前言
配置的虛擬機為Centos6.7系統,hadoop版本為2.6.0版本,先前已經完成搭建CentOS部署Hbase、CentOS6.7搭建Zookeeper和撰寫MapReduce前置插件Hadoop-Eclipse-Plugin 安裝,在此基礎上完成了Hive詳解以及CentOS下部署Hive和Mysql和Spark框架在CentOS下部署搭建,Spark的組件Spark SQL的部署:Spark SQL CLI部署CentOS分布式集群Hadoop上方法,
配置JDK1.8、Scala11.12
本文將介紹DataFrame基礎操作以及實體運用
一、DataFrame
Spark SQL提供了一個名為DataFrame的抽象編程模型,是由SchemaRDD發展而來,不同于SchemaRDD直接繼承RDD,DataFrame自己實作了RDD的絕大多數功能,可以把Spark SQL DataFrame理解為一個分布式的Row物件的資料集合,
Spark SQL已經集成在spark-shell中,因此只要啟動spark-shell就可以使用Spark SQL的Shell互動介面,如果在spark-shell中執行SQL陳述句,需要使用SQLContext物件來呼叫sql()方法,Spark SQL對資料的查詢分成了兩個分支:SQLContext和HiveContext,其中HiveContext繼承了SQLContext,因此HiveContext除了擁有SQLContext的特性之外還擁有自身的特性,
二、創建DataFrame物件
DataFrame可以通過結構化資料檔案、Hive中的表、外部資料庫、Spark計算程序中生成的RDD進行創建,不同的資料源轉換成DataFrame的方式也不同,
創建sqlContext物件:
val sqlContext=new org.apache.spark.sql.SQLContext(sc)

通過這種方式創建的SQLContext只能執行SQL陳述句,不能執行HQL的陳述句,
創建HiveContext物件:
val hiveContext=new org.apache.spark.sql.hive.HiveContext(sc)

HiveContext不僅支持HiveQL語法決議器,同時也支持SQL語法決議器,
1.結構化資料檔案創建DataFrane
一般情況下,把結構化資料檔案存盤在HDFS,Spark SQL最常見的結構化資料檔案格式是Parquet檔案或JSON檔案,Spark SQL可以通過load()方法將HDFS上的格式化檔案轉換為DataFrame,load默認匯入的檔案格式是Parquet,

JSON檔案轉換DataFrame有兩種方法,一種使用format()方法:
val dfPeople=sqlContext.read.format(“json”).load(“/user/SparkSql/”test2.json")

也可以直接用json()方法:

2.外部資料庫創建DataFrame
SparkSQL還可以從外部資料庫中創建DataFrame,使用這種方式創建DataFrame需要通過JDBC連接或者ODBC連接的方式訪問資料庫,
這個應該是常用方法通過資料庫匯入,本人虛擬機MYsql并沒有匯入檔案這里不作演示,代碼:
val jdbcDF=sqlContext.read.format("jdbc").options(
|Map("url"->url,
|"user"->"root",
|"passwword"->"root",
|"dbtable"->"people")).load()
3.RDD創建DataFrame
RDD資料轉為DataFrame有兩種方式:
第一種方式利用反射機制推斷RDD模式,需要定義一個case class類:
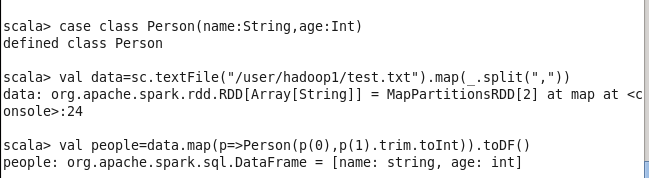
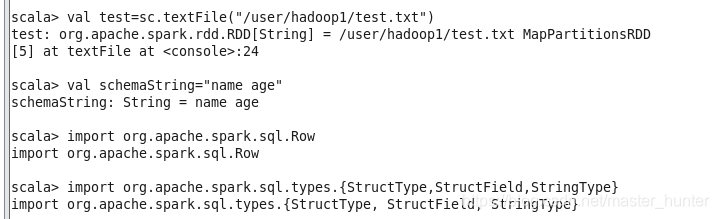
第二種方式是當無法提前定義case class時,可以采用編程指定Schema的方式將RDD轉換成DataFrame,通過編程指定Schame需要3步:
(1)從原來的RDD創建一個元組或串列的RDD,
(2)用StructType創建一個和步驟(1)在創建的RDD中元組或串列的結構相匹配的Schema,
(3)通過SQLContext提供的createDataFrame方法將Schema應用到RDD上,



4.Hive中的表創建DataFrame
從Hive表中的表創建DataFrame,可以宣告一個HiveContext物件:

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/277003.html
標籤:其他