前言
配置的虛擬機為Centos6.7系統,hadoop版本為2.6.0版本,先前已經完成搭建CentOS部署Hbase、CentOS6.7搭建Zookeeper和撰寫MapReduce前置插件Hadoop-Eclipse-Plugin 安裝,在此基礎上完成了Hive詳解以及CentOS下部署Hive和Mysql和Spark框架在CentOS下部署搭建,現在進行Spark的組件Spark SQL的部署,
對于Spark SQL的詳細介紹可以在Spark框架深度理解二:生態圈中參閱,
首先我所部署的集群配置為
CentOS-6.7
Spark-2.4.7
Hive-2.3.7
若有版本不兼容的問題可參考其他版本的部署,
若要使用Spark SQL CLI的方式訪問操作Hive表資料,需要對Spark SQL進行如下所示的環境配置,將Spark SQL 連接到一個部署好的Hive上,
當然即使沒有部署好Hive,Spark SQL也是可以運行的,但是Spark SQL會在當前的作業目錄中創建出自己的Hive元資料庫,稱為metastore_db,
現在正式進行配置,
(1)尋找自己所安裝的Hive,進入到conf中:
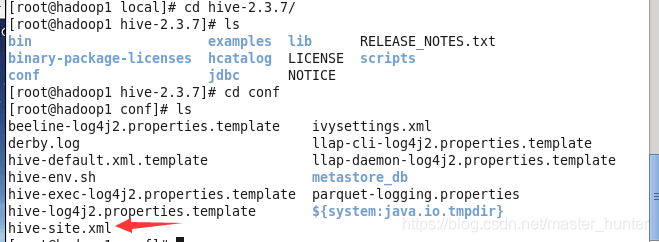
將hive-site.xml檔案復制到spark的conf目錄下:
cp /usr/local/hive-2.3.7/conf/hive-site.xml /usr/local/spark2.4.7/conf
(2)現在我們需要MySQL驅動,缺少MySQL驅動可以自行在官網上下載
wget http://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.40.tar.gz
不過既然配置過Hive想必MySQL驅動以及放在原有的Hive的lib目錄下
![]()
將該驅動放入spark的jars中(spark升到2.0.0版本后lib改為了jars目錄)
cp mysql-connector-java-5.1.40-bin.jar /usr/local/spark2.4.7/jars
然后在spark的spark-env.sh檔案下添加一行路徑
export SPARK_CLASSPATH=/usr/local/spark2.4.7/jars/mysql-connector-java-5.1.40-bin.jar
(3)啟動MySQL服務
service mysqld start
![]()
(4)啟動Hive的metastore服務:
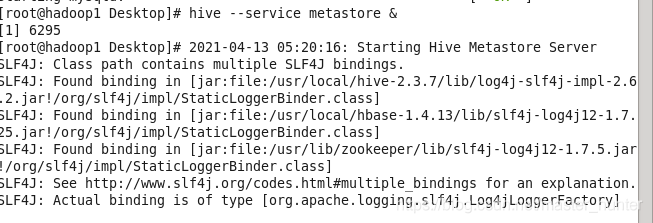
(5)修改日志級別,
進入spark的conf目錄:
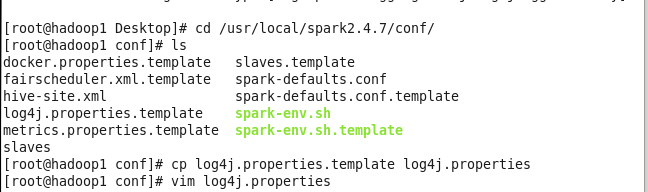
將該目錄下的log4j.properties.template檔案復制為log4j.properties,修改該檔案:
![]()
(6)啟動Spark集群,
./start-all.sh
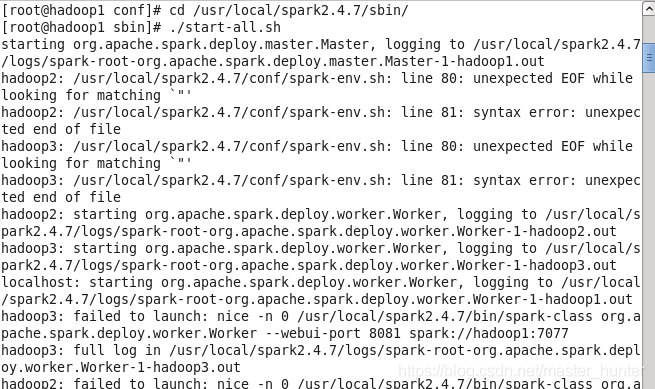
(7)啟動spark-sql,進入spark的bin目錄下:
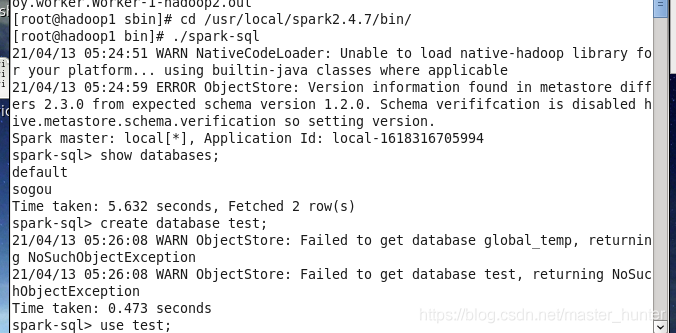
測驗完后驗證部署成功,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/275765.html
標籤:其他