supervised-ml-sentiment-analysis Supervised ML(training)
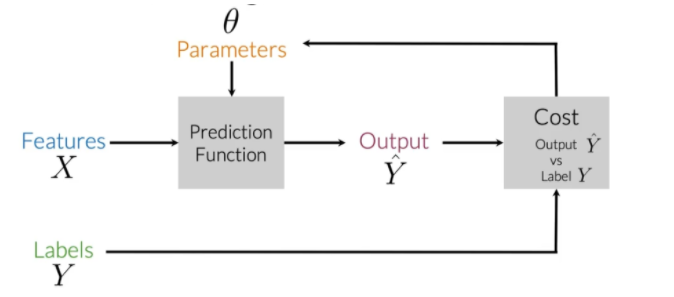
在監督機器學習中你要輸入特征X和一組標簽Y,現在為了確保基于你的資料能夠得到最準確的預測,你的目標是盡可能減少錯誤率或成本,為了做到這一點,你要運行你的預測函式,它接受引數資料來映射你的特征到輸出標簽Y ^ \hat{Y}Y^,現在,當期望值Y和預測值Y ^ \hat{Y}Y^差值最小時從特征到標簽實作最佳的映射,然后你更新你的引數,反復整個程序直到你的成本最小, vocabulary-feature-extraction

如何將一個文本表示為一個向量,為了讓你這么做,首先你必須建立一個詞匯表,它允許你來編碼任何一個文本或任何一條推特作為一個數字陣列,然后你的詞匯表,V,將會是來自你的推特串列中的唯一單詞串列,為了得到這個串列,你必須瀏覽所有推文中的所有單詞,并保存搜索中出現的每一個新單詞,所以在這個例子中,你會有單詞 I,然后單詞是am和happy, because 等等,但是請注意,單詞I和am不會在詞匯表中重復出現,

讓我們使用你的詞匯表來提取這些推特的特征,要做到這一點,你必須核對你的詞匯表中是否每個單詞都出現在在推特上,像"I"這個單詞而言,你會給這個特征賦值1,像這樣,如果它沒有出現(在推特上),你會賦值0,像那樣,在這個例子中,你的推特表征由6個1和很多0構成,這對應于你的詞匯表中沒有出現在推特上的每一個唯一的單詞,現在這種帶有相對數量較小的非零值的表示稱為稀疏表示,
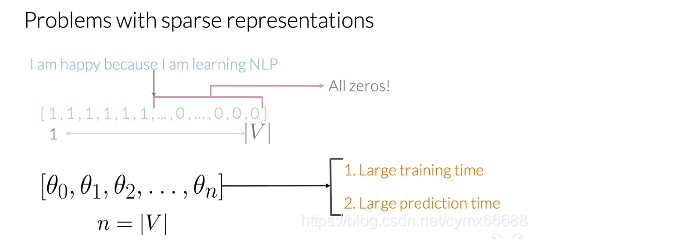
使用稀疏表示,一個邏輯回歸模型必須學習n+1個引數,n個引數跟你的詞匯表大小相等,你可以想象,對于大的詞匯表,這將是有問題的,這將花費過多的時間來訓練你的模型,而做預測所需要的時間則遠遠多于所需時間, negative-and-positive-frequencies 生成"計數",,給定一個單詞,你需要記錄次數,也就是它出現正類的次數,給定另一個單詞你需要記錄它出現負類的次數,使用這兩種計數,然后你抽取特征,使用這些特征進入到你的邏輯回歸分類器中, 在這個情感分析的例子中,你有兩類,一類與積極情緒相關聯,另一類帶有消極情緒,所以在你的語料庫中,你有一組屬于正類的2條推特和一組屬于負類的2條推特,

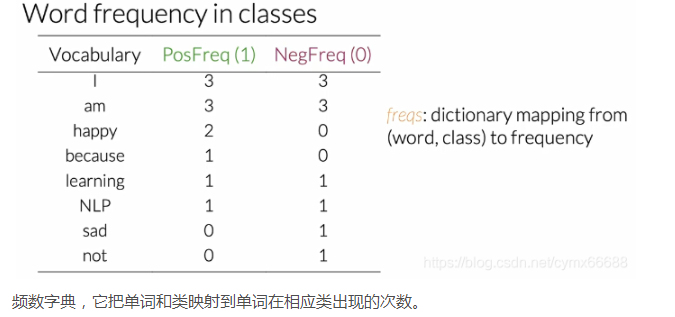
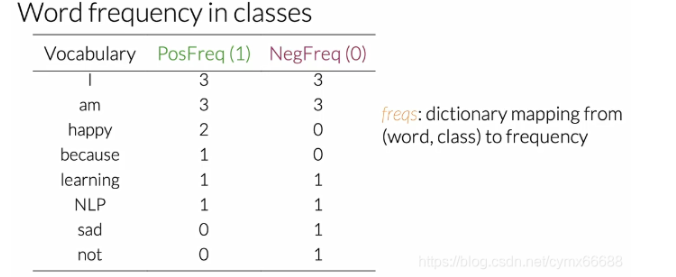
讓我們以正類為例,現在,看你的語料庫,要想在你的詞匯表中得到任何一個單詞的正頻數,你必須計算它出現在正推特中的次數,例如,單詞"happy"在第一條正推特中出現一次,另一次在第二條正推特中,所以它的正頻數是2,完整的表像這樣,請隨時暫停并檢查其中的任何條目,

這整張表包括了語料庫的正頻數和負頻數,在實際編碼時,這個表是一個從一個單詞到它頻率的字典映射,所以它把單詞和她對應的類映射到它在類中出現的頻率或次數,
feature-extraction-with-frequencies 現在將學習把一條推特或特定的表征編碼成一個3維的向量,這樣的話,你的邏輯回歸分類器的速度會快得多,因為你不需要學習V個特征,而只需要學習3個特征, 你只看到一個單詞在這個類中的頻率僅僅是這個詞出現在一組推特屬于那個類時的次數,這個表基本上是一個從單詞類對到頻率的字典,或者它只是告訴我們每個單詞在對應的類中出現了多少次,
現在已經構建了頻率詞字典,可以使用它抽取用于情感分析的有用特征,我們來看任意的推特m,第一個特征是bias(偏差),單位等于1,第二個是在推文m上每一個唯一單詞的正頻率之和,第三個是在推文m上每一個唯一單詞的負頻率之和,所以為了抽取這個表示的特征,你只需要對單詞的頻率求和,
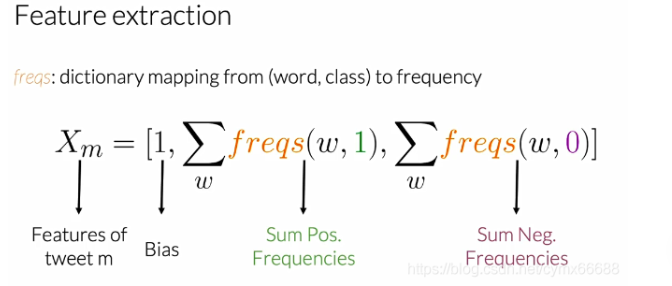
簡單的,例如,以下面的推特為例,讓我們來看下上節課正頻率的情況,詞匯表中沒有在這些推特中出現的單詞是"happy"和"because",現在讓我們看看你們在上一張幻燈片上看到的第二個特征,為了獲得這個值,你需要對出現在推特上的詞匯表中單詞的頻率求和,最后,你得到值等于8,

現在讓我們得到第三個特征的值,它是出現在推特詞匯表上的單詞負頻率的和,在這個例子中,把帶下劃線的頻率加起來應該是11,

到目前為止,這個推特,這個表示將等于向量[1, 8, 11]

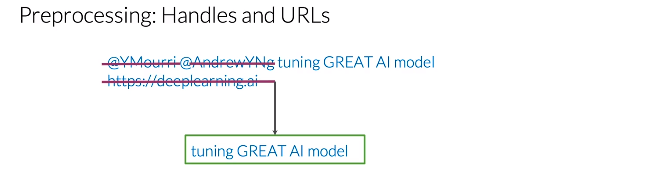
現在知道如何把一條推特表示為一個3維向量, preprocessing 現在你將學習預處理的兩個概念,你要學習的第一件事叫做stemming(詞干分析),第二件事叫做stop words(停用詞),具體來說,你要學習如何使用詞干分析和停用詞來預處理你的文本, 讓我們處理下這條推特,首先我移除所有對推特沒有重要意義的單詞,又稱停用詞和標點符號,在實踐中,你必須將推特與兩個串列進行比較,一個帶有英文的停用詞,另一個帶有標點符號,這些串列通常是比較大的,但對于本例的目的來說,它們就足夠了,推特中的每個單詞也出現在停用詞的串列中應該被消除,所以必須要消除單詞"and"、“are”、“a”、“at”,沒有停用詞的推特像這個,請注意,這個句子的整體意思可以毫不費力地推斷出來,

推特和其他型別的文本經常有handle和url,但這對情感分析任務沒有任何價值,讓我們消除這兩個@和這條url,在這個程序的最后,產生的推特包含所有與其情感相關的重要資訊,
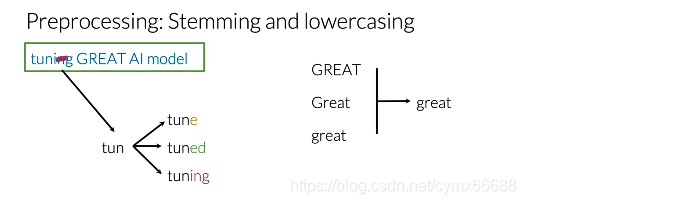
既然示例上的推特僅僅只有必要的資訊,我將對每個單詞進行詞干提取,NLP中的詞干提取只是將任何單詞轉換為它的基本詞干,你可以將基本詞干定位為用于構造詞及其派生的一組字符,看下示例中的第一個詞,它的詞干已經完成了,因為添加一個字母"e",就組成了單詞"tune",添加后綴"ed",就組成單詞"tuned",添加后綴"ing",就組成單詞"tuning",在你對語料庫執行詞干分析之后,單詞"tune"、“tuned"和"tuning"會轉化為"tun”,因此,當你對語料庫中的每個單詞執行這個程序時,你的詞匯量將會顯著減少,為了進一步減少你的詞匯量而又不丟失有價值的資訊,你必須把每個單詞都小寫,所以單詞"GREAT","Great"和"great"將被視為完全相同的單詞,這是最后的預處理推特作為單詞串列,
putting-it-all-together 你現在使用你所學的一切來創建一個與你的訓練示例的所有特征相對應的矩陣,具體來講,我會帶你進入一個演算法允許你生成這個x矩陣,讓我們看看你怎么創建吧,你先前看到如何預訓練一個像這樣的推特得到一個單詞串列,包含NLP中情感分析任務所有的相關資訊,有了這個單詞串列,你能夠使用頻率字典映射得到一個很好的表示,最后,得到一個帶有偏差單位的向量和兩個額外的特征,用來存盤你的行程推特中出現在正推文中的次數之和和它們出現在負推文中的次數之和,
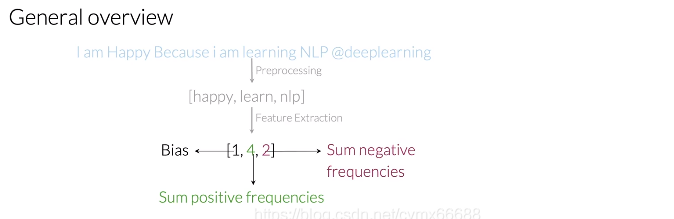
在實踐中,你必須對一組m個推文執行此程序,因此給定一組多個原始推文,你必須一個接一個的對它們進行預處理,已獲得每個推文的對應的一組單詞串列,最后,你能夠使用一個頻率字典映射來提取特征,

最后,你會得到一個矩陣X,m行3列,每行會包含你的每一條推特的特征,

這個程序的綜合實作是比較容易的,首先,你創建頻率字典,然后初始化矩陣X來匹配你的推文個數,之后,你需要仔細檢查你的一組推文,洗掉停用詞、詞干,洗掉URL、@,和小寫轉換,最后,通過對推文的正向頻率和負向頻率求和來提取特征,這周的設計,已經提供了一些幫助函式,build_frequs和process_tweet,然而,你必須實作提取單個推文特征的函式,

logistic-regression-overview 先前你學習了提取特征,現在你將使用這些已提取的特征來預測是否一個推文有一個正向情緒或是一個負向情緒,邏輯回歸使用了一個sigmoid函式,輸出一個在0到1之間的概率,讓我們回顧下邏輯回歸,簡單回歸下,在監督機器學習中,你輸入特征和一組標簽,為了基于你的資料做預測,你使用一個帶有一些引數來映射你的特征的函式來輸出標簽,為了得到一個從你的特征到標簽的最佳映射,你將成本函式最小化,這個函式用來比較你的輸出值Y ^ \hat{Y}Y^和資料中真實標簽Y YY有多接近,在引數被更新后,你重復這個程序直到你的成本最小化,對于邏輯回歸,這個函式F等同于sigmoid函式,
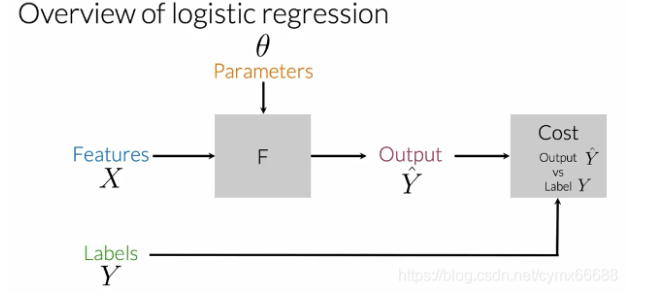
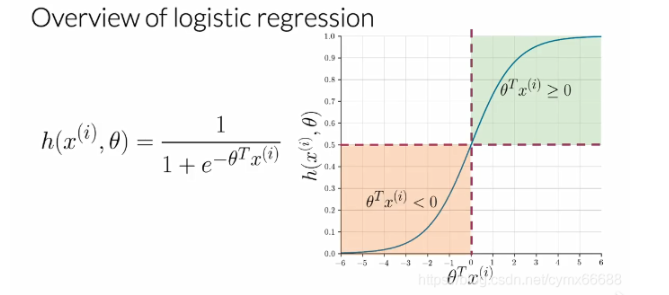
邏輯回歸中用于分類的函式H是個sigmoid函式,它取決于引數θ \thetaθ,然后特征向量x i x^ixi,i ii用來表示第i ii個觀察值或資料點,在推文中,是第i ii個推文,從視覺上看,sigmoid函式有這樣的形式,它趨近于0,是θ \thetaθ轉置與X的點乘,在這里,X趨近于負無窮,趨近于正無窮是1,對于分類,需要給定一個閾值,通常被設定為0.5,這個值相當于θ \thetaθ轉置與X的點乘等于0,因此無論何時點乘是越來越大或大于等于0,預測是正的,無論何時點乘小于0,預測是負的,
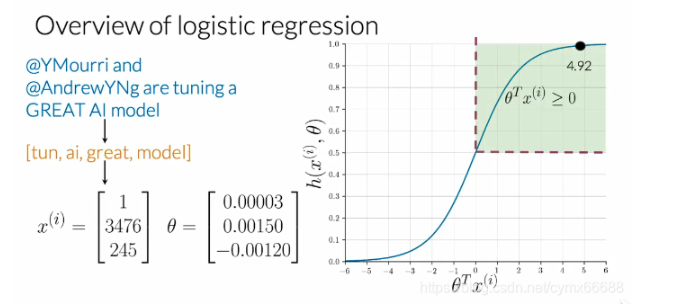
讓我們來看一個現在熟悉的推文和情感分析示例,看下面的推文,在預處理之后,你應該得到一個像這樣的串列,請注意要把@的洗掉,所有都是小寫,單詞tuning減少到它的詞干tun,然后你能夠提取特征得到一個頻率字典,得到一個與下面相似的向量,這里有一個偏置單位,還有兩個特征是你已處理的推文中所有單詞的正向頻率和負向頻率,現在假設你已經有一組最優引數θ \thetaθ,你能夠得到sigmoid函式值,在這種情況下,等于4.92,最后,預測為一個正向情緒,
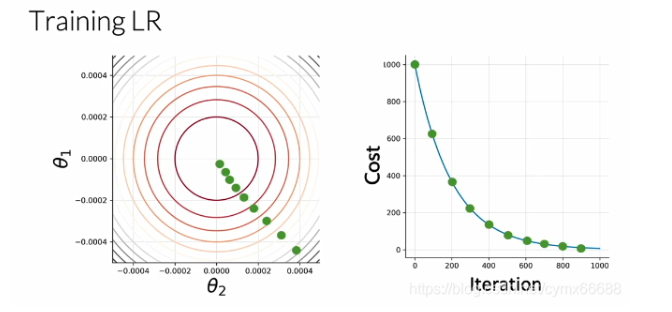
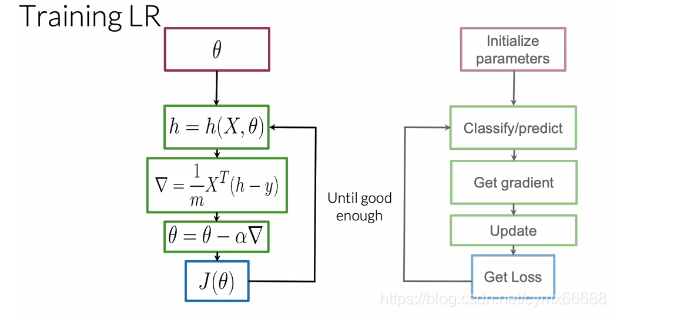
現在你知道了邏輯回歸的符號,你能使用它來訓練一個權重因子θ \thetaθ logistic-regression-training 在先前的視頻中,你學習了如何分類是否一個推文有一個積極情緒或是消極情緒,通過使用一個我給你的θ \thetaθ,在這個視頻中,你將從零開始學習θ \thetaθ,具體的說,我將帶你們通過一個演算法來得到θ \thetaθ變數,讓我們看看怎么做吧,為了訓練你的邏輯回歸分類器,迭代直到你發現一組引數θ \thetaθ,來使你的成本函式最小化,讓我們假設你的損失僅取決于引數θ 1 \theta_1θ1?和θ 2 \theta_2θ2?,你會有一個成本函式,就像左邊的等高線圖,在右邊,你可以看到迭代程序中成本函式的變化,首先,你必須初始化你的引數θ \thetaθ,然后你就可以自代價函式的梯度方向上更新你的θ \thetaθ,在100次迭代之后,將是這個點,在這里200次迭代,等等,在許多次迭代之后,你獲得一個跟你最優成本相近的點,你的訓練在這里終止了,
讓我們看下模型的詳細程序,首先,你必須初始化你的引數向量θ \thetaθ,然后你使用邏輯函式來得到你的每一個觀察值,接著,你能夠計算你的成本函式梯度并更新你的引數,最后,你計算你的成本J,根據一個停止引數或迭代的最大值來確定是否需要更多的迭代,正如你在其他課程中看到的,這種演算法被稱為梯度下降法,
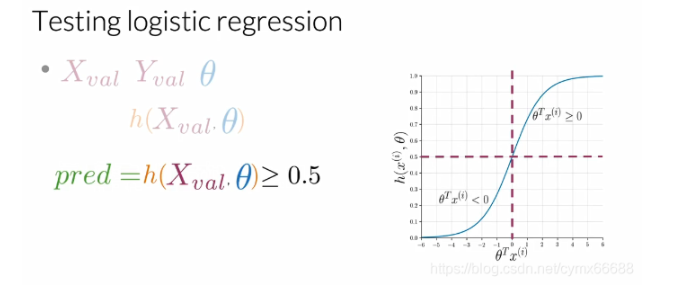
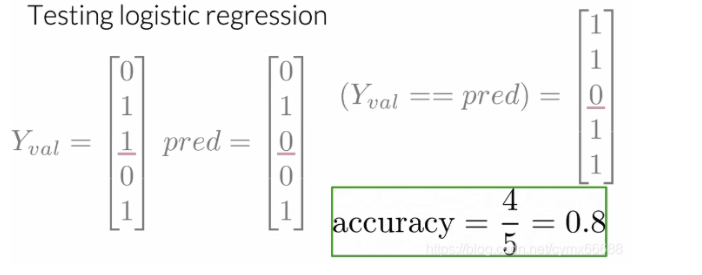
現在你有了你的θ \thetaθ變數,你想要計算你的θ \thetaθ,意味著你想要計算你的分類器,一旦你把θ \thetaθ放到你的sigmoid函式中,你能得到一個好的分類器還是一個差的分類器? logistic-regression-testing 現在你已經有了資料,你將使用這個資料來預測我們新的資料點,例如,給一個新的推特,你使用這個資料來看這條推特是積極的還是消極的,在這情況下,你想要分析你的模型是否可以很好地概括,在這個視頻中,我們將給你展示你的模型是否可以很好地概括,具體來講,我們將給你展示如何計算模型的準確率,讓我們看看你要怎么做吧,對于這個,你需要驗證集X和驗證集Y,在訓練中被擱置的資料,也被稱為驗證集,θ \thetaθ是你從資料訓練中得到的一組最優引數,首先,你將對驗證集X計算帶有引數θ \thetaθ的sigmoid函式,然后你將評估帶有θ \thetaθ的h每個值是否大于或等于閾值,閾值通常設為0.5,
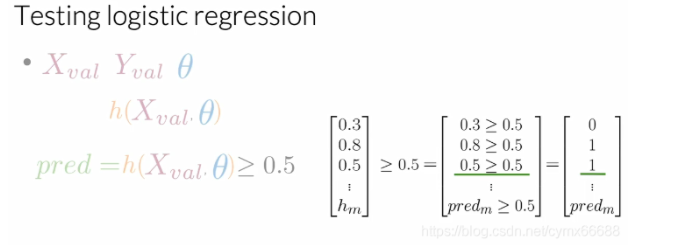
例如,如果你的h ( X v a l , θ ) h(X_val, \theta)h(Xv?al,θ)等于下面的向量0.5,0.8,0.5等等,直到驗證集的示例數(即h ( X v a l , θ ) = [ 0.3 0.8 0.5 . . . h m ] T h(X_val, \theta)=[0.30.80.5...hm]T h(Xv?al,θ)=[0.3?0.8?0.5?...?hm?]T?),你將斷言它的每個部分是否大于等于0.5,所以0.3大于等于0.5嗎?不,因此我們的第一個預測等于0,0.8大于等于0.5嗎?是的,因此我們第二個樣本預測是1,0.5大于等于0.5嗎?是的,因此我們第三個預測等于1,等等,最后,你將會有一個填充了0和1的向量,分別表示預測的正例和負例,
在創建預測向量之后,你可以計算驗證集上你的模型準確率,這樣做的話,你將對你做的預測和驗證資料中每一個觀察的真實值作比較,如果值等于你的預測值,那么是正確的,這個度量給了一個你的邏輯回歸將正確作用于未知資料上的次數估計,所以如果你的準確率等于0.5,這意味著50%的情況下,你的模型可以作業的很好,
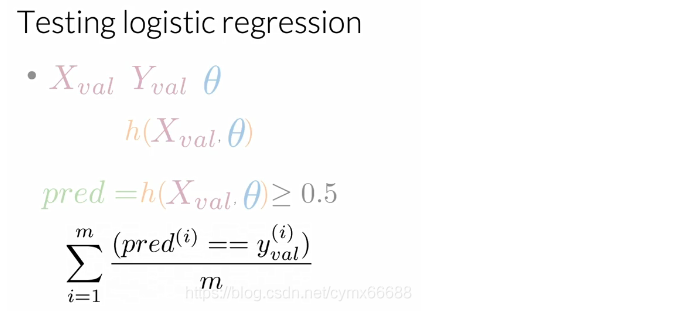
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/277302.html
標籤:其他