背景介紹
上一章我們講過了如何將Flink和Iceberg結合,演示了一些常用的操作,并且在文章的最后演示了一個比較全的DEMO,
主要是講了一些使用上的內容,對于原理沒有太過深入,而既然我們的標題是從入門到放棄,那么必然是要對Iceberg進行深入了解的,不然怎么會放棄呢😂
所以,今天我們就來對Flink 結合 Iceberg后,寫在HDFS上的元資料檔案進行決議
不過在開始之前先準備一下作業
先下載avro-tools點我下載用來分析我們的元資料檔案
再將我們上一次表中的所有元資料檔案下載下來
hdfs dfs -get /user/hive/warehouse/iceberg_db.db/iceberg_kafka_test/metadata
簡單介紹
貼一下官網對元資料檔案的解釋,同時加上我的翻譯&理解
Snapshot
A snapshot is the state of a table at some time.
代表一張表在某個時刻的狀態,對應著${TABLE_PATH}/metadata/XXX.metadata.jsonEach snapshot lists all of the data files that make up the table’s contents at the time of the snapshot. Data files are stored across multiple manifest files, and the manifests for a snapshot are listed in a single manifest list file.
每個快照檔案列出了在某個時刻所有構成這一次快照的資料檔案,資料檔案存盤在多個manifest files中,而某一次快照的manifests會被展示在一個manifest list中Manifest list
對應著${TABLE_PATH}/metadata/snap-XXX.avro檔案
A manifest list is a metadata file that lists the manifests that make up a table snapshot.
一個manifest list 是一個元資料檔案,它列出了構成快照的listEach manifest file in the manifest list is stored with information about its contents, like partition value ranges, used to speed up metadata operations.
manifest list中的每個manifest file 都存盤著有關其內容的資訊,比如磁區值范圍,用來加速元資料的操作(更容易找到資料檔案Manifest file
A manifest file is a metadata file that lists a subset of data files that make up a snapshot.
一個manifest file是一個元資料檔案,它列出了組成一個快照的資料檔案的子集,Each data file in a manifest is stored with a partition tuple, column-level stats, and summary information used to prune splits during scan planning.
每個manifest中的資料檔案都存盤有磁區元祖、列級統計資訊和摘要資訊,這些資訊用于在Scan時進行優化(過濾無用檔案

有些同學可能看不明白,沒事,我們進入下一小節
深度理解
以select * from iceberg_catalog.iceberg_db.iceberg_kafka_test /*+ OPTIONS('streaming'='true', 'monitor-interval'='1s', 'start-snapshot-id'='3821550127947089987') */ ;
這樣一條SQL為案例,講一下三種型別檔案,在查詢的時候起到什么作用
-
首先會通過
iceberg_catalog這個Hive Catalog,獲取到iceberg_db.iceberg_kafka_test的資訊,類似于我們執行desc formatted iceberg_db.iceberg_kafka_test得到的資訊
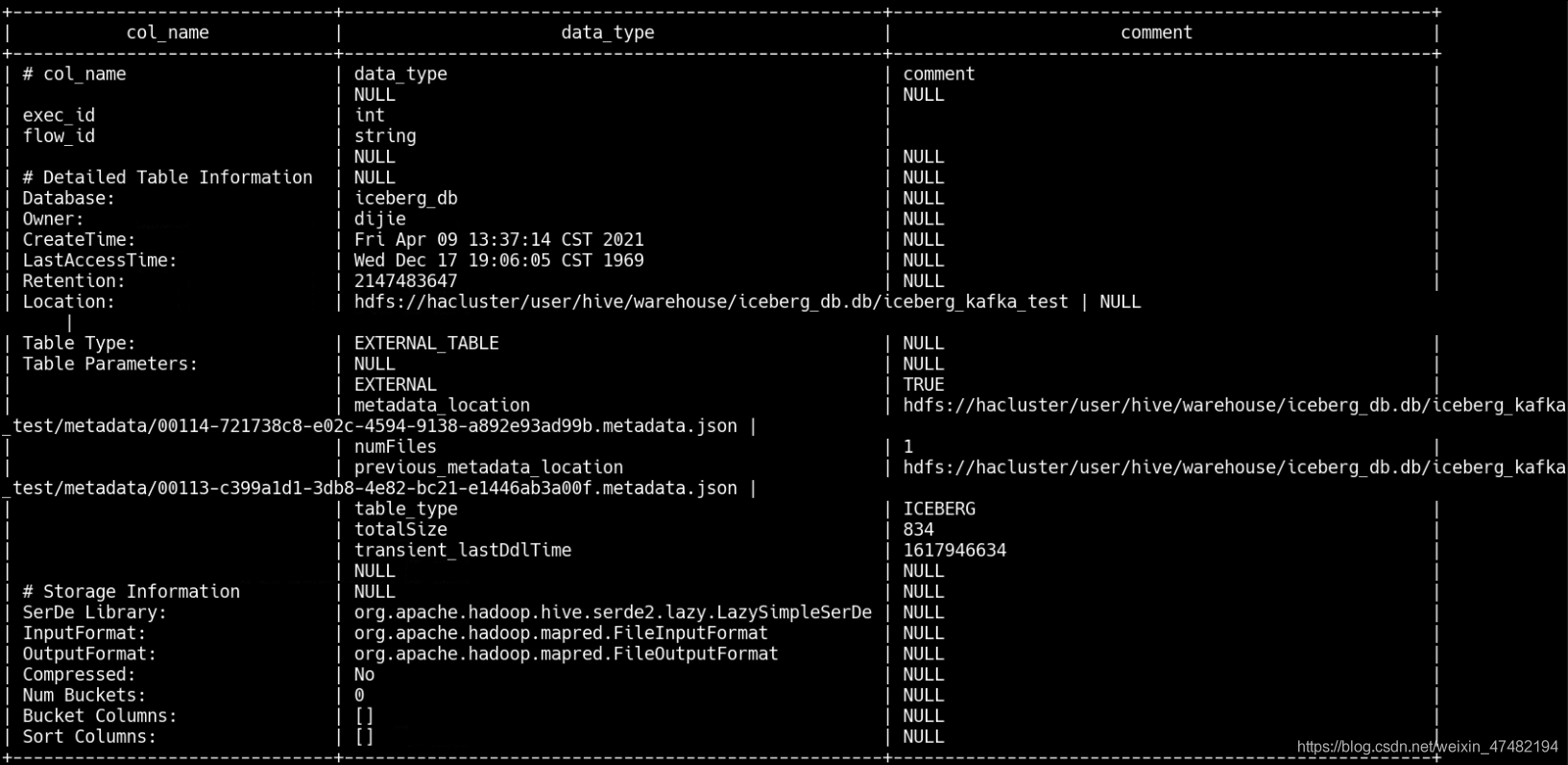
主要是為了獲取其中的
metadata_location對應的資訊 -
metadata_location對應的值代表著最新的快照路徑,我們將下載到本地的對應路徑檔案打開
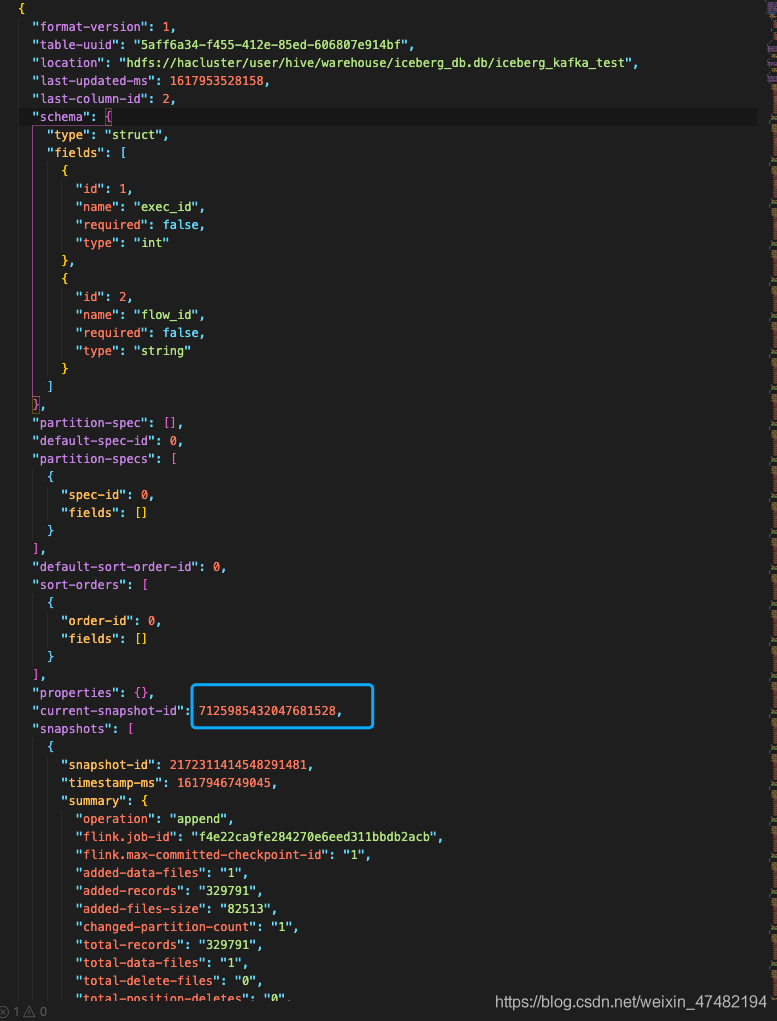
檔案中每個欄位的解釋可以參考[1],在這里展開說太多了
-
可以看到我們當前的snapshotId是
7125985432047681528,然后在這個檔案中,搜索這個id,可以找到這個
{
"snapshot-id": 7125985432047681528,
"parent-snapshot-id": 5099196027648958107,
"timestamp-ms": 1617953528158,
"summary": {
"operation": "append",
"flink.job-id": "f4e22ca9fe284270e6eed311bbdb2acb",
"flink.max-committed-checkpoint-id": "114",
"changed-partition-count": "0",
"total-records": "14208615",
"total-data-files": "4",
"total-delete-files": "0",
"total-position-deletes": "0",
"total-equality-deletes": "0"
},
"manifest-list": "hdfs://hacluster/user/hive/warehouse/iceberg_db.db/iceberg_kafka_test/metadata/snap-7125985432047681528-1-f8876013-1621-4786-bf37-7bebde4ef003.avro"
}
-
manifest-list的值,代表著manifest list檔案的HDFS路徑,我們找到對應路徑的本地檔案,然后通過我們最開始下載的工具,進行檔案內容的展開java -jar ~/Downloads/avro-tools-1.9.2.jar tojson ~/Downloads/iceberg_kafka_test/metadata/snap-7125985432047681528-1-f8876013-1621-4786-bf37-7bebde4ef003.avro -
將控制臺輸出的內容貼到任意文本中,因為工具原因,其實輸出的內容是多行JSON,我們先單獨拎出一個JSON來分析
{ "manifest_path": "hdfs://hacluster/user/hive/warehouse/iceberg_db.db/iceberg_kafka_test/metadata/57485d8a-71c4-4365-8d82-d16d8f7d2c83-m0.avro", "manifest_length": 5642, "partition_spec_id": 0, "added_snapshot_id": { "long": 7393188362216980000 }, "added_data_files_count": { "int": 1 }, "existing_data_files_count": { "int": 0 }, "deleted_data_files_count": { "int": 0 }, "partitions": { "array": [] }, "added_rows_count": { "long": 1883380 }, "existing_rows_count": { "long": 0 }, "deleted_rows_count": { "long": 0 } } -
manifest_path對應的值,就是我們manifest file的路徑,其他的一些欄位可以看這里[2]
我們用同樣的方式打開manifest_path對應的檔案,得到這么個JSON{ "status": 1, "snapshot_id": { "long": 7393188362216980000 }, "data_file": { "file_path": "hdfs://hacluster/user/hive/warehouse/iceberg_db.db/iceberg_kafka_test/data/00000-0-4b4eda19-ef65-431b-b491-7218496b3e5e-00004.parquet", "file_format": "PARQUET", "partition": {}, "record_count": 1883380, "file_size_in_bytes": 520712, "block_size_in_bytes": 67108864, "column_sizes": { "array": [ { "key": 1, "value": 381659 }, { "key": 2, "value": 128478 } ] }, "value_counts": { "array": [ { "key": 1, "value": 1883380 }, { "key": 2, "value": 1883380 } ] }, "null_value_counts": { "array": [ { "key": 1, "value": 0 }, { "key": 2, "value": 0 } ] }, "nan_value_counts": { "array": [] }, "lower_bounds": { "array": [ { "key": 1, "value": "j?\u0000\u0000" }, { "key": 2, "value": "016e8f531504f847" } ] }, "upper_bounds": { "array": [ { "key": 1, "value": "\u0007?\u0001\u0000" }, { "key": 2, "value": "f75292f8fef16edg" } ] }, "key_metadata": null, "split_offsets": { "array": [ 4 ] } } } -
終于,我們根據這個JSON里面的
file_path的值,我們找到了iceberg_kafka_test這張表,一部分資料,如果我們把manifest list檔案里面的多個JSON中的manifest_path對應的檔案全部打開,那我們就可以根據這些JSON檔案中的file_path的值,獲取到這張表的全部有效資料檔案路徑 -
這個JSON和上一個JSON大家可以對照著看一下,有一些有趣的地方,比如某些數值是一樣的,那么這些數值又代表著什么呢?還是請大家移步官網查看[3]
-
總結一下:每次掃描的時候,會先根據Hive Metadata找到表的最新的快照路徑,然后根據檔案內的當前快照id找到manifest list檔案,然后根據檔案中每一行的值找到每一個manifest file,然后通過
scan planning去過濾掉不需要的manifest file,根據剩下的manifest file找到真正的資料檔案路徑 -
看到這里大家應該對這3種型別的檔案的作用,有個大概的了解,可是為什么Iceberg要這么大費周章的去找最后的
file_path呢?統一的寫在同一個檔案不好嗎?而scan planning又是什么?
Scan Planning
Iceberg每次的掃描是通過讀取當前快照的manifest files來規劃的,已洗掉的資料和已洗掉的manifest files將不會被掃描到,
通過file counts 或者 partition summaries來跳過不匹配的manifests,
對于每個manifest,掃描謂詞(用于篩選資料行)被轉換為磁區謂詞(用于篩選資料檔案和洗掉檔案),此轉換使用磁區規范,被用于寫入manifest file,
使用包含式projection將掃描謂詞轉換為磁區謂詞:如果掃描謂詞與某行匹配,則該磁區謂詞必須與該行的磁區匹配,之所以稱為包含,是因為磁區謂詞可能會將與掃描謂詞不匹配的行包括在掃描中,
舉個栗子:一個帶有時間戳列ts的事件表,它按ts_day=day(ts)進行磁區,用戶根據ts > X來尋找這張表;此時,包含projection就是ts_day >= day(X),用于選擇可能有匹配行的檔案,請注意,在大多數情況下,掃描中將包括X之前的時間戳記,因為檔案包含與謂詞匹配的行和與謂詞不匹配的行
掃描謂詞還用于使用manifest file中存盤列邊界和計數的欄位,來篩選資料檔案和洗掉檔案,對于資料檔案和洗掉檔案,可以使用相同的篩選器邏輯,因為這兩個檔案都存盤插入或洗掉行的指標值,如果指標顯示洗掉檔案沒有與掃描謂詞匹配的行,則可以忽略該檔案,就像忽略資料檔案一樣,
掃描必須讀取與查詢過濾器匹配的資料檔案,
匹配查詢過濾器的洗掉檔案必須在讀取時應用于資料檔案,使用以下規則限制洗掉檔案的范圍
當所有以下都為真時,位置洗掉檔案必須應用到資料檔案:
-
資料檔案的序列號小于或等于洗掉檔案的序列號
-
資料檔案的磁區(spec和磁區值)等于洗掉檔案的磁區
當所有以下都為真時,必須對資料檔案應用等值洗掉檔案
- 資料檔案的序列號嚴格地小于洗掉的序列號
- 資料檔案的磁區(spec和partition值)等于洗掉檔案的磁區或洗掉檔案的磁區spec未磁區
注意:
- 如果檔案中的所有行都必須與掃描謂詞匹配,則另一種嚴格projection將創建一個與檔案匹配的磁區謂詞,這些投影用于計算掃描中每個檔案的剩余謂詞
- 舉個栗子:如果file_a包含id在1到10之間的行,而洗掉檔案包含id在1到4之間的行,那么id = 9的掃描可能會忽略洗掉檔案,因為沒有一個洗掉檔案可以匹配將要選擇的行,
以上內容是對官網scan-planning進行了翻譯和一定的自我理解,如有不對,歡迎指出,位置洗掉和等值洗掉可以參考[5]
當然,因為我們的寫入引擎是Flink,目前只支持Append的方式寫入,所以也就沒有洗掉檔案了,所以每次的查詢只要找到對應的快照號就行
寫在最后
- 看完今天這個分享,想必大家對Iceberg的原理有了更進一步的了解,并且知道了Iceberg為什么能做到比Hive更快的定位到檔案
- 下一次的分享,我會對Iceberg中的模塊
iceberg-flink進行原始碼解讀,說白了,就是讀程序分析,敬請期待 - 如果本文或者別的文章有任何不對的地方,歡迎指出
[1]table-metadata
[2]manifest-lists
[3]manifests
[4]scan-planning
[5]delete-format
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/275759.html
標籤:其他
上一篇:堆排序(JAVA)