協同過濾
- 前言
- 一、什么是協同過濾?(Collaborative Filtering)
- 二、協同過濾涉及的相關性強弱的計算(相似度)
- 1.皮爾遜相關系數
- 2.余弦相似度
- 3.評分預測公式
- 三、具體分類
- 1.基于用戶的協同過濾(UserCF)
- 1.1實體解說UserCF
- 1.11 例子
- 1.12 代碼實作
- 2,基于物品的協同過濾(ItemCF)
- 2.1 相似度計算的套路公式
- 2.11 直接上例子
- 2.2 求用戶對某件商品的興趣
- 2.21 矩陣乘法
- 2.12 例子的代碼實作
前言
下面主要以個別例子來探討一下何為協同過濾以及鄙人一些個性化的理解,希望能幫到你們,
提示:以下是本篇文章正文內容,下面案例可供參考
一、什么是協同過濾?(Collaborative Filtering)
協同過濾(簡稱CF)是推薦系統最重要的思想之一,協同協同,不明思議,那就是有“共同”部分,過濾是指濾去相關性不強的部分,不管是基于用戶的協同過濾還是基于物品的協同過濾,均是由一定的資料計算出得相關性大小來對使用者進行較為合理的推薦而衍生出的一種演算法,
二、協同過濾涉及的相關性強弱的計算(相似度)
計算相似度強弱時,用英文單詞similarity的簡寫sim(a,b)表示a與b的相識度,下面主要介紹一種基于用戶協同過濾的例子用到的經典演算法皮爾遜相關系數(Pearson Correlation Coefficient)的詳細用法,當然還有余弦相識度(Cosine-based Similarity),調整后的余弦相識度(Adjusted Cosine Similarity),歐式距離相似度,杰卡德相似系數等(有關公式可上網查詢)
1.皮爾遜相關系數
公式: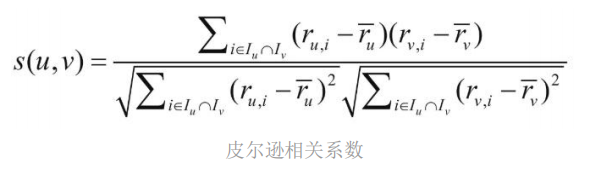
其中,i 表示項,例如商品;Iu 表示用戶 u 評價的項集;Iv 表示用戶 v 評價的項 集;ru.i表示用戶 u 對項 i 的評分;rv.i 表示用戶 v 對項 i 的評分;帶上劃線的表示用戶 的平均評分,
2.余弦相似度
公式: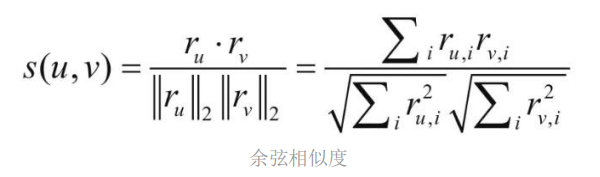
余弦距離通過向量空間中兩個向量夾角的余弦值作為衡量兩個個體間差異的大小的度量,
三角形余弦定理公式: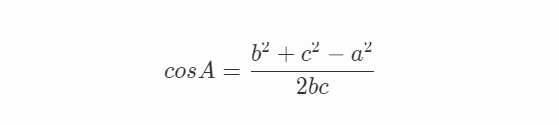
由三角形余弦定理公式可知,角 A 越小,bc 兩邊越接近,當 A 為 0 度時,bc 兩邊完全重合,
在向量空間中,對于向量 a 和向量 b 符合公式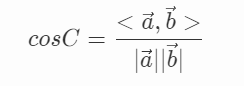
當 a 和 b 越接近(越相似),即兩個向量越接近時,二者之間的夾角為0,此時余弦值為1,恰恰這個時候,二者的相似度最大,
所以在比對 a 和 b 的相似度時,可以將其向量化后,計算它的余弦值,從而比較其相似度,即: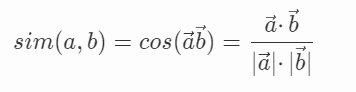
類似的也可以推廣到n個樣本的相似性度量公式: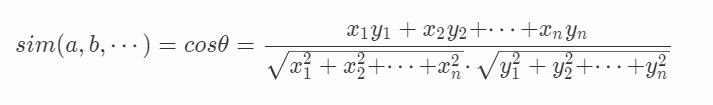
對于用戶A和B兩者形成的資料集合的相似性度量,為了方便起見,我們常常也用到下面的公式: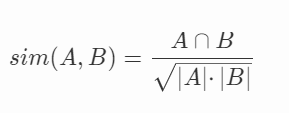
3.評分預測公式
不管是由余弦,皮爾遜系數,還是其他的相似度公式求得的關聯常數,都可代入以下公式求得預測值,
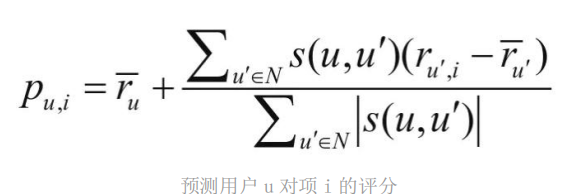
ru加上劃線記做aver(ru)表示用戶u的評分的平均值等類似的資訊,s(u,u*)表示兩者的相似度
三、具體分類
1.基于用戶的協同過濾(UserCF)
簡介:用戶指的是商品的購買者或者說是某件商品的使用者,基于他們涉及購買的物品的交集以及相關性的有關計算(通常為購買后的評價或者有關瀏覽量)來鎖定兩個相關性最強的用戶,假設為A和B,然后把A方未購買的物品推薦給B方,
1.1實體解說UserCF
為了能更直觀的解釋基于用戶的協同過濾,下面映入的將是實實在在的現實中應用的有關資料以及推薦原理的解說,
1.11 例子
假設你通過網路后臺得到了一些用戶與商品的一些評分資料,那你是否能用剛才提到的相關知識和理論來探討以下基于用戶的推薦原理嗎?
當然實際上的資料是不能拿來講理論知識的,這里只是極簡極簡的丁點資料,歡迎大家深探,當然也可發明更為可靠的演算法推薦,后生可畏也,
| 用戶 | 商品1 | 商品 2 | 商品 3 | 商品 4 | average |
|---|---|---|---|---|---|
| A | 4 | 0 | 3 | 5 | 4 |
| B | 0 | 5 | 4 | 0 | 4.5 |
| C | 5 | 4 | 2 | 0 | 3.667 |
| D | 2 | 4 | 0 | 3 | 3 |
| E | 3 | 4 | 5 | 0 | 4 |
(1)尋找可利用的“好友”
比如現在我們需要預測用戶 C 對商品 4 的評分,我們就要找到已經對商品4進行過評分的用戶來“利用”,肉眼可見,為用戶A和D,然后根據公共評分來求相關系數,
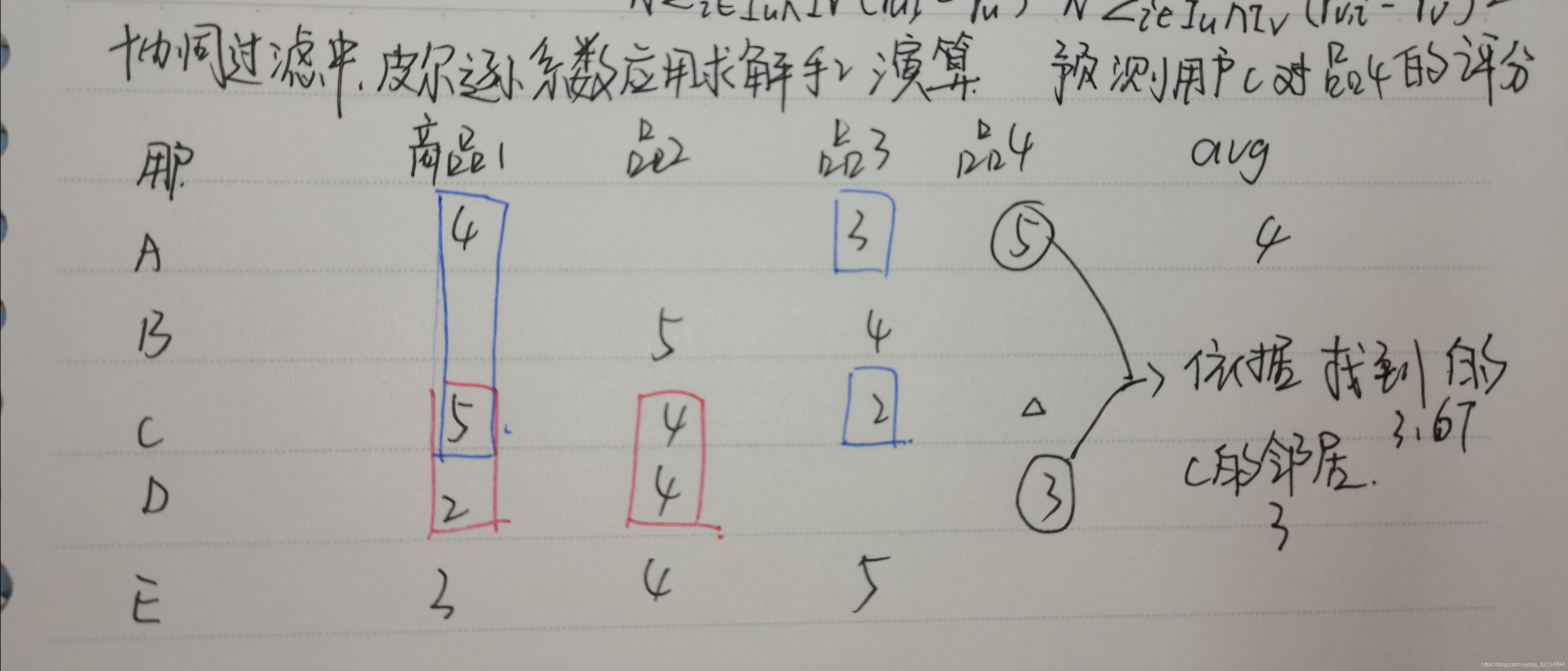
根據皮爾遜相關系數公式有:
其他的計算類似,
1.12 代碼實作
溫馨提示:下面兩個代碼雖然長,除了相似度計算函式不一樣外,其他大致相同,不必被紙老虎嚇住,
(1)利用皮爾遜系數的代碼實作
import numpy as np
from math import sqrt
def pier(lst_1,lst_2,M,N):#求皮爾遜系數的函式的構建
aver_1=0
aver_2=0
a=0
b=0
fenzi=0
fang_1=0
fang_2=0
for i in range(M):#前兩個for回圈用于求得兩個用戶的平均值
if lst_1[i]!=0:
a+=1
aver_1+=lst_1[i]
aver_1=aver_1/a
for i in range(M):
if lst_2[i]!=0:
b+=1
aver_2+=lst_2[i]
aver_2=aver_2/b
for i in range(M):
fenzi+=(lst_1[i]-aver_1)*(lst_2[i]-aver_2)
fang_1+=pow((lst_1[i]-aver_1),2)
fang_2+=pow(lst_2[i]-aver_2,2)
fenmu=sqrt(fang_1)*sqrt(fang_2)
return fenzi/fenmu
def yuping(lst_u,R,u_u,M,N,n):#求預測評分函式 lst_u表示需要預測的用戶,R為原始的用戶和物品形成的二維陣列,N表示用戶陣列
fenzi=0
fenmu=0
aver_1=0#平均值
aver_2=0
a=0#當前用戶購買物品數量
b=0
for i in range(M):
if lst_u[i]!=0:
a+=1
aver_1 +=lst_u[i]
aver_1=aver_1/a
for o in range(N):
if R[o][m]!=0:
for i in range(M):
if R[o][i]!=0:
b+=1
aver_2 +=R[o][i]
aver_2=aver_2/b
fenzi+=u_u[n][o]*(R[o][m]-aver_2)
fenmu+=abs(pier(lst_u,R[o],M,N))
return aver_1+fenzi/fenmu
R=np.array([[4,0,3,5],#生成原始矩陣R
[0,5,4,0],
[5,4,2,0],
[2,4,0,3],
[3,4,5,0]])
N=len(R)#列長
M=len(R[0])#行長
u_u=np.zeros((N,N))#建立用戶與用戶之間相關性矩陣u_u
for n in range(N):#建立一個對R的回圈篩選未評分item并進行預測評分
for m in range(N):
if n<m:
u_u[n][m]=pier(R[n],R[m],M,N)
u_u[m][n]=u_u[n][m]
print("得到的用戶-用戶相似度矩陣:")
print(u_u)#列印用戶與用戶相似度矩陣
user=['A','B','C','D','E']#用戶集合
items=['p1','p2','p3','p4']#商品集合
for n in range(N):#建立一個對R回圈尋找未評分項并且對未評分項進行預測
for m in range(M):
if R[n][m]==0:
R[n][m]=yuping(R[n],R,u_u,M,N,n)
if R[n][m]>3:
print("將商品{:}推薦給用戶{:}".format(items[m],user[n]))
print("評分預測矩陣R^:")
print("{:}".format(R))
(2)余弦相似度的代碼實作:
import numpy as np
from math import sqrt
def pex(ls_1,ls_2,M): #求余弦相似度的函式 ls_1,ls_2表示用戶1,2的相關陣列,M表示總的物品數
fenzi=0#余弦相似度分子
fenmu=0#分母
abs_1=0#分母左邊絕對值里的值
abs_2=0#分母右邊絕對值里的值
for i in range(M):
fenzi += ls_1[i] * ls_2[i]
abs_1 += pow(ls_1[i],2)
abs_2 += pow(ls_2[i],2)
fenmu=sqrt(abs_1*abs_2)
return fenzi/fenmu#ls_1,ls_2用戶相關系數
def yuping(lst_u,R,u_u,M,N,n):#求預測評分函式 lst_u表示需要預測的用戶,R為原始的用戶和物品形成的二維陣列,N表示用戶陣列
fenzi=0
fenmu=0
aver_1=0#平均值
aver_2=0
a=0#當前用戶購買物品數量
b=0
for i in range(M):
if lst_u[i]!=0:
a+=1
aver_1 +=lst_u[i]
aver_1=aver_1/a
for o in range(N):
if R[o][m]!=0:
for i in range(M):
if R[o][i]!=0:
b+=1
aver_2 +=R[o][i]
aver_2=aver_2/b
fenzi+=u_u[n][o]*(R[o][m]-aver_2)
fenmu+=abs(pex(lst_u,R[o],M))
return aver_1+fenzi/fenmu
R=np.array([[4,0,3,5],#生成原始矩陣R
[0,5,4,0],
[5,4,2,0],
[2,4,0,1],
[3,4,5,0]])
N=len(R)#列長
M=len(R[0])#行長
u_u=np.zeros((N,N))#建立用戶與用戶之間相關性矩陣u_u
for n in range(N):#建立一個對R的回圈篩選未評分item并進行預測評分
for m in range(N):
if n<m:
u_u[n][m]=pex(R[n],R[m],M)
u_u[m][n]=u_u[n][m]
print("得到的用戶-用戶相似度矩陣:")
print(u_u)#列印用戶與用戶相關系數矩陣
user=['A','B','C','D','E']#用戶集合
items=['p1','p2','p3','p4']#商品集合
for n in range(N):#建立一個對R回圈尋找未評分項并且對未評分項進行預測
for m in range(M):
if R[n][m]==0:
R[n][m]=yuping(R[n],R,u_u,M,N,n)
if R[n][m]>3:
print("將商品{:}推薦給用戶{:}".format(items[m],user[n]))
print("評分預測矩陣R^:")
print("{:}".format(R))
2,基于物品的協同過濾(ItemCF)
基于物品,是指主要以計算物品間的相似度,來對用戶推薦另一件物品,假設你購買了手機和筆記本,有相當一部分人在購買了手機,筆記本之后也購買了ipad,那么通過相關計算就會定下ipad與手機和筆記本的相似度較高,而給你推薦ipad,宣告的是這里用購買的相關記錄的統計來計算物品間的相似度大小,
2.1 相似度計算的套路公式
兩物品的相似度的計算與用戶的相似度的計算大體相同,公式如下:
上述圖片為修改過的計算公式,是為了避開熱門商品的巨大影響,有興趣的可以了解一下,公式中的N(i)^N(j)表示用戶N對商品i和j同時喜歡(即購買)的次數,Wij表示i與j的相似度,
2.11 直接上例子
由于某種力量,你又再次得到了好幾個用戶與商品的歷史資訊,如下表所示:
| A | a | b | d |
|---|---|---|---|
| B | a | c | b |
| C | b | e | c |
| D | c | d | e |
結果你發現并不能很好的得到物品之間同時被你和他一起喜歡的次數,于是接下來要引入的是共現矩陣
提示:下表純粹是為了更直觀的統計同時購買兩件商品的用戶數,與代碼沒有任何聯系,不要誤以為我會在代碼中建立圖1的矩陣.
| a | b | c | d | e | |
|---|---|---|---|---|---|
| a | 2 | 2 | 1 | 0 | |
| b | 2 | 2 | 1 | 1 | |
| c | 2 | 2 | 2 | 2 | |
| d | 1 | 1 | 2 | 1 | |
| e | 0 | 1 | 2 | 1 |
圖1
然后由公式計算a與b的相似度:
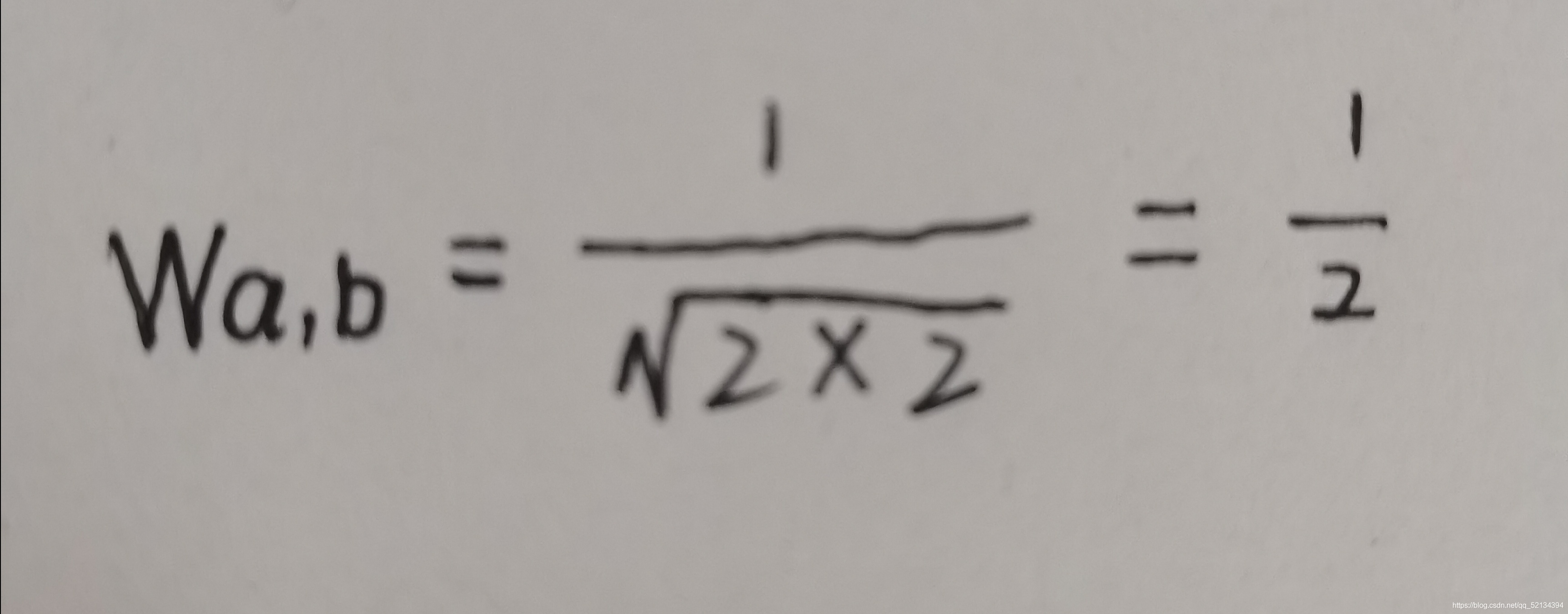
得到共現矩陣:(物品相似度矩陣)
| a | b | c | d | e | |
|---|---|---|---|---|---|
| a | 0 | 0.8164 | 0.7071 | 0.5 | 0 |
| b | 0.8164 | 0 | 0.8660 | 0.4082 | 0.4082 |
| c | 0.7071 | 0.8660 | 0 | 0.7071 | 0.7071 |
| d | 0.5 | 0.4082 | 0.7071 | 0 | 0.5 |
| e | 0 | 0.4082 | 0.7071 | 0.5 | 0 |
圖2
2.2 求用戶對某件商品的興趣
如何讓計算機去幫我們求用戶u對于物品j的興趣濃厚呢?
下面給出如下公式:
這里 N(u)是用戶喜歡(購買)的物品的集合,S(j,K)是和物品 j 最相似的 K 個物品的集合,Wji 是物品 j 和 i 的相似度,rui 是用戶 u 對物品 i 的興趣,(對于隱反饋資料集, 如果用戶 u 對物品 i 有過購買評分的行為,即可令rui=1,為啥令他等于1不是等于其他數值呢?個人認為是因為物品與物品之間的相似度最大值為1的原因,就是絕對關聯) 該公式的含義是,和用戶歷史 上感興趣的物品越相似的物品,越有可能在用戶的推薦串列中獲得比較高的排名,
注意:那么這個公式具體要表達什么呢?看不懂怎么辦?那就用上面的例子代入使用一下:
那么問題來了,如何能更快捷的對每兩件物品計算出他們的相似度呢?接下來要引入的是另一種計算方法(更確切的說是更為簡便的計算形式):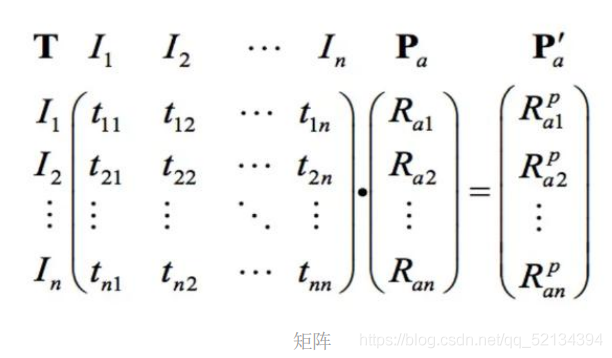
其中,Pa 為新用戶對已有產品的向量,(這里我們把用戶有過的記為1,不曾擁有的記為0,構造列為1的向量)T 為物品的共現矩陣,得到的 P`a 為新用 戶對每個產品的興趣度,
2.21 矩陣乘法
(1)以上用到的矩陣相乘的知識點,本博主大浪淘沙給你們找了B站上比較不錯的視頻,鏈接在下面,請取所需:
女學霸詳解矩陣相乘
上面例子的解釋如下圖:
[
0
0.8164
0.7071
0.5
0
0.8164
0
0.8660
0.4082
0.4082
0.7071
0.8660
0
0.7071
0.7071
0.5
0.4082
0.7071
0
0.5
0
0.4082
0.7071
0.5
0
]
\begin{bmatrix} 0&0.8164&0.7071&0.5&0\\ 0.8164&0&0.8660&0.4082&0.4082\\0.7071&0.8660&0&0.7071&0.7071\\ 0.5&0.4082&0.7071&0&0.5\\ 0&0.4082&0.7071&0.5&0\end{bmatrix}
???????00.81640.70710.50?0.816400.86600.40820.4082?0.70710.866000.70710.7071?0.50.40820.707100.5?00.40820.70710.50????????*
[
0
1
0
1
1
]
\begin{bmatrix} 0\\1\\0\\1\\1\end{bmatrix}
???????01011????????=
[
1.3164
0.8164
2.2802
0.9082
0.9082
]
\begin{bmatrix}1.3164\\0.8164\\2.2802\\0.9082\\0.9082\end{bmatrix}
???????1.31640.81642.28020.90820.9082????????
由于這種計算方法沒有像公式那樣進行物品相似度大小的比較,所以可能導致過擬合,寫代碼時可以用遍歷的方法來對相似度在0.6以上的進行過濾
2.12 例子的代碼實作
import numpy as np
from math import sqrt
'''
用戶/物品 | 物品a | 物品b | 物品c | 物品d | 物品e |
用戶A | 1 | 1 | 1 | 1 | |
用戶B | 1 | 1 | 1 | | |
用戶C | | 1 | 1 | | 1 |
用戶d | | | 1 | 1 | 1 |
'''
#定義余弦相似性度量計算
def simil(ls_1,ls_2,n): #求item之間的相似度
fenzi=0#分子
fenmu=0#分母
n_1=n_2=0#喜歡商品的用戶數初始值
for k in range(n):
#分子值為同時喜歡兩個物品的用戶數,若ls_1,ls_2同時為1(即用戶都購買過這兩件商品),相乘得1,分子加1即統計一次
fenzi+=ls_1[k] * ls_2[k]
n_1 += ls_1[k]
n_2 += ls_2[k]
fenmu=sqrt(n_1*n_2)
return fenzi/fenmu#ls_1,ls_2物品相似度
#定義預測興趣度函式
def fore(ls_1,ls_2):
return np.dot(ls_1,ls_2)
#構建用戶——商品矩陣
user_item=np.array([[1,1,1,1,0],
[1,1,1,0,0],
[0,1,1,0,1],
[0,0,1,1,1]])
print("用戶-物品矩陣:")
print(user_item)
#建立用戶串列
user = ['用戶A','用戶B','用戶C','用戶D']
#建立物品串列
item = ['物品a','物品b','物品c','物品d','物品e']
n = len(user) #n個用戶
m = len(item) #m個物品
#建立物品——用戶倒排表
item_user=user_item.T
print(item_user)
#建立物品——物品相似度共現矩陣
sim = np.zeros((m,m)) #相似度矩陣,默認全為0
#下面對相似度空矩陣回圈并填充
for i in range(m):
for j in range(m):
if i < j:
sim[i][j] = simil(item_user[i],item_user[j],n)
sim[j][i] = sim[i][j]
print("得到的物品-物品相似度矩陣:")
print(sim) #列印物品-物品相似度矩陣
#做一個物品——物品最相似物品相似度矩陣
#相似度矩陣有了,我們預測興趣度
REuser_item=np.zeros((n,m))#建立預測空矩陣
for i in range(n):#遍歷用戶
for j in range(m):#遍歷商品
if user_item[i][j]==0:#將原矩陣里空興趣度進行預測并填補到預測空矩陣中
REuser_item[i][j]=fore(sim[j],user_item[i])
if REuser_item[i][j]>0.6:
print("對{:}推薦商品{:}".format(user[i],item[j]))
print("用戶——物品預測矩陣:\n",REuser_item)
結果: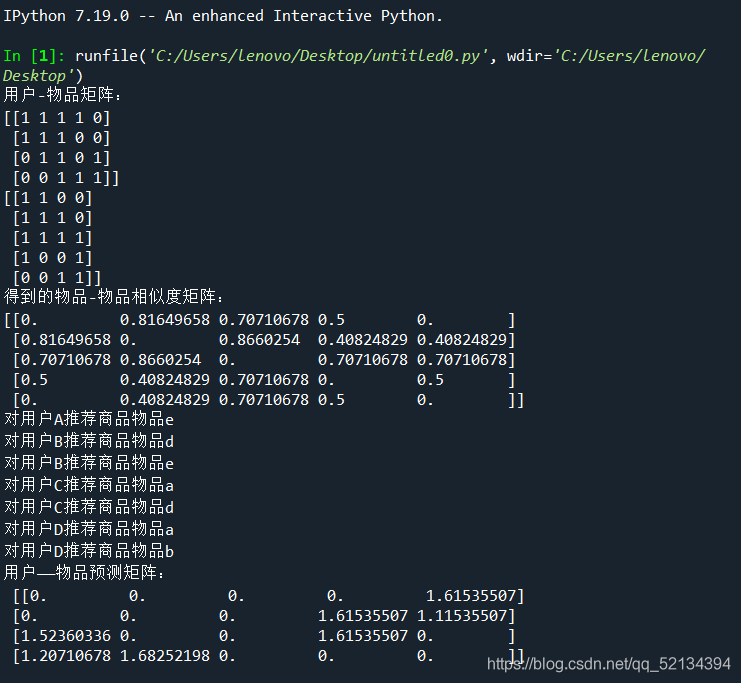
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/276152.html
標籤:其他
上一篇:Hadoop學習之大資料概論