瀏覽https://www.abc.net.au/news/justin
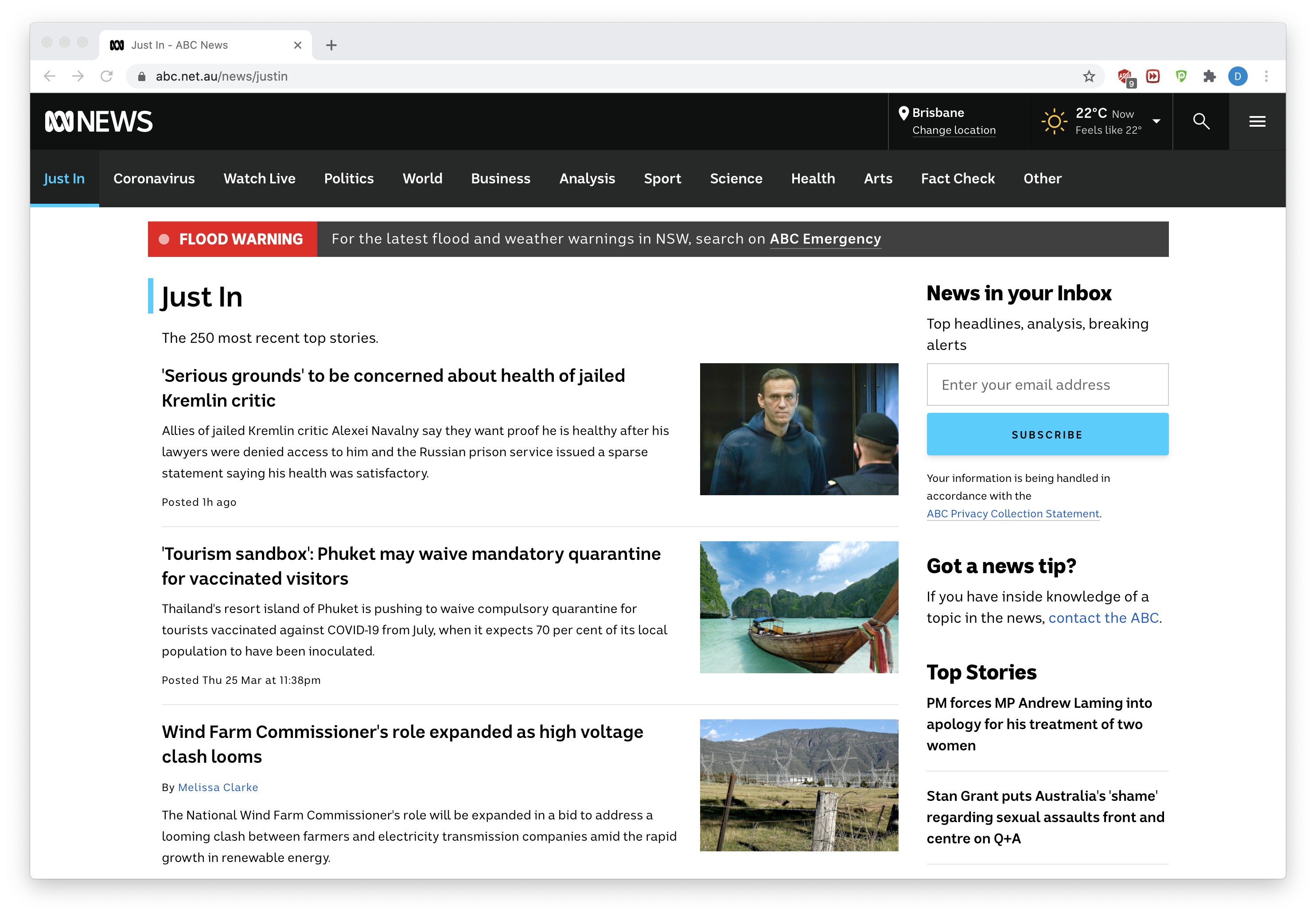
我們對Just in部分的新聞標題和超鏈接感興趣。更具體地說,這就是下圖中突出顯示的部分
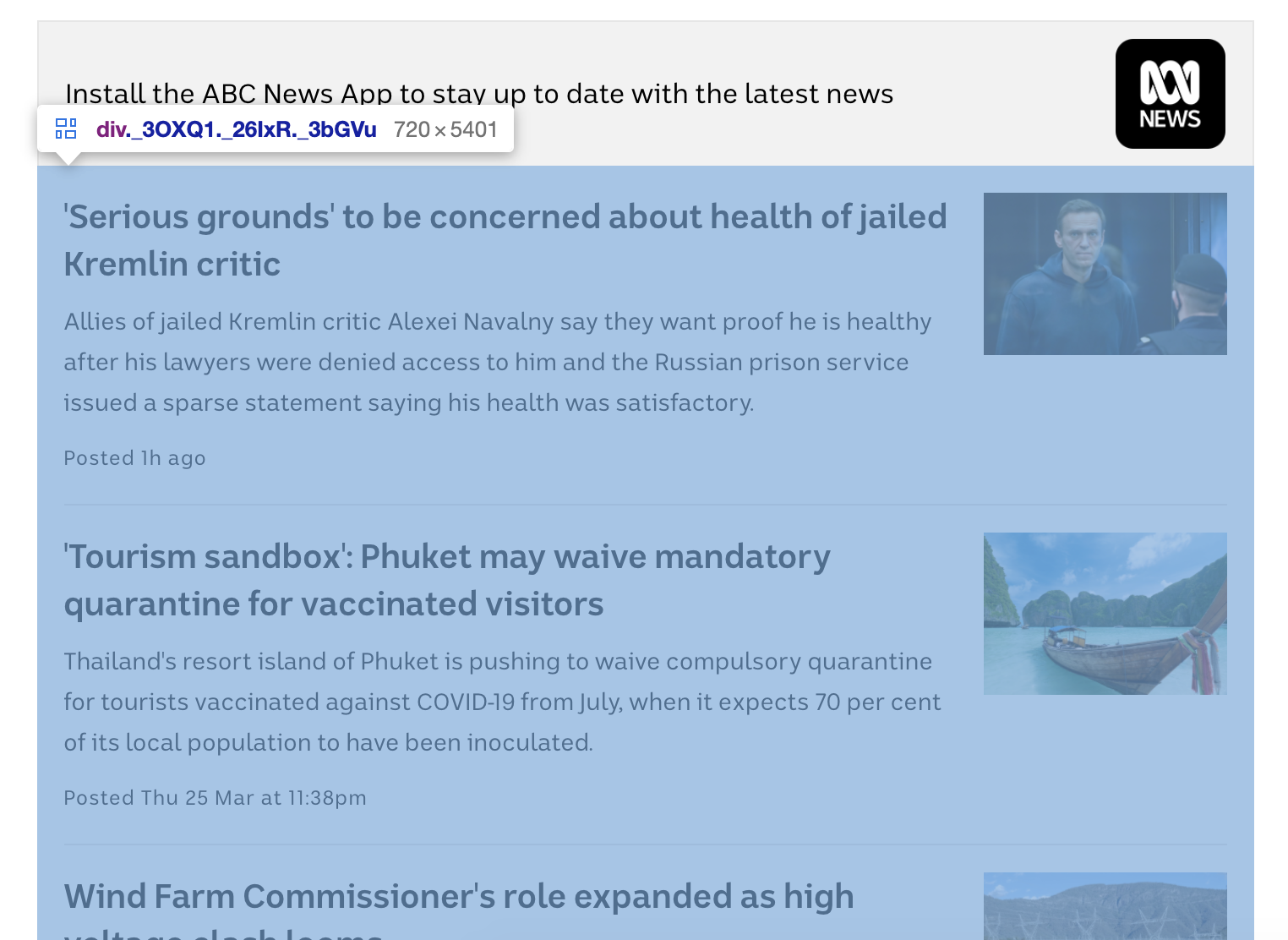
自這個練習發布以來,該頁面上的內容已經更新。盡管內容發生了變化,但原則仍然不變。
您需要做的是:在Just in頁面的突出顯示部分中收集所有(1)標題、(2)底層超鏈接和(3)新聞文章的描述。將資訊保存到一個名為abcnews.csv的csv檔案中,該檔案包含三個變數:標題、超鏈接和“描述”。每篇文章一行,結合文章的標題、超鏈接和描述。
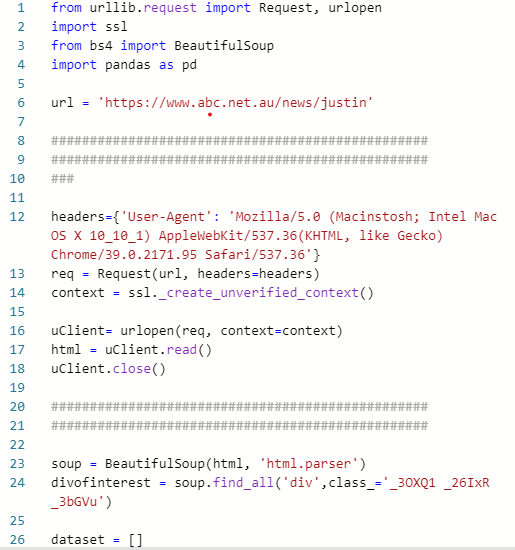

from urllib.request import Request, urlopen
import ssl
from bs4 import BeautifulSoup
import pandas as pd
url = 'https://www.abc.net.au/news/justin'
#################################################
#################################################
###
headers={'User-Agent': 'Mozilla/5.0 (Macinstosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36(KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36'}
req = Request(url, headers=headers)
context = ssl._create_unverified_context()
uClient= urlopen(req, context=context)
html = uClient.read()
uClient.close()
#################################################
#################################################
soup = BeautifulSoup(html, 'html.parser')
divofinterest = soup.find_all('div',class_='_3OXQ1 _26IxR _3bGVu')
dataset = []
for item in divofinterest('a'):
title = item.find('p').getText()
url = item['href']
print(title)
print(url)
print()
dataset.append({'title':title,'url':url})
dataset = pd.DataFrame(dataset)
dataset.to_csv('abcnews.csv',sep=';',index=False)
目前寫成這樣
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/276376.html
上一篇:Python