HashMap的擴容機制
hashMap擴容:
擴容就是重新計算容量,向hashMap不停的添加元素,當hashMap無法裝載新的元素,物件將需要擴大陣列容量,以便裝入更多的元素,
haspMap擴容跟資料遷移具有很大的關聯,我們先用圖解的方式來說明資料遷移.
進行擴容前先介紹一些hahMap原始碼的變數
Node<K,V> loHead = null, loTail = null; //低位鏈表的頭尾結點
Node<K,V> hiHead = null, hiTail = null; //高位鏈表的頭尾結點
Node<K,V> next; //next指標 指向下一個元素
遷移前: 這里將其設定為長度為 8,擴容臨界點 8 * 0.75 = 6 主要是為了畫圖 (hashMap默認容量是16)
以下講解都是基于陣列容量為 8 講解的,流程都是一樣的.
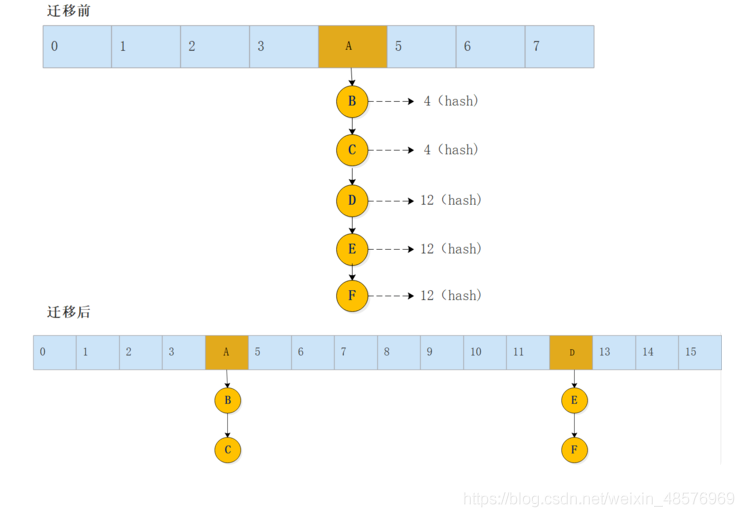
從圖可知,發生了擴容并且是2的次方,并且 A,B,C兩元素新的位置剛好是原陣列位置的索引位置,D,E,F剛好在原陣列位置索引 + 8 即原陣列位置索引+陣列容量,是不是真的是這樣呢??,這時需要看原始碼分析一波
流程講解
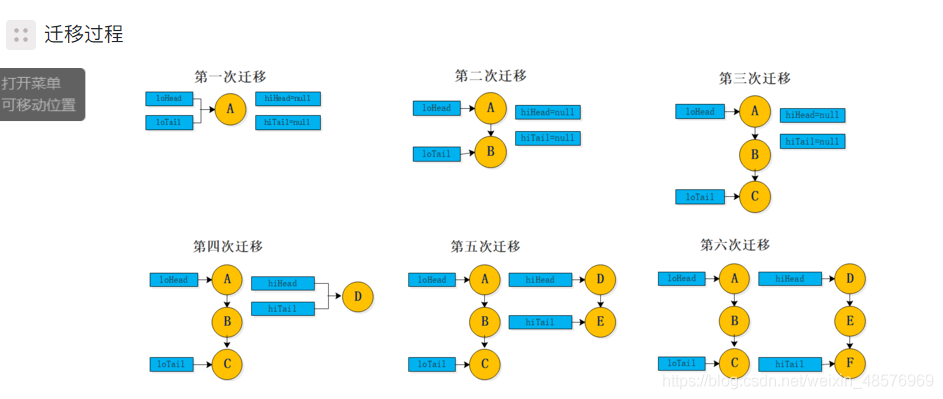
剛開始進行第一次擴容的時候,得到A的index索引為4,put進陣列中,hashMap先會將A的hash進行 & oldCap(8) 運算,判斷是否 ==0,如果為true,則代表為低位鏈表,這里涉及到二進制運算,比如A的index =4 (二進制 = 0000 0100) oldCap = 8(二進制=0000 1000) &運算之后 =0,后4位為低位,當然hash肯定不是8個bit位,hashCode得到索引值為int型別,一個int型別占4個位元組,一個位元組占8個bit位,所以hash二進制所占bit為 32,后4位為低位,高位遠遠多于低位,所以這也是put操作的時候需要將高位參與進來,減少hasp沖突,(這是put流程,put詳情操作請看我另一篇博客)
言歸正傳,當A進行判斷后,會將 loHead和loTail賦值給A,此時鏈表只有A元素,當回圈到第二次遷移后,也就是將B元素進行遷移 B進行 &運算之后,同樣為true,所以加入低位鏈表,而此時鏈表中有A元素,所以講A鏈表的尾結點.next指向B元素即可,同理C也是一樣,添加到B尾結點下面,直到添加完所有元素,當添加D元素時,因為D元素的hash為12, 進行 & 運算時為false ,則代表添加到高位鏈表,此時 hiHead和 hiTail指向D 之后流程都是一樣的,當結束回圈之后,低位鏈表的元素將會以原陣列下標索引添加到新陣列中,但是高位鏈表的元素會將原陣列的下標索引 + oldCap添加到新陣列,并且低位高位都會講原先的陣列設定為null ,方便gc
原始碼實體
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length; //陣列容量(舊)
int oldThr = threshold; //擴容臨界點(舊)
int newCap, newThr = 0; //陣列容量(新)、擴容臨界點(新)
if (oldCap > 0) {
//如果舊容量大于等于了最大的容量 2^30
if (oldCap >= MAXIMUM_CAPACITY) {
//將臨界值設定為Integer.MAX_VALUE
threshold = Integer.MAX_VALUE;
return oldTab;
}
//擴容2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // 新閾值設定2倍
}
else if (oldThr > 0) // HashMap(int initialCapacity, float loadFactor)呼叫
newCap = oldThr;
else { // 第一次put操作的時候,因為jdk1.8hashMap先添加元素再擴容
//建構式將jdk1.7的擴容移動到這
newCap = DEFAULT_INITIAL_CAPACITY; //默認容量 16
//臨界值 16 *0.75 =12
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {//如果新閾值為0,根據負載因子設定新閾值
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {如果舊的陣列中有資料,回圈
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null; //gc處理
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e; //只有一個節點,賦值,回傳
else if (e instanceof TreeNode) //判斷是否為紅黑樹結點
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null; //低位鏈表
Node<K,V> hiHead = null, hiTail = null; //高位鏈表
Node<K,V> next;
do {
next = e.next; //指向下個元素結點,做為while回圈的條件
if ((e.hash & oldCap) == 0) { //判斷是否為低位鏈表
if (loTail == null) //鏈表沒有元素,則將該元素作為頭結點
loHead = e;
else
loTail.next = e; //加在鏈表的下方
loTail = e;
}
else { {//不為0,元素位置在擴容后陣列中的位置發生了改變,新的下
//標位置是(原下標位置+原陣列長)
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
//遍歷完成后,進行資料遷移
if (loTail != null) {
//鏈表最后
loTail.next = null;
//將元素原位置遷移到新陣列中,位置一樣
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
//高位鏈表遷移 + 舊陣列容量
newTab[j + oldCap] = hiHead;
}
}
}
}
}
//回傳新陣列
return newTab;
}
總結(擴容與遷移):
1、擴容就是將舊表的資料遷移到新表
2、遷移過去的值需要重新計算hashCode,也就是他的存盤位置
3、關于位置可以這樣理解:比如舊表的長度8、新表長度16
舊表位置4有6個資料,假如前三個hashCode是一樣的,后面的三個hashCode是一樣的遷移的時候;就需要計算這6個值的存盤位置
4、如何計算位置?采用低位鏈表和高位鏈表;如果位置4下面的資料e.hash & oldCap等于0,那么它對應的就是低位鏈表,也就是資料位置不變,e.hash & oldCap不等于0呢?就要重寫計算他的位置也就是j + oldCap(4+8);這個12,就是高位鏈表位置(新陣列12位置)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/277469.html
標籤:其他