上次讀了前沿論文,發現確實水平遠遠不足,因此更加努力的看視頻和學數學,希望后續能有所改善!
本文主要總結關于神經網路訓練不起來該怎么處理的問題進行論述,大家可以選擇性觀看!
目錄
- 偶遇Critical Point
- Saddle Point
- Local Minimum
- 如何鑒別Critical Point
- 批處理與動量
- Batch批處理
- 動量
- 自動更新學習率
- Batch Normalization(批正則化)
- 總結
偶遇Critical Point
有些時候,當我們構建的模型隨著訓練集的輸入,它的Loss將會越來越小,但有時候,當它收斂結束后,我們可能對它的結果依舊不滿意,或者甚至它在最初根本就沒有訓練起來,那么,在以前就會有人說可能是遇到了Critical Point,

它一般分為兩大類,一類是Local Minimum(區域最小值),另一類是Saddle Point(馬鞍點)
Saddle Point
鞍點,詞如其名,就是在某一方向或者某些方向上是最小的點,但在另一些方向上卻仍可以繼續優化,當我們遇到馬鞍點,我們或許不需要特別驚慌,因為我們還有方向可以繼續優化,
Local Minimum
區域最小值,不同于前者,其周圍一般都是陡峭的懸崖,看上去我們已經找不到路可以走了,最初,它被認為是無法逃離的地方,
如何鑒別Critical Point
那么,我們可能會想知道,當我們遇到Critical Point時如何判別自己究竟是遇到了無法逃離的區域最小值還是有路可走的鞍點,
我們可以首先使用Taylor Series Approximation來估計θ附近的Loss:
L
(
θ
)
≈
L
(
θ
′
)
+
(
θ
+
θ
′
)
T
g
+
1
2
(
θ
+
θ
′
)
T
H
(
θ
+
θ
′
)
L\left(\theta\right)\approx L\left(\theta'\right)+\left(\theta+\theta'\right)^Tg+\frac{1}{2}\left(\theta+\theta'\right)^TH\left(\theta+\theta'\right)
L(θ)≈L(θ′)+(θ+θ′)Tg+21?(θ+θ′)TH(θ+θ′)
其中Gradient g是一個向量:
g
=
?
L
(
θ
′
)
g
i
=
?
L
(
θ
′
)
?
θ
i
g=\nabla L\left(\theta'\right)\ \ \ \ g_i=\frac{\partial L\left(\theta'\right)}{\partial\theta_i}
g=?L(θ′) gi?=?θi??L(θ′)?
它代表著,你用現有的Function中每個引數對Loss求偏導的結果,
而Hessian H是一個矩陣:
H
i
j
=
?
2
?
θ
i
?
θ
j
L
(
θ
′
)
H_{ij}=\frac{\partial^2}{\partial\theta_i\partial\theta_j}L\left(\theta'\right)
Hij?=?θi??θj??2?L(θ′)
它的第i行第j個元素是對Loss求第i個引數和第j個引數的二階偏導,
那么這個公式有什么用呢?當我們遇到Critical Point時Gradient = 0上式就可以寫作
L
(
θ
)
≈
L
(
θ
′
)
+
1
2
(
θ
+
θ
′
)
T
H
(
θ
+
θ
′
)
L\left(\theta\right)\approx L\left(\theta'\right)+\frac{1}{2}\left(\theta+\theta'\right)^TH\left(\theta+\theta'\right)
L(θ)≈L(θ′)+21?(θ+θ′)TH(θ+θ′)
我們假設
v
=
(
θ
?
θ
′
)
v=\left(\theta-\theta'\right)
v=(θ?θ′)
當對于所有的θ:
v
T
H
v
>
0
v^THv>0
vTHv>0
則L(θ)>L(θ’),該點為Local Minimum
同理,當:
v
T
H
v
<
0
v^THv<0
vTHv<0
則L(θ)<L(θ’),該點為Local Maximum
而當其有時候大于0有時小于0時,它為Saddle Point
也可以用Hessian的特征值判斷
當H的Eigen Value全為Positive時則為Local Minimum
當H的Eigen Value全為Negative時則為Local Maximum
當H的Eigen Value有時為Positive,有時為Negative時則為Saddle Point
我們假設存在一種簡單的神經網路,和一組簡單有標注資料集:
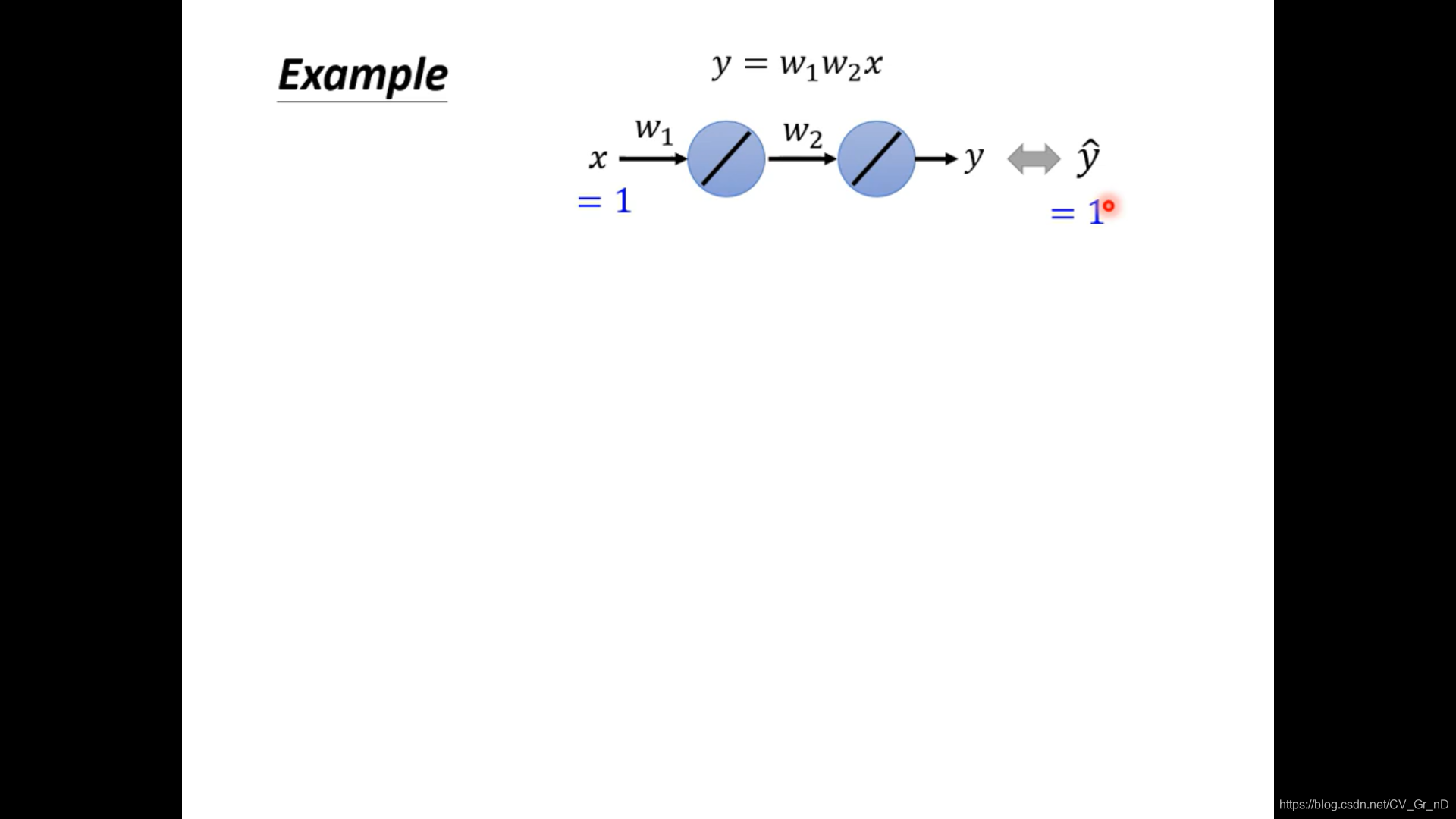
它的函式集:
y
=
w
1
w
2
x
y=w_1w_2x
y=w1?w2?x
它的Error Surface:
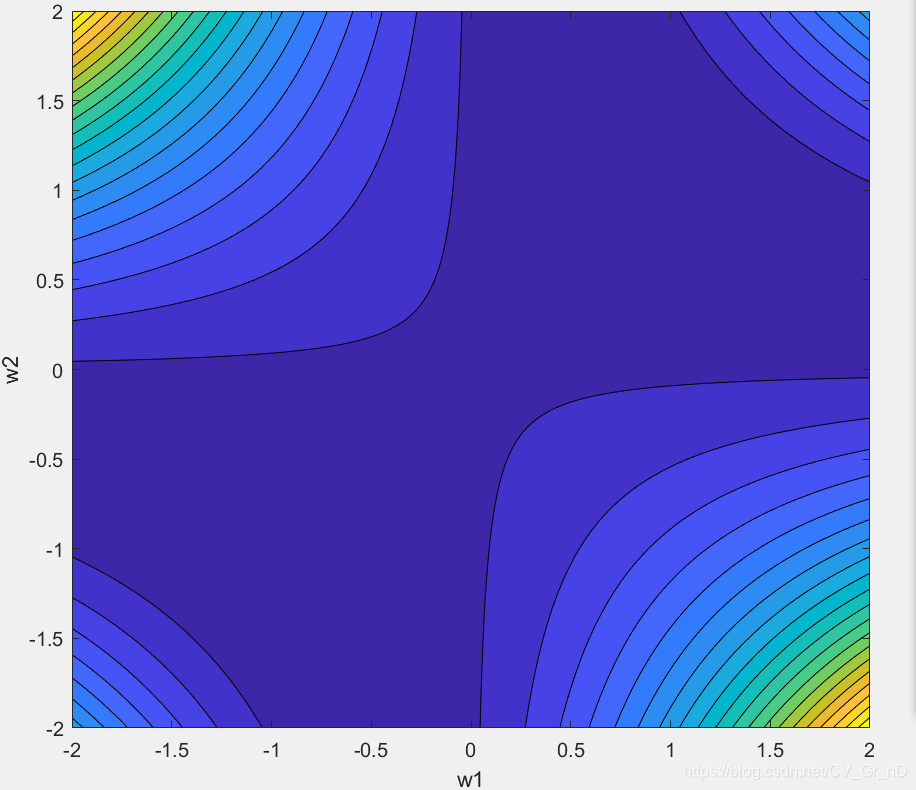
可知,當w1=w2=0時,為馬鞍點,當w1*w2=1時為local minima
我們選取其中w1=w2=0的一點
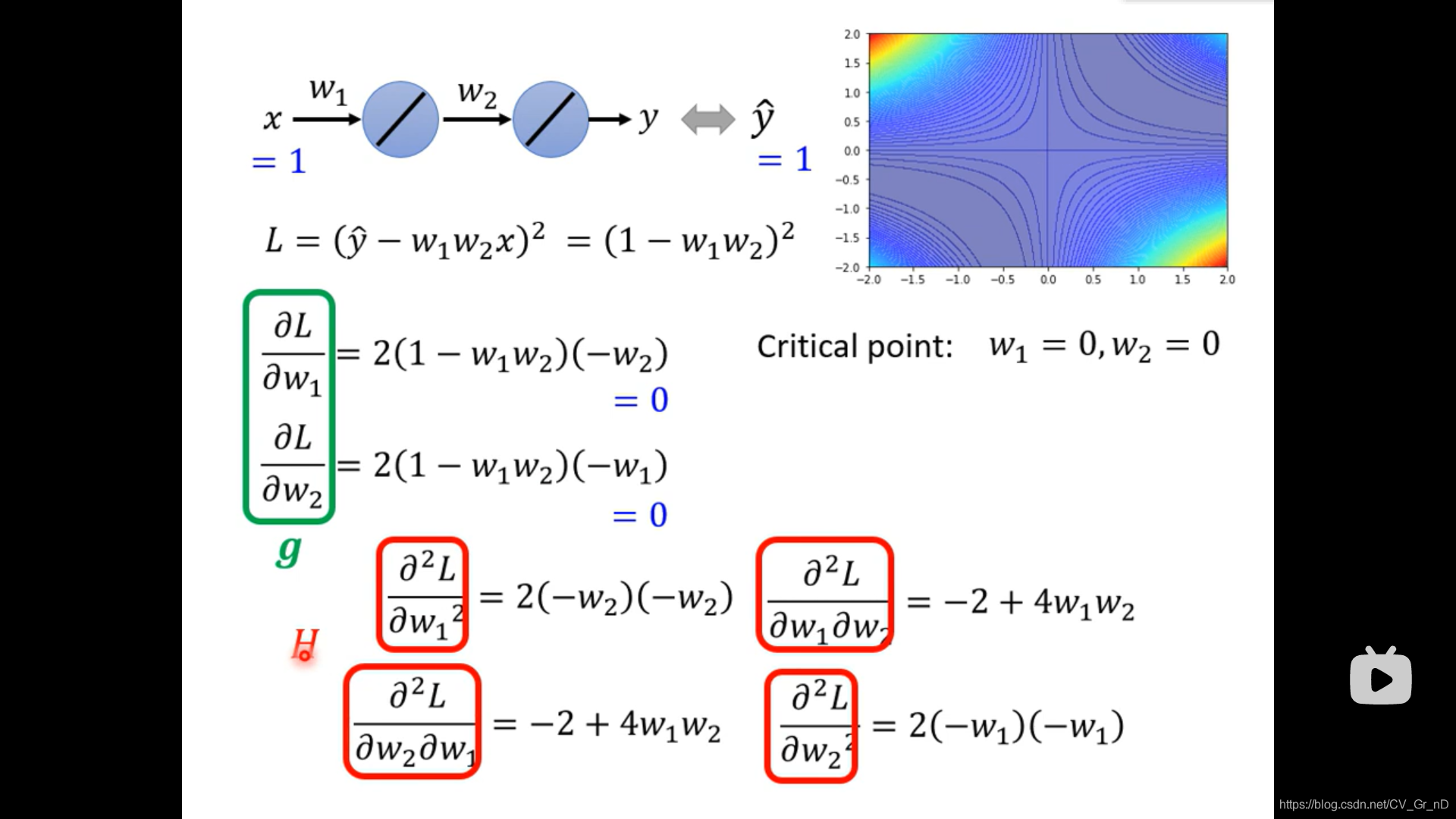
發現它g為零向量,H特征值一正一負,它為saddle point,沿著它特征值矩陣方向還能繼續減少Loss,
幸運的是,當θ維度夠大的時候,它一般總會有路可以走,也就是說遇到Local Minima的機會很少,
批處理與動量
Batch批處理
神經網路有很多違背直覺的東西,batch就是其中之一,我們需要確定一個批次大小,每訓練過Batch個再更新一次引數向量,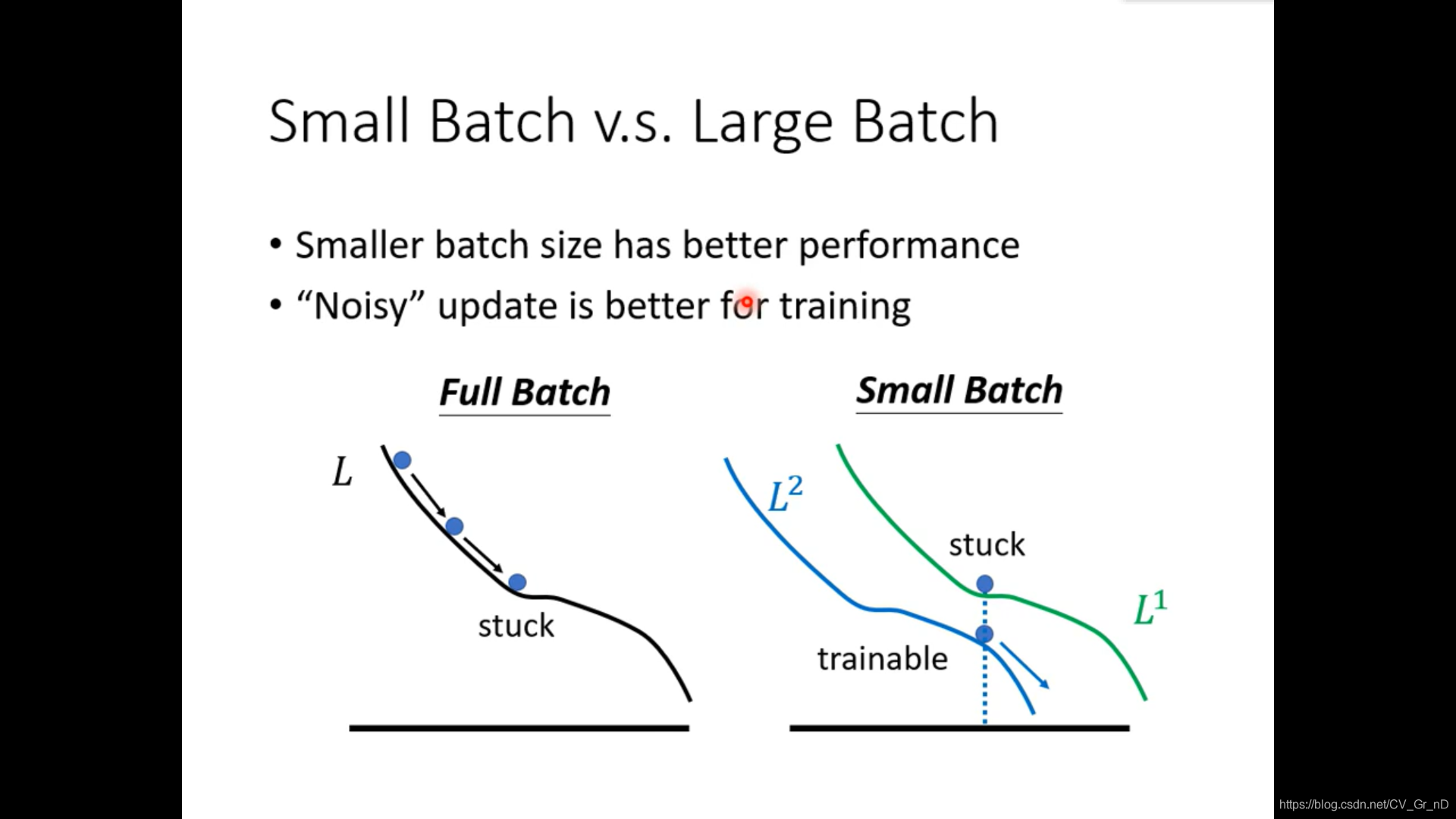
結果是一般來說,更大的Batch(例如Full Batch)更節省時間,而更小的Batch(例如單個)在測驗集上表現更好,
一般的解釋是,小批次的噪音有助于訓練,而GPU的并行訓練節省了大Batch的時間,
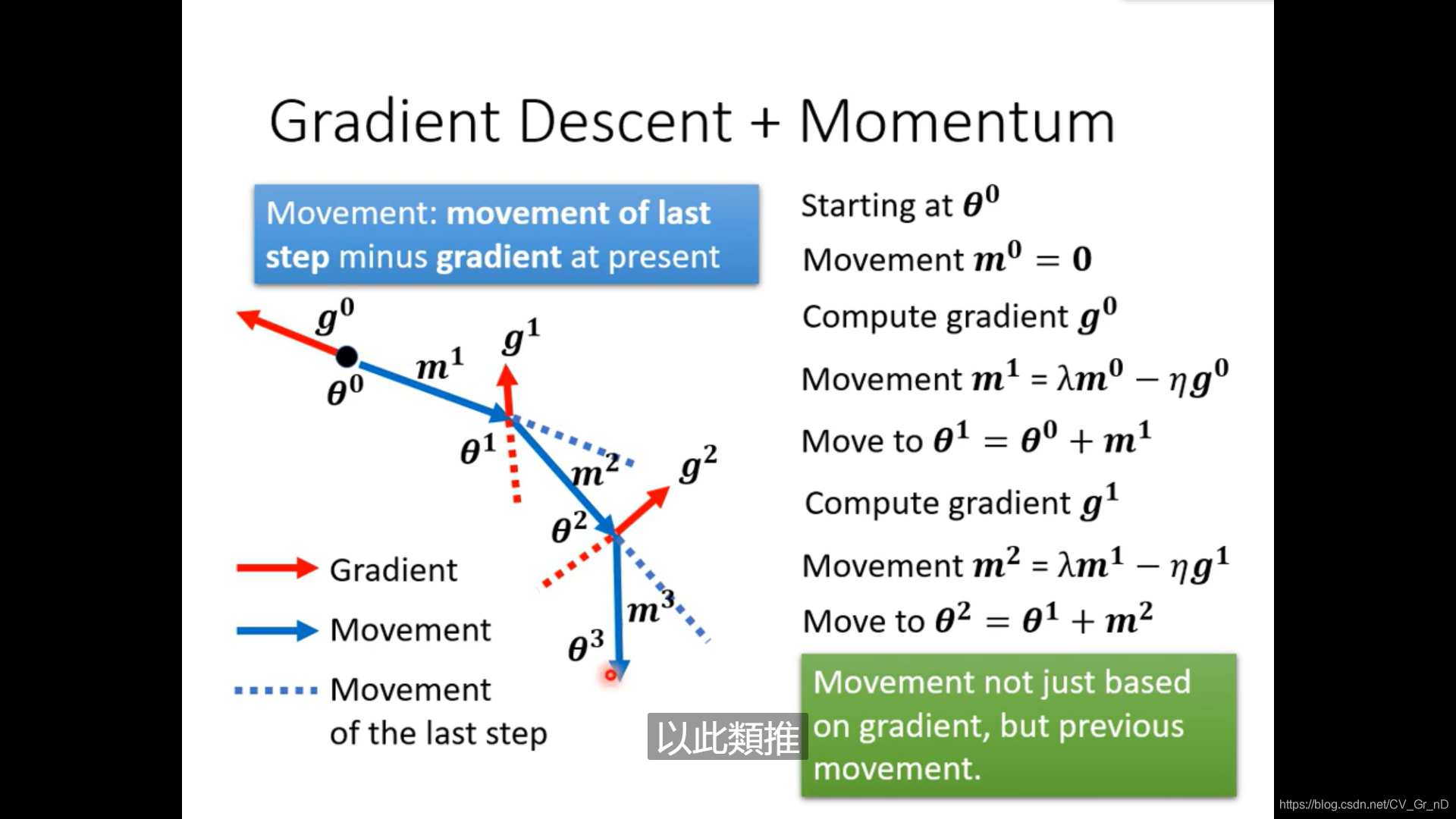
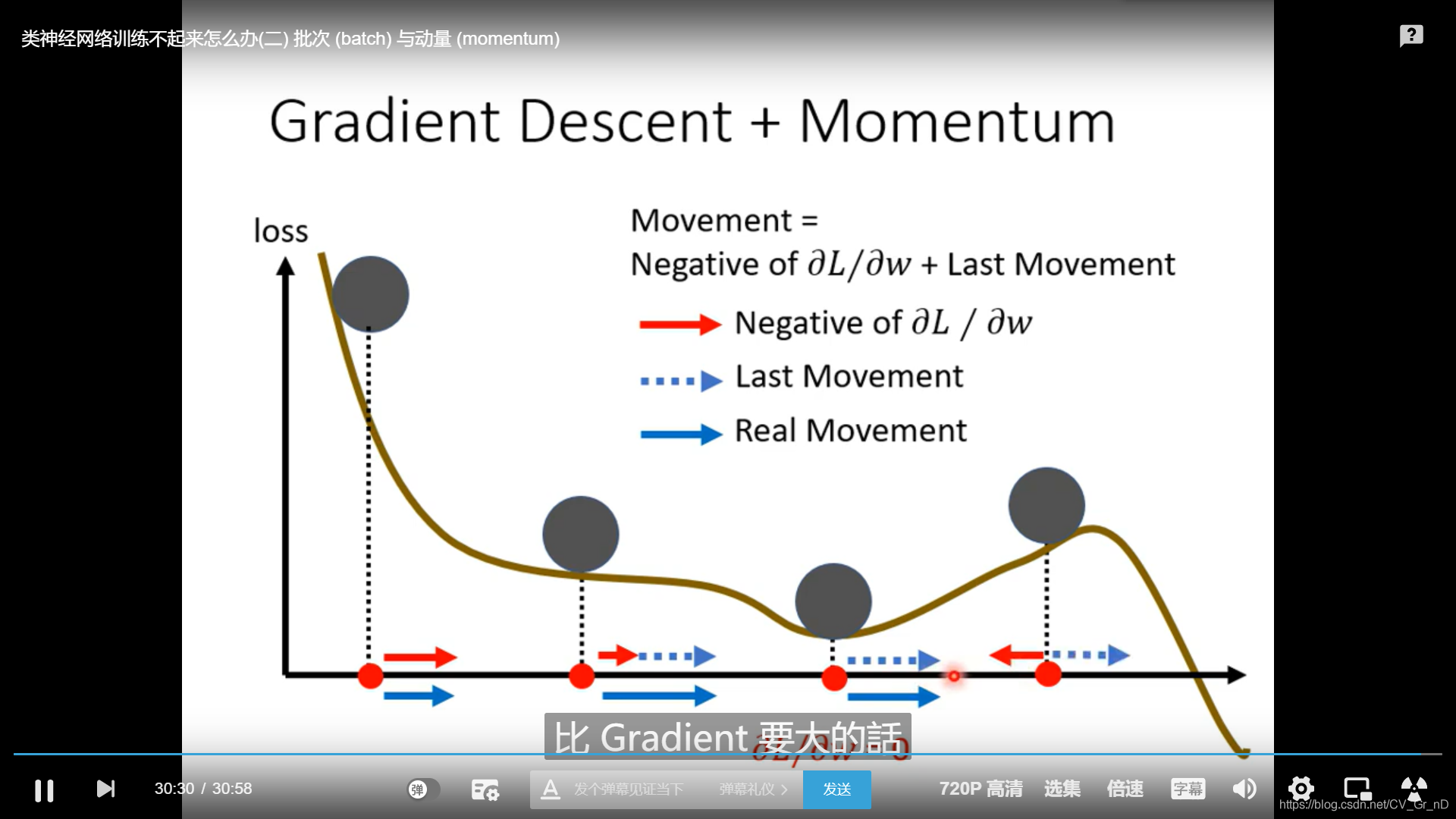
動量
為了防止一遇到平坦地界就被卡住,我們設定了動量來助推它走過平坦或者狹窄坑道,如圖
自動更新學習率
η在過去對我們來說,是一個常量,但當多個變數之間變化曲線有差距甚至差異極大時,它經常會導致許多問題,我們就考慮當當前梯度較大時使其學習率較小,當梯度較小時學習率增大,
η
1
=
η
0
σ
\eta^1=\frac{\eta^0}{\sigma}
η1=ση0?
η
1
=
η
σ
i
t
g
i
t
σ
i
t
=
α
(
σ
i
t
?
1
)
2
+
(
1
?
α
)
(
g
i
t
)
2
\eta^1=\frac{\eta}{\sigma_i^t}g_i^t\ \ \ \sigma_i^t=\sqrt{\alpha\left(\sigma_i^{t-1}\right)^2+\left(1-\alpha\right)\left(g_i^t\right)^2}
η1=σit?η?git? σit?=α(σit?1?)2+(1?α)(git?)2
?

我們可以通過α來控制我們對于當前位置梯度的在乎程度,
Batch Normalization(批正則化)
在上文,我們發現,當引數梯度相差非常多的時候,普通的優化器已經無法應對了,因此我們也改進了我們的優化器為RMSProp,但現在我們改變我們的想法,是否可以通過改變資料的分布而使其梯度整體上趨于一致呢?
但僅僅改變某一個資料會導致其失去整體特征變為噪音,因此我們選擇Batch Normalization,對一批資料的某一行資料整體正則化,如圖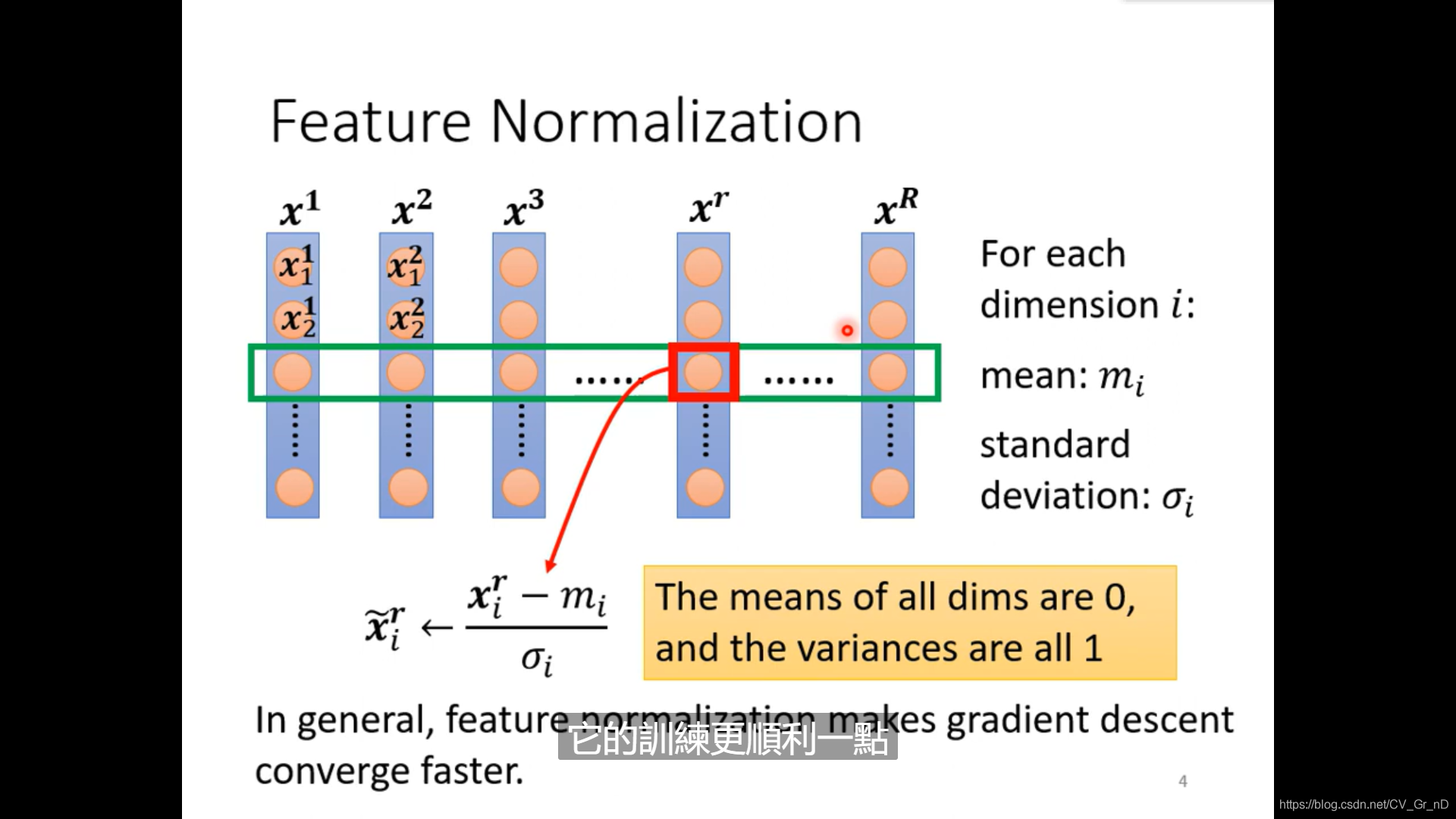
讓其擁有共同的平均值0以及方差1,特征更緊致,
現在也出現了許多可以讓網路自調整其均值與方差值,讓其分布更具備多樣性,
總結
本文總結了筆者最近觀看的網課,后續將開始涉及卷積神經網路,繼續加油!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/275147.html
標籤:其他
上一篇:HOPC演算法:基于結構相似性的多模態遙感影像配準方法(含matlab程式)
下一篇:深入理解計算機系統bomb實驗