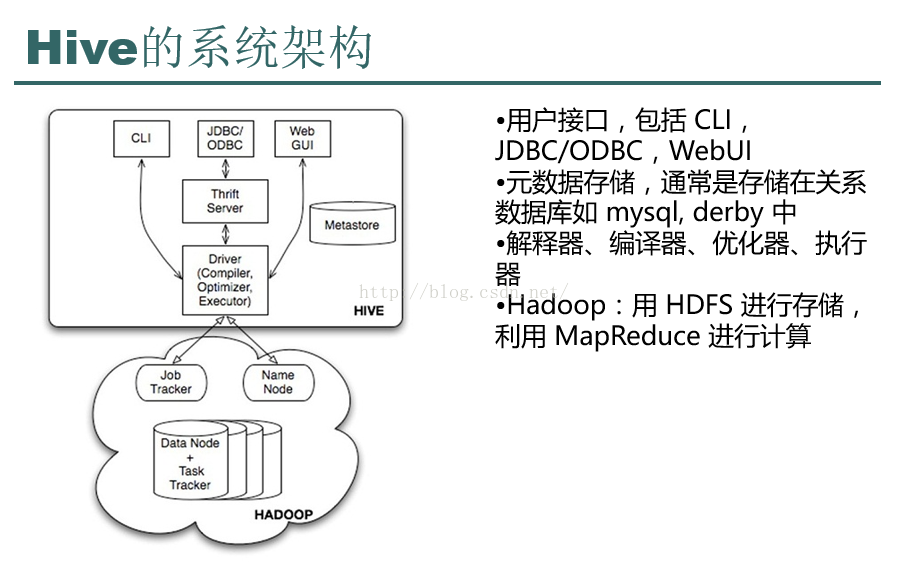
Hive是一個基于Hadoop的資料倉庫工具,它本身并不存盤資料,部署在Hadoop集群上,資料是存盤在HDFS上的.
Hive所建的表在HDFS上對應的是一個檔案夾,表的內容對應的是一個檔案,它不僅可以存盤大量的資料而且可以對存盤的資料進行分析,但它有個缺點就是不能實時的更新資料,無法直接修改和洗掉資料,如果想要修改資料需要先把資料所在的檔案下載下來,修改完之后再上傳上去,
Hive也不是分布式計算框架,Hive的核心作業就是把sql陳述句翻譯成MR程式去執行,不用我們再手動去寫MapReduce了,
Hive也不提供資源調度系統,默認由Hadoop集群中的YARN集群來調度,
Hive可以將結構化的資料映射為一張資料庫表,并提供HQL(HiveSQL)查詢功能,
Hive的語法非常類似于我們的MySQL陳述句,所以上起手來特別容易,
hive正是實作了hadoop和DBA掛鉤,hive是要類SQL陳述句(HiveQL)來實作對hadoop下的資料管理,那么,資料庫和資料倉庫到底有什么區別了,這里簡單說明一下:
資料庫側重于OLTP(在線事務處理),資料倉庫側重OLAP(在線分析處理);也就是說,例如mysql類的資料庫更側重于短時間內的資料處理,反之
無hive:使用者.....->mapreduce...->hadoop資料(可能需要會mapreduce)
有hive:使用者...->HQL(SQL)->hive...->mapreduce...->hadoop資料(只需要會SQL陳述句)

介紹完Hive的理論知識,接下來我們一起真正操作一下我們的Hive,在操作之前請確保您的Hadoop集群是正常的,如果還沒有搭建好集群請參考:https://blog.csdn.net/suwei825/article/details/115122465這篇博客進行搭建,
首先我們需要下載Hive的安裝包,這里我使用的是 apache-hive-3.1.1-bin.tar.gz,可以在這里 https://download.csdn.net/download/suwei825/16693276 下載
下載完開發包之后上傳到master105服務器上,然后把它解壓到/software/目錄下

我們進到檔案夾的bin目錄下,可以查看到一些hive的可執行腳本
我們再切換到conf目錄下,里面是組態檔
接下來
1、配置環境變數,添加HIVE_HOME
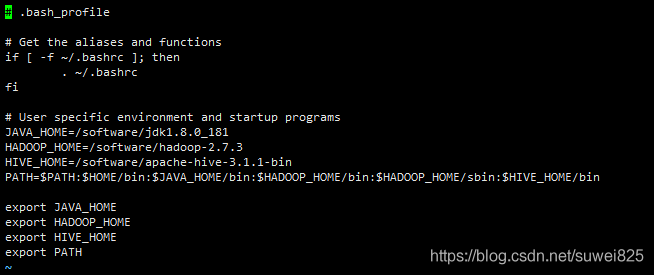
添加保存后,記得執行 source .bash_profile
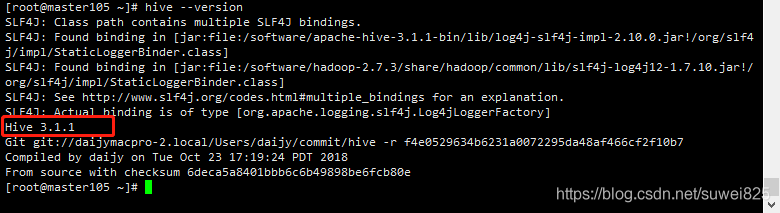
2、驗證配置
我們執行 hive --version,列印出如下資訊,說明環境變數配置生效了
3、配置hive-site.xml
我們去到conf目錄
里面沒有hive-site.xml檔案,我們復制一個 cp hive-default.xml.template hive-site.xml 也可以新建一個,內容如下<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.179.3:3306/sshive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>000000</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
</configuration>
以上配置我連接的mysql是我物理主機的mysql
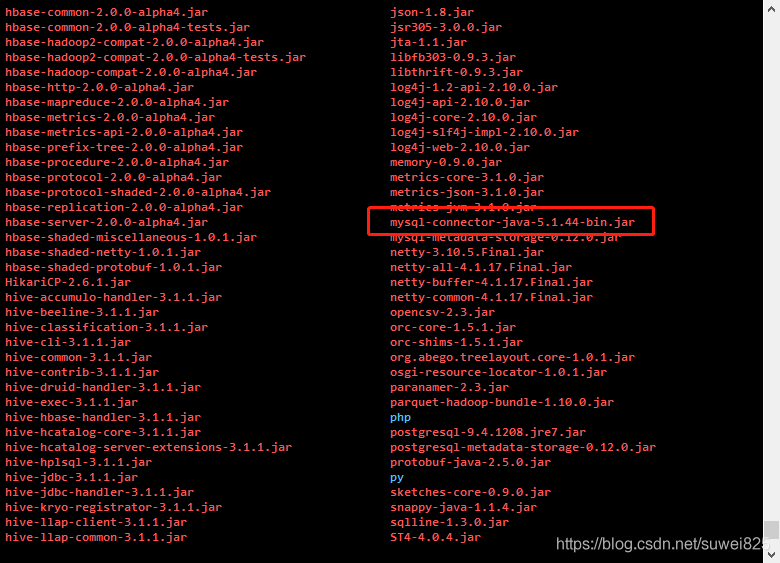
4、復制mysql驅動
我們把組態檔配置的mysql資料庫驅動檔案mysql-connector-java-5.1.44-bin.jar,放到/software/apache-hive-3.1.1-bin/lib里面
5、在mysql中創建hive的schema(在此之前需要創建mysql下的hive資料庫)
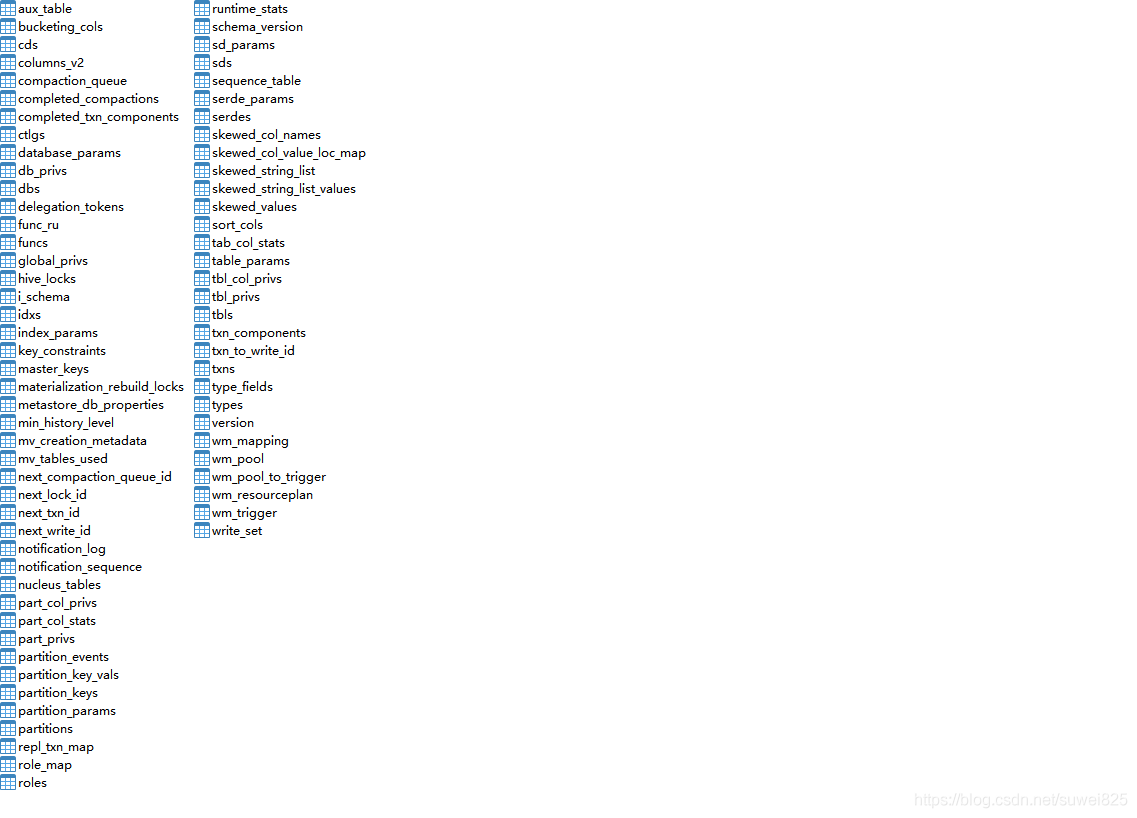
執行初始化 schematool -dbType mysql -initSchema執行后,結果如下表示成功了

我們用資料庫工具打開sshive庫,可以看到已經初始化成功的資料表
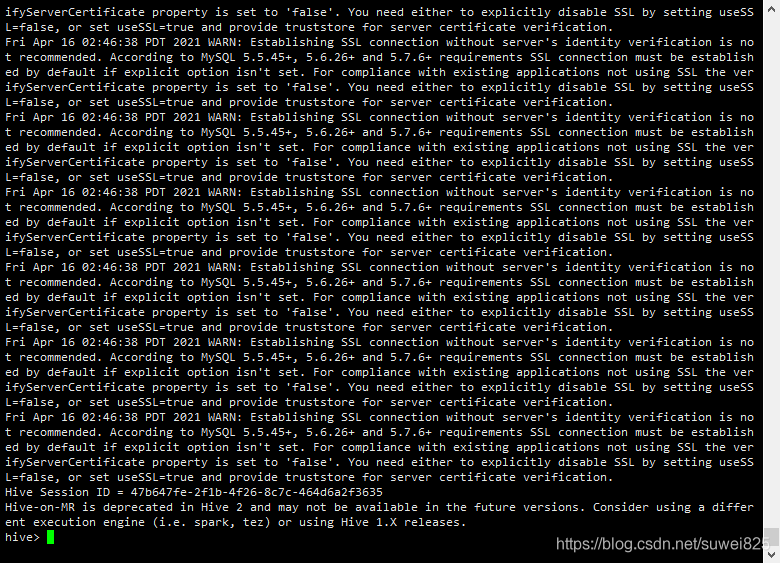
6、進入hive,我們在終端直接執行hive,出現下圖界面就成功了
7、hive on hadoop
我們執行下面2個操作
create database hivetest;
show databases;
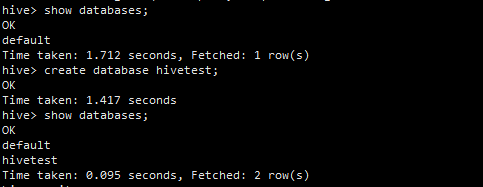
這樣我們已經創建了一個hivetest庫那我們的hive和hadoop有什么聯系呢?不要著急,我們前面初始化mysql元資料庫的時候,里面有一張表dbs
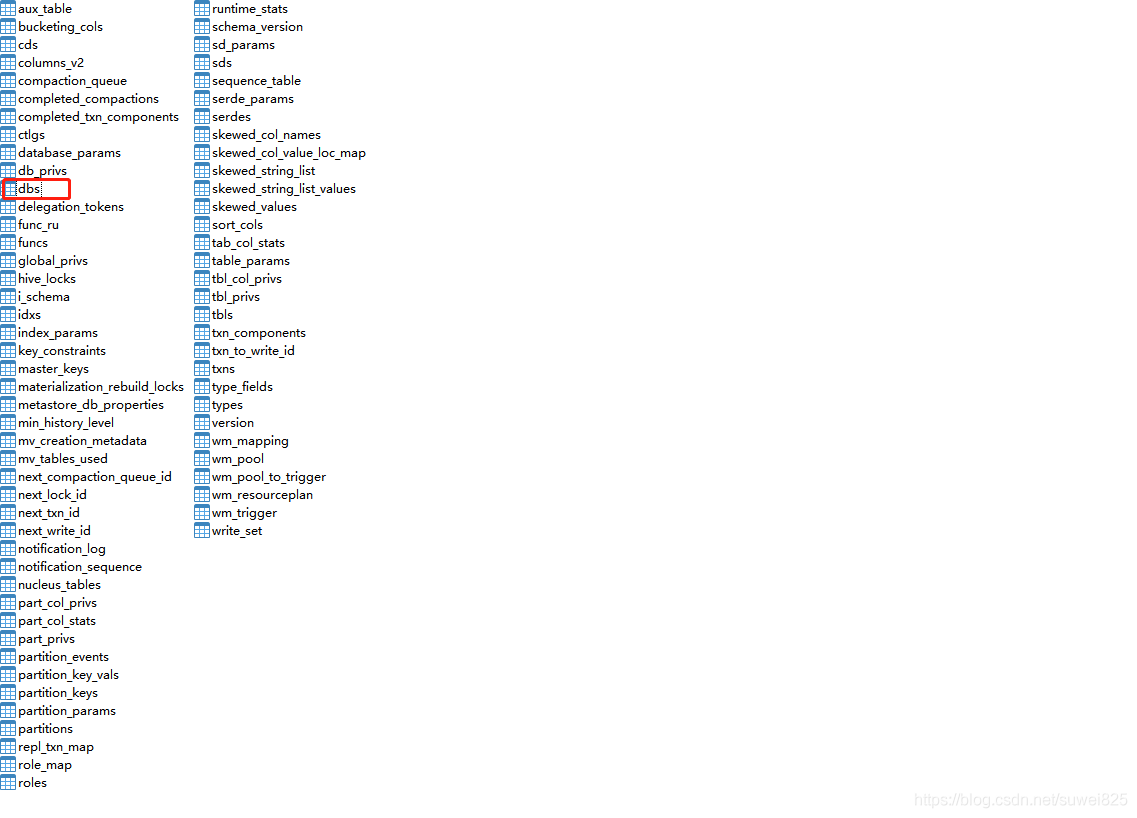
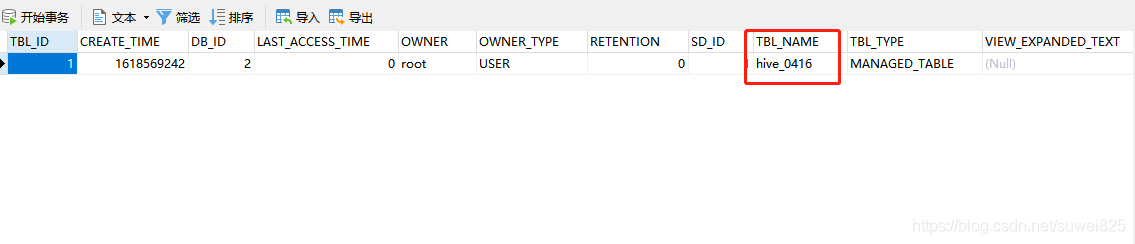
我們打開這個dbs表,看第二條記錄,hivetest庫已經在里面了

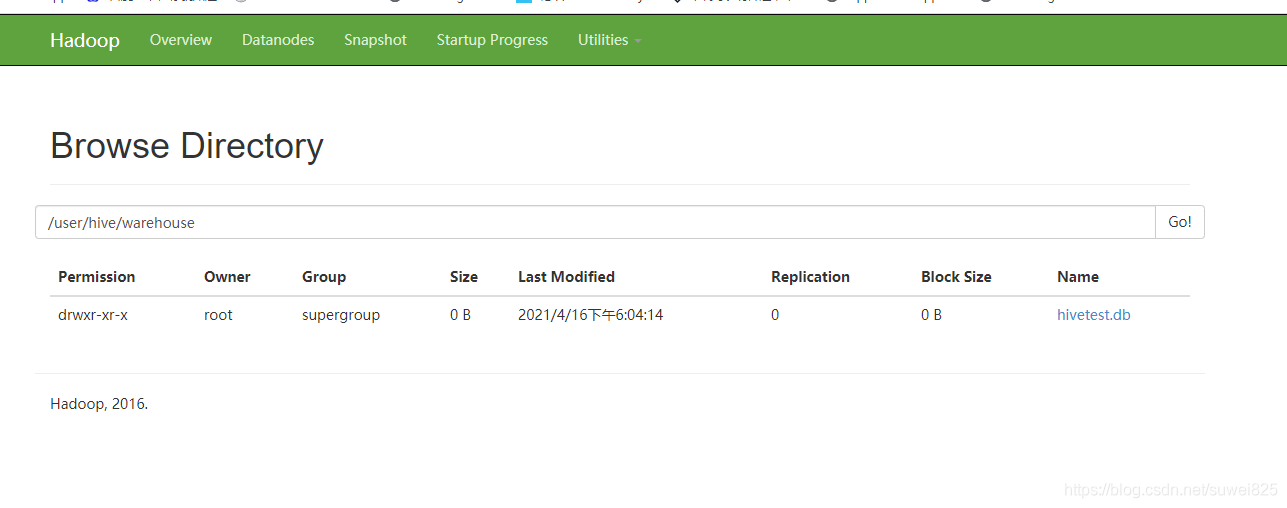
我們再打開master105的hdfs管理界面,可以找到/user/hive/warehouse下面的hivetest.db的存盤檔案了,hive的資料就存盤到HDFS里面了
我們在hivitest庫再創建一個表
use hivetest;
create table hive_01 (id int,name string);
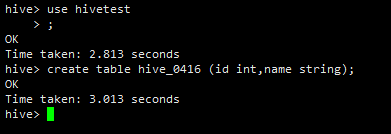
show tables; 表hive_0416也創建好了
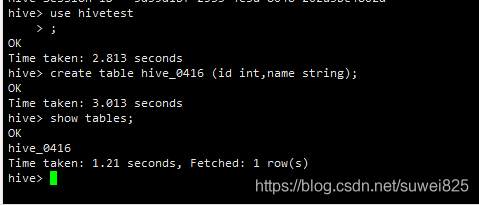
我們可以在元資料庫里tbls找到新建的表記錄
也可以在hdfs瀏覽到 http://master105:50070/explorer.html#/user/hive/warehouse/hivetest.db
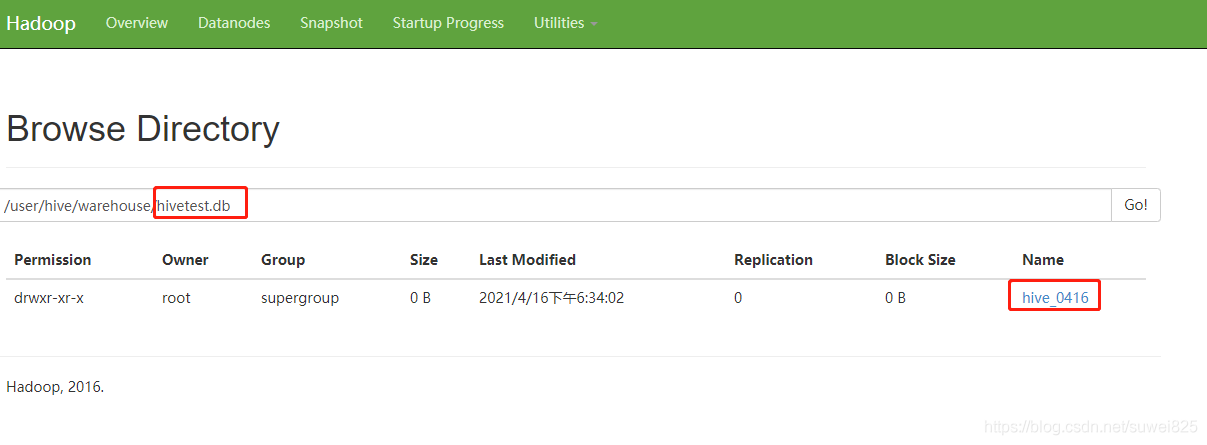
結論:在 hive 中創建的資料庫和表存盤在 hdfs 中,元資料存盤在 元資料庫 中;
hive-site.xml里的 hive.user.install.directory 引數,定義了HDFS的路徑,默認/user
今天的課程就到這里了,如果對內容覺得滿意,請點擊下方一鍵三連
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/276993.html
標籤:其他
上一篇:scala常見筆試題