近日,騰訊云和中國人民大學在資料庫基礎研究上有了進展,聚焦在“資料例外”領域,這是資料庫可串行化理論體系中的重要概念,
資料例外是打開并發訪問控制技術大門的金鑰匙,在資料庫行業中,以往只發現了10多種資料例外現象,但騰訊云TDSQL資料庫團隊對資料例外做了體系化研究,證明了資料例外是無窮多的,同時,開發出一款資料檢測工具,可以檢測識別出任何種類的資料例外,現已開源,GitHub地址為https://github.com/Tencent/3TS,據悉,目前這項基礎研究已經申請專利,并正在申報行業學術論文,
過去在資料庫基礎研究中,文獻討論的都是通過一個一個的資料例外案例(case by case)來進行討論、提出有限個數的例外,缺乏全域觀,并不利于認識資料例外,也不利于掌握并發訪問控制演算法,騰訊云資料庫的科學家們,將資料例外做了定義:并發事務的一個History中,如存在一個依據偏序對構成的有向環,則稱為資料例外,在定義了資料例外后,進一步據此簡明易懂地定義了事務的一致性:不存在資料例外則稱為資料符合一致性,
該基礎研究的核心意義在于,可探究到資料例外的本質和內在規律,并揭示出隔離級別和并發演算法的本質,使得基于該項基礎技術作業可進一步系統地研究各種并發訪問控制演算法、改進并發演算法,
這對于資料庫領域,屬于基礎的開創性作業,與傳統對的可串行化理論相對,該新方法具有諸多優勢,如下圖:
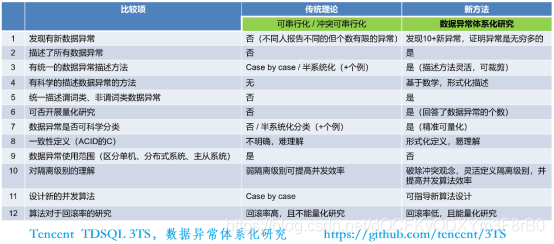
(騰訊云資料庫團隊TDSQL資料例外體系化研究方向及新理論應用)
作為三大基礎軟體之一,資料庫的安全可控和技術創新關乎國計民生,在國家大力發展新基建以及倡導走“更高水平的自力更生之路”背景下,加快實作新興國產資料庫的安全可控,
近年來,騰訊云資料庫的研究主要聚焦在資料庫核心基礎理論層面的研究與實踐,例如分布式一致性與事務性一致性融合的體系化的研究;再如事務性資料例外的體系化研究,重新對事務一致性做了定義等,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/277463.html
標籤:AI