寫在前面:博主是一只經過實戰開發歷練后投身培訓事業的“小山豬”,昵稱取自影片片《獅子王》中的“彭彭”,總是以樂觀、積極的心態對待周邊的事物,本人的技術路線從Java全堆疊工程師一路奔向大資料開發、資料挖掘領域,如今終有小成,愿將昔日所獲與大家交流一二,希望對學習路上的你有所助益,同時,博主也想通過此次嘗試打造一個完善的技術圖書館,任何與文章技術點有關的例外、錯誤、注意事項均會在末尾列出,歡迎大家通過各種方式提供素材,
- 對于文章中出現的任何錯誤請大家批評指出,一定及時修改,
- 有任何想要討論和學習的問題可聯系我:zhuyc@vip.163.com,
- 發布文章的風格因專欄而異,均自成體系,不足之處請大家指正,
演算法導論之經典演算法:折半插入排序全面決議
本文關鍵字:演算法導論、經典演算法、插入排序、折半插入排序、演算法實踐
文章目錄
- 演算法導論之經典演算法:折半插入排序全面決議
- 一、什么是演算法
- 1. 演算法的定義
- 2. 補充的概念
- 二、插入排序
- 1. 插入排序介紹
- 2. 折半插入排序
- 3. 偽代碼
- 三、演算法實踐
- 1. 演算法實作
- 2. 時間復雜度
- 3. 空間復雜度
一、什么是演算法
本專欄為《手撕演算法》欄目的子專欄:《演算法導論》,會講述一些經典演算法,并進行分析,在此之前我們要先了解什么是演算法,能夠解決什么樣的問題,
1. 演算法的定義
以下為經典教材《Introduction.to.Algorithms》開篇中的內容,
Informally, an algorithm is any well-de?ned computational procedure that takes some value, or set of values, as input and produces some value, or set of values, as output. An algorithm is thus a sequence of computational steps that transform the input into the output.
可以看到,任何被明確定義的計算程序都可以稱作演算法,它將某個值或一組值作為輸入,并產生某個值或一組值作為輸出,所以演算法可以被稱作將輸入轉為輸出的一系列的計算步驟,
這樣的概括是比較標準和抽象的,其實說白了就是步驟明確的解決問題的方法,由于是在計算機中執行,所以通常先用偽代碼來表示,清晰的表達出思路和步驟,這樣在真正執行的時候,就可以使用不同的語言來實作出相同的效果,
概括的說,演算法就是解決問題的工具,在描述一個演算法時,我們關注的是輸入與輸出,也就是說只要把原始資料和結果資料描述清楚了,那么演算法所做的事情也就清楚了,我們在設計一個演算法時也是需要先明確我們有什么和我們要什么,這一點相信大家在后面的文章中會慢慢體會到,
2. 補充的概念
- 資料結構
演算法經常會和資料結構一起出現,這是因為對于同一個問題(如:排序),使用不同的資料結構來存盤資料,對應的演算法可能千差萬別,所以在整個學習程序中,也會涉及到各種資料結構的使用,
常見的資料結構包括:陣列、堆、堆疊、佇列、鏈表、樹等等,
- 演算法的效率
在一個演算法設計完成后,還需要對演算法的執行情況做一個評估,一個好的演算法,可以大幅度的節省運行的資源消耗和時間,在進行評估時不需要太具體,畢竟資料量是不確定的,通常是以資料量為基準來確定一個量級,通常會使用到時間復雜度和空間復雜度這兩個概念,
- 時間復雜度
通常把演算法中的基本操作重復執行的頻度稱為演算法的時間復雜度,演算法中的基本操作一般是指演算法中最深層回圈內的陳述句(賦值、判斷、四則運算等基礎操作),我們可以把時間頻度記為T(n),它與演算法中陳述句的執行次數成正比,其中的n被稱為問題的規模,大多數情況下為輸入的資料量,
對于每一段代碼,都可以轉化為常數或與n相關的函式運算式,記做f(n),如果我們把每一段代碼的花費的時間加起來就能夠得到一個刻畫時間復雜度的運算式,在合并后保留量級最大的部分即可確定時間復雜度,記做O(f(n)),其中的O就是代表數量級,
常見的時間復雜度有(由低到高):O(1)、O(
log
?
2
n
\log _{2} n
log2?n)、O(n)、O(
n
log
?
2
n
n\log _{2} n
nlog2?n)、O(
n
2
n^{2}
n2)、O(
n
3
n^{3}
n3)、O(
2
n
2^{n}
2n)、O(n!),
- 空間復雜度
程式從開始執行到結束所需要的記憶體容量,也就是整個程序中最大需要占用多少的空間,為了評估演算法本身,輸入資料所占用的空間不會考慮,通常更關注演算法運行時需要額外定義多少臨時變數或多少存盤結構,如:如果需要借助一個臨時變數來進行兩個元素的交換,則空間復雜度為O(1),
- 偽代碼約定
偽代碼是用來描述演算法執行的步驟,不會具體到某一種語言,為了表達清晰和標準化,會有一些約定的含義:
縮進:表示塊結構,如回圈結構或選擇結構,使用縮進來表示這一部分都在該結構中,
回圈計數器:對于回圈結構,在回圈終止時,計數器的值應該為第一個超出界限的值,
to:表示回圈計數器的值增加,
downto:表示回圈計數器的值減少,
by:回圈計數器的值默認變化量為1,當大于1時可以使用by,
變數默認是區域定義的,
陣列元素訪問:通過"陣列名[下標]"形式,在偽代碼中,下標從1開始("A[1]“代表陣列A的第一個元素),
子陣列:使用”…"來代表陣列中的一個范圍,如"A[i…j]"代表從第i個到第j個元素組成的子陣列,
物件與屬性:復合的資料會被組織成物件,如鏈表包含后繼(next)和存盤的資料(data),使用“物件名 + 點 + 屬性名”,
特殊值NIL:表示指標不指向任何物件,如二叉樹節點無子孩子可認為左右子節點資訊為NIL,
return:回傳到呼叫程序的呼叫點,在偽代碼中允許回傳多個值,
and和or:與運算和或運算默認短路,即如果已經能夠確定運算式結果時,其他條件不會去判斷或執行,
二、插入排序
1. 插入排序介紹
插入排序的基本思路是每次插入一個元素,每一趟完成對一個待排元素的放置,直到全部插入完成,
- 直接插入排序
直接插入排序是一種最簡單的排序方法,程序就是將每個待排元素逐個插入到已經排好的有序序列中,
文章傳送門:演算法導論之經典演算法:直接插入排序全面決議,
- 折半插入排序
由于在插入排序的程序中,已經生成了一個(排好的元素組成的)有序數列,所以在插入待排元素時可以使用折半查找的方式更快速的確定新元素的位置,當元素個數較多時,折半插入排序優于直接插入排序,
- 希爾排序
希爾排序可以看做是分組插入的排序方法,把全部元素分成幾組(等距元素分到一組),在每一組內進行直接插入排序,然后繼續減少間距,形成新的分組,進行排序,直到間距為1時停止,
2. 折半插入排序
- 輸入
n個數的序列,通常直接存放在陣列中,可能是任何順序,
- 輸出
輸入序列的一個新排列,滿足從小到大的順序(默認討論升序,簡單的修改就可以實作降序排列),
- 演算法說明
每次從原有資料中取出一個數,插入到之前已經排好的序列中,直到所有的數全部取完,那么新的有序排列也就完成了,這個程序與直接插入排序十分類似,不同的地方在于插入時如何尋找位置,
- 直接插入排序:從后(排好的最后一個元素)至前逐一比較尋找位置,
- 折半插入排序:利用已排好的元素有序的特點,使用折半查找的方式快速確定位置,
對于折半查找的詳細步驟,可直接查看文章:演算法導論之經典演算法:折半查找全面決議,
- 演算法流程
以下圖片取材自《資料結構簡明教程》:
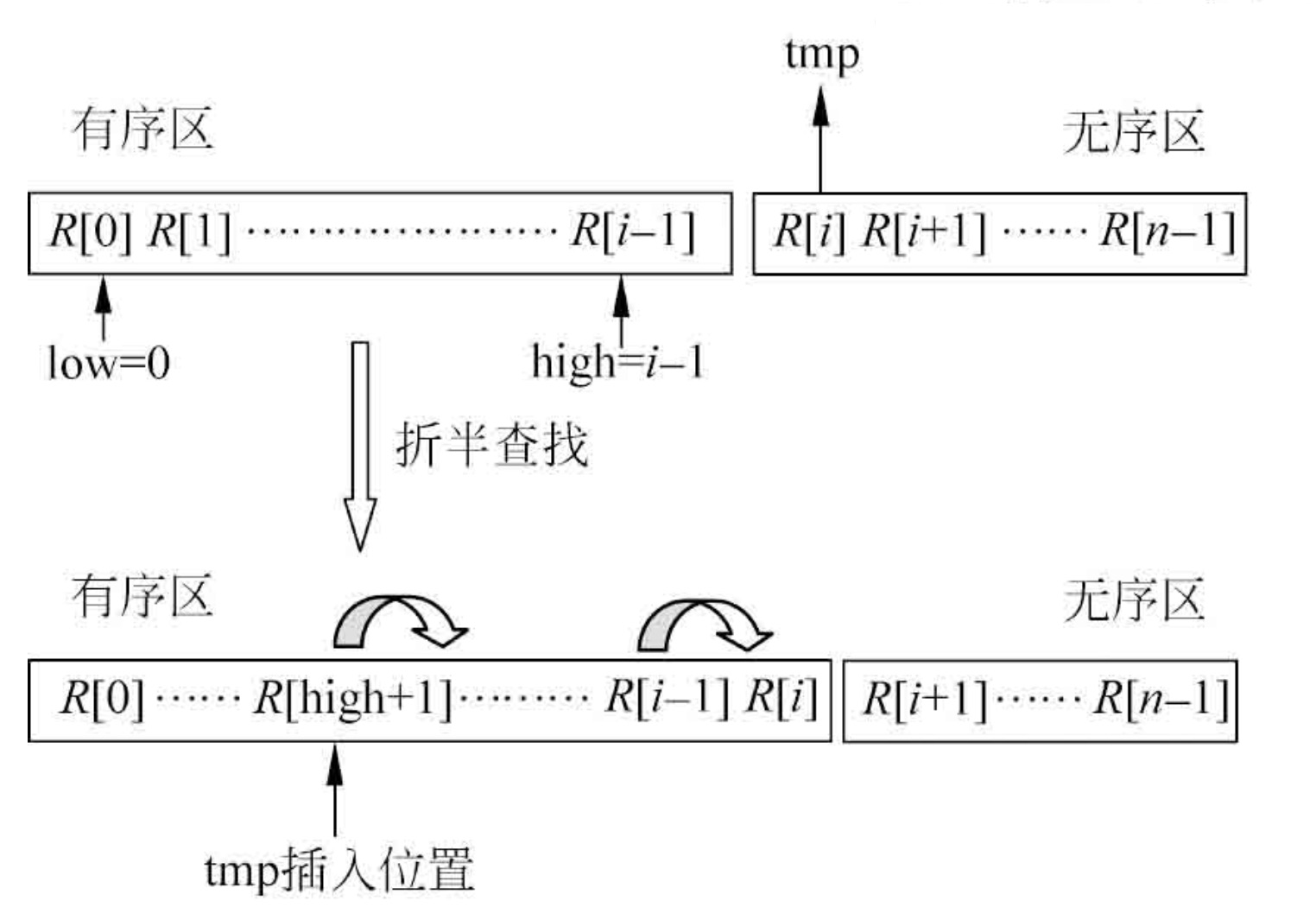
- 輸入資料集被分為有序區和無序區兩部分,
- 最初有序區沒有元素,從無序區不斷取出元素放入,保證放入的元素均已有序,
- 已知前i個元素已排好(下標從0至i-1),從無序區取出第一個元素(資料集的第i + 1個元素),
- 先與有序區的最后一個元素比較
- 如果較大則代表該元素已經在合適的位置,則直接歸入有序區,進入下一個元素的判斷,
- 如果較小則需要進一步確定位置,執行以下步驟,
- 搜索區間為從low至high,初始區間為整個有序區(從0至i-1),
- 將待插入元素記錄在臨時變數tmp中,為后續的元素串位做準備,
- 計算mid = (low + high) / 2,將該位置的元素與 **R[i] **比較,
- 不斷的縮小搜索區間,直到確定插入位置(原理與折半查找相同),
- 確定位置后,將有序區中的元素從后至前逐個后串,最后將tmp中的值覆寫到插入位置,
3. 偽代碼
折半插入排序可以看做是將直接插入排序與折半查找兩種演算法進行結合,排序的思路與直接插入排序相同,只是在確定插入位置時借助了折半查找的方法(不考慮集合中有重復元素的情況),
for i = 2 to A.length
if A[i] < A[i - 1]
tmp = A[i]
low = 0
high = i - 1
while low <= high
mid = (low + high) / 2
if A[mid] > tmp
high = mid - 1
else
low = mid + 1
for j = i - 1 downto high + 1
A[j + 1] = A[j]
A[high + 1] = tmp
由于不會出現重復元素,所以最后一定會將搜索區間縮小至low與high重合(左右區間端點不斷移動),在最后一次回圈時,low、high的值相同,在比較完成后,left與right發生交錯,相差為1,此時要選擇一個變數的值作為新插入元素的位置參照,
需要明確的是,最后一次比較時不會出現左端點向左移或右端點向右移的情況,因為在上一次比較時,待插入元素必定是能夠落在low與high的區間內的,這就決定了tmp一定大于low對應的元素,小于high對應的元素,
并且由于mid的計算方法,最后一次比較是tmp與low對應元素的比較,并且tmp(待插入元素)是較大的,此時進else分支,并且我們知道最終的插入位置應該放在最后比較元素的后一個位置,也就是mid對應位置的后面,所以是mid + 1,
如果用low表示,就剛好是low,如果用right表示,則應該是high + 1,
三、演算法實踐
1. 演算法實作
- 輸入資料(input):11,34,20,10,12,35,41,32,43,14
- Java源代碼
public class BinaryInsert {
public static void main(String[] args) {
// input data
int[] a = {11,34,20,10,12,35,41,32,43,14};
// 陣列下標從0開始,j初始為1,指向第二個元素
for (int i = 1;i < a.length;i++){
if (a[i] < a[i - 1]){
// 使用temp記錄當前元素的值
int tmp = a[i];
// 初始化變數
int left = 0;
int right = i - 1;
// while回圈作用:使用二分查找確定元素位置,并串出對應的位置
while(left <= right){
// 取中間元素,以下寫法防止資料量較大時發生溢位
int mid = (right - left) / 2 + left;
if(a[mid] > tmp){
// 待排元素較小,將搜索區間縮小至左一半
right = mid - 1;
}else {
// 待排元素較大,將搜索區間縮小至右一半
left = mid + 1;
}
}
// 將待排元素放在對應的位置
for (int j = i - 1;j >= right + 1;j--){
a[j + 1] = a[j];
}
a[right + 1] = tmp;
}
}
// 查看排序結果
for (int data : a){
System.out.print(data + "\t");
}
}
}
- 執行效果
2. 時間復雜度
對于折半插入排序來說,由于元素的串位次數沒有發生變化,只是在查找位置是更加快速了,所以總得來說與直接插入排序處于同一量級,在資料量很大時,要優于直接插入排序,
- 最壞的情況
如果輸入的元素剛好是反向有序的,那么每次都需要進行位置的查找,但是在查找的次數要少一些,可以知道,由于區間每次縮小一半,可以得到尋找位置的次數最多為 log ? 2 i \log _{2} i log2?i 量級,但是由于移動元素的次數沒變,時間復雜度依然是 O( n 2 n^{2} n2),
- 最好的情況
最好的情況與直接插入排序相同,如果元素已經是正向有序的,那么在最開始比較的時候就會認為在合適的位置,不需要再進行位置的尋找和串位,因此時間復雜度為O(n),
- 平均情況
綜合兩種情況,插入排序的時間復雜度為O( n 2 n^{2} n2),
3. 空間復雜度
演算法執行程序中直接在原集合上操作,只需要幾個額外的變數記錄關鍵資訊,所以空間復雜度為常數級:O(1),

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/276188.html
標籤:其他
上一篇:【資料庫原理及應用】經典題庫附答案(14章全)——第七章:資料庫恢復技術
下一篇:C站能力認證訓練Day1