Redis資料同步:主從庫實作資料一致
Redis實體宕機了怎么辦
我們知道通過AOF和RDB,如果Redis發生了宕機,它們可以分別通過回放日志和重新讀入 RDB檔案的方式恢復資料,從而保證盡量少丟失資料,提升可靠性,
不過,即使用了這兩種方法,也依然存在服務不可用的問題,比如說,我們在實際使時只運行了以個 Redis實體,那么,如果這個實體宕機了,它在恢復期間,是無法服務新來的資料存取請求的,
那我們總說的Redis具有高可靠性,又是什么意思呢?其實,這里有兩層含義:
-
1.資料盡量少丟失
-
2.服務盡量少中斷,
AOF和RDB保證了前者,?對于后者,Redis的做法就是增加副本冗余量 ,將一份資料同時保存在多個實體上,即使有一個實體出現了故障,需要過一段時間才能恢復,其他實體也可以對外提供服務,不會影響業務使用,
多實體保存同一份資料,但是,我們必須要考慮一個問題:這么多副本,它們之間的資料如何保持一致呢?資料讀寫操作可以發給所有的實體嗎?
實際上,Redis提供了主從庫模式,以保證資料副本的一致,主從庫之間采用的是讀寫分離的方式,
-
讀操作:主庫、從庫都可以接受;
-
寫操作:首先到主庫執行,然后,主庫將寫操作同步給從庫,
為什么要采用讀寫分離的方式?
設想一下,在一個一主多從的Redis 系統中,不管是主庫還是從庫,都能接收客戶端的寫操作,那么,一個直接的問題就是:如果客戶端對同一個資料(例如k1)前后修改了三次,每一次的修改請求都發送到不同的實體上,在不同的實體上執行,那么這個資料在這三個實體上的副本就不一致的了(分別是v1、v2和v3),在讀取這個資料的時候,就可能讀取到舊的值,
如果我們非要保持這個資料在三個實體上一致,就要涉及到加鎖、實體間協商是否完成修改等一系列操作,但這會帶來巨額的開銷,當然是不太能接受的,
而主從庫模式一旦采用了讀寫分離,所有資料的修改只會在主庫上進行,不用協調三個實體,主庫有了最新的資料后,會同步給從庫,這樣,主從庫的資料就是一致的,
那么,主從庫同步是如何完成的呢?主庫資料是一次性傳給從庫,還是分批同步?要是主從庫間的網路斷連了,資料還能保持一致嗎?本文就來討論一下主從庫同步的原理,以及應對網路斷連風險的方案,
我們先來看看主從庫間的第一次同步是如何進行的,這也是Redis實體建立主從庫模式后的規定動作,
主從庫間如何進行第一次同步?
當我們啟動多個Redis實體的時候,它們相互之間就可以通過replicaof(Redis 5.0之前使用slaveof)命令形成主庫和從庫的關系,之后會按照三個階段完成資料的第一次同步,
例如,現在有實體1(ip:172.16.19.3)和實體2(ip:172.16.19.5),我們在實體2上執行以下這個命令后,實體2就變成了實體1的從庫,并從實體1上復制資料:
replicaof 172.16.19.3 6379

-
第一階段:主從庫間建立連接、協商同步的程序,主要是為全量復制做準備,在這一步,從庫和主庫建立起連接,并告訴主庫即將進行同步,主庫確認回復后,主從庫間就可以開始同步了
- 具體來說,從庫給主庫發送
psync命令,表示要進行資料同步,主庫根據這個命令的引數來啟動復制,psync命令包含了主庫的runID和復制進度offset兩個引數, - runID : 每個Redis實體啟動時都會?動?成的?個隨機ID,?來唯?標記這個實體,當從庫和主庫第? 次復制時,因為不知道主庫的runID,所以將runID設為“?”,
- offset: 此時設為-1,表?第?次復制,
- 具體來說,從庫給主庫發送
-
主庫收到psync命令后,會?FULLRESYNC回應命令帶上兩個引數:主庫runID和主庫?前的復制進度 offset,回傳給從庫,從庫收到回應后,會記錄下這兩個引數
-
這里有個地方需要注意,FULLRESYNC回應表示第一次復制采用的全量復制,也就是說,主庫會把當前所有的資料都復制給從庫,
-
第二階段:主庫將所有資料同步給從庫,從庫收到資料后,在本地完成資料加載,這個程序依賴于記憶體快照生成的RDB檔案,
-
具體來說,主庫執行
bgsave命令,生成RDB檔案,接著將檔案發給從庫,從庫接收到RDB檔案后,會先清空當前資料庫,然后加載RDB檔案,這是因為從庫在通過replicaof命令開始和主庫同步前,可能保存了其他資料,為了避免之前資料的影響,從庫需要先把當前資料庫清空, -
在主庫將資料同步給從庫的程序中,主庫不會被阻塞,仍然可以正常接收請求,否則,Redis的服務就被中斷了,但是,這些請求中的寫操作并沒有記錄到剛剛生成的RDB檔案中,為了保證主從庫的資料一致性,主庫會在記憶體中用專門的replication buffer,記錄RDB檔案生成后收到的所有寫操作,
-
-
第三階段:主庫會把第一階段執行程序中新收到的寫命令,再發送給從庫,具體的操作是,當主庫完成RDB檔案發送后,就會把此時
replication buffer中的修改操作發給從庫,從庫再重新執行這些操作,這樣一來,主從庫就實作同步了,
主從級聯模式分擔全量復制時的主庫壓力
通過分析主從庫間第一次資料同步的程序可以看到,一次全量復制中,對于主庫來說,需要完成兩個耗時的操作:生成RDB檔案和傳輸RDB檔案,
如果從庫數量很多,而且都要和主庫進行全量復制的話,就會導致主庫忙于fork行程生成RDB檔案,進行資料全量同步,fork這個操作會阻塞主執行緒處理正常請求,從而導致主庫回應應用程式的請求速度變慢,此外,傳輸RDB檔案也會占用主庫的網路帶寬,同樣會給主庫的資源使用帶來壓力,那么,有沒有好的解決方法可以分擔主庫壓力呢?
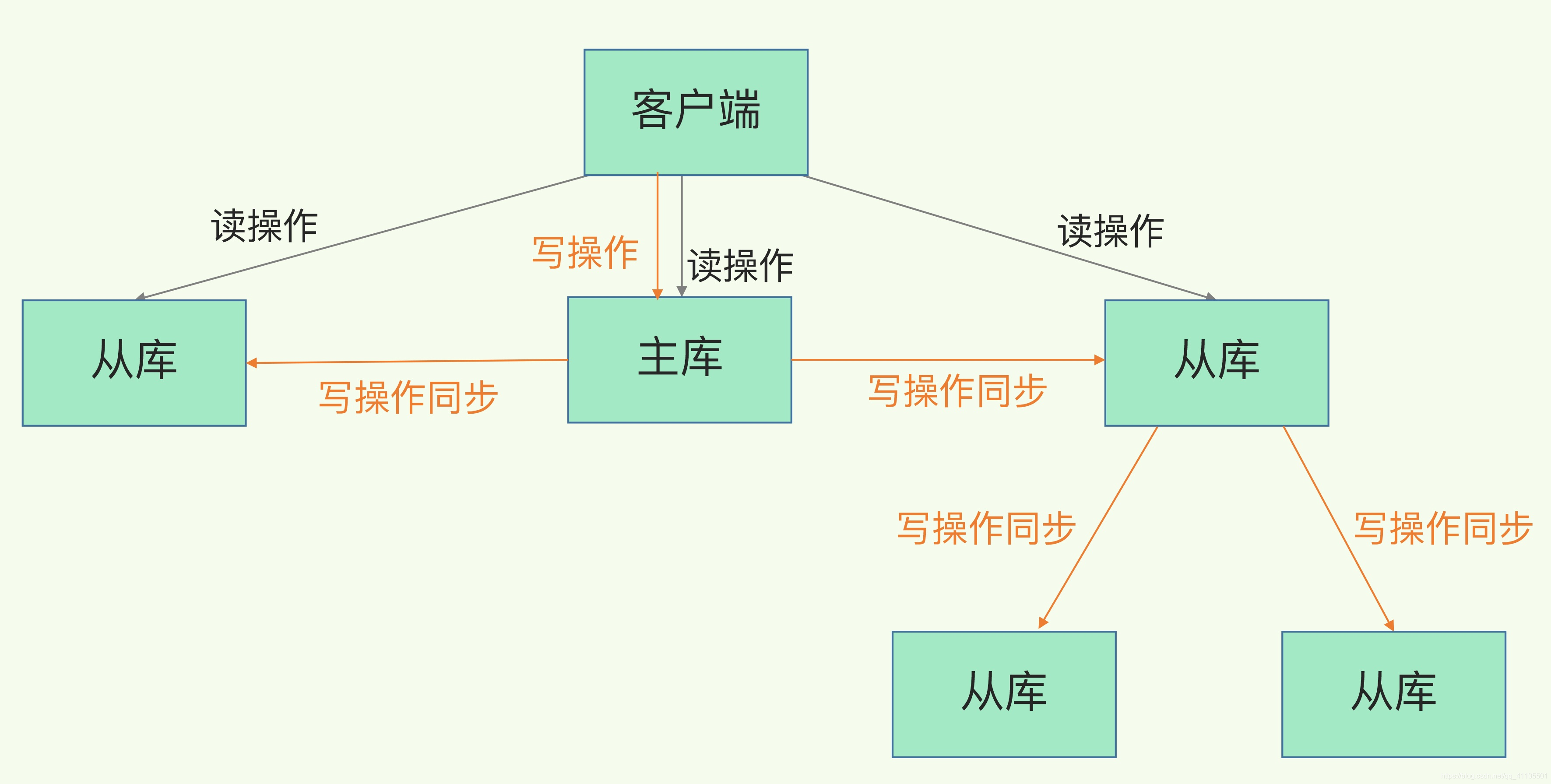
主-從-從 級聯模式:在剛才介紹的主從庫模式中,所有的從庫都是和主庫連接,所有的全量復制也都是和主庫進行的,現在,我們可以通過“主-從-從”模式將主庫生成RDB和傳輸RDB的壓力,以級聯的方式分散到從庫上,
- 簡單來說,我們在部署主從集群的時候,可以手動選擇一個從庫(比如選擇記憶體資源配置較高的從庫),用于級聯其他的從庫,然后,我們可以再選擇一些從庫(例如三分之一的從庫),在這些從庫上執行如下命令,讓它們和剛才所選的從庫,建立起主從關系,
replicaof 所選從庫的IP 6379
這樣這些從庫就會知道,在進行同步時,不會再和主庫進行互動了,只要和級聯的從庫進行寫操作同步就行了,這就可以減輕主庫上的壓力,如下圖所示:
從此一旦主從庫完成了全量復制,它們之間就會維護一個網路連接,主庫會通過這個連接將后續陸續收到的命令操作再同步給從庫,這個程序也稱為基于長連接的命令傳播,可以避免頻繁建立連接的開銷,
但是這個程序中存在著風險點,最常見的就是網路斷連或阻塞,如果網路斷連,主從庫之間就無法進行命令傳播了,從庫的資料自然也就沒辦法和主庫保持一致了,客戶端就可能從從庫讀到舊資料,
主從庫間網路斷連怎么辦?
從Redis 2.8開始,網路斷了之后,主從庫會采用增量復制的方式繼續同步,即只會把主從庫網路斷連期間主庫收到的命令,同步給從庫,
增量復制時,主從庫之間如何保持同步?
-
增量復制的重點在
repl_backlog_buffer這個緩沖區,當主從庫斷連后,主庫會把斷連期間收到的寫操作命令,寫入replication buffer,同時也會把這些操作命令寫入repl_backlog_buffer這個緩沖區, -
repl_backlog_buffer是一個環形緩沖區,主庫會記錄自己寫到的位置,從庫則會記錄自己已經讀到的位置, -
剛開始的時候,主庫和從庫的寫讀位置在一起,這算是它們的起始位置,隨著主庫不斷接收新的寫操作,它在緩沖區中的寫位置會逐步偏離起始位置,我們通常用偏移量來衡量這個偏移距離的大小,對主庫來說,對應的偏移量就是
master_repl_offset,主庫接收的新寫操作越多,這個值就會越大, -
同樣,從庫在復制完寫操作命令后,它在緩沖區中的讀位置也開始逐步偏移剛才的起始位置,此時,從庫已復制的偏移量
slave_repl_offset也在不斷增加,正常情況下,這兩個偏移量基本相等
主從庫連接恢復后:
-
主從庫的連接恢復之后,從庫首先會給主庫發送
psync命令,并把自己當前的slave_repl_offset發給主庫,主庫會判斷從庫的master_repl_offset和slave_repl_offset之間的差距, -
在網路斷連階段,主庫可能會收到新的寫操作命令,所以,一般來說,
master_repl_offset會大于slave_repl_offset,此時,主庫只用把master_repl_offset和slave_repl_offset之間的命令操作同步給從庫就行,
當然這里需要注意的是,因為 repl_backlog_buffer 是一個環形緩沖區,所以在緩沖區寫滿后,主庫會繼續寫入,此時,就會覆寫掉之前寫入的操作,如果從庫的讀取速度比較慢,就有可能導致從庫還未讀取的操作被主庫新寫的操作覆寫了,這會導致主從庫間的資料不一致,
從庫還未讀取的操作被主庫新寫的操作覆寫?
要想辦法避免這一情況,一般而言,我們可以調整 repl_backlog_size 這個引數,這個引數和所需的緩沖空間大小有關,緩沖空間的計算公式是:緩沖空間大小 = 主庫寫入命令速度 * 操作大小 - 主從庫間網路傳輸命令速度 * 操作大小,在實際應用中,考慮到可能存在一些突發的請求壓力,我們通常需要把這個緩沖空間擴大一倍,即 repl_backlog_size = 緩沖空間大小 * 2,這也就是 repl_backlog_size的最終值,
示例:如果主庫每秒寫入2000個操作,每個操作的大小為2KB,網路每秒能傳輸1000個操作,那么,有1000個操作需要緩沖起來,這就至少需要2MB的緩沖空間,否則,新寫的命令就會覆寫掉舊操作了,為了應對可能的突發壓力,我們最終把 repl_backlog_size 設為4MB,
這樣一來,增量復制時主從庫的資料不一致風險就降低了,不過,如果并發請求量非常大,連兩倍的緩沖空間都存不下新操作請求的話,此時,主從庫資料仍然可能不一致, 針對這種情況,一方面,你可以根據Redis所在服務器的記憶體資源再適當增加 repl_backlog_size值,比如設定成緩沖空間大小的4倍,另一方面,你可以考慮使用切片集群來分擔單個主庫的請求壓力,
小結
Redis的主從庫同步的基本原理,三種模式:全量復制、基于長連接的命令傳播,以及增量復制,
-
全量復制雖然耗時,但是對于從庫來說,如果是第一次同步,全量復制是無法避免的,
- 所以建議:一個Redis實體的資料庫不要太大,一個實體大小在幾GB比較合適,這樣可以減少RDB檔案生成、傳輸和重新加載的開銷,另外,為了避免多個從庫同時和主庫進行全量復制,給主庫過大的同步壓力, 我們也可以采用“主-從-從”級聯模式,來緩解主庫的壓力
-
長連接復制是主從庫正常運行后的常規同步階段,在這個階段中,主從庫之間通過命令傳播實作同步,不過,這期間如果遇到了網路斷連,就需要使用增量復制,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/275433.html
標籤:其他
上一篇:CSDN【精品專欄】第14期
下一篇:Centos7安裝Redis