撰寫高質量可維護的代碼既是程式員的基本修養,也是能決定專案成敗的關鍵因素,本文試圖總結出問題專案普遍存在的共性問題并給出相應的解決方案,
1. 程式員的宿命?
程式員的職業生涯中難免遇到爛專案,有些專案是你加入時已經爛了,有些是自己從頭開始親手做成了爛專案,有些是從里到外的爛,有些是表面光鮮等你深入進去發現是個“焦油坑”,有些是此時還沒爛但是已經出現問題征兆走在了腐爛的路上,
國內基本上是這樣,國外情況我了解不多,不過從英文社區和技術媒體上老外同行的抱怨程度看,應該是差不多的,雖然整體素質可能更高,但是也因更久的資訊化而積累了更多問題,畢竟“焦油坑、Shit_Mountain 屎山”這些舶來的術語不是無緣無故被發明出來的,
Any way,這大概就是我們這個行業的宿命——要么改行,要么就是與爛專案爛代碼長相伴,
就像宇宙的“熵增加定律”一樣:
孤立系統的一切自發程序均向著令其狀態更無序的方向發展,如果要使系統恢復到原先的有序狀態是不可能的,除非外界對它做功,
面對這宿命的陰影,有些人認命了麻木了,逐漸對這個行業失去熱情,
那些不認命的選擇與之抗爭,但是地上并沒有路,當年軟體危機的陰云也從未真正散去,人月神話仍然是神話,于是人們做出了各自不同的判斷和嘗試:
- 掀桌子另起爐灶派:
- 很多人把專案做爛的原因歸咎于專案前期的基礎沒打好、需求不穩定一路打補丁、前面的架構師和程式員留下的爛攤子難以收拾,
- 他們要么沒有信心去收拾爛攤子,要么覺得這是費力不討好,于是要放棄掉專案,寄希望于出現一個機會能重頭再來,
- 但是他們對于如何避免重蹈覆轍、做出另一個爛專案是沒有把握也沒有深入思考的,只是盲目樂觀的認為自己比前任更高明,
- 激進改革派:
- 這個派別把原因歸結于爛專案當初沒有采用正確的編程語言、最新最強大的技術堆疊或工具,
- 他們中一部分人也想著有機會另起爐灶,用時下最流行最熱門的技術堆疊(spring boot、springcloud、redis、nosql、docker、vue),
- 或者即便不另起爐灶,也認為現有技術堆疊太過時無法容忍了(其實可能并不算過時),不用微服務不用分布式就不能接受,于是激進的引入新技術堆疊,魯莽的對專案做大手術,
- 這種對剛剛流行還不成熟技術的盲目跟風、技術選型不慎重的情況非常普遍,今天在他們眼中落伍的技術堆疊,其實也不過是幾年前另一批人趕的時髦,
- 我不反對技術上的追新,但是同樣的,這里的問題是:他們對于大手術的風險和副作用,對如何避免重蹈覆轍用新技術架構做出另一個爛專案,沒有把握也沒有深入思考的,只是盲目樂觀的認為新技術能帶來成功,
- 也沒人能阻止這種簡歷驅動的技術選型浮躁風氣,畢竟花的是公司的資源,用新東西顯得自己很有追求,失敗了也不影響簡歷美化,簡歷上只會增加一段專案履歷和幾種精通技能,不會提到又做爛了一個專案,名利雙收穩賺不賠,
- 保守改良派:
- 還有一類人他們不愿輕易放棄這個有問題但仍在創造效益的專案,因為他們看到了專案仍然有維護的價值,也看到了另起爐灶的難度(萬事開頭難,其實專案的冷啟動存在很多外部制約因素)、大手術對業務造成影響的代價、系統遷移的難度和風險,
- 同時他們嘗試用溫和漸進的方式逐步改善專案質量,采用一系列工程實踐(主要包括重構熱點代碼、補自動化測驗、補檔案)來清理“技術債”,消除制約專案開發效率和交付質量的瓶頸,
如果把一個問題專案比作病入膏肓的病人,那么這三種做法分別相當于是放棄治療、截肢手術、保守治療,
2. 一個 35+ 程式員的反思
年輕時候我也是掀桌子派和激進派的,新工程新框架大開大合,一路走來經驗值技能樹蹭蹭的漲,跳槽加薪好不快活,
但是近幾年隨著年齡增長,一方面新東西學不動了,另一方面對經歷過的專案反思的多了觀念逐漸改變了,
對我觸動最大的一件事是那個我在 2016 年初開始從零搭建起的專案,在我 2018 年底離開的時候(僅從代碼質量角度)已經讓我很不滿意了,只是,這一次沒有任何借口了:
- 從技術選型到架構設計到代碼規范,都是我自己做的,團隊不大,也是我自己組建和一手帶出來的;
- 最開始的半年進展非常順利,用著我最趁手的技術和工具一路狂奔,年底前替換掉了之前采購的那個垃圾產品(對的,有個前任在業務上做參照也算是個很大的有利因素);
- 做的程序我也算是全力以赴,用盡畢生所學——前面 13 年作業的經驗值和走過的彎路、教訓,使得公司只用其它同類公司同類專案 20% 的資源就把平臺做起來了;
- 如果說多快好省是最高境界,那么當時的我算是做到了多、快、省——交付的功能非常豐富且貼近業務需求、開發節奏快速、對公司開發資源很節省;
- 但是現在看來,“好”就遠遠沒有達到了,到了專案中期,簡單優先級高的需求都已經做完了,公司業務上出現了新的挑戰——接入另一個核心系統以及外部平臺,真正的考驗來了,
- 那個改造工程影響面比較大,需要對我們的系統做大面積修改,最麻煩的是這意味著從一個簡單的單體系統變成了一個分布式的系統,而且業務涉及資金交易,可靠性要求較高,是難上加難,
- 于是問題開始出現了:我之前架構的優點——簡單直接——這個時候不再是優點了,簡單直接的架構在業務環境、技識訓境都簡單的情況下可以做到多快好省,但是當業務、技識訓境都陡然復雜起來時,就不行了;
- 具體的表現就是:架構和代碼層面的結構都快速的變得復雜、混亂起來了——熵急劇增加;
- 后面的事情就一發不可收拾:代碼改起來越來越吃力、測驗問題變多、生產環境故障和問題變多、于是消耗在排查測驗問題生產問題和修復資料方面的精力急劇增加、出現惡性回圈,,,
- 到了這個境地,專案就算是做爛了!一個我從頭開始做起的沒有任何借口的失敗!
于是我意識到一個非常淺顯的道理:擁有一張空白的畫卷、一支最高級的畫筆、一間專業的畫室,無法保證你可以畫出美麗的畫卷,如果你不善于畫畫,那么一切都是空想和意淫,
然后我變成了一個“保守改良派”,因為我意識到掀桌子和激進的改革都是不負責任的,說不好聽的那樣其實是掩耳盜鈴、逃避困難,人不可能逃避一輩子,你總要面對,
即便掀了桌子另起爐灶了,你還是需要找到一種辦法把這個新的爐灶燒好,因為隨著專案發展之前的老問題還是會一個一個冒出來,還是需要面對現實、不逃避、找辦法,
面對問題不僅有助于你把當前專案做好,也同樣有助于將來有新的專案時更好的把握住機會,
無論是職業生涯還是自然年齡,人到了這個階段都開始喜歡回顧和總結,也變得比過去更在乎專案、產品乃至公司的商業成敗,
軟體開發作為一種商業活動,判斷其成敗的依據應該是:能否以可接受的成本、可預期的時間節奏、穩定的質量水平、持續交付滿足業務需要的功能市場需要的產品,
其實就是專案管理四要素——成本、進度、范圍、質量,傳統專案管理理論認為這四要素彼此制約難以兼得,專案管理的藝術在于四要素的平衡取舍,
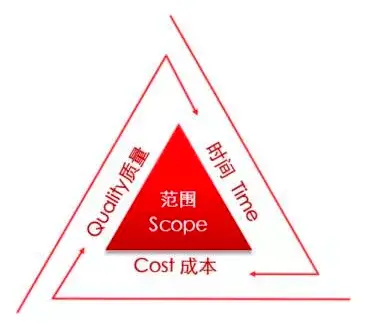
關于軟體工程和專案管理的理論和著作已經很多很成熟,這里我從程式員的視角提出一個新的觀點——質量不可妥協:
- 質量要素不是一個可以被犧牲和妥協的要素——犧牲質量會導致其它三要素全都受損,反之同理,追求質量會讓你在其它三個方面同時受益,
- 在保持一個質量水平的前提下,成本、進度、范圍三要素確確實實是互相制約關系——典型的比如犧牲成本(加班加點)來加快進度交付急需的功能,
- 正如著名的“破窗效應”所啟示的那樣:任何一種不良現象的存在,都在傳遞著一種資訊,這種資訊會導致不良現象的無限擴展,同時必須高度警覺那些看起來是偶然的、個別的、輕微的“過錯”,如果對這種行為不聞不問、熟視無睹、反應遲鈍或糾正不力,就會縱容更多的人“去打爛更多的窗戶玻璃”,就極有可能演變成“千里之堤,潰于蟻穴”的惡果——質量不佳的代碼之于一個專案,正如一扇破了的窗之于一幢建筑、一個螞蟻巢之于一座大堤,
- 好訊息是,只要把質量提上去專案就會逐漸走上健康的軌道,其它三個方面也都會改善,管好了質量,你就很大程度上把握住了專案成敗的關鍵因素,
- 壞訊息是,專案的質量很容易失控,現實中質量不佳、越做越臃腫混亂的專案比比皆是,質量改善越做越好的案例聞所未聞,以至于人們將其視為如同物理學中“熵增加定律”一樣的必然規律了,
- 當然任何事情都有一個度的問題,當質量低于某個水平時才會導致其它三要素同時受損,反之當質量高到某個水平以后,繼續追求質量不僅得不到明顯收益,而且也會損害其它三要素——邊際效用遞減定律,
- 這個度需要你為自己去評估和測量,如果目前的質量水平還在兩者之間,那么就應該重點改進專案質量,當然,現實世界中很少看到哪個專案質量高到了不需要重視的程度,
3. 專案走向衰敗的最常見誘因——代碼質量不佳
一個專案的衰敗一如一個人健康狀況的惡化,當然可能有多種多樣的原因——比如需求失控、業務調整、人員變動流失,但是作為我們技術人,如果能做好自己分內的作業——撰寫出可維護的代碼、減少技術債利息成本、交付一個健壯靈活的應用架構,那也絕對是功德無量的,
雖然很難估算出這究竟能挽救多少專案,但是在我十多年職業生涯中,經歷的和近距離觀察的幾十個專案,確實看到了大量的專案正是由于代碼質量不佳導致的失敗和遺憾,同時我也發現其實失敗專案的很多問題、癥結也確確實實都可以歸因到專案代碼的混亂和質量低下,比如一個常見的專案腐爛惡性回圈:代碼亂》bug 多》排查問題耗時》復用度低》加班 996》士氣低落……
所謂“千里之堤,毀于蟻穴”,代碼問題就是蟻穴,
接下來,讓我們從專案管理聚焦到專案代碼質量這個相對小的領域來深入剖析,撰寫高質量可維護的代碼是程式員的基本修養,本文試圖在代碼層面找到一些失敗專案中普遍存在的癥結問題,同時基于個人十幾年開發經驗總結出的一些設計模式作為藥方分享出來,
關于代碼質量的話題其實很難通過一篇文章闡述明白,甚至需要一本書的篇幅,里面涉及到的很多概念關注點之間存在復雜微妙關系,
推薦《設計模式之美》的第二章節《從哪些維度評判代碼質量的好壞?如何具備寫出高質量代碼的能力?》,這是我看到的關于代碼質量主題最精彩深刻的論述,
4. 一個失敗專案復盤
先貼幾張代碼截圖,看一下這個重病纏身的專案的病灶和癥狀:
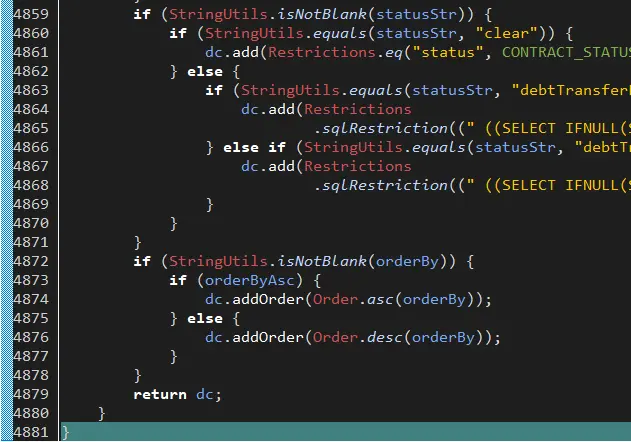
- 這是該專案中一個最核心、最復雜也是最經常要被改動的 class,代碼行數 4881;
- 結果就是冗長的 API 串列(串列需要滾動 4 屏才能到底,公有私有 API 180 個);
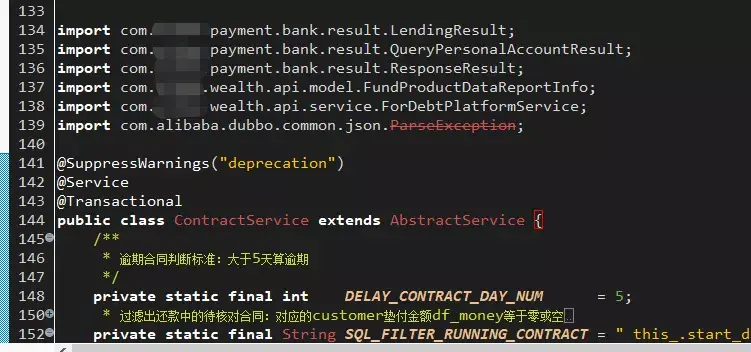
- 還是那個 Class,頭部的 import 延綿到了 139 行,去掉第一行 package 宣告和少量空行總共 import 引入了 130 個 class!
- 還是那個坑爹的組件,從 156 行開始到 235 行宣告了 Spring 依賴注入的組件 40 個!
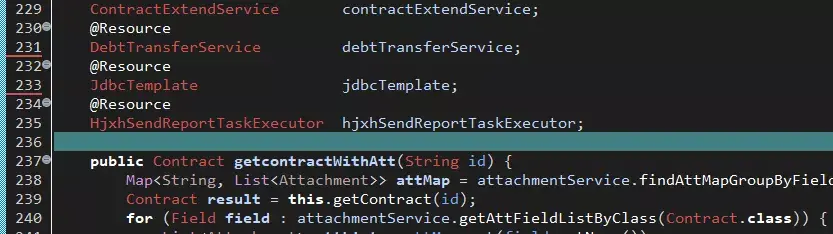
這里先不去分析這個類的問題,只是初步展示一下病情嚴重程度,
我相信這應該不算是特別糟糕的情況,比這個嚴重的專案俯拾皆是,但是這也應該足夠拿來暴露問題、剖析成因了,
4.1 癥結 1:組件粒度過大、API 泛濫
分層的理念早已深入人心,尤其是業務邏輯層的獨立,徹底杜絕了之前(不分層的年代)業務邏輯與展現邏輯、持久化邏輯等混雜的問題,
但是好景不長,隨著業務的復雜和變更,在業務邏輯層的復雜性也急劇增加,成為了新的開發效率瓶頸,
問題就出在了業務邏輯組件的劃分方式——按領域模型劃分業務邏輯組件:
- 業界關于如何設計業務邏輯層 并沒有標準和最佳實踐,絕大多數專案(我自己經歷過的專案以及我有機會深入了解的專案)中大家都是想當然的按照業務領域物件來設計;
- 例如:領域物體物件有 Account、Order、Delivery、Campaign,于是業務邏輯層就設計出 AccountService、OrderService、DeliveryService、CampaignService
- 這種做法在專案簡單是沒什么問題,事實上專案簡單時 你隨便怎么設計都問題不大,
- 但是當專案變大和復雜以后,就會出現問題了:
- 組件臃腫:Service 組件的個數跟領域物體物件個數基本相當,必然造成個別 Service 組件變得非常臃腫——API 非常多,代碼行數達到幾千行;
- 職責模糊:業務邏輯往往跨多個領域物體,無論放在哪個 Service 都不合適,同樣的,要找一個功能的實作邏輯也無法確定在哪個 Service 中;
- 代碼重復 or 邏輯糾纏的兩難選擇:當遇到一個業務邏輯,其中的某個環節在另一個業務邏輯 API 中已經實作,這時如果不想忍受重復實作和代碼,就只能去呼叫那個 API,但這樣就造成了業務邏輯組件之間的耦合與依賴,這種耦合與依賴很快會擴散——新的 API 又會被其它業務邏輯依賴,最終形成蜘蛛網一樣的復雜依賴甚至回圈依賴;
- 復用代碼、減少重復雖然是好的,但是復雜耦合依賴的害處也很大——趕走一只狼引來了一只虎,兩杯毒酒給你選!
前面截圖的那個問題組件 ContractService 就是一個典型案例,這樣的組件往往是熱點代碼以及整個專案的開發效率的瓶頸,
4.2 藥方 1:倒金字塔結構——業務邏輯組件職責單一、禁止層內依賴
問題根源的反面其實就藏著解決方案,只是需要我們有意識的去改變習慣、遵循新的設計風格,而不是憑直覺去設計:
- 業務邏輯層應該被設計成一個個功能非常單一的小組件,所謂小是指 API 數量少、代碼行數少;
- 由于職責單一因此必然組件數量多,每一個組件對應一個很具體的業務功能點(或者幾個相近的);
- 復用(呼叫、依賴)只應該發生在相鄰的兩層之間——上層呼叫下層的 API 來實作對下層功能的復用;
- 于是系統架構就自然呈現出倒立的金字塔形狀:越接近頂層的業務場景組件數量越多,越往下層的復用性高,于是組件數量越少,
4.3 癥結 2:低內聚、高耦合
經典面向物件理論告訴我們,好的代碼結構應該是“高內聚、低耦合”的:
- 高內聚:組件本身應該盡可能的包含其所實作功能的所有重要資訊和細節,以便讓維護者無需跳轉到其它多個地方去了解必要的知識,
- 低耦合:組件之間的互相依賴和了解盡可能少,以便在一個組件需要改動時其它組件不受影響,
其實這兩者就是一體兩面,做到了高內聚基本也就做到了低耦合,相反如果內聚度很低,勢必存在大量高耦合的組件,
我觀察發現,很低專案都存在低內聚、高耦合的問題,根本原因在于很多程式員,甚至是很多經驗豐富的程式員也缺少這方面的意識——對概念不甚清楚、對危害沒有認識、對如何避免更是無從談起,
很多人從一開始就憑直覺寫程式,有了一定經驗以后一般能認識到重復代碼的危害,對復用性有很強的認識,于是就會掉進一個陷阱——盲目追求復用,結果破壞了內聚性,
- 業界關于“復用性”的認識存在一個誤區——認為包括業務邏輯組件在內的任何層面的組件都應該追求最大限度的可復用性;
- 復用當然是好的,但那應該有個前提條件:不增加系統復雜度的情況下的復用,才是好的,
- 什么樣的復用會增加系統復雜性、是不好的呢?前面提到的,一個業務邏輯 API 被另一個業務邏輯 API 復用——就是不好的:
- 損害了穩定性:因為業務邏輯本身是跟現實世界的業務掛鉤的,而業務會發生變化;當你復用一個會發生變化的 API,相當于在沙子上建高樓——地基是松動的;
- 增加了復雜性:這樣的依賴還造成代碼可讀性降低——在一個本就復雜的業務邏輯代碼中,包含了對另一個復雜業務邏輯的呼叫,復雜度會急劇增加,而且會不斷泛濫和傳遞;
- 內聚性被破壞:由于業務邏輯被打散在了多個組件的方法內,變得支離破碎,無法在一個地方看清整體邏輯脈絡和實作步驟——內聚性被破壞,同時也意味著,這個呼叫鏈條上涉及的所有組件之間存在高耦合,
4.4 藥方 2:復用的兩種正確姿勢——打造自己的 lib 和 framework
軟體架構中有兩種東西來實作復用——lib 和 framework,
- lib 庫是供你(應用程式)呼叫的,它幫你實作特定的能力(比如日志、資料庫驅動、json 序列化、日期計算、http 請求),
- framework 框架是供你擴展的,它本身就是半個應用程式,定義好了組件劃分和互動機制,你需要按照其規則擴展出特定的實作并系結集成到其中,來完成一個應用程式,
- lib 就是組合方式的復用,framework 則是繼承式的復用,繼承的 Java 關鍵字是 extends,所以本質上是擴展,
- 過去有個說法:“組合優于繼承,能用組合解決的問題盡量不要繼承”,我不同意這個說法,這容易誤導初學者以為組合優于繼承,其實繼承才是面向物件最強大的地方,當然任何東西都不能亂用,
- 典型的繼承亂用就是為了獲得父類的某個 API 而去繼承,繼承一定是為了擴展,而不是為了直接獲得一個能力,獲得能力應該呼叫 lib,父類不應該去實作具體功能,那是 lib 該做的事,
- 也不應該為了使用 lib 而去繼承 lib 中的 Class,lib 就是用來被組合被呼叫的,framework 就是用來被繼承、擴展的,
- 再展開一下:lib 既可以是第三方的(log4j、httpclient、fastjson),也可是你自己工程的(比如你的持久層 Dao、你的 utils);
- framework 同理,既可以是第三方的(springmvc、jpa、springsecurity),也可以是你專案內封裝的面向具體業務領域的(比如 report、excel 匯出、paging 或任何可復用的演算法、流程),
- 從這個意義上說,一個專案中的代碼其實只有 3 種:自定義的 lib class、自定義的 framework 相關 class、擴展第三方或自定義 framework 的組件 class,
- 再擴展一下:相對于過去,現在我們已經有了足夠多的第三方 lib 和 framework 來復用,來幫助專案節省大量代碼,開發作業似乎變成了索然無味、沒技術含量的 CRUD,但是對于業務非常復雜的專案,則需要有經驗、有抽象思維、懂設計模式的人,去設計面向業務的 framework 和面向業務的 lib,只有這樣才能交付可維護、可擴展、可復用的軟體架構——高質量架構,幫助專案或產品取得成功,
4.5 癥結 3:抽象不夠、邏輯糾纏——High Level 業務邏輯和 Low Level 實作邏輯糾纏
當我們說“代碼中包含的業務邏輯”的時候,我們到底在說什么?業界并沒有一個標準,大家經常講的 CRUD 增刪改查其實屬于更底層的資料訪問邏輯,
我的觀點是:所謂代碼中的業務邏輯,是指這段代碼所表現出的所有輸入輸出規則、演算法和行為,通常可以分為以下 5 類:
- 輸入合法性校驗:
- 業務規則校驗:典型的如檢查交易記錄狀態、金額、時限、權限等,通常包含資料庫或外部介面的查詢作為參考;
- 資料持久化行為:資料庫、快取、檔案、日志等任何形式的資料寫入行為;
- 外部介面呼叫行為;
- 輸出/回傳值準備,
當然具體到某一個組件實體,可能不會包括上述全部 5 類業務邏輯,但是也可能每一類業務邏輯存在多個,
單這樣看你可能覺得并不是特別復雜,但是現實中上述 5 類業務邏輯中的每一個通常還包含著一到多個底層實作邏輯,如 CRUD 資料訪問邏輯或第三方 API 的呼叫,
例如輸入合法性校驗,通常需要查詢對應記錄是否存在,外部介面呼叫前通常需要查詢相關記錄以獲得呼叫介面需要的引數,呼叫介面后還需要根據結果更新相關記錄狀態,
顯然這里存在兩個 Level 的邏輯——High Level 的與業務需求對應且關聯緊密的邏輯、Low Level 的實作邏輯,
如果對兩個 Level 的邏輯不加以區分、混為一談,代碼質量立刻就會遭到嚴重損害:
- 可讀性變差:兩個維度的復雜性——業務復雜性和底層實作的技術復雜性——被摻雜在了一起,復雜度 1+1>2 劇增,給其他人閱讀代碼增加很大負擔;
- 可維護性差:可維護性通常指排查和解決問題所需花費的代價高低,當兩個 level 的邏輯糾纏在一起,會使排查問題變的更困難,修復問題時也更容易出錯;
- 可擴展性無從談起:擴展性通常指為系統增加一個特性所需花費的代價高低,代價越高擴展性越差;與排查修復問題類似,邏輯糾纏顯然也會使添加新特性變得困難、一不小心就破壞了已有功能,
下面這段代碼就是一個典型案例——High Level 的邏輯流程(引數獲取、反序列化、引數校驗、快取寫入、資料庫持久化、更新相關交易記錄)完全淹沒在了 Low Level 的實作邏輯(字串比較、Json 反序列化、redis 操作、dao 操作以及前后各種瑣碎的引數準備和回傳值處理),下一節我會針對這段問題代碼給出重構方案,
@Override
public void updateFromMQ(String compress) {
try {
JSONObject object = JSON.parseObject(compress);
if (StringUtils.isBlank(object.getString("type")) || StringUtils.isBlank(object.getString("mobile")) || StringUtils.isBlank(object.getString("data"))){
throw new AppException("MQ回傳引數例外");
}
logger.info(object.getString("mobile")+"<<<<<<<<<獲取來自MQ的授權資料>>>>>>>>>"+object.getString("type"));
Map map = new HashMap();
map.put("type",CrawlingTaskType.get(object.getInteger("type")));
map.put("mobile", object.getString("mobile"));
List<CrawlingTask> list = baseDAO.find("from crt c where c.phoneNumber=:mobile and c.taskType=:type", map);
redisClientTemplate.set(object.getString("mobile") + "_" + object.getString("type"),CompressUtil.compress( object.getString("data")));
redisClientTemplate.expire(object.getString("mobile") + "_" + object.getString("type"), 2*24*60*60);
//保存成功 存入redis 保存48小時
CrawlingTask crawlingTask = null;
// providType:(0:新顏,1XX支付寶,2:ZZ淘寶,3:TT淘寶)
if (CollectionUtils.isNotEmpty(list)){
crawlingTask = list.get(0);
crawlingTask.setJsonStr(object.getString("data"));
}else{
//新增
crawlingTask = new CrawlingTask(UUID.randomUUID().toString(), object.getString("data"),
object.getString("mobile"), CrawlingTaskType.get(object.getInteger("type")));
crawlingTask.setNeedUpdate(true);
}
baseDAO.saveOrUpdate(crawlingTask);
//保存芝麻分到xyz
if ("3".equals(object.getString("type"))){
String data = https://www.cnblogs.com/siyuanwai/p/object.getString("data");
Integer zmf = JSON.parseObject(data).getJSONObject("taobao_user_info").getInteger("zm_score");
Map param = new HashMap();
param.put("phoneNumber", object.getString("mobile"));
List<Dperson> list1 = personBaseDaoI.find("from xyz where phoneNumber=:phoneNumber", param);
if (list1 !=null){
for (Dperson dperson:list1){
dperson.setZmScore(zmf);
personBaseDaoI.saveOrUpdate(dperson);
AppFlowUtil.updateAppUserInfo(dperson.getToken(),null,null,zmf);//查詢多租戶表 身份認證、淘寶認證 為0 置為1
}
}
}
} catch (Exception e) {
logger.error("更新my MQ授權資訊失敗", e);
throw new AppException(e.getMessage(),e);
}
}
4.6 藥方 3:控制邏輯分離——業務模板 Pattern of NestedBusinessTemplate
解決“邏輯糾纏”最關鍵是要找到一種隔離機制,把兩個 Level 的邏輯分開——控制邏輯分離,分離的好處很多:
- 根據經驗,當我們著手維護一段代碼時,一定是想先弄清楚它的整體流程、演算法和行為,而不是一上來就去研究它的細枝末節;
- 控制邏輯分離后,只需要去看 High Level 部分就能了解到上述內容,閱讀代碼的負擔大幅度降低,代碼可讀性顯著增強;
- 讀懂代碼是后續一切維護、重構作業的前提,而且一份代碼被讀的次數遠遠高于被修改的次數(高一個數量級),因此代碼對人的可讀性再怎么強調都不為過,可讀性增強可以大幅度提高系統可維護性,也是重構的最主要目標,
- 同時,根據我的經驗,High Level 業務邏輯的變更往往比 Low Level 實作邏輯變更要來的頻繁,畢竟前者跟業務直接對應,當然不同型別專案情況不一樣,另外它們發生變更的時間點往往也不同;
- 在這樣的背景下,控制邏輯分離的好處就更明顯了:每次維護、擴充系統功能只需改動一個 Levle 的代碼,另一個 Level 不受影響或影響很小,這會大幅降低修改成本和風險,
我在總結過去多個專案中的教訓和經驗后,總結出了一項最佳實踐或者說是設計模式——業務模板 Pattern of NestedBusinessTemplat,可以非常簡單、有效的分離兩類邏輯,先看代碼:
public class XyzService {
abstract class AbsUpdateFromMQ {
public final void doProcess(String jsonStr) {
try {
JSONObject json = doParseAndValidate(jsonStr);
cache2Redis(json);
saveJsonStr2CrawingTask(json);
updateZmScore4Dperson(json);
} catch (Exception e) {
logger.error("更新my MQ授權資訊失敗", e);
throw new AppException(e.getMessage(), e);
}
}
protected abstract void updateZmScore4Dperson(JSONObject json);
protected abstract void saveJsonStr2CrawingTask(JSONObject json);
protected abstract void cache2Redis(JSONObject json);
protected abstract JSONObject doParseAndValidate(String json) throws AppException;
}
@SuppressWarnings({ "unchecked", "rawtypes" })
public void processAuthResultDataCallback(String compress) {
new AbsUpdateFromMQ() {
@Override
protected void updateZmScore4Dperson(JSONObject json) {
//保存芝麻分到xyz
if ("3".equals(json.getString("type"))){
String data = https://www.cnblogs.com/siyuanwai/p/json.getString("data");
Integer zmf = JSON.parseObject(data).getJSONObject("taobao_user_info").getInteger("zm_score");
Map param = new HashMap();
param.put("phoneNumber", json.getString("mobile"));
List<Dperson> list1 = personBaseDaoI.find("from xyz where phoneNumber=:phoneNumber", param);
if (list1 !=null){
for (Dperson dperson:list1){
dperson.setZmScore(zmf);
personBaseDaoI.saveOrUpdate(dperson);
AppFlowUtil.updateAppUserInfo(dperson.getToken(),null,null,zmf);
}
}
}
}
@Override
protected void saveJsonStr2CrawingTask(JSONObject json) {
Map map = new HashMap();
map.put("type",CrawlingTaskType.get(json.getInteger("type")));
map.put("mobile", json.getString("mobile"));
List<CrawlingTask> list = baseDAO.find("from crt c where c.phoneNumber=:mobile and c.taskType=:type", map);
CrawlingTask crawlingTask = null;
// providType:(0:xx,1yy支付寶,2:zz淘寶,3:tt淘寶)
if (CollectionUtils.isNotEmpty(list)){
crawlingTask = list.get(0);
crawlingTask.setJsonStr(json.getString("data"));
}else{
//新增
crawlingTask = new CrawlingTask(UUID.randomUUID().toString(), json.getString("data"),
json.getString("mobile"), CrawlingTaskType.get(json.getInteger("type")));
crawlingTask.setNeedUpdate(true);
}
baseDAO.saveOrUpdate(crawlingTask);
}
@Override
protected void cache2Redis(JSONObject json) {
redisClientTemplate.set(json.getString("mobile") + "_" + json.getString("type"),CompressUtil.compress( json.getString("data")));
redisClientTemplate.expire(json.getString("mobile") + "_" + json.getString("type"), 2*24*60*60);
}
@Override
protected JSONObject doParseAndValidate(String json) throws AppException {
JSONObject object = JSON.parseObject(json);
if (StringUtils.isBlank(object.getString("type")) || StringUtils.isBlank(object.getString("mobile")) || StringUtils.isBlank(object.getString("data"))){
throw new AppException("MQ回傳引數例外");
}
logger.info(object.getString("mobile")+"<<<<<<<<<獲取來自MQ的授權資料>>>>>>>>>"+object.getString("type"));
return object;
}
}.doProcess(compress);
}
如果你熟悉經典的 GOF23 種設計模式,很容易發現上面的代碼示例其實就是 Template Method 設計模式的運用,沒什么新鮮的,
沒錯,我這個方案沒有提出和創造任何新東西,我只是在實踐中偶然發現 Template Method 設計模式真的非常適合解決廣泛存在的邏輯糾纏問題,而且也發現很少有程式員能主動運用這個設計模式;
一部分原因可能是意識到“邏輯糾纏”問題的人本就不多,同時熟悉這個設計模式并能自如運用的人也不算多,兩者的交集自然就是少得可憐;不管是什么原因,結果就是這個問題廣泛存在成了通病,
我看到一部分對代碼質量有追求的程式員 他們的解決辦法是通過"結構化編程"和“模塊化編程”:
- 把 Low Level 邏輯提取成 private function,被 High Level 代碼所在的 function 直接呼叫;
- 問題 1 硬連接不靈活:首先,這樣雖然起到了一定的隔離效果,但是兩個 level 之間是靜態的硬關聯,Low Level 無法被簡單的替換,替換時還是需要修改和影響到 High Level 部分;
- 問題 2 組件內可見性造成混亂:提取出來的 private function 在當前組件內是全域可見的——對其它無關的 High Level function 也是可見的,各個模塊之間仍然存在邏輯糾纏,這在很多專案中的熱點代碼中很常見,問題也很突出:試想一個包含幾十個 API 的組件,每個 API 的 function 存在一兩個關聯的 private function,那這個組件內部的混亂程度、維護難度是難以承受的,
- 把 Low Level 邏輯抽取到新的組件中,供 High Level 代碼所在的組件依賴和呼叫;更有經驗的程式員可能會增加一層介面并且借助 Spring 依賴注入;
- 問題 1 API 泛濫:提取出新的組件似乎避免了“結構化編程”的局限性,但是帶來了新的問題——API 泛濫:因為組件之間呼叫只能走 public 方法,而這個 API 其實沒有太多復用機會根本沒必要做成 public 這種最高可見性,
- 問題 2 同層組件依賴失控:組件和 API 泛濫后必然導致組件之間互相依賴成為常態,慢慢變得失控以后最終變成所有組件都依賴其它大部分組件,甚至出現回圈依賴;比如那個擁有 130 個 import 和 40 個 Spring 依賴組件的 ContractService,
下面介紹一下 Template Method 設計模式的運用,簡單歸納就是:
- High Level邏輯封裝在抽象父類AbsUpdateFromMQ的一個final function中,形成一個業務邏輯的模板;
- final function保證了其中邏輯不會被子類有意或無意的篡改破壞,因此其中封裝的一定是業務邏輯中那些相對固定不變的東西,至于那些可變的部分以及暫時不確定的部分,以abstract protected function形式預留擴展點;
- 子類(一個匿名內部類)像“做填空題”一樣填充,模板實作Low Level邏輯——實作那些protected function擴展點;由于擴展點在父類中是abstract的,因此編譯器會提醒子類的程式員該擴展什么,
那么它是如何避免上面兩個方案的 4 個局限性的:
- Low Level 需要修改或替換時,只需從父類擴展出一個新的子類,父類全然不知無需任何改動;
- 無論是父類還是子類,其中的 function 對外層的 XyzService 組件都是不可見的,即便是父類中的 public function 也不可見,因為只有持有類的實體物件才能訪問到其中的 function;
- 無論是父類還是子類,它們都是作為 XyzService 的內部類存在的,不會增加新的 java 類檔案更不會增加大量無意義的 API(API 只有在被專案內復用或發布出去供外部使用才有意義,只有唯一的呼叫者的 API 是沒有必要的);
- 組件依賴失控的問題當然也就不存在了,
SpringFramework 等框架型的開源專案中,其實早已大量使用 Template Method 設計模式,這本該給我們這些應用開發程式員帶來啟發和示范,但是很可惜業界沒有注意到和充分發揮它的價值,
NestedBusinessTemplat 模式就是對其充分和積極的應用,前面一節提到過的復用的兩種正確姿勢——打造自己的 lib 和 framework,其實 NestedBusinessTemplat 就是專案自身的 framework,
4.7 癥結 4:無處不在的 if else 牛皮癬

無論你的編程啟蒙語言是什么,最早學會的邏輯控制陳述句一定是 if else,但是不幸的是它在你開始真正的編程作業以后,會變成一個損害專案質量的壞習慣,
幾乎所有的專案都存在 if else 泛濫的問題,但是卻沒有引起足夠重視警惕,甚至被很多程式員認為是正常現象,
首先我來解釋一下為什么 if else 這個看上去人畜無害的東西是有害的、是需要嚴格管控的:
- if else if ...else 以及類似的 switch 控制陳述句,本質上是一種 hard coding 硬編碼行為,如果你同意“magic number 魔法數字”是一種錯誤的編程習慣,那么同理,if else 也是錯誤的 hard coding 編程風格;
- hard coding 的問題在于當需求發生改變時,需要到處去修改,很容易遺漏和出錯;
- 以一段代碼為例來具體分析:
if ("3".equals(object.getString("type"))){
String data = https://www.cnblogs.com/siyuanwai/p/object.getString("data");
Integer zmf = JSON.parseObject(data).getJSONObject("taobao_user_info").getInteger("zm_score");
Map param = new HashMap();
param.put("phoneNumber", object.getString("mobile"));
List<Dperson> list1 = personBaseDaoI.find("from xyz where phoneNumber=:phoneNumber", param);
if (list1 !=null){
for (Dperson dperson:list1){
dperson.setZmScore(zmf);
personBaseDaoI.saveOrUpdate(dperson);
AppFlowUtil.updateAppUserInfo(dperson.getToken(),null,null,zmf);
}
}
}
- if ("3".equals(object.getString("type")))
- 顯然這里的"3"是一個 magic number,沒人知道 3 是什么含義,只能推測;
- 但是僅僅將“3”重構成常量 ABC_XYZ 并不會改善多少,因為 if (ABC_XYZ.equals(object.getString("type"))) 仍然是面向程序的編程風格,無法擴展;
- 到處被參考的常量 ABC_XYZ 并沒有比到處被 hard coding 的 magic number 好多少,只不過有了含義而已;
- 把常量升級成 Enum 列舉型別呢,也沒有好多少,當需要判斷的型別增加了或判斷的規則改變了,還是需要到處修改——Shotgun Surgery(霰彈式修改)
- 并非所有的 if else 都有害,比如上面示例中的 if (list1 !=null) { 就是無害的,沒有必要去消除,也沒有消除它的可行性,判斷是否有害的依據:
- 如果 if 判斷的變數狀態只有兩種可能性(比如 boolean、比如 null 判斷)時,是無傷大雅的;
- 反之,如果 if 判斷的變數存在多種狀態,而且將來可能會增加新的狀態,那么這就是個問題;
- switch 判斷陳述句無疑是有害的,因為使用 switch 的地方往往存在很多種狀態,
4.8 藥方 4:充血列舉型別——Rich Enum Type
正如前面分析呈現的那樣,對于代碼中廣泛存在的狀態、型別 if 條件判斷,僅僅把被比較的值重構成常量或 enum 列舉型別并沒有太大改善——使用者仍然直接依賴具體的列舉值或常量,而不是依賴一個抽象,
于是解決方案就自然浮出水面了:在 enum 列舉型別基礎上進一步抽象封裝,得到一個所謂的“充血”的列舉型別,代碼說話:
- 實作多種系統通知機制,傳統做法:
enum NOTIFY_TYPE { email,sms,wechat; } //先定義一個enum——一個只定義了值不包含任何行為的“貧血”的列舉型別
if(type==NOTIFY_TYPE.email){ //if判斷型別 呼叫不同通知機制的實作
,,,
}else if (type=NOTIFY_TYPE.sms){
,,,
}else{
,,,
}
- 實作多種系統通知方式,充血列舉型別——Rich Enum Type 模式:
enum NOTIFY_TYPE { //1、定義一個包含通知實作機制的“充血”的列舉型別
email("郵件",NotifyMechanismInterface.byEmail()),
sms("短信",NotifyMechanismInterface.bySms()),
wechat("微信",NotifyMechanismInterface.byWechat());
String memo;
NotifyMechanismInterface notifyMechanism;
private NOTIFY_TYPE(String memo,NotifyMechanismInterface notifyMechanism){//2、私有建構式,用于初始化列舉值
this.memo=memo;
this.notifyMechanism=notifyMechanism;
}
//getters ...
}
public interface NotifyMechanismInterface{ //3、定義通知機制的介面或抽象父類
public boolean doNotify(String msg);
public static NotifyMechanismInterface byEmail(){//3.1 回傳一個定義了郵件通知機制的策的實作——一個匿名內部類實體
return new NotifyMechanismInterface(){
public boolean doNotify(String msg){
.......
}
};
}
public static NotifyMechanismInterface bySms(){//3.2 定義短信通知機制的實作策略
return new NotifyMechanismInterface(){
public boolean doNotify(String msg){
.......
}
};
}
public static NotifyMechanismInterface byWechat(){//3.3 定義微信通知機制的實作策略
return new NotifyMechanismInterface(){
public boolean doNotify(String msg){
.......
}
};
}
}
//4、使用場景
NOTIFY_TYPE.valueof(type).getNotifyMechanism().doNotify(msg);
- 充血列舉型別——Rich Enum Type 模式的優勢:
- 不難發現,這其實就是 enum 列舉型別和 Strategy Pattern 策略模式的巧妙結合運用,
- 當需要增加新的通知方式時,只需在列舉類 NOTIFY_TYPE 增加一個值,同時在策略介面 NotifyMechanismInterface 中增加一個 by 方法回傳對應的策略實作;
- 當需要修改某個通知機制的實作細節,只需修改 NotifyMechanismInterface 中對應的策略實作;
- 無論新增還是修改通知機制,呼叫方完全不受影響,仍然是 NOTIFY_TYPE.valueof(type).getNotifyMechanism().doNotify(msg);
- 與傳統 Strategy Pattern 策略模式的比較優勢:常見的策略模式也能消滅 if else 判斷,但是實作起來比較麻煩,需要開發更多的 class 和代碼量:
- 每個策略實作需單獨定義成一個 class;
- 還需要一個 Context 類來做初始化——用 Map 把型別與對應的策略實作做映射;
- 使用時從 Context 獲取具體的策略;
- Rich Enum Type 的進一步的充血:
- 上面的例子中的列舉型別包含了行為,因此已經算作充血模型了,但是還可以為其進一步充血;
- 例如有些場景下,只是要對列舉值做個簡單的計算獲得某種 flag 標記,那就沒必要把計算邏輯抽象成 NotifyMechanismInterface 那樣的介面,殺雞用了牛刀;
- 這是就可以在列舉型別中增加 static function 封裝簡單的計算邏輯;
- 策略實作的進一步抽象:
- 當各個策略實作(byEmail bySms byWechat)存在共性部分、重復邏輯時,可以將其抽取成一個抽象父類;
- 然后就像前一章節——業務模板 Pattern of NestedBusinessTemplate 那樣,在各個子類之間實作優雅的邏輯分離和復用,
5. 重構前的火力偵察:為你的專案編制一套代碼庫目錄/索引——CODEX
以上就是我總結出的最常見也最影響代碼質量的 4 個問題及其解決方案:
- 職責單一、小顆粒度、高內聚、低耦合的業務邏輯層組件——倒金字塔結構;
- 打造專案自身的 lib 層和 framework——正確的復用姿勢;
- 業務模板 Pattern of NestedBusinessTemplate——控制邏輯分離;
- 充血的列舉型別 Rich Enum Type——消滅硬編碼風格的 if else 條件判斷;
接下來就是如何動手去針對這 4 個方面進行重構了,但是事情還沒有那么簡單,
上面所有的內容雖然來自實踐經驗,但是要應用到你的具體專案,還需要一個步驟——火力偵察——弄清楚你要重構的那個模塊的邏輯脈絡、演算法以致實作細節,否則貿然動手,很容易遺漏關鍵細節造成風險,重構的效率更難以保證,陷入進退兩難的尷尬境地,
我 2019 年一整年經歷了 3 個代碼十分混亂的專案,最大的識訓就是摸索出了一個梳理爛代碼的最佳實踐——CODEX:
- 在閱讀代碼程序中,在關鍵位置添加結構化的注釋,形如://CODEX ProjectA 1 體檢預約流程 1 預約服務 API 入口
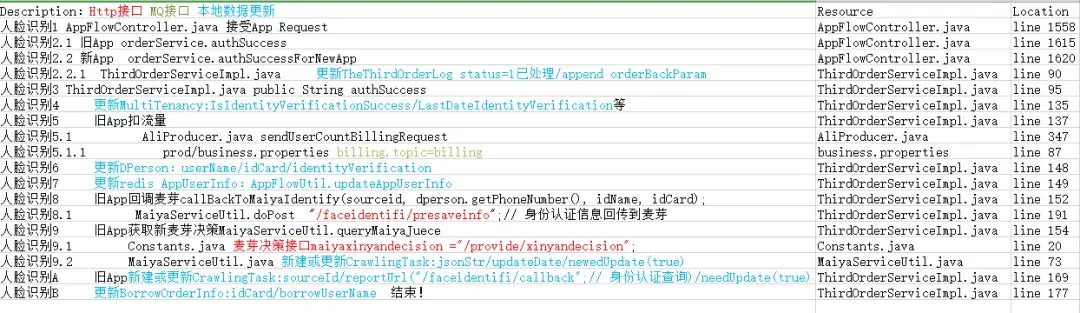

- 所謂結構化注釋,就是在注釋內容中通過規范命名的編號前綴、分隔符等來體現出其所對應的專案、模塊、流程步驟等資訊,類似文本編輯中的標題 1、2、3;
- 然后設定 IDE 工具識別這種特殊的注釋,以便結構化的顯示,Eclipse 的 Tasks 顯示效果類似下圖;
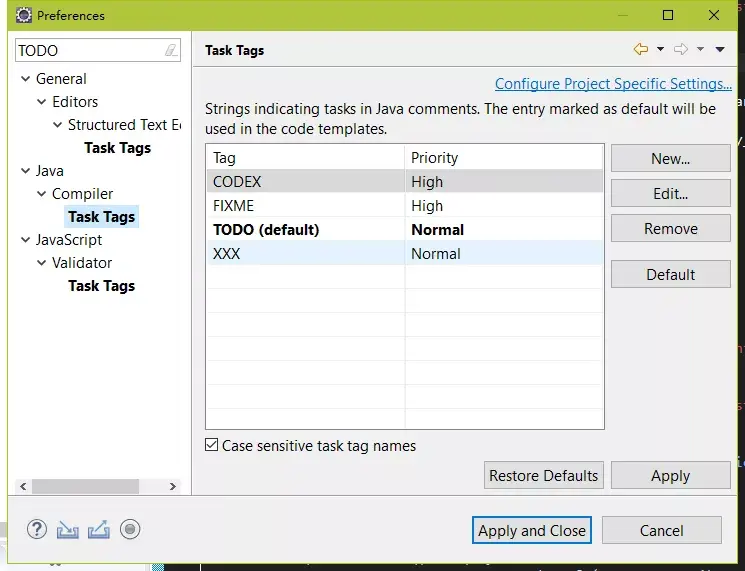
- 這個結構化視圖,本質上相對于是代碼庫的索引、目錄,不同于 javadoc 檔案,CODEX 具有更清晰的邏輯層次和更強的代碼查找便利性,在 Eclipse Tasks 中點擊就能跳轉到對應的代碼行;
- 這些結構化注釋隨著代碼一起提交后就實作了團隊共享;
- 這樣的一份精確無誤、共享的、活的源代碼索引,無疑會對整個團隊的開發維護作業產生巨大助力,
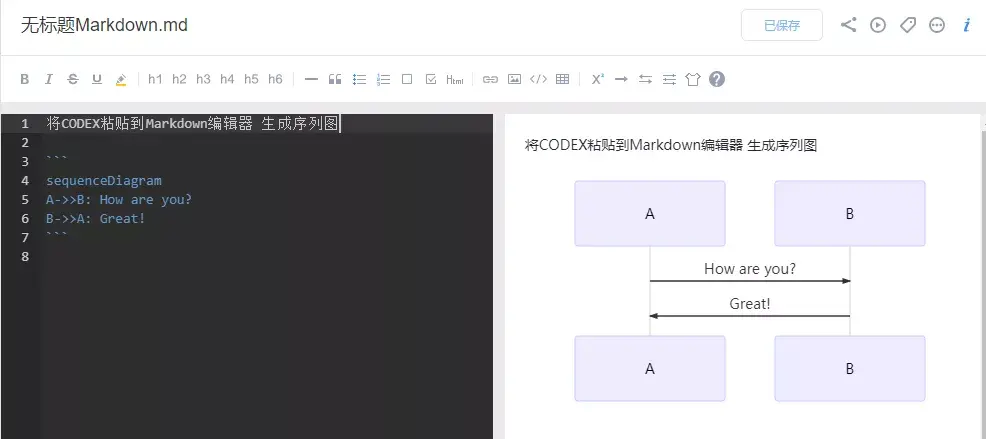
- 進一步的,如果在 CODEX 中添加 Markdown 關鍵字,甚至可以將匯出的 CODEX 簡單加工后,變成一張業務邏輯的 Sequence 序列圖,如下所示,
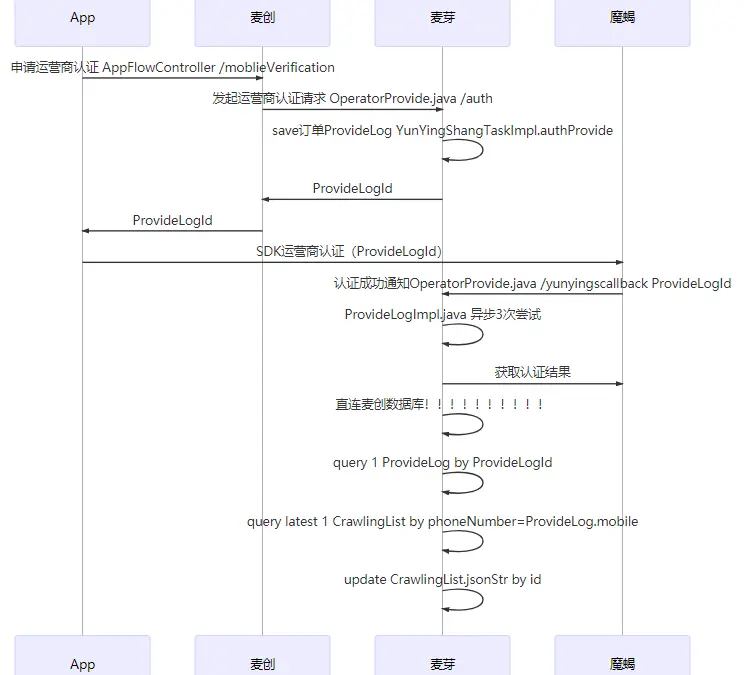
6. 總結陳詞——不要辜負這個程式員最好的時代
毫無疑問這是程式員最好的時代,互聯網浪潮已經席卷了世界每個角落,各行各業正在越來越多的依賴 IT,過去只有軟體公司、互聯網公司和銀行業會雇傭程式員,隨著云計算的普及、產業互聯網和互聯網+興起,已經有越來越多的傳統企業開始雇傭程式員搭建 IT 系統來支撐業務運營,
資本的推動 IT 需求的旺盛,使得程式員成了稀缺人才,各大招聘平臺上,程式員的崗位數量和薪資水平長期名列前茅,
但是我們這個群體的整體表現怎么樣呢,捫心自問,我覺得很難令人滿意,我所經歷過的以及近距離觀察到的專案,鮮有能夠稱得上成功的,這里的成功不是商業上的成功,僅限于作為一個軟體專案和工程是否能夠以可接受的成本和質量長期穩定的交付,
商業的短期成功與否,很多時候與專案工程的成功與否沒有必然聯系,一個商業上很成功的專案可能在工程上做的并不好,只是通過巨量的資金資源投入換來的暫時成功而已,
歸根結底,我們程式員群體需要為自己的聲譽負責,長期來看也終究會為自己的聲譽獲益或受損,
我認為程式員最大的聲譽、最重要的職業素養,就是通過寫出高質量的代碼做好一個個專案、產品,來幫助團隊、幫助公司、幫助組織創造價值、增加成功的機會,
希望本文分享的經驗和方法能夠對此有所幫助!
你好,我是四猿外,
一家上市公司的技術總監,管理的技術團隊一百余人,
我從一名非計算機專業的畢業生,轉行到程式員,一路打拼,一路成長,
我會通過公眾號,
把自己的成長故事寫成文章,
把枯燥的技術文章寫成故事,

我建了一個讀者交流群,里面大部分是程式員,一起聊技術、作業、八卦,歡迎加我微信,拉你入群

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/275694.html
標籤:其他
上一篇:有哪些是程式員才懂的梗?