本次我們繼續生產問題的疑難雜癥排查系統的文章,在開始我們下一次集中討論Redis的問題之前,還需要用兩次博客來專門講一下有關于記憶體的問題,本文先行討論一下記憶體分配的時間復雜度,下一篇計劃叫《疑難雜癥:記憶體還夠為何申請不到》討論一下記憶體分配的空間碎片問題,這兩篇博客與之前的《疑難雜癥:系統雪崩到底是為什么》和《疑難雜癥: 遇到一個殺不掉,追不到,找不著的行程怎么破?》共同作為Redis問題排查的前序鋪墊,給諸位讀者們普及一下基礎知識,
本次這篇博客源自于今天上午《編程之美》的作者鄒欣老師在群里發的一個網頁截圖,這是一個有關JAVA記憶體分配的問題,
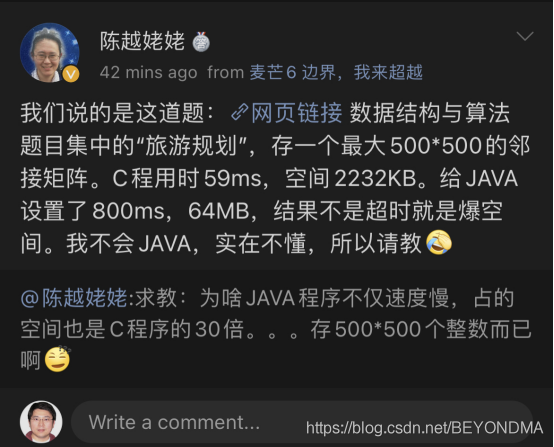
問題的原形是用JAVA創建一個500*500的領接矩陣,結果不但用時超長而且所耗費的時間還大大超出預期,從而JAVA的效率被人嫌棄了,這里雖然筆者沒看到題目中重要的限定詞領接矩陣,不過這也不影響最后問題的解決與排查,這里先簡要分享一下問題的排查與解決,
簡要排查程序簡述
因為這個問題在描述的程序中并沒有貼代碼,因此筆者只能用猜的方式來試驗,為避免我所用的電腦配置過高所帶來的問題,我選取了阿里云普通計算型2C8G的ECS作為實驗平臺,作業系統為Debian10,
1.首先我直接申請了一下500*500的整型資料,實驗結果2毫秒級就結束了,速度非常快的了任務,這段代碼就不放了,太簡單了,
2.申請500*500的二維資料并遍歷賦值,用時20ms,這個具體的代碼如下:
public class TestArray {
public static void main (String[] args) {
double timeNow=System.currentTimeMillis();
int [][] intB=new int[500][500];
for(int i=0;i<intB.length;i++){
for(int j=0;j<intB[i].length;j++){
intB[i][j]=1;
}
}
System.out.println(System.currentTimeMillis()-timeNow);
}
}
運行結果如下:
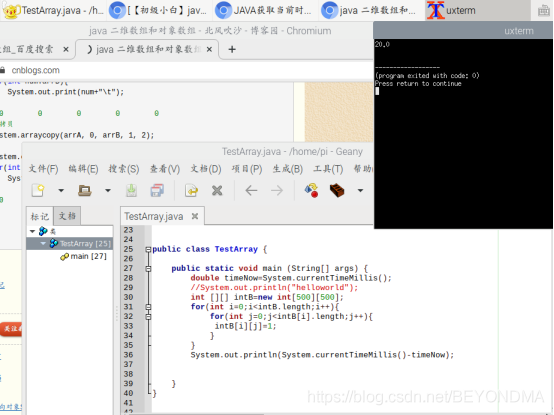
這個和800ms差得也太遠了,相信問題的提出者肯定不是這么寫的代碼,
3.先申請一個500[]的資料,然后再將他們逐一初始化,耗時3ms
我先申請了一個500行,但是列不固定的二維陣列,然后再將每列初始化
public class TestArray {
public static void main (String[] args) {
double timeNow=System.currentTimeMillis();
int [][] intB=new int[500][];
for(int i=0;i<intB.length;i++){
intB[i]=new int[500];
}
System.out.println(System.currentTimeMillis()-timeNow);
}
}
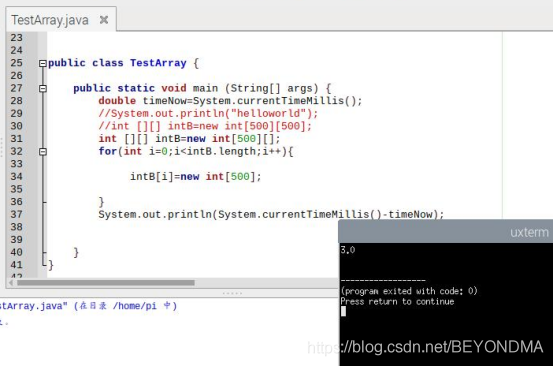
說實話這個操作就有點接近于鄰接矩陣的操作了,不過后面我會講到由于這個記憶體的申請并沒有超出JVM的初始值,JAVA并沒有額外進行記憶體碎片的整理,因此這個JAVA程式運行也很快3ms結束,
4.申請一個10000*10000的陣列,這回用了191ms,并且記憶體占用也上升到了387M
public class TestArray {
public static void main (String[] args) {
System.out.println("Total init memory "+Runtime.getRuntime().totalMemory()/(1024*1024));
double timeNow=System.currentTimeMillis();
int [][] intB=new int[10000][10000];
System.out.println(System.currentTimeMillis()-timeNow);
System.out.println("Total init memory "+Runtime.getRuntime().totalMemory()/(1024*1024));
}
}
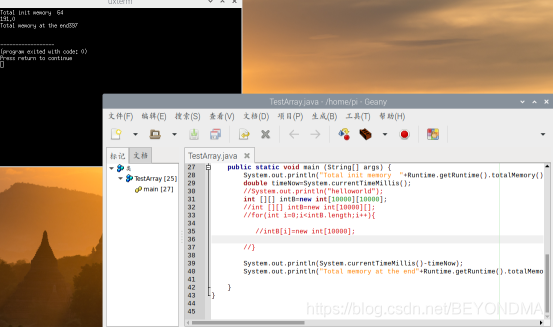
5.先申請一個10000[]的資料,然后再將他們逐一初始化,耗時1009ms
public class TestArray {
public static void main (String[] args) {
System.out.println("Total init memory "+Runtime.getRuntime().totalMemory()/(1024*1024));
double timeNow=System.currentTimeMillis();
//System.out.println("helloworld");
//int [][] intB=new int[500][500];
int [][] intB=new int[10000][];
for(int i=0;i<intB.length;i++){
intB[i]=new int[10000];
}
System.out.println(System.currentTimeMillis()-timeNow);
System.out.println("Total memory at the end"+Runtime.getRuntime().totalMemory()/(1024*1024));
}
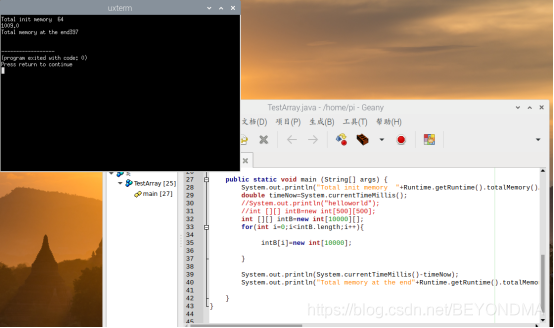
其實這個操作和領接矩陣就已經差不多了,接下來我們會詳細的講一下其中的原理,這里先定性的說一下如何避免這樣的問題發生,如果在JAVA當中需要申請大的記憶體頁,需要在啟動引數中指定-XX:+UseLargePages,并將初始的JVM虛擬機所申請的記憶體大小固定下來,避免JAVA頻繁向作業系統申請記憶體,因此可以使用如下命令列來運行領接矩陣程式,
java -XX:+UseLargePages -Xmx512m -Xms512m -cp . org.kilik.perf.ClassicMatrixMulti
接下來我們詳細分析一下記憶體申請時作業系統和JAVA虛擬機JVM到底都在作什么,
記憶體申請耗時的背后-資料區域性原理產生的回圈
我在《疑難雜癥:系統雪崩到底是為什么》曾經介紹過,資料的訪問往往都有區域性,比如記憶體單元A被訪問了,那么他的鄰居A’和A’’被訪問到的可能性也會極大的增加,因此CPU的高速快取、硬碟的快取都會將這些集中資料訪問進行優化,這種優化機制也強化了連續資料的訪問性能,比如讀取連續的磁盤空間通常性能能比隨機讀高三、四個數量級;記憶體也是同樣,讀取連續空間比讀取非連續空間要快得多,其機制就是硬碟及CPU快取一般會將要快取單元的鄰居也一并呼叫到快取當中,
而要搞清我們剛剛所說的Java問題成因,還要把記憶體管理的模型以及物理記憶體分配的演算法講清楚,如果把計算機比成一個酒店,那記憶體就是客房,行程就是住戶而CPU就是酒店的管家,從這個角度上理解邏輯地址、線性地址以及物理地址是最為簡單的,
邏輯地址我們剛剛所撰寫的JAVA程式,它所訪問的地址其實就是邏輯地址,邏輯地址的引入其實就是讓行程之間彼此相互不會影響,都以為自己獨享整個客房,而屏蔽了底層物理地址的硬體細節 ,
線性地址(Linear Address)也叫虛擬地址(virtual address):這層的引入其實基本上是由于英特爾對于x86向前兼容的需要,按照原有的英特爾規劃,線性地址是暴露給作業系統管理的,也就是應用所在的邏輯地址空間會映射到一個大的線性空間,方便作業系統統一呼叫管理,而像Linux等目前主流的作業系統內核,全部啟用分頁機制進行行程之間的記憶體隔離與保護,線性地址其實就是邏輯地址,
物理地址,這就是真正的CPU地址總線訪問記憶體使用的址了,由硬體電路控制(現在這些硬體是可編程的了)其具體含義,物理地址中很大一部分是留給記憶體條中的記憶體的,但也常被映射到其他存盤器上(如顯存、BIOS等),
在實際地址映射時,CPU要利用其段式記憶體管理單元,先將為個邏輯地址轉換成一個線性地址,再利用其分頁功能,轉換為最終物理地址,也就是行程訪問的邏輯地址可能是相同的,但是最終他們訪問到的物理地址完全不同,當然這個轉換其實一次就夠了,之所以這樣冗余,正如前文所說完全是為了X86的向前兼容,
記憶體必須容納作業系統和各種用戶行程,因此必須盡可能有效得分配記憶體,在分配記憶體程序中,通常需要將多個行程放入記憶體中,前面提到過,我們需要每個行程的空間相互獨立,而且我們必須保護每個行程的記憶體空間的獨立性,如果不同的行程間需要通信,可以按照我們前面提到的通信方法進行通信,但是在此時,我們考慮記憶體空間獨立性的實作,這就涉及到物理記憶體分配:
我們將整個記憶體區域多個固定大小的磁區,每個磁區容納一個行程,當一個磁區空閑時,可以將記憶體調入記憶體,等待執行,這是最簡單的記憶體分配方案,但是這種方案存在很多問題,我們并不知道每個行程需要多大的空間,如果空間過小,那么我們的行程就存不下,如果行程都很小,但是我們磁區很大的話,那么會造成很大程度的浪費,這些在每個磁區未被利用的空間,我們稱之為碎片,
為了盡可能的減少碎片-伙伴演算法正式登場
伙伴演算法,簡而言之,就是將記憶體分成若干塊,然后盡可能以最適合的方式滿足程式記憶體需求的一種記憶體管理演算法,而針對于Linux作業系統還有針對更小塊記憶體申請的slab分配機制,好在JAVA不涉及此部分,申請時,伙伴演算法會給程式分配一個較大的記憶體空間,即保證所有大塊記憶體都能得到滿足,
其中大小為 b 的一對空閑伙伴塊合并為一個大小為 2b 的單獨塊,滿足以下條件的兩個塊稱為伙伴:
- 兩個塊具有相同的大小,記作 b
- 它們的物理地址是連續的
下面通過一個簡單的例子來說明該演算法的作業原理:
假設系統中有 1MB 大小的記憶體需要動態管理,按斬訓伴演算法的要求:需要將這1M大小的記憶體進行劃分,這里,我們將這1M的記憶體分為 64K、64K、128K、256K、和512K 共五個部分,如下圖所示:
![]()
而記憶體申請的程序如下:
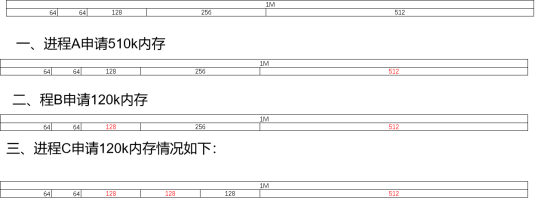
可以說想了解伙伴演算法關鍵就是要多畫畫上面這張圖,當然你不了解伙伴演算法也沒關系,以下幾個結論記住就可以了,
有關伙伴演算法需要仔細畫一下圖才能了解,這里只要先了解下面幾個結論就好,
1作業系統會在行程申請或者釋放記憶體的同時進行記憶體碎片的整理,
2在記憶體使用率比較高的情況下去申請或者釋放記憶體都可能造成作業系統頻繁進行記憶體頁的合并或者切割,而這樣的操作都是加鎖保護的,一般會使系統整體的運行效率大幅下降,
問題的啟示
那么這個問題的啟示也非常明顯,
首先作業系統和JAVA都沒有開大記憶體頁的功能,這造成每次申請都是小步快跑式的,無論對于JVM還是對作業系統都是極大的負擔,
其次本質上講JAVA是作業系統的一個行程,他只能看到邏輯空間,但是JAVA虛擬機JVM本身也具有作業系統的屬性,也需要進行記憶體的分頁管理,以盡量減少碎片的產生,并且JAVA還要進行垃圾回收,記憶體的管理對于JAVA本身壓力就比C的程式大,而每次小規模記憶體的申請都要經過JVM與作業系統兩道工序,這也極大的拖慢了速度,
以上就是個人對于鄒老師上午提出JAVA記憶體管理小問題進行的一個初步歸納與總結,比較匆忙不當之處請指正!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/275392.html
標籤:AI