正則運算式
1.限定符
? 1)?:表示前面一個字母出現了0次或一次,
? 例如:ab?c=ac/abc
? 2)*:表示前面一個字母出現了0次或多次 ,
? 例如:ab * c=ac/abc/abbbbbbc
? 3)+:表示前面一個字母出現了一次或多次,
? 例如:ab+c=abc/abbbbbbc
? 4){x}
? (1){6}:使前面一個字母出現六次,
? 例如:ab{6}c=abbbbbbc
? (2){2,6}:使前面的一個字母出現兩次到六次,
? 例如:ab{2,6}c=abbc/abbbbc/abbbbbbc
? (3){2,}:使前面的一個字母出現兩次以上,
? 例如:ab{2,}c=abbc/abbbbbbc/abbbbbbbbbc
? 4)倘若要同時匹配多個字符,可以在需要匹配的字符旁加上“()”
2.“或”運算子
? X (XX|XX):先匹配前面的“X”,后面括號中的內容表示要么是cat,要么是dog
? 例如:a (cat|dog)=a cat / a dog
3.字符類
? [XXX]+:匹配由“XXX”這幾個字母構成的單詞,方括號里的內容代表要求匹配的字符只能取自于它們
? 1)[a-z]:匹配所有小寫英文字符
? 2)[a-zA-Z]:匹配所有英文字符
? 3)[0-9]:匹配所有數字
? 4)[ ^XXX ]:匹配除了“ ^ ”后面列出的以外的字符
? 例如:[ ^ 0-9 ]=所有非數字字符(包括換行符)
4.元字符
? 1.\d:代表所有的數字字符
? 2.\w:代表所有的英文、數字及下劃線
? 3.\s:代表空白符(包含Tab和換行符)
? 4.\D:代表非數字字符
? 5.\W:代表非單詞字符
? 6.\S:代表非空白字符
? 7. ,:代表任意字符,但不包括換行符
? 8.^ :匹配行首
? 例如:^a只會匹配行首的a
? 9.$ :匹配行尾
? 例如:$a只會匹配行尾的a
5.貪婪與非貪婪匹配
1)什么是貪婪與非貪婪匹配
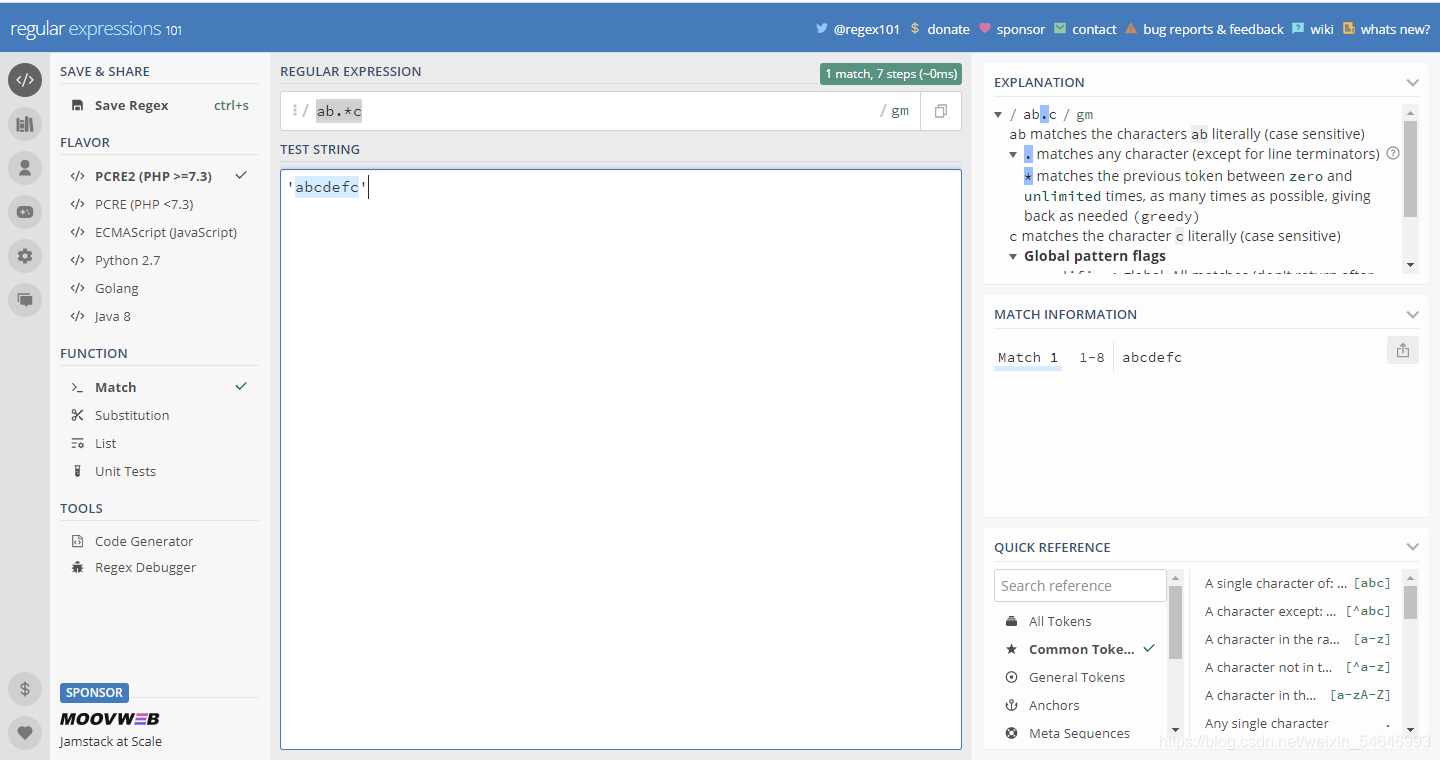
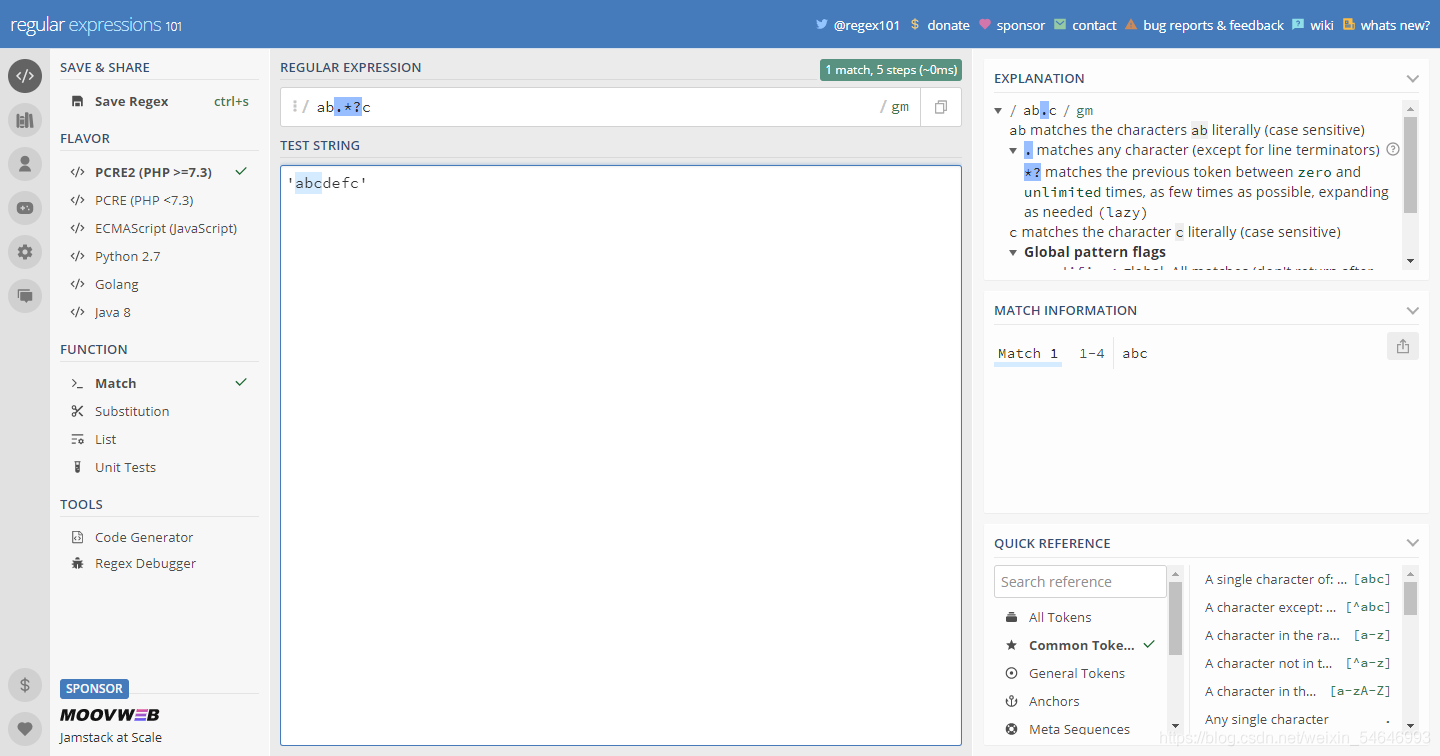
? 例子:’abcdefc‘
? 貪婪匹配:一般趨向于最大長度匹配,也就是所謂的貪婪匹配,如上例,結果就是匹配到:abcaxc(*ab.c),
? **非貪婪匹配:**匹配到的結果字符越短,就選哪一個,這就是所謂的非貪婪匹配,如上例,結果就是匹配到:abc(ab.*?c),
2)編程中如何區分兩種模式
? 默認是貪婪模式,在量詞后面直接加上一個問號?就是非貪婪模式,
我們熟知的量詞有:
| 符號 | 含義 |
|---|---|
| * | 任意多個 |
| + | 至少一個 |
| ? | 0或1個 |
| {m,n} | m到n個 |
3)實體

?
? 嘗試匹配HTML標簽,運用
<.+>
? 進行嘗試
? 結果
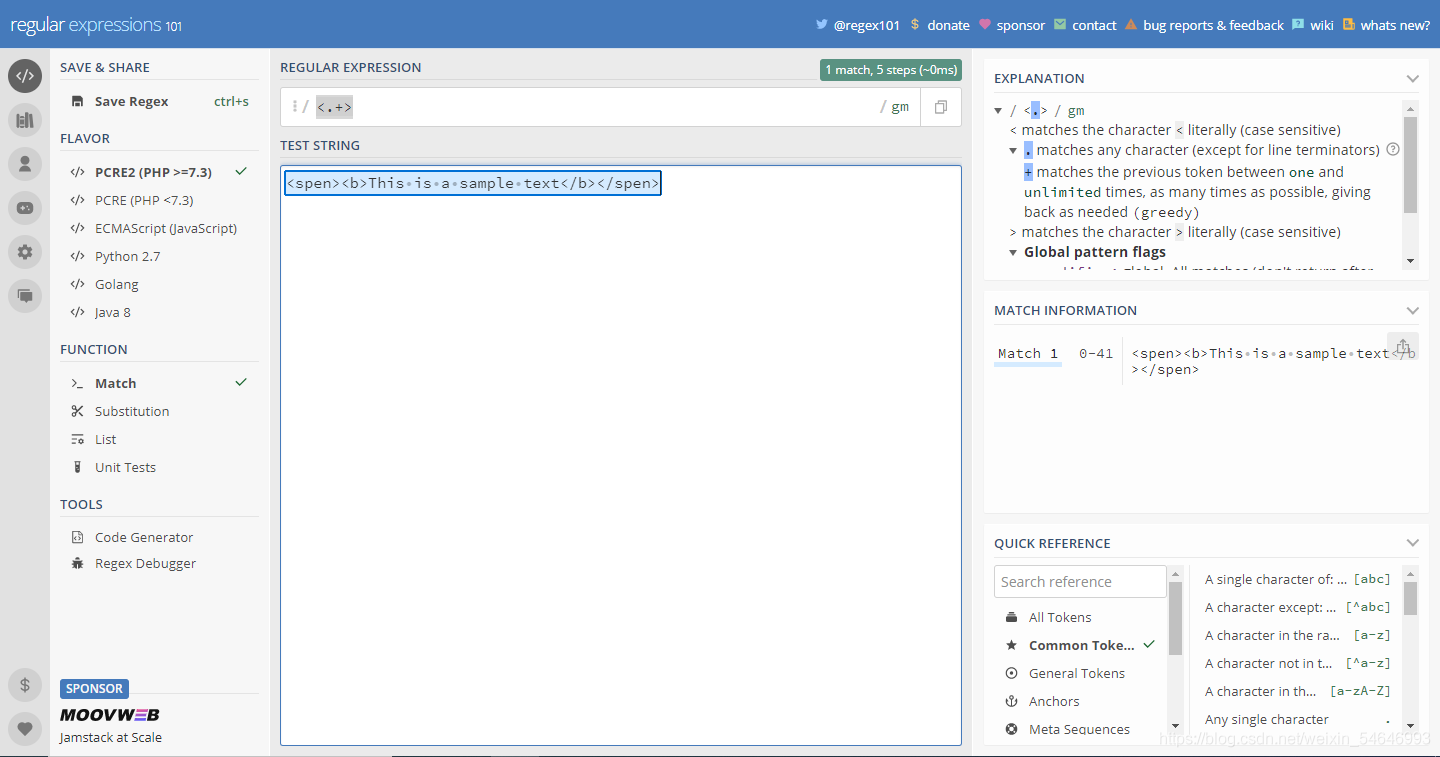
? 不成功,估計需要用到非貪婪匹配
? 就嘗試在**+后加上一個?**
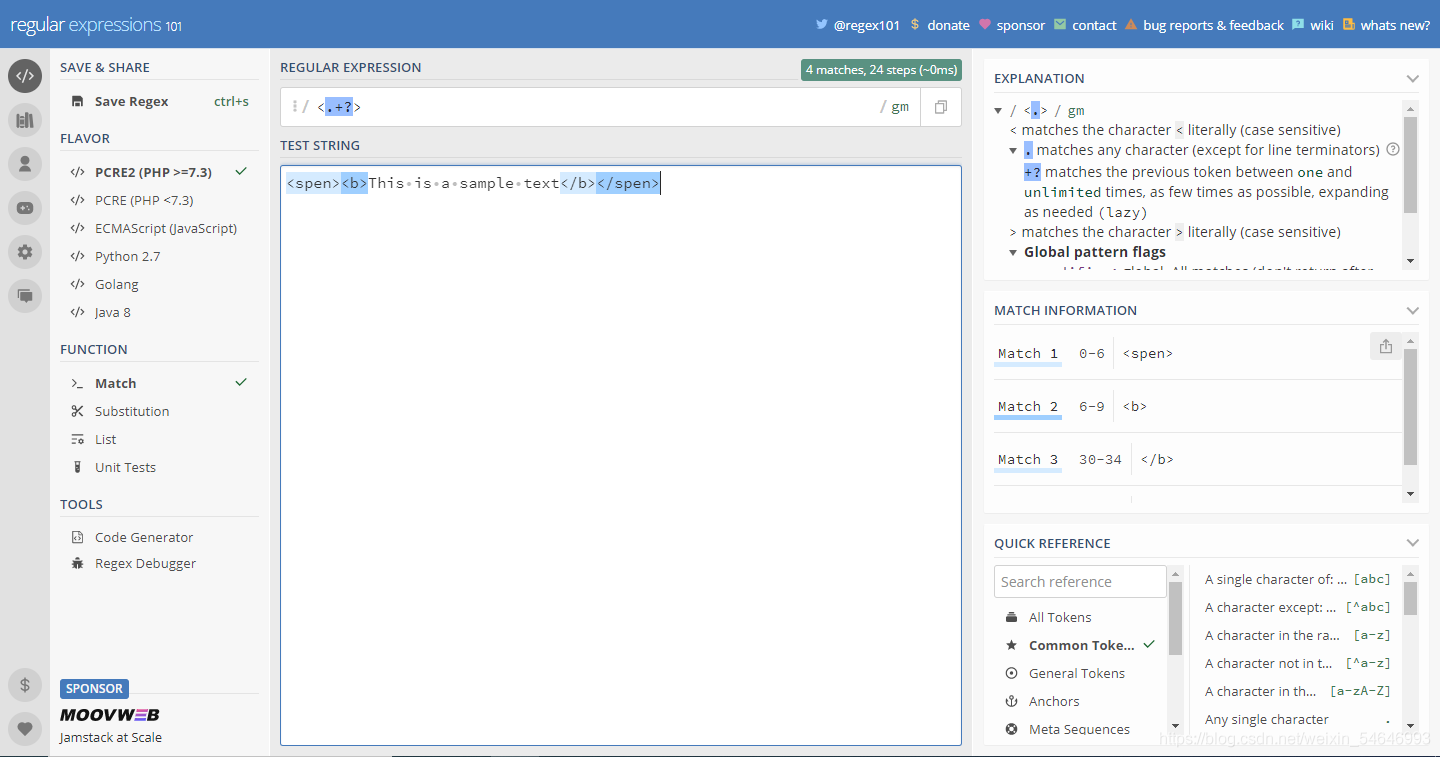
? 成功
6.總結
? 目前我現在就學了這么多,如有問題,還望莫怪,
本文參考文章和視頻:
視頻:https://www.bilibili.com/video/BV1da4y1p7iZ?share_source=copy_web
文章:https://blog.csdn.net/m0_37673307/article/details/81631880?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522161864958216780269826861%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=161864958216780269826861&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduend~default-3-81631880.first_rank_v2_pc_rank_v29&utm_term=%E6%AD%A3%E5%88%99%E8%A1%A8%E8%BE%BE%E5%BC%8F%E8%B4%AA%E5%A9%AA
本文運用的正則運算式網址為:https://regex101.com/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/277490.html
標籤:其他
上一篇:Docker——使用Git來實作Jenkins發布、測驗專案
下一篇:ELK7.12.0環境搭建教程