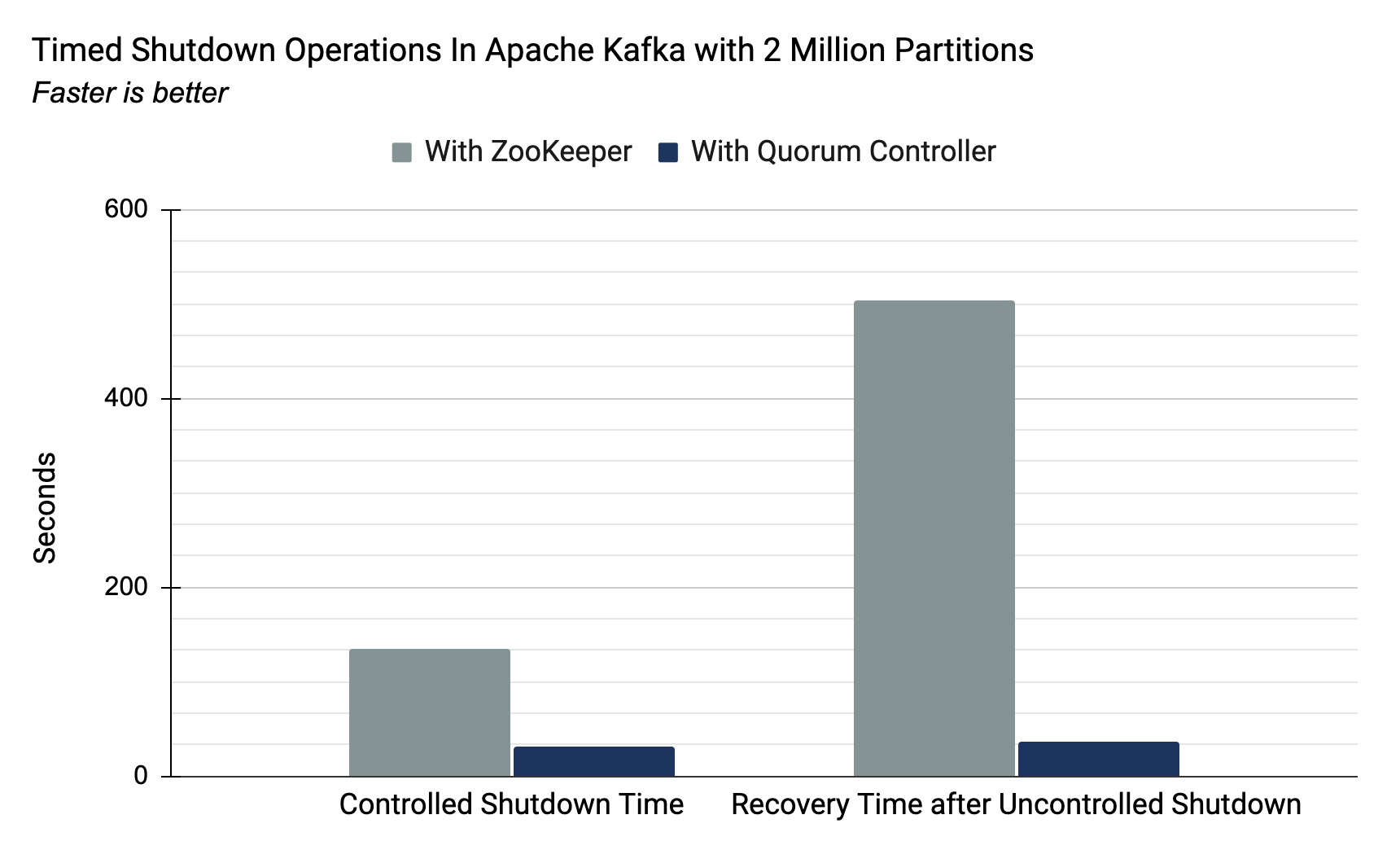
| With ZooKeeper-Based Controller | With Quorum Controller | |
|---|---|---|
| Controlled Shutdown Time(2 million partitions) | 135 sec. | 32 sec. |
| Recovery from Uncontrolled Shutdown (2 million partitions) | 503 sec. | 37 sec. |
這兩個指標都非常重要,
Controlled Shutdown Time(受控制的關機):滾動重啟:我們的軟體在重新部署中始終保持可用性的一個標準,
Recovery from Uncontrolled Shutdown (從不受控制的shutdown中恢復):這個指標可能更重要,因為它決定了系統的RTO(系統的恢復時間)
1.4 Kafka不再重量級,僅僅是一個行程
zk時代的kafka被普遍認為是一個重量級的應用,因為我們不僅僅要管理Kakf集群,還要去管理Zookeeper集群,這往往會造成系統在剛開始使用的時候去選擇ActiveMQ 和 RabbitMQ等訊息鐘家中間件,并在具備一定的規模的時候才會遷移到Kafka集群,
不好意思,Kafka也輕量級了,您倆改怎么辦呢----------------------------
現在完全可以很輕巧的去使用Kafka了,不管你是自己練習還是商用,都可以從小規模開始然后慢慢的往大規模中去發展,都是使用相同的基礎結構,非常方便(下載安裝包,簡單修改配置啟動即可,腳本操作再也不需要 --zookeeper-list的這個操作了,僅僅執行一個broker的資訊即可),
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/275126.html
標籤:其他