QUESTION
Before you get started, explore the website https://www.abc.net.au/news/justin
We are interested in the titles of and hyperlinks to the news items in the Just In section. More specifically, that's the section that is highlighted in the following image:
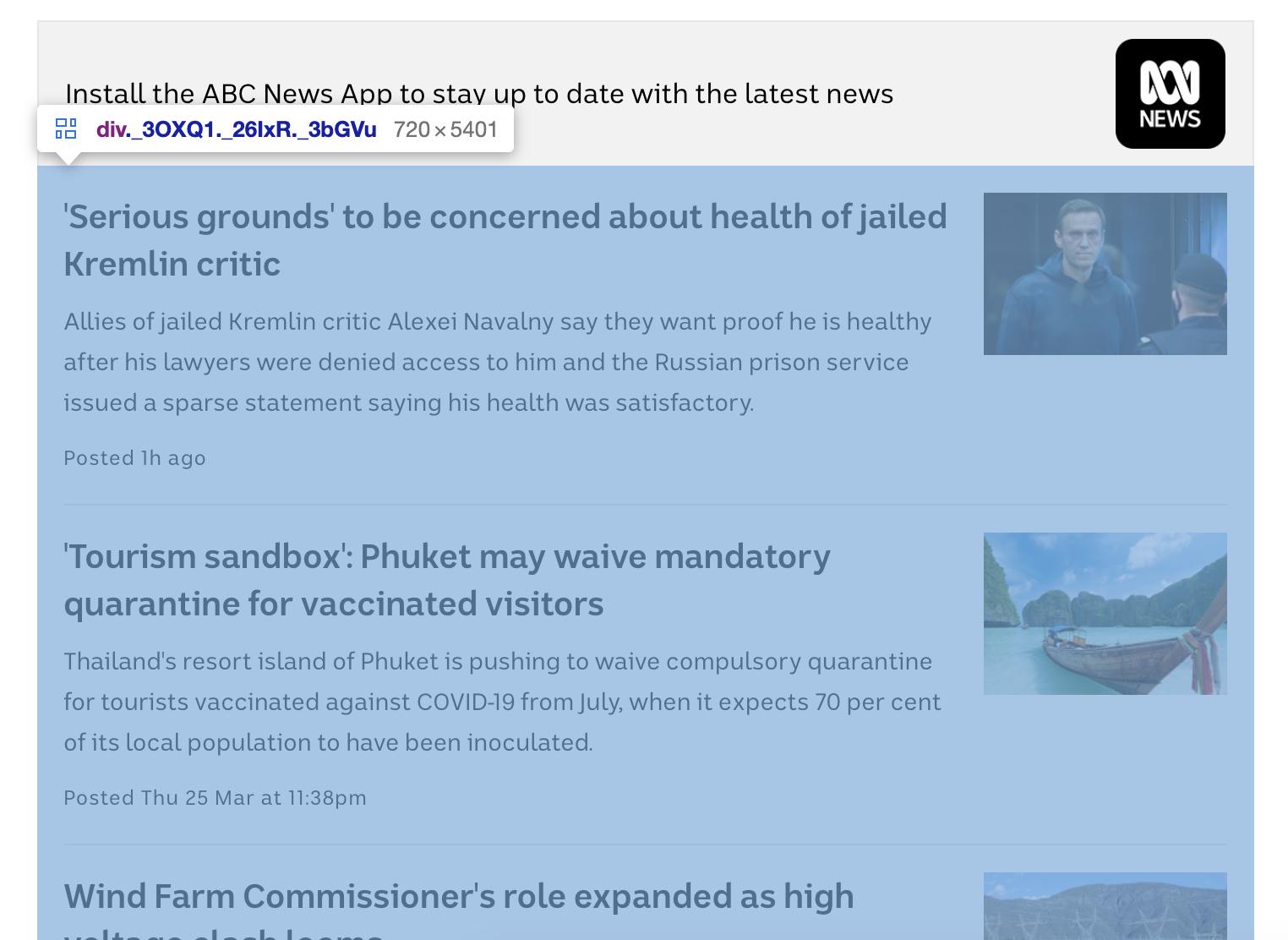
The content on that page has obviously been updated since this exercise was set up. Still, even though the exact content changed, the principle stays the same.
What you need to do is:
Scrape all the (1) titles, (2) the underlying hyperlinks, and the (3) descriptions of the news items in the highlighted section of the Just In page. In the historic example in the screenshot that would be 'Serious grounds to be concerned about...', 'Tourism sandbox: Phuket...', etc. for the titles, the urls you are directed to if you would click those titles, and the descriptions 'Allies of jailed...', 'Thailand's resort island...', etc. that belong to the titles.
Save the information into a csv file named ‘abcnews.csv’ that contains three variables: ‘title’, ‘url’, and 'descriptions'. One row for each article, combining title, hyperlink, and description for that article.
目前寫成這樣怎么也實作不了
from urllib.request import Request, urlopen
import ssl
from bs4 import BeautifulSoup
import pandas as pd
url = 'https://www.abc.net.au/news/justin'
#################################################
#################################################
###
headers={'User-Agent': 'Mozilla/5.0 (Macinstosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36(KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36'}
req = Request(url, headers=headers)
context = ssl._create_unverified_context()
uClient= urlopen(req, context=context)
html = uClient.read()
uClient.close()
#################################################
#################################################
soup = BeautifulSoup(html, 'html.parser')
divofinterest = soup.find_all('div',class_='_3OXQ1 _26IxR _3bGVu')
dataset = []
for item in divofinterest('a'):
title = item.find('p').getText()
url = item['href']
print(title)
print(url)
print()
dataset.append({'title':title,'url':url})
dataset = pd.DataFrame(dataset)
dataset.to_csv('abcnews.csv',sep=';',index=False)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/275604.html