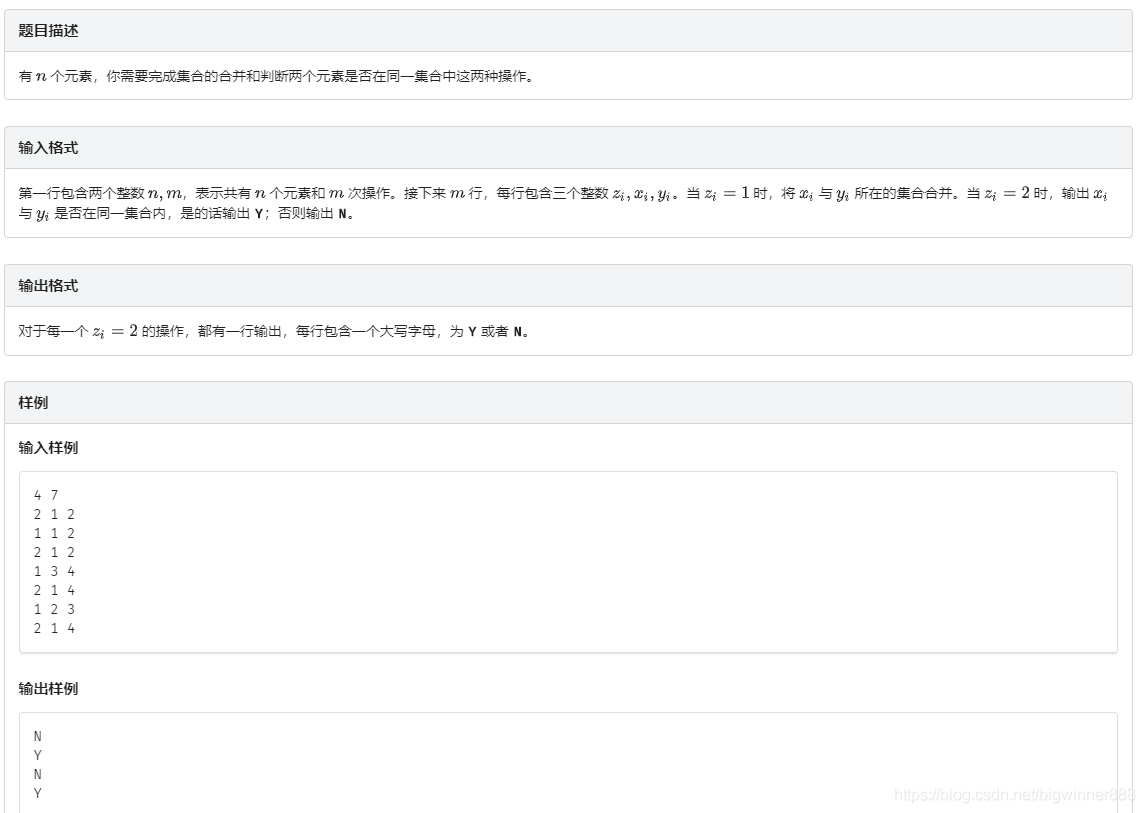
例題一:【模板】并查集 link

#include <bits/stdc++.h>
#define fre(x) freopen(#x".in","r",stdin),freopen(#x".out","w",stdout);
#define ll long long
using namespace std;
const int MAX = 2147483647;
const int N = 1e4 + 10;
int n, m, type, x, y, fa[N];
int find(int x) {return x == fa[x]? x: fa[x] = find(fa[x]);}
void unionn(int u , int v)
{
int x = find(u), y = find(v);
if(x != y) fa[x] = y;
return ;
}
void check(int u , int v)
{
int x = find(u), y = find(v);
if(x != y) printf("N\n");
else printf("Y\n");
return ;
}
int main()
{
//fre();
scanf("%d%d", &n, &m);
for(int i = 1; i <= n; i++) fa[i] = i;
for(int i = 1; i <= m; i++)
{
scanf("%d%d%d", &type, &x, &y);
if(type == 1) unionn(x , y);
else check(x , y);
}
return 0;
}
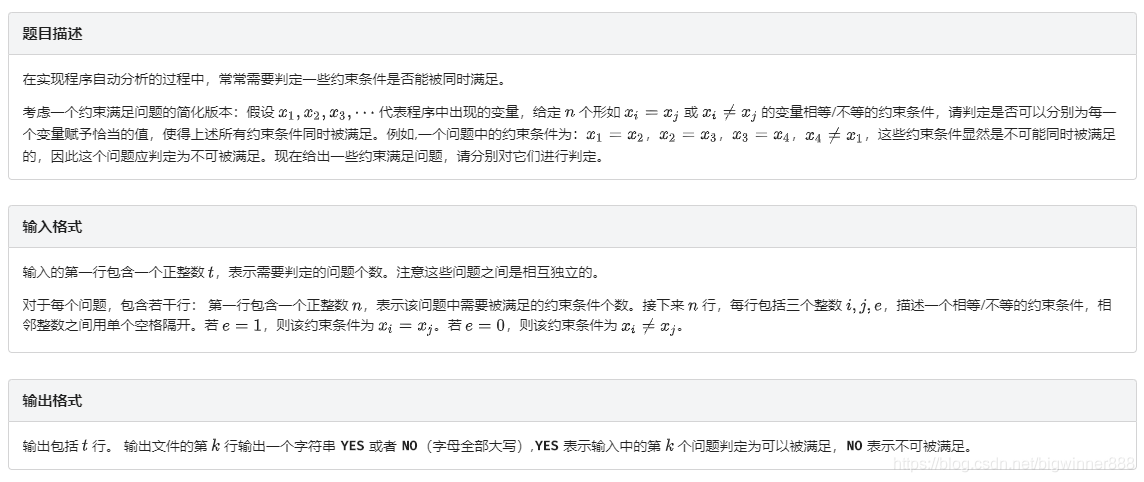
例題二:程式自動分析 link

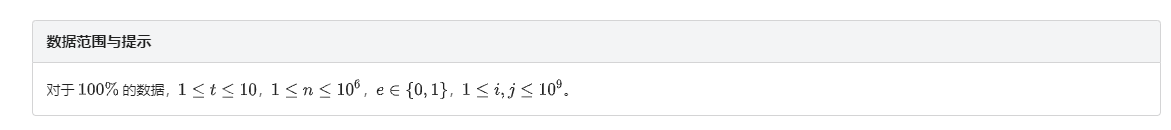
思路:
這道題我們考慮用并查集來做,
關心 x=y,那只用將其合并到同一個集合中
x≠y反之亦然,
再來考慮一下判定是否滿足怎么做?
想必大家都知道:
- 如果判斷為x=y,但是兩數不在同一集合,No
- 如果判斷為x≠y,但是兩數在同一集合,No
- 其他情況則為Yes
但是資料不是很友好,編號最大有
1
9
1^9
19,陣列這樣開一定會爆,
于是我們最后考慮用一下離散化縮小絕對大小變成相對大小,
#include<iostream>
#include<cstdio>
#include<cstring>
#include<algorithm>
#define R register int
using namespace std;
inline int read()
{
int f=1,x=0; char ch=getchar();
while(ch<'0'||ch>'9'){if(ch=='-') f=-1; ch=getchar();}
while(ch<='9'&&ch>='0') x=x*10+ch-'0',ch=getchar();
return f*x;
}
const int maxn=1000005;
struct data
{
int x,y,e;
}a[maxn];
inline bool cmp(data x,data y)
{
return x.e>y.e;
}
int t,n,f[maxn],b[maxn<<2];
inline int find(int x)
{
return x==f[x]?x:f[x]=find(f[x]);
}
int main()
{
t=read();
while (t--)
{
memset(a,0,sizeof(a));
memset(b,0,sizeof(b));
memset(f,0,sizeof(f));
n=read();int tot=0;
for (R i=1;i<=n;++i)
{
a[i].x=read();a[i].y=read();a[i].e=read();
b[++tot]=a[i].x;
b[++tot]=a[i].y;
}
sort(b+1,b+1+tot); //離散化
int tott=unique(b+1,b+1+tot)-b; //去重
for (R i=1;i<=n;++i)
{
a[i].x=lower_bound(b+1,b+1+tott,a[i].x)-b;
a[i].y=lower_bound(b+1,b+1+tott,a[i].y)-b;
}
for (R i=1;i<=tott;++i) f[i]=i;
sort(a+1,a+1+n,cmp);
bool ff=true;
for (R i=1;i<=n;++i)
{
if (a[i].e==1)
{
int f1=find(a[i].x),f2=find(a[i].y);
if (f1!=f2)
{
f[f1]=f2;
}
}else {
int f1=find(a[i].x),f2=find(a[i].y);
if (f1==f2)
{
ff=false;
break;
}
}
}
if (ff==true) printf("YES\n");
else printf("NO\n");
}
return 0;
}
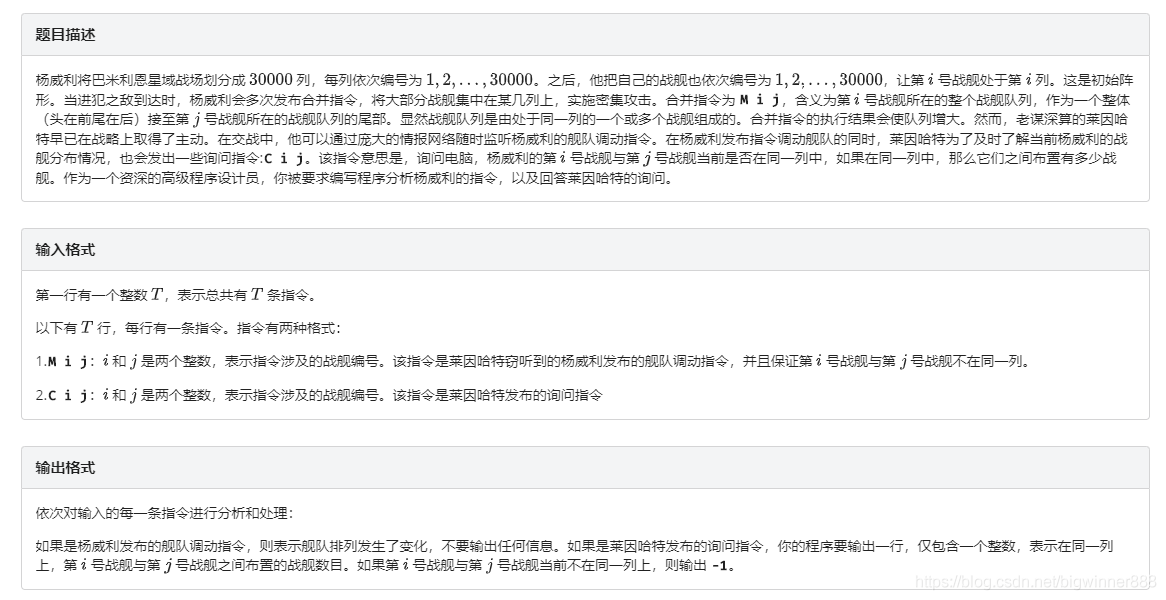
例題三:銀河英雄傳說 link
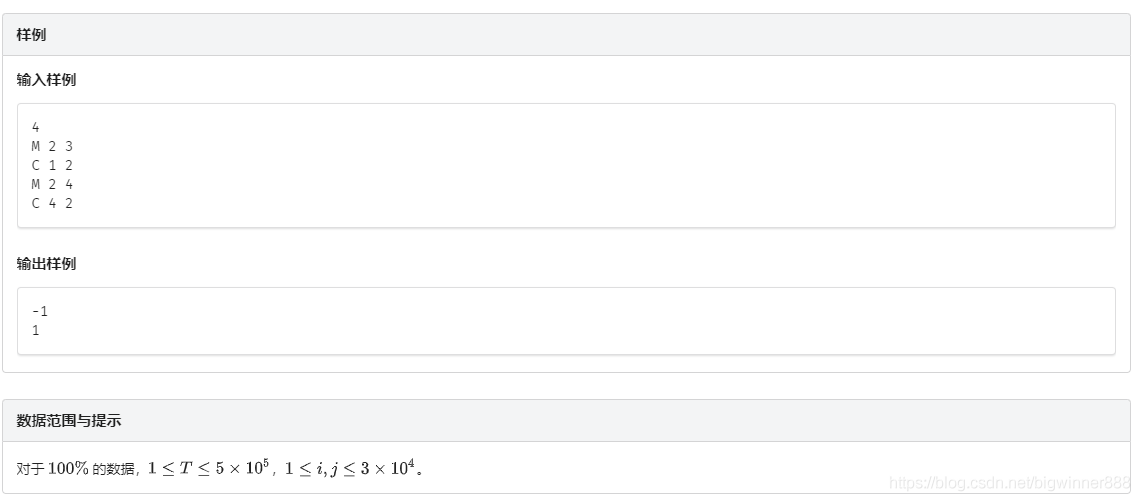
思路:
先來分析一下這些指令的特點,很容易發現對于每個M指令,只可能一次移動整個佇列,并且是把兩個佇列首尾相接合并成一個佇列,不會出現把一個佇列分開的情況,因此,我們必須要找到一個可以一次操作合并兩個佇列的方法,
再來看下C指令:判斷飛船i和飛船j是否在同一列,若在,則輸出它們中間隔了多少艘飛船,我們先只看判斷是否在同一列,由于每列一開始都只有一艘飛船,之后開始合并,結合剛剛分析過的M指令,很容易就想到要用并查集來實作,
定義一個陣列fa,fa[i]表示飛船i的祖先節點,即其所在列的隊頭,再定義一個用于查找飛船祖先的函式find,在每次遞回找祖先的同時更新fa,壓縮路徑,大大減小以后的時間消耗,初始時對于每個fa[i]都賦值為i,合并時就先分別查找飛船i和飛船j的祖先,然后將飛船i的祖先的祖先(即fa[飛船i的祖先])賦值為飛船j的祖先,最后每次判斷時只需要找到飛船i和飛船j的祖先,判斷是否是同一艘飛船,若是,則在同一列,反之,則不在,
現在,判斷是否在同一列以及如何一次操作合并兩個佇列的問題已經解決,但還有問題需要解決:如何在以上方法的基礎上,進一步得到兩艘飛船之間的飛船數量呢?
我們先來分析一下:兩艘飛船之間的飛船數量,其實就是艘飛船之間的距離,那么,這就轉換為了一個求距離的問題,兩艘飛船都是在佇列里的,最簡單的求距離的方法就是前后一個一個查找,但這個方法太低效,會超時,看見多次求兩個點的距離的問題,便想到用前綴和來實作:開一個front陣列,front[i]表示飛船i到其所在佇列隊頭的距離,然后飛船i和飛船j之間的飛船數量即為它們到隊頭的距離之差減一,就是abs(front[i]-front[j])-1,
解決了如何高效得到兩艘飛船之間飛船數量的問題,便又發現了新的問題:如何在之前方法的基礎上,得到每艘飛船和隊頭的距離呢?
來分析一下現在已經使用的演算法——并查集,它的特點就是不是直接把一個佇列里的所有飛船移到另一個佇列后面,而是通過將要移動的佇列的隊頭連接到另一個佇列的隊頭上,從而間接連接兩個佇列,因此,我們在這個演算法的基礎上,每次只能更新一列中一艘飛船到隊頭的距離(如果更新多艘的話并查集就沒有意義了),
那么,該更新哪艘飛船呢?現在我們已經知道,使用并查集合并兩個佇列時只改變隊頭的祖先,而這個佇列里其它飛船的祖先還是它原來的隊頭,并沒有更新,所以這個佇列里的其它飛船在佇列合并之后,仍然可以找到它原來的隊頭,也就可以使用它原來隊頭的資料,因此,在每次合并的時候,只要更新合并前隊頭到目前隊頭的距離就可以了,之后其它的就可以利用它來算出自己到隊頭的距離,
理清了思路,但又有問題出現:該怎樣更新呢?該怎么計算呢?
更新很容易,我們來分析一下:對于原來的隊頭,它到隊頭的距離為0,當將它所在的佇列移到另一個佇列后面時,它到隊頭的距離就是排在它前面的飛船數,也就是合并前另一個佇列的飛船數量,因此,就知道該怎樣實作了,我們再建一個陣列num,num[i]表示以i為隊頭的佇列的飛船數量,初始時都是1,在每次合并的時候,fx為合并前飛船i的隊頭,fy為合并前飛船j的隊頭,每次合并時,先更新front[fx],即給它加上num[fy],然后開始合并,即fa[fx]=fy,最后更新num, num[fy]+= num[fx];num[fx]=0,
現在就差最后一步了:如何計算每個飛船到隊頭的距離,再來分析一下:對于任意一個飛船,我們都知道它的祖先(不一定是隊頭,但一定間接或直接指向隊頭),還知道距離它祖先的距離,對于每一個飛船,它到隊頭的距離,就等于它到它祖先的距離加上它祖先到隊頭的距離,而它的祖先到隊頭的距離,也可以變成類似的,可以遞回實作,由于每一次更新都要用到已經更新完成的祖先到隊頭的距離,所以要先遞回找到隊頭,然后在回溯的時候更新(front[i]+=front[fa[i]]),可以把這個程序和查找隊頭的函式放在一起,
#include <cstdio>
#include <iostream>
#include <cmath>
using namespace std;
const int N = 3e4 + 10;
int t, f[N], u, v, front[N], num[N];
char x;
int find(int x)
{
if(x == f[x]) return x;
int nx = find(f[x]);
front[x] += front[f[x]];
return f[x] = nx;
}
int main()
{
scanf("%d", &t);
for(int i = 1; i <= 30000; i++) f[i] = i, front[i] = 0, num[i] = 1;
while(t--)
{
cin>>x;
scanf("%d%d", &u, &v);
int fx = find(u), fy = find(v);
if(x == 'M')
{
front[fx] += num[fy];
f[fx] = fy;
num[fy] += num[fx];
num[fx] = 0;
}
else
{
if(fx!=fy) printf("-1\n");
else printf("%d\n", abs(front[u] - front[v]) - 1);
}
}
return 0;
}
例題四:食物鏈 link
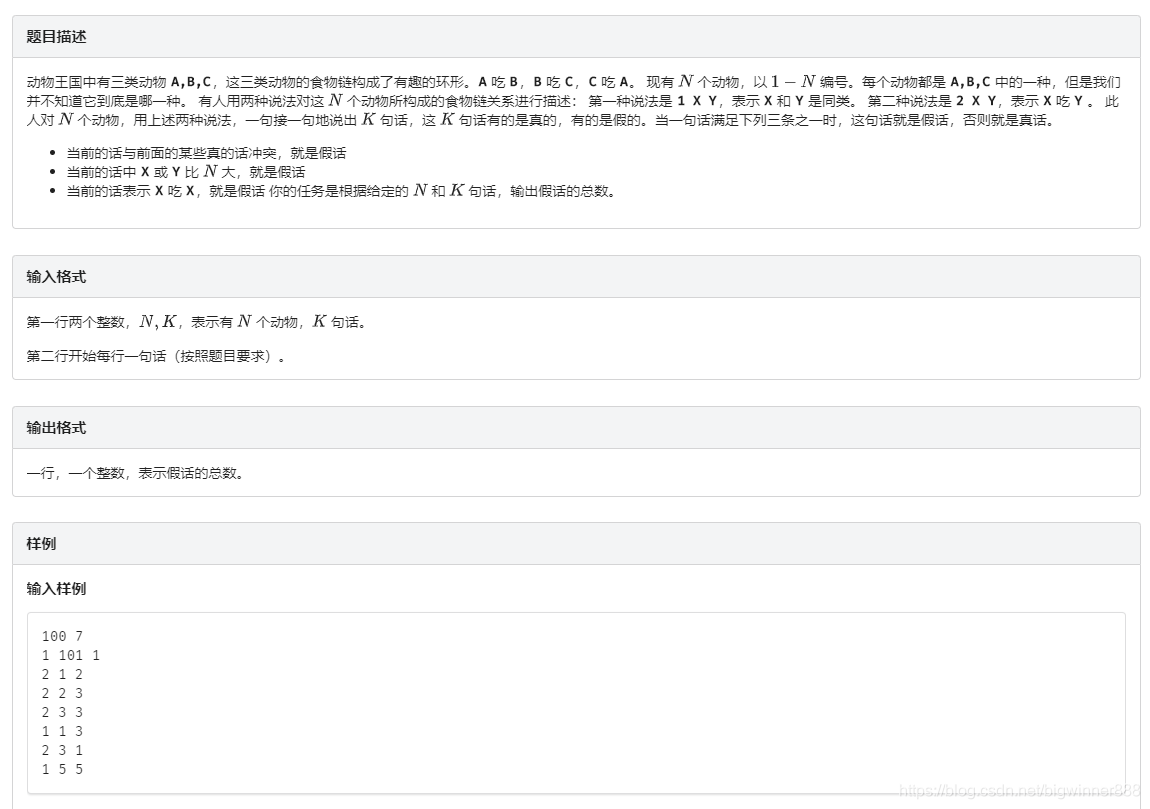
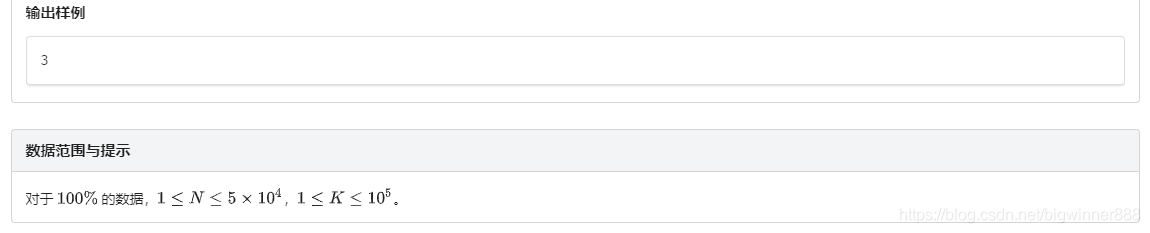
思路:
用3倍的并查集的存各種動物的關系
一倍存本身,二倍存獵物,三倍存天敵
唯一容易忽略的點就是:一的獵物的獵物 就是一的天敵
那么我們每次只要維護三個并查積的關系就可以了
#include <cstdio>
#include <iostream>
using namespace std;
const int N = 5e4 + 10;
int n, k, type, x, y, ans, f[N * 3];
int find(int x) {return x == f[x] ? x : f[x] = find(f[x]);}
int main()
{
scanf("%d%d", &n, &k);
for(int i = 1; i <= 3 * n; i++) f[i] = i;
for(int i = 1; i <= k; i++)
{
scanf("%d%d%d", &type, &x, &y);
if(x > n || y > n || (x == y && type == 2)) {ans++; continue;}
int fx = find(x), fy = find(y); //同類
int fx1 = find(x + n), fy1 = find(y + n); //獵物
int fx2 = find(x + n * 2), fy2 = find(y + n * 2); //天敵
if(type == 1)
{
if(fx1 == fy || fx2 == fy) {ans++; continue;};
f[fx] = fy, f[fx1] = fy1, f[fx2] = fy2;
}
if(type == 2)
{
if(fx == fy || fx2 == fy) {ans++; continue;}
f[fx] = fy2, f[fx1] = fy, f[fx2] = fy1;
}
}
printf("%d\n", ans);
return 0;
}
例題五:超市購物 link
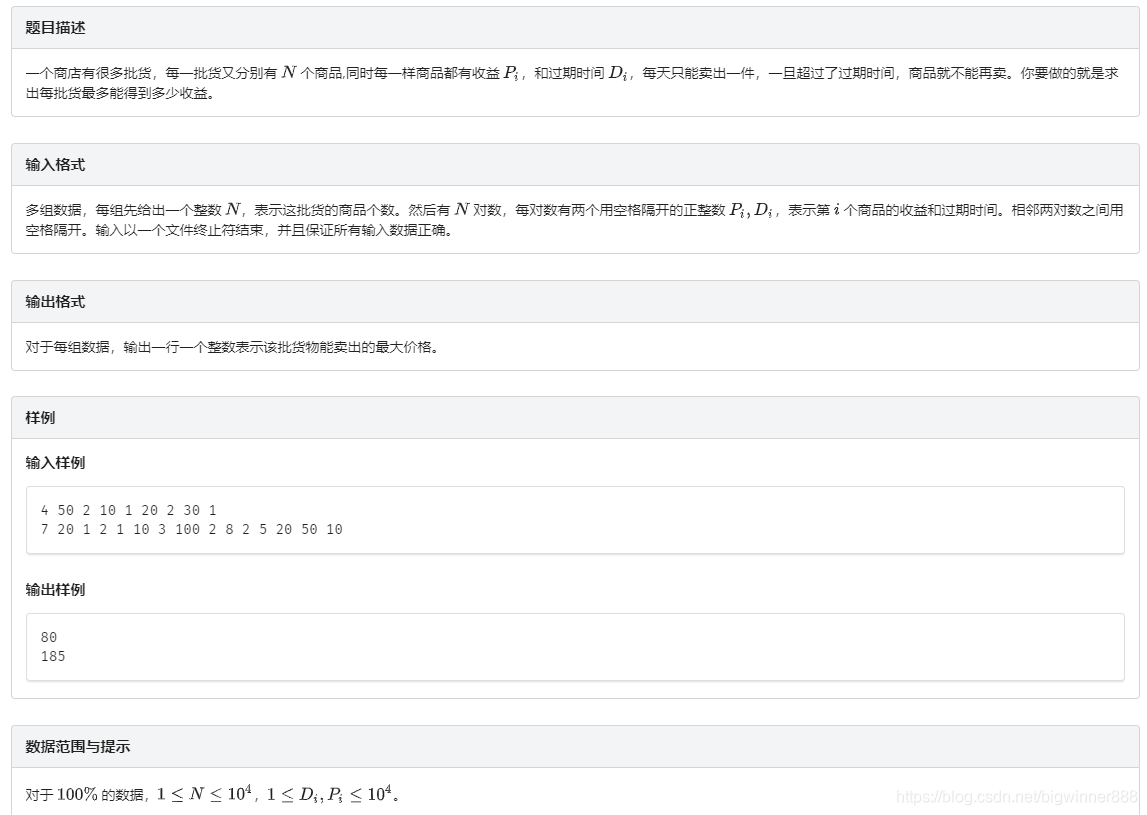
思路:
這道題可以用貪心配上并查集來做,
我們把商品按收益從大到小排序,然后一個一個列舉,
用過期時間來并查集,如果賣,
那么當前時間就不能賣其他的商品了,就只能在前一秒賣了,
#include <cstdio>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 1e4 + 10;
struct node {int p, d;} a[N];
int n, ans, f[N];
int find(int x) {return x == f[x] ? x : f[x] = find(f[x]);}
bool cmp(node a, node b) {return a.p > b.p;}
int main()
{
while(cin>>n)
{
ans = 0;
for(int i = 1; i <= 10000; i++) f[i] = i;
for(int i = 1; i <= n; i++) scanf("%d%d", &a[i].p, &a[i].d);
sort(a + 1, a + 1 + n, cmp);
for(int i = 1; i <= n; i++)
{
int fx = find(a[i].d);
if(fx)
{
ans += a[i].p;
f[fx] = fx - 1;
}
}
printf("%d\n", ans);
}
return 0;
}
例題六:逐個擊破 link

思路:
并查集做不到最小代價刪邊(貌似相似有個分治線段樹的東西),
根據容斥原理,用最小代價刪邊,
就等價于用最大代價建邊,那剩下的就是最小代價所要刪的邊,
現在我們來考慮一下怎么建邊,
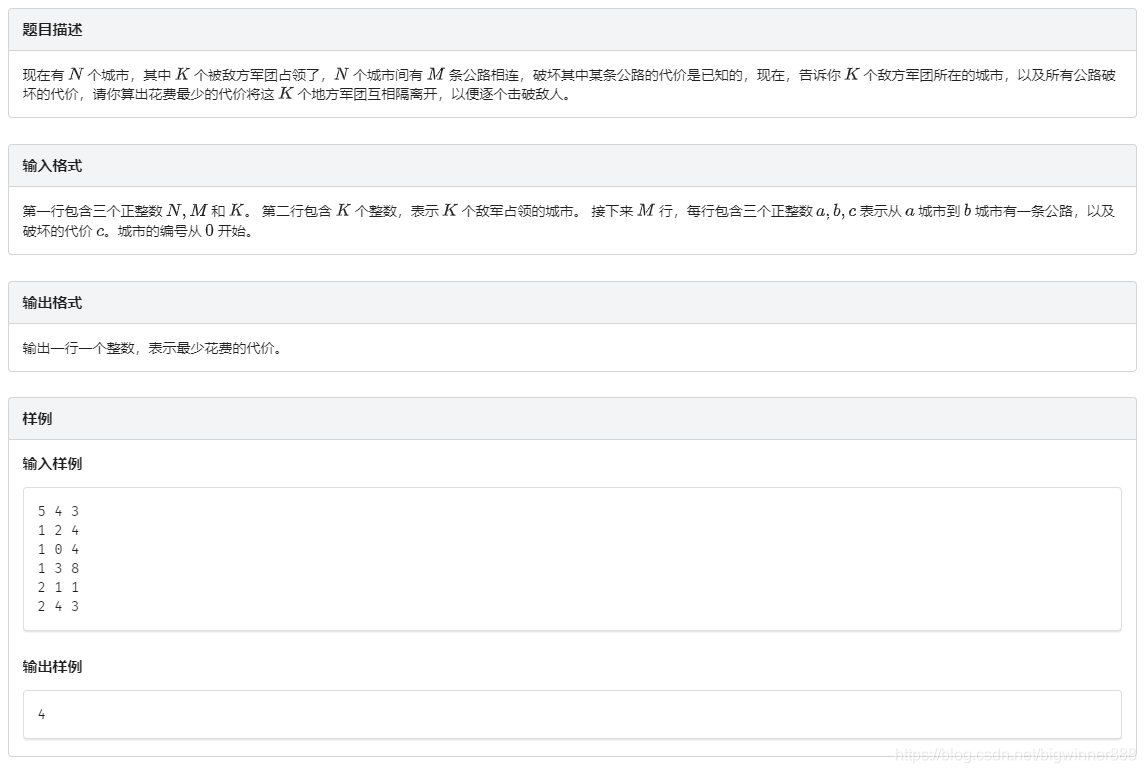
下面的圖中,紅色代表敵人節點,綠色代表我方節點.
顯然一定不會將兩個敵方軍團放在一個集合中,
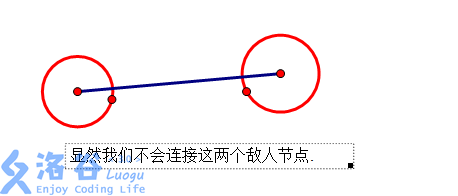
還有,如果我們已經將敵人包圍建出下面這樣的圖這時,還有一個敵人節點.↓
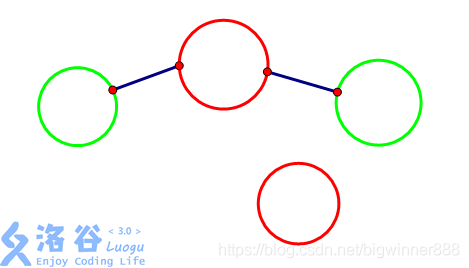
如果我們連接某一個我方節點,不連接敵方節點,那敵人也會互相連接(翻過屋后的山
所以說我們需要考慮一下如何解決這種情況.
如果,我方節點已經連接了敵方節點,則需要標記我方節點,
使得敵方節點無法通過我方節點連接敵方節點.
因此說,我們可以把連接到敵人節點的我方節點變成敵人節點.
從而使得其他敵人節點與其無法連接.
那我們上面的圖就變成這樣↓
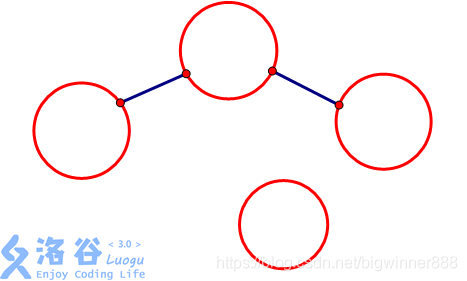
這樣我們的程式就可以實作我們所想了.
最后我們會將邊權大的邊加入到并查集中.
則最后沒有加入到并查集中的點,就會是被孤立的敵方節點.
所以我們把總邊權減去我們加入到圖中的邊權就是我們的ans啦!
#include <cstdio>
#include <iostream>
#include <algorithm>
#define ll long long
using namespace std;
const int N = 1e6 + 10;
struct node {ll u, v, w;} a[N];
ll n, m, k, ans, f[N];
bool flag[N];
bool cmp(node x, node y) {return x.w > y.w;}
ll find(ll x) {return x == f[x] ? x : f[x] = find(f[x]);}
int main()
{
scanf("%lld%lld%lld", &n, &m, &k);
for(ll i = 1; i <= n; i++) f[i] = i;
for(ll i = 1, x; i <= k; i++) scanf("%lld", &x), flag[x + 1] = 1;
for(ll i = 1; i <= m; i++)
{
scanf("%lld%lld%lld", &a[i].u, &a[i].v, &a[i].w);
a[i].u++, a[i].v++;
ans += a[i].w;
}
sort(a + 1, a + m + 1, cmp);
for(ll i = 1; i <= m; i++)
{
ll fx = find(a[i].u), fy = find(a[i].v);
if(fx == fy) ans -= a[i].w;
else if(!flag[fx] || !flag[fy])
{
ans -= a[i].w;
if(flag[fy]) f[fx] = fy;
else f[fy] = fx;
}
}
printf("%lld\n", ans);
return 0;
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/277436.html
標籤:其他
上一篇:運算子“++”和“- -”使用