面試必會演算法(1):排序演算法
面試必會演算法系列之排序演算法
前文推薦:
【著作權申明】未經博主同意,謝絕轉載!(請尊重原創,博主保留追究權);
本博客的內容來自于;面試必會演算法(1):排序演算法
學習、合作與交流聯系q384660495;
本博客的內容僅供學習與參考,并非營利;
文章目錄
- 面試必會演算法(1):排序演算法
- 一、排序演算法綜述
- 1、概念
- 2、分類
- 3、演算法比較
- 二、冒泡排序
- 1、基本思想
- 2、演算法描述
- 3、動圖演示
- 4、演算法分析
- 4、代碼實作
- 三、選擇排序
- 1、基本思想
- 2、演算法描述
- 3、動圖演示
- 4、演算法分析
- 5、代碼實作
- 四、插入排序
- 1、基本思想
- 2、演算法描述
- 3、動圖演示
- 4、演算法分析
- 5、代碼實作
- 五、希爾排序
- 1、基本思想
- 2、演算法描述
- 3、動圖演示
- 4、演算法分析
- 5、代碼實作
- 六、歸并排序
- 1、基本思想
- 2、演算法描述
- 3、動圖演示
- 4、演算法分析
- 5、代碼實作
- 七、快速排序
- 1、基本思想
- 2、演算法描述
- 3、動圖演示
- 4、演算法分析
- 5、代碼實作
- 八、堆排序
- 1、基本思想
- 2、演算法描述
- 3、動圖演示
- 4、演算法分析
- 5、代碼實作
- 九、計數排序
- 1、基本思想
- 2、演算法描述
- 3、動圖演示
- 4、演算法分析
- 5、代碼實作
- 十、桶排序
- 1、基本思想
- 2、演算法描述
- 3、動圖演示
- 4、演算法分析
- 5、代碼實作
- 十一、基數排序
- 1、基本思想
- 2、演算法描述
- 3、動圖演示
- 4、演算法分析
- 5、代碼實作
- 總結
- 參考資料
一、排序演算法綜述
1、概念
將雜亂無章的資料元素,通過一定的方法按關鍵字順序排列的程序叫做排序,
2、分類
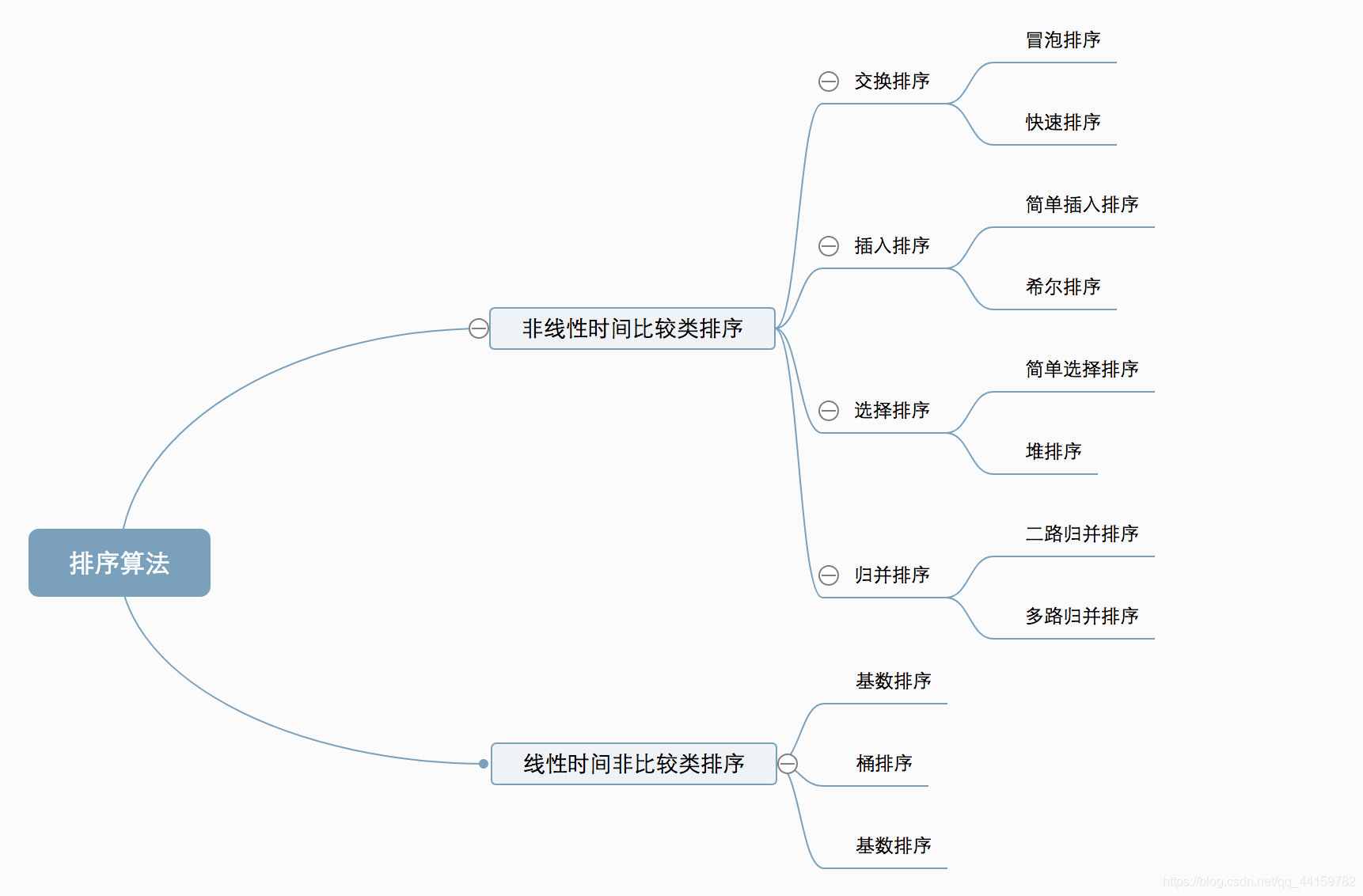
十種常見排序演算法可以分為兩大類:
非線性時間比較類排序:通過比較來決定元素間的相對次序,由于其時間復雜度不能突破O(nlogn),因此稱為非線性時間比較類排序,
線性時間非比較類排序:不通過比較來決定元素間的相對次序,它可以突破基于比較排序的時間下界,以線性時間運行,因此稱為線性時間非比較類排序,
3、演算法比較
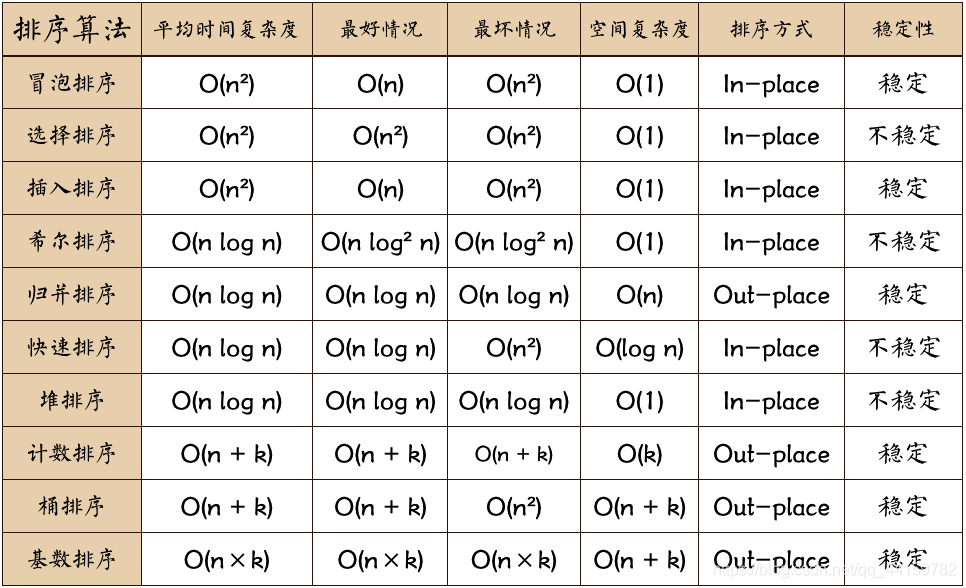
穩定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面,
不穩定:如果a原本在b的前面,而a=b,排序之后 a 可能會出現在 b 的后面,
時間復雜度:對排序資料的總的操作次數,反映當n變化時,操作次數呈現什么規律,
空間復雜度:是指演算法在計算機內執行時所需存盤空間的度量,它也是資料規模n的函式,
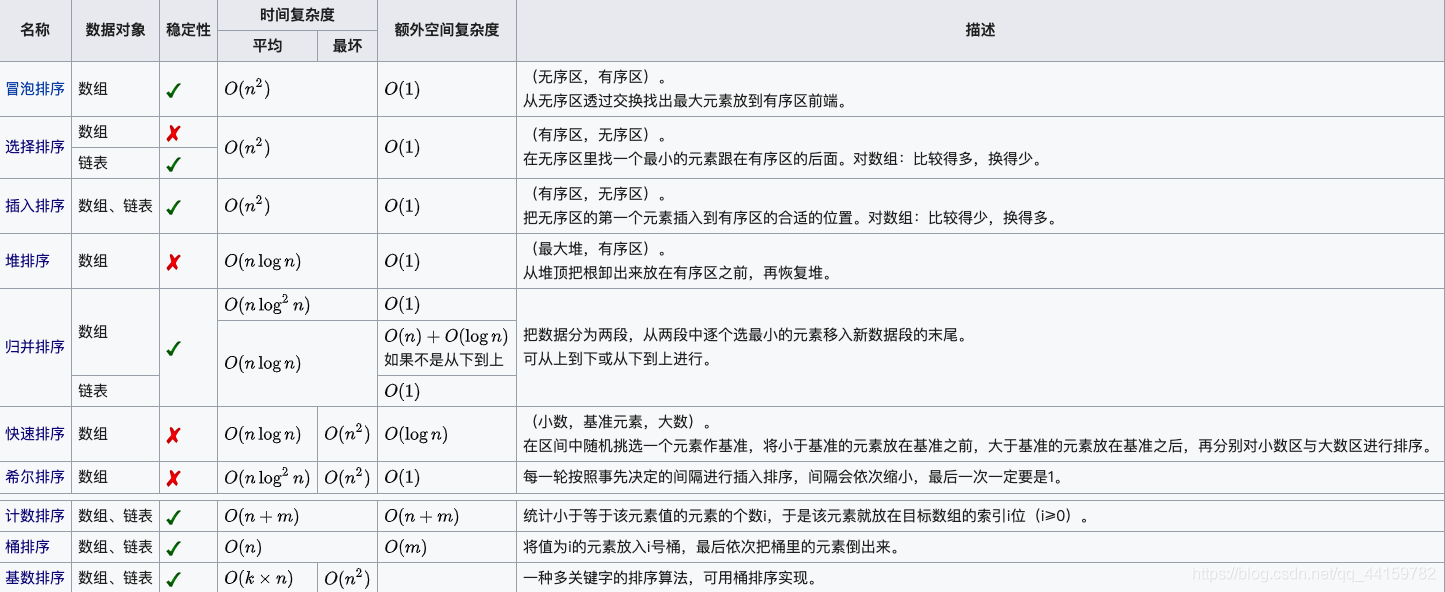
n:資料規模
k:"桶"的個數
In-place:占用常數記憶體,不占用額外記憶體
Out-place:占用額外記憶體
穩定性:排序后 2 個相等鍵值的順序和排序之前它們的順序相同
- 平方階 (O(n2)) 排序 各類簡單排序:直接插入、直接選擇和冒泡排序,
- 線性對數階 (O(nlog2n)) 排序 快速排序、堆排序和歸并排序;
- O(n1+§)) 排序,§ 是介于 0 和 1 之間的常數, 希爾排序
- 線性階 (O(n)) 排序 基數排序,此外還有桶、箱排序,
內部排序:若整個排序程序不需要訪問外存便能完成,則稱此類排序問題為內部排序,
外部排序:若參加排序的記錄數量很大,整個序列的排序程序不可能在記憶體中完成,則稱此類排序問題為外部排序,
就地排序:若排序演算法所需的輔助空間并不依賴于問題的規模n,即輔助空間為O(1),稱為就地排序,
穩定排序: 假定在待排序的記錄序列中,存在多個具有相同的關鍵字的記錄,若經過排序后,這些記錄的相對次序保持不變,即在原序列中 ri=rj, ri 在rj 之前,而在排序后的序列中,ri 仍在 rj 之前,則稱這種排序演算法是穩定的;否則稱為不穩定的
二、冒泡排序
1、基本思想
基本思想: 冒泡排序,類似于水中冒泡,較大的數沉下去,較小的數慢慢冒起來,假設從小到大,即為較大的數慢慢往后排,較小的數慢慢往前排,
直觀表達,每一趟遍歷,將一個最大的數移到序列末尾,
2、演算法描述
依次比較相鄰的兩個數,將比較小的數放在前面,比較大的數放在后面,
(1)第一次比較:首先比較第一和第二個數,將小數放在前面,將大數放在后面,
(2)比較第2和第3個數,將小數放在前面,大數放在后面,
…
(3)如此繼續,知道比較到最后的兩個數,將小數放在前面,大數放在后面,重復步驟,直至全部排序完成
(4)在上面一趟比較完成后,最后一個數一定是陣列中最大的一個數,所以在比較第二趟的時候,最后一個數是不參加比較的,
(5)在第二趟比較完成后,倒數第二個數也一定是陣列中倒數第二大數,所以在第三趟的比較中,最后兩個數是不參與比較的,
(6)依次類推,每一趟比較次數減少依次
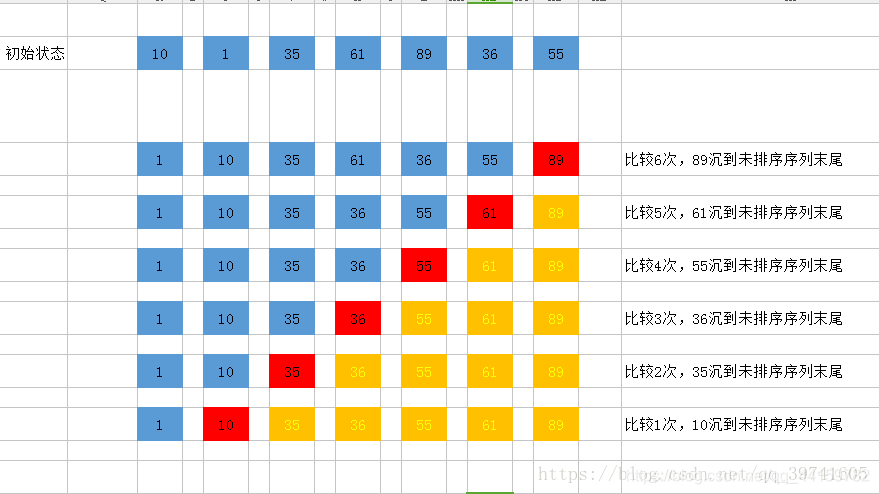
(1)要排序陣列:[10,1,35,61,89,36,55]
(2)第一趟排序:
第一次排序:10和1比較,10大于1,交換位置 [1,10,35,61,89,36,55]
第二趟排序:10和35比較,10小于35,不交換位置 [1,10,35,61,89,36,55]
第三趟排序:35和61比較,35小于61,不交換位置 [1,10,35,61,89,36,55]
第四趟排序:61和89比較,61小于89,不交換位置 [1,10,35,61,89,36,55]
第五趟排序:89和36比較,89大于36,交換位置 [1,10,35,61,36,89,55]
第六趟排序:89和55比較,89大于55,交換位置 [1,10,35,61,36,55,89]
第一趟總共進行了六次比較,排序結果:[1,10,35,61,36,55,89]
(3)第二趟排序:
第一次排序:1和10比較,1小于10,不交換位置 1,10,35,61,36,55,89
第二次排序:10和35比較,10小于35,不交換位置 1,10,35,61,36,55,89
第三次排序:35和61比較,35小于61,不交換位置 1,10,35,61,36,55,89
第四次排序:61和36比較,61大于36,交換位置 1,10,35,36,61,55,89
第五次排序:61和55比較,61大于55,交換位置 1,10,35,36,55,61,89
第二趟總共進行了5次比較,排序結果:1,10,35,36,55,61,89
(4)第三趟排序:
1和10比較,1小于10,不交換位置 1,10,35,36,55,61,89
第二次排序:10和35比較,10小于35,不交換位置 1,10,35,36,55,61,89
第三次排序:35和36比較,35小于36,不交換位置 1,10,35,36,55,61,89
第四次排序:36和61比較,36小于61,不交換位置 1,10,35,36,55,61,89
第三趟總共進行了4次比較,排序結果:1,10,35,36,55,61,89
到目前位置已經為有序的情形了
3、動圖演示
4、演算法分析
(1)冒泡排序的優點:每進行一趟排序,就會少比較一次,因為每進行一趟排序都會找出一個較大值,如上例:第一趟比較之后,排在最后的一個數一定是最大的一個數,第二趟排序的時候,只需要比較除了最后一個數以外的其他的數,同樣也能找出一個最大的數排在參與第二趟比較的數后面,第三趟比較的時候,只需要比較除了最后兩個數以外的其他的數,以此類推……也就是說,沒進行一趟比較,每一趟少比較一次,一定程度上減少了演算法的量,
(3)時間復雜度
1.如果我們的資料正序,只需要走一趟即可完成排序,所需的比較次數C和記錄移動次數M均達到最小值,即:Cmin=n-1;Mmin=0;所以,冒泡排序最好的時間復雜度為O(n),
2.如果很不幸我們的資料是反序的,則需要進行n-1趟排序,每趟排序要進行n-i次比較(1≤i≤n-1),且每次比較都必須移動位置,在這種情況下,比較和移動次數均達到最大值:
4、代碼實作
public static void main(String[] args) {
int[] array = new int[]{1,2,5,2,1,2,3,4,5,1};
array = bubbleSort(array);
System.out.println("Arrays.toString(array) = " + Arrays.toString(array));
}
public static int[] bubbleSort(int[] array){
//一定要記住判斷邊界條件,很多人不注意這些細節,面試官看到你的代碼的時候都懶得往下看,
if(arr == null || arr.length < 2){
return array;
}
for(int i = 0; i < array.length; i++){
for(int j = 0; j < array.length - 1 - i; j++){//這邊減1是防止陣列越界
if(array[j] > array[j+1]){
int temp = array[j+1];
array[j+1] = array[j];
array[j] = temp;
}
}
}
return array;
}
還可以對冒泡排序進行優化,詳細可參考冒泡排序的三種優化,冒泡排序的三種優化
public static int[] bubbleSort(int[] array){
//一定要記住判斷邊界條件,很多人不注意這些細節,面試官看到你的代碼的時候都懶得往下看,你的代碼哪個專案敢往里面加?
if(array == null || array.length < 2){
return array;
}
for(int i = 0; i < array.length-1; i++){
int flag = 1;
for(int j = 0; j < array.length - 1 - i; j++){
if(array[j] > array[j+1]){
int temp = array[j+1];
array[j+1] = array[j];
array[j] = temp;
flag =0;
}
}
if(flag == 1){
return array;
}
}
return array;
}
三、選擇排序
1、基本思想
選擇排序(Selection-sort)是一種簡單直觀的排序演算法,它的作業原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再從剩余未排序元素中繼續尋找最小(大)元素,然后放到已排序序列的末尾,以此類推,直到所有元素均排序完畢,
2、演算法描述
n個記錄的直接選擇排序可經過n-1趟直接選擇排序得到有序結果,具體演算法描述如下:
初始狀態:無序區為R[1…n],有序區為空;
第i趟排序(i=1,2,3…n-1)開始時,當前有序區和無序區分別為R[1…i-1]和R(i…n),該趟排序從當前無序區中-選出關鍵字最小的記錄 R[k],將它與無序區的第1個記錄R交換,使R[1…i]和R[i+1…n)分別變為記錄個數增加1個的新有序區和記錄個數減少1個的新無序區;
n-1趟結束,陣列有序化了
3、動圖演示
4、演算法分析
- 復雜度
時間復雜度:O(n^2)
空間復雜度:O(1),在原陣列空間內操作,需要的額外空間是指標空間
- 穩定性
不穩定:
如果待排序列中有兩個相同的數a、b,最右邊的數b的右邊所有的數都比ab大,則不會出現不穩定情況,如[3, 2-a, 2-b, 4, 5],第一次交換后[2-a, 3, 2-b, 4, 5],第二次交換后[2-a, 2-b, 3, 4, 5],最終結果a和b保持原來的相對順序,
如果待排序列中的兩個相同數a、b,最右邊的數b的右邊的所有數中有比ab小的數,在一次交換中可能會將a交換到b的右邊,比如[3, 5-a, 7, 5-b, 2],第二次交換后[2, 3, 7, 5-b, 5-a],最終結果[2, 3, 5-b, 5-a, 7],a和b不能保持原來的相對順序,
5、代碼實作
public static int[] selectionSort(int[] array){
if(array == null || array.length<2){
return array;
}
for(int i = 0; i < array.length-1; i++){
int index = i;
for(int j = i+1; j<array.length; j++){
if(array[j] < array[i]){
index = j;
}
}
if(index != i) {
int temp = array[i];
array[i] = array[index];
array[index] = temp;
}
}
return array;
}
還可以對選擇排序進行優化,即每次查找不僅找出最小值,還找出最大值,分別插到前面和后面,可以減少一半的查詢時間選擇排序優化,選擇排序優化
四、插入排序
1、基本思想
插入排序(Insertion-Sort)的演算法描述是一種簡單直觀的排序演算法,它的作業原理是通過構建有序序列,對于未排序資料,在已排序序列中從后向前掃描,找到相應位置并插入,
2、演算法描述
從第一個元素開始,該元素可以認為已經被排序;
取出下一個元素,在已經排序的元素序列中從后向前掃描;
如果該元素(已排序)大于新元素,將該元素移到下一位置;
重復步驟3,直到找到已排序的元素小于或者等于新元素的位置;
將新元素插入到該位置后;
重復步驟2~5,
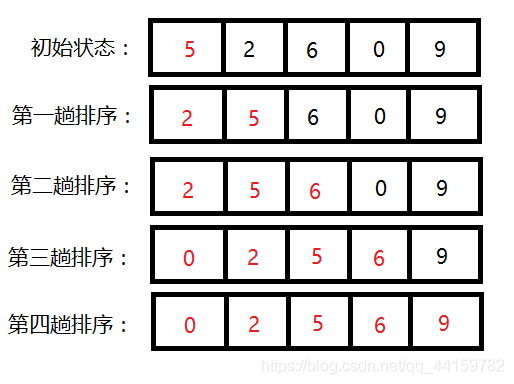
程序:
初始狀態:設5為有序,其中i為1,即:5 2 0 6 9
第一趟排序:第i個元素2比5小,則插入到5前面,然后i自增,即 : 2 5 0 6 9
第二趟排序:第i個元素0比2,5小,則插入到2前面,然后i自增,即:0 2 5 6 9
第三趟排序:第i個元素6比5大,則插入到5后面,然后i自增,即:0 2 5 6 9
第四趟排序:第i個元素9比6大,則插入到6后面,然后i自增,即:0 2 5 6 9
最終的答案為:0 2 5 6 9
3、動圖演示
4、演算法分析
1.在最好情況下,嚴格遞增的陣列,比較次數C和移動次數M為:
C = n - 1
M = 0
時間復雜度為O(n),
2.在最壞情況下,嚴格遞減的陣列,比較次數C和移動次數M為:
C = n(n-1)/2
M = n(n-1)/2
時間復雜度為O(n2),
綜上,時間復雜度為:O(n2) ,
優缺點:
優點 : 穩定,相對于冒泡排序與選擇排序更快;
缺點 : 比較次數不一定,比較次數越少,插入點后的資料移動越多,特別是當資料總量大的時候;
5、代碼實作
public static int[] insertionSort(int[] array) {
if (array == null || array.length < 2) {
return array;
}
for (int i = 1; i < array.length; i++) {
int current = array[i];
int preIndex = i - 1;
for (; preIndex >= 0; preIndex--) {
if (current < array[preIndex]) {
array[preIndex + 1] = array[preIndex];
}else{
break;
}
}
array[preIndex + 1] = current;
}
return array;
}
插入排序的優化方式可以參考插入排序優化方法
有興趣的朋友可以了解一下為什么插入排序比冒泡排序更歡迎
五、希爾排序
1、基本思想
希爾排序是把記錄按下標的一定增量分組,對每組使用直接插入排序演算法排序;隨著增量逐漸減少,每組包含的關鍵詞越來越多,當增量減至1時,整個檔案恰被分成一組,演算法便終止,
2、演算法描述
先將整個待排序的記錄序列分割成為若干子序列分別進行直接插入排序,具體演算法描述:
選擇一個增量序列t1,t2,…,tk,其中ti>tj,tk=1;
按增量序列個數k,對序列進行k 趟排序;
每趟排序,根據對應的增量ti,將待排序列分割成若干長度為m 的子序列,分別對各子表進行直接插入排序,僅增量因子為1 時,整個序列作為一個表來處理,表長度即為整個序列的長度,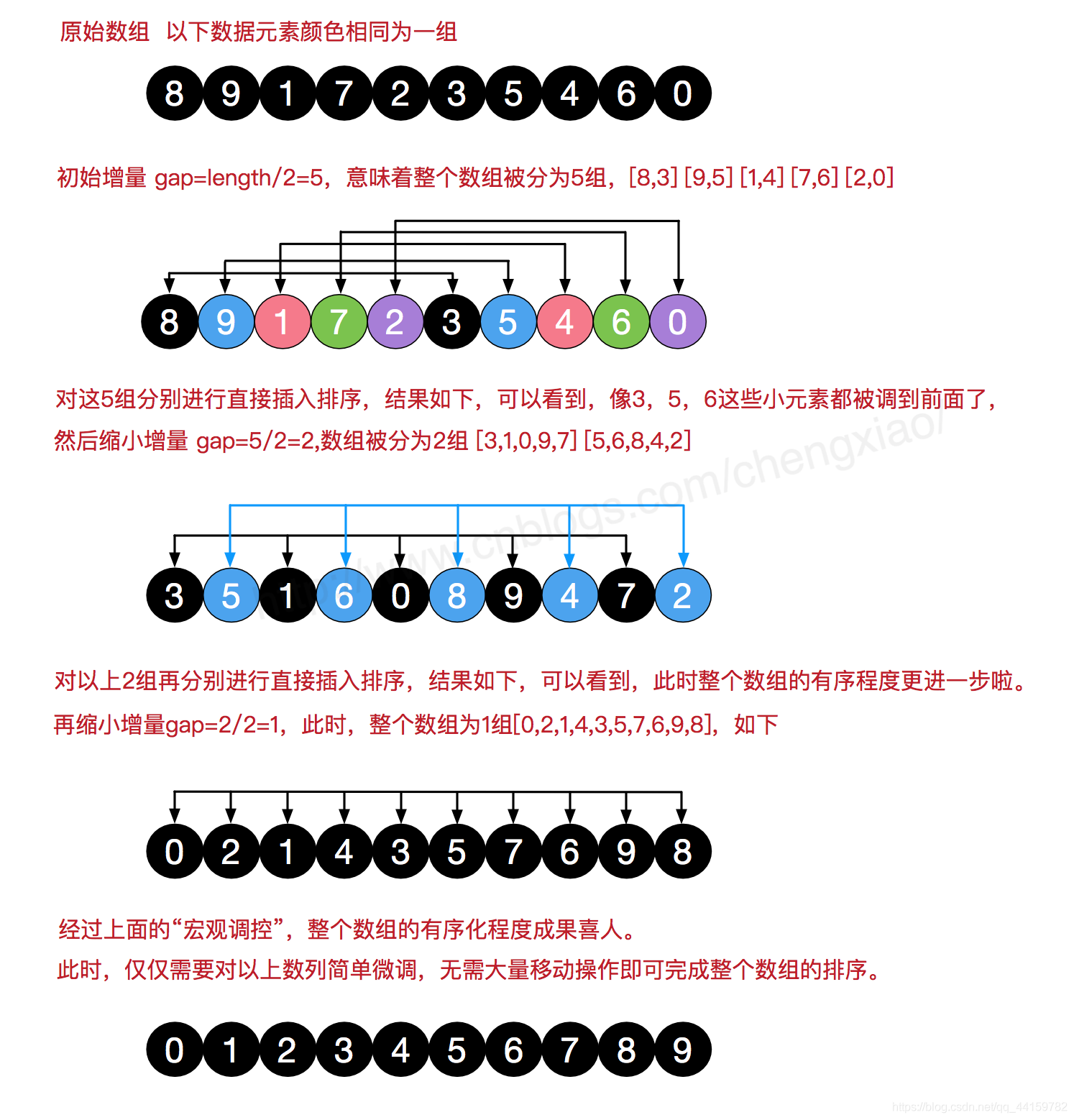
3、動圖演示
4、演算法分析
希爾排序的核心在于間隔序列的設定,既可以提前設定好間隔序列,也可以動態的定義間隔序列,
while (gap < len / 3) { // 動態定義間隔序列
gap = gap * 3 + 1;
}
5、代碼實作
public static int[] shellSort(int[] array){
if(array == null || array.length < 2){
return array;
}
int temp;
int gap = array.length/2;
while(gap > 0){
for(int i = gap; i < array.length; i++){
temp = array[i];
int preIndex = i - gap;
while(preIndex >= 0 && array[preIndex] > temp){
array[preIndex + gap] = array[preIndex];
preIndex -= gap;
}
array[preIndex + gap] = temp;
}
gap /= 2;
}
return array;
}
希爾排序的優化方法可以參考希爾排序優化方法
六、歸并排序
1、基本思想
歸并排序是建立在歸并操作上的一種有效的排序演算法,該演算法是采用分治法(Divide and Conquer)的一個非常典型的應用,將已有序的子序列合并,得到完全有序的序列;即先使每個子序列有序,再使子序列段間有序,若將兩個有序表合并成一個有序表,稱為2-路歸并
2、演算法描述
把長度為n的輸入序列分成兩個長度為n/2的子序列;
對這兩個子序列分別采用歸并排序;
將兩個排序好的子序列合并成一個最終的排序序列
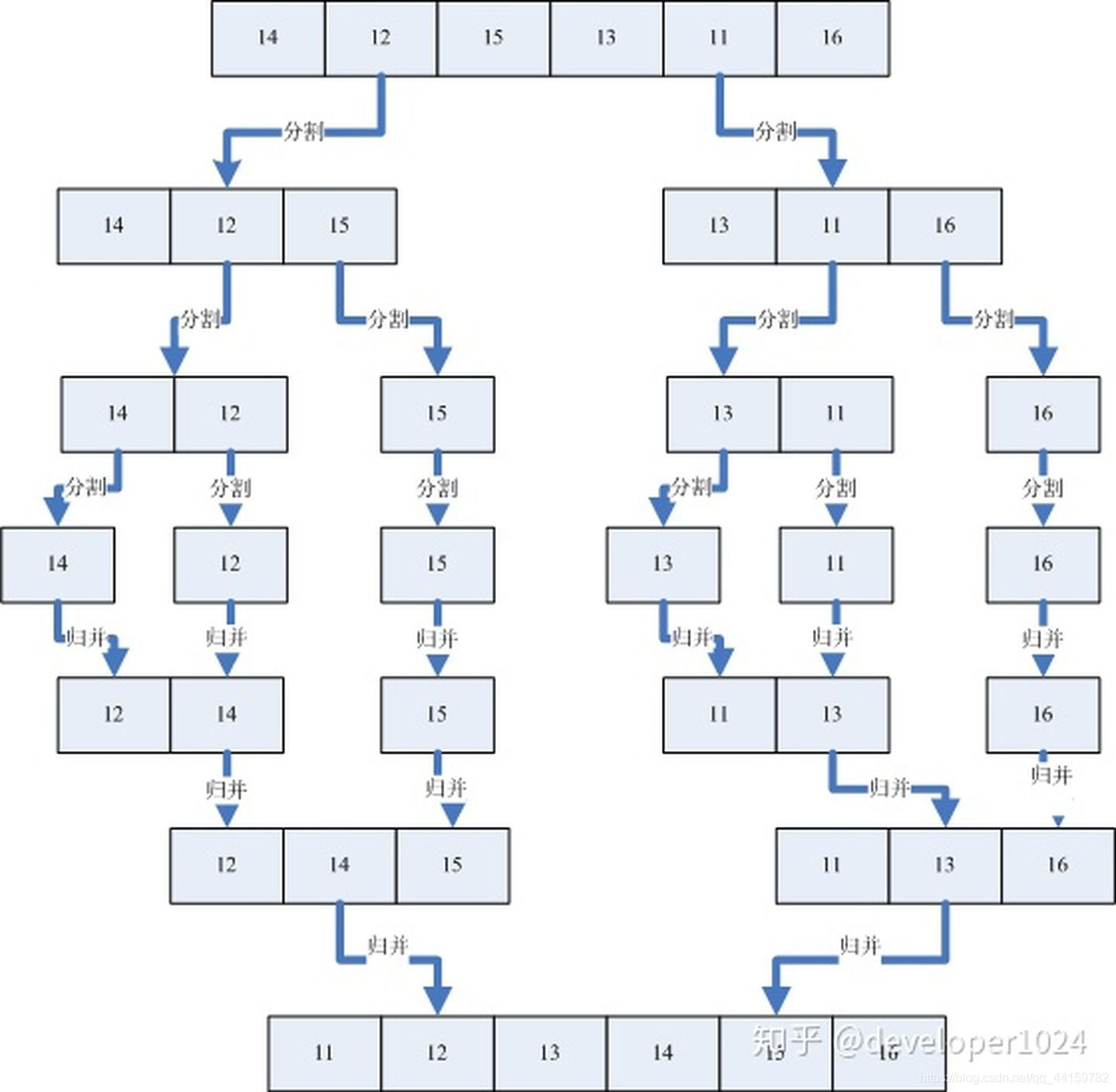
上圖中首先把一個未排序的序列從中間分割成2部分,再把2部分分成4部分,依次分割下去,直到分割成一個一個的資料,再把這些資料兩兩歸并到一起,使之有序,不停的歸并,最后成為一個排好序的序列,
總的來說就是,將陣列分成二組,依次類推,當分出來的小組只有一個資料時,可以認為這個小組組內已經達到了有序,然后再合并相鄰的二個小組就可以了,這樣通過先遞回的分解數列,再合并數列就完成了歸并排序,
3、動圖演示
4、演算法分析
歸并排序的時間復雜度,在最壞,最好和平均都是O(nlogn),這是效率,性能非常好的排序演算法,
只不過它需要占用 O(n)的記憶體空間,如果資料量一旦很大,記憶體可能吃不消,這是它的弱點和致命傷,而其他排序演算法,比如快速排序,希爾排序,都是就地排序演算法,它們不占用額外的記憶體空間,
5、代碼實作
public static void sort(int[] unsorted, int start, int end, int[] sorted){
if(start < end){
int middle = (start + end)/2;
sort(unsorted, start, middle, sorted);
sort(unsorted, middle+1, end, sorted);
merge(unsorted, start, middle, end, sorted);
System.out.println("區間["+start+","+end+"]:"+Arrays.toString(sorted));
}
}
private static void merge(int[] unsorted, int start, int middle, int end, int[] sorted) {
int num1 = start;
int num2 = middle + 1;
int k = start;
while(num1 <= middle && num2 <= end){
if(unsorted[num1] < unsorted[num2]){
sorted[k++] = unsorted[num1++];
}else{
sorted[k++] = unsorted[num2++];
}
}
while(num1 <= middle){
sorted[k++] = unsorted[num1++];
}
while(num2 <= end){
sorted[k++] = unsorted[num2++];
}
while (start <= end){
unsorted[start] = sorted[start];
start++;
}
}
歸并排序的優化可以參考歸并排序優化
歸并排序優化大白話歸并排序講解
七、快速排序
1、基本思想
通過一趟排序將待排記錄分隔成獨立的兩部分,其中一部分記錄的關鍵字均比另一部分的關鍵字小,則可分別對這兩部分記錄繼續進行排序,以達到整個序列有序,
2、演算法描述
快速排序使用分治法來把一個串(list)分為兩個子串(sub-lists),具體演算法描述如下:
從數列中挑出一個元素,稱為 “基準”(pivot);
重新排序數列,所有元素比基準值小的擺放在基準前面,所有元素比基準值大的擺在基準的后面(相同的數可以到任一邊),在這個磁區退出之后,該基準就處于數列的中間位置,這個稱為磁區(partition)操作;
遞回地(recursive)把小于基準值元素的子數列和大于基準值元素的子數列排序,
3、動圖演示
4、演算法分析
快速排序的時間復雜度在最壞的情況下是O(N2),因為和冒泡排序一樣,需要兩兩交換,平均情況下,快速排序的時間復雜度是O(NlogN)
5、代碼實作
private static int partition(int[] arr, int low, int high) {
//指定左指標i和右指標j
int i = low;
int j= high;
//將第一個數作為基準值,挖坑
int x = arr[low];
//使用回圈實作磁區操作
while(i<j){//5 8
//1.從右向左移動j,找到第一個小于基準值的值 arr[j]
while(arr[j]>=x && i<j){
j--;
}
//2.將右側找到小于基準數的值加入到左邊的(坑)位置, 左指標想中間移動一個位置i++
if(i<j){
arr[i] = arr[j];
i++;
}
//3.從左向右移動i,找到第一個大于等于基準值的值 arr[i]
while(arr[i]<x && i<j){
i++;
}
//4.將左側找到的列印等于基準值的值加入到右邊的坑中,右指標向中間移動一個位置 j--
if(i<j){
arr[j] = arr[i];
j--;
}
}
//使用基準值填坑,這就是基準值的最終位置
arr[i] = x;//arr[j] = y;
//回傳基準值的位置索引
return i; //return j;
}
private static void quickSort(int[] arr, int low, int high) {//???遞回何時結束
if(low < high){
//磁區操作,將一個陣列分成兩個磁區,回傳磁區界限索引
int index = partition(arr,low,high);
//對左磁區進行快排
quickSort(arr,low,index-1);
//對右磁區進行快排
quickSort(arr,index+1,high);
}
}
快速排序的優化方法可以參考快速排序優化方法快速排序的多種實作方式
關于快速排序和歸并排序的時間空間復雜度分析可以參考這一篇文章:排序(下):如何用快排思想在O(n)內查找第K個大元素?
八、堆排序
1、基本思想
堆排序(Heapsort)是指利用堆這種資料結構所設計的一種排序演算法,堆積是一個近似完全二叉樹的結構,并同時滿足堆積的性質:即子結點的鍵值或索引總是小于(或者大于)它的父節點,
堆是具有以下性質的完全二叉樹:每個結點的值都大于或等于其左右孩子結點的值,稱為大頂堆;或者每個結點的值都小于或等于其左右孩子結點的值,稱為小頂堆,
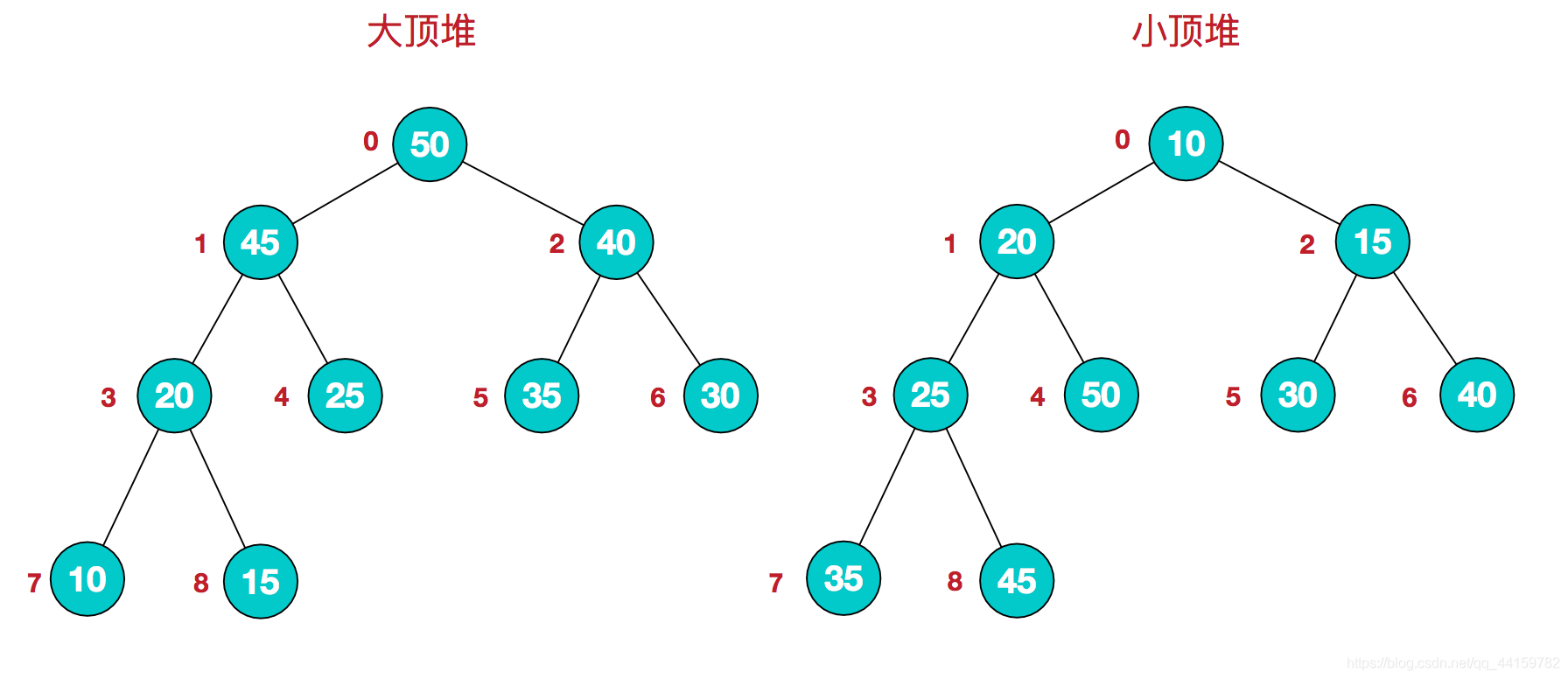
2、演算法描述
堆排序的基本思路:
a.將無需序列構建成一個堆,根據升序降序需求選擇大頂堆或小頂堆;
b.將堆頂元素與末尾元素交換,將最大元素"沉"到陣列末端;
c.重新調整結構,使其滿足堆定義,然后繼續交換堆頂元素與當前末尾元素,反復執行調整+交換步驟,直到整個序列有序,
詳細步驟可參考圖文解釋堆排序,寫的非常詳細,
3、動圖演示
4、演算法分析
堆排序是一種選擇排序,整體主要由構建初始堆+交換堆頂元素和末尾元素并重建堆兩部分組成,其中構建初始堆經推導復雜度為O(n),在交換并重建堆的程序中,需交換n-1次,而重建堆的程序中,根據完全二叉樹的性質,[log2(n-1),log2(n-2)…1]逐步遞減,近似為nlogn,所以堆排序時間復雜度一般認為就是O(nlogn)級,
關于堆排序和快速排序的比較可以參考這一篇文章:堆排序缺點何在
5、代碼實作
void heapSort(int array[], int n)
{
int i;
for (i=n/2;i>0;i--)
{
HeapAdjust(array,i,n);//從下向上,從右向左調整
}
for( i=n;i>1;i--)
{
swap(array, 1, i);
HeapAdjust(array, 1, i-1);//從上到下,從左向右調整
}
}
void HeapAdjust(int array[], int s, int n )
{
int i,temp;
temp = array[s];
for(i=2*s;i<=n;i*=2)
{
if(i<n&&array[i]<array[i+1])
{
i++;
}
if(temp>=array[i])
{
break;
}
array[s]=array[i];
s=i;
}
array[s]=temp;
}
void swap(int array[], int i, int j)
{
int temp;
temp=array[i];
array[i]=array[j];
array[j]=temp;
}
九、計數排序
1、基本思想
計數排序不是基于比較的排序演算法,其核心在于將輸入的資料值轉化為鍵存盤在額外開辟的陣列空間中, 作為一種線性時間復雜度的排序,計數排序要求輸入的資料必須是有確定范圍的整數,
2、演算法描述
找出待排序的陣列中最大和最小的元素;
統計陣列中每個值為i的元素出現的次數,存入陣列C的第i項;
對所有的計數累加(從C中的第一個元素開始,每一項和前一項相加);
反向填充目標陣列:將每個元素i放在新陣列的第C(i)項,每放一個元素就將C(i)減去1,
演算法步驟為:
第一步:找出原陣列中元素值最大的,記為max,
第二步:創建一個新陣列count,其長度是max加1,其元素默認值都為0,
第三步:遍歷原陣列中的元素,以原陣列中的元素作為count陣列的索引,以原陣列中的元素出現次數作為count陣列的元素值,
第四步:創建結果陣列result,起始索引index,
第五步:遍歷count陣列,找出其中元素值大于0的元素,將其對應的索引作為元素值填充到result陣列中去,每處理一次,count中的該元素值減1,直到該元素值不大于0,依次處理count中剩下的元素,
第六步:回傳結果陣列result,
詳細步驟可以參考這篇文章:深入淺出計數排序
3、動圖演示
4、演算法分析
計數排序的空間復雜度為O(n+k),其中n為資料規模,k為資料范圍,根據這個空間復雜度,我們可以得出以下結論:
在大規模資料的情況下,記憶體根本無法一口氣存下這么大規模的資料,這個時候就要使用歸并排序這種天然適合外部排序的演算法了,
再者,計數排序只適用于對資料范圍比較集中的資料集合進行排序,如果資料的值非常分散,需要額外申請的輔助陣列就更不可能存盤了,雖然可以通過離散化或者bitmap等方式來進行優化,但會增加演算法實作的復雜性,
而且,計數排序只能直接應用于非負整數的排序中,如果需要排序的資料含有負數,或者是其他型別的值,那么,還需要在不改變相對大小的情況下映射成非負整數,使整個排序邏輯變得復雜,
計數排序速度這么快,為什么使用范圍這么小?
5、代碼實作
/**
* 計數排序
*
* @param array
* @return
*/
public static int[] CountingSort(int[] array) {
if (array.length == 0) return array;
int bias, min = array[0], max = array[0];
for (int i = 1; i < array.length; i++) {
if (array[i] > max)
max = array[i];
if (array[i] < min)
min = array[i];
}
bias = 0 - min;
int[] bucket = new int[max - min + 1];
Arrays.fill(bucket, 0);
for (int i = 0; i < array.length; i++) {
bucket[array[i] + bias]++;
}
int index = 0, i = 0;
while (index < array.length) {
if (bucket[i] != 0) {
array[index] = i - bias;
bucket[i]--;
index++;
} else
i++;
}
return array;
}
十、桶排序
1、基本思想
桶排序是計數排序的變種,把計數排序中相鄰的m個”小桶”放到一個”大桶”中,在分完桶后,對每個桶進行排序(一般用快排),然后合并成最后的結果,
2、演算法描述
元素值域的劃分,也就是元素到桶的映射規則,映射規則需要根據待排序集合的元素分布特性進行選擇,若規則設計的過于模糊、寬泛,則可能導致待排序集合中所有元素全部映射到一個桶上,則桶排序向比較性質排序演算法演變,若映射規則設計的過于具體、嚴苛,則可能導致待排序集合中每一個元素值映射到一個桶上,則桶排序向計數排序方式演化,
排序演算法的選擇,從待排序集合中元素映射到各個桶上的程序,并不存在元素的比較和交換操作,在對各個桶中元素進行排序時,可以自主選擇合適的排序演算法,桶排序演算法的復雜度和穩定性,都根據選擇的排序演算法不同而不同,
1、設定一個定量的陣列當作空桶;
2、遍歷輸入資料,并且把資料一個一個放到對應的桶里去;
3、 對每個不是空的桶進行排序;
4、從不是空的桶里把排好序的資料拼接起來,
3、動圖演示
4、演算法分析
快速排序是將集合拆分為兩個值域,這里稱為兩個桶,再分別對兩個桶進行排序,最終完成排序,桶排序則是將集合拆分為多個桶,對每個桶進行排序,則完成排序程序,兩者不同之處在于,快排是在集合本身上進行排序,屬于原地排序方式,且對每個桶的排序方式也是快排,桶排序則是提供了額外的操作空間,在額外空間上對桶進行排序,避免了構成桶程序的元素比較和交換操作,同時可以自主選擇恰當的排序演算法對桶進行排序,
當然桶排序更是對計數排序的改進,計數排序申請的額外空間跨度從最小元素值到最大元素值,若待排序集合中元素不是依次遞增的,則必然有空間浪費情況,桶排序則是榷訓了這種浪費情況,將最小值到最大值之間的每一個位置申請空間,更新為最小值到最大值之間每一個固定區域申請空間,盡量減少了元素值大小不連續情況下的空間浪費情況,
具體可以參考這篇文章排序演算法(九):桶排序
5、代碼實作
/**
* 桶排序
*
* @param array
* @param bucketSize
* @return
*/
public static ArrayList<Integer> BucketSort(ArrayList<Integer> array, int bucketSize) {
if (array == null || array.size() < 2)
return array;
int max = array.get(0), min = array.get(0);
// 找到最大值最小值
for (int i = 0; i < array.size(); i++) {
if (array.get(i) > max)
max = array.get(i);
if (array.get(i) < min)
min = array.get(i);
}
int bucketCount = (max - min) / bucketSize + 1;
ArrayList<ArrayList<Integer>> bucketArr = new ArrayList<>(bucketCount);
ArrayList<Integer> resultArr = new ArrayList<>();
for (int i = 0; i < bucketCount; i++) {
bucketArr.add(new ArrayList<Integer>());
}
for (int i = 0; i < array.size(); i++) {
bucketArr.get((array.get(i) - min) / bucketSize).add(array.get(i));
}
for (int i = 0; i < bucketCount; i++) {
if (bucketSize == 1) { // 如果帶排序陣列中有重復數字時 感謝 @見風任然是風 朋友指出錯誤
for (int j = 0; j < bucketArr.get(i).size(); j++)
resultArr.add(bucketArr.get(i).get(j));
} else {
if (bucketCount == 1)
bucketSize--;
ArrayList<Integer> temp = BucketSort(bucketArr.get(i), bucketSize);
for (int j = 0; j < temp.size(); j++)
resultArr.add(temp.get(j));
}
}
return resultArr;
}
十一、基數排序
1、基本思想
基數排序是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次類推,直到最高位,有時候有些屬性是有優先級順序的,先按低優先級排序,再按高優先級排序,最后的次序就是高優先級高的在前,高優先級相同的低優先級高的在前,
2、演算法描述
1、取得陣列中的最大數,并取得位數;
2、arr為原始陣列,從最低位開始取每個位組成radix陣列;
3、對radix進行計數排序(利用計數排序適用于小范圍數的特點);
3、動圖演示

4、演算法分析
基數排序基于分別排序,分別收集,所以是穩定的,但基數排序的性能比桶排序要略差,每一次關鍵字的桶分配都需要O(n)的時間復雜度,而且分配之后得到新的關鍵字序列又需要O(n)的時間復雜度,假如待排資料可以分為d個關鍵字,則基數排序的時間復雜度將是O(d*2n) ,當然d要遠遠小于n,因此基本上還是線性級別的,
這三種排序演算法都利用了桶的概念,但對桶的使用方法上有明顯差異:
基數排序:根據鍵值的每位數字來分配桶
計數排序:每個桶只存盤單一鍵值
桶排序:每個桶存盤一定范圍的數值
5、代碼實作
/**
* 基數排序
* @param array
* @return
*/
public static int[] RadixSort(int[] array) {
if (array == null || array.length < 2)
return array;
// 1.先算出最大數的位數;
int max = array[0];
for (int i = 1; i < array.length; i++) {
max = Math.max(max, array[i]);
}
int maxDigit = 0;
while (max != 0) {
max /= 10;
maxDigit++;
}
int mod = 10, div = 1;
ArrayList<ArrayList<Integer>> bucketList = new ArrayList<ArrayList<Integer>>();
for (int i = 0; i < 10; i++)
bucketList.add(new ArrayList<Integer>());
for (int i = 0; i < maxDigit; i++, mod *= 10, div *= 10) {
for (int j = 0; j < array.length; j++) {
int num = (array[j] % mod) / div;
bucketList.get(num).add(array[j]);
}
int index = 0;
for (int j = 0; j < bucketList.size(); j++) {
for (int k = 0; k < bucketList.get(j).size(); k++)
array[index++] = bucketList.get(j).get(k);
bucketList.get(j).clear();
}
}
return array;
}
總結
搞到這里,這樣一篇長篇博客終于弄完了,寫一篇長文博客真的很不容易,雖然很大一部分內容都是直接參考了優質博主的文章,但是匯總這么多文章真是一件很不容易的事情,希望以后自己也可以發一個原創的文章,看完這篇文章的你會不會有所識訓了,希望大家指出文章中的錯誤,我會及時修正,也會陸續增添文章的內容,點贊,關注,大家一起進步,
參考資料
前端面試十大經典排序演算法(影片演示)
十大經典排序演算法總結(Java語言實作)
十大經典排序演算法動圖圖解
十大經典排序演算法
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/277504.html
標籤:其他
上一篇:各專欄及學習資料分享
下一篇:51單片機數碼管顯示歷史鍵值